归并排序详解:递归实现+非递归实现(图文详解+代码)
文章目录
- 归并排序
- 1.递归实现
- 2.非递归实现
- 3.海量数据的排序问题
归并排序
- 时间复杂度:O ( N * logzN ) 每一层都是N,有log2N层
- 空间复杂度:O(N),每个区间都会申请内存,最后申请的数组大小和array大小相同
- 稳定性:稳定
目前为止,稳定的排序有:插入、冒泡、归并
- 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,采用了分治法

- 将待排序列分解,先使每个子序列有序,再使子序列段间有序
- 将已有序的子序列合并,得到完全有序的序列
- 若将两个有序表合并成一个有序表,称为二路归并
1.递归实现
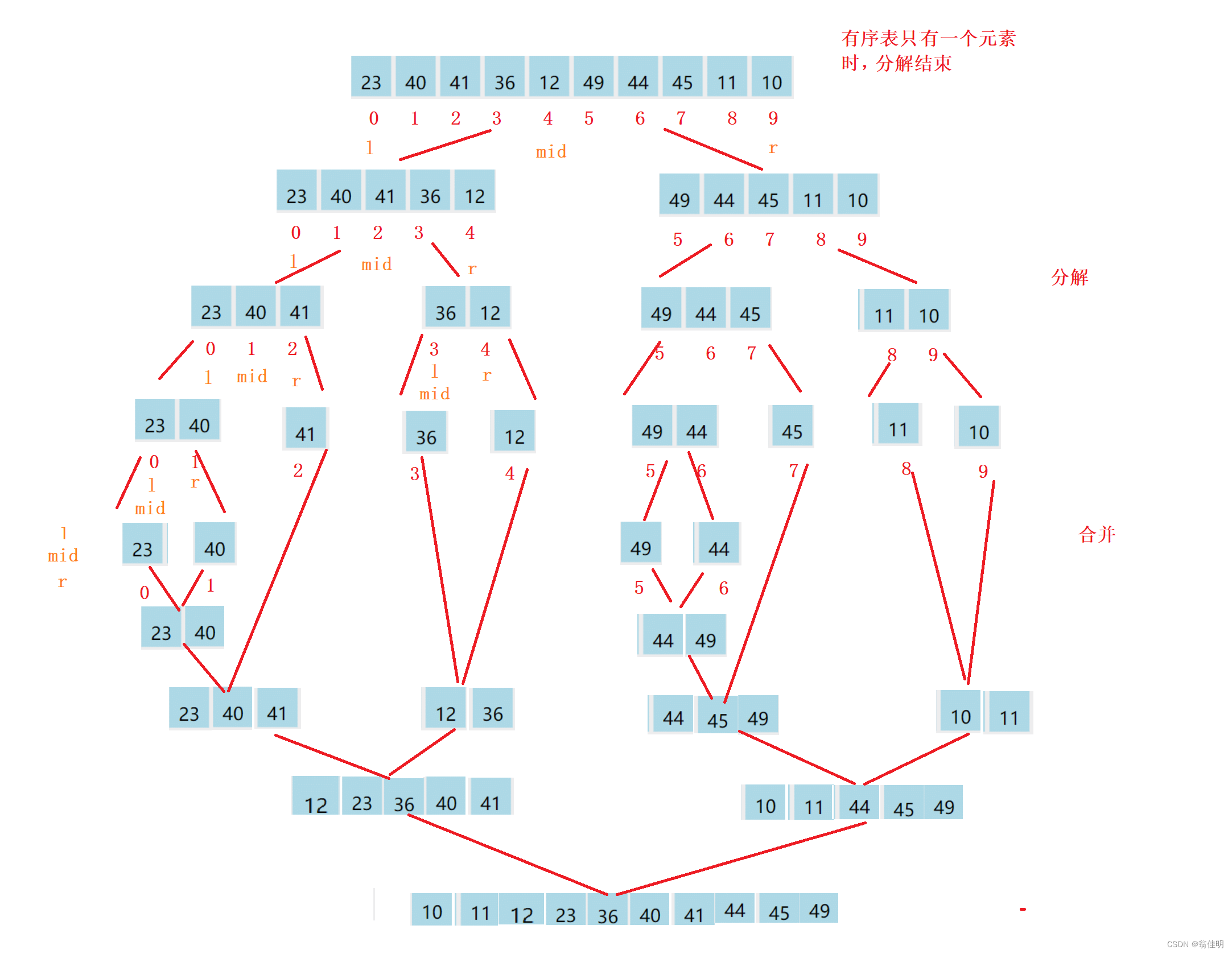
- 1.确定递归的结束条件,求出中间数mid,
- 2.进行分解,根据mid来确定递归的区间大小
- 3.递归分解完左边,然后递归分解右边
- 4.左右分解完成后,进行合并
- 5.申请新数组进行合并,比较两个数组段,记得查漏补缺
- 6.和并的时候要对齐下标,每个tmp的下标要找到array中对应的下标
/*** 归并排序* @param array*/public static void mergeSort(int[] array) {mergeSortFunc(array,0,array.length-1);}private static void mergeSortFunc(int[] array, int left, int right) {//结束条件if (left >= right) {return;}//进行分解int mid = (left + right) / 2;mergeSortFunc(array, left, mid);mergeSortFunc(array, mid + 1, right);//左右分解完成后,进行合并merge(array, left, right, mid);}//进行合并private static void