Python数据分析实战① Python实现数据可视化
文章目录
- 一、数据可视化介绍
- 二、matplotlib和pandas画图
- 1.matplotlib简介和简单使用
- 2.matplotlib常见作图类型
- 3.使用pandas画图
- 4.pandas中绘图与matplotlib结合使用
- 三、订单数据分析展示
- 四、Titanic灾难数据分析显示
一、数据可视化介绍
数据可视化是指将数据放在可视环境中、进一步理解数据的技术,可以通过它更加详细地了解隐藏在数据表面之下的模式、趋势和相关性。
Python提供了很多数据可视化的库:
- matplotlib
是Python基础的画图库,官网为https://matplotlib.org/,在案例地址https://matplotlib.org/gallery/index.html中介绍了很多种类的图和代码示例。 - pandas
是在matplotlib的基础上实现画图的,官网为https://pandas.pydata.org/。 - matlpotlib和pandas结合
利用pandas进行数据读取、数据清洗和数据选取等操作,再使用matlpotlib显示数据。
二、matplotlib和pandas画图
1.matplotlib简介和简单使用
matplotlib是Python最著名的绘图库,它提供了一整套和Matlab相似的命令API,十分适合进行交互式制图;也可以方便地将它作为绘图控件,嵌入GUI应用程序中。
文档相当完备,并且Gallery页面中有上百幅缩略图,打开之后都有源代码。如果需要绘制某种类型的图,只需要在这个页面中进行简单的浏览、复制、粘贴,就能实现画图。
https://matplotlib.org/gallery.html中有大量的缩略图案例可以使用。
matplotlib画图的子库:
- pyplot子库
提供了和matlab类似的绘图API,方便用户快速绘制2D图表。 - pylab模块
其中包括了许多numpy和pyplot中常用的函数,方便用户快速进行计算和绘图,可以用于IPython中的快速交互式使用。
使用matplotlib快速绘图导入库和创建绘图对象如下:
import matplotlib.pyplot as pltplt.figure(figsize=(8,4))
创建绘图对象时,同时使它成为当前的绘图对象。
通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
dpi参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80。
因此本例中所创建的图表窗口的宽度为8 * 80 = 640像素。
也可以不创建绘图对象直接调用plot方法绘图,matplotlib会自动创建一个绘图对象。
如果需要同时绘制多幅图表的话,可以给figure传递一个整数参数指定图标的序号,如果所指定序号的绘图对象已经存在的话,将不创建新的对象,而只是让它成为当前绘图对象。
pyplot画图简单使用如下:
import numpy as np
import matplotlib.pyplot as plt # 首先载入matplotlib的绘图模块pyplot,并且重命名为pltx = np.linspace(0, 10, 1000) y = np.sin(x)
z = np.cos(x**2)plt.figure(figsize=(8,4)) #2 创建绘图对象plt.plot(x,y,label="$sin(x)$",color="red",linewidth=2)
plt.plot(x,z,"b--",label="$cos(x^2)$") plt.xlabel("Time(s)")
plt.ylabel("Volt")
plt.title("PyPlot First Example")
plt.ylim(-1.2,1.2)
plt.legend()plt.show()
显示:
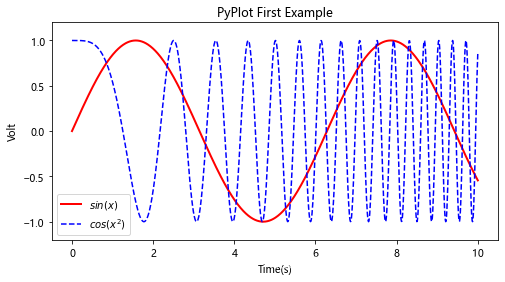
其中:
plt.plot(x,y,label="$sin(x)$",color="red",linewidth=2)
plt.plot(x,z,"b--",label="$cos(x^2)$")
第一行将x、y数组传递给plot之后,用关键字参数指定各种属性:
- label
给所绘制的曲线取一个名字,用于在图示(legend)中显示;
在字符串前后添加$符号,就会使用内置的latex引擎绘制数学公式。 - color
指定曲线的颜色:颜色可以用英文单词,或者以#字符开头的三个16进制数,例如#ff0000表示红色,或者用值在0到1范围之内的三个元素的元组表示,例如(1.0, 0.0, 0.0)也表示红色。 - linewidth
指定曲线的宽度,可以不是整数,也可以使用缩写形式的参数名lw。 - 曲线样式
第三个参数b--指定曲线的颜色和线型,它通过一些易记的符号指定曲线的样式,其中b表示蓝色,--表示线型为虚线。
在IPython中输入plt.plot?可以查看格式化字符串以及各个参数的详细说明。
plt.xlabel("Time(s)")
plt.ylabel("Volt")
plt.title("PyPlot First Example")
plt.ylim(-1.2,1.2)
plt.legend()
通过一系列函数设置当前Axes对象的各个属性:
- xlabel、ylabel
分别设置X、Y轴的标题文字。 - title
设置子图的标题。 - xlim、ylim
分别设置X、Y轴的显示范围。 - legend
显示图示,即图中表示每条曲线的标签(label)和样式的矩形区域。
最后调用plt.show()显示出绘图窗口。
一个绘图对象(figure)可以包含多个轴(axis),在Matplotlib中用轴表示一个绘图区域,可以将其理解为子图。上面的第一个例子中,绘图对象只包括一个轴,因此只显示了一个轴(子图Axes)。可以使用subplot函数快速绘制有多个轴的图表。
subplot函数的调用形式如下:
subplot(numRows, numCols, plotNum)
subplot将整个绘图区域等分为numRows行和numCols列个子区域,然后按照从左到右、从上到下的顺序对每个子区域进行编号,左上的子区域的编号为1。
如果numRows、numCols和plotNum这三个数都小于10的话,可以把它们缩写为一个整数,例如subplot(323)和subplot(3,2,3)是相同的。
subplot在plotNum指定的区域中创建一个轴对象,如果新创建的轴和之前创建的轴重叠,之前的轴将被删除。
如下:
for idx, color in enumerate("rgbyck"):plt.subplot(320+idx+1, facecolor=color)
plt.show()
显示:
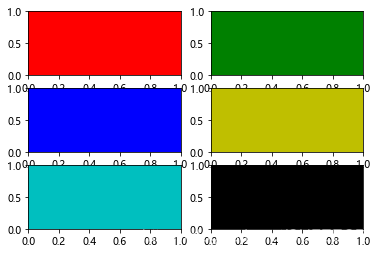
可以看到:
创建3行2列共6个轴,通过facecolor参数给每个轴设置不同的背景颜色。
如果希望某个轴占据整个行或者列的话,可以如下:
plt.subplot(221) # 第一行的左图
plt.subplot(222) # 第一行的右图
plt.subplot(212) # 第二整行
plt.show()
显示:
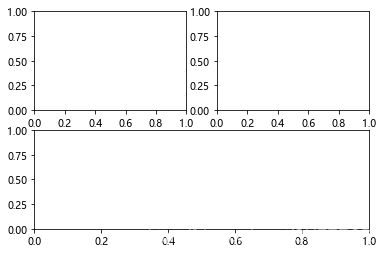
再举一个创建子图的例子:
plt.figure(1) # 创建图表1
plt.figure(2) # 创建图表2
ax1 = plt.subplot(211) # 在图表2中创建子图1
ax2 = plt.subplot(212) # 在图表2中创建子图2x = np.linspace(0, 3, 100)
for i in range(5):plt.figure(1) # 选择图表1plt.plot(x, np.exp(i*x/3))plt.sca(ax1) # 选择图表2的子图1,将当前轴实例设置为axplt.plot(x, np.sin(i*x))plt.sca(ax2) # 选择图表2的子图2plt.plot(x, np.cos(i*x))
plt.show()
显示:
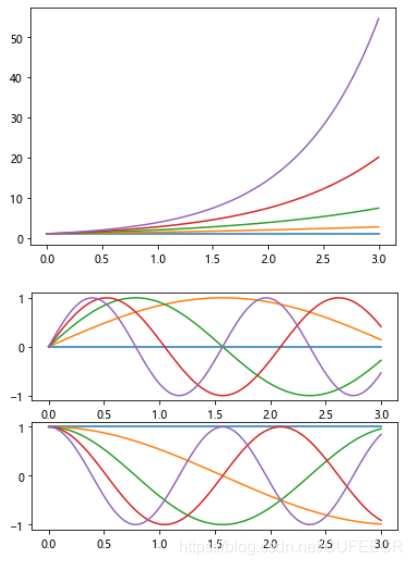
首先通过figure()创建了两个图表,它们的序号分别为1和2;
然后在图表2中创建了上下并排的两个子图,并用变量ax1和ax2保存。
在循环中:
先调用figure(1)让图表1成为当前图表,并在其中绘图。
然后调用sca(ax1)和sca(ax2)分别让子图ax1和ax2成为当前子图,并在其中绘图。
当它们成为当前子图时,包含它们的图表2也自动成为当前图表,因此不需要调用figure(2)依次在图表1和图表2的两个子图之间切换,逐步在其中添加新的曲线即可。
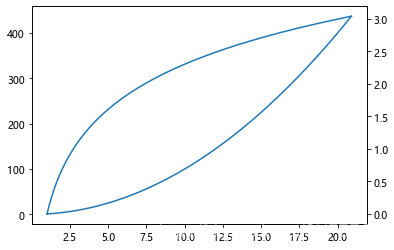
其中,twinx()可以为图增加纵坐标轴,使用如下:
x = np.arange(1, 21, 0.1)y1 = x * x
y2 = np.log(x)plt.plot(x, y1)# 添加一条y轴的坐标轴
plt.twinx()
plt.plot(x, y2)plt.show()
显示:
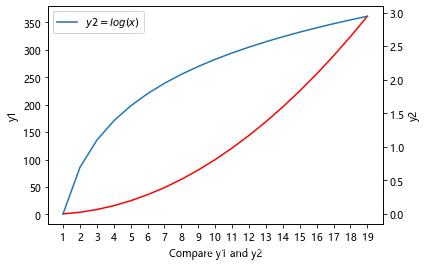
进一步使用如下:
import numpy as np
import matplotlib.pyplot as pltx = np.arange(1, 20, 1)
y1 = x * x
y2 = np.log(x)fig = plt.figure()
ax1 = fig.add_subplot(111)ax1.plot(x, y1, label = "$y1 = x * x$", color = "r")
ax1.legend(loc = 0)
# 设置对应坐标轴的名称
ax1.set_ylabel("y1")
ax1.set_xlabel("Compare y1 and y2")# 设置x轴刻度的数量
ax = plt.gca()
ax.locator_params("x", nbins = 20)# 添加坐标轴,并在新添加的坐标轴中画y2 = log(x)图像
ax2 = plt.twinx()
ax2.set_ylabel("y2")
ax2.plot(x, y2, label = "$y2 = log(x)$")
ax2.legend(loc = 0)plt.show()
显示:
2.matplotlib常见作图类型
画图在工作中在所难免,尤其在进行数据探索时显得尤其重要,matplotlib常见的一些作图种类如下:
- 散点图
- 条形图
- 饼图
- 三维图
先导入库和基础配置如下:
from __future__ import division
from numpy.random import randn
import numpy as np
import os
import matplotlib.pyplot as plt
np.random.seed(12345)
plt.rc('figure', figsize=(10, 6))
from pandas import Series, DataFrame
import pandas as pd
np.set_printoptions(precision=4)get_ipython().magic(u'matplotlib inline')
get_ipython().magic(u'pwd')
打印:
'XXX\\3_Visualization_Of_Data_Analysis\\basicuse'
基础画图如下:
# matplotlib创建图表
plt.plot([1,2,3,2,3,2,2,1])
plt.show()plt.plot([4,3,2,1],[1,2,3,4])
plt.show()
显示:

