生产环境_移动目标轨迹压缩应用和算法处理-Douglas-Peucker轨迹压缩算法
场景:
我目前设计到的场景是:即在地图应用中,对GPS轨迹数据进行压缩,减少数据传输和存储开销,因为轨迹点太频繁了,占用空间太大,运行节点太慢了,经过小组讨论需要上这个算法,。
涉及到的算法
- Douglas-Peucker算法:该算法通过递归地将轨迹分割为线段,并丢弃那些与整体轨迹偏差较小的线段,从而实现轨迹的压缩。
- Visvalingam-Whyatt算法:该算法基于三角形面积的概念,通过不断移除面积最小的点来达到轨迹压缩的目的
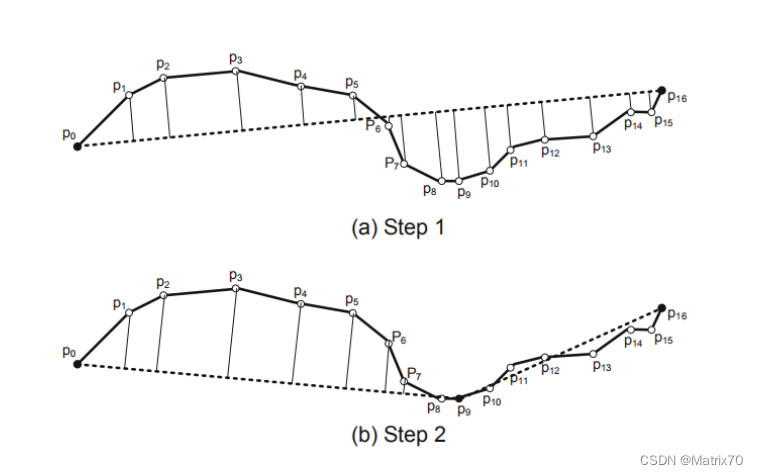
图片来源:郑宇博士《computing with spatial trajectories》
Haversine公式计算距离和Douglas-Peucker压缩算法代码实现-scala版
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
import scala.math._// 定义表示点的类
case class Point(lon: Double, lat: Double, time: String, id: String)// Haversine距离计算函数
def haversineDistance(point1: Point, point2: Point): Double = {val R = 6371000.0 // 地球半径(米)val dLat = toRadians(point2.lat - point1.lat)val dLon = toRadians(point2.lon - point1.lon)val a = pow(sin(dLat / 2), 2) + cos(toRadians(point1.lat)) * cos(toRadians(point2.lat)) * pow(sin(dLon / 2), 2)val c = 2 * atan2(sqrt(a), sqrt(1 - a))R * c
}// Douglas-Peucker轨迹压缩函数
def douglasPeucker(points: List[Point], epsilon: Double): List[Point] = {if (points.length < 3) {return points}val dmax = points.view.zipWithIndex.map { case (point, index) =>if (index != 0 && index != points.length - 1) {perpendicularDistance(point, points.head, points.last)} else {0.0}}.maxif (dmax > epsilon) {val index = points.view.zipWithIndex.maxBy { case (point, index) =>if (index != 0 && index != points.length - 1) {perpendicularDistance(point, points.head, points.last)} else {0.0}}._2val recResults1 = douglasPeucker(points.take(index+1), epsilon)val recResults2 = douglasPeucker(points.drop(index), epsilon)recResults1.init ::: recResults2} else {List(points.head, points.last)}
}// 创建Spark会话
val spark = SparkSession.builder().appName("TrajectoryCompression").getOrCreate()// 创建包含lon、lat、time和id列的示例DataFrame
//https://blog.csdn.net/qq_52128187?type=blog,by_laoli
val data = Seq((40.7128, -74.0060, "2023-11-18 08:00:00", "1"),(40.7215, -74.0112, "2023-11-18 08:05:00", "1"),(40.7312, -74.0146, "2023-11-18 08:10:00", "1"),(40.7356, -74.0162, "2023-11-18 08:15:00", "1"),(40.7391, -74.0182, "2023-11-18 08:20:00", "1"),(40.7483, -74.0224, "2023-11-18 08:25:00", "1"),(40.7527, -74.0260, "2023-11-18 08:30:00", "1")
).toDF("lon", "lat", "time", "id")// 为DataFrame添加id列
val dfWithId = data.withColumn("id", monotonically_increasing_id())// 将DataFrame转换为Point列表
val points = dfWithId.as[(Double, Double, String, Long)].collect().map(p => Point(p._1, p._2, p._3, p._4.toString)).toList// 执行轨迹压缩
val compressedPoints = douglasPeucker(points, epsilon = 10) // 设置您期望的epsilon值// 将压缩后的数据重新转换为DataFrame
import spark.implicits._
val df2 = compressedPoints.toDF("lon", "lat", "time", "id")
参考文章
- Douglas, D.H., and Peucker, T.K. "Algorithms for the reduction of the number of points required to represent a digitized line or its caricature." The Canadian Cartographer 10.2 (1973): 112-122.
- Visvalingam, M., and Whyatt, J.D. "Line generalization by repeated elimination of the smallest-area triangle." Cartographic Journal 30.1 (1993): 46-51.
- 轨迹数据压缩的Douglas-Peucker算法(附代码及原始数据) - 知乎
相关文章:
生产环境_移动目标轨迹压缩应用和算法处理-Douglas-Peucker轨迹压缩算法
场景: 我目前设计到的场景是:即在地图应用中,对GPS轨迹数据进行压缩,减少数据传输和存储开销,因为轨迹点太频繁了,占用空间太大,运行节点太慢了,经过小组讨论需要上这个算法&#x…...
HINSTANCE是什么?
HINSTANCE 就是 HMODULE:...

