GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
GPT实战系列-如何使用P-Tuning本地化训练ChatGLM2等LLM模型?(二)
文章目录
- GPT实战系列-
- 1.训练参数配置传递
- 2.训练前准备
- 3.训练参数配置
- 4.训练对象,seq2seq训练
- 5.执行训练
- 6.训练模型评估
- 依赖
- 数据集的预处理
P-Tuning v2 将 ChatGLM2-6B 模型需要微调的参数量,减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
本文试图分析程序结构和代码,解释序列转换生成模型的微调训练。为了篇幅不要过长,分两篇文章解读,本文解读训练代码。框架概述请看前篇文章:GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
对相关的内容感兴趣,也可以到GPT专栏里的文章看看。如果没有你感兴趣的,请留言,后续一起讨论。
GPT专栏:https://blog.csdn.net/alex_starsky/category_12467518.html
下面解读ptuning目录下的main.py代码。
1.训练参数配置传递
训练环节中,通过命令行配置参数(sh脚本),然后通过HfArgumentParser方法,把配置参数指定到模型,数据和训练的参数类中。通过参数解析器parser,进一步分类为模型参数,数据参数和训练超参数。
# 新版本的transformers中的ner没有采用传统的parser模块,利用HfArgumentParser方法,将参数类转化为argparse参数,以便于在命令行中指定他们。
# ModelArguments类为model/config/tokenizer涉及的参数。ModelArguments类 中包含的是关于模型的属性,如model_name,config_name,tokenizer_name等,类在run.py文件中定义;
# DataTrainingArguments类 为训练、测试数据集操作涉及到的参数。DataTrainingArguments类 中包含的是关于微调数据的属性,如task_name,data_dir等,类在transformers/data/datasets/glue.py文件中定义;
# TrainingArguments中包含的是关于微调过程的参数,如batch_size,learning_rate等参数,类在transformers/training_args.py中定义。parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
# 通过参数解析器parser,进一步分类为模型参数,数据参数和训练超参数。
# 训练时输入python run_ner.py *******.json,即从.json中读取参数。
# 当sys.argv参数为2时,此时sys.argv[0]为自己本身,即"run_ner.py",sys.argv[1]为json文件
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:model_args, data_args, training_args = parser.parse_args_into_dataclasses()如果参数过多,或者需要保存参数,采用json文件格式,比如:
{"do_train": true,"train_file": "dataset/AdvertiseGen/train.json","validation_file": "dataset/AdvertiseGen/dev.json","preprocessing_num_workers": 10,"prompt_column": "content","response_column": "summary","overwrite_cache": true,"model_name_or_path": "/Users/andy/Desktop/LLM/model/chatglm2-6b","output_dir": "output/adgen-chatglm2-6b-lora_version","overwrite_output_dir": true,"max_source_length": 64,"max_target_length": 128,"per_device_train_batch_size": 1,"per_device_eval_batch_size": 1,"gradient_accumulation_steps": 16,"predict_with_generate": true,"max_steps": 3000,"logging_steps": 10,"save_steps": 100,"learning_rate": 2e-5,"lora_r": 32,"model_parallel_mode": true,"output_dir": "output"
}
训练过程的日志排版,打印信息等相关设置
#设置日志相关,排版格式,日期格式
# Setup logging
logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",handlers=[logging.StreamHandler(sys.stdout)],
)
#设置打印信息
if training_args.should_log:# The default of training_args.log_level is passive, so we set log level at info here to have that default.transformers.utils.logging.set_verbosity_info()#设置日志信息等级,transformer日志配置
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
# datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
2.训练前准备
训练前的准备工作,包括预处理,训练数据集、验证数据集、测试数据集等参数配置
训练数据准备
# 加载数据集,训练文件,验证文件,测试文件,文件名,文件类型(扩展名)# Load datasetdata_files = {}if data_args.train_file is not None:data_files["train"] = data_args.train_fileextension = data_args.train_file.split(".")[-1]if data_args.validation_file is not None:data_files["validation"] = data_args.validation_fileextension = data_args.validation_file.split(".")[-1]if data_args.test_file is not None:data_files["test"] = data_args.test_fileextension = data_args.test_file.split(".")[-1]# 加载训练、验证、测试数据文件,cache目录raw_datasets = load_dataset(extension,data_files=data_files,cache_dir=model_args.cache_dir,use_auth_token=True if model_args.use_auth_token else None,)
训练模型的配置
预训练模型加载,序列长度,序列前缀处理
# 加载模型配置(模型架构),预训练模型
# Load pretrained model and tokenizer
config = AutoConfig.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
