人机交互——自然语言生成
自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。
1.简介
自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本,而基于统计的方法则通过大量的语料库和训练数据来学习生成文本的规律和模式。
- 在机器翻译领域,自然语言生成技术可以将一种语言的文本自动翻译成另一种语言的文本;
- 在智能客服领域,自然语言生成技术可以帮助企业自动回答用户的问题和解决用户的问题;
- 在自动摘要领域,自然语言生成技术可以将大量的文本自动摘要为一个简短的文本;
- 在对话系统领域,自然语言生成技术可以帮助人们自动地与机器人进行对话交流。
自然语言生成技术是人工智能领域的重要分支之一,它可以帮助计算机更好地理解和生成人类语言,从而为人们的生活和工作带来更多的便利和价值。
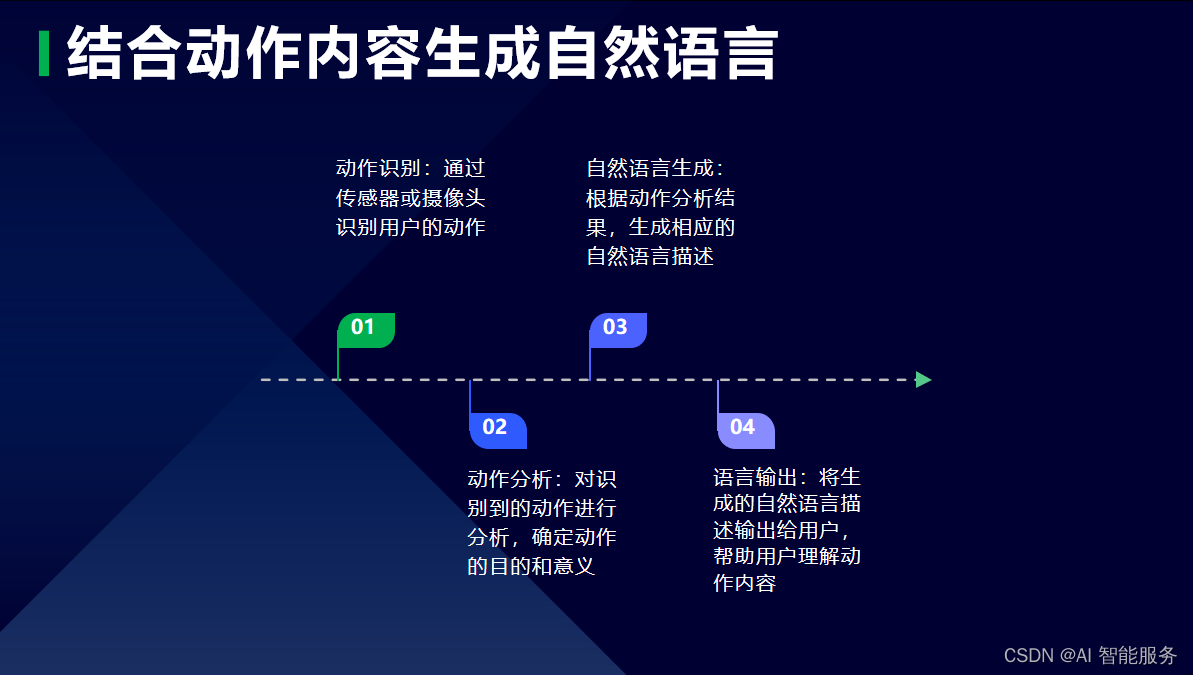
2.基于规则生成
2.1基于规则的自然语言生成特点
基于规则的自然语言生成方法是一种通过事先定义规则和模式来处理文本的方法。这种方法依赖于人工设计的规则,通过匹配和处理规则来实现对文本的分析和理解。
在基于规则的自然语言生成方法中,规则是由语言学家和专家根据语言学知识和领域知识设计的。这些规则通常包括语法规则、语义规则、词汇规则等,用于指导计算机如何生成符合语言规范的自然语言文本。
基于规则的自然语言生成方法通常分为两个阶段:分析阶段和生成阶段。在分析阶段,计算机将输入的文本进行分析和处理,以获得其语法和语义信息。在生成阶段,计算机使用规则和模式将分析阶段获得的语法和语义信息转换为自然语言文本。

