下厨房网站月度最佳栏目菜谱数据获取及分析PLus
目录
概要
源数据获取
写Python代码爬取数据
Scala介绍与数据处理
1.Sacla介绍
2.Scala数据处理流程
数据可视化
最终大屏效果
小结
概要
本文的主题是获取下厨房网站月度最佳栏目近十年数据,最终进行数据清洗、处理后生成所需的数据库表,最终进行数据可视化。用到的技术栈有Python网络爬虫、数据分析、Scala引擎、Flask框架等,其中会重点讲解使用Scala数据处理的过程,其他步骤则是一笔带过。
源数据获取
- 首先是源数据地址,网站来源于下厨房 (xiachufang.com),查看网站情况如下:
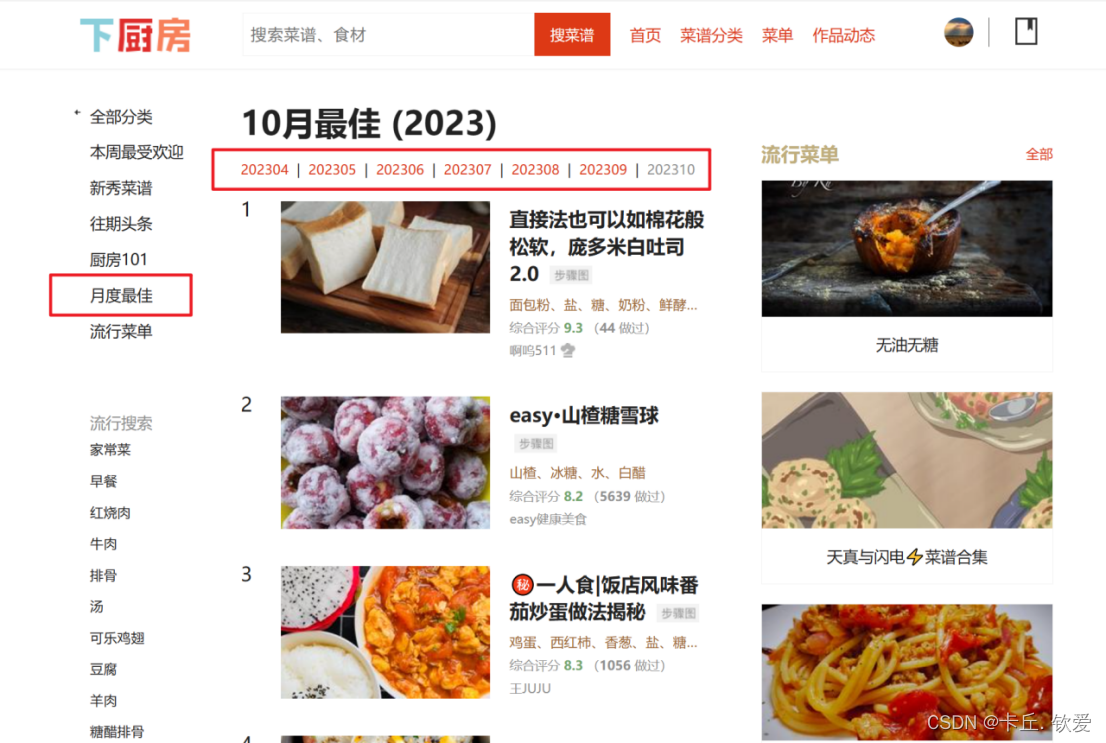
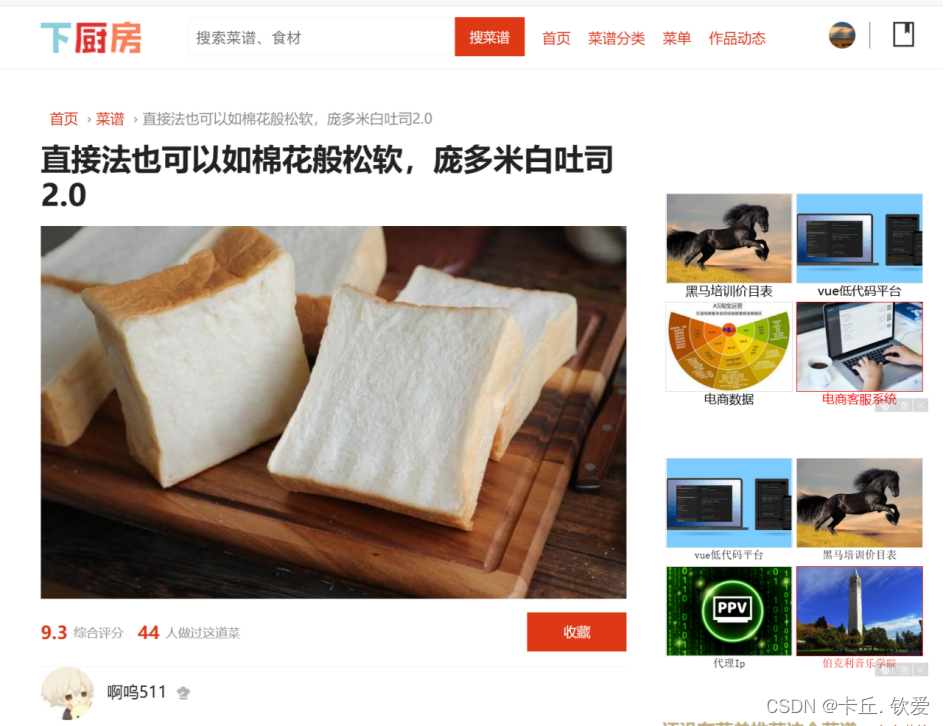

可以看见,本次的数据源是下厨房网站里面的月度最佳栏目,该栏目有2011年3月到至今2023年10月的连续数据,其中每个月有50道当月最受欢迎菜品,每个菜谱点进去后,不仅有菜名、详细用料等,还贴出具体步骤。
-
写Python代码爬取数据
如图,利用所学知识,编写爬虫代码对网站进行解析并爬取数据,最后经过简单处理后存储至MySQL数据库并另存为csv表格留档,本次只获取了2015年5月至2023年10月近10年的数据