config.pre_seq_len = model_args.pre_seq_len
config.prefix_projection = model_args.prefix_projection
加载分词器,对自然语言序列进行分解,分词处理
# 分词器
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)预训练模型的加载,有两种方式,一种是把过程加载方式,checkpoint,另一种是整合为一个模型bin格式,然后直接加载。
# 含有训练过程信息的checkpoint模型的加载模式,如ptuning训练中间结果,需要从pytorch_model.bin加载字典,
# 或者直接加载模型
if model_args.ptuning_checkpoint is not None:# Evaluation# Loading extra state dict of prefix encodermodel = AutoModel.from_pretrained(model_args.model_name_or_path, config=config, trust_remote_code=True)prefix_state_dict = torch.load(os.path.join(model_args.ptuning_checkpoint, "pytorch_model.bin"))new_prefix_state_dict = {}for k, v in prefix_state_dict.items():if k.startswith("transformer.prefix_encoder."):new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = vmodel.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
else:model = AutoModel.from_pretrained(model_args.model_name_or_path, config=config, trust_remote_code=True)
训练量化精度配置
加载模型后,考虑到模型大小,占用显存大小,以及训练速度,需要配置模型数据精度,一般分为float32为浮点,f16半浮点精度,bf16半浮点精度,及int8,int4等整型8,4位精度。
# 量化处理,f16半浮点精度,即将pytorch默认的32位浮点型都改成16位浮点型。
if model_args.quantization_bit is not None:print(f"Quantized to {model_args.quantization_bit} bit")model = model.quantize(model_args.quantization_bit)
if model_args.pre_seq_len is not None:# P-tuning v2model = model.half()model.transformer.prefix_encoder.float() #前缀编码器
else:# Finetunemodel = model.float()
数据预处理
数据集预处理,包括训练数据集,验证数据集,测试数据集。
prefix = data_args.source_prefix if data_args.source_prefix is not None else ""# 数据集预处理,分词处理# Preprocessing the datasets.# We need to tokenize inputs and targets.if training_args.do_train:column_names = raw_datasets["train"].column_nameselif training_args.do_eval:column_names = raw_datasets["validation"].column_nameselif training_args.do_predict:column_names = raw_datasets["test"].column_nameselse:logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")return# 输入数据(prompt),标注目标数据(response),上下文历史会话(history)# Get the column names for input/target.prompt_column = data_args.prompt_columnresponse_column = data_args.response_columnhistory_column = data_args.history_column# 最大模板长度# Temporarily set max_target_length for training.max_target_length = data_args.max_target_length
3.训练参数配置
训练数据集参数配置,最大训练样本数,数据预处理函数,GPU显卡数,批处理,cache处理等配置
# 训练前配置和数据集处理,训练,训练数据,最大训练样本数,if training_args.do_train:if "train" not in raw_datasets:raise ValueError("--do_train requires a train dataset")train_dataset = raw_datasets["train"]if data_args.max_train_samples is not None:max_train_samples = min(len(train_dataset), data_args.max_train_samples)train_dataset = train_dataset.select(range(max_train_samples))with training_args.main_process_first(desc="train dataset map pre-processing"):train_dataset = train_dataset.map(preprocess_function_train,batched=True,num_proc=data_args.preprocessing_num_workers,remove_columns=column_names,load_from_cache_file=not data_args.overwrite_cache,desc="Running tokenizer on train dataset",)print_dataset_example(train_dataset[0])
同样方式,配置验证数据集,测试数据集参数。