基于规则的自然语言生成方法的优点是可以对文本进行精确的控制和处理,因为规则是由人工设计的,可以根据具体需求进行调整和修改。这种方法适用于处理特定领域的文本,例如法律、医学等专业领域的文本。然而,基于规则的自然语言生成方法也存在一些局限性。首先,设计和维护规则需要耗费大量的人力和时间,而且规则的覆盖范围有限,无法处理一些复杂的语言现象。其次,规则方法对于新的、未知的文本往往无法处理,因为缺乏对未知现象的规则定义。


为了克服基于规则的自然语言生成方法的局限性,一些研究人员提出了基于统计的自然语言生成方法。这种方法通过大量的语料库和训练数据来学习生成文本的规律和模式,可以自动生成符合语言规范的自然语言文本。相比之下,基于统计的自然语言生成方法具有更高的灵活性和可扩展性,可以适应各种类型的文本和领域。
2.2基于规则生成的代码示例
基于规则的自然语言生成方法通常需要大量的手动干预和定制,因此很难用简单的代码来展示。但是,我们可以尝试用一些伪代码来描述基于规则的自然语言生成方法的基本原理。
假设我们有一个简单的规则,用于将英文句子中的代词(例如it、them等)替换为相应的名词。我们可以定义一个规则如下:
rule: replace_pronoun(sentence, pronoun, noun) 1. find the position of pronoun in sentence 2. replace pronoun with noun in sentence at the found position 3. return the modified sentence这个规则可以通过一些参数来调用,例如:
sentence = "I saw them playing football"
pronoun = "them"
noun = "boys"
new_sentence = replace_pronoun(sentence, pronoun, noun)
print(new_sentence) # "I saw boys playing football"自然语言生成系统中,可能需要考虑更多的规则和模式,例如句子的结构、词序、语气、时态等等。因此,基于规则的自然语言生成方法需要更多的手动干预和定制,通常需要专业的语言学家和领域专家参与开发。
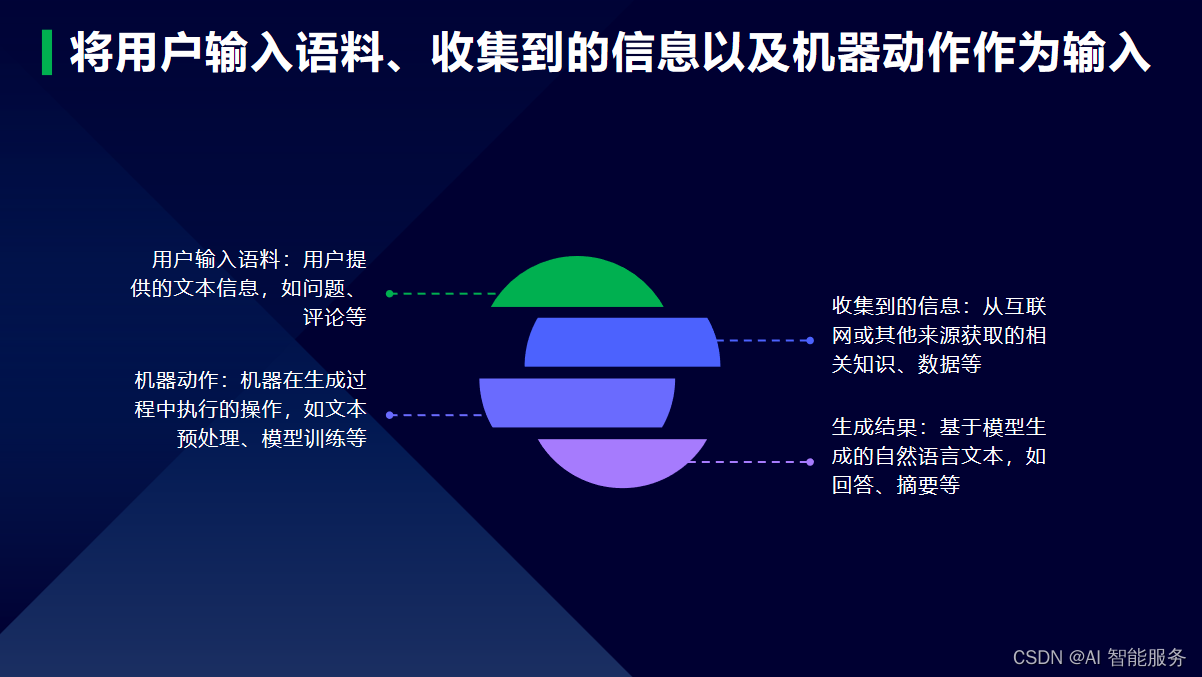
3.基于统计生成
基于统计生成(Statistical Generation)是一种自然语言处理方法,它基于大量的训练数据,学习语言规律,然后根据学习结果生成自然语言。该方法主要包括以下几个步骤:
- 收集语料库:收集一定量的语言数据,可以是书籍、报纸、网站、对话等,数据的规模和质量直接影响到生成结果的好坏。
- 数据预处理:对收集到的数据进行处理,如去除标点符号、停用词等。
- 模型训练:使用统计模型对处理后的数据进行训练,学习语言规律。
- 生成文本:根据模型的学习结果生成自然语言文本。
基于统计生成的方法通常使用机器学习算法,如朴素贝叶斯、决策树、神经网络等,来学习和生成文本。相比基于规则的方法,基于统计生成的方法具有更高的灵活性和可扩展性,可以适应各种类型的文本和领域。但是,它也需要大量的训练数据和计算资源。
3.1基于统计生成的步骤