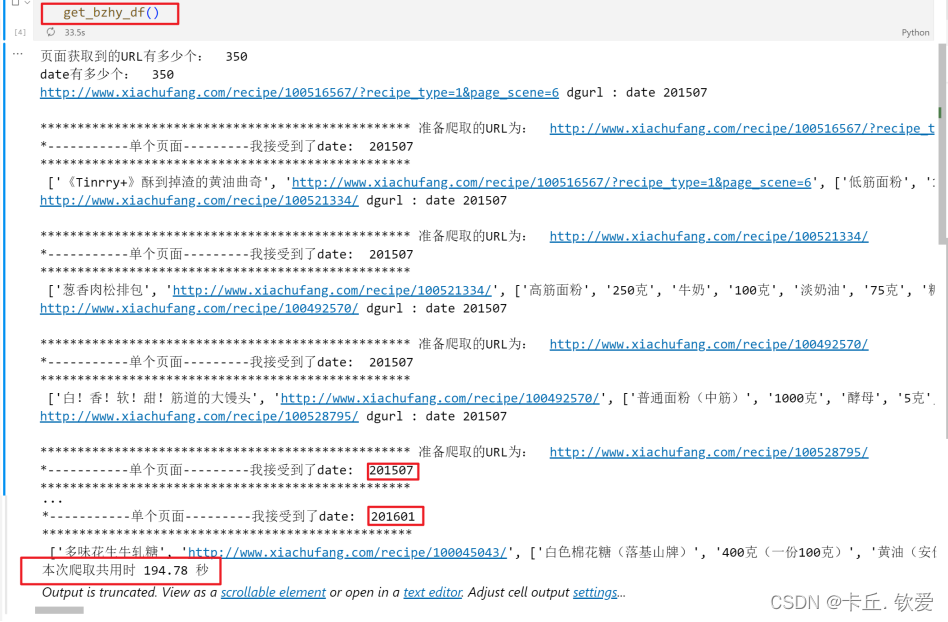
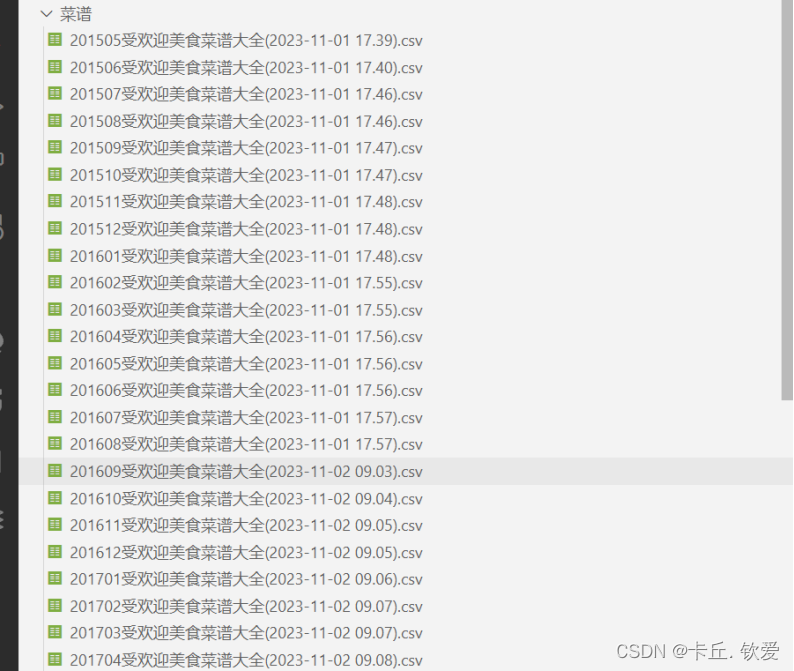
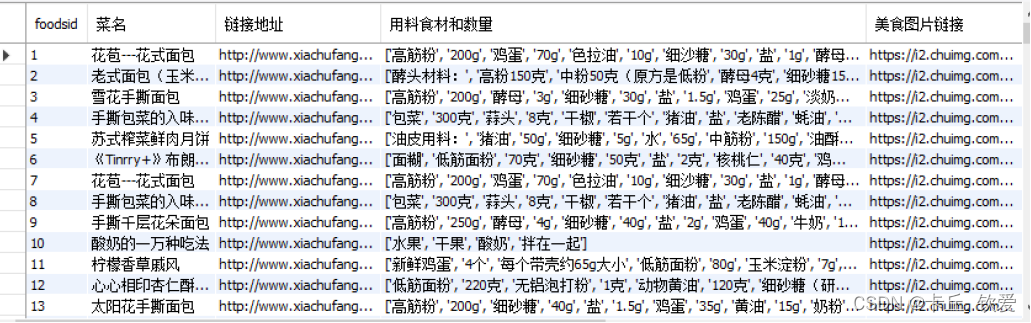