# 训练前验证评价的配置和数据集处理,验证评价if training_args.do_eval:max_target_length = data_args.val_max_target_lengthif "validation" not in raw_datasets:raise ValueError("--do_eval requires a validation dataset")eval_dataset = raw_datasets["validation"]#最大验证样本数if data_args.max_eval_samples is not None:max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)eval_dataset = eval_dataset.select(range(max_eval_samples))#with training_args.main_process_first(desc="validation dataset map pre-processing"):eval_dataset = eval_dataset.map(preprocess_function_eval,batched=True,num_proc=data_args.preprocessing_num_workers,remove_columns=column_names,load_from_cache_file=not data_args.overwrite_cache,desc="Running tokenizer on validation dataset",)print_dataset_example(eval_dataset[0])# 训练前预测的配置和数据集处理,预测if training_args.do_predict:max_target_length = data_args.val_max_target_lengthif "test" not in raw_datasets:raise ValueError("--do_predict requires a test dataset")predict_dataset = raw_datasets["test"]#最大预测样本if data_args.max_predict_samples is not None:max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)predict_dataset = predict_dataset.select(range(max_predict_samples))#数据集重映射with training_args.main_process_first(desc="prediction dataset map pre-processing"):predict_dataset = predict_dataset.map(preprocess_function_eval,batched=True,num_proc=data_args.preprocessing_num_workers,remove_columns=column_names,load_from_cache_file=not data_args.overwrite_cache,desc="Running tokenizer on prediction dataset",)print_dataset_example(predict_dataset[0])
数据分词,类型转换,pad等数据预处理操作
#训练准备,模型,数据加载# Data collatorlabel_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_iddata_collator = DataCollatorForSeq2Seq(tokenizer,model=model,label_pad_token_id=label_pad_token_id,pad_to_multiple_of=None,padding=False)
4.训练对象,seq2seq训练
序列训练参数配置,生成的length,beams配置,
# 序列训练参数配置,如有配置则重置解码参数# Override the decoding parameters of Seq2SeqTrainertraining_args.generation_max_length = (training_args.generation_max_lengthif training_args.generation_max_length is not Noneelse data_args.val_max_target_length)training_args.generation_num_beams = (data_args.num_beams if data_args.num_beams is not None else training_args.generation_num_beams)训练器参数配置,预训练模型,训练超参数,相关数据集。分词器,训练度量器等过程参数配置。
#初始化训练参数,配置模型,训练参数,训练数据,分词器,数据加载工具,过程度量# Initialize our Trainertrainer = Seq2SeqTrainer(model=model,args=training_args,train_dataset=train_dataset if training_args.do_train else None,eval_dataset=eval_dataset if training_args.do_eval else None,tokenizer=tokenizer,data_collator=data_collator,compute_metrics=compute_metrics if training_args.predict_with_generate else None,save_changed=model_args.pre_seq_len is not None)
5.执行训练
执行训练过程,模型保存方式,过程度量及状态保存。
# 训练执行过程# Trainingif training_args.do_train:checkpoint = Noneif training_args.resume_from_checkpoint is not None:checkpoint = training_args.resume_from_checkpoint# elif last_checkpoint is not None:# checkpoint = last_checkpointmodel.gradient_checkpointing_enable()model.enable_input_require_grads()train_result = trainer.train(resume_from_checkpoint=checkpoint)# trainer.save_model() # Saves the tokenizer too for easy uploadmetrics = train_result.metricsmax_train_samples = (data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset))metrics["train_samples"] = min(max_train_samples, len(train_dataset))trainer.log_metrics("train", metrics)trainer.save_metrics("train", metrics)trainer.save_state()
6.训练模型评估
训练后,数据集评估模型效果,预测处理。
#训练结束后评估# Evaluationresults = {}max_seq_length = data_args.max_source_length + data_args.max_target_length + 1# 训练评估if training_args.do_eval:logger.info("*** Evaluate ***")metrics = trainer.evaluate(metric_key_prefix="eval", do_sample=True, top_p=0.7, max_length=max_seq_length, temperature=0.95)max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))trainer.log_metrics("eval", metrics)trainer.save_metrics("eval", metrics)# 训练预测if training_args.do_predict:logger.info("*** Predict ***")predict_results = trainer.predict(predict_dataset, metric_key_prefix="predict", max_length=max_seq_length, do_sample=True, top_p=0.7, temperature=0.95)metrics = predict_results.metricsmax_predict_samples = (data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset))metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))trainer.log_metrics("predict", metrics)trainer.save_metrics("predict", metrics)if trainer.is_world_process_zero():if training_args.predict_with_generate:predictions = tokenizer.batch_decode(predict_results.