3.2基于统计生成的代码示例
下面是一个基于Python的简单示例,展示如何使用基于统计的方法生成文本。这个例子使用了朴素贝叶斯分类器来生成文本。
import nltk
from nltk.corpus import reuters # 加载路透社语料库
reuters_corpus = reuters.sents() # 训练朴素贝叶斯分类器
classifier = nltk.NaiveBayesClassifier.train(reuters_corpus) # 生成文本
def generate_text(n): for _ in range(n): # 使用分类器生成文本 label = classifier.classify(nltk.NaiveBayesClassifier.prob_classify(classifier).sample()) print(f"{label}: {nltk.translate.ibm1.ibm1(classifier, reuters_corpus, label)}") # 生成10个文本
generate_text(10)这个例子使用了NLTK库来加载路透社语料库,并使用朴素贝叶斯分类器来学习和生成文本。在生成文本时,我们首先使用分类器来预测文本的类别,然后根据类别和已有的文本生成新的文本。在这个例子中,我们只生成了10个文本,但是你可以通过增加generate_text函数的参数来生成更多的文本。请注意,这个例子是一个简单的演示,实际上基于统计的自然语言生成方法需要更复杂的模型和大量的训练数据。
相关文章:
人机交互——自然语言生成
自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。 1.简介 自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本࿰…...
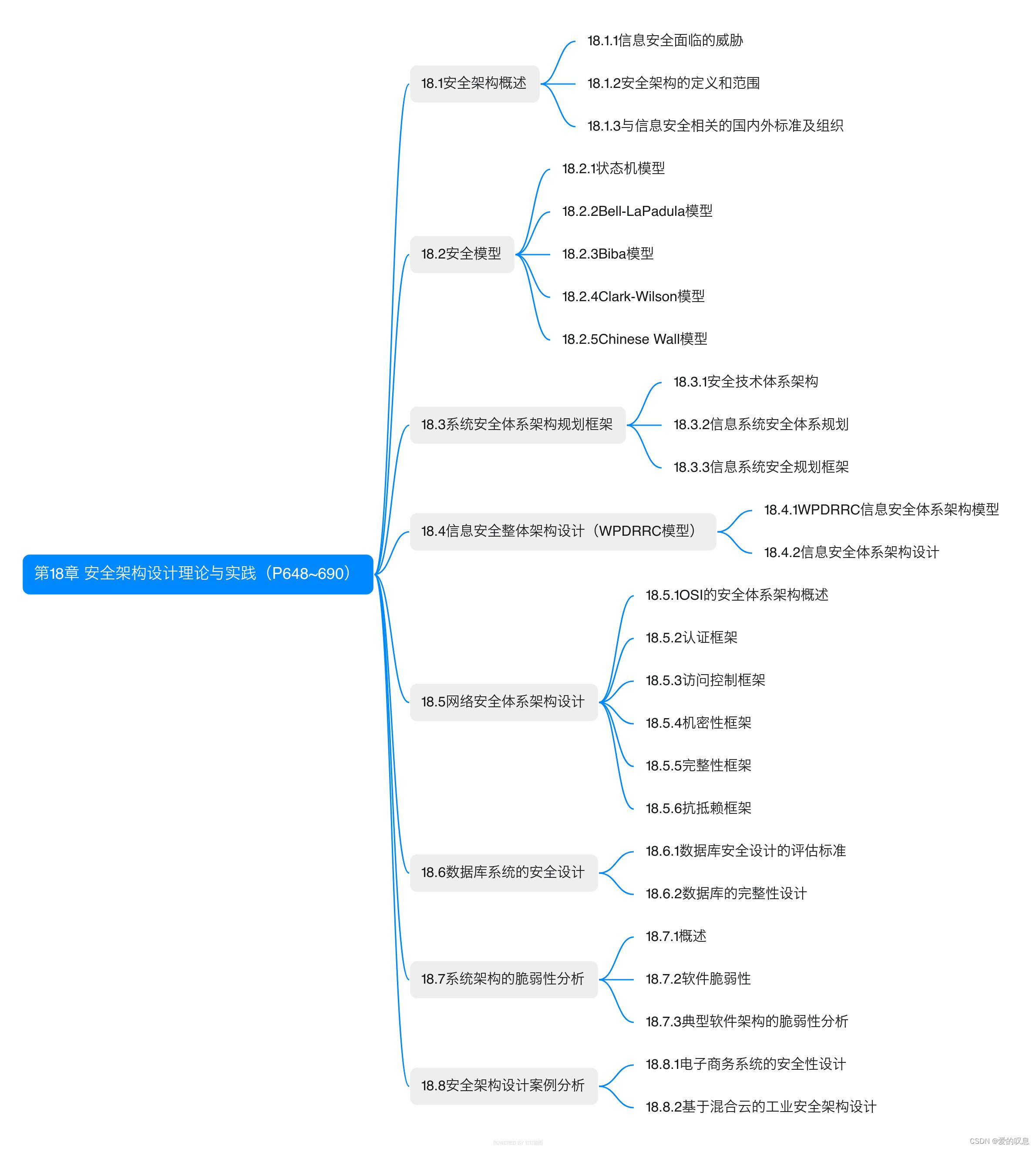
软考-高级-系统架构设计师教程(清华第2版)【第18章 安全架构设计理论与实践(P648~690)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第18章 安全架构设计理论与实践(P648~690)-思维导图】 课本里章节里所有蓝色字体的思维导图...

