计算机基础知识54
ORM的介绍
# ORM是什么?
我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(增、删、改、查),而一旦谈到数据的管理操作,就需要用到数据库管理软件,例如mysql、oracle、Microsoft SQL Server等。
# ORM的概念:
ORM全称Object Relational Mapping,即对象关系映射,是在pymysq之上又进行了一层封装,对于数据的操作,我们无需再去编写原生sql,取代代之的是基于面向对象的思想去编写类、对象、调用相应的方法等,ORM会将其转换/映射成原生SQL然后交给pymysql执行

ORM的使用之数据库迁移
1、创建模型:数据来源于数据库的表,而ORM的模型类对应数据库表
# 创建django项目,新建名为app01的app,在app01的models.py中创建模型 class Employee(models.Model): # 必须是models.Model的子类id=models.AutoField(primary_key=True)name=models.CharField(max_length=16)gender=models.BooleanField(default=1)birth=models.DateField()department=models.CharField(max_length=30)salary=models.DecimalField(max_digits=10,decimal_places=1)2、 配置settings.py
INSTALLED_APPS = ['django.contrib.admin','django.contrib.auth','django.contrib.contenttypes','django.contrib.sessions','django.contrib.messages','django.contrib.staticfiles', 'app01.apps.App01Config', # django2.x+版本 # 'app01', # django1.x版本]DATABASES = { # 删除\注释掉原来的DATABASES配置项,新增下述配置'default': {'ENGINE': 'django.db.backends.mysql', # 使用mysql数据库'NAME': 'db1', # 要连接的数据库'USER': 'root', # 链接数据库的用于名'PASSWORD': '', # 链接数据库的用于名 'HOST': '127.0.0.1', # mysql服务监听的ip 'PORT': 3306, # mysql服务监听的端口 'ATOMIC_REQUEST': True, #设置为True代表同一个http请求所对应的所有sql都放在一个事务中3.配置日志:如果想打印orm转换过程中的sql,需要在settings中进行配置日志
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console':{'level':'DEBUG','class':'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level':'DEBUG',},} }4、数据库迁移命令
python manage.py makemigrations python manage.py migrate
模型层models:表查询
模型层的表查询:跟数据库打交道的
1、单表查询:
insert update delete all filter
2、常见的查询方法:
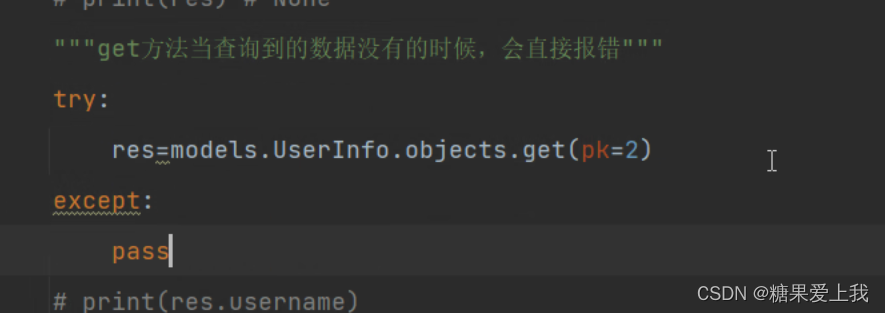
单表操作: 1、all() 查询所有数据,索引取值 2、filter() 过滤条件查询 3、get() 查询数据,查询数据为空的情况直接报错 4、last() 取所有数据的最后一条 5、values( id,username,password ) 取值,列表套字典[{'id':1,'username':...},{...}] 6、vallues_list() 取值,列表套元组,都支持for循环 7、pring(res.quert) 查看内部的SQL语句,只有防御的结果是queryset对象的时候才能查看 8、distinct() 去重 9、order_by( 'id' ) 默认情况升序排序;('-id')倒序 10、reverse() 翻转 11、count() 统计当前表中数据的个数 12、exclude(pk=1) 排除在外 13、exists() 看数据到底有没有
3、基于双下划线的查询:
res = models.UserInfo.object.filter(age_gt=38).all() age__gt=1---大于 age__lt=1---小于 age__gte=1---大于等于 age__lte=1---小于等于 ageage__in=[18,40] 年龄在十八或40的,或 age__range=[18,40] 年龄在十八到40的,之间# 包含s的数据,模糊查询:
包含s的数据,模糊查询:# select * from userinfor where name like '%s%',res = models.UserInfo.object.filter(username__contains='s').all()print(res)print(res.query) username__icontains--忽略大小写 username__startswith=='o'--以o开头的 username__endswith=='o'--以o结尾的# 日期查询:
register_time = models.DateTimeField(auto_now=True,auto_now_add=True,null=True) auto_now: 修改的时间 auto_now_add: 刚加进去时间 查询时间:查2020年1月份的 filter(register_time__year='2020',register_time__month='01).all()
多表查询(跨表查询)
子查询:分步查询
链表查询:把多个有关系的表拼接成一个大表(虚拟表)
inner join
left join
right join
基于双下划线的查询
年龄大于35岁的数据:
res = models.User.objects.filter(age__gt=35)
年龄小于35岁的数据:
res = models.User.objects.filter(age__lt=35)
大于等于 小于等于:
res = models.User.objects.filter(age__gte=32)
res = models.User.objects.filter(age__lte=32)
年龄是18 或者 32 或者40:
res = models.User.objects.filter(age__in=[18,32,40])
年龄在18到40岁之间的 首尾都要:
res = models.User.objects.filter(age__range=[18,40])
查询出名字里面含有s的数据 模糊查询:
res = models.User.objects.filter(name__contains='s')
是否区分大小写 查询出名字里面含有p的数据 区分大小写:
res = models.User.objects.filter(name__contains='p')
忽略大小写:
res = models.User.objects.filter(name__icontains='p')
以 'j' 开头或以 'j' 结尾:
res = models.User.objects.filter(name__startswith='j')
res1 = models.User.objects.filter(name__endswith='j')查询出注册时间是 2020 1月:
res = models.User.objects.filter(register_time__month='1')
res = models.User.objects.filter(register_time__year='2020')
多表查询前期表准备