画三角函数曲线如下:
# 画简单的图形
from pylab import *
x=np.linspace(-np.pi,np.pi,256,endpoint=True)
c,s=np.cos(x),np.sin(x)
plot(x,c, color="blue", linewidth=2.5, linestyle="-", label="cosine")
plot(x,s,color="red", linewidth=2.5, linestyle="-", label="sine")
show()
显示:

画散点图如下:
# 散点图
from pylab import *
n = 1024
X = np.random.normal(0,1,n)
Y = np.random.normal(0,1,n)
scatter(X,Y)
show()
显示:
画条形图如下:
#条形图
from pylab import *
n = 12
X = np.arange(n)
Y1 = (1-X/float(n)) * np.random.uniform(0.5,1.0,n)
Y2 = (1-X/float(n)) * np.random.uniform(0.5,1.0,n)
bar(X, +Y1, facecolor='#9999ff', edgecolor='white')
bar(X, -Y2, facecolor='#ff9999', edgecolor='white')
for x,y in zip(X,Y1):text(x+0.4, y+0.05, '%.2f' % y, ha='center', va= 'bottom')
ylim(-1.25,+1.25)
show()
显示:
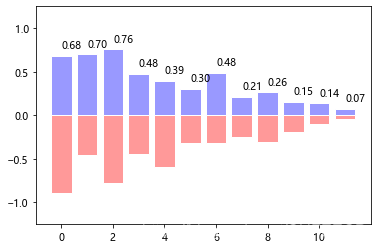
饼图如下:
#饼图
from pylab import *
n = 20
Z = np.random.uniform(0,1,n)
pie(Z)
show()
显示:
画立体图如下:
#画三维图
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from pylab import *
fig=figure()
ax=Axes3D(fig)
x=np.arange(-4,4,0.1)
y=np.arange(-4,4,0.1)
x,y=np.meshgrid(x,y)
R=np.sqrt(x**2+y**2)
z=np.sin(R)
ax.plot_surface(x,y,z,rstride=1,cstride=1,cmap='hot')
show()
显示:
画其他简单图形如下:
#更多简单的图形
x = [1,2,3,4]
y = [5,4,3,2]plt.figure()
plt.subplot(2,3,1)
plt.plot(x, y)plt.subplot(232)
plt.bar(x, y)plt.subplot(233)
plt.barh(x, y)plt.subplot(234)
plt.bar(x, y)
y1 = [7,8,5,3]
plt.bar(x, y1, bottom=y, color = 'r')plt.subplot(235)
plt.boxplot(x)plt.subplot(236)
plt.scatter(x,y)plt.show()
显示:
3.使用pandas画图
pandas中画图的主要类型包括:
- 累和图
- 柱状图
- 散点图
- 饼图
- 矩阵散点图
先导入所需要的库:
from __future__ import division
from numpy.random import randn
import numpy as np
import os
import matplotlib.pyplot as plt
np.random.seed(12345)
from pandas import Series, DataFrame
import pandas as pd
%matplotlib inline
在pandas中,有行标签、列标签和分组信息等,如果使用matplotlib画图,可能需要一大堆的代码,现在调用Pandas的plot()方法即可简单实现。
画简单线图如下:
#线图
s = Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot()
plt.show()
显示:
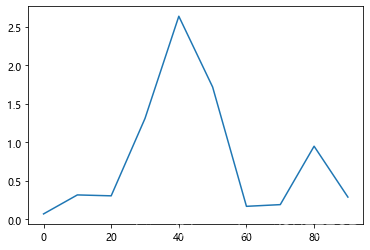
pandas.Series.plot()的常见参数及说明如下:
| 参数 | 说明 |
|---|---|
| label | 用于图例的标签 |
| ax | 要在其上进行绘制的matplotlib subplot对象,如果没有设置,则使用当前matplotlib subplot |
| style | 将要传给matplotlib的风格字符串,例如'ko-' |
| alpha | 图表的填充不透明(0-1) |
| kind | 可以是'line'、'bar'、'barh'、'kde' |
| logy | 在Y轴上使用对数标尺 |
| use_index | 将对象的索引用作刻度标签 |
| rot | 旋转刻度标签(0-360) |
| xticks | 用作X轴刻度的值 |
| yticks | 用作Y轴刻度的值 |
| xlim | X轴的界限 |
| ylim | Y轴的界限 |
| grid | 显示轴网格线 |
Pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象,从而能够在网络布局中更为灵活地处理subplot的位置。DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例。
画多列线图如下:
df = DataFrame(np.random.randn(10, 4).cumsum(0),columns=['A', 'B', 'C', 'D'],index=np.arange(0, 100, 10))
df.plot()
plt.show()
显示:
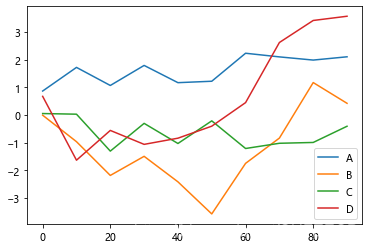
相对于Series,DataFrame还有一些用于对列进行灵活处理的选项,例如要将所有列都绘制到一个subplot中还是创建各自的subplot等,具体如下:
| 参数 | 说明 |
|---|---|
| subplots | 将各个DataFrame列绘制到单独的subplot中 |
| sharex | 如果subplots=True,则共用同一个X轴,包括刻度和界限 |
| sharey | 如果subplots=True,则共用同一个Y轴,包括刻度和界限 |
| figsize | 表示图像大小的元组 |
| title | 表示图像标题的字符串 |
| legend | 添加—个subplot图例(默认为True) |
| sort_columns | 以字母表顺序绘制各列,默认使用前列顺序 |
画简单累和图如下:
#线图 CUM
plt.close('all')s = Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot()
plt.show()
显示:
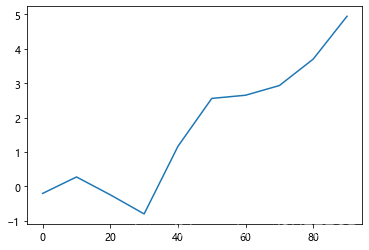
画多列的类和图如下:
df = DataFrame(np.random.randn(10, 4).cumsum(0),columns=['A', 'B', 'C', 'D'],index=np.arange(0, 100, 10))
df.plot()
plt.show()
显示:
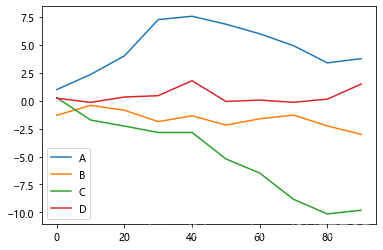
当提升了数据规模之后,累和图如下:
s = pd.Series([2, np.nan, 5, -1, 0])
print(s)print(s.cumsum())#画累和图
ts=pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000',periods=1000))
ts=ts.cumsum()
ts.plot()
plt.show()