Hive调优
1.参数配置优化 设定Hive参数有三种方式: (1)配置Hive文件 当修改配置Hive文件的设定后,对本机启动的所有Hive进程都有效,因此配置是全局性的。 一般地,Hive的配置文件包括两部分: aÿ…...

基于R语言平台Biomod2模型的物种分布建模与可视化分析
!](https://img-blog.csdnimg.cn/84e1cc8c7f9b4b6ab60903ffa17d82f0.jpeg#pic_center)...

Docker 安装一个本地的画图软件 —— 筑梦之路
画图是必不可少的,比如流程图、架构图等等,网上有很多画图软件是要收费的,使用起来很不方便,因此在内网部署一个免费开源的画图软件是有必要的。 如何部署 docker run -it --rm --name"drawio" -p 8080:8080 -p 8443:…...

【python】Conda强大的包/环境管理工具
Conda强大的包/环境管理工具 1. 简介2. 安装3. 指令 1. 简介 Conda是Anaconda中一个强大的包和环境管理工具,可以在Windows的Anaconda Prompt命令行使用,也可以在macOS或者Linux系统的终端窗口(terminal window)的命令行使用。2. 安装 [Linux平台安装教…...

常见面试题-Netty线程模型以及TCP粘包拆包
介绍一下 Netty 使用的线程模型? 答: Netty 主要基于主从 Reactor 多线程模型,其中主从 Reactor 多线程模型将 Reactor 分为两部分: mainReactor:监听 Server Socket,用来处理网络 IO 连接建立操作&…...
03.webpack中hash,chunkhash和contenthash 的区别
hash、contenthash 和 chunkhash 是通过散列函数处理之后,生成的一串字符,可用于区分文件。 作用:善用文件的哈希值,解决浏览器缓存导致的资源未及时更新的问题 1.文件名不带哈希值 const path require(path) const HtmlWebpac…...
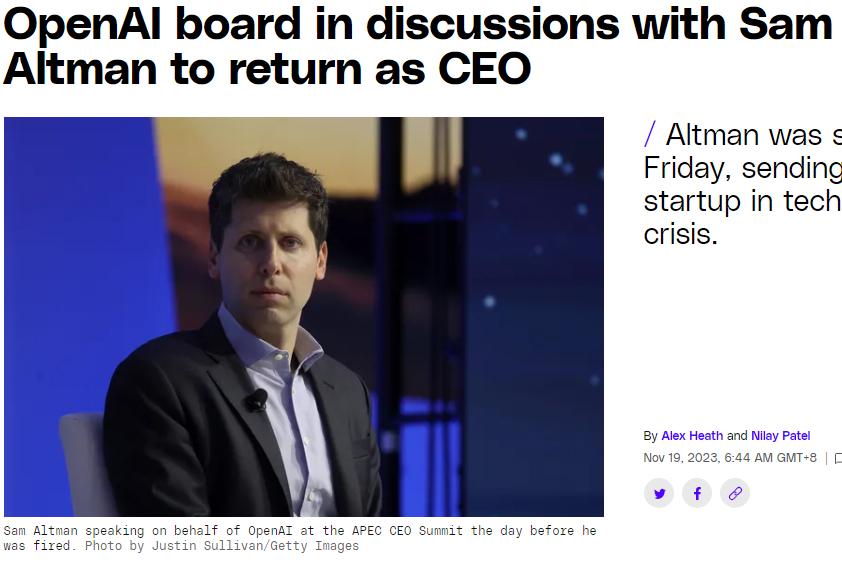
OpenAI前CEO萨姆·阿尔特曼可能重返CEO职位;用LoRA微调LLM的实用技巧
🦉 AI新闻 🚀 OpenAI前CEO萨姆阿尔特曼可能重返CEO职位 摘要:据报道,OpenAI前CEO萨姆阿尔特曼有望重新担任CEO职位,并对公司董事会进行重大改变。微软等投资人正努力恢复阿尔特曼的职位,尽管董事会仍然是…...

修改docker默认数据目录
前言: docker默认数据目录是/var/lib/docker,根目录的存储空间有限,我们往往不能使用默认配置,需要创建空间相对较大的数据data目录 停止docker服务 systemctl stop docker 编辑配置文件 vi /etc/docker/daemon.json 增加选项 “graph”…...
wpf devexpress post 更改数据库
这个教程示范如何使用GridControl编辑数据,和保存更改到数据库。这个教程基于前一个篇。 Items Source Wizard 当 CRUD (Create, Read, Update, Delete) 启动选项时添加Post data功能 Items Source Wizard 生成如下代码: 1、设置 TableView.ShowUpdat…...

