Week-T10 数据增强
文章目录
- 一、准备环境和数据
- 1.环境
- 2. 数据
- 二、数据增强(增加数据集中样本的多样性)
- 三、将增强后的数据添加到模型中
- 四、开始训练
- 五、自定义增强函数
- 六、一些增强函数
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第10周:数据增强(训练营内部成员可读)
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
本文说明了两种数据增强方式,以及如何自定义数据增强方式并将其放到我们代码当中,两种数据增强方式如下:
● 将数据增强模块嵌入model中
● 在Dataset数据集中进行数据增强
常用的tf增强函数在文末有说明
一、准备环境和数据
1.环境
import matplotlib.pyplot as plt
import numpy as np
import sys
from datetime import datetime
#隐藏警告
import warnings
warnings.filterwarnings('ignore')from tensorflow.keras import layers
import tensorflow as tfprint("--------# 使用环境说明---------")
print("Today: ", datetime.today())
print("Python: " + sys.version)
print("Tensorflow: ", tf.__version__)gpus = tf.config.list_physical_devices("GPU")
if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")# 打印显卡信息,确认GPU可用print(gpus)
else:print("Use CPU")

2. 数据
使用上一课的数据集,即猫狗识别2的数据集。其次,原数据集中不包括测试集,所以使用tf.data.experimental.cardinality确定验证集中有多少批次的数据,然后将其中的 20% 移至测试集。
# 从本地路径读入图像数据
print("--------# 从本地路径读入图像数据---------")
data_dir = "D:/jupyter notebook/DL-100-days/datasets/Cats&Dogs Data2/"
img_height = 224
img_width = 224
batch_size = 32# 划分训练集
print("--------# 划分训练集---------")
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)# 划分验证集
print("--------# 划分验证集---------")
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)# 从验证集中划20%的数据用作测试集
print("--------# 从验证集中划20%的数据用作测试集---------")
val_batches = tf.data.experimental.cardinality(val_ds)
test_ds = val_ds.take(val_batches // 5)
val_ds = val_ds.skip(val_batches // 5)print('验证集的批次数: %d' % tf.data.experimental.cardinality(val_ds))
print('测试集的批次数: %d' % tf.data.experimental.cardinality(test_ds))# 显示数据类别
print("--------# 显示数据类别---------")
class_names = train_ds.class_names
print(class_names)print("--------# 归一化处理---------")
AUTOTUNE = tf.data.AUTOTUNEdef preprocess_image(image,label):return (image/255.0,label)# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
test_ds = test_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)# 数据可视化
print("--------# 数据可视化---------")
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(5, 8, i + 1) plt.imshow(images[i])plt.title(class_names[labels[i]])plt.axis("off")

二、数据增强(增加数据集中样本的多样性)
数据增强的常用方法包括(但不限于):随机平移、随机翻转、随机旋转、随机亮度、随机对比度,可以在Tf中文网的experimental/preprocessing类目下查看,也可以在Tf中文网的layers/类目下查看。
本文使用随机翻转和随机旋转来进行增强:
● tf.keras.layers.experimental.preprocessing.RandomFlip:水平和垂直随机翻转每个图像
● tf.keras.layers.experimental.preprocessing.RandomRotation:随机旋转每个图像
# 第一个层表示进行随机的水平和垂直翻转,而第二个层表示按照 0.2 的弧度值进行随机旋转。
print("--------# 数据增强:随机翻转+随机旋转---------")
data_augmentation = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])# Add the image to a batch.
print("--------# 添加图像到batch中---------")
# Q:这个i从哪来的??????
image = tf.expand_dims(images[i], 0)print("--------# 显示增强后的图像---------")
plt.figure(figsize=(8, 8))
for i in range(9):augmented_image = data_augmentation(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0])plt.axis("off")
--------# 数据增强:随机翻转+随机旋转---------
--------# 添加图像到batch中---------
--------# 显示增强后的图像---------
WARNING:tensorflow:Using a while_loop for converting RngReadAndSkip cause there is no registered converter for this op.
WARNING:tensorflow:Using a while_loop for converting Bitcast cause there is no registered converter for this op.

