深度学习笔记:不同的反向传播迭代方法
1 随机梯度下降法SGD

随机梯度下降法每次迭代取梯度下降最大的方向更新。这一方法实现简单,但是在很多函数中,梯度下降的方向不一定指向函数最低点,这使得梯度下降呈现“之”字形,其效率较低

class SGD:"""随机梯度下降法(Stochastic Gradient Descent)"""def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):for key in params.keys():params[key] -= self.lr * grads[key]
2 Momentum

momentum即动量。该方法设置变量v代表梯度下降的速度,其中dL/dW(梯度值)代表改变速度的“受力”,而α则作为“阻力”,限制v变化。该方法进行梯度下降可以类比一个小球在三维平面上滚动。
在下面的示例中,可以看到虽然迭代方向还是呈“之”字形,但是在x方向,虽然梯度较小,但是由于受力始终在一个方向,速度逐渐加快。在y方向,虽然梯度大,但上下受力相反,使得y方向不会有很大偏移

class Momentum:"""Momentum SGD"""def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items(): self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] = self.momentum*self.v[key] - self.lr*grads[key] params[key] += self.v[key]
在程序里一开始v设为None,在第一次调用update时会将v更新为和各权重形状一样的0矩阵
3 AdaGrad

AdaGrad的思路是根据上一轮迭代的变化量动态调整每一个权重的学习率。一个权重在迭代中变化量越大,其在下一轮中学习率就会减少更多。
在公式中,我们用h记录过去所有梯度的平方和(⊙代表矩阵元素相乘),在更新权重时之前变化较大的权重值变化量会变小。
由于h是不断累加的平方和,如果学习一直持续下去,W更新率会不断趋于0,要改善这一问题可以参考RMSProp,该方法会对较早更新的梯度逐渐“遗忘”,而更多反应新更新的状态
AdaGrad
class AdaGrad:"""AdaGrad"""def __init__(self, lr=0.01):self.lr = lrself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
在这里注意我们在h的每个元素中加上了微小的1e-7,这是为了防止h中有元素为0时,作为除数会报错。
RMSProp
class RMSprop:"""RMSprop"""def __init__(self, lr=0.01, decay_rate = 0.99):self.lr = lrself.decay_rate = decay_rateself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] *= self.decay_rateself.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
RMSProp的方法和AdaGrad类似,除了每一轮迭代时会将h乘上一个decay_rate(大小在0-1)以减小之前梯度对h的影响

如图,一开始由于y方向梯度变化大,所以更新快,但因此y方向上学习率也减小较快,使得网络在后期逐渐沿x方向更新
Adam
Adam类似于momentum和AdaGrad两种方法的结合,其具体原理较为复杂,可以找原论文http://arxiv.org/abs/1412.6980v8
class Adam:"""Adam (http://arxiv.org/abs/1412.6980v8)"""def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):self.lr = lrself.beta1 = beta1self.beta2 = beta2self.iter = 0self.m = Noneself.v = Nonedef update(self, params, grads):if self.m is None:self.m, self.v = {}, {}for key, val in params.items():self.m[key] = np.zeros_like(val)self.v[key] = np.zeros_like(val)self.iter += 1lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter) for key in params.keys():#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)
利用mnist数据集对几种训练方式进行比较:
在该测试程序中,我们使用5层神经网络,每层神经元个数100。利用SGD, momentum, AdaGrad, Adam, RMSProp分别进行2000次迭代,并比较最终各网络的总损失
# coding: utf-8
import os
import sys
sys.path.append("D:\AI learning source code") # 为了导入父目录的文件而进行的设定
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import *# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000# 1:进行实验的设置==========
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
optimizers['RMSprop'] = RMSprop()networks = {}
train_loss = {}
for key in optimizers.keys():networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],output_size=10)train_loss[key] = [] # 2:开始训练==========
for i in range(max_iterations):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]for key in optimizers.keys():grads = networks[key].gradient(x_batch, t_batch)optimizers[key].update(networks[key].params, grads)loss = networks[key].loss(x_batch, t_batch)train_loss[key].append(loss)if i % 100 == 0:print( "===========" + "iteration:" + str(i) + "===========")for key in optimizers.keys():loss = networks[key].loss(x_batch, t_batch)print(key + ":" + str(loss))# 3.绘制图形==========
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D", "RMSprop": "v"}
x = np.arange(max_iterations)
for key in optimizers.keys():plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()实验结果如下

