深度学习之生成唐诗案例(Pytorch版)
主要思路:
对于唐诗生成来说,我们定义一个"S" 和 "E"作为开始和结束。

示例的唐诗大概有40000多首,
首先数据预处理,将唐诗加载到内存,生成对应的word2idx、idx2word、以及唐诗按顺序的字序列。
Dataset_Dataloader.py
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoaderdef deal_tangshi():with open("poems.txt", "r", encoding="utf-8") as fr:lines = fr.read().strip().split("\n")tangshis = []for line in lines:splits = line.split(":")if len(splits) != 2:continuetangshis.append("S" + splits[1] + "E")word2idx = {"S": 0, "E": 1}word2idx_count = 2tangshi_ids = []for tangshi in tangshis:for word in tangshi:if word not in word2idx:word2idx[word] = word2idx_countword2idx_count += 1idx2word = {idx: w for w, idx in word2idx.items()}for tangshi in tangshis:tangshi_ids.extend([word2idx[w] for w in tangshi])return word2idx, idx2word, tangshis, word2idx_count, tangshi_idsword2idx, idx2word, tangshis, word2idx_count, tangshi_ids = deal_tangshi()class TangShiDataset(Dataset):def __init__(self, tangshi_ids, num_chars):# 语料数据self.tangshi_ids = tangshi_ids# 语料长度self.num_chars = num_chars# 词的数量self.word_count = len(self.tangshi_ids)# 句子数量self.number = self.word_count // self.num_charsdef __len__(self):return self.numberdef __getitem__(self, idx):# 修正索引值到: [0, self.word_count - 1]start = min(max(idx, 0), self.word_count - self.num_chars - 2)x = self.tangshi_ids[start: start + self.num_chars]y = self.tangshi_ids[start + 1: start + 1 + self.num_chars]return torch.tensor(x), torch.tensor(y)def __test_Dataset():dataset = TangShiDataset(tangshi_ids, 8)x, y = dataset[0]print(x, y)if __name__ == '__main__':# deal_tangshi()__test_Dataset()
TangShiModel.py:唐诗的模型
import torch
import torch.nn as nn
from Dataset_Dataloader import *
import torch.nn.functional as Fclass TangShiRNN(nn.Module):def __init__(self, vocab_size):super().__init__()# 初始化词嵌入层self.ebd = nn.Embedding(vocab_size, 128)# 循环网络层self.rnn = nn.RNN(128, 128, 1)# 输出层self.out = nn.Linear(128, vocab_size)def forward(self, inputs, hidden):embed = self.ebd(inputs)# 正则化层embed = F.dropout(embed, p=0.2)output, hidden = self.rnn(embed.transpose(0, 1), hidden)# 正则化层embed = F.dropout(output, p=0.2)output = self.out(output.squeeze())return output, hiddendef init_hidden(self):return torch.zeros(1, 64, 128)main.py:
import timeimport torchfrom Dataset_Dataloader import *
from TangShiModel import *
import torch.optim as optim