可以看见获取的数据总共有十个字段,有菜名、链接、做法等信息,其中foods_id、收藏人数、最佳年月字段是整型,其余字段都是文本类型
Scala介绍与数据处理
1.Sacla介绍
Scala是一种通用的编程语言,它结合了面向对象编程和函数式编程的特点,并且在大数据处理领域被广泛使用。
Scala最初于2003年由Martin Odersky教授开发,并于2004年首次发布。Scala在Java虚拟机(JVM)上运行,可以与Java互操作,并且可以直接使用Java的库和工具。
Scala的主要特点包括:
静态类型系统:Scala是一种静态类型的语言,这意味着在编译时会进行类型检查,减少运行时错误。
面向对象和函数式编程:Scala支持面向对象编程,可以使用类、继承和多态等概念。同时,Scala也支持函数式编程,提供了高阶函数、匿名函数和不可变数据结构等特性。
表达力强大:Scala具有强大而灵活的语法,可以用更少的代码实现复杂的任务。它提供了模式匹配、高级类型推断和代数数据类型等功能,使编程变得更加简洁和易读。
并发编程支持:Scala内置了并发编程库,提供了可以简化并发编程的抽象和工具。其中,最著名的是Akka框架,它提供了基于消息传递的并发模型。
在大数据处理领域,Scala通常与Apache Spark搭配使用。Spark是一个快速、通用的大数据处理引擎,Scala是其主要支持的编程语言之一。借助Scala的强大特性和Spark的分布式计算能力,开发人员可以编写高效、可扩展的大数据处理应用程序。
总而言之,Scala是一种强大的编程语言,特别适用于大数据处理和并发编程。它结合了面向对象和函数式编程的优点,并且在大数据处理领域有着广泛的应用和影响。
2.Scala数据处理流程
现在数据库已经有了源数据,接下来就是进行数据处理了。这里我选择的技术是Scala引擎,不熟悉的小伙伴可以上网查看该技术的语法格式和注意事项,我就不进行过多描述,直接进行代码解读。首先,要明确处理的目标和步骤,通过查看数据,我设立了5个指标,附上指标说明和代码:
- 代码前文:mysql_da是数据库源数据,de_Data是根据菜名去重后的数据
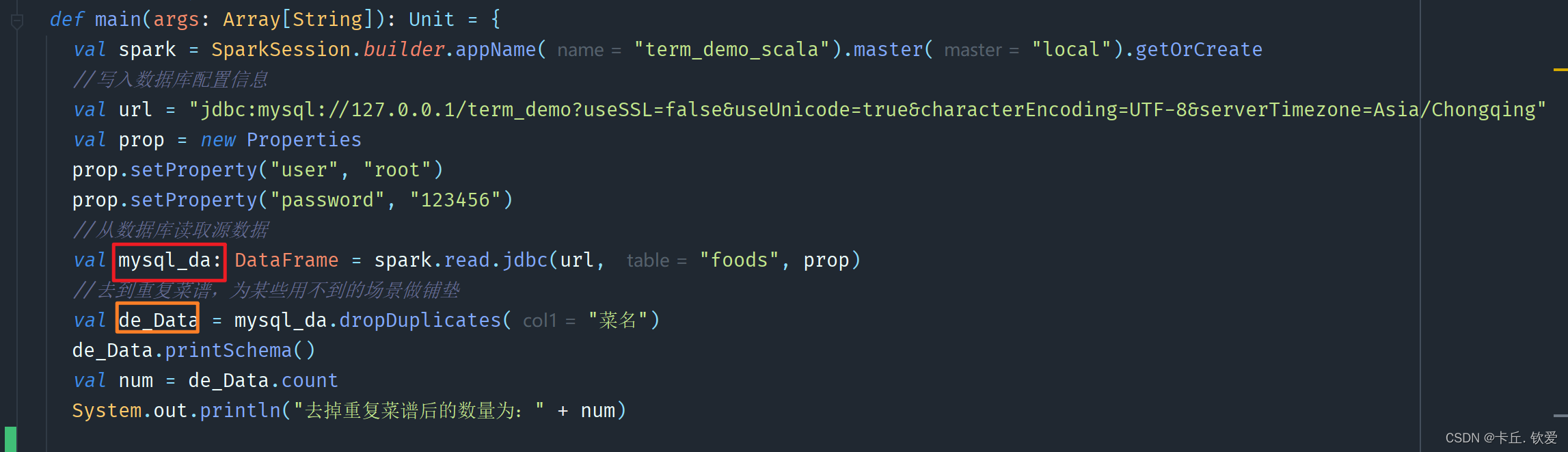
- 1 作者菜谱及收藏总量
这里对去重后的数据,根据作者id进行分组,然后聚合行数即为菜品数量、聚合收藏人数即为中收藏数量,最后调用write方法将处理后的数据存储到新的数据表和Hadoop集群的hdfs组件
//1 查询数据源里面属于一个作者的菜品和总收藏量有多少,保存前100个作者,存储下来val num_foods = de_Data.groupBy("作者id").agg(functions.count("*").alias("菜品数量"),functions.sum("收藏人数").alias("总收藏数量")).sort(functions.desc("菜品数量")).limit(100)//打印看看结果是否出来num_foods.show();System.out.println("*************菜谱数量top100*********")//存储至本地数据库num_foods.write.mode(SaveMode.Overwrite).jdbc(url, "foods_num", prop)//存储到hdfsnum_foods.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_num")
- 2 历年收藏Top10
- 首先,对最佳年月字段进行处理,将其转换为年份,并创建临时视图"foods_with_year"。
- 接着,使用SQL语句查询不同年份中收藏人数最多的前10道菜,并生成临时视图"year_tab1"。
- 最后,从临时视图"year_tab1"中选取字段,并按年份升序、收藏人数降序排序,并展示前100行结果。
- 将结果数据保存至本地数据库和HDFS中。
//2 查询数据里面不同年份最多收藏人数的前10菜品// 将最佳年月字段转换为年份System.out.println("做到第二题了")val de_year = de_Data.withColumnRenamed("收藏人数", "sl")de_year.createOrReplaceTempView("foods")spark.sql("SELECT *, CAST(SUBSTRING(`最佳年月`, 1, 4) AS int) as year FROM foods").createOrReplaceTempView("foods_with_year")// 查询不同年份中收藏人数最多的前10道菜val year = spark.sql("SELECT * FROM (SELECT *, row_number() " +"OVER (PARTITION BY year ORDER BY sl desc ) AS rank_no FROM foods_with_year ) tmp WHERE rank_no <= 10 ")//分两步进行sql查询,第一步是开窗函数进行分组统计,第二步是根据年份和收藏人数排序year.createOrReplaceTempView("year_tab1")val foods_year = spark.sql("select `year`, `菜名`,`用料食材和数量`, `链接地址`, `作者id`, `sl`,`rank_no` " +"from year_tab1 order by `year` asc, `sl` desc")foods_year.show(100, false)//存储至本地数据库foods_year.write.mode(SaveMode.Overwrite).jdbc(url, "foods_year", prop)//存储到hdfsfoods_year.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_year")
- 3 历年收藏Top10
首先,根据创建时间添加了一个名为“季节”的字段,根据不同的月份范围为每个菜品添加上了对应的季节信息,然后修改了字段名为“season”以方便后续处理。
使用窗口函数,在每个季节内按收藏人数进行降序排名,并取出每个季节收藏数量排名前5的菜品,将结果存储在名为“data_jj1”的DataFrame中。
将结果数据分别保存至本地数据库和HDFS中。在保存至本地数据库时,使用了覆盖的保存模式。
//3 根据创建时间再添加一个字段:季节,比如3-5月是春季,6-8是夏季~//根据季节来进行分组计数,计算出每个季节收藏数量排名前5的菜品// 添加季节字段var data_jj = de_Data.withColumn("季节", functions.when(month(col("创建时间")).between(3, 5), "春季").when(month(col("创建时间")).between(6, 8), "夏季").when(month(col("创建时间")).between(9, 11), "秋季").otherwise("冬季"))// 把季节改成英文方便开窗函数运行data_jj = data_jj.withColumnRenamed("季节", "season")data_jj = data_jj.withColumnRenamed("收藏人数", "sl")data_jj.createTempView("data_jj")val windowSpec = Window.partitionBy("season").orderBy(functions.desc("sl"))val data_jj1 = data_jj.withColumn("rank_no", row_number.over(windowSpec)).orderBy(expr("CASE season " +"WHEN '春季' THEN 1 " +"WHEN '夏季' THEN 2 " +"WHEN '秋季' THEN 3 " +"WHEN '冬季' THEN 4 " +"ELSE 5 " + "END"), col("rank_no")).filter(col("rank_no").leq(5))System.out.println("*************每个季节收藏数量排名前5的菜品*********")// 将数据存储到本地数据库和hdfs集群//保存模式为覆盖data_jj1.write.mode(SaveMode.Overwrite).jdbc(url, "foods_season", prop)//存储到hdfsdata_jj.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_season")
- 4 历年收藏Top10
- 将数据加载到临时视图"ws_data"中,以便后续查询操作。
- 使用SQL语句进行查询,按照年份对每个作者的收藏数量进行汇总,并按收藏数量降序排名。取每年收藏数量前3的作者和总收藏量数据,将结果保存在名为"foods_with_year"的临时视图中。
- 从"foods_with_year"视图中查询结果并展示。
- 将结果数据保存至本地数据库,并使用覆盖的保存模式。
- 将结果数据保存至HDFS中,数据格式为parquet,并使用覆盖的保存模式。
//4每年收藏数量前3的作者和总收藏量mysql_da.createTempView("ws_data")spark.sql("SELECT `最佳年月`, `作者id`, `年收藏量`\n" +"FROM (\n" + " SELECT `最佳年月`, `作者id`, SUM(`收藏人数`) AS `年收藏量`,\n" +"ROW_NUMBER() OVER(PARTITION BY FLOOR(`最佳年月` / 100) ORDER BY Max(`收藏人数`) DESC) AS `排名`\n" + " " +"FROM ws_data\n" + " GROUP BY `最佳年月`, `作者id`\n" + ") AS subquery\n" + "WHERE `排名` <= 3\n" + "ORDER BY `最佳年月`,`排名`").createOrReplaceTempView("foods_with_year")val fsj = spark.sql("SELECT CAST(SUBSTRING(`最佳年月`, 1, 4) AS int) as `年份` ,`作者id`, `年收藏量` FROM foods_with_year")fsj.show()//存储至本地数据库fsj.write.mode(SaveMode.Overwrite).jdbc(url, "foods_nszl", prop)//存储到hdfsfsj.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_nscl")
- 5 历年收藏Top10
- 将数据加载到临时视图"ws_data1"中,为后续查询做准备。
- 使用SQL语句查询每个最佳年月的作者的年收藏量,并按照排名进行排序,将结果保存在名为"foods_zly"的临时视图中。
- 从"foods_zly"视图中提取年份、作者ID和年收藏量的数据。
- 计算每年的总收藏人数增长趋势,包括计算增长率,并展示结果。
- 将结果数据保存至本地数据库中,并使用覆盖的保存模式。
- 将结果数据保存至HDFS中,数据格式为parquet,并使用覆盖的保存模式。
//5.每年的收藏率趋势mysql_da.createTempView("ws_data1")// 查询每个最佳年月的作者的年收藏量,并按照排名进行排序spark.sql("SELECT `最佳年月`, `作者id`, SUM(`收藏人数`) AS `年收藏量`,\n" + "" +"ROW_NUMBER() OVER(PARTITION BY FLOOR(`最佳年月` / 100) ORDER BY MAX(`收藏人数`) DESC) AS `排名`\n" +"FROM ws_data1\n" + "GROUP BY `最佳年月`, `作者id`\n" + "ORDER BY `最佳年月`,`排名`").createOrReplaceTempView("foods_zly")// 提取年份、作者ID和年收藏量val zzl = spark.sql("SELECT CAST(SUBSTRING(`最佳年月`, 1, 4) AS int) AS `年份`, `作者id`, `年收藏量` FROM foods_zly")// 计算每年的总收藏人数增长趋势var trend = zzl.groupBy("`年份`").agg(sum("`年收藏量`").as("总收藏人数")).orderBy("`年份`")// 计算增长率val windowSpec1 = Window.orderBy("年份")trend = trend.withColumn("前一年收藏人数", lag("`总收藏人数`", 1).over(windowSpec1)).withColumn("增长率",round(expr("(cast(`总收藏人数` as double) / cast(`前一年收藏人数` as double)) - 1"), 2)).drop("前一年收藏人数")trend.show()trend.write.mode(SaveMode.Overwrite).jdbc(url, "foods_zzl", prop)//存储到hdfstrend.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_zzl")查看处理后的数据
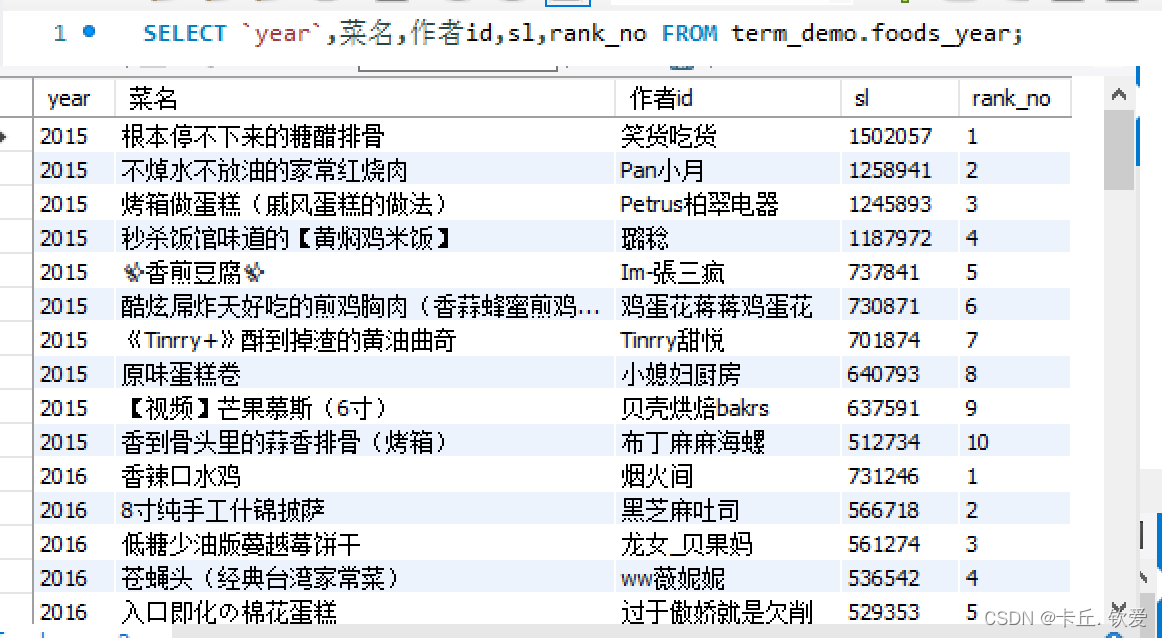
foods_year