相关文章:
深度学习笔记:不同的反向传播迭代方法
1 随机梯度下降法SGD 随机梯度下降法每次迭代取梯度下降最大的方向更新。这一方法实现简单,但是在很多函数中,梯度下降的方向不一定指向函数最低点,这使得梯度下降呈现“之”字形,其效率较低 class SGD:"""随机…...
ElasticSearch 学习笔记总结(三)
文章目录一、ES 相关名词 专业介绍二、ES 系统架构三、ES 创建分片副本 和 elasticsearch-head插件四、ES 故障转移五、ES 应对故障六、ES 路由计算 和 分片控制七、ES集群 数据写流程八、ES集群 数据读流程九、ES集群 更新流程 和 批量操作十、ES 相关重要 概念 和 名词十一、…...

深入理解border以及应用
深入border属性以及应用👏👏 border这个属性在开发过程中很常用,常常用它来作为边界的。但是大家真的了解border吗?以及它的形状是什么样子的。 我们先来看这样一段代码:👏 <!--* Author: syk 185901…...

如何复现论文?什么是论文复现?
参考资料: 学习篇—顶会Paper复现方法 - 知乎 如何读论文?复现代码?_复现代码是什么意思 - CSDN 我是如何复现我人生的第一篇论文的 - 知乎 在我看来,论文复现应该有一个大前提和分为两个层次。 大前提是你要清楚地懂得自己要…...
 A~C)
22.2.28打卡 Codeforces Round #851 (Div. 2) A~C
A题 One and Two 题面翻译 题目描述 给你一个数列 a1,a2,…,ana_1, a_2, \ldots, a_na1,a2,…,an . 数列中的每一个数的值要么是 111 要么是 222 . 找到一个最小的正整数 kkk,使之满足: 1≤k≤n−11 \leq k \leq n-11≤k≤n−1 , anda1⋅a2⋅……...

Learining C++ No.12【vector】
引言: 北京时间:2023/2/27/11:42,高数考试还在进行中,我充分意识到了学校的不高级,因为题目真的没什么意思,虽然挺平易近人,但是……,考试期间时间比较放松,所以不能耽误…...
【数电基础】——逻辑代数运算
目录 1.概念 1.基本逻辑概念 2.基本逻辑电路(与或非) 逻辑与运算 与门电路: 逻辑或运算 或门电路: 逻辑非运算(逻辑反) 非门电路编辑 3.复合逻辑电路(运算) 与非逻辑…...