from tqdm import tqdmdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")def train():dataset = TangShiDataset(tangshi_ids, 128)epochs = 100model = TangShiRNN(word2idx_count).to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=1e-3)for idx in range(epochs):dataloader = DataLoader(dataset, batch_size=64, shuffle=True, drop_last=True)start_time = time.time()total_loss = 0total_num = 0total_correct = 0total_correct_num = 0hidden = model.init_hidden()for x, y in tqdm(dataloader):x = x.to(device)y = y.to(device)# 隐藏状态hidden = model.init_hidden()hidden = hidden.to(device)# 模型计算output, hidden = model(x, hidden)# print(output.shape)# print(y.shape)# 计算损失loss = criterion(output.permute(1, 2, 0), y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()total_loss += loss.sum().item()total_num += len(y)total_correct_num += y.shape[0] * y.shape[1]# print(output.shape)total_correct += (torch.argmax(output.permute(1, 0, 2), dim=-1) == y).sum().item()print("epoch : %d average_loss : %.3f average_correct : %.3f use_time : %ds" %(idx + 1, total_loss / total_num, total_correct / total_correct_num, time.time() - start_time))torch.save(model.state_dict(), f"./modules/tangshi_module_{idx + 1}.bin")if __name__ == '__main__':train()
predict.py:
import torch
import torch.nn as nn
from Dataset_Dataloader import *
from TangShiModel import *device = torch.device("cuda" if torch.cuda.is_available() else "cpu")def predict():model = TangShiRNN(word2idx_count)model.load_state_dict(torch.load("./modules/tangshi_module_100.bin", map_location=torch.device('cpu')))model.eval()hidden = torch.zeros(1, 1, 128)start_word = input("输入第一个字:")flag = Nonetangshi_strs = []while True:if not flag:outputs, hidden = model(torch.tensor([[word2idx["S"]]], dtype=torch.long), hidden)tangshi_strs.append("S")flag = Trueelse:tangshi_strs.append(start_word)outputs, hidden = model(torch.tensor([[word2idx[start_word]]], dtype=torch.long), hidden)top_i = torch.argmax(outputs, dim=-1)if top_i.item() == word2idx["E"]:breakprint(top_i)start_word = idx2word[top_i.item()]print(tangshi_strs)if __name__ == '__main__':predict()
完整代码如下:
https://github.com/STZZ-1992/tangshi-generator.git![]() https://github.com/STZZ-1992/tangshi-generator.git
https://github.com/STZZ-1992/tangshi-generator.git
相关文章:
深度学习之生成唐诗案例(Pytorch版)
主要思路: 对于唐诗生成来说,我们定义一个"S" 和 "E"作为开始和结束。 示例的唐诗大概有40000多首, 首先数据预处理,将唐诗加载到内存,生成对应的word2idx、idx2word、以及唐诗按顺序的字序列。…...
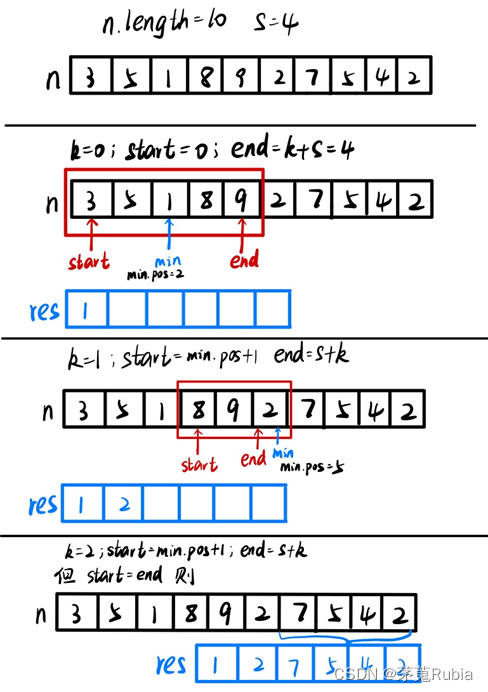
算法设计与分析算法实现——删数问题
通过棋盘输入一个高精度的正整数n(n的有效位数<=240)去掉其中任意s个数字后,剩下的数字按原左右次序将组成一个新的正整数。变成对给定的n和s,寻找一种方案,使得剩下的数字组成的新数最小。 输入:n,s 输出:最后剩下的最小数 输入实例: 178543 4 输出示例: 13 首先…...