class Book(models.Model):title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8,decimal_places=2)publish_date = models.DateField(auto_now_add=True)# 一对多publish = models.ForeignKey(to='Publish')# 多对多authors = models.ManyToManyField(to='Author')class Publish(models.Model):name = models.CharField(max_length=32)addr = models.CharField(max_length=64)# varchar(254) 该字段类型不是给models看的 而是给后面我们会学到的校验性组件看的def __str__(self):return self.nameclass Author(models.Model):name = models.CharField(max_length=32)age = models.IntegerField()# 一对一author_detail = models.OneToOneField(to='AuthorDetail')class AuthorDetail(models.Model):phone = models.BigIntegerField() # 电话号码用BigIntegerField或者直接用CharFieldaddr = models.CharField(max_length=64)
一对多外键增删改查
# 增:
方式一:直接写实际字段 id models.Book.objects.create(title='论语',price=899.23,publish_id=1) models.Book.objects.create(title='聊斋',price=444.23,publish_id=2) models.Book.objects.create(title='老子',price=333.66,publish_id=1) 方式二:虚拟字段 对象 publish_obj = models.Publish.objects.filter(pk=2).first() models.Book.objects.create(title='红楼梦',price=666.23,publish=publish_obj)# 删: models.Publish.objects.filter(pk=1).delete() # 级联删除
# 修改
models.Book.objects.filter(pk=1).update(publish_id=2) publish_obj = models.Publish.objects.filter(pk=1).first() models.Book.objects.filter(pk=1).update(publish=publish_obj)
多对多外键增删改查
# 增,给书籍添加作者:
book_obj = models.Book.objects.filter(pk=1).first() print(book_obj.authors) # 就类似于你已经到了第三张关系表了 book_obj.authors.add(1) # 书籍id为1的书籍绑定一个主键为1 的作者 book_obj.authors.add(2,3)author_obj = models.Author.objects.filter(pk=1).first() author_obj1 = models.Author.objects.filter(pk=2).first() author_obj2 = models.Author.objects.filter(pk=3).first() book_obj.authors.add(author_obj) """add给第三张关系表添加数据,括号内既可以传数字也可以传对象 并且都支持多个"""# 删:
book_obj.authors.remove(2) book_obj.authors.remove(1,3)author_obj = models.Author.objects.filter(pk=2).first() author_obj1 = models.Author.objects.filter(pk=3).first() book_obj.authors.remove(author_obj,author_obj1) """remove,括号内既可以传数字也可以传对象 并且都支持多个"""# 修改:
book_obj.authors.set([1,2]) # 括号内必须给一个可迭代对象 book_obj.authors.set([3]) # 括号内必须给一个可迭代对象author_obj = models.Author.objects.filter(pk=2).first() author_obj1 = models.Author.objects.filter(pk=3).first() book_obj.authors.set([author_obj,author_obj1]) # 括号内必须给一个可迭代对象# 清空,在第三张关系表中清空某个书籍与作者的绑定关系
book_obj.authors.clear()
clear括号内不要加任何参数
正反向的概念
正向:外键字段在我手上那么,我查你就是正向,按 外键字段
反向:外键字段如果不在手上,我查你就是反向,按 表名小写
book >>>外键字段在书那儿(正向)>>> publish
publish >>>外键字段在书那儿(反向)>>>book
_set
多表查询之子查询
子查询---基于对象的跨表查询
1.查询书籍主键为1的出版社:
book_obj = models.Book.objects.filter(pk=1).first() # 书查出版社 正向 res = book_obj.publish print(res) print(res.name) print(res.addr)2.查询书籍主键为2的作者:
book_obj = models.Book.objects.filter(pk=2).first() # 书查作者 正向 res = book_obj.authors # app01.Author.None res = book_obj.authors.all() # 查的多的话要用all() print(res)3.查询作者jason的电话号码:
author_obj = models.Author.objects.filter(name='jason').first() res = author_obj.author_detail print(res) print(res.phone) print(res.addr)4.查询出版社是东方出版社出版的书:
publish_obj = models.Publish.objects.filter(name='东方出版社').first() # 出版社查书 反向 res = publish_obj.book_set # app01.Book.None res = publish_obj.book_set.all() print(res)5.查询作者是jason写过的书:
author_obj = models.Author.objects.filter(name='jason').first() # 作者查书 反向 res = author_obj.book_set # app01.Book.None res = author_obj.book_set.all() print(res)6.查询手机号是110的作者姓名:
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first() res = author_detail_obj.author print(res.name)# 如果是一个则直接拿到数据对象
book_obj.publish
book_obj.authors.all()
author_obj.author_detail# 在书写orm语句的时候跟写sql语句一样的,不要企图一次性将orm语句写完 如果比较复杂 就写一点看一点
# 基于对象 : 反向查询的时候
当你的查询结果可以有多个的时候 就必须加_set.all()
当你的结果只有一个的时候 不需要加_set.all()
多表查询之联表查询
联表查询---基于双下划线的跨表查询
1.查询jason的手机号和作者姓名:
res = models.Author.objects.filter(name='jason').values('author_detail__phone','name') print(res) # 反向 res = models.AuthorDetail.objects.filter(author__name='jason') # 拿作者姓名是jason的作者详情 res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','author__name') print(res)2.查询书籍主键为1的出版社名称和书的名称:
res = models.Book.objects.filter(pk=1).values('title','publish__name') print(res) # 反向 res = models.Publish.objects.filter(book__id=1).values('name','book__title') print(res)3.查询书籍主键为1的作者姓名:
res = models.Book.objects.filter(pk=1).values('authors__name') print(res) # 反向 res = models.Author.objects.filter(book__id=1).values('name') print(res)4.查询书籍主键是1的作者的手机号:
book author authordetail res = models.Book.objects.filter(pk=1).values('authors__author_detail__phone') print(res)# 你只要掌握了正反向的概念以及双下划线,那么你就可以无限制的跨表
多表查询之分组查询
select age from t group by age; """MySQL分组查询都有哪些特点分组之后默认只能获取到分组的依据 组内其他字段都无法直接获取了严格模式ONLY_FULL_GROUP_BYset global sql_mode='ONLY_FULL_GROUP_BY' """# 你们的机器上如果出现分组查询报错的情况,你需要修改数据库严格模式
# 分组查询 annotate
from django.db.models import Max, Min, Sum, Count, Avg
1.统计每一本书的作者个数:
res = models.Book.objects.annotate() # models后面点什么 就是按什么分组 res = models.Book.objects.annotate(author_num=Count('authors')).values('title','author_num') res1 = models.Book.objects.annotate(author_num=Count('authors__id')).values('title','author_num') print(res,res1) """author_num是我们自己定义的字段 用来存储统计出来的每本书对应的作者个数"""2.统计每个出版社卖的最便宜的书的价格:
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price') print(res)3.统计不止一个作者的图书:
# 先按照图书分组 求每一本书对应的作者个数
# 过滤出不止一个作者的图书res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title','author_num') print(res)4.查询每个作者出的书的总价格:
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price') print(res)# 代码没有补全 不要怕,正常写,补全给你是pycharm给你的,到后面在服务器上直接书写代码,什么补全都没有,颜色提示也没有
# 只要你的orm语句得出的结果还是一个queryset对象,那么它就可以继续无限制的点queryset对象封装的方法
F查询
F查询:能够帮助你直接获取到表中某个字段对应的数据
1.查询卖出数大于库存数的书籍:
from django.db.models import F res = models.Book.objects.filter(maichu__gt=F('kucun')) print(res)2.将所有书籍的价格提升500块:
models.Book.objects.update(price=F('price') + 500)3.将所有书的名称后面加上爆款两个字:
from django.db.models.functions import Concat #拼接字符串 from django.db.models import Value models.Book.objects.update(title=Concat(F('title'), Value('爆款'))) # models.Book.objects.update(title=F('title') + '爆款') # 所有的名称会全部变成空白 """在操作字符类型的数据的时候 F不能够直接做到字符串的拼接"""
Q查询
1.查询卖出数大于100或者价格小于600的书籍:
res = models.Book.objects.filter(maichu__gt=100,price__lt=600) """filter括号内多个参数是and关系""" from django.db.models import Q # res = models.Book.objects.filter(Q(maichu__gt=100),Q(price__lt=600)) #Q逗号分割还是and关系 res = models.Book.objects.filter(Q(maichu__gt=100)|Q(price__lt=600)) # | or关系 # res = models.Book.objects.filter(~Q(maichu__gt=100)|Q(price__lt=600)) # ~ not关系 print(res) # <QuerySet []>2、Q的高阶用法 能够将查询条件的左边也变成字符串的形式
q = Q() q.connector = 'or' q.children.append(('maichu__gt',100)) q.children.append(('price__lt',600)) res = models.Book.objects.filter(q) # 默认还是and关系 print(res)
查看内部sql语句的方式
方式1:queryset对象才能够点击query查看内部的sql语句
res = models.User.objects.values_list('name','age') # <QuerySet [('jason', 18), ('egonPPP', 84)]> print(res.query)方式2:所有的sql语句都能查看
# uptade等等没有queryset对象的只需设置配置文件setting
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console':{'level':'DEBUG','class':'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level':'DEBUG',},} }
今日思维导图:
相关文章:
计算机基础知识54
ORM的介绍 # ORM是什么? 我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(增、删、改、查),而一旦谈到数据的管理操作,就需要用到数据库管理软件,例如mysql、oracle…...
深度系统(Deepin)开机无法登录,提示等待一千五百分钟
深度系统(Deepin)20.0, 某次开机无法登录,提示等待一千五百分钟。 ????????? 用电脑这么多年,头一回遇到这种…...
工具及方法 - 多邻国: Duolingo
网站:Duolingo 有iOS和Android应用,在App Store和Google Play上都能下载。也可以使用网页版。我就在iOS上安装了付费版,为了小朋友学习英语,一年的费用¥588。 目前学习中的课程是英语、日语和粤语。英语是小学课程&a…...