foods_season
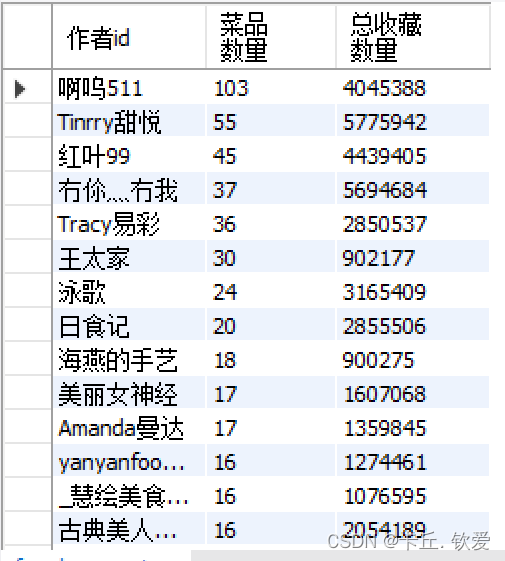
foods_num
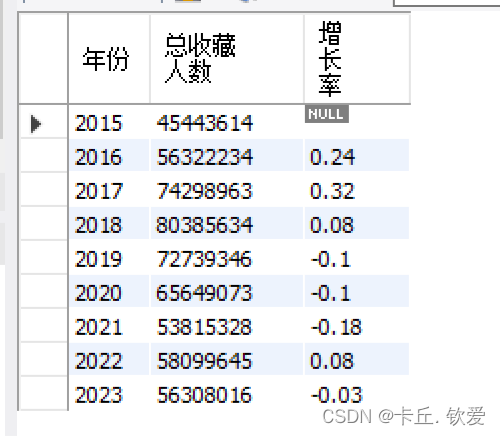
foods_zzl
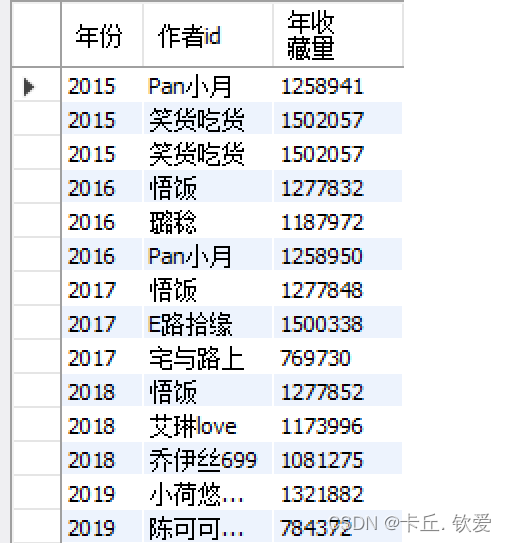
foods_nszl
数据可视化
最后是数据可视化展示,用python将Spark处理存储到数据库的数据读取,并且将其加工成所需类型后转成json格式,供后面大屏读取用,下面是部分处理代码:

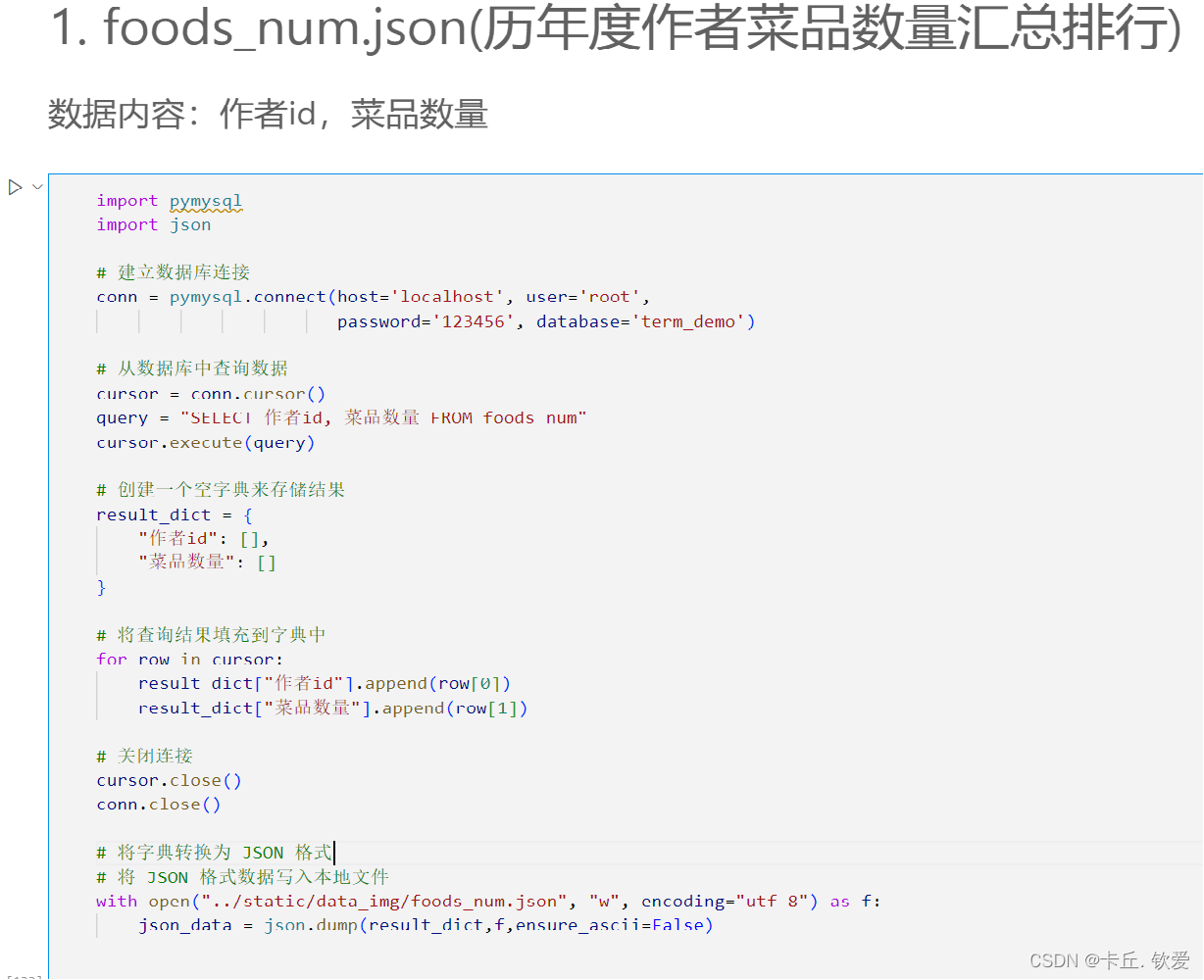
随后新建html文件,在里面添加各项依赖后,在<script>标签里面添加一下Echarts的配置项,并用Ajax技术读取刚才处理好的json文件传入给配置项后,即可在通过Flask框架在网页上渲染出数据大屏