三、将增强后的数据添加到模型中
两种方式:
- (1)将其嵌入model中:
优点是:
● 数据增强这块的工作可以得到GPU的加速(如果使用了GPU训练的话)
注意:只有在模型训练时(Model.fit)才会进行增强,在模型评估(Model.evaluate)以及预测(Model.predict)时并不会进行增强操作。
'''
model = tf.keras.Sequential([data_augmentation,layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),
])
'''
"\nmodel = tf.keras.Sequential([\n data_augmentation,\n layers.Conv2D(16, 3, padding='same', activation='relu'),\n layers.MaxPooling2D(),\n])\n"
- (2)在Dataset数据集中进行数据增强
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNEdef prepare(ds):ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE)return dsprint("--------# 增强后的图像加到模型中---------")
train_ds = prepare(train_ds)
四、开始训练
# 设置模型
print("--------# 设置模型---------")
model = tf.keras.Sequential([layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(len(class_names))
])# 设置编译参数
# ● 损失函数(loss):用于衡量模型在训练期间的准确率。
# ● 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
# ● 评价函数(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
print("--------# 设置编译器参数---------")
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])print("--------# 开始训练---------")
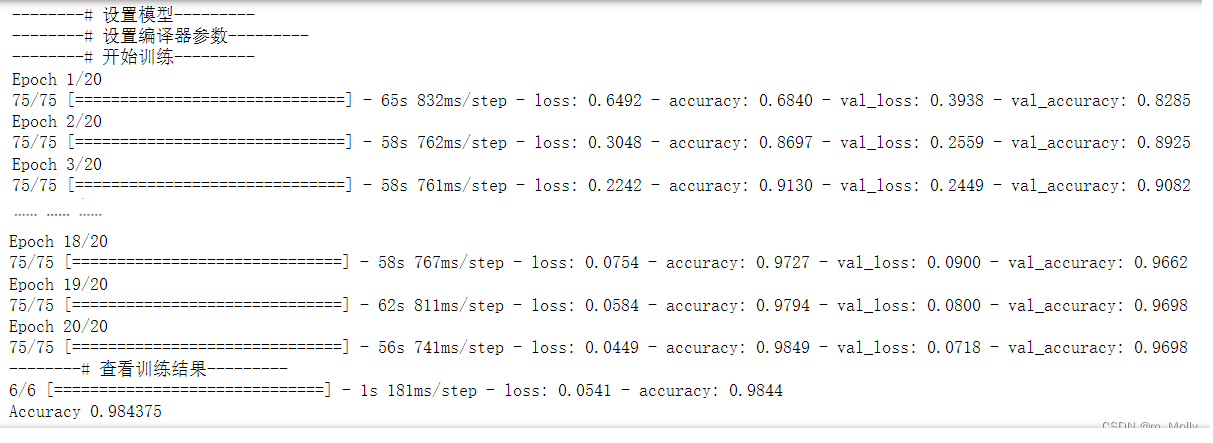
epochs=20
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)print("--------# 查看训练结果---------")
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
五、自定义增强函数
print("--------# 自定义增强函数---------")
import random
# 这是大家可以自由发挥的一个地方
def aug_img(image):seed = (random.randint(0,9), 0)# 随机改变图像对比度stateless_random_brightness = tf.image.stateless_random_contrast(image, lower=0.1, upper=1.0, seed=seed)return stateless_random_brightnessimage = tf.expand_dims(images[3]*255, 0)
print("Min and max pixel values:", image.numpy().min(), image.numpy().max())plt.figure(figsize=(8, 8))
for i in range(9):augmented_image = aug_img(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0].numpy().astype("uint8"))plt.axis("off")# Q: 将自定义增强函数应用到我们数据上呢?
# 请参考上文的 preprocess_image 函数,将 aug_img 函数嵌入到 preprocess_image 函数中,在数据预处理时完成数据增强就OK啦。