Redis篇---第十一篇
系列文章目录 文章目录 系列文章目录前言一、说说Redis持久化机制二、缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级等问题三、热点数据和冷数据是什么前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章…...

linux CentOS7 安装git 配置秘钥公钥克隆代码
第一步:安装git yum -y install git #查看版本 git --version 第二步:配置git信息 git config --global user.name "username" git config --global user.email "XXXXX.com" 第三步:生成密钥和公钥, 后…...
深度学习之生成唐诗案例(Pytorch版)
主要思路: 对于唐诗生成来说,我们定义一个"S" 和 "E"作为开始和结束。 示例的唐诗大概有40000多首, 首先数据预处理,将唐诗加载到内存,生成对应的word2idx、idx2word、以及唐诗按顺序的字序列。…...
算法设计与分析算法实现——删数问题
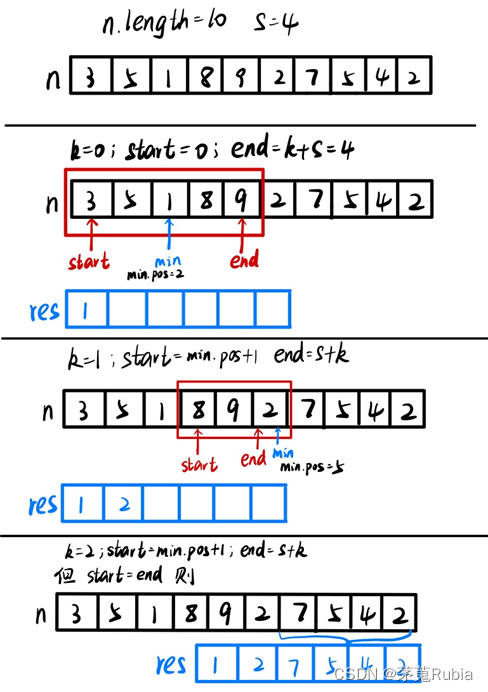
通过棋盘输入一个高精度的正整数n(n的有效位数<=240)去掉其中任意s个数字后,剩下的数字按原左右次序将组成一个新的正整数。变成对给定的n和s,寻找一种方案,使得剩下的数字组成的新数最小。 输入:n,s 输出:最后剩下的最小数 输入实例: 178543 4 输出示例: 13 首先…...