uniapp小程序定位;解决调试可以,发布不行的问题
遇见这个问题;一般情况就两种 1、域名配置问题; 2、隐私协议问题 当然,如果你的微信小程序定位接口没开启;定位也会有问题; 第一种,小程序一般是腾讯地图;所以一般都会用https://apis.map.qq.co…...

C++学习 --pair
目录 1, 什么是pair 2, 创建pair 2-1, 标准数据类型 2-2, 自定义数据类型 3, 查询元素 3-1, 标准数据类型 3-2, 自定义数据类型 1, 什么是pair 数据以键值对形式存放的容器&…...

Android Frgment中onActivityResult无效的问题
前言 最近在fragment中使用二维码扫描 发现拿不到onActivityResult返回 查了资料说是启动模式 或者是返回值为负数 断点调试 发现根本没走onActivityResult方法 问题 onActivityResult 在附属Activity中被拦截了 所以没有触发该方法 解决 在Fragment所依赖的Activity中执…...
【C#二开业务冠邑】通过界面查看数据来源
前言 重构框架(CS【C#】转BS【Java】)时,突然发现公司的代码和数据库,有部分都没有写注释,嘎嘎,这不非常影响开发效率,于是乎,开始帮公司整理表结构和数据来源,也从而加…...
使用大语言模型 LLM 做文本分析
本文主要分享 传统聚类算法 LLM与嵌入算法 嵌入算法聚类 LLM的其他用法 聚类是一种无监督机器学习技术,旨在根据相似的数据点的特征将其分组在一起。使用聚类成簇,有助于解决各种问题,例如客户细分、异常检测和文本分类等。尽管传统的聚…...

Windows本地搭建rtmp推流服务
前言 开发时偶尔需要使用rtmp直播流做视频流测试,苦于网上开源的rtmp视频流都已经失效,无奈只好尝试在本地自己搭建一个rtmp的推流服务,方便测试使用。 一、工具准备 Nginx:使用nginx-rtmp-win64推流工具FFmpeg:官方…...