Ubuntu 18.04/20.04 LTS 操作系统设置静态DNS
1、nano /etc/systemd/resolved.conf 2、修改配置 使用DNS服务器:223.5.5.5 223.6.6.6 [Resolve] DNS223.5.5.5 223.6.6.6 3、重启服务 systemctl restart systemd-resolved.service 4、查看解析文件 cat /run/systemd/resolve/resolv.conf # This file is man…...

VSCode使用MinGW中的go并支持CGO
在Windows中,如果想使用Linux下的一些命令或者开发工具,可以安装Cygwin或者MinGW,MinGW相比Cygwin要轻量得多,笔者就安装的MinGW,但是安装MinGW后,如果把它加到Windows系统的PATH环境变量中,则可…...

tensor张量 ------ python特殊的数据结构
点赞收藏关注! 如需转载请注明出处! 张量与数组和矩阵非常相似。 在PyTorch中,使用张量来编码模型的输入和输出,以及模型的参数。 张量可以在GPU或其他硬件加速器上运行。 张量和NumPy数组通常可以共享相同的底层内存,…...

openai/chatgpt的api接口,各个模型的最大输入token一览表
chatgpt的各个3.5api模型接口的最大输入量一览表: MODELDESCRIPTIONCONTEXT WINDOWTRAINING DATAgpt-3.5-turbo-1106Updated GPT 3.5 Turbo New The latest GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel…...