最终大屏效果

小结
项目到这里就算是完成了,做的时候其实涉及到的技术栈还是蛮多的,虽然都不是很深,但是途中也遇到了各种各样的困难。特别是用Scala技术进行数据处理时,由于对语法的不熟悉报了很多错、还有数据库数据的格式和提取转换难点等问题。后面都一一解决了,
这次的项目让我得到了成长和提升,让我也对所学知识进行了学以致用,融会贯通。
最后感谢给我传授知识的广林哥、川哥等老师,祝你们家庭和睦,工作顺利。
相关文章:
下厨房网站月度最佳栏目菜谱数据获取及分析PLus
目录 概要 源数据获取 写Python代码爬取数据 Scala介绍与数据处理 1.Sacla介绍 2.Scala数据处理流程 数据可视化 最终大屏效果 小结 概要 本文的主题是获取下厨房网站月度最佳栏目近十年数据,最终进行数据清洗、处理后生成所需的数据库表,最终进…...
buildadmin+tp8表格操作(5)自定义组装搜索的查询
有时候我们会自定义组装一些数据,发送给后端,让后端来进行筛选,这里有一个示例 const onComSearchIdEq () > {// 展开公共搜索baTable.table.showComSearch true/*** 公共搜索表单赋值* 范围搜索有两个输入框,输入框绑定变量…...

企业级固态硬盘如何稳定运行?永铭固液混合铝电解电容来帮忙
企业级 固态硬盘 永铭固液混合铝电解电容 企业级固态硬盘(SSD)主要应用于互联网、云服务、金融和电信等客户的数据中心,企业级SSD具备更快传输速度、更大单盘容量、更高使用寿命以及更高的可靠性要求。 企业级固态硬盘的运行要求—固液混合电…...