【Redis】什么是缓存与数据库双写不一致?怎么解决?
1. 热点缓存重建 我们以热点缓存 key 重建来一步步引出什么是缓存与数据库双写不一致,及其解决办法。 1.1 什么是热点缓存重建 在实际开发中,开发人员使用 “缓存 过期时间” 的策略来实现加速数据读写和内存使用率,这种策略能满足大多数…...
互联网衰退期,测试工程师35岁之路怎么走...
国内的互联网行业发展较快,所以造成了技术研发类员工工作强度比较大,同时技术的快速更新又需要员工不断的学习新的技术。因此淘汰率也比较高,超过35岁的基层研发类员工,往往因为家庭原因、身体原因,比较难以跟得上工作…...
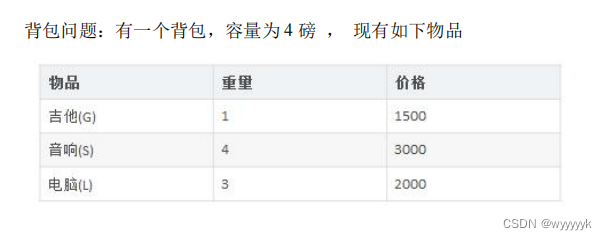
动态规划(以背包问题为例)
1) 要求达到的目标为装入的背包的总价值最大,并且重量不超出2) 要求装入的物品不能重复动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法。动态规划算法与分治算法类似ÿ…...
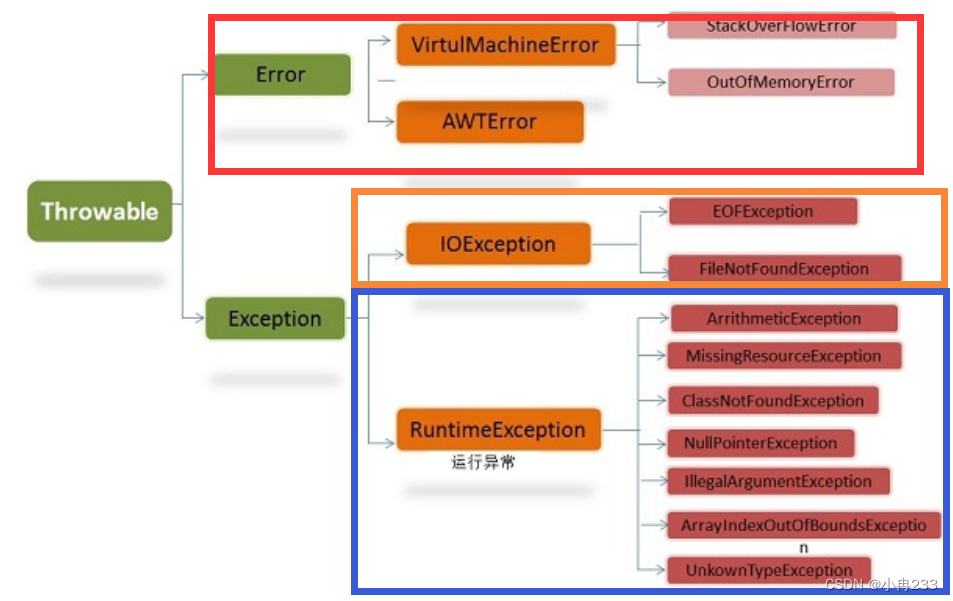
Java异常
异常的体系结构 在java的Throwable下有Error和Exception两个子类 Error(错误):程序运行中出现了严重的问题,非代码性错误,无法处理,常见的有虚拟机运行错误和内存溢出等Exception(异常):是由于代码本身造成的问题,可以进行处理,异常一个可以分为运行时异常和编译时异常 运行…...

别克GL8改装完工,一起来看看效果
①豪华商务头等舱 别克GL8作为商务车,不管是家用还是商务接待,原车内饰都太掉档次了,所以车主要求全部换掉。>>织布座椅换成航空座椅 主副驾:改装纳帕皮 中排:改装水晶宝座豪华版航空座椅,带通风、加…...

mac 中 shell 一些知识
mac 设置环境变量首先得看你所使用的 shell shell 是一个命令行解释器,顾名思义就是机器外面的一层壳,用于人机交互,只要是人与电脑之间交互的接口,就可以称为 shell。表现为其作用是用户输入一条命令,shell 就立即解…...
)
CentOS 配置FTP(开启VSFTPD服务)
网上已经有很多关于VSFTPD的配置,但有两个通病,要么就是原理介绍太多,要么就是不完整,操作下来又要查询多篇文章才能用。 我这里不讲原理,只记录操作,尽可能通过复制下面的操作可以实现FTP读写功能。方便自…...

Http的请求方法
Http的请求方法对应的数据传输能力把Http请求分为Url类请求和Body类请求 1.Url类请求包括但不限于GET、HEAD、OPTIONS、TRACE 等请求方法 2.Body类请求包括但不限于POST、PUSH、PATCH、DELETE 等请求方法。 3.原因:get请求没有请求体(好像也可以…...

Python字典-- 内附蓝桥题:统计数字
字典 ~~不定时更新🎃,上次更新:2023/02/28 🗡常用函数(方法) 1. dic.get(key) --> 判断字典 dic 是否有 key,有返回其对应的值,没有返回 None 举个栗子🌰 dic …...