df=pd.DataFrame(np.random.randn(1000,4),index=ts.index,columns=list('ABCD'))# cumulative意为累计、累积,这个函数可以返回一个累计值,经常会遇到月累计、年累计这种指标,会用这个函数
df=df.cumsum()
df.plot()
plt.show()
打印:
0 2.0
1 NaN
2 5.0
3 -1.0
4 0.0
dtype: float64
0 2.0
1 NaN
2 7.0
3 6.0
4 6.0
dtype: float64
显示:
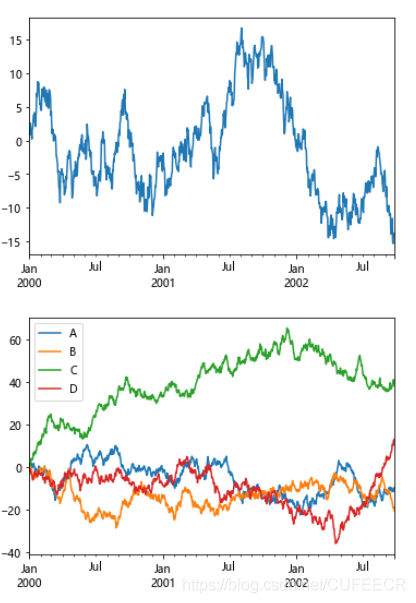
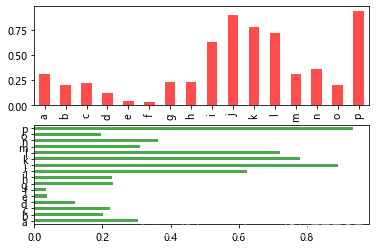
画Series柱状图如下:
#柱形图
fig, axes = plt.subplots(2, 1)
data = Series(np.random.rand(16), index=list('abcdefghijklmnop'))
data.plot(kind='bar', ax=axes[0], color='r', alpha=0.7)
data.plot(kind='barh', ax=axes[1], color='g', alpha=0.7)
plt.show()
显示:
DataFrame画柱状图:
df = DataFrame(np.random.rand(6, 4),index=['one', 'two', 'three', 'four', 'five', 'six'],columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))df.plot(kind='bar') #图例plt.figure()df.plot(kind='barh', stacked=True, alpha=0.5)plt.show()
显示:
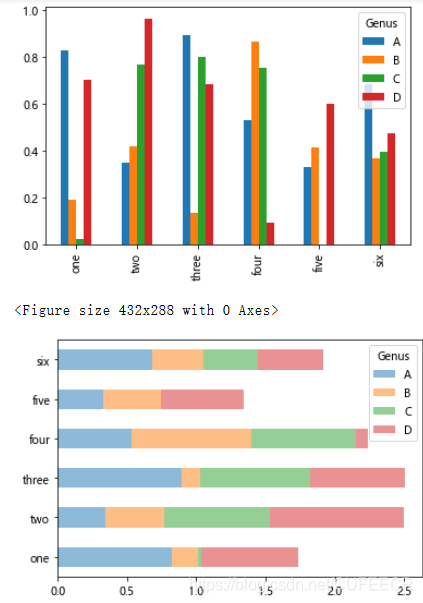
可以看到:
对于DataFrame,柱形图会将每一行的值分为一组;
DataFrame的各列名称都被用作了图例的标题;
设置stacked=True即可为DataFrame生成堆积柱形图,这样每行的值就会被堆积在一起。
餐馆小费数据如下:
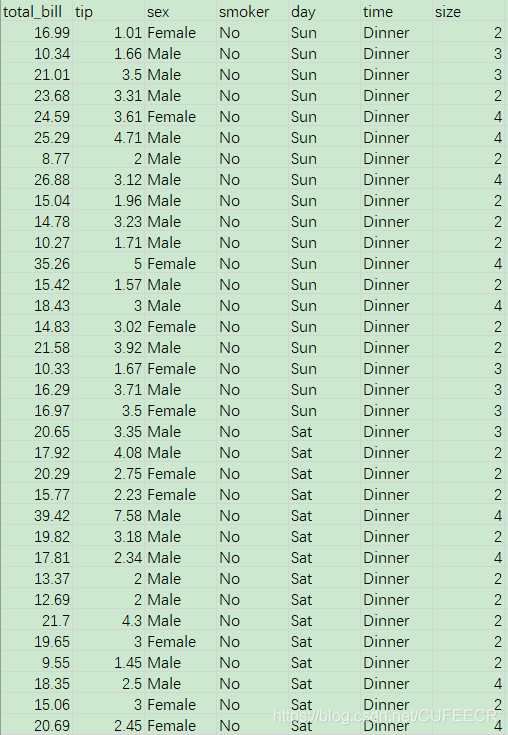
进行数据可视化如下:
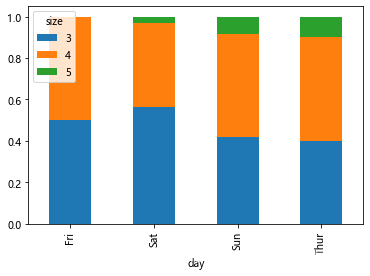
tips = pd.read_csv('tips.csv') # 各数据点的百分比
party_counts = pd.crosstab(tips.day, tips['size']) #size聚会人数
print(party_counts)party_counts = party_counts.iloc[:, 2:5] # 选取一部分数据
print(party_counts)party_pcts = party_counts.div(party_counts.sum(1).astype(float), axis=0) # 转换成百分比, 1 代表维度 行的方向
print(party_pcts)
party_pcts.plot(kind='bar', stacked=True) #每天的高度都是1
plt.show()
打印:
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
size 3 4 5
day
Fri 1 1 0
Sat 18 13 1
Sun 15 18 3
Thur 4 5 1
size 3 4 5
day
Fri 0.500000 0.50000 0.000000
Sat 0.562500 0.40625 0.031250
Sun 0.416667 0.50000 0.083333
Thur 0.400000 0.50000 0.100000
显示:
画较复杂的柱状图如下:
#画柱状图
df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df2.plot(kind='bar') #分开并列线束
df2.plot(kind='bar', stacked=True) #四个在同一个里面显示 百分比的形式
df2.plot(kind='barh', stacked=True)#纵向显示
plt.show()
df4=pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),'c':np.random.randn(1000)-1},columns=list('abc'))
df4.plot(kind='hist', alpha=0.5)
df4.plot(kind='hist', stacked=True, bins=20)
df4['a'].plot(kind='hist', orientation='horizontal',cumulative=True) #cumulative是按顺序排序
plt.show()
#Area Plot
df = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df.plot(kind='area')
df.plot(kind='area',stacked=False)
plt.show()
显示:
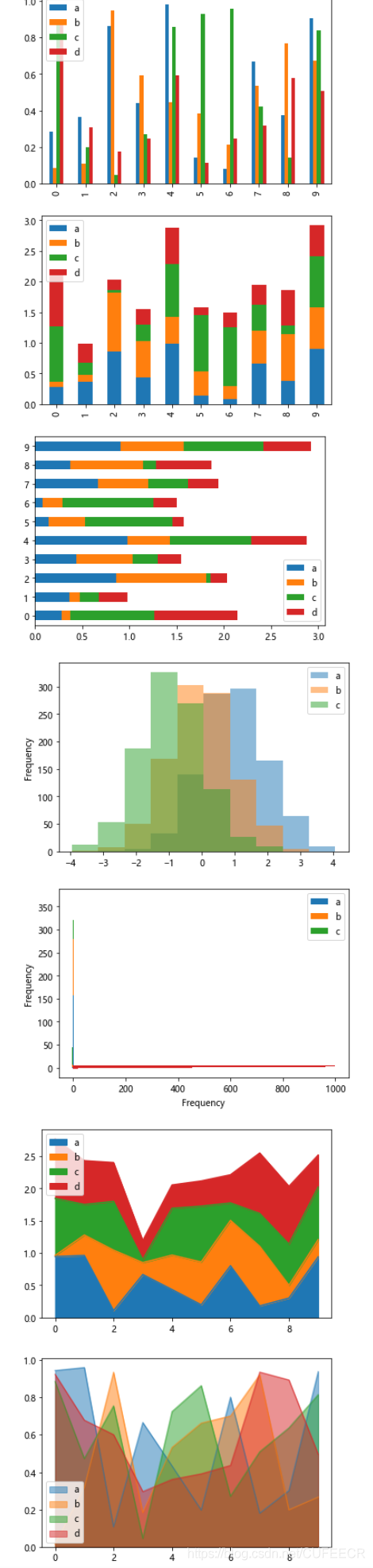
直方图histogram:
是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。
调用Series.hist()即可实现,在之后调用plot时加上参数kind='kde'即可生成一张密度图。
根据小费数据画直方图如下:
# 直方图--给小费占总费用的比例的分布图
plt.figure()tips['tip_pct'] = tips['tip'] / tips['total_bill'] # 增加一个新的列
tips['tip_pct'].hist(bins=50) # 分为50个区间 plt.figure()
显示:
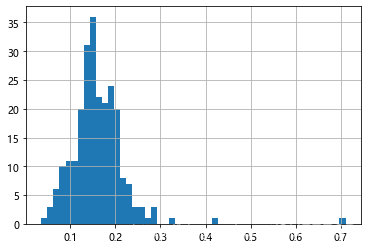
在统计学中,核密度估计(KDE)是一种估计随机变量概率密度函数(PDF)的非参数方法,利用高斯核生成核密度估计图如下:
comp1 = np.random.normal(0, 1, size=200) # N(0, 1) 模拟出 0,1 的正态分布数据 0,期望值, 1 方差值
comp2 = np.random.normal(10, 2, size=200) # 10,期望值, 2 方差值 方差值大,跨度就大些
values = Series(np.concatenate([comp1, comp2]))
values.hist(bins=100, alpha=0.3, color='k', density=True)
values.plot(kind='kde', style='k--')
显示:
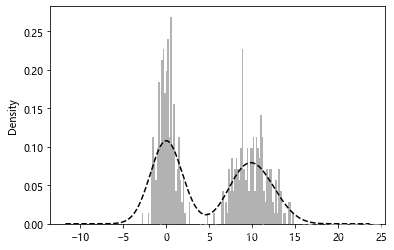
根据小费数据画密度图如下:
tips['tip_pct'].plot(kind='kde') # 利用高斯核生成核密度估计图plt.figure()
显示:
散点图scatter plot:
是观察两个一维数据序列之间的关系的有效手段,研究两个变量的关系,特别是是否有线性或曲线相关性。matplotlib的scatter方法是绘制散布图的主要方法。利用plt.scatter()即可轻松绘制一张简单的散布图。pandas也提供了能从DataFrame创建散步图矩阵的scatter_matrix()方法,还支持在对角线上放置变量的直方图或密度图。
画简单散点图如下:
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
df.plot(kind='scatter', x='a', y='b')
df.plot(kind='scatter', x='a', y='b',color='DarkBlue', label='Group 1')
plt.show()
显示:
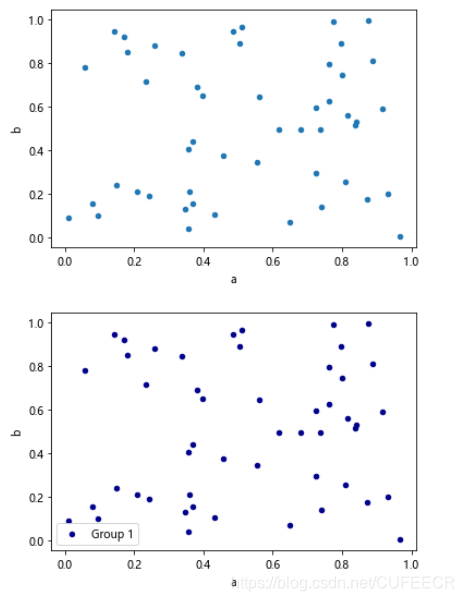