【MISRA C 2012】Rule 4.2 不应该使用三连符
1. 规则1.1 原文1.2 分类 2. 关键描述3. 代码实例 1. 规则 1.1 原文 Rule 4.2 Trigraphs should not be used Category Advisory Analysis Decidable, Single Translation Unit Applies to C90, C99 1.2 分类 规则4.2:不应该使用三连符 Advisory建议类规范。 2…...

spring boot加mybatis puls实现,在新增/修改时,对某些字段进行处理,使用的@TableField()
1.先说场景,在对mysql数据库表数据插入或者更新时都得记录时间和用户id 传统实现有点繁琐,这里还可以封装一下公共方法。 2.解决方法: 2.1:使用aop切面编程(记录一下,有时间再攻克)。 2.2&…...
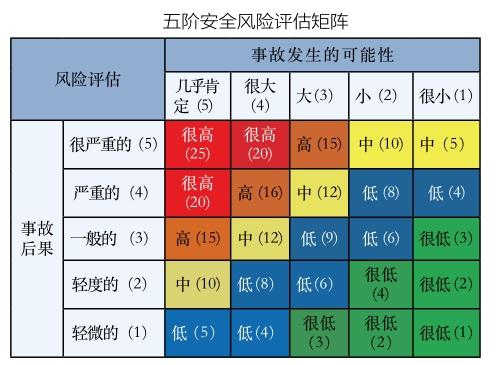
如何构建风险矩阵?3大注意事项
风险矩阵法(RMA)是确定威胁优先级别的最有效工具之一,可以帮助项目团队识别和评估项目中的风险,帮助项目团队对风险进行排序,清晰地展示风险的可能性和严重性,为项目团队制定风险管理策略提供依据。 如果没…...

SpringSecurity5|12.实现RememberMe 及 实现原理分析
security/day08 这个功能大家还熟悉么?我们在登录网站的时候,除了让你输入用户名和密码,还会有个勾选框: 记住我!!!不是让大家记住我哈。 值得一提的是,Spring Security 也提供了这个…...
持续集成交付CICD:Jenkins Sharedlibrary 共享库
目录 一、理论 1.共享库 2.共享库配置 3.使用共享库 4.共享库扩展 二、实验 1.连接共享库 2.使用共享库 三、问题 1.路径报错 2.readJSON 报错 一、理论 1.共享库 (1)概念 1)共享库这并不是一个全新的概念,其实在编…...

Linux--网络编程
一、网络编程概述1.进程间通信: 1)进程间通信的方式有**:管道,消息队列,共享内存,信号,信号量这么集中 2)特点:依赖于linux内核,基本是通过内核来实现应用层…...

数据结构 并查集
作用 快速的处理以下问题:【近乎O(1)的时间完成】 1.将两个集合合并 2.询问两个元素是否在一个集合中 用树的形式维护集合 基本原理 每一个集合用一棵树表示 每一个集合的编号就是根结点的编号,对于每一个结点,都存储其父结点…...
)
算法通关村第十六关黄金挑战——求滑动窗口中的最大值(滑动窗口与堆方法、双端队列法和直接比较法)
大家好,我是怒码少年小码。 今天这篇就讲一道题目,不难😎,但是一定要学会自己思考。 滑动窗口最大值 LeetCode 239:给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。…...

常见树种(贵州省):009楠木、樟木、桂木种类
摘要:本专栏树种介绍图片来源于PPBC中国植物图像库(下附网址),本文整理仅做交流学习使用,同时便于查找,如有侵权请联系删除。 图片网址:PPBC中国植物图像库——最大的植物分类图片库 一、楠木 …...
全志H616开发版
开发板介绍: 二、开发板刷机 SDFormatter TF卡的格式化工具、Win32Diskimager 刷机工具 刷机镜像为:Orangepizero2_2.2.0_ubuntu_bionic_desktop_linux4.9.170.img 使用MobaXterm_Personal_20.3连接使用 网络配置:nmcli dev wifi 命令接入网…...
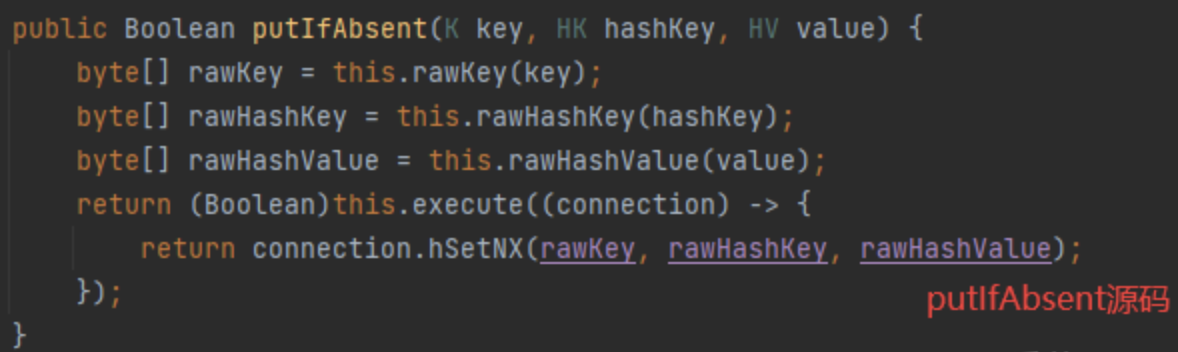
【Spring boot】RedisTemplate中String、Hash、List设置过期时间
文章目录 前言Redis中String设置时间的方法Redis中Hash和List设置时间的方法Redis中Hash的put、putAll、putIfAbsent区别 前言 时间类型:TimeUnit import java.util.concurrent.TimeUnit;TimeUnit.SECONDS:秒 TimeUnit.MINUTES:分 TimeUnit.HOURS&…...
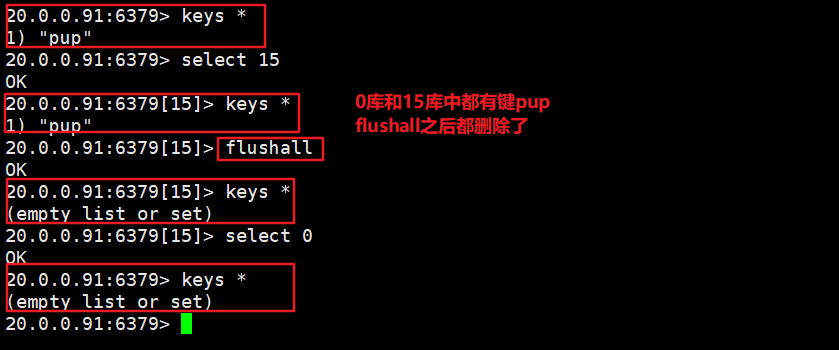
Nosql之redis概述及基本操作
关系数据库与非关系型数据库概述 关系型数据库 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。SQL语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型…...