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True)predictions = [pred.strip() for pred in predictions]labels = tokenizer.batch_decode(predict_results.label_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)labels = [label.strip() for label in labels]output_prediction_file = os.path.join(training_args.output_dir, "generated_predictions.txt")with open(output_prediction_file, "w", encoding="utf-8") as writer:for p, l in zip(predictions, labels):res = json.dumps({"labels": l, "predict": p}, ensure_ascii=False)writer.write(f"{res}\n")
依赖
中文分词器,中文评价指标,数据集管理
pip install rouge_chinese nltk jieba datasets
依赖模块解读
transformers提供数千个预先训练好的模型来执行不同模式的任务,如文本、视觉和音频。
transformer提供api,可以快速下载,并在给定文本上使用这些预训练的模型,在您自己的数据集上对它们进行微调,然后在Huggingface的模型中心上与社区共享。同时,每个定义架构的python模块都是完全独立的,可以进行修改以进行快速研究实验。
- AutoConfig模块,模型的配置类是指定模型的构建方式。配置指定模型的属性,如隐藏层或注意力头的数量。当从自定义配置类初始化模型时,将从头开始。模型属性是随机初始化的,在使用模型得到有意义的结果之前,需要对模型进行训练。导入AutoConfig,然后加载要修改的预训练模型。在AutoConfig.from_pretrained()中,可以指定要更改的属性,例如注意力头的数量。
- AutoModel加载一个预训练模型,Transformers提供简单统一的方法来加载。
- AutoTokenizer加载的一个自动分词器。
- DataCollatorForSeq2Seq 是在进行序列生成任务时(QA、文本概括等)使用的数据收集器,需要模型的输出是一个序列。该数据收集器不仅会动态的填充数据的数据,而且也会填充数据对应的标签。
- HfArgumentParser可以将类对象中的实例属性转换成转换为解析参数。必须注意的是,这里的类对象必须是通过@dataclass()创建的类对象。并且通过HfArgumentParser创建的解析参数,都是可选参数。
# Transformers 工具已经帮我们封装了用于训练文本生成模型的 Seq2SeqTrainer 类,无需我们自己再去定义损失函数与优化方法了。
import transformers
from transformers import (AutoConfig,AutoModel,AutoTokenizer,DataCollatorForSeq2Seq,HfArgumentParser,Seq2SeqTrainingArguments,set_seed,
)Trainer 所有模型都是标准的torch.nn.Module,因此可以在任何典型的训练循环中使用它们。虽然您可以编写自己的训练迭代器,但Transformers为PyTorch提供了Trainer类,其中包含基本的训练循环,并添加了额外的功能,如分布式训练、混合精度等。
- Seq2SeqTrainingArguments 设置训练参数。
- Seq2SeqTrainer 序列类的训练迭代器
# Seq2SeqTrainingArguments 设置训练参数。
# 例如,下面设置训练参数,配置学习率为2e-5,训练时batch大小为8,验证时为batch大小32,训练轮数为5,权重衰减大小为0.01,输出文件夹为model_for_seq2seqlm,日志记录的步长为10,即10个batch记录一次;评估策略为训练完一个epoch之后进行评估,模型保存策略同上,设置训练完成后加载最优模型,并指定最优模型的评估指标为rougeL,最后,需要指定predict_with_generate参数值为True。
# training_args = Seq2SeqTrainingArguments(
# learning_rate=3e-5,
# per_device_train_batch_size=8,
# per_device_eval_batch_size=32,
# num_train_epochs=5,
# weight_decay=0.01,
# output_dir="model_for_seq2seqlm",
# logging_steps=10,
# evaluation_strategy = "epoch",
# save_strategy = "epoch",
# load_best_model_at_end=True,
# metric_for_best_model="rougeL",
# predict_with_generate=True # 训练最后会调用generate方法进行生成
# )from trainer_seq2seq import Seq2SeqTrainer- ModelArguments模型参数,
- DataTrainingArguments数据集操作涉及的参数
#ModelArguments类为model/config/tokenizer涉及的参数
#DataTrainingArguments类为数据涉及到的参数
from arguments import ModelArguments, DataTrainingArguments
数据集的预处理
ADGEN数据集任务的数据形式,输入(content),生成输出(summary)
{"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳","summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
觉得有用 点个赞 + 收藏 吧
End
GPT专栏文章:
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
决策引擎专栏:
Falcon构建轻量级的REST API服务
决策引擎-利用Drools实现简单防火墙策略
相关文章:
)
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
GPT实战系列-如何使用P-Tuning本地化训练ChatGLM2等LLM模型?(二) 文章目录 GPT实战系列-1.训练参数配置传递2.训练前准备3.训练参数配置4.训练对象,seq2seq训练5.执行训练6.训练模型评估依赖数据集的预处理 P-Tuning v2 将 ChatGLM2-6B 模型需要微调的参…...