画散点矩阵图和直方图如下:
df = pd.DataFrame(np.random.randn(1000, 4), columns=['A','B','C','D'])
pd.plotting.scatter_matrix(df, alpha=0.2)
显示:‘
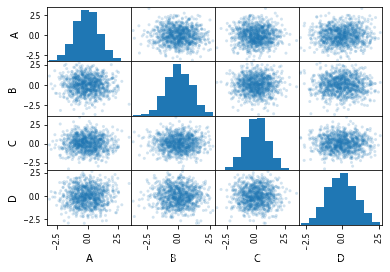
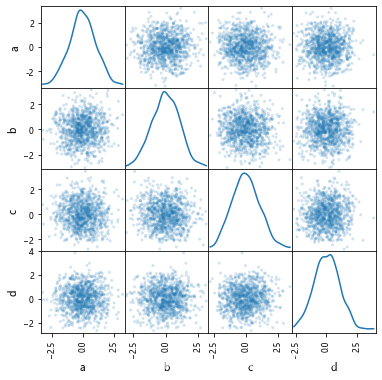
画三点矩阵图和密度图如下:
df = pd.DataFrame(np.random.randn(1000, 4), columns=['a', 'b', 'c', 'd'])
pd.plotting.scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal='kde')
plt.show()
显示:
宏观经济数据macrodata.csv如下:
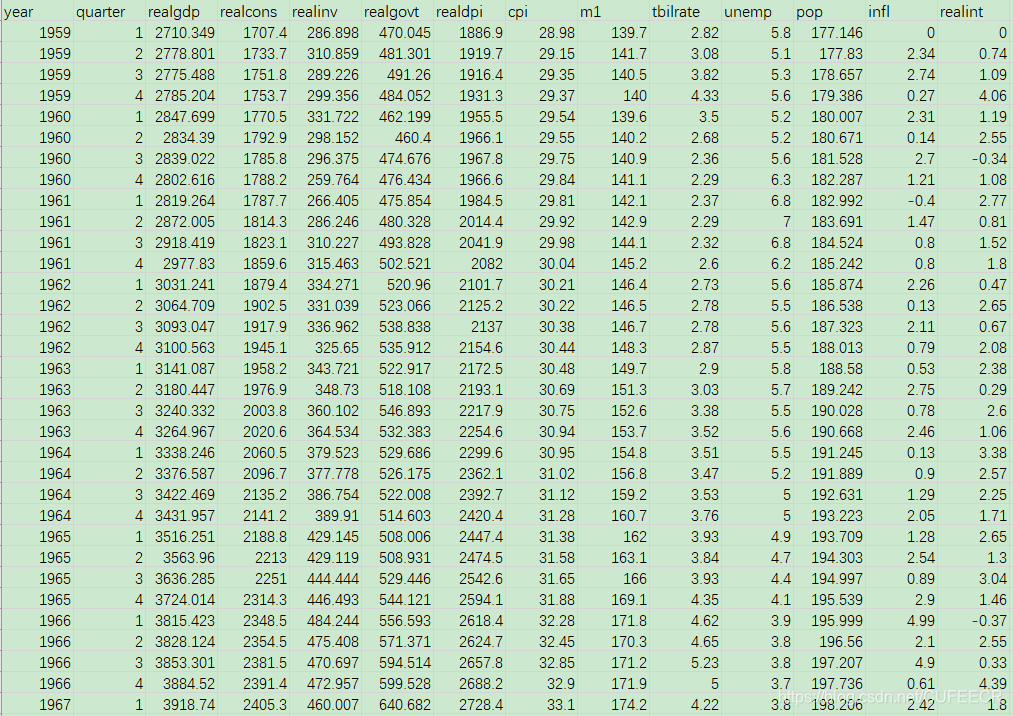
读取和选取数据如下:
macro = pd.read_csv("macrodata.csv")
data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
trans_data = np.log(data).diff().dropna()
trans_data[-5:]
print(trans_data[-5:])
plt.figure()
打印:
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560<Figure size 432x288 with 0 Axes><Figure size 432x288 with 0 Axes>
画散点图和散点矩阵图如下:
plt.scatter(trans_data['m1'], trans_data['unemp'])
plt.title('Changes in log %s vs. log %s' % ('m1', 'unemp'))pd.plotting.scatter_matrix(trans_data, diagonal='kde', color='k', alpha=0.3)
plt.show()
显示:
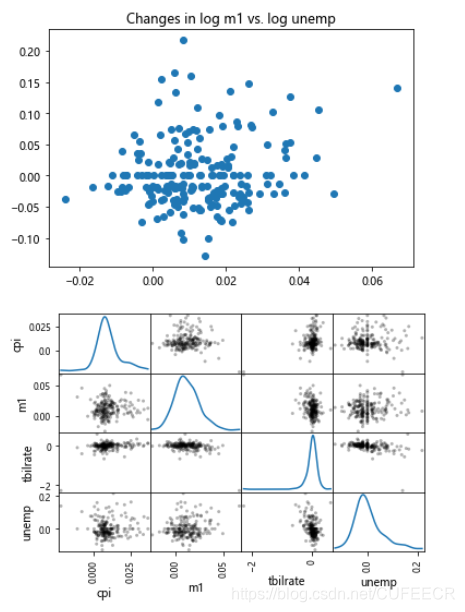
可以简单看出各经济变量之间是否存在关系。
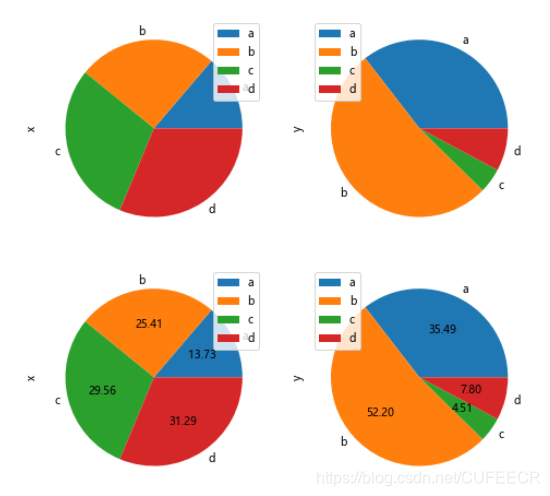
画饼图示意如下:
#饼图
df = pd.DataFrame(3 * np.random.rand(4, 2), index=['a', 'b', 'c', 'd'], columns=['x', 'y'])
df.plot(kind='pie', subplots=True, figsize=(8, 4))
df.plot(kind='pie', subplots=True,autopct='%.2f',figsize=(8, 4)) # 显示百分比
plt.show()
显示:
4.pandas中绘图与matplotlib结合使用
有时候想方便地集成的绘图方式,比如df.plot(),但是又想加上matplotlib的很多操
作来增强图片的表现力,这时可以将两者结合。
构造数据如下:
df=pd.DataFrame(np.random.randn(3,4),index=list('123'),columns=list('ABCD'))
df2=pd.DataFrame(np.random.randn(4,4),index=list('1234'),columns=list('ABCD'))
display(df, df2)
显示:
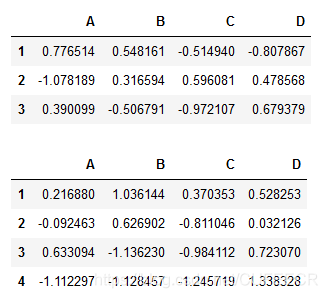
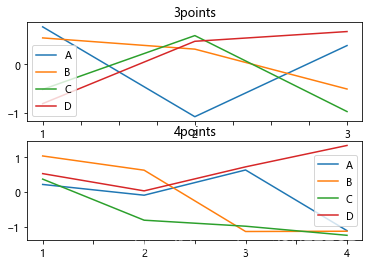
可视化如下:
fig, axes = plt.subplots(2, 1)
df.plot(ax=axes[0])
df2.plot(ax=axes[1])
axes[0].set_title('3points')
axes[1].set_title('4points')
显示:
三、订单数据分析展示
主要作图包括订单与GMV趋势、商家趋势、订单来源分布、类目占比,涉及折线图、饼图、堆积柱形图、组合图等类型,目标是综合使用pandas和matplotlib。
订单数据.csv如下:
导库和读取数据如下:
#导入库
import pandas as pd
import matplotlib.pyplot as plt# plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文标签
# plt.rcParams['axes.unicode_minus'] = False #显示符号#读取数据
orders = pd.read_excel("订单数据.xlsx")
orders['付款时间'] = orders['付款时间'].astype('str') #方便作图,将日期改为字符串格式
不同日期订单金额折线图如下:
#折线图
data1 = orders.groupby('付款时间')['支付金额'].sum() #处理数据
x = data1.index #x值
y = data1.values #y值plt.title('GMV走势') #图表标题
plt.plot(x,y,label='GMV',color='red') #label是图例,color是线条颜色
plt.legend(loc=1) #显示图例,loc设置图例展示位置,默认为0(最优位置)、1右上角、2左上角
plt.show() #显示图
显示:
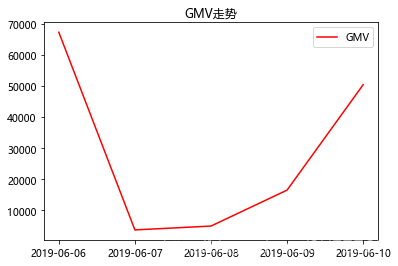
可以看出不同时间订单金额的变化趋势,找出哪些天订单金额较高、哪些天较低。
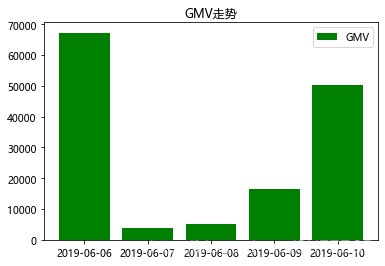
还可以用柱状图显示:
#柱形图
data1 = orders.groupby('付款时间')['支付金额'].sum() #处理数据
x = data1.index #x值
y = data1.values #y值plt.title('GMV走势') #图表标题
plt.bar(x,y,label='GMV',color='green') #其实很简单,只要把plot换成bar
plt.legend(loc=1) #显示图例,loc设置图例展示位置,默认为0(最优位置)、1右上角、2左上角
plt.show() #显示图
显示:
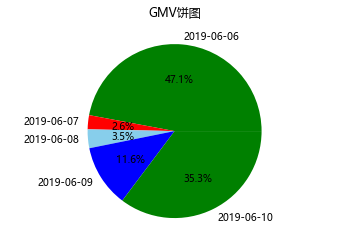
还可以用饼图直观看出各天所占的比例:
#饼图
data1 = orders.groupby('付款时间')['支付金额'].sum() #处理数据
x = data1.index #x值
y = data1.values #y值plt.title('GMV饼图') #图表标题
plt.axis('equal') #正圆,饼图会默认是椭圆
plt.pie(y,labels=x,autopct='%1.1f%%',\colors=['green','red','skyblue','blue']) #labels是标签,autopct是占比保留1位小数
plt.show() #显示图
显示:
还可以为柱形图添加数据标签,如下:
# 为柱形图添加数据标签
data1 = orders.groupby('付款时间')['支付金额'].sum() #处理数据
x = data1.index #x值
y = data1.values #y值plt.title('GMV走势') #图表标题
plt.bar(x,y,label='GMV',color='green') #label是图例,color是线条颜色
plt.legend(loc=1) #显示图例,loc设置图例展示位置,默认为0(最优位置)、1右上角、2左上角
for a,b in zip(x,y): #添加数据标签plt.text(a,b,'%d'%b,ha='center',va='bottom') #在x,y的位置上添加订单数据
plt.show() #显示图
显示:

工作中很常见柱形图与折线图的组合图形,但是两个指标的数量级往往不一致,如果只用一个纵坐标,可能数量级小的那个会看不到图,所以要用到主次坐标轴,如下:
#组合图形&主次坐标轴
data1 = orders.groupby('付款时间')[['支付金额','订单编号']].agg({'支付金额':'sum','订单编号':'count'}) #处理数据
x = data1.index #x轴
y1 = data1['支付金额'] #y主轴数据
y2 = data1['订单编号'] #y次轴数据plt.title('订单&GMV走势') #图表标题plt.bar(x,y1,label='GMV') #GMV柱形图
plt.ylim(0,100000) #设置y1的坐标轴范围
for a,b in zip(x,y1): #添加数据标签plt.text(a,b+0.1,'%d'%b,ha='center',va='bottom') #在x,y1+0.1的位置上添加GMV数据 , '%d'%y 即标签数据, ha和va控制标签位置
plt.legend(loc=1) #显示图例,loc=1为右上角plt.twinx() #次纵坐标轴
plt.plot(x,y2,label='订单数',color='red') #订单折线图,红色
plt.ylim(-2100,2200) #设置y2的坐标轴范围
for a,b in zip(x,y2): #添加数据标签plt.text(a,b+0.2,'%d'%b,ha='center',va='bottom') #在x,y2+0.1的位置上添加订单数据
plt.legend(loc=2) #显示图例,loc=2为左上角
显示:
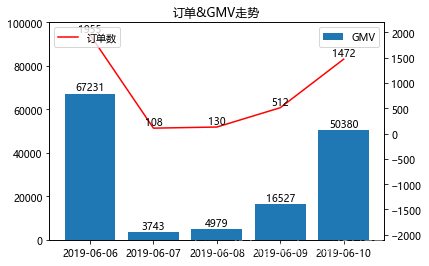
需要注意:
纵坐标轴范围、图例、数据标签,需要在各自的纵坐标里设置,即先进行主纵坐标的设置,之后是次纵坐标。如果都放在后面去设置,那么text(x,y)的y位置,就都是次纵坐标了。
制作简单的数据仪表盘如下:
#制作数据仪表盘
plt.figure(figsize=(15,8)) #设置图的整体大小 #总共4个子图,用subplot()#第一个:每日订单与成交额走势,柱形图与折线图组合
data1 = orders.groupby('付款时间')[['支付金额','订单编号']].agg({'支付金额':'sum','订单编号':'count'}) #处理数据
x = data1.index #x轴
y1 = data1['支付金额'] #y主轴数据
y2 = data1['订单编号'] #y次轴数据plt.subplot(2,2,1) #2×2个子图:第一个
plt.title('订单&GMV走势') #图表标题plt.bar(x,y1,label='GMV') #GMV柱形图
plt.ylim(0,100000) #设置y1的坐标轴范围
for a,b in zip(x,y1): #添加数据标签plt.text(a,b+0.1,'%d'%b,ha='center',va='bottom') #在x,y1+0.1的位置上添加GMV数据 , '%d'%y 即标签数据, ha和va控制标签位置
plt.legend(loc=1) #显示图例,loc=1为右上角plt.twinx() #次纵坐标轴
plt.plot(x,y2,label='订单数',color='red') #订单折线图,红色
plt.ylim(-2100,2200) #设置y2的坐标轴范围
for a,b in zip(x,y2): #添加数据标签plt.text(a,b+0.2,'%d'%b,ha='center',va='bottom') #在x,y2+0.1的位置上添加订单数据
plt.legend(loc=2) #显示图例,loc=2为左上角#第二个:主要商家,每日GMV趋势。 多条折线图
#数据处理
data2 = pd.DataFrame(orders[orders['商家名称'].isin(['店铺3','店铺5','店铺6','店铺9'])].groupby(['商家名称','付款时间'])['支付金额'].sum())
#店铺3、5、6、9的成交额
data2_tmp = pd.DataFrame(index=set(data2.index.get_level_values(0)),columns=set(data2.index.get_level_values(1)))for ind in data2_tmp.index:for col in data2_tmp.columns:data2_tmp.loc[ind,col] = data2.loc[ind,:].loc[col,'支付金额']plt.subplot(2,2,2) #2×2个子图:第二个
plt.title('主要商家GMV趋势')
colors = ['green','red','skyblue','blue'] #设置曲线颜色
x = sorted(data2_tmp.columns) #日期是横轴for i in range(len(data2_tmp.index)):plt.plot(x,data2_tmp.loc[data2_tmp.index[i],:],label=data2_tmp.index[i],color=colors[i])
plt.legend() #显示图例,loc默认为0,即最优位置#第三个:订单来源端口,每日趋势。 堆积柱形图
#数据处理
data3_tmp = pd.DataFrame(orders.groupby(['平台来源','付款时间'])['支付金额'].sum())
data3 = pd.DataFrame(index=set(data3_tmp.index.get_level_values(0)),columns=set(data3_tmp.index.get_level_values(1)))
for ind in data3.index:print(ind)for col in data3.columns:data3.loc[ind,col] = data3_tmp.loc[ind,:].loc[col,'支付金额']barx = data3.columns
bary1 = data3.loc['android',:]
bary2 = data3.loc['iphone',:]plt.subplot(2,2,3) #2×2个子图:第三个
plt.title('订单来源端口分布') #底部是安卓,顶部是iPhone。先画iPhone=安卓+iPhone,再画安卓
plt.bar(barx,bary1+bary2,label='iphone',color='green')
plt.bar(barx,bary1,label='android',color='red') #底部是bar_y数据
plt.legend()
for a,b,c in zip(barx,bary1,bary2): #添加数据标签,注意:底部是安卓,即y1plt.text(a,1000,'%d'%b,ha='center',va='bottom') #在a,1000的位置上,添加数据标签plt.text(a,b+c-1000,'%d'%c,ha='center',va='bottom') #调整标签的位置#第四个:类目占比。 饼图#最近一天的类目金额
data4 = orders[orders['付款时间']==max(orders['付款时间'])].groupby('类目')['支付金额'].sum().sort_values() plt.subplot(2,2,4) #2×2个子图:第四个
plt.title('最近一天的类目占比')
plt.axis('equal') #正圆,饼图会默认是椭圆
plt.pie(data4.values,labels=data4.index,autopct='%1.1f%%',\colors=['green','red','skyblue','blue']) #显示百分数,1位小数
plt.show()
显示:
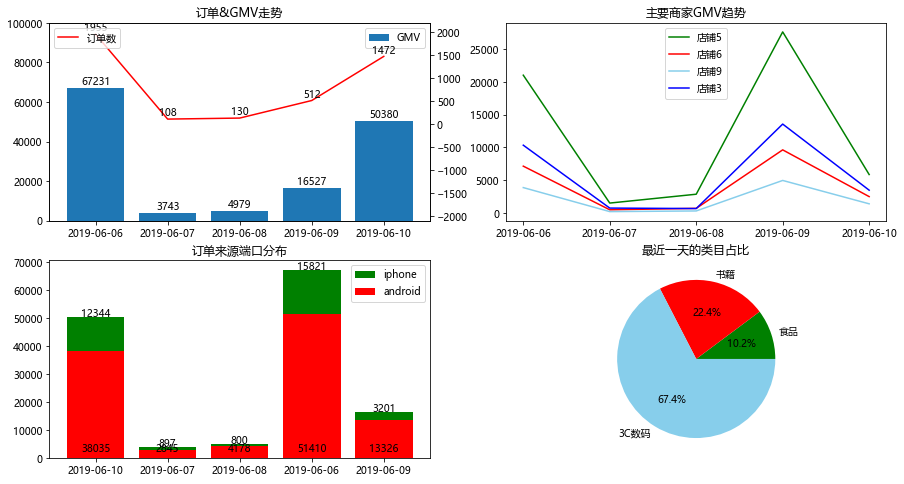
过程稍复杂,需慢慢理解。
四、Titanic灾难数据分析显示
主要过程如下:
- 导入必要的库
- 导入数据
- 设置为索引
- 绘制展示男女乘客比例的扇形图
- 绘制展示船票Fare与乘客年龄和性别的散点图
- 生还人数
- 绘制展示船票价格的直方图
数据titanicdata.csv如下:
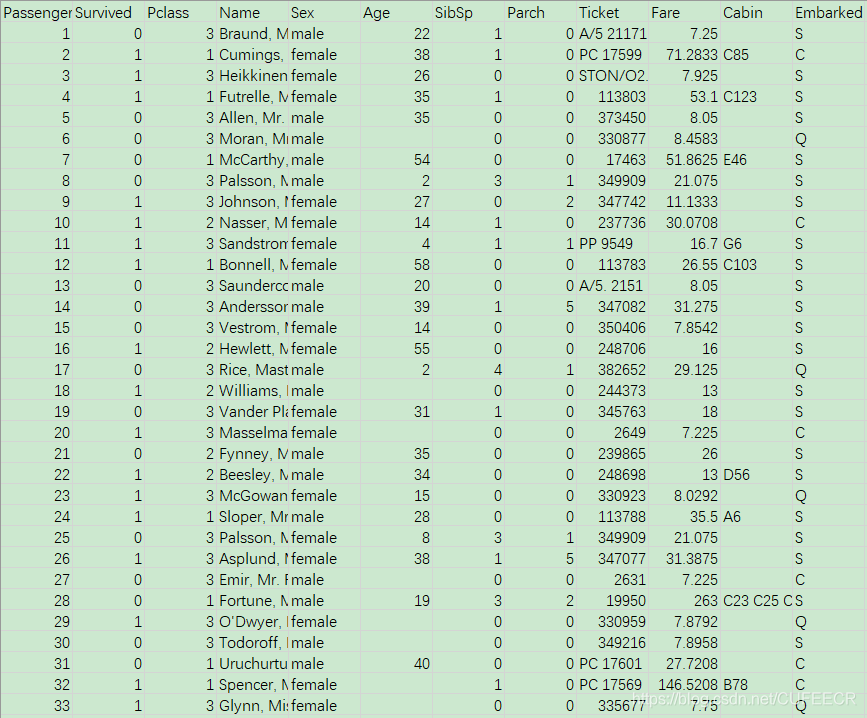
导库和读取数据如下:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np%matplotlib inlinetitanic = pd.read_csv("titanicdata.csv")titanic.head()
显示:

设置索引如下:
titanic.set_index('PassengerId').head()
显示:
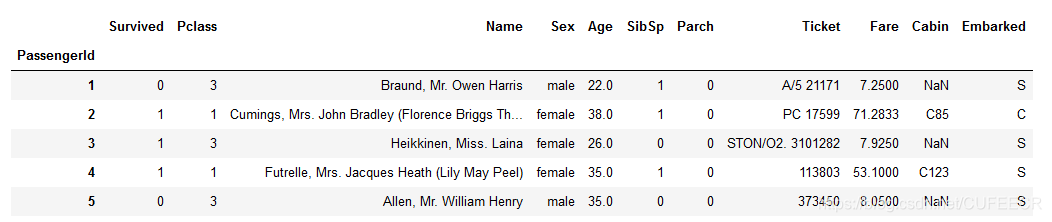
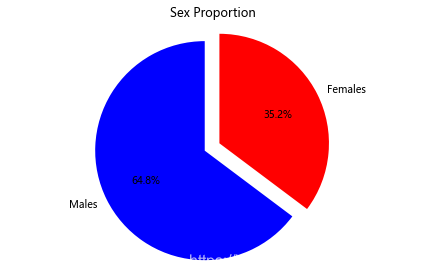
创建一个饼图,展示男性/女性的比例:
# sum the instances of males and females
males = (titanic['Sex'] == 'male').sum()
females = (titanic['Sex'] == 'female').sum()# put them into a list called proportions
proportions = [males, females]# Create a pie chart
plt.pie(# using proportionsproportions,# with the labels being officer nameslabels = ['Males', 'Females'],# with no shadowsshadow = False,# with colorscolors = ['blue','red'],# with one slide exploded outexplode = (0.15 , 0),# with the start angle at 90%startangle = 90,# with the percent listed as a fractionautopct = '%1.1f%%')# View the plot drop above
plt.axis('equal')# Set labels
plt.title("Sex Proportion")# View the plot
plt.tight_layout()
plt.show()
显示:
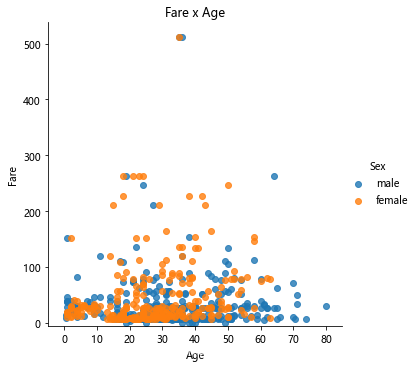
用所付费用和年龄创建散点图,按性别区分图的颜色:
# 创建绘图
lm = sns.lmplot(x = 'Age', y = 'Fare', data = titanic, hue = 'Sex', fit_reg=False)# set title
lm.set(title = 'Fare x Age')# 获取axes对象并对其进行调整
axes = lm.axes
axes[0,0].set_ylim(-5,)
axes[0,0].set_xlim(-5,85)
显示:
查看幸存人数:
titanic.Survived.sum()
打印:
342
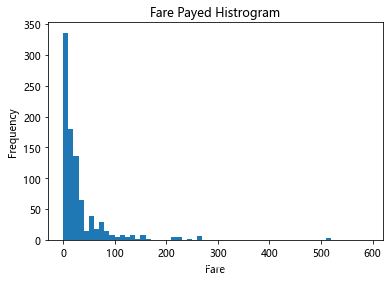
创建一个柱状图,显示已付车费:
# 将值从顶部到最小值排序,并对前5项进行切片
df = titanic.Fare.sort_values(ascending = False)# 使用numpy创建存储箱间隔
binsVal = np.arange(0,600,10)
binsVal# 创建绘图
plt.hist(df, bins = binsVal)# 设置标题和标签
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.title('Fare Payed Histrogram')# 展示绘图
plt.show()
显示:
相关文章:
Python数据分析实战① Python实现数据可视化
文章目录 一、数据可视化介绍二、matplotlib和pandas画图1.matplotlib简介和简单使用2.matplotlib常见作图类型3.使用pandas画图4.pandas中绘图与matplotlib结合使用 三、订单数据分析展示四、Titanic灾难数据分析显示 一、数据可视化介绍 数据可视化是指将数据放在可视环境中…...