使ros1和ros2的bag一直互通
很多文章都是先source ros1 然后source ros2,再play bag source /opt/ros/noetic/setup.bash source /opt/ros/foxy/setup.bash ros2 bag play -s rosbag_v2 kitti_raw00.bag 但实测会出问题: 为使ros1和ros2的bag一直互通 sudo apt update sudo apt install ros-foxy-ro…...

【正点原子 linux 驱动编程】
在此声明,正用点编的说明书真的拉,丝毫不具备兼容性。。比如linux的第一个实验,其中包含的 unregister_chrdev_region 函数,fileoperation 结构体等均来自 <linux/fs.h> 文件,搞不懂,他们方ide.h&…...

使用Python的turtle模块绘制玫瑰花图案(含详细Python代码与注释)
1.1引言 turtle模块是Python的标准库之一,它提供了一个绘图板,让我们可以在屏幕上绘制各种图形。通过使用turtle,我们可以创建花朵、叶子、复杂的图案等等。本博客将介绍如何使用turtle模块实现绘制图形的过程,并展示最终结果。 …...

Redis学习笔记14:基于spring data redis及lua脚本ZSET有序集合实现环形结构案例及lua脚本如何发送到redis服务器
案例实现目标,一、实现一个环形结构,环形结构上节点有一个阀值threshold,超过阀值则移除分数score最低的成员,不足则将当前成员添加进环中,且确保成员不可重复;二、每次访问环中的数据都需要刷新key的过期时间…...

openssl C++研发之pem格式处理详解
一、PEM_writeXXX和EM_write_bio_XXX 在OpenSSL的crypto/pem.h头文件中,PEM_write_XXXX和PEM_write_bio_XXXX系列函数用于将特定类型的数据写入文件或BIO(内存缓冲区)中,其中XXXX代表不同的数据类型。 这些函数的使用方式相似&a…...

Claw Mentor:为OpenClaw智能体实现自动化配置同步与社区化演进
1. 项目概述:为你的AI智能体引入“导师”机制在AI智能体(Agent)开发领域,尤其是基于OpenClaw这类开源框架时,我们常常面临一个困境:如何持续地学习和迭代,跟上领域内最佳实践的发展速度…...

2026届学术党必备的六大降重复率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 减小AIGC率的关键之处在于使文本的统计规律性以及模式化特性得以弱化。首先,别去…...

Taotoken用量看板如何帮助开发者清晰掌握消费明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助开发者清晰掌握消费明细 对于使用大模型API的开发者而言,成本控制与预算管理是项目持续运营的…...
——深入分析Ring AllReduce算法与带宽最优性)
训练篇第5节:NCCL(二)——深入分析Ring AllReduce算法与带宽最优性
理解Ring AllReduce,你就掌握了数据并行分布式训练的通信命脉 前言 上一节我们学习了分布式训练的三种并行策略,其中数据并行最核心的通信原语就是AllReduce。在深入篇中,我们简单介绍了NCCL和AllReduce,但那一节更侧重API使用。今天,我们将深入Ring AllReduce算法的内部…...

BLheli电调硬件避坑指南:搞懂MOS驱动逻辑,别让固件和电路“打架”
BLheli电调硬件设计深度解析:从MOS驱动逻辑到实战排错 在无刷电机控制领域,BLheli固件因其出色的性能和开源特性成为众多开发者的首选。但当你兴奋地将精心设计的硬件与下载的固件结合时,电机却纹丝不动,甚至冒出缕缕青烟——这种…...

GM 卖司机数据被罚,汽车越来越像一个会移动的数据采集器
你以为车是你买的,结果你的驾驶数据也被卖了 我现在对“智能汽车”这四个字,越来越没什么浪漫想象了。 以前听到智能汽车,脑子里是自动驾驶、大屏幕、语音助手、座椅按摩、车机生态。听起来挺高级,像是未来生活终于愿意照顾一下普通人。 现在再看,未来是来了。 只不过…...

[具身智能-631]:获取音频输入的代码示例
树莓派 4B/5、RK3568/RK3588 音频输入代码示例统一用 Python pyaudio wave,适配:USB 麦克风、I2S 麦克风、板载音频输入,一套代码通用。一、先装依赖bash运行sudo apt update sudo apt install portaudio19-dev python3-pip pip3 install p…...

如何用嘎嘎降AI处理法学论文:案例引用密集的法学毕业论文降AI完整操作教程
如何用嘎嘎降AI处理法学论文:案例引用密集的法学毕业论文降AI完整操作教程 关于法学论文降AI教程,有几个细节提前知道,能少走很多弯路。 核心用嘎嘎降AI(www.aigcleaner.com),4.8元,达标率99.…...
)
从Gazebo仿真到真机部署:一文搞懂MoveIt的ros_control控制器配置核心(以六轴机械臂为例)
从仿真到现实:MoveIt与ros_control的机械臂控制实战指南 当你在Gazebo中看着机械臂流畅地完成抓取动作时,是否想过这些算法如何真正控制实体电机转动?仿真环境中的完美轨迹规划,在真实硬件上可能面临电机响应延迟、关节抖动甚至失…...

Keil MDK编译89C51老项目,遇到error C132报错别慌,先检查这个分号
Keil MDK编译89C51老项目遇到error C132报错的系统排查指南 当你在维护一个尘封多年的89C51项目时,Keil MDK突然抛出一连串error C132和C244错误,那种感觉就像打开一个老式收音机却只听到刺耳的杂音。但别急着重写整个项目——根据我的经验,…...