Python3.7+PyQt5 pyuic5将.ui文件转换为.py文件、Python读取配置文件、生成日志
1.实际开发项目时,是使用Qt Designer来设计UI界面,得到一个.ui的文件,然后利用PyQt5安装时自带的工具pyuic5将.ui文件转换为.py文件: pyuic5 -o mywindow.py mywindow.ui #先是py文件名,再是ui文件名样式图 QT5 UI&am…...

使用 VPN ,一定要知道的几个真相!
你们好,我的网工朋友。 今天想和你聊聊VPN。在VPN出现之前,企业分支之间的数据传输只能依靠现有物理网络(例如Internet)。 但由于Internet中存在多种不安全因素,报文容易被网络中的黑客窃取或篡改,最终造…...

数电实验-----实现74LS153芯片扩展为8选1时间选择器以及应用(Quartus II )
目录 一、74LS153芯片介绍 管脚图 功能表 二、4选1选择器扩展为8选1选择器 1.扩展原理 2.电路图连接(Quartus II ) 3.仿真结果 三、8选1选择器的应用 1.三变量表决器 2.奇偶校验电路 一、74LS153芯片介绍 74ls153芯片是属于四选一选择器的芯片。…...
如何实现MATLAB与Simulink的数据交互
参考链接:如何实现MATLAB与Simulink的数据交互 MATLAB是一款强大的数学计算软件,Simulink则是一种基于模型的多域仿真平台,常用于工程和科学领域中的系统设计、控制设计和信号处理等方面。MATLAB和Simulink都是MathWorks公司的产品࿰…...
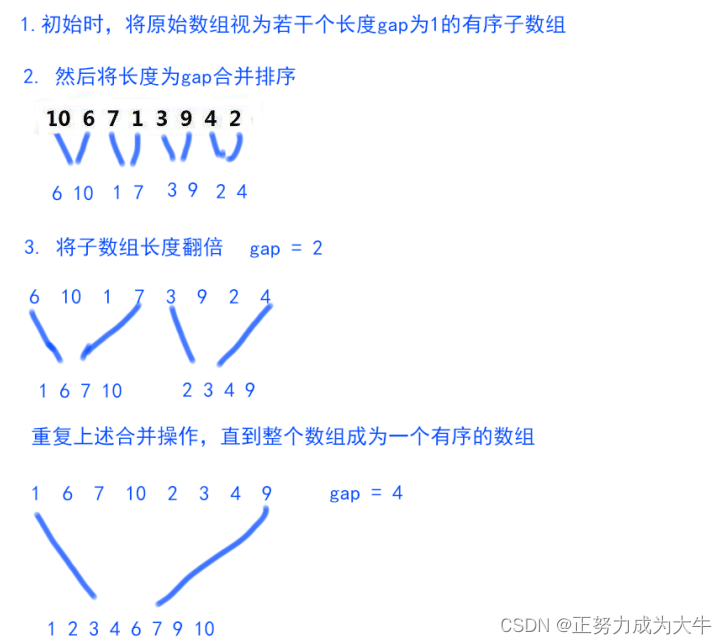
【数据结构】归并排序
👦个人主页:Weraphael ✍🏻作者简介:目前正在学习c和算法 ✈️专栏:数据结构 🐋 希望大家多多支持,咱一起进步!😁 如果文章有啥瑕疵 希望大佬指点一二 如果文章对你…...