merge(int[] array, int start, int end, int mid) {int s1 = start;int s2 = mid + 1;int[] tmp = new int[end - start + 1];int k = 0;//k为tmp数组的下标while (s1 <= mid && s2 <= end) {//两个数组中都有数据//进行比较,放到新申请的数组if (array[s1] <= array[s2]) {tmp[k++] = array[s1++];} else {tmp[k++] = array[s2++];}}//因为有&&条件,数组不一定走完while (s1 <= mid) {tmp[k++] = array[s1++];}while (s2 <= end) {tmp[k++] = array[s2++];}//此时,将排好的tmp数组的数组,拷贝到arrayfor (int i = 0; i < tmp.length; i++) {array[i+start] = tmp[i];//对齐下标}}
2.非递归实现
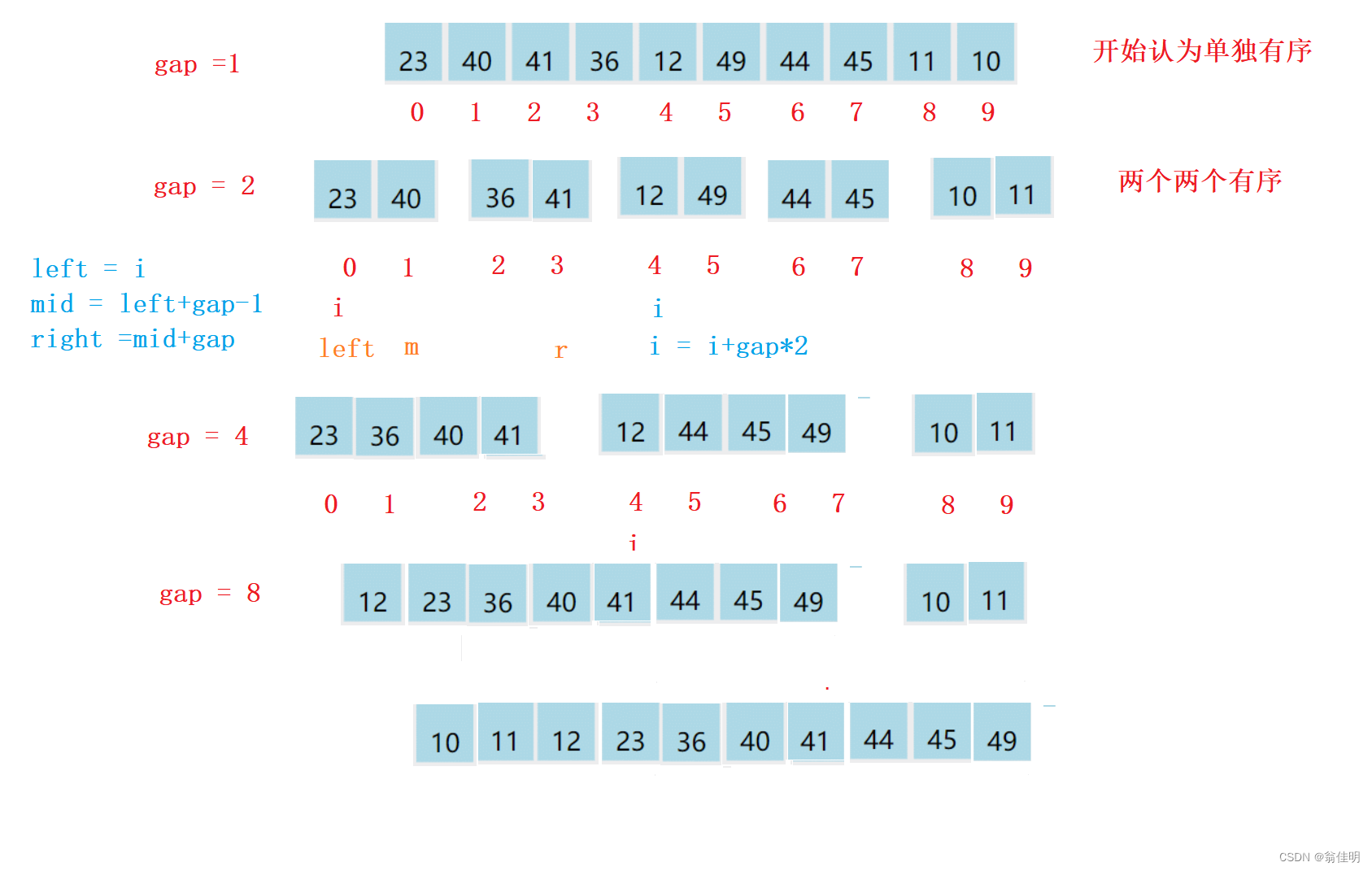
- 1.从1开始分组,先保证每个数都是独立有序的
- 2.进行循环,i下标从0开始,每次跳转组数的两倍
- 3.根据left = i,求出mid和right
- 4.要避免mid和right越界
- 5.分组进行合并
- 6.二倍数扩大组数
/**** 归并排序,非递归实现* @param array*/public static void mergeSort2(int[] array) {int gap = 1;while (gap < array.length) {//i += gap * 2 i每次跳到下一组for (int i = 0; i < array.length; i += gap * 2) {int left = i;//要避免mid和right越界int mid = left + gap - 1;if(mid>=array.length){mid = array.length-1;//修正越界的情况}int right = mid + gap;if (right>=array.length){//修正越界的情况right = array.length-1;}merge(array,left,right,mid);//进行合并}gap *=2;//2倍数扩大组数}}//进行合并private static void merge(int[] array, int start, int end, int mid) {int s1 = start;int s2 = mid + 1;int[] tmp = new int[end - start + 1];int k = 0;//k为tmp数组的下标while (s1 <= mid && s2 <= end) {//两个数组中都有数据//进行比较,放到新申请的数组if (array[s1] <= array[s2]) {tmp[k++] = array[s1++];} else {tmp[k++] = array[s2++];}}//因为有&&条件,数组不一定走完while (s1 <= mid) {tmp[k++] = array[s1++];}while (s2 <= end) {tmp[k++] = array[s2++];}//此时,将排好的tmp数组的数组,拷贝到arrayfor (int i = 0; i < tmp.length; i++) {array[i + start] = tmp[i];//对齐下标}}
3.海量数据的排序问题
外部排序:排序过程需要在磁盘等外部存储进行的排序
前提:内存只有 1G,需要排序的数据有 100G
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序
- 先把文件切分成 200 份,每个 512 M
- 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以
- 进行 2路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
点击移步博客主页,欢迎光临~