# 从本地路径读入图像数据
print("--------# 从本地路径读入图像数据---------")
data_dir = "D:/jupyter notebook/DL-100-days/datasets/Cats&Dogs Data2/"
img_height = 224
img_width = 224
batch_size = 32# 划分训练集
print("--------# 划分训练集---------")
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)# 划分验证集
print("--------# 划分验证集---------")
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)# 从验证集中划20%的数据用作测试集
print("--------# 从验证集中划20%的数据用作测试集---------")
val_batches = tf.data.experimental.cardinality(val_ds)
test_ds = val_ds.take(val_batches // 5)
val_ds = val_ds.skip(val_batches // 5)print('验证集的批次数: %d' % tf.data.experimental.cardinality(val_ds))
print('测试集的批次数: %d' % tf.data.experimental.cardinality(test_ds))# 显示数据类别
print("--------# 显示数据类别---------")
class_names = train_ds.class_names
print(class_names)print("--------# 归一化处理---------")
AUTOTUNE = tf.data.AUTOTUNEprint("--------# 将自定义增强函数应用到数据上---------")
def preprocess_image(aug_img,label):return (aug_img/255.0,label)# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
test_ds = test_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)# 数据可视化
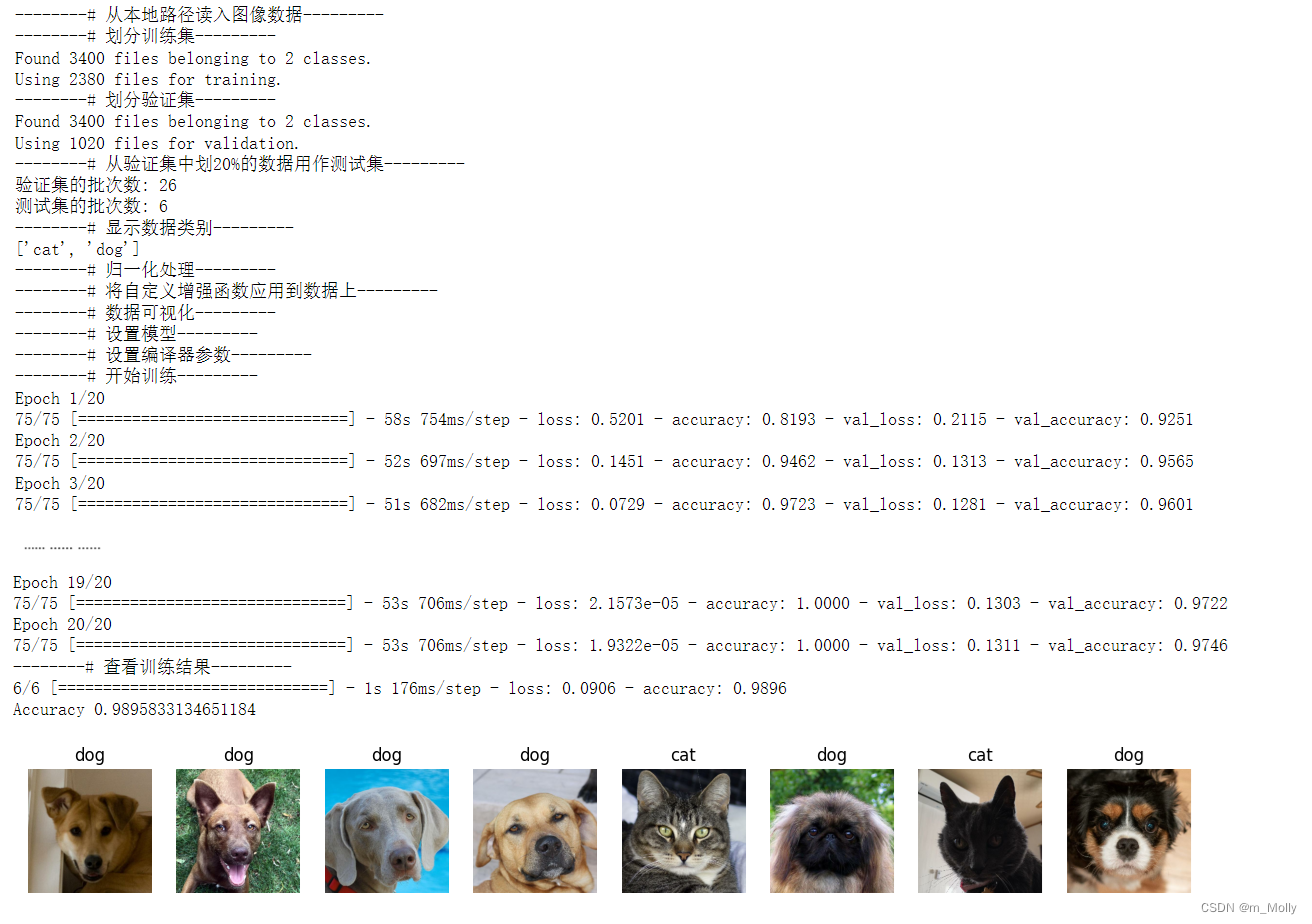
print("--------# 数据可视化---------")
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(5, 8, i + 1) plt.imshow(images[i])plt.title(class_names[labels[i]])plt.axis("off")# 设置模型
print("--------# 设置模型---------")
model = tf.keras.Sequential([layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(len(class_names))
])# 设置编译参数
# ● 损失函数(loss):用于衡量模型在训练期间的准确率。
# ● 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
# ● 评价函数(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
print("--------# 设置编译器参数---------")
