扩散模型实战(十):Stable Diffusion文本条件生成图像大模型
推荐阅读列表:
扩散模型实战(一):基本原理介绍
扩散模型实战(二):扩散模型的发展
扩散模型实战(三):扩散模型的应用
扩散模型实战(四):从零构建扩散模型
扩散模型实战(五):采样过程
扩散模型实战(六):Diffusers DDPM初探
扩散模型实战(七):Diffusers蝴蝶图像生成实战
扩散模型实战(八):微调扩散模型
扩散模型实战(九):使用CLIP模型引导和控制扩散模型
在AIGC时代,Stable Diffusion无疑是其中最亮的“仔”,它是一个强大的文本条件隐式扩散模型(text-conditioned latent diffusion model),可以根据文字描述(也称为Prompt)生成精美图片。
一、基本概念
1.1 隐式扩散
对于基于transformer的大模型来说,self-attention的计算复杂度与输入数据是平方关系的,比如一张128X128像素的图片在像素数量上是64X64像素图片的4倍,内存和计算量是16倍。这正是高分辨率图像生成任务存在的普遍现象。
为了解决这个问题,提出了隐式扩散(Latent Diffusion)方法,该方法认为图片通常包含大量冗余信息,首先使用大量图片数据训练一个Variational Auto-Encode(VAE)模型,编码器将图片映射到一个较小的隐式表示,解码器可以将较小的隐式表示映射到原始图片。Stable Diffusion中的VAE接受一张3通道图片作为输入,生成一个4通道的隐式特征,同时每一个空间维度都将减少为原来的八分之一。例如,一张512X512像素的图片可以被压缩到一个4X64X64的隐式表示。
通过在隐式表示(而不是完整图像)上进行扩散,可以使用更少的内存也可以减少UNet层数,从而加速图片生成,极大降低了训练和推理成本。
隐式扩散的结构,如下图所示:

1.2 以文本为生成条件
前面的章节展示了如何将额外信息输入给UNet,以实现对生成图像的控制,这种方法称为条件生成。以文本为条件进行控制图像的生成是在推理阶段,我们可以输入期望图像的文本描述(Prompt),并把纯噪声数据作为起点,然后模型对噪声数据进行“去噪”,从而生成能够匹配文本描述的图像。那么这个过程是如何实现的呢?
我们需要对文本进行编码表示,然后输入给UNet作为生成条件,文本嵌入表示如下图ENCODER_HIDDEN_STATES

Stable Diffusion使用CLIP对文本描述进行编码,首先对输入文本描述进行分词,然后输入给CLIP文本编码器,从而为每个token产生一个768维(Stable Diffusion 1.x版本)或者1024维(Stable Diffusion 2.x版本)向量,为了使输入格式一致,文本描述总是被补全或者截断为77个token。
那么,如何将这些条件信息输入给UNet进行预测呢?答案是使用交叉注意力(cross-attention)机制。UNet网络中的每个空间位置都可以与文本条件中的不同token建立注意力(在稍后的代码中可以看到具体的实现),如下图所示:

1.3 无分类器引导
第2节我们提到可以使用CLIP编码文本描述来控制图像的生成,但是实际使用中,每个生成的图像都是按照文本描述生成的吗?当然不一定,其实是大模型的幻觉问题,原因可能是训练数据中图像与文本描述相关性弱,模型可能学着不过度依赖文本描述,而是从大量图像中学习来生成图像,最终达不到我们的期望,那如何解决呢?
我们可以引入一个小技巧-无分类器引导(Classifier-Free Guidance,CFG)。在训练时,我们时不时把文本条件置空,强制模型去学习如何在无文字信息的情况下对图像“去噪”。在推理阶段,我们分别进行了两个预测:一个有文字条件,另一个则没有文字条件。这样我们就可以利用两者的差异来建立一个最终的预测了,并使最终结果在文本条件预测所指明的方向上依据一个缩放系数(引导尺度)更好的生成文本描述匹配的结果。从下图看到,更大的引导尺度能让生成的图像更接近文本描述。