Spark作业串行与并行提交job
在Scala中,您可以以串行和并行的方式提交Spark作业。看看如何使用for和par.foreach构造对应的例子。 串行Spark作业(使用for) // 串行Spark作业设置 for (tag <- tags) {spark.sparkContext.setJobGroup(tag.toString, s"Tag: $tag…...
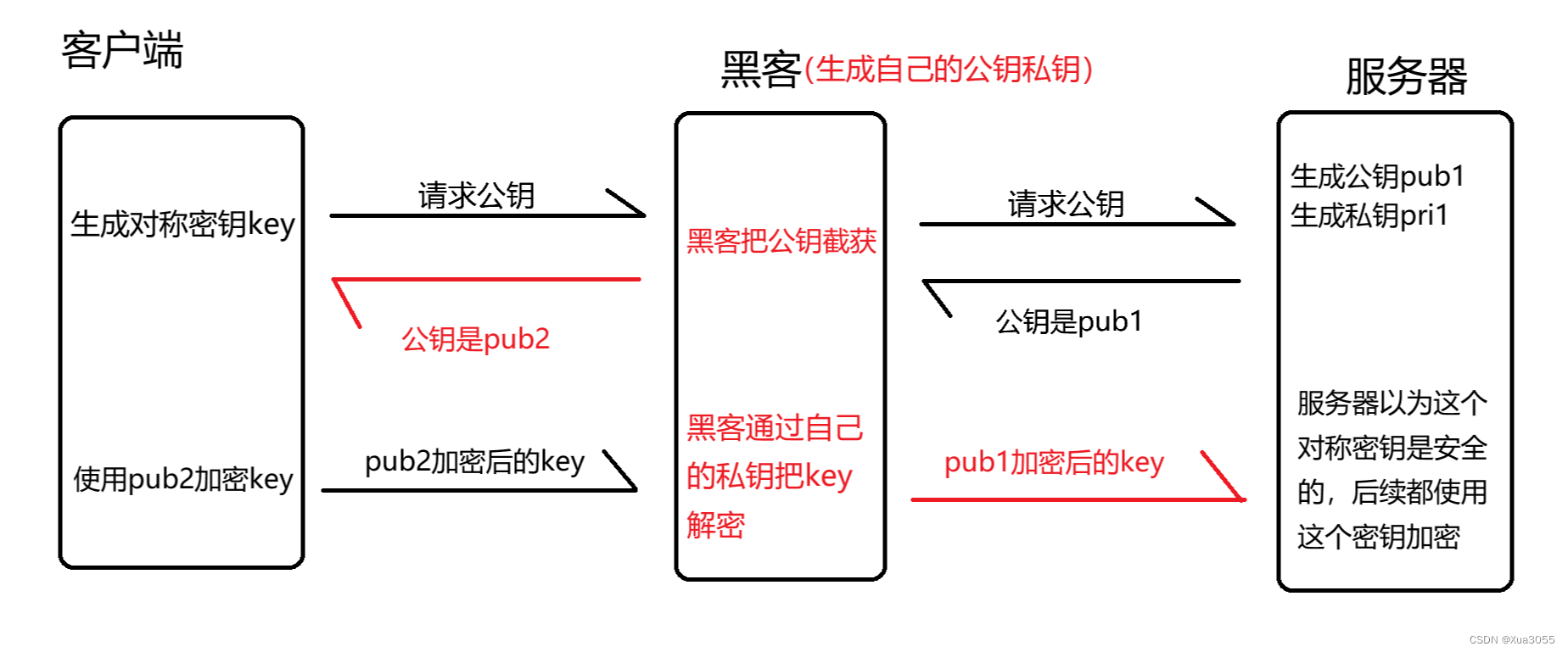
HTTP HTTPS 独特的魅力
目录 HTTP协议 HTTP协议的工作过程 首行 请求头(header) HOST Content-Length编辑 User-Agent(简称UA) Referer Cookie 空行 正文(body) HTTP响应详解 状态码 报文格式 HTTP响应格式 如何…...
人名分类器实战项目(对比RNN、LSTM、GRU模型)工程管理方式)
【nlp】2.5(gpu version)人名分类器实战项目(对比RNN、LSTM、GRU模型)工程管理方式