ASP.NET 开发几个知识点
1、 皮肤设定: 项目右键,建立皮肤 app_themes 文件夹,右键 建立 web from 皮肤文件, 设定皮肤样式。全局使用皮肤 web.config 增加 <pages styleSheetTheme"Skin1" /> ,或在 具体页面 头 增加 sty…...

企业微信H5开发遇到的坑
企业微信官方推荐wx.agentConfig引用<script src"https://open.work.weixin.qq.com/wwopen/js/jwxwork-1.0.0.js"></script>是没有效果的 必须引用以下代码才有效果,这也是我看了社区的回答才有所收获,是一个坑 且VUE引用在线的…...

mysql使用--分组查询
1.分组数据 _1.复杂的数据统计 如:SELECT AVG(score) FROM student_score WHERE subject ‘Mysql是怎样运行的’; 上述实现查询指定课程的平均成绩。对FROM得到的结果集1,通过WHER进一步过滤得到结果集2。对结果集2中每一行执行汇总计算。 _2.创建分组 …...

Android网络模块基本实现步骤
Android网络模块主要是用于访问网络和获取数据,下面是网络模块的基本实现步骤: 选择网络框架:Android中常用的网络框架有HttpURLConnection、OkHttp、Volley和Retrofit等。最新的版本已经支持使用Kotlin协程完成网络请求,可以根据…...
)
Rust6.2 An I/O Project: Building a Command Line Program (mini_grep)
Rust学习笔记 Rust编程语言入门教程课程笔记 参考教材: The Rust Programming Language (by Steve Klabnik and Carol Nichols, with contributions from the Rust Community) Lecture 12: An I/O Project: Building a Command Line Program project: minigrep src/main.r…...

云轴科技ZStack信创云平台支撑长江航务管理局35套航运管理系统
信创是数字中国建设的重要组成部分,也是数字经济发展的关键推动力量。作为云基础软件企业,云轴科技ZStack产品矩阵全面覆盖数据中心云基础设施,ZStack信创云首批通过可信云《一云多芯IaaS平台能力要求》先进级,是其中唯一兼容四种…...

Canal+Kafka实现MySQL与Redis数据同步(一)
CanalKafka实现MySQL与Redis数据同步(一) 前言 在很多业务情况下,我们都会在系统中加入redis缓存做查询优化。 如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新redis的代码。 这种数据同步的代码跟业务代码糅合…...

集合的运算
集合的运算 #include <stdio.h> #include <stdlib.h> void print(int size, char arr[]) {if (size 0) {printf("null");}for (int i 0; i < size; i) {printf("%c", arr[i]);}printf("\n"); } int main() {char U[] { a,b,c,…...

在MySQL上实现间隔5分钟汇总取数及相关字符串、时间处理方法实践
1. 实践案例需求描述 查询mysql数据库,按每5分钟分组获取3个小时内的电量数据,参考SQL语句如下。 select sd.RecordTime RecordTime, sd.sddl sddl,sd.pvdl ,cap.capdl capdl from ((SELECT CONCAT(DATE_FORMAT(RecordTime,%Y-%m-%d %H:), LPAD(floor(…...

什么是AIGC
1 定义 "AIGC"代表“人工智能生成内容”(Artificial Intelligence Generated Content),它指的是使用人工智能(AI)技术自动生成的内容,这些内容可以包括文本、图像、音乐、视频或其他多媒体形式。…...
〖大前端 - 基础入门三大核心之JS篇㊳〗- DOM访问元素节点
说明:该文属于 大前端全栈架构白宝书专栏,目前阶段免费,如需要项目实战或者是体系化资源,文末名片加V!作者:不渴望力量的哈士奇(哈哥),十余年工作经验, 从事过全栈研发、产品经理等工作…...

GitHub Universe 2023:AI 技术引领软件开发创新浪潮
GitHub 是全球领先的软件开发和协作平台,数百万开发者和企业在此分享、学习和创建卓越的软件。同时 GitHub 处在 AI 技术前沿,通过其先进的 AI 技术增强开发者体验并赋能未来软件开发的使命。在今天的文章中,我们将一起看看在 GitHub 年度大会…...

数据结构:红黑树的插入实现(C++)
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》《Linux》 文章目录 一、红黑树二、红黑树的插入三、代码实现总结 一、红黑树 红黑树的概念: 红黑树是一颗二叉搜索树,但在每个节点上增加一个存储位表示节点的颜色&…...
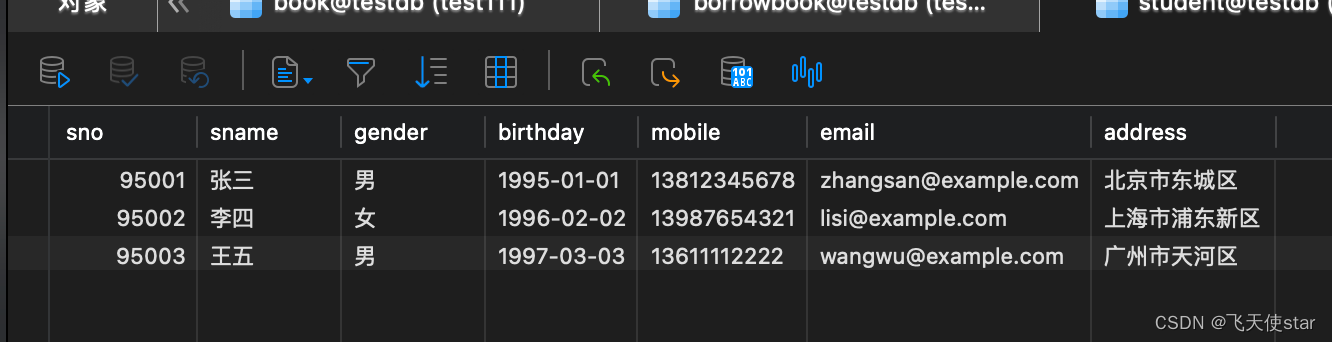
飞天使-django之数据库简介
文章目录 增删改查解决数据库不能存储中文问题创建表数据类型表的基本操作主键唯一键 unique外键实战 增删改查 四个常用的语句查询 : insert delete update select insert into student(Sno,name) values(95001,"张三") delete from student where name张三 upda…...