1.4 其他类型的条件生成模型:Img2Img、Inpainting与Depth2Img模型
其实除了使用文本描述作为条件生成图像,还有其他不同类型的条件可以控制Stable Diffusion生成图像,比如图片到图片、图片的部分掩码(mask)到图片以及深度图到图片,这些模型分别使用图片本身、图片掩码和图片深度信息作为条件来生成最终的图片。
Img2Img是图片到图片的转换,包括多种类型,如风格转换(从照片风格转换为动漫风格)和图片超分辨率(给定一张低分辨率图片作为条件,让模型生成对应的高分辨率图片,类似Stable Diffusion Upscaler)。Inpainting又称图片修复,模型会根据掩码的区域信息和掩码之外的全局结构信息生成连贯的图片。Depth2Img采用图片的深度新作为条件,模型生成与深度图本身相似的具有全局结构的图片,如下图所示:

1.5 使用DreamBooth微调扩散模型
DreamBooth可以微调文本到图像的生成模型,最初是为Google的Imagen Model开发的,很快被应用到Stable Diffusion中。它可以根据用户提供的一个主题3~5张图片,就可以生成与该主题相关的图像,但它对于各种设置比较敏感。
二、环境准备
安装python库
pip install -Uq diffusers ftfy acceleratepip install -Uq git+https://github.com/huggingface/transformers
数据准备
import torchimport requestsfrom PIL import Imagefrom io import BytesIOfrom matplotlib import pyplot as plt# 这次要探索的管线比较多from diffusers import (StableDiffusionPipeline,StableDiffusionImg2ImgPipeline,StableDiffusionInpaintPipeline,StableDiffusionDepth2ImgPipeline)# 因为要用到的展示图片较多,所以我们写了一个旨在下载图片的函数def download_image(url):response = requests.get(url)return Image.open(BytesIO(response.content)).convert("RGB")# Inpainting需要用到的图片img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/ inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"init_image = download_image(img_url).resize((512, 512))mask_image = download_image(mask_url).resize((512, 512))device = ("mps"if torch.backends.mps.is_available()else "cuda"if torch.cuda.is_available()else "cpu")
三、使用文本描述控制生成图像
加载Stable Diffusion Pipeline,当然可以通过model_id切换Stable Diffusion版本
# 载入管线model_id = "stabilityai/stable-diffusion-2-1-base"pipe = StableDiffusionPipeline.from_pretrained(model_id).to(device)
如果GPU显存不足,可以尝试以下方法来减少GPU显存的使用
- 降低模型的精度为FP16
pipe = StableDiffusionPipeline.from_pretrained(model_id,revision="fp16",torch_dtype=torch.float16).to(device)
- 开启注意力切分功能,可以降低速度来减少GPU显存的使用
pipe.enable_attention_slicing()- 减小生成图像的尺寸
# 给生成器设置一个随机种子,这样可以保证结果的可复现性generator = torch.Generator(device=device).manual_seed(42)# 运行这个管线pipe_output = pipe(prompt="Palette knife painting of an autumn cityscape",# 提示文字:哪些要生成negative_prompt="Oversaturated, blurry, low quality",# 提示文字:哪些不要生成height=480, width=640, # 定义所生成图片的尺寸guidance_scale=8, # 提示文字的影响程度num_inference_steps=35, # 定义一次生成需要多少个推理步骤generator=generator # 设定随机种子的生成器)# 查看生成结果,如图6-7所示pipe_output.images[0]

主要参数介绍:
width和height:用于指定生成图片的尺寸,他们必须可以被8整除,否则VAE不能整除工作;
num_inference_steps:会影响生成图片的质量,采用默认50即可,用户也可以尝试不同的值来对比一下效果;
negative_prompt:用于强调不希望生成的内容,该参数一般在无分类器引导的情况下使用。列出一些不想要的特征,以帮助模型生成更好的结果;
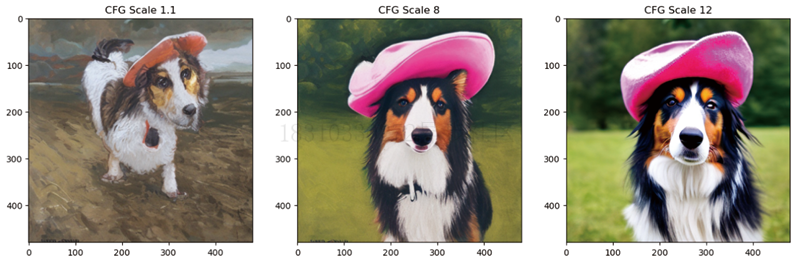
guidance_scale:决定了无分类器引导的影响强度。增大这个参数可以使生成的内容更接近给出的文本描述,但是参数值过大,则可能导致结果过于饱和,不美观,如下图所示:
cfg_scales = [1.1, 8, 12]prompt = "A collie with a pink hat"fig, axs = plt.subplots(1, len(cfg_scales), figsize=(16, 5))for i, ax in enumerate(axs):im = pipe(prompt, height=480, width=480,guidance_scale=cfg_scales[i], num_inference_steps=35,generator=torch.Generator(device=device).manual_seed(42)).images[0]ax.imshow(im); ax.set_title(f'CFG Scale {cfg_scales[i]}')
相关文章:
扩散模型实战(十):Stable Diffusion文本条件生成图像大模型
推荐阅读列表: 扩散模型实战(一):基本原理介绍 扩散模型实战(二):扩散模型的发展 扩散模型实战(三):扩散模型的应用 扩散模型实战(四ÿ…...