人名分类器实战项目 0 说明1 工程项目设计2 数据预处理data_processing3 创建模型model4 模型测试test5 训练配置config6 模型训练train7 模型对比绘图plotfigure8 模型预测predict9 代码测试demo0 说明 本项目对前一个博客内容2.5(cpu version) 人名分类器实战项目(对比RNN、…...
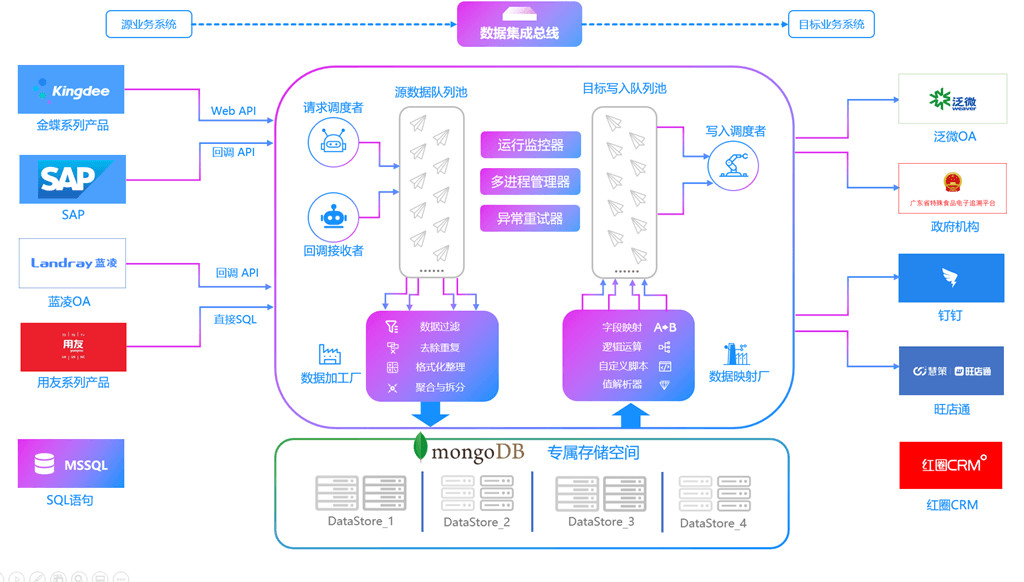
金蝶云星空对接打通旺店通·旗舰奇门采购退料单查询接口与创建货品档案接口
金蝶云星空对接打通旺店通旗舰奇门采购退料单查询接口与创建货品档案接口 来源系统:金蝶云星空 金蝶K/3Cloud在总结百万家客户管理最佳实践的基础上,提供了标准的管理模式;通过标准的业务架构:多会计准则、多币别、多地点、多组织、多税制应用…...
在线识别二维码工具
具体请前往:在线二维码识别解码工具--在线识别并解码二维码网址等内容...