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])print("--------# 开始训练---------")
epochs=20
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)print("--------# 查看训练结果---------")
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
使用自定义增强函数增强后的数据重新训练的结果:
六、一些增强函数
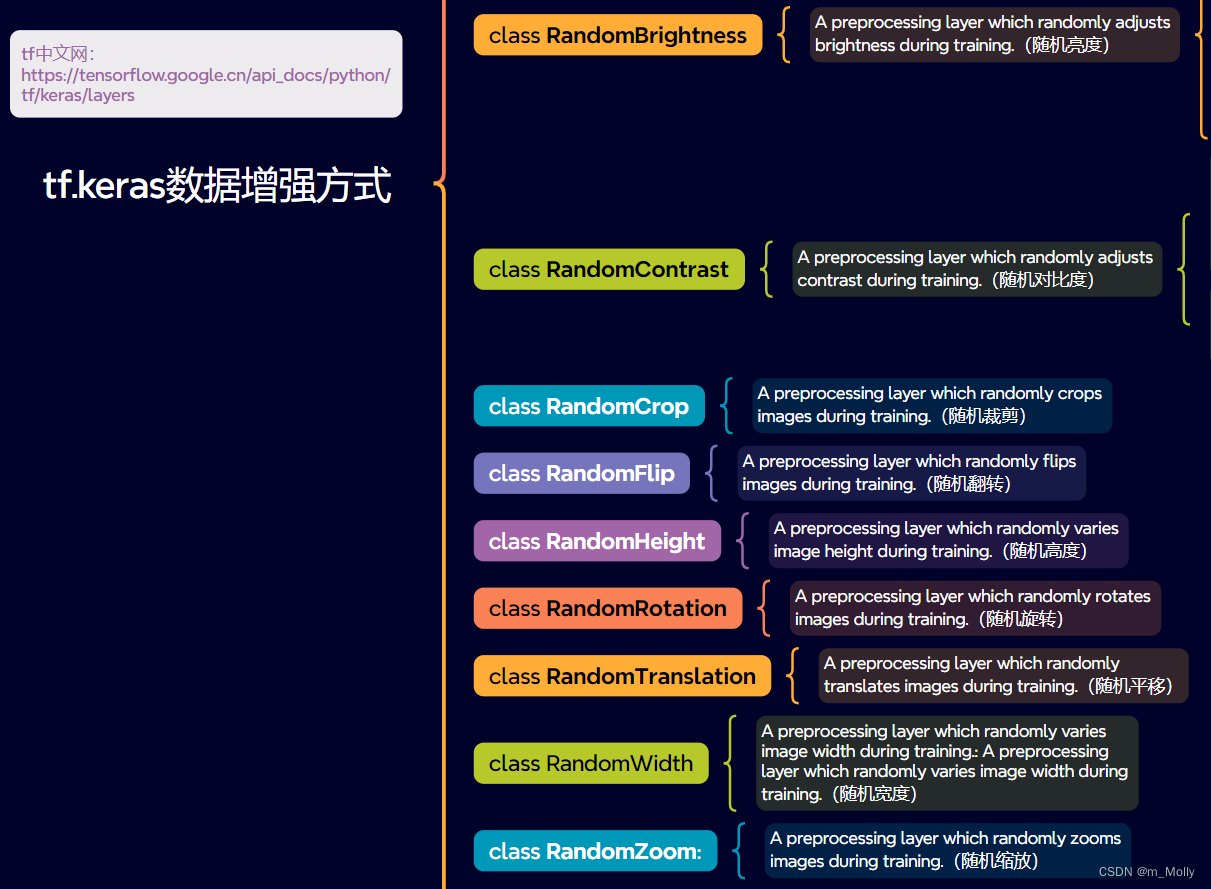
(1)随机亮度(RandomBrightness)
tf.keras.layers.RandomBrightness( factor, value_range=(0, 255), seed=None, **kwargs )
(2)随机对比度(RandomContrast)
tf.keras.layers.RandomContrast( factor, seed=None, **kwargs )
(3)随机裁剪(RandomCrop)
tf.keras.layers.RandomCrop( height, width, seed=None, **kwargs )
(4)随机翻转(RandomFlip)
tf.keras.layers.RandomFlip( mode=HORIZONTAL_AND_VERTICAL, seed=None, **kwargs )
(5)随机高度(RandomHeight)和随机宽度(RandomWidth)
tf.keras.layers.RandomHeight( factor, interpolation='bilinear', seed=None, **kwargs )
tf.keras.layers.RandomWidth( factor, interpolation='bilinear', seed=None, **kwargs )
(6)随机平移(RandomTranslation)
tf.keras.layers.RandomTranslation( height_factor, width_factor, fill_mode='reflect', interpolation='bilinear', seed=None, fill_value=0.0, **kwargs )
(7)随机旋转(RandonRotation)
tf.keras.layers.RandomRotation( factor, fill_mode='reflect', interpolation='bilinear', seed=None, fill_value=0.0, **kwargs )
(8)随机缩放(RandonZoom)
tf.keras.layers.RandomZoom( height_factor, width_factor=None, fill_mode='reflect', interpolation='bilinear', seed=None, fill_value=0.0, **kwargs )
相关文章:
Week-T10 数据增强
文章目录 一、准备环境和数据1.环境2. 数据 二、数据增强(增加数据集中样本的多样性)三、将增强后的数据添加到模型中四、开始训练五、自定义增强函数六、一些增强函数 🍨 本文为🔗365天深度学习训练营 中的学习记录博客…...