LaTex编写伪代码,并实现根据所在章编号(连字符),例如算法1-1
1 首先导入包: 按需要添加或者删除option,但是algochapter是必须的。 \usepackage[linesnumbered,ruled,algochapter]{algorithm2e}各个option的作用如下: 您好,这是Bing。我可以帮您解释algorithm2e包中这几个option的意思。&a…...

vue.js javascript js判断是值否为空
检查一个对象(Object)是否为空,即不包含任何元素。Javascript 中的对象就是一个字典,其中包含了一系列的键值对(Key Value Pair)。检查一个对象是否为空,等价于检查对象中有没有键值对。 1、如…...

网页开发如何实现简易页面跳动/跳转,html课堂练习/作业,页面ABC的相互跳转
先建一个文件夹,文件夹包含三个文件夹,三个文件夹分别包含各自的代码。(可以只建一个文件夹,文件夹包含各页面代码) 页面1的代码: <head> <meta http-equiv"Content-Type" content"text/html; charsetu…...

某大型房地产公司绩效面谈项目成功案例纪实
——开展有效的绩效面谈,促进和完善管理工作 【客户行业】房地产行业;国有企业 【问题类型】绩效面谈改进 【客户背景】 某大型房地产公司是某国企集团的省级分公司,集团公司现拥有北京、上海、广州、山东等8大区域公司,现有员…...
BGP联盟和团体属性实验
目录 一、实验拓扑 二、实验要求 三、实验步骤 1、IP地址配置 2、ospf配置 3、BGP建邻 4、宣告网段 5、配置团体属性 一、实验拓扑 二、实验要求 1、按照图示配 IP 地址,R2,R3,R4,R5分别配 Loopbacke 口地址作为OSPF的Ro…...
代码随想录-刷题第二天
977. 有序数组的平方 题目链接:977. 有序数组的平方 思路:双指针思想,数组是有序的且含有负数,其中元素的平方一定是两边最大。定义两个指针,从两端开始向中间靠近,每次比较两个指针的元素平方大小&#…...
DAY59 503.下一个更大元素II + 42. 接雨水
503.下一个更大元素II 题目要求: 给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数&am…...

【如何将任何直流电机变成伺服电机】
【如何将任何直流电机变成伺服电机】 1 前沿2 伺服电机工作原理3 如何制作定制伺服电机4 AS5600 编码器 – 磁性旋转位置传感器5 定制伺服电机电路图6 PCB设计7 自定义伺服3D模型8 定制伺服齿轮箱的 3D 打印零件9 对控制器进行编程9.1 引导加载程序刻录9.2 代码上传9.3 源代码9…...

单片机语音芯片在工业控制中的应用优势
单片机语音芯片,这一智能化的代表产品,不仅在家庭和消费电子领域发挥着重要的作用,更为工业控制领域注入了新的活力。将单片机语音芯片与语音交互技术相结合,为工业设备的控制和监测提供了前所未有的解决方案。 首先,…...

【开源】基于Vue.js的高校实验室管理系统的设计和实现
项目编号: S 015 ,文末获取源码。 \color{red}{项目编号:S015,文末获取源码。} 项目编号:S015,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、研究内容2.1 实验室类型模块2.2 实验室模块2.3 实…...

Xrdp+内网穿透实现远程访问Linux Kali桌面
XrdpCpolar实现远程访问Linux Kali桌面 文章目录 XrdpCpolar实现远程访问Linux Kali桌面前言1. Kali 安装Xrdp2. 本地远程Kali桌面3. Kali 安装Cpolar 内网穿透4. 配置公网远程地址5. 公网远程Kali桌面连接6. 固定连接公网地址7. 固定地址连接测试 前言 Kali远程桌面的好处在于…...