机器学习二元分类 二元交叉熵 二元分类例子
二元交叉熵损失函数 深度学习中的二元分类损失函数通常采用二元交叉熵(Binary Cross-Entropy)作为损失函数。 二元交叉熵损失函数的基本公式是: L(y, y_pred) -y * log(y_pred) - (1 - y) * log(1 - y_pred)其中,y是真实标签&…...
)
Postgresql运维信息(一)
1. 运维系统视图 PostgreSQL 提供了一系列系统视图和函数,可以用于获取数据库的运维统计信息。这些信息对于监控和优化数据库性能非常有用。以下是一些常用的 PostgreSQL 运维统计信息: 1.1. pg_stat_activity 这个系统视图包含了当前数据库连接的活动…...
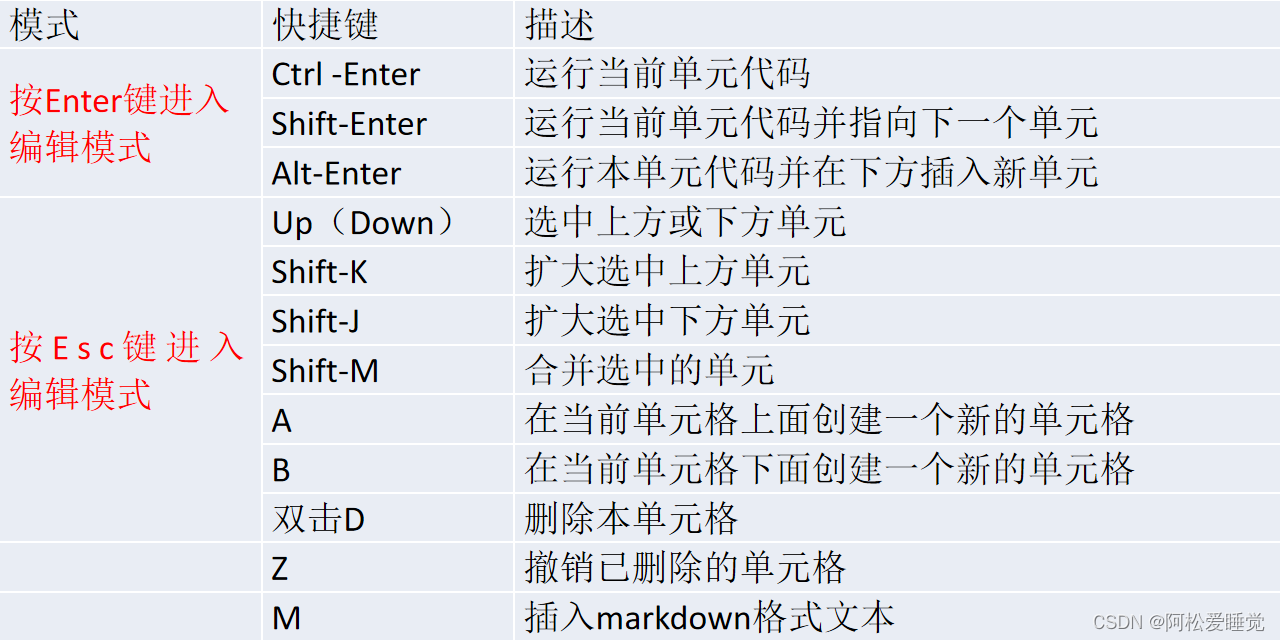
Jupyter Notebook的下载安装与使用教程_Python数据分析与可视化
Jupyter Notebook的下载安装与使用 Jupyter简介下载与安装启动与创建NotebookJupyter基本操作 在计算机编程领域,有一个很强大的工具叫做Jupyter。它不仅是一个集成的开发环境,还是一个交互式文档平台。对于初学者来说,Jupyter提供了友好的界…...
快速入门:构建您的第一个 .NET Aspire 应用程序
##前言 云原生应用程序通常需要连接到各种服务,例如数据库、存储和缓存解决方案、消息传递提供商或其他 Web 服务。.NET Aspire 旨在简化这些类型服务之间的连接和配置。在本快速入门中,您将了解如何创建 .NET Aspire Starter 应用程序模板解决方案。 …...

主流开源大语言模型的微调方法
文章目录 模型ChatGLM2网址原生支持微调方式 ChatGLM3网址原生支持微调方式 Baichuan 2网址原生支持微调方式 Qwen网址原生支持微调方式 框架FireflyEfficient-Tuning-LLMsSuperAdapters 模型 ChatGLM2 网址 https://github.com/thudm/chatglm2-6b 原生支持微调方式 https…...