基于Vue+SpringBoot的超市账单管理系统 开源项目
项目编号: S 032 ,文末获取源码。 \color{red}{项目编号:S032,文末获取源码。} 项目编号:S032,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统设计3.1 总体设计3.2 前端设计3…...

【Linux 内核分析课程作业 1】mmap 实现一个 key-valueMap
作业一 功能要求利用 mmap(虚拟内存映射文件) 机制实现一个带持久化能力的 key-valueMap 系统,至少支持单机单进程访问。(可能用到的 linux API: mmap、msync、mremap、munmap、ftruncate、fallocate 等) 电子版提交方式: 2023 年 11 月 20 日 18:00 前通…...
)
docker compose使用教程(docker-compose教程)
文章目录 Docker Compose 使用教程安装Docker ComposeLinuxWindows 和 macOS Docker Compose 基础Compose 文件结构配置服务网络与卷 Docker Compose 命令启动服务停止服务查看服务状态查看日志缩放服务 多环境部署健康检查与依赖管理Docker Compose 最佳实践常见问题解析如何覆…...

印刷企业实施MES管理系统需要哪些硬件设施
随着科技的飞速发展,印刷行业正面临着前所未有的挑战和机遇。为了提高生产效率,降低成本,并增强市场竞争力,越来越多的印刷企业开始实施制造执行系统(MES)管理系统。本文将重点讨论印刷企业在实施MES管理系…...

Java JSON字符串替换其中对应的值
代码: public static void main(String[] args) { // String theData crmScene.getData();String theData "[{\"type\":1,\"values\":[\"审批中\",\"未交付\"],\"name\":\"status\"}]"…...

Android VSYNC发展历程
0 前言 安卓直到android-4.1.1_r1才首次引入VSYNC实现,然后逐步演进到android-4.4才得以完善,并在android-11、12后继续大改。 1 尚未引入 android-4.0.4_r2.1之前尚未引入VSYNC[1],SurfaceFlinger被实现为一个线程,通过睡眠来实…...

外呼系统作用和优势有哪些okcc,ai源码
随着外呼系统诞生,普通中小企业也开始广泛使用,系统给他们带来更多的服务方式和提升业绩的可能。然而,许多企业对外呼系统的理解相对片面和简单,认为它是一个成本中心,需要继续投入人力和使用。事实上,外呼…...