相关文章:
归并排序详解:递归实现+非递归实现(图文详解+代码)
文章目录 归并排序1.递归实现2.非递归实现3.海量数据的排序问题 归并排序 时间复杂度:O ( N * logzN ) 每一层都是N,有log2N层空间复杂度:O(N),每个区间都会申请内存,最后申请的数组大小和array大小相同稳定…...
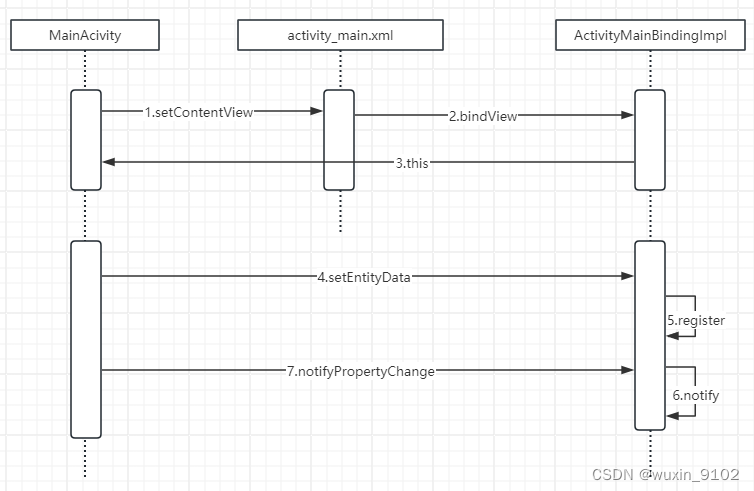
DataBinding原理
1、MainActivity首先使用DataBindingUtil.setContentView设置布局文件activity_main.xml。 2、随后,经过一系列函数调用,ActivityMainBindingImpl对象最终会实例化,并与activity_main.xml进行绑定。 3、实例化后的ActivityMainBindingImpl对象…...
docker更换国内源
docker更换国内源 1、编辑Docker配置文件 在终端中执行以下命令,编辑Docker配置文件: vi /etc/docker/daemon.json2、添加更新源 在打开的配置文件中,添加以下内容: {"registry-mirrors": ["https://hub-mirror…...
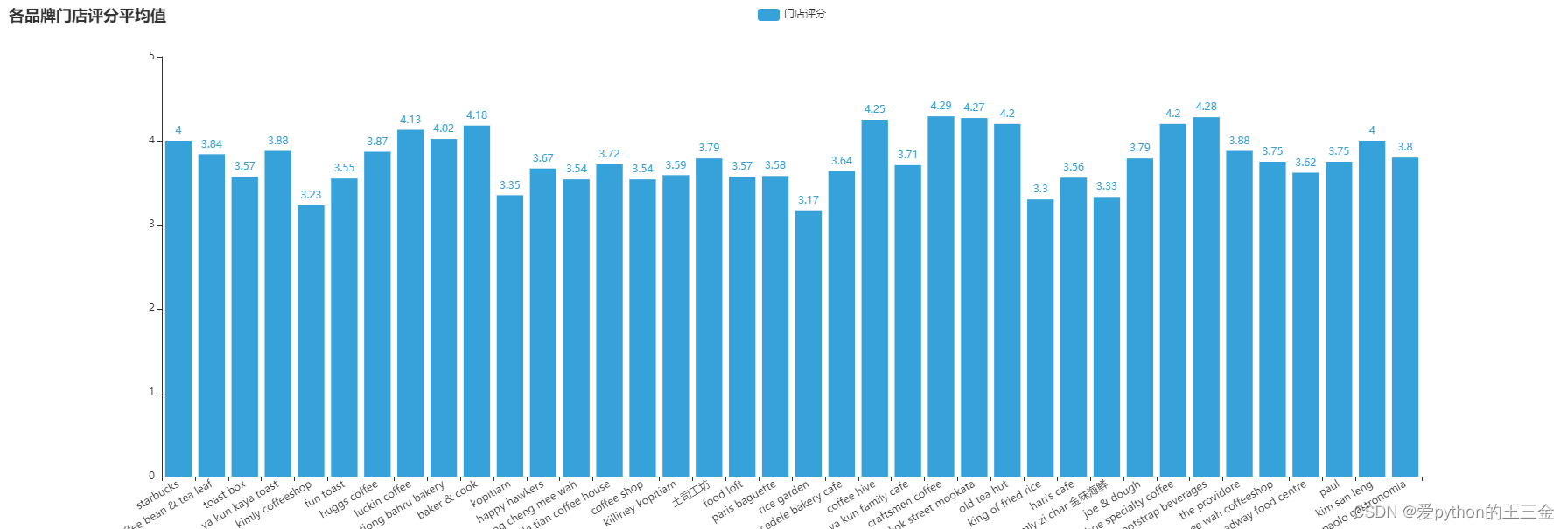
【咖啡品牌分析】Google Maps数据采集咖啡市场数据分析区域分析热度分布分析数据抓取瑞幸星巴克
引言 咖啡作为一种受欢迎的饮品,已经成为我们生活中不可或缺的一部分。随着国内外咖啡品牌的涌入,新加坡咖啡市场愈加多元化和竞争激烈。 本文对新加坡咖啡市场进行了全面的品牌门店数占比分析,聚焦于热门品牌的地理分布、投资价值等。通过…...