文本处理工具
Grep工具的基本使用grep作用:grep是行过滤工具;用于根据关键字进行行过滤提示:通过alias命令设置grep别名,搜索参数时带颜色显示alias grepgrep colorauto 命令语法格式:grep [选项] 参数 文件名grep命令选项ÿ…...
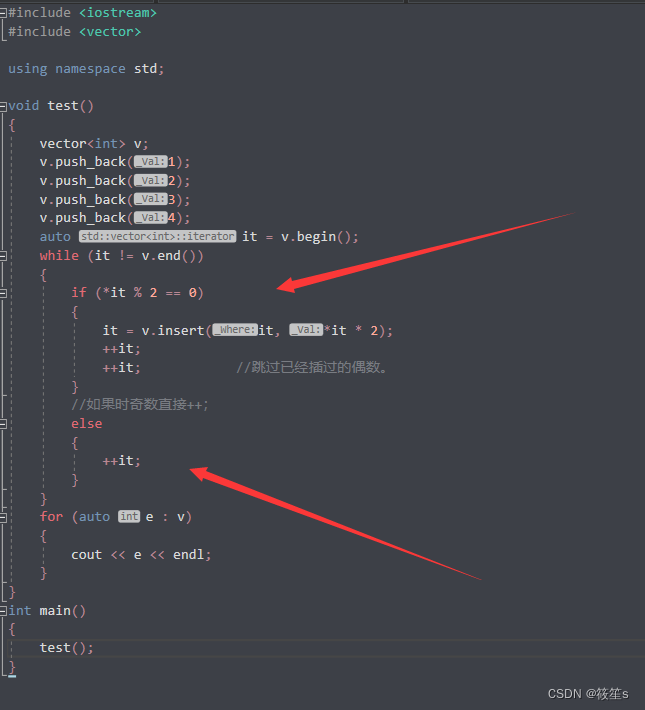
C++STL详解(三)——vector的介绍和使用
文章目录vector的介绍vector的使用vector的定义方式vector的空间增长问题reserve和resizevector的迭代器使用begin 和endrbegin和rendinsert 和erasefind函数元素访问vector迭代器失效问题1:inserse插入扩容时空间销毁造成野指针问题2:erase删除或者inse…...
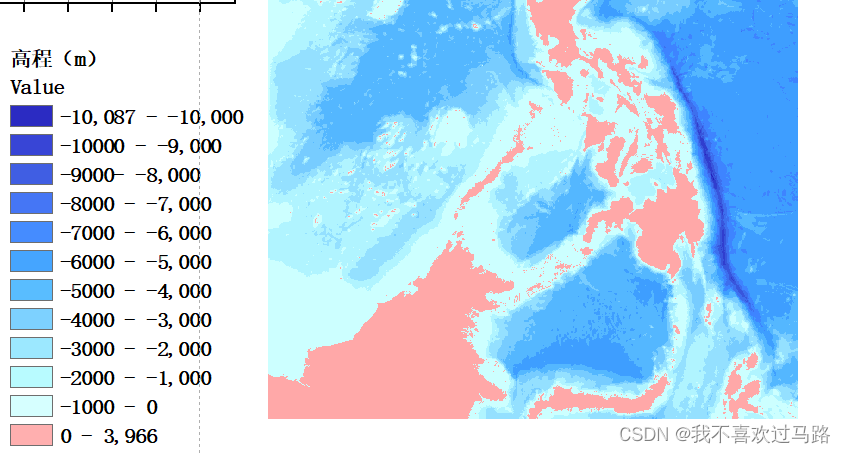
GEBCO海洋数据下载
一、数据集简介 GEBCO(General Bathymetric chart of the Oceans)旨在为世界海洋提供最权威的、可公开获取的测深数据集。 目前的网格化测深数据集,即GEBCO_2022网格,是一个全球海洋和陆地的地形模型,在15角秒间隔的…...
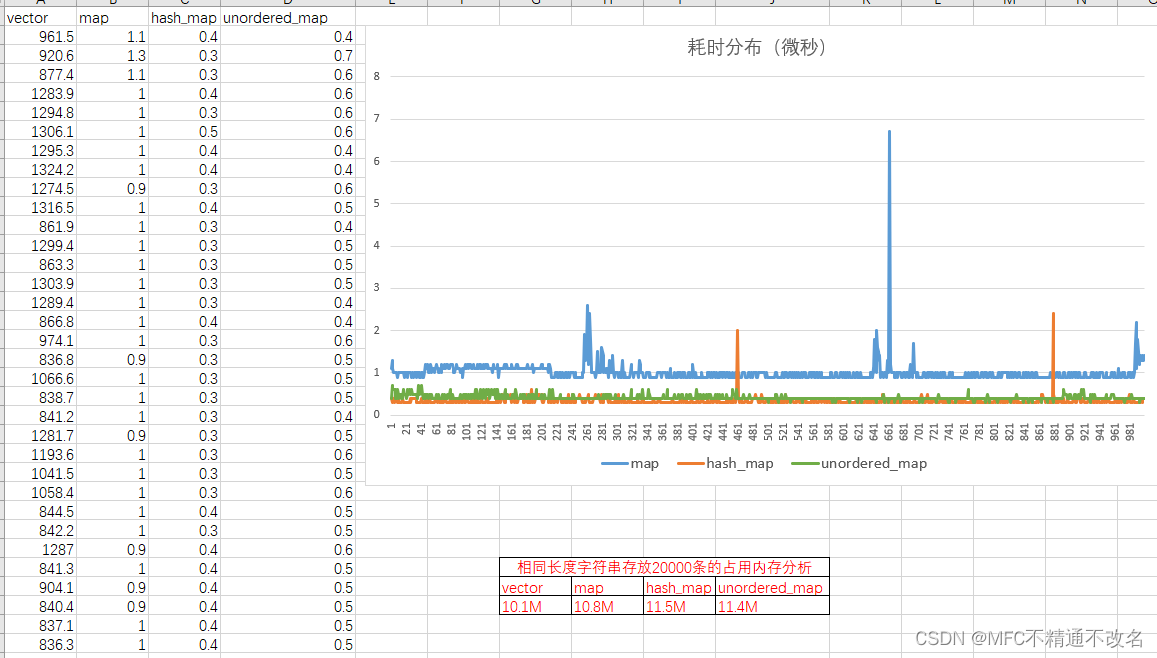
【C++容器】vector、map、hash_map、unordered_map四大容器的性能分析【2023.02.28】
摘要 vector是标准容器对数组的封装,是一段连续的线性的内存。map底层是二叉排序树。hash_map是C11之前的无序map,unordered_map底层是hash表,涉及桶算法。现对各个容器的查询与”插入“性能做对比分析,方便后期选择。 测试方案…...