智元机器人岗位内推
Hi there 👋 智元机器人招聘信息 官网: https://www.agibot.com/ 内推联系 邮箱:jiejietopgmail.com微信:yij1799 高级C软件工程师(上海) 岗位职责: 开发自研机器人操作系统,…...
)
el-popover和el-tooltip样式修改(普通的组件样式修改方法,对popover是不生效的)
第一步:‘popper-class’=‘popperClass’ //添加类名 <el-table-column label="审核状态" align="center"><template slot-scope="scope"><el-popoverpopper-class="addformPanel"placement="top"width=&…...
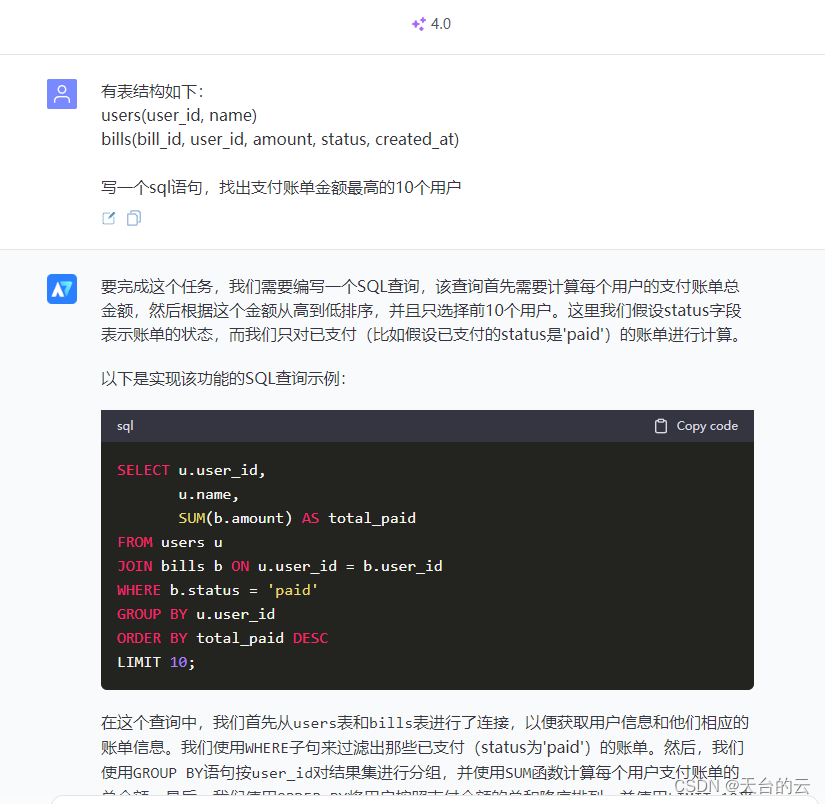
【AI实用技巧】GPT写sql统计语句
编写sql的统计语句是一项复杂的任务,特别是涉及多表的情况下。但有了GPT的帮助,一切变得轻松愉快。 AI7号 - 最强人工智能(GPT)中文版https://ai7.pro/s/9v2um 举例说明 有表结构如下: users(user_id, name) bills(…...
LeetCode(31)无重复字符的最长子串【滑动窗口】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 无重复字符的最长子串 1.题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc"&…...
天猫超市电商营销系统:无代码开发实现API连接集成
无代码开发实现天猫超市与电商系统的高效连接 天猫超市,作为天猫推出的网络零售超市,为广大网购消费者提供了一站式的购物服务。而通过无代码开发的方式,天猫超市能够实现与各种电商系统的连接和集成,这种方式无需进行繁琐的API开…...
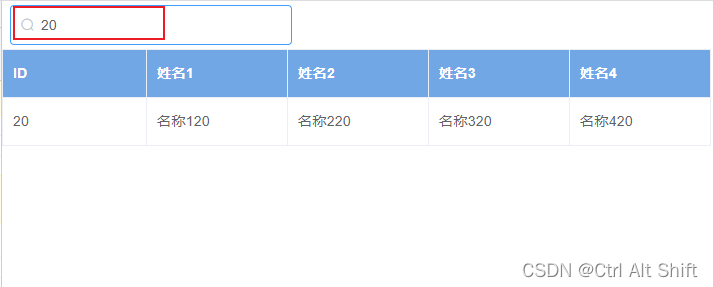
element表格分页+数据过滤筛选
目录 前言效果展示分页效果展示搜索效果展示 代码分析分页功能过滤数据功能 全部代码 前言 在el-element的标签里的tableData数据过多时,会导致表格页面操作卡顿。为解决这一问题,有以下解决方法: 分页加载: 将大量数据进行分页&…...

小程序判断是否授权位置信息和手动授权
文章目录 概要微信小程序的,使用的是高德地图 概要 当用户来到页面之后就会弹出是否授权弹框,但是如果第一次关闭之后,下一次再过来的话页面的授权弹框就不出现了,针对于这种情况写了一个方法 微信小程序的,使用的是…...

2023年亚太杯数学建模亚太赛A题思路解析+代码+论文
下文包含:2023年亚太杯数学建模亚太赛A题思路解析代码参考论文等及如何准备数学建模竞赛(23号比赛开始后逐步更新) C君将会第一时间发布选题建议、所有题目的思路解析、相关代码、参考文献、参考论文等多项资料,帮助大家取得好成…...

【Android】画面卡顿优化列表流畅度六(终篇)
上一篇: 【Android】画面卡顿优化列表流畅度五之下拉刷新上拉加载更多组件RefreshLayout修改 场景回顾: 业务经过一年半左右的运行后,出现了明显的列表卡顿情况;于是开始着手进行列表卡顿优化。目前的情况是: 网络图…...
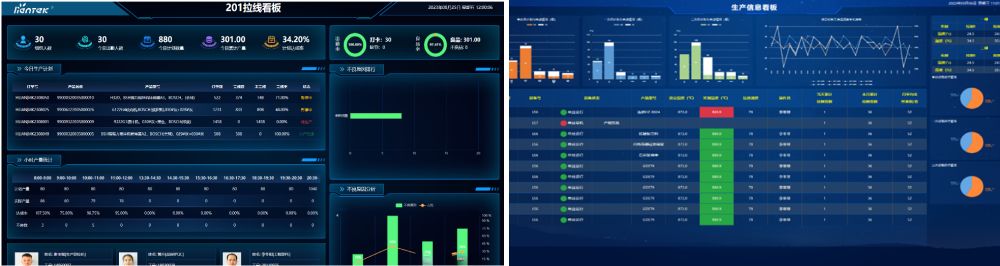
一文了解:离散型制造业轻量化MES解决方案
离散型制造业的特点 离散型生产行业主要是通过对原材料物理形状的改变、组装,成为产品,使其增值。典型的离散型行业包括:机械、电子、航空、汽车等行业。这些企业既有按订单生产(MTO),也有按照库存生产&am…...