基于Vue+SpringBoot的超市账单管理系统 开源项目
项目编号: S 032 ,文末获取源码。 \color{red}{项目编号:S032,文末获取源码。} 项目编号:S032,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统设计3.1 总体设计3.2 前端设计3…...

【Linux 内核分析课程作业 1】mmap 实现一个 key-valueMap
作业一 功能要求利用 mmap(虚拟内存映射文件) 机制实现一个带持久化能力的 key-valueMap 系统,至少支持单机单进程访问。(可能用到的 linux API: mmap、msync、mremap、munmap、ftruncate、fallocate 等) 电子版提交方式: 2023 年 11 月 20 日 18:00 前通…...
)
docker compose使用教程(docker-compose教程)
文章目录 Docker Compose 使用教程安装Docker ComposeLinuxWindows 和 macOS Docker Compose 基础Compose 文件结构配置服务网络与卷 Docker Compose 命令启动服务停止服务查看服务状态查看日志缩放服务 多环境部署健康检查与依赖管理Docker Compose 最佳实践常见问题解析如何覆…...

印刷企业实施MES管理系统需要哪些硬件设施
随着科技的飞速发展,印刷行业正面临着前所未有的挑战和机遇。为了提高生产效率,降低成本,并增强市场竞争力,越来越多的印刷企业开始实施制造执行系统(MES)管理系统。本文将重点讨论印刷企业在实施MES管理系…...

Java JSON字符串替换其中对应的值
代码: public static void main(String[] args) { // String theData crmScene.getData();String theData "[{\"type\":1,\"values\":[\"审批中\",\"未交付\"],\"name\":\"status\"}]"…...