物理 AI 为什么离不开边缘计算?
过去两年,AI 给人的印象基本是一回事——一个对话框,一个输入框。你打字它打字,你上传它分析,AI 安静地待在屏幕里,处理着一切关于文字、图像、代码的事情。行业的注意力也都跟着堆在那一头。云厂商抢算力,…...

从零构建AI编程助手:Groundhog项目解析与Rust实现
1. 项目概述:一个从零开始理解AI编程助手的教学项目如果你和我一样,对Cursor、GitHub Copilot这类AI编程助手背后的工作原理感到好奇,甚至有点“黑盒”恐惧,那么这个叫Groundhog的项目,可能就是为你量身打造的。它不是…...

Gemini3.1Pro成本优化实战指南
在做 2026 年的多模态项目时,大家最关心的往往不是“能不能用”,而是“怎么用得更划算”。如果你正在对接不同模型、比较价格与可用性,先把计费规则与调用链路梳理清楚,会省下大量试错成本。你也可以把 KULAAI(dl.877a…...
Translumo:让游戏外语对话秒变母语的神奇翻译助手
Translumo:让游戏外语对话秒变母语的神奇翻译助手 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 还在为看不懂…...

TI毫米波雷达IWR1642数据采集实战:从mmWave Studio参数设置到16MB bin文件大小计算全解析
TI毫米波雷达IWR1642数据采集实战:从mmWave Studio参数设置到16MB bin文件大小计算全解析 毫米波雷达在自动驾驶、工业检测等领域的应用日益广泛,而TI的IWR1642作为一款高性价比的毫米波雷达传感器,其数据采集过程却常常让开发者感到困惑。特…...

如何快速上手res-downloader:3个技巧解决网络资源下载难题
如何快速上手res-downloader:3个技巧解决网络资源下载难题 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...

ImageGlass:Windows平台终极开源图像浏览解决方案
ImageGlass:Windows平台终极开源图像浏览解决方案 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 在数字图像日益丰富的今天,Windows用户迫切需要一…...

终极网盘加速方案:3步实现多平台高速数据流优化
终极网盘加速方案:3步实现多平台高速数据流优化 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 网盘直链下载助手是一款开源免费的浏览器脚本工具,专为解决主流云存储服…...

如何永久保存微信聊天记录:5分钟掌握完整数据备份方案
如何永久保存微信聊天记录:5分钟掌握完整数据备份方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

终极指南:如何用Elasticvue轻松管理你的Elasticsearch集群
终极指南:如何用Elasticvue轻松管理你的Elasticsearch集群 【免费下载链接】elasticvue Elasticsearch gui - desktop app, browser extension, docker, self hosted 项目地址: https://gitcode.com/gh_mirrors/el/elasticvue Elasticsearch是当今最流行的分…...