【Java】异常处理(一)
🌺个人主页:Dawn黎明开始 🎀系列专栏:Java ⭐每日一句:什么都不做,才会来不及 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️ 文章目录 📋前…...

【高级程序设计】Week2-4Week3-1 JavaScript
一、Javascript 1. What is JS 定义A scripting language used for client-side web development.作用 an implementation of the ECMAScript standard defines the syntax/characteristics of the language and a basic set of commonly used objects such as Number, Date …...

PHP笔记-->读取JSON数据以及获取读取到的JSON里边的数据
由于我以前是写C#的,现在学一下PHP, 在读取json数据的时候被以前的思维卡住了。 以前用C#读取的时候,是先定义一个数组,将反序列化的json存到数组里面,在从数组里面获取jaon中的“data”数据。 其实PHP的思路也是一样…...

【Spring Boot】如何集成Redis
在pom.xml文件中导入spring data redis的maven坐标。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 在application.yml文件中加入redis相关配置。 spr…...
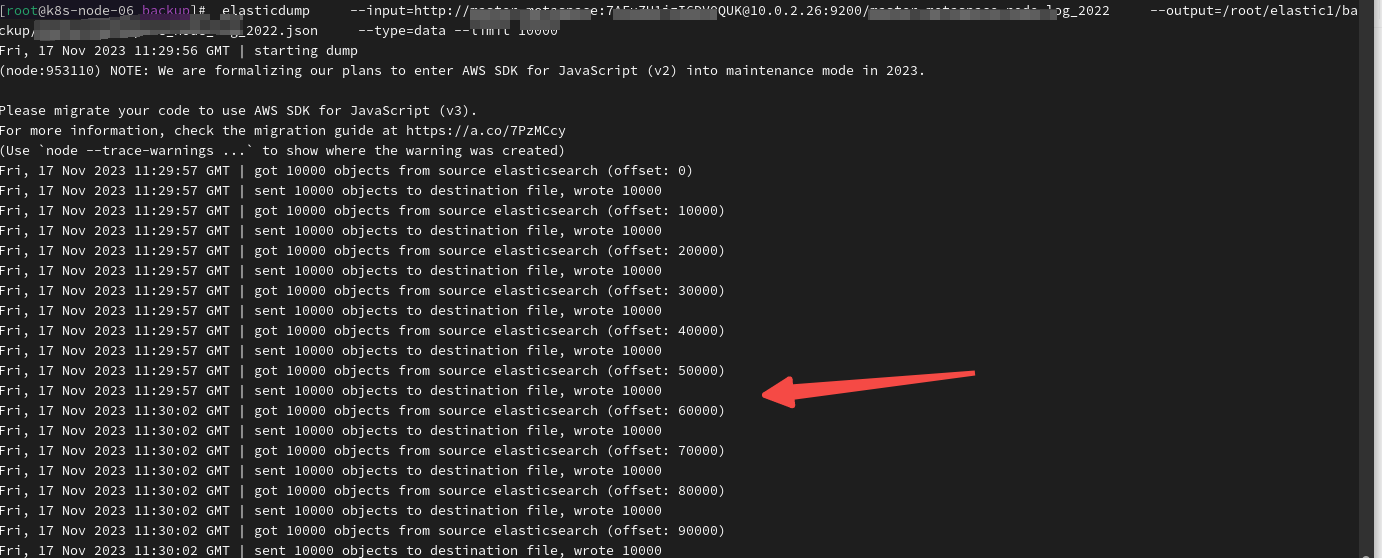
Elasticsearch备份与还原:使用elasticdump
在数据管理的世界里,备份和还原数据是重中之重的日常工作,特别是对于Elasticsearch这样的强大而复杂的搜索引擎。备份不仅可以用于灾难恢复,还可以在数据迁移、测试或者升级等场景中发挥重要作用。 在本博客中,我们将会重点介绍如…...

给大伙讲个笑话:阿里云服务器开了安全组防火墙还是无法访问到服务
铺垫: 某天我在阿里云上买了一个服务器,买完我就通过MobaXterm进行了ssh(这个软件是会保存登录信息的) 故事开始: 过了n天之后我想用这个服务器来部署流媒体服务,咔咔两下就部署好了流媒体服务器&#x…...