【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5713-洛谷团队系统【入门2分支结构】🌏题目描述🌏输入格…...
Eclipse切换中文环境
PACK包链接 地址,进入后可以看到不同版本的包。 要选择跟自己Eclipse版本一致的包,比如我的Eclipse启动界面如下,我就要找Helios的包( Juno、Indigo、Helios、Kepler这些具体怎么划分的我也不清楚)。 在线安装 打…...

栈和队列概念
栈stack 栈只能在一端插入/删除元素先入后出只能从栈顶插入,栈顶删除栈底不允许插入和删除push:进栈pop:出栈应用场景: 队列 Queue 队列的插入操作称为 “入队”(Enqueue),是在队尾进行的&am…...
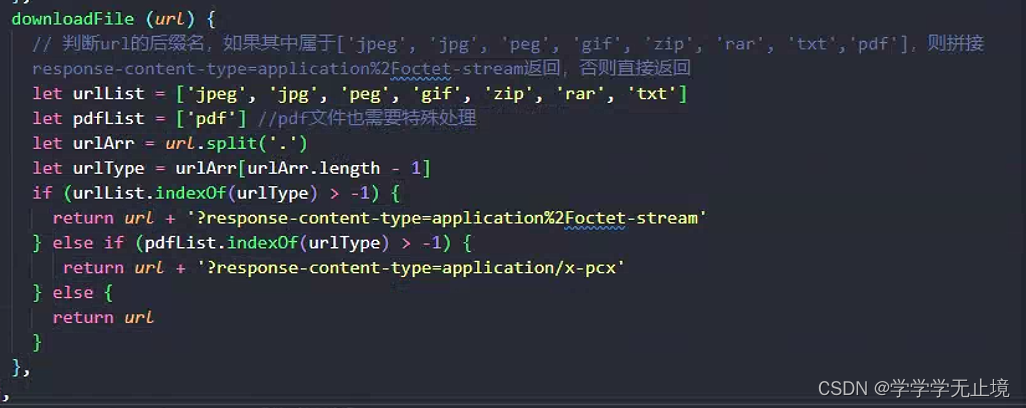
a标签下载文件与解决浏览器默认打开某些格式文件的问题
前言 在实际项目中,我们通常会遇到这么一个需求:后端给前端返回一个任意文件类型的完整的url路径,前端拿到这个路径直接通过浏览器下载文件到本地。我想大家应该都会首先想到使用HTML中的<a>标签,,因为<a>…...

EasyCVR视频监控+AI智能分析网关如何助力木材厂安全生产?
旭帆科技有很多工厂的视频监管方案,小编也经常分享出来供大家参考。近期,又有伙伴后台私信我们想要关于木材厂的方案。针对木材厂的生产过程与特性以及安全风险等,我们来分享一下相关的监管方案: 1)温湿度监测…...
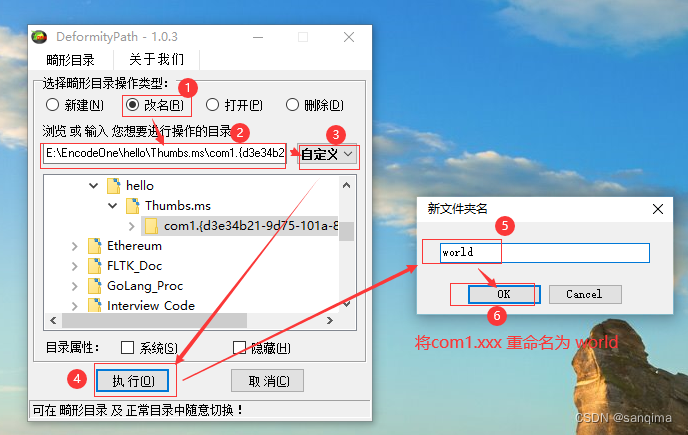
重命名com1.{d3e34b21-9d75-101a-8c3d-00aa001a1652}文件夹
今天在win10系统上,发现一个名称为: com1.{d3e34b21-9d75-101a-8c3d-00aa001a1652} 的文件夹,该文件夹很奇怪,既不能手动删除,也不能手动给文件夹重命名,如图(1)所示: E:\EncodeOne\hello\Thumbs.ms\com1.…...