史上最全!PMP实用应试技巧汇总!
PMP(Project Management Professional 项目管理专业人士资格认证,由全球最大的项目管理专业组织机构——美国PMI发起,目的是用来严格评估管理项目人员知识技能是否具有高品质的资格认证考试。给大家带来关于PMP考试的实用应试技巧。 PMP解题…...
037、目标检测-SSD实现
之——实现 目录 之——简单实现 杂谈 正文 1.类别预测层 2.边界框预测 3.多尺度输出联结做预测(提高预测效率) 4.多尺度实现 5.基本网络块 6.完整模型 杂谈 原理查看:037、目标检测-算法速览-CSDN博客 正文 1.类别预测层 类别预测…...

【开题报告】基于SpringBoot的摄影作品展示网站的设计与实现
1.研究背景 随着社会的发展和人民生活水平的提高,摄影作品已成为一种非常受欢迎的艺术形式。越来越多的人开始对摄影艺术产生兴趣,并且拥有了自己的摄影作品。然而,如何将这些摄影作品展示出来并与其他摄影爱好者进行交流,成为了…...

SVR和SVM是什么关系
SVR(Support Vector Regression)和 SVM(Support Vector Machines)是支持向量机(Support Vector Machine)的两个不同方面,分别用于回归和分类问题。 SVM (Support Vector Machines): SVM是一种用…...

Flutter 3.16 中带来的更新
Flutter 3.16 中带来的更新 目 录 1. 概述2. 框架更新2.1 Material 3 成为新默认2.2 支持 Material 3 动画2.3 TextScaler2.4 SelectionArea 更新2.5 MatrixTransition 动画2.6 滚动更新2.7 在编辑菜单中添加附加选项2.8 PaintPattern 添加到 flutter_test 3. 引擎更新…...

批量插入数据与分页的原理及推导
批量插入数据 【1】准备数据 class Book(models.Model):title models.CharField(max_length32) 【2】一条一条插入 后端 def ab_many(request):# (1)先给Book表插入一万条数据for i in range(1000):models.Book.objects.create(titlef第{i}本书)# (2)将所有数据查询到并展…...
SMART PLC累计流量功能块(梯形积分法+浮点数累加精度控制)
S7-200SMART PLC数值积分器相关知识请参考下面文章链接: SMART PLC数值积分器功能块(矩形+梯形积分法完整源代码)-CSDN博客文章浏览阅读153次。PLC的数值积分器算法也可以参考下面文章链接:PLC算法系列之数值积分器(Integrator)-CSDN博客数值积分和微分在工程上的重要意义不…...

【金融分析】Python:病人预约安排政策 | 金融模拟分析
目录: 说明(Instructions) 问题描述(Problem Description) 仿真设置(Simulation Setting) 仿真过程的 Python 代码...

后端接口测试,令牌校验住,获取tocken 接口的方式
post : http://127.0.0.1:端口号/login { "username":"admin", "password":"admin123", "code":"3", "uuid":"966c34e409434f15942ec29a284da0a6" } headers tocken false...

Ghidra逆向工具配置 MacOS 的启动台显示(Python)
写在前面 通过 ghidra 工具, 但是只能用命令行启动, 不太舒服, 写个脚本生成 MacOS 的 app 格式并导入启动台. 不算复杂, 主要是解析包的一些元信息还有裁剪软件图标(通过 MacOS 自带的 API) 脚本 #!/opt/homebrew/bin/python3import os import re import subprocess as sp…...