js:react使用zustand实现状态管理
文档 https://www.npmjs.com/package/zustandhttps://github.com/pmndrs/zustandhttps://docs.pmnd.rs/zustand/getting-started/introduction 安装 npm install zustand示例 定义store store/index.js import { create } from "zustand";export const useCount…...
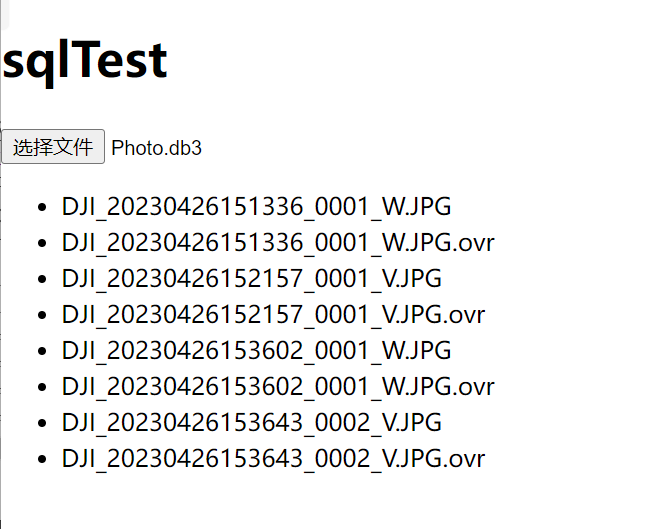
vue3+vite+SQL.js 读取db3文件数据
前言:好久没写博客了,最近一直在忙,没时间梳理。最近遇到一个需求是读取本地SQLite文件,还是花费了点时间才实现,没怎么看到vite方面写这个的文章,现在分享出来完整流程。 1.pnpm下载SQL.js(什么都可以下)…...
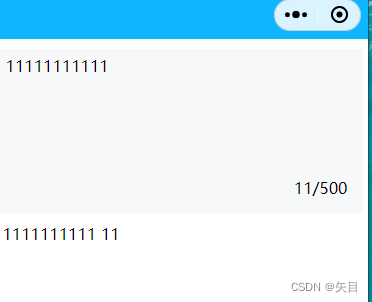
微信小程序 限制字数文本域框组件封装
微信小程序 限制字数文本域框 介绍:展示类组件 导入 在app.json或index.json中引入组件 "usingComponents": {"text-field":"/pages/components/text-field/index"}代码使用 <text-field maxlength"500" bindtabsIt…...
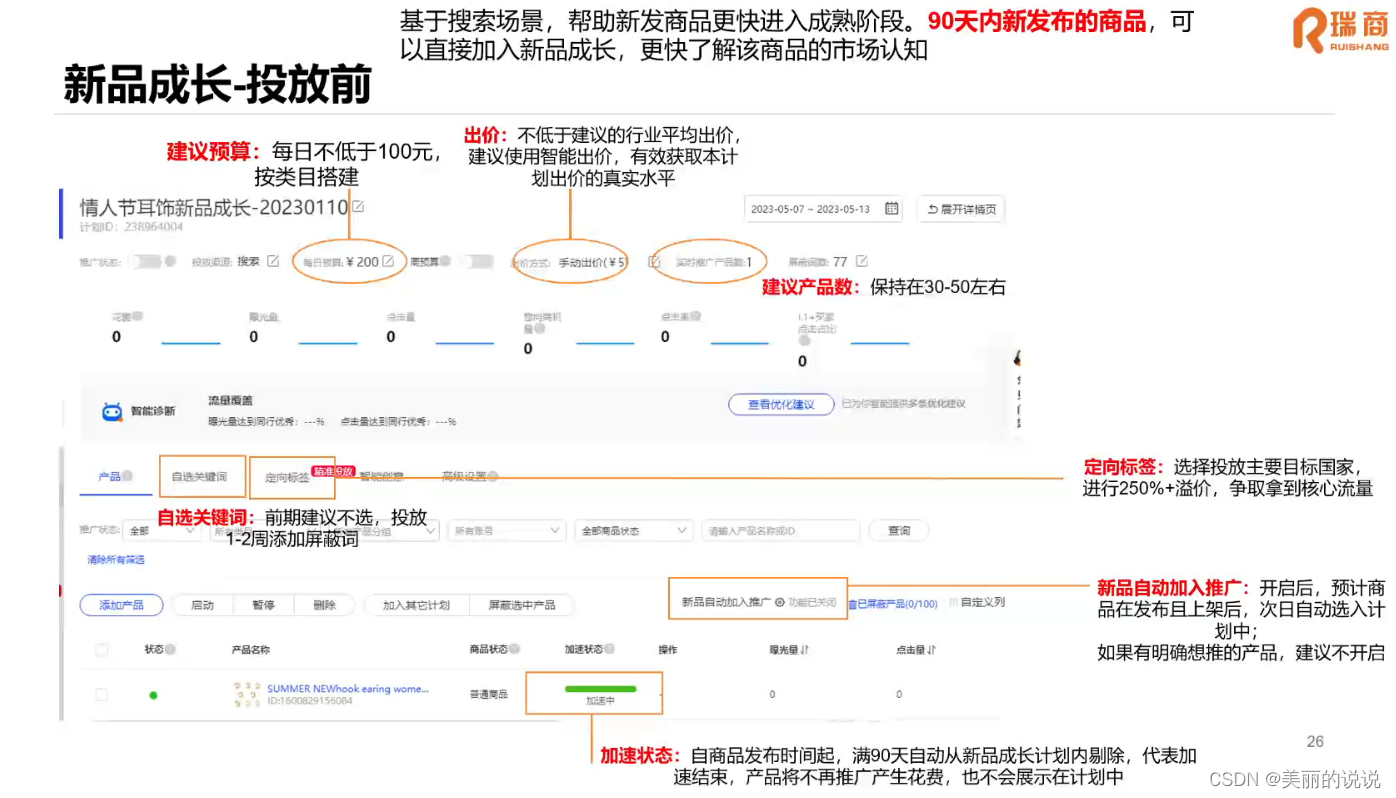
阿里国际站(直通车)
1.国际站流量 2.直通车即P4P(pay for performance点击付费) 2.1直通的含义:按点击付费,通过自助设置多维度展示产品信息,获得大量曝光吸引潜在买家。 注意:中国大陆和尼日利尼地区点击不扣费。 2.2扣费规…...