Android VSYNC发展历程
0 前言 安卓直到android-4.1.1_r1才首次引入VSYNC实现,然后逐步演进到android-4.4才得以完善,并在android-11、12后继续大改。 1 尚未引入 android-4.0.4_r2.1之前尚未引入VSYNC[1],SurfaceFlinger被实现为一个线程,通过睡眠来实…...

外呼系统作用和优势有哪些okcc,ai源码
随着外呼系统诞生,普通中小企业也开始广泛使用,系统给他们带来更多的服务方式和提升业绩的可能。然而,许多企业对外呼系统的理解相对片面和简单,认为它是一个成本中心,需要继续投入人力和使用。事实上,外呼…...

智元机器人岗位内推
Hi there 👋 智元机器人招聘信息 官网: https://www.agibot.com/ 内推联系 邮箱:jiejietopgmail.com微信:yij1799 高级C软件工程师(上海) 岗位职责: 开发自研机器人操作系统,…...
)
el-popover和el-tooltip样式修改(普通的组件样式修改方法,对popover是不生效的)
第一步:‘popper-class’=‘popperClass’ //添加类名 <el-table-column label="审核状态" align="center"><template slot-scope="scope"><el-popoverpopper-class="addformPanel"placement="top"width=&…...
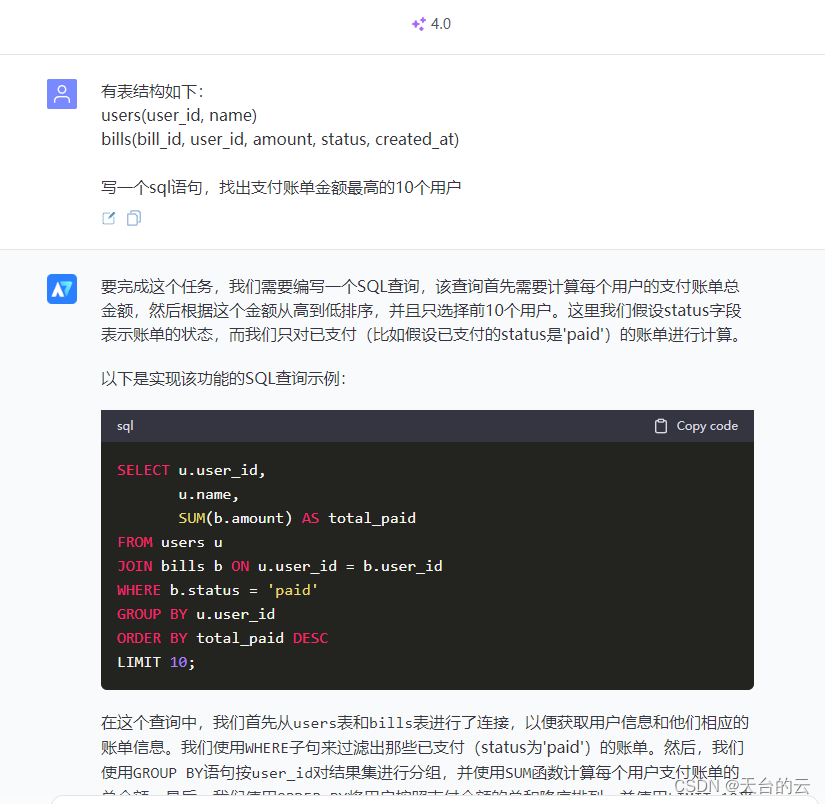
【AI实用技巧】GPT写sql统计语句
编写sql的统计语句是一项复杂的任务,特别是涉及多表的情况下。但有了GPT的帮助,一切变得轻松愉快。 AI7号 - 最强人工智能(GPT)中文版https://ai7.pro/s/9v2um 举例说明 有表结构如下: users(user_id, name) bills(…...
LeetCode(31)无重复字符的最长子串【滑动窗口】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 无重复字符的最长子串 1.题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc"&…...
天猫超市电商营销系统:无代码开发实现API连接集成
无代码开发实现天猫超市与电商系统的高效连接 天猫超市,作为天猫推出的网络零售超市,为广大网购消费者提供了一站式的购物服务。而通过无代码开发的方式,天猫超市能够实现与各种电商系统的连接和集成,这种方式无需进行繁琐的API开…...
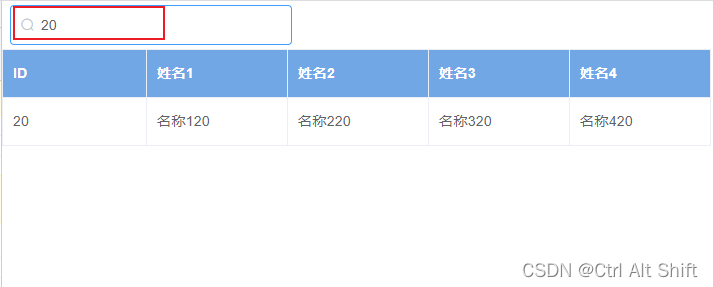
element表格分页+数据过滤筛选
目录 前言效果展示分页效果展示搜索效果展示 代码分析分页功能过滤数据功能 全部代码 前言 在el-element的标签里的tableData数据过多时,会导致表格页面操作卡顿。为解决这一问题,有以下解决方法: 分页加载: 将大量数据进行分页&…...