数字引领,智慧赋能|袋鼠云与易知微共同亮相2023智慧港口大会
2023年10月19日,由中国港口协会、中国交通通信信息中心、天津港(集团)有限公司主办,中国港口协会智慧港口专业委员会、《港口科技》杂志社等单位承办的以“数字引领 智慧赋能”为主题的“2023智慧港口大会”在天津顺利召开。 袋鼠…...
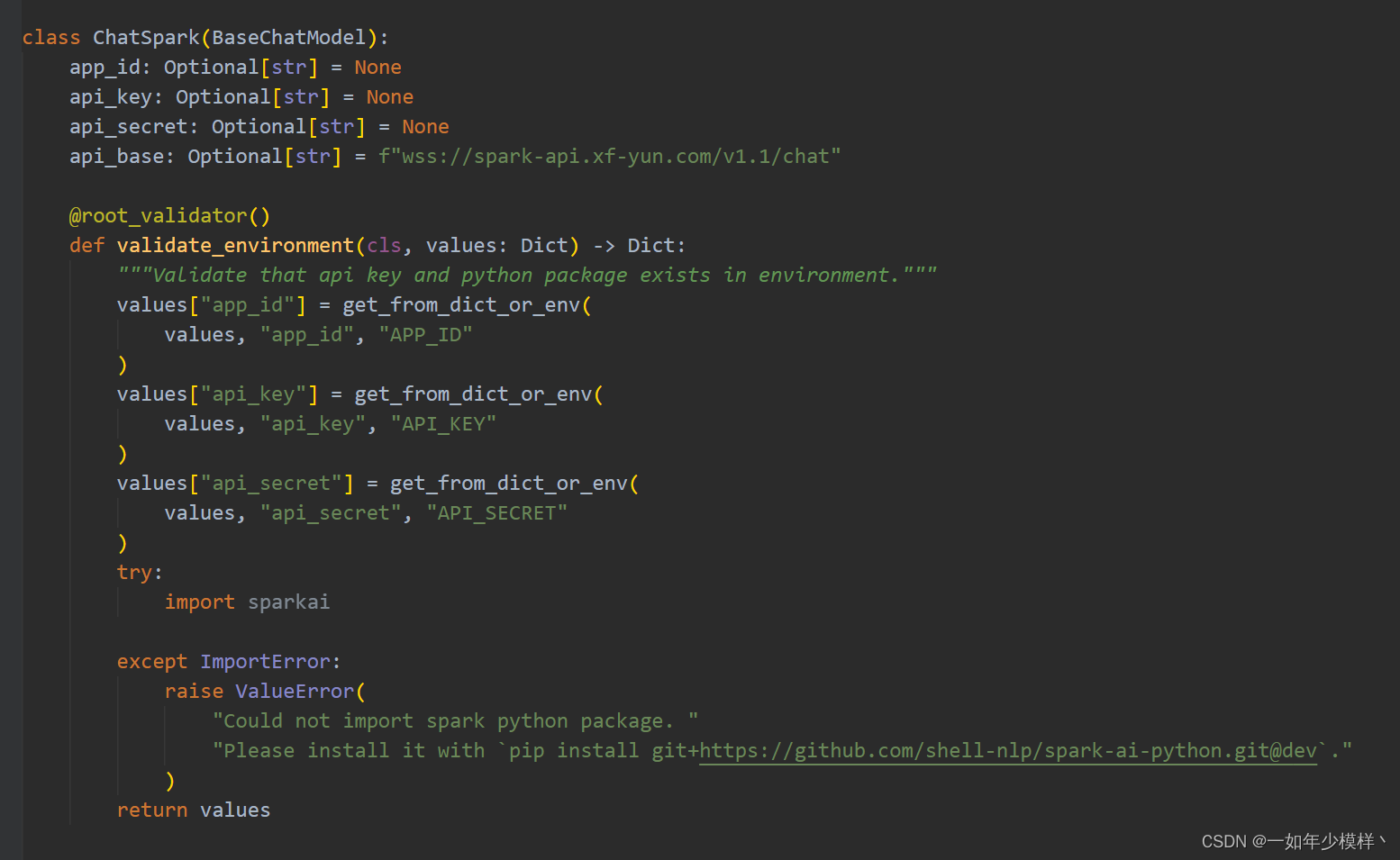
星火模型(Spark)的langchain 实现
星火模型的langchain实现 测试已通过,希望有所帮助。 使用前请先安装环境: pip install githttps://github.com/shell-nlp/spark-ai-python.git注意: 一定要使用上面方式安装spark库,因对官方的库做了改动。官方的库已经长时间不…...