C# GC机制
在C#中,垃圾回收(Garbage Collection,简称GC)是CLR(公共语言运行时)的一个重要部分,用于自动管理内存。它会自动释放不再使用的对象所占用的内存,避免内存泄漏,减少程序员…...
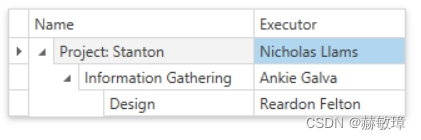
wpf devexpress在未束缚模式中生成Tree
TreeListControl 可以在未束缚模式中没有数据源时操作,这个教程示范如何在没有数据源时创建tree 在XAML生成tree 创建ProjectObject类实现数据对象显示在TreeListControl: public class ProjectObject {public string Name { get; set; }public string Executor {…...

Python利器:os与chardet读取多编码文件
在数据处理中会遇到读取位于不同位置的文件,每个文件所在的层级不同,而且每个文件的编码类型各不相同,那么如何高效地读取文件呢? 在读取文件时首先需要获取文件的位置信息,然后根据文件的编码类型来读取文件。本文将使用os获取文件路径,使用chardet得到文件编码类型。 …...

微服务和注册中心
微服务和注册中心是紧密相关的概念,可以说注册中心是微服务架构中必不可少的一部分。 在微服务架构中,系统被拆分成了若干个独立的服务,因此服务之间需要进行通信和协作。为了实现服务的发现和调用,需要一个中心化的注册中心来进…...
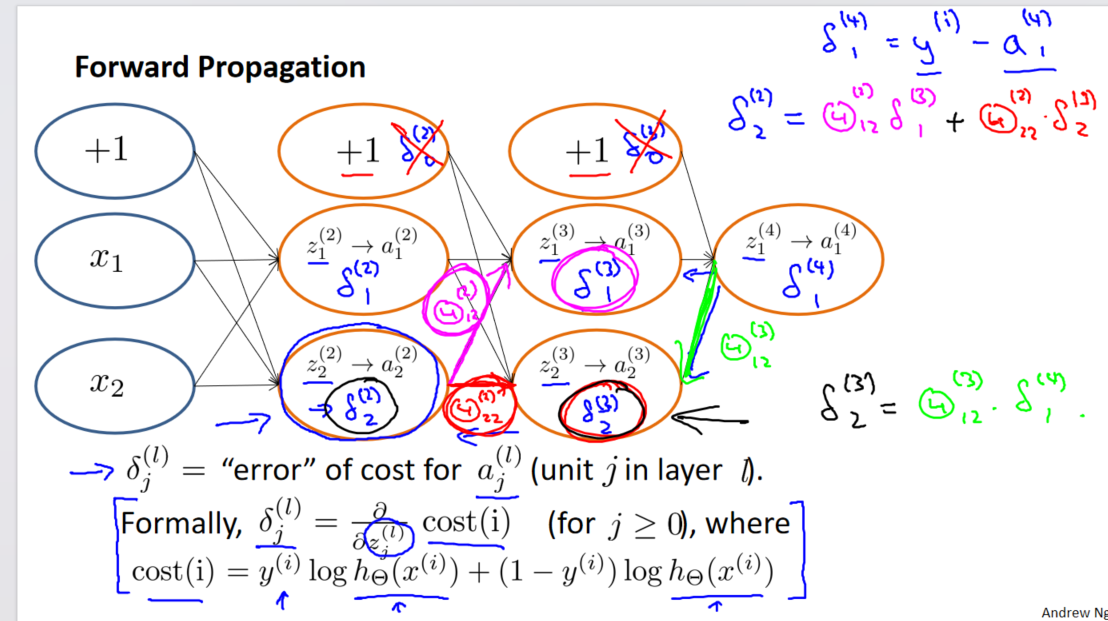
吴恩达《机器学习》9-1-9-3:反向传播算法、反向传播算法的直观理解
一、正向传播的基础 在正向传播中,从神经网络的输入层开始,通过一层一层的计算,最终得到输出层的预测结果。这是一种前向的计算过程,即从输入到输出的传播。 二、反向传播算法概述 反向传播算法是为了计算代价函数相对于模型参数…...
Java 算法篇-链表的经典算法:判断回文链表、判断环链表与寻找环入口节点(“龟兔赛跑“算法实现)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 链表的创建 2.0 判断回文链表说明 2.1 快慢指针方法 2.2 使用递归方式实现反转链表方法 2.3 实现判断回文链表 - 使用快慢指针与反转链表方法 3.0 判断环链表说明…...

如何快速掌握GetQzonehistory:QQ空间备份的完整教程
如何快速掌握GetQzonehistory:QQ空间备份的完整教程 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心多年积累的QQ空间说说会随着时间流逝而消失?那些记…...