Django DRF权限组件
在Django的drf框架内的权限组件,如果遇到多个权限认证类,是需要所有的权限类都要通过验证,才能访问视图。 一、简单示例 1、per.py 自定义权限类 from rest_framework.permissions import BasePermission import randomclass MyPerssion(B…...

leetcode每日一题31
搜索旋转排序数组 那……二分法呗 数组中的数可以相同 比 33. 搜索旋转排序数组 多了一个「有重复元素」,导致无法根据 num > nums[0] 来判断 num 在哪一半,比如 [1,1,1,1,1,2,1,1,1] 旋转数组两头相等,元素 1 可能在左半边可能在右半边 …...
)
使用Pytorch测试cuda设备的性能(单卡或多卡并行)
以下CUDA设备泛指NVIDIA显卡 或 启用ROCm的AMD显卡 测试环境: Distributor ID: UbuntuDescription: Ubuntu 22.04.3 LTSRelease: 22.04Codename: jammy 1.首先,简单使用torch.ones测试CUDA设备 import torch import timedef cuda_benchmark(device_id…...

SpringBoot-AOP-基础到进阶
SpringBoot-AOP AOP基础 学习完spring的事务管理之后,接下来我们进入到AOP的学习。 AOP也是spring框架的第二大核心,我们先来学习AOP的基础。 在AOP基础这个阶段,我们首先介绍一下什么是AOP,再通过一个快速入门程序,…...

Midjourney绘画提示词Prompt参考学习教程
一、工具 SparkAi: SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软…...

美国费米实验室SQMS启动“量子车库”计划!30+顶尖机构积极参与
11月6日,美国能源部费米国家加速器实验室(SQMS)正式启动了名为“量子车库”的全新旗舰量子研究设施。这个6,000平方英尺的实验室是由超导量子材料与系统中心负责设计和建造,旨在联合国内外的科学界、工业领域和初创企业,共同推动量子信息科…...
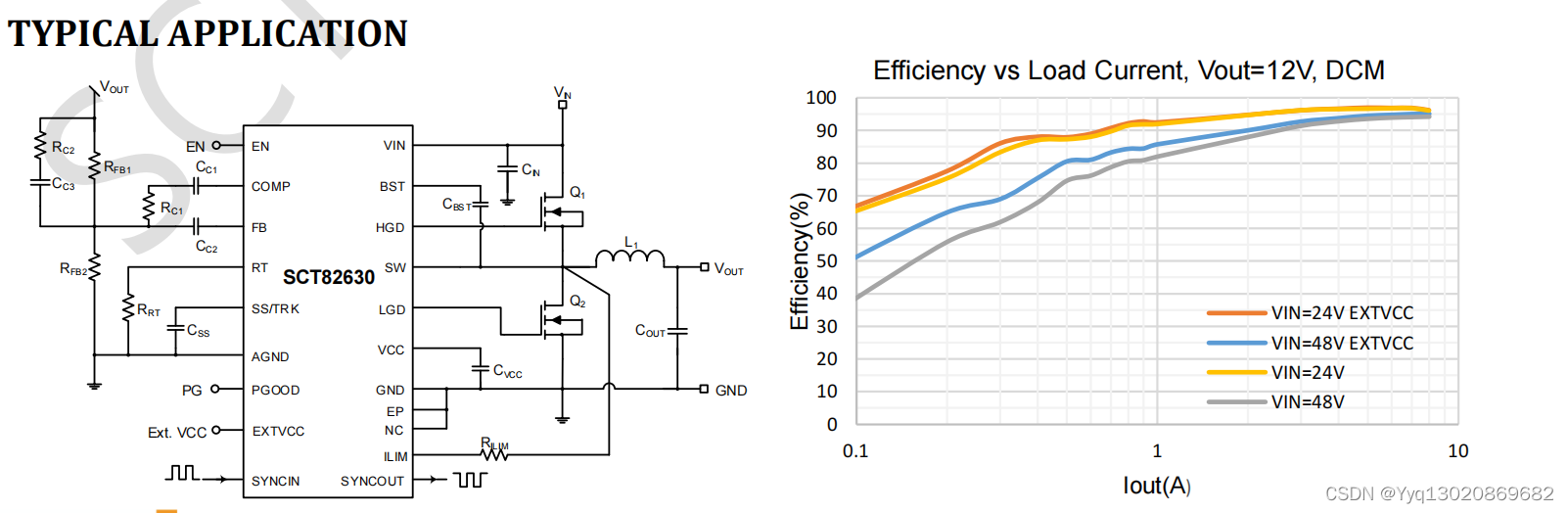
DCDC同步降压控制器SCT82A30\SCT82630
SCT82A30是一款100V电压模式控制同步降压控制器,具有线路前馈。40ns受控高压侧MOSFET的最小导通时间支持高转换比,实现从48V输入到低压轨的直接降压转换,降低了系统复杂性和解决方案成本。如果需要,在低至6V的输入电压下降期间&am…...