python运算符重载之构造函数和迭代器
1 python运算符重载之构造函数和迭代器 python运算符重载是在类方法中拦截内置操作-当类的实例使用内置操作时,pytho自动调用对应方法,并且返回操作结果。 NO#描述1拦截运算运算符重载拦截内置操作,比如打印、函数调用、点号运算、表达式运…...

【数据处理】Python:实现求条件分布函数 | 求平均值方差和协方差 | 求函数函数期望值的函数 | 概率论
猛戳订阅! 👉 《一起玩蛇》🐍 💭 写在前面:本章我们将通过 Python 手动实现条件分布函数的计算,实现求平均值,方差和协方差函数,实现求函数期望值的函数。部署的测试代码放到文后了,运行所需环境 python version >= 3.6,numpy >= 1.15,nltk >= 3.4,tqd…...

new/delete 和malloc/free的区别
C中: 创建单个数据空间: char *ch new char; delete ch; ch NULL; 创建多个数据空间: char *ch new char[4]; delete [] ch; ch NULL; C语言中: 创建单个数据空间: char *ch malloc(sizeof(char)); fre…...

Linux程序设计(上)
系列文章目录 文章目录 系列文章目录前言一、unix, linux, GNU, POSIXLinux程序 二、shellshell语法1.变量2.语句 函数命令命令的执行dialog工具-- 三、文件操作1. Linux 文件结构2. 系统调用和设备驱动程序3. 库函数4. 底层文件访问5. 标准I/O库6.格式化输入输出7. 文件和目录…...

mysql面试题——存储引擎相关
一:MySQL 支持哪些存储引擎? MySQL支持多种存储引擎,比如InnoDB,MyISAM, MySQL大于等于5.5之后,默认存储引擎是InnoDB 二:InnoDB 和 MyISAM 有什么区别? InnoDB支持事务,MyISAM不支持InnoD…...

趣学python编程 (四、数据结构和算法介绍)
数据结构和算法在编程中非常重要。数据结构是组织和存储数据的方式,而算法是解决问题的方法和步骤。你要挑战的蓝桥杯,实际也是在设计算法解决问题。其实各种编程语言都只是工具,而程序的核心数据结构算法。犹如练武,数据结构和算…...
使用Pandas进行时间重采样,充分挖掘数据价值
大家好,时间序列数据蕴含着很大价值,通过重采样技术可以提升原始数据的表现形式。本文将介绍数据重采样方法和工具,提升数据可视化技巧。 在进行时间数据可视化时,数据重采样是至关重要且非常有用的,它支持控制数据的…...
Django(九、choices参数的使用、多对多表的三种创建方式、Ajax技术)
文章目录 一、choices参数choices参数的用法choices 参数用法总结 二、MVC与MTV模式1.MVC2.MTV 三、多对多的三种创建方式1.全自动创建2.纯手动创建半自动创建 四、Django与Ajax1.什么是Ajax常见的场景Ajax案例 一、choices参数 在没有用到choices参数之前,我们在D…...

德语B级SampleAcademy
德语B级 一, 反身代词(1)A 主语和宾语一致(2)D 双宾语,主语与直接宾语不一致(3), 补充单词(4)真反身代词(5)假反身代词(6)真假反身代词(7)相互反身(8)非反身#反身#相互反身 二,Nomen…...

vue3自定义hooks
获取dom的id属性 index.ts import { onMounted } from "vue" type option {el: string }export default function(option:option):Promise<{name: string}> {return new Promise((resolve)>{onMounted(()>{const dom:HTMLElement document.querySele…...