为什么你的Mac无法写入Windows硬盘?5分钟彻底解决NTFS读写难题
为什么你的Mac无法写入Windows硬盘?5分钟彻底解决NTFS读写难题 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and manag…...

智能家居DIY入门:用E18-MS1-PCB Zigbee模块和串口助手5分钟搭建你的第一个无线传感网络
智能家居DIY入门:5分钟用Zigbee模块搭建无线传感网络 在智能家居领域,Zigbee技术以其低功耗、自组网和高可靠性成为DIY爱好者的首选。E18-MS1-PCB作为一款性价比极高的Zigbee模块,让初学者也能快速搭建自己的无线传感网络。本文将带你从零开始…...

终极指南:快速免费将OFD转PDF的完整解决方案
终极指南:快速免费将OFD转PDF的完整解决方案 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf OFD(开放版式文档)作为中国的标准电子文档格式,在电子发票…...

如何永久保存微信聊天记录?3步实现数据自主掌控的完整方案
如何永久保存微信聊天记录?3步实现数据自主掌控的完整方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

Qobuz-DL终极指南:解锁无损音乐下载的完整高效方案
Qobuz-DL终极指南:解锁无损音乐下载的完整高效方案 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐追求极致音质的今天,无损音频获取工…...

WeChatMsg:如何实现微信聊天记录的永久保存与深度分析?
WeChatMsg:如何实现微信聊天记录的永久保存与深度分析? 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trend…...

GPT-5.5 免费开放背后:技术普惠与行业竞争的双重逻辑
在 AI 大模型快速迭代的当下, o.zzmax.cn 作为一个优秀 ai 大模型聚合站,见证了过去一年多时间里行业从 "付费尝鲜" 到 "普惠普及" 的关键转变。2026 年 5 月 6 日,OpenAI 正式宣布 GPT-5.5 Instant 全面取代 GPT-5.3 In…...

xrdp会话管理进阶:从sesman.ini配置解读到打造稳定的多用户远程环境
xrdp会话管理进阶:从sesman.ini配置解读到打造稳定的多用户远程环境 远程桌面服务在现代IT基础设施中扮演着关键角色,特别是对于需要为团队提供Linux桌面访问的中小型企业和实验室环境。xrdp作为开源的远程桌面协议(RDP)服务器,以其轻量级和易…...

Python 爬虫反爬突破:多维度风控综合对抗策略
前言 当下主流互联网平台的反爬体系,早已告别单一 IP 封禁、请求头校验的初级阶段,转而采用多维度联动风控体系,从访问行为、设备指纹、网络环境、请求特征、账号画像、流量链路六大维度构建多层防护屏障。单一的换 IP、伪造 UA、简单 Cooki…...

TQVaultAE终极指南:告别泰坦之旅仓库混乱,打造完美装备管理系统
TQVaultAE终极指南:告别泰坦之旅仓库混乱,打造完美装备管理系统 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》的仓库空间不足而…...