昇腾CANN opbase 算子注册与分发调度:从 API 到 AI Core 的路径追踪
所有 CANN 算子都依赖 opbase——它不是写具体算子的地方,而是算子的"注册中心 调度器"。用户调用 torch.nn.functional.softmax(x) → PyTorch 转发到 CANN → CANN 查 opbase 的算子注册表 → 找到对应的 Ascend C kernel → 加载到 AI Core → 执行。…...

小电视空降助手:终极B站广告跳过插件完整指南
小电视空降助手:终极B站广告跳过插件完整指南 【免费下载链接】BilibiliSponsorBlock 一款跳过小电视视频中恰饭片段的浏览器插件,移植自 SponsorBlock。A browser extension to skip sponsored segments in videos, ported from the SponsorBlock 项目…...

RTX51实时系统任务抢占与邮箱机制深度解析
1. RTX51实时系统中的任务抢占与邮箱机制解析在嵌入式实时操作系统领域,任务间通信与优先级调度是核心机制。RTX51作为Keil C51开发环境中的经典实时内核,其抢占行为与邮箱通信的交互方式直接影响系统实时性表现。本文将深入剖析当低优先级任务向高优先级…...
)
【2024播客降本增效终极方案】:单人团队如何用开源TTS实现月产60期高保真节目(附实测MOS分对比表)
更多请点击: https://codechina.net 第一章:AI语音合成在播客制作中的应用 AI语音合成技术正深刻重塑播客内容的生产流程,从脚本转语音、多角色配音到个性化音色定制,已实现端到端自动化与高质量听感的统一。相比传统录音方式&am…...

开源AI编辑器的未来发展趋势
基于当前发展状况来分析,开源AI编辑器的未来发展趋势主要体现在以下几个核心方向:一、技术能力:从“辅助补全”迈向“智能体化”全流程自主化:AI编辑器正从基础的代码补全、语法检查,向具备自主决策能力的智能体&#…...

Python数据库设计模式:从ORM到数据层架构
Python数据库设计模式:从ORM到数据层架构 引言 数据库设计是后端开发的核心环节。作为从Python转向Rust的后端开发者,我发现Python的数据库生态非常成熟,尤其是SQLAlchemy提供了强大的ORM能力。本文将深入探讨Python数据库设计模式࿰…...

SpringBoot+Vue旅游管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任
企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任 引言 各位正在关注 AI Agent 落地企业生产环境的技术负责人、CTO、架构师、开发者们: 去年我在国内某头部 SaaS 公司做内部 Hackathon 的评委时,看到了一支由 3 个应届毕业的计算机科学博士和 2 个资深后…...

进程与线程:并发编程基础
摘要:进程与线程是操作系统面试的必考点,也是理解 AI 分布式训练和多线程数据加载的基础。本文从进程内存模型出发,系统讲解线程同步机制(锁、信号量、条件变量),并通过 Python 代码展示多线程爬虫和生产者…...

Python自动化登录:破解验证码与Cookie会话维持实战
1. 这不是“绕过验证”,而是理解会话机制的起点很多人看到“跳过验证码登陆”第一反应是:这合规吗?会不会被封?其实这个问题本身就暴露了一个关键误区——我们不是在“绕过”什么,而是在还原真实用户登录时浏览器自动完…...