《云计算:云端协同,智慧互联》
《云计算:云端协同,智慧互联》 云计算,这个科技领域中的热门词汇,正在逐渐改变我们的生活方式。它像一座座无形的桥梁,将世界各地的设备、数据、应用紧密连接在一起,实现了云端协同,智慧互联的愿…...

从‘虚方法表’到性能优化:深入.NET运行时看C# virtual关键字的设计哲学
从‘虚方法表’到性能优化:深入.NET运行时看C# virtual关键字的设计哲学 在C#开发中,virtual关键字看似简单,却承载着面向对象编程中多态性的核心实现。当我们在基类中标记一个方法为virtual时,实际上是在向.NET运行时声明&#…...
)
告别多个客户端!用DBeaver企业版一站式管理Hive、Impala、Redis等5种数据源(附驱动下载与配置避坑)
数据工程师的效率革命:DBeaver企业版全栈数据源管理实战指南 在数据驱动的时代,工程师们每天需要面对的是散落在不同平台、不同协议下的数据孤岛。从传统的关系型数据库到新兴的NoSQL存储,从大数据分析引擎到内存数据库,每种数据源…...

Ubuntu 服务器运维如何利用 Taotoken 实现大模型 API 的容灾与成本控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu 服务器运维如何利用 Taotoken 实现大模型 API 的容灾与成本控制 对于在 Ubuntu 生产服务器上集成 AI 功能的运维工程师而言…...

告别手动抠图:layerdivider智能图像分层工具完整指南
告别手动抠图:layerdivider智能图像分层工具完整指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经花费数小时在Photoshop中手动…...

深度解析B站视频下载器:技术架构与实战应用指南
深度解析B站视频下载器:技术架构与实战应用指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 在数字内容消费日益增长的…...

从一次失败的MS08-067攻击说起:深入理解Metasploit中Exploit、Payload与Session的协作机制
从一次失败的MS08-067攻击说起:深入理解Metasploit中Exploit、Payload与Session的协作机制 当你看到控制台输出"Exploit completed, but no session was created"时,是否曾感到困惑?这就像成功打开了保险箱却发现里面空空如也。本文…...

FreeRTOS项目踩坑实录:我的低功耗设计是如何被‘空闲任务’和‘Tickless模式’拯救的
FreeRTOS低功耗实战:从STOP模式异常到Tickless模式优化 记得第一次在STM32上尝试FreeRTOS低功耗设计时,我信心满满地启用了STOP模式,结果设备唤醒后直接卡死。屏幕上的日志仿佛在嘲笑我的无知——原来RTOS的低功耗远不是简单调用HAL_PWR_Ente…...

douyin-downloader抖音下载器:5大核心功能解密与实战指南
douyin-downloader抖音下载器:5大核心功能解密与实战指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

STM32新手避坑指南:正点原子、野火、慧净、小马飞控的Systick延时函数到底差在哪?
STM32开发板Systick延时函数深度对比:从原理到避坑实战 第一次接触STM32开发时,我对着四块不同品牌的开发板愣了半天——正点原子、野火、慧净、小马飞控,每家的例程里Systick延时函数实现都不一样。有的用72MHz时钟,有的用9MHz&a…...

8大网盘直链下载助手:开源工具如何彻底改变你的文件下载体验?
8大网盘直链下载助手:开源工具如何彻底改变你的文件下载体验? 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中…...