Consistency Models 阅读笔记
简介 Diffusion models需要多步迭代采样才能生成一张图片,这导致生成速度很慢。一致性模型(Consistency models)的提出是为了加速生成过程。 Consistency models可以直接一步采样就生成图片,但是也允许进行多步采样来提高生成的质…...

杭电oj 2034 人见人爱A-B C语言
此处的c和a指向同一块内存空间,改变c就是改变a,反之亦然,此处是为了方便看这么写的,如果不想c和a指向同一空间请分别开辟空间(即不如此写camalloc) #include<stdio.h> #include<stdlib.h>int …...

三分钟完成Taotoken的PythonSDK配置与首次聊天补全调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 三分钟完成Taotoken的Python SDK配置与首次聊天补全调用 对于刚拿到Taotoken API Key的Python开发者来说,最迫切的需求…...

腾讯 Marvis 马维斯完整使用教程 2026 最新版
从下载安装到文件整理 电脑控制 跨端协同 隐私模式和向量引擎扩展 一篇讲清楚一 先说结论 Marvis不是普通聊天工具 如果你最近关注 AI 助手,大概率已经刷到过腾讯 Marvis,也就是中文名马维斯。 它在 2026 年 5 月正式开放下载后,最大的看点…...

从概率拟合到内生心智:七层投影架构重构AGI数字生命新范式
自2017年Transformer架构问世以来,人工智能领域正式迈入大模型迭代时代。十余年间,千亿、万亿参数模型不断涌现,依托自注意力机制的概率拟合算法,AI在文本生成、多模态交互、逻辑问答等领域实现了规模化突破,彻底改变了…...

2026年阿里云OpenClaw/Hermes Agent配置Token Plan部署一文读懂
2026年阿里云OpenClaw/Hermes Agent配置Token Plan部署一文读懂。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

智能指挥官 · 用 Multi-Agent 编排让 AI 团队自己干活
🧑💻 博主介绍 & 诚邀关注 作者:专注于 Java、Python、前端开发的技术博主 | 全网粉丝 30 万 在校期间协助导师完成毕业设计课题分类、论文格式初审及代码整理工作;工作后持续分享毕设思路,助力毕业生顺利完成…...

免费图片去水印工具有哪些?2026 在线图片去水印软件推荐指南
日常刷到好看的图片想做壁纸或素材,角落那个突兀的水印总让人头疼。不管是自己拍摄时误触了时间水印,还是下载的参考图需要二次编辑,找到一个顺手且确实能用的去水印工具,是许多人在 2026 年依然高频遇到的需求。这篇文章就来整理…...

这些坑我已经帮你踩过了,Vue3+TS 实战开发必看!
这些坑我已经帮你踩过了,Vue3TS 实战开发必看! 上周五临下班,产品突然甩过来一个“紧急需求”:把核心的数据看板模块用 Vue3 TypeScript 重构,周一早会直接给老板演示。我当时的内心是极度自信的:“Vue3 组…...

为什么92%的NotebookLM项目在第3轮迭代后风格失控?——基于17个真实客户日志的归因分析与防御协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的NotebookLM项目在第3轮迭代后风格失控?——基于17个真实客户日志的归因分析与防御协议 在对17个企业级NotebookLM部署案例进行全链路日志回溯后,我们发现一个高度一致…...

大模型MoE架构揭秘:稀疏激活与专家路由原理
1. 这不是“参数越多越强”的简单故事:拆解大模型里被悄悄激活的那2% 你可能已经看过不少标题党文章,说“GPT-4有1.8万亿参数”,然后配上一张CPU满载、风扇狂转的动图,仿佛这串数字本身就在燃烧算力。但真实情况恰恰相反——它只用…...

Python API认证与授权实战:从Basic Auth到OAuth2.0
Python API认证与授权实战:从Basic Auth到OAuth2.0 引言 API安全是后端开发中至关重要的一环。作为从Python转向Rust的后端开发者,我深刻体会到认证与授权机制的重要性。一个安全可靠的API需要完善的认证体系来保护敏感数据和资源。本文将从实战角度出…...