ChatGPT系统提示词仓库:从原理到实战的AI协作指南
1. 项目概述:一个被低估的ChatGPT系统提示词仓库如果你经常使用ChatGPT、Claude这类大语言模型,并且已经过了“随便问问”的新手阶段,开始尝试用它来辅助编程、撰写深度报告或者进行专业领域的对话,那么你大概率会遇到一个瓶颈&am…...

桌面杂乱无章?这款免费神器5分钟帮你打造高效工作空间
桌面杂乱无章?这款免费神器5分钟帮你打造高效工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否曾面对满屏的桌面图标感到无从下手?工作文…...

为LLM注入联网能力:SuGPT-kexue项目的架构设计与工程实践
1. 项目概述与核心价值最近在开源社区里,一个名为“SuGPT-kexue”的项目引起了不少开发者和AI爱好者的注意。这个项目名本身就挺有意思,它指向了一个非常具体且实用的场景:如何让一个大型语言模型(LLM)具备科学上网的能…...

罗技PUBG压枪宏完整指南:从原理到实战的深度解析
罗技PUBG压枪宏完整指南:从原理到实战的深度解析 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这类FPS游戏中&#…...

终极免费B站4K视频下载器:解锁大会员高清内容完整指南
终极免费B站4K视频下载器:解锁大会员高清内容完整指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 还在为B站大会员专属…...

终极解决方案:用代码绘图插件让Draw.io效率提升300%的完整指南
终极解决方案:用代码绘图插件让Draw.io效率提升300%的完整指南 【免费下载链接】drawio_mermaid_plugin Mermaid plugin for drawio desktop 项目地址: https://gitcode.com/gh_mirrors/dr/drawio_mermaid_plugin 还在为技术文档中的图表绘制而烦恼吗&#x…...

如何高效管理Switch游戏文件:NSC_BUILDER完全指南
如何高效管理Switch游戏文件:NSC_BUILDER完全指南 【免费下载链接】NSC_BUILDER Nintendo Switch Cleaner and Builder. A batchfile, python and html script based in hacbuild and Nuts python libraries. Designed initially to erase titlerights encryption f…...

NoPUA:基于信任与内在动机的AI代理效能提升框架
1. 项目概述:当AI代理遇到“职场PUA”,我们如何用两千年前的智慧重塑其工作动力?如果你最近在AI编程领域活跃,大概率听说过“PUA技能”这个概念。它源自一个名为“pua”的开源项目,核心思路是把企业里那套“绩效威胁”…...
)
告别regsvr32!易语言调用大漠插件dm.dll的免注册实战(附Win7/10/11避坑指南)
易语言免注册调用大漠插件全攻略:从原理到多系统兼容实战 在自动化脚本开发领域,大漠插件因其强大的图像识别和模拟操作功能而广受欢迎。然而,传统的regsvr32注册方式常让开发者陷入系统权限、路径依赖和版本管理的泥潭。想象一下这样的场景&…...

如何快速免费解锁电脑隐藏性能:UXTU硬件调优终极完整指南
如何快速免费解锁电脑隐藏性能:UXTU硬件调优终极完整指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 还在为电…...