Flink之KeyedState
前面的文章中介绍过Operator State,这里介绍一下Keyed State. 在使用Operator State时必须要实现CheckpointFunction接口,而Keyed State则不需要,在使用keyBy(...)分组分组后,调用的函数必须是实现RichFuntion接口的函数才可以使用Keyed State.同样使用Keyed State也必须开启Ch…...
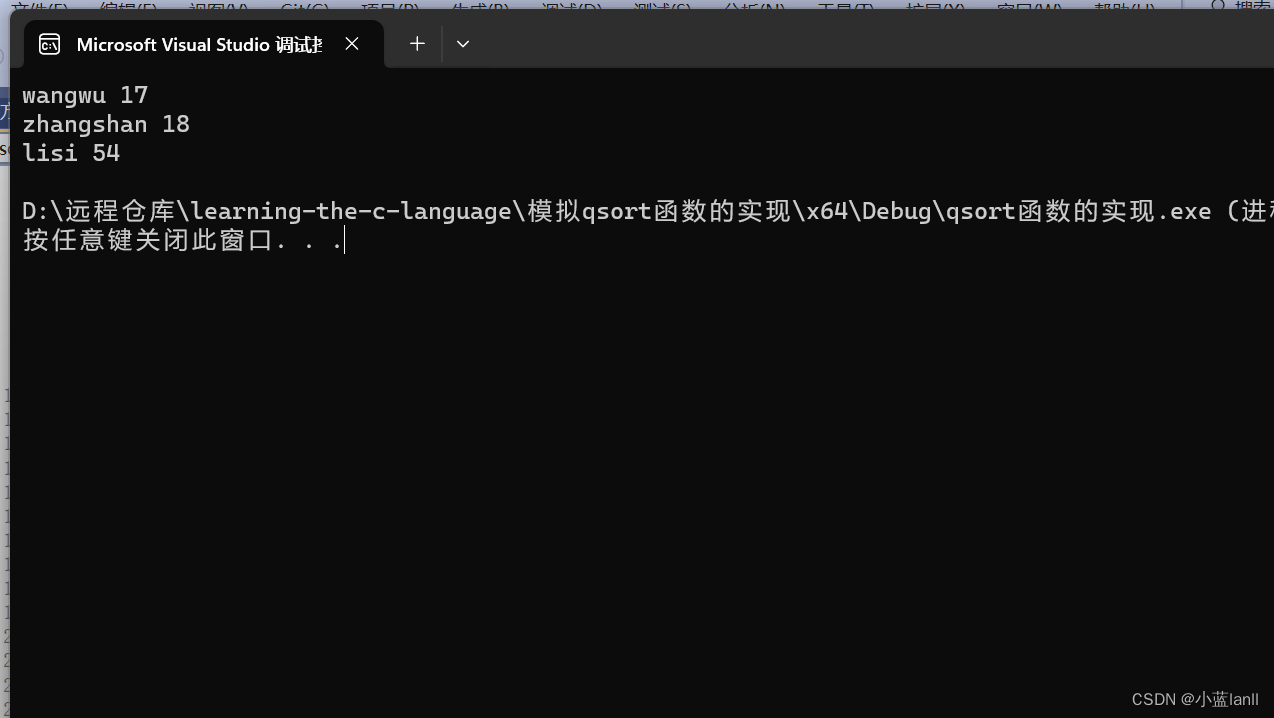
c语言:模拟实现qsort函数
qsort函数的功能: qsort相较于冒泡排序法,不仅效率更快,而且能够比较不同类型的元素,如:浮点数,结构体等等。这里我们来模拟下qsort是如何实现这一功能的,方便我们对指针数组有一个更深层次的理…...

从0开始学习数据结构 C语言实现 1.前篇及二分查找算法
一、前篇 1、什么是数据结构? 数据结构是带有结构特性的数据元素的集合,它研究的是数据的逻辑结构和数据的物理结构以及它们之间的相互关系 2、时间复杂度与空间复杂度 大O符号是用于描述函数渐进行为的数学符号 常用函数的增长表 阶乘O(n!) > 指数…...
VSCode 使用CMakePreset找不到cl.exe编译器的问题
在用vscode开发c项目的时候,使用预先配置的CMakePresets.json可以把一些特定的cmake选项固定下来,在配置时直接使用 "cmake --config --preset presetname"就可以进行配置,免去在命令行输入过多的配置参数。 但是在vscode中&#…...
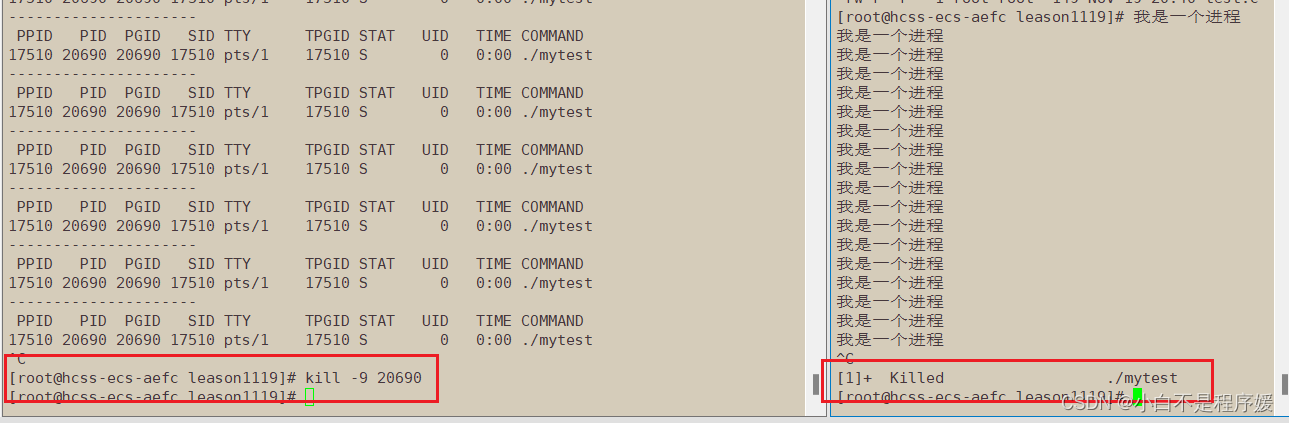
【Linux系统化学习】进程的状态 | 僵尸进程 | 孤儿进程
个人主页点击直达:小白不是程序媛 Linux专栏:Linux系统化学习 目录 操作系统进程的状态 运行状态 阻塞状态 进程阻塞的现象 挂起阻塞状态 Linux进程状态 Linux内核源代码怎么说 R(running状态)运行状态 S(sl…...

5分钟上手!Linux用户必备的Apple Emoji字体安装教程
5分钟上手!Linux用户必备的Apple Emoji字体安装教程 【免费下载链接】apple-emoji-ttf Brings Apples vibrant color emojis to Linux, Windows, and the Web 项目地址: https://gitcode.com/gh_mirrors/ap/apple-emoji-ttf apple-emoji-ttf项目能够为Linux和…...
)
从塔防到RPG:在Unity里用A*算法实现不同游戏类型的敌人AI(实战案例)
从塔防到RPG:在Unity里用A*算法实现不同游戏类型的敌人AI(实战案例)当你在玩一款塔防游戏时,是否好奇那些怪物为何总能找到通往终点的最优路径?或者在RPG游戏中,NPC为何能绕过复杂地形精准追踪玩家…...

ARM SME架构下的浮点外积运算优化实践
1. ARM SME架构与浮点外积运算概述在当代处理器设计中,SIMD(单指令多数据)架构已成为提升计算性能的关键技术。ARMv9引入的SME(Scalable Matrix Extension)指令集将这种并行计算能力提升到了矩阵运算层面,特…...

饲料颗粒机生产厂家
行业痛点分析:一场关于“磨损”与“成本”的持久战在饲料加工领域,颗粒机设备的稳定性与耐用性,直接决定了生产线的整体效率与运营成本。然而,长期困扰行业的核心痛点之一,是磨盘与压辊的耐磨性问题。根据行业调研数据…...

高质量测试 Skill 编写手册 -- 渐进式披露
什么是渐进式披露渐进式披露是高质量 Skill 中最基础也最重要的技巧之一。 用一句话表达就是:不要把所有的规则和知识都一股脑的写在提示词中交给大模型,而是只在必要的时候,加载对应的知识。为什么需要渐进式披露在大模型领域有一句话叫上下…...

2026最新免费在线去水印工具详细教程,在线去本地视频水印保姆级指南
你是不是也遇到过这种情况?辛辛苦苦在网上找到一个绝美视频素材想用在剪辑里,结果画面正中央横着一个硕大的水印;或者刷小红书看到一段干货满满的教学视频,想保存下来反复学习,却被角落的Logo劝退。更头疼的是…...

对比自建代理,使用Taotoken聚合平台在稳定性与运维上的体验提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自建代理,使用Taotoken聚合平台在稳定性与运维上的体验提升 过去,一些开发团队为了便捷地使用特定的大…...

为什么91%的DeepSeek部署在第7轮后开始“失忆”?揭秘KV Cache碎片率超阈值的实时熔断策略
更多请点击: https://codechina.net 第一章:DeepSeek多轮对话优化 DeepSeek系列大模型在多轮对话场景中面临上下文衰减、指代歧义与意图漂移等典型挑战。为提升长程一致性与角色连贯性,需从提示工程、状态管理与响应重校准三个维度协同优化。…...

本地大语言模型推理新选择:为什么llama-cpp-python成为开发者首选?
本地大语言模型推理新选择:为什么llama-cpp-python成为开发者首选? 【免费下载链接】llama-cpp-python Python bindings for llama.cpp 项目地址: https://gitcode.com/gh_mirrors/ll/llama-cpp-python 在人工智能快速发展的今天,能够…...

Gofile极速下载器:Python多线程并发下载的完整实现指南
Gofile极速下载器:Python多线程并发下载的完整实现指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader Gofile作为流行的文件共享平台,其官方下载机…...