通过curl命令快速测试Taotoken接口连通性与模型响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken接口连通性与模型响应效果 对于开发者而言,在集成大模型服务时,快速验证接口…...

三分钟永久备份你的QQ空间:告别数据丢失的终极解决方案
三分钟永久备份你的QQ空间:告别数据丢失的终极解决方案 【免费下载链接】QZoneExport QQ空间导出助手,用于备份QQ空间的说说、日志、私密日记、相册、视频、留言板、QQ好友、收藏夹、分享、最近访客为文件,便于迁移与保存 项目地址: https:…...

终极指南:5分钟学会使用html-to-docx将HTML完美转换为Word文档
终极指南:5分钟学会使用html-to-docx将HTML完美转换为Word文档 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx 你是否曾经需要将网页内容转换为专业的Word文档,却发现格式完全…...

工业级字符识别实战:C#结合YOLO+Tesseract实现药品批号与电子元件丝印精准校验
在工业自动化生产线上,字符识别一直是质量管控的核心环节。从药品包装的批号、有效期到电子元件的丝印型号、批次号,每一个字符的错误都可能导致严重的产品质量问题甚至安全事故。 传统的OCR方案在面对工业场景时往往力不从心:字符倾斜、背景…...

Mac Mouse Fix:3步让你的普通鼠标超越苹果触控板体验
Mac Mouse Fix:3步让你的普通鼠标超越苹果触控板体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾为macOS上鼠标功能受限…...

临近毕业10款降AI率工具实测+避坑:到底哪个降AI率工具是真的有用
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

3个关键问题解析:如何用PlantUML Editor提升UML设计效率
3个关键问题解析:如何用PlantUML Editor提升UML设计效率 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 你是否曾在UML设计过程中陷入这样的困境:花费大量时间调整…...

找工厂用什么工具?为什么“收录企业更多“是个伪指标
很多人在选工商数据工具的时候,被一个指标带着走——“收录企业数量更多”。直觉上,数据库越大越好,选谁不选大的。 但如果你的实际需求是"找工厂"——上游销售要找工厂客户、采购方要找代工供应商、跨境卖家要找一手代工厂——这个指标对你毫无意义,甚至是负担。原因…...

交互式振动传感器工作原理
交互式振动传感器通过实时采集机械振动数据,结合无线通信与智能算法,实现设备状态监测与预警反馈。 其工作原理基于以下核心环节:一、核心工作流程振动感知:传感器元件:采用MEMS三轴加速度计(如ADXL3…...