springboot+activiti5.22.0集成Activiti在线流程设计器
SpringBoot集成Activiti5.22在线流程设计器 文章目录 SpringBoot集成Activiti5.22在线流程设计器📝1.增加配置pom依赖 增加数据库及redis配置文件📜 2.启动类ActivitiDesignApplication排除安全校验注解启动项目后将会自动在数据库中生成表 📘…...

pdf如何让多张图片在一页
pdf保存为一页六张图片的方法是: 1、打开pdf查看器,打开文档。 2、点击【打印】图标进入打印程序,选择打印范围。 3、在【打印处理】选项,选择【每张张上放置多页】。 4、自定义每页放置的图片张数为六张,并对打印排版预览设置。 5、设置打印…...

破解特征相关性难题:MVIM与CVIM如何提供更稳健的变量重要性评估
1. 项目概述:从“黑盒”到“可解释”的桥梁在数据科学和机器学习的日常工作中,我们常常面临一个核心矛盾:一方面,以XGBoost、深度神经网络为代表的复杂模型因其卓越的预测性能而备受青睐;另一方面,这些模型…...

机器学习增强无导数优化:Sobolev学习与代理模型实践
1. 项目概述与核心思路在工程优化、材料设计乃至金融建模中,我们常常会遇到一类“黑箱”问题:你有一个复杂的仿真程序或物理实验,输入一组参数,它能吐出一个结果(比如性能指标、成本或误差),但你…...

基于密度距离度量构建高质量科学仿真训练集:从原理到工程实践
1. 项目概述:从仿真数据到高质量训练集的桥梁在计算物理、流体力学或者天体物理模拟这类科学计算项目中,我们常常会生成海量的仿真数据。这些数据,比如一个随时间演化的等离子体密度场,其本身是复杂且高维的。直接把这些“原始矿石…...

安卓加固反调试核心机制:D-Bus监听与/proc/self/maps检测绕过实战
1. 这不是“绕过检测”,而是理解检测者如何思考你打开一个加固过的金融类App,Frida一挂上去,进程秒退;换上repack后的so,刚调用Java.perform就抛出SecurityException;甚至只是加载了frida-gadget.so&#x…...

8051开发中禁用自动代码分区的实践指南
1. 禁用自动代码分区的技术背景在8051架构的嵌入式开发中,代码分区(Bank Switching)是一种扩展程序存储器空间的常用技术。传统8051芯片的寻址空间有限,通过分区切换机制可以将代码分布到不同的物理存储区域。Keil C51开发工具链默…...

自制靶机--Believe
Believe设计思路 靶机名称: Believe 作者:Gropers 靶机ID:661 难度: baby 靶机下载地址: https://ova-believe.oss-cn-beijing.aliyuncs.com/Believe.ova 靶机收集地址: https://maze-sec.com 靶机IP: 192.168.1.150 攻击机IP: 192.168.1.195(Kali Linu…...

数据科学实践案例与项目管理
数据科学实践案例与项目管理 1. 技术分析 1.1 数据科学项目管理概述 数据科学项目管理是确保项目成功的关键: 项目生命周期问题定义: 明确目标数据收集: 获取数据数据处理: 清洗转换模型开发: 构建模型评估验证: 评估效果部署上线: 生产环境项目管理要素:目标设定进…...

【Appium 系列】第18节-重试与容错 — 移动端测试的稳定性保障
配套代码:utils/retry.py、tests/test_login_api.py说明:本节所有代码示例均来自一个真实的移动端自动化测试项目,已做模糊化处理。为什么需要重试移动端测试比 Web 测试更容易出现偶发性失败。以下几种情况在本地和 CI 上反复出现࿱…...

Anthropic Managed Agents:AI 运行时的事件日志革命
1. 这不是新赛道,是 runtime 层的“操作系统时刻”来了你有没有试过让一个 AI 代理连续工作四十分钟?不是闲聊,而是真正在查文档、调 API、写代码、改配置、再验证——一环扣一环地推进一个真实业务流程。我去年就带着团队跑过这样一个销售线…...

宏裕塑胶高性能RTP导电塑料,打造卓越导电材料新标杆
导读:在高端制造领域,导电塑料的性能直接决定产品的可靠性与竞争力。宏裕塑胶高性能RTP导电塑料,通过整合美国RTP公司尖端技术,正在重新定义行业标准,为电子、汽车、医疗等领域提供稳定高效的解决方案。宏裕塑胶高性能…...