关于交换芯片调试 tx_delay rx_delay 的一点经验
按照官方的介绍,需要用示波器 测量数据和时钟 实质相位差在2ns 左右,但是由于时钟 125M ,数据方波需要的示波器带宽更高,所以普通示波器是没有办法的,测试变形很大,所以调试的方法如下: 1.根据官方手册,先在设备树里设置跟手册示例一样的,保证ping的时候可以ping通,…...
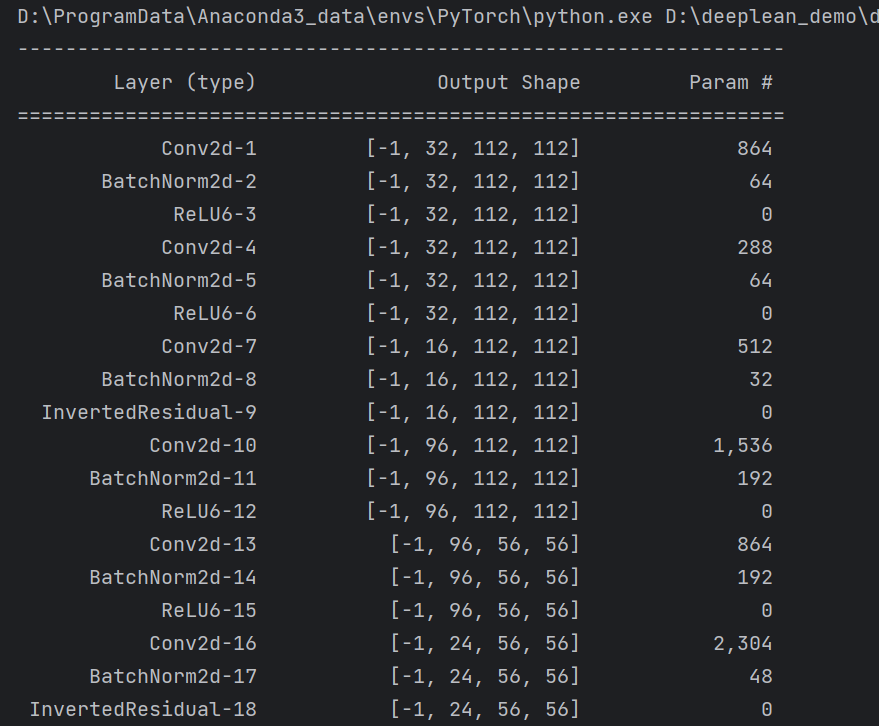
【图像分类】【深度学习】【轻量级网络】【Pytorch版本】MobileNets_V2模型算法详解
【图像分类】【深度学习】【轻量级网络】【Pytorch版本】MobileNets_V2模型算法详解 文章目录 【图像分类】【深度学习】【轻量级网络】【Pytorch版本】MobileNets_V2模型算法详解前言MobleNet_V2讲解反向残差结构(Inverted Residuals)兴趣流形(Manifold of interest)线性瓶颈层…...
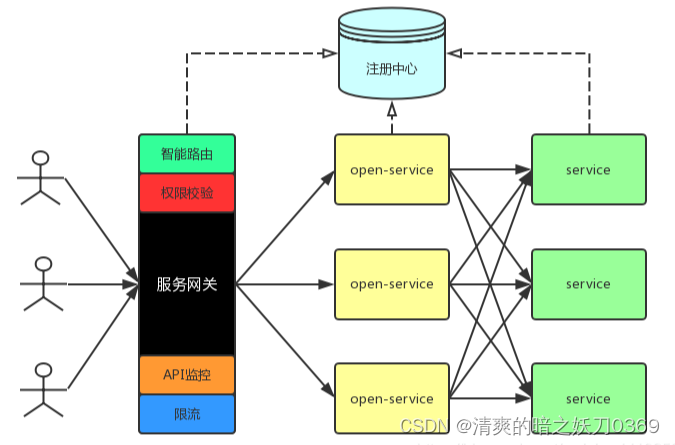
Spring Cloud 简介
1、简介 Spring CloudLevel up your Java code and explore what Spring can do for you.https://spring.io/projects/spring-cloud Spring Cloud 是一系列有序框架的集合,其主要的设施有,服务发现与注册,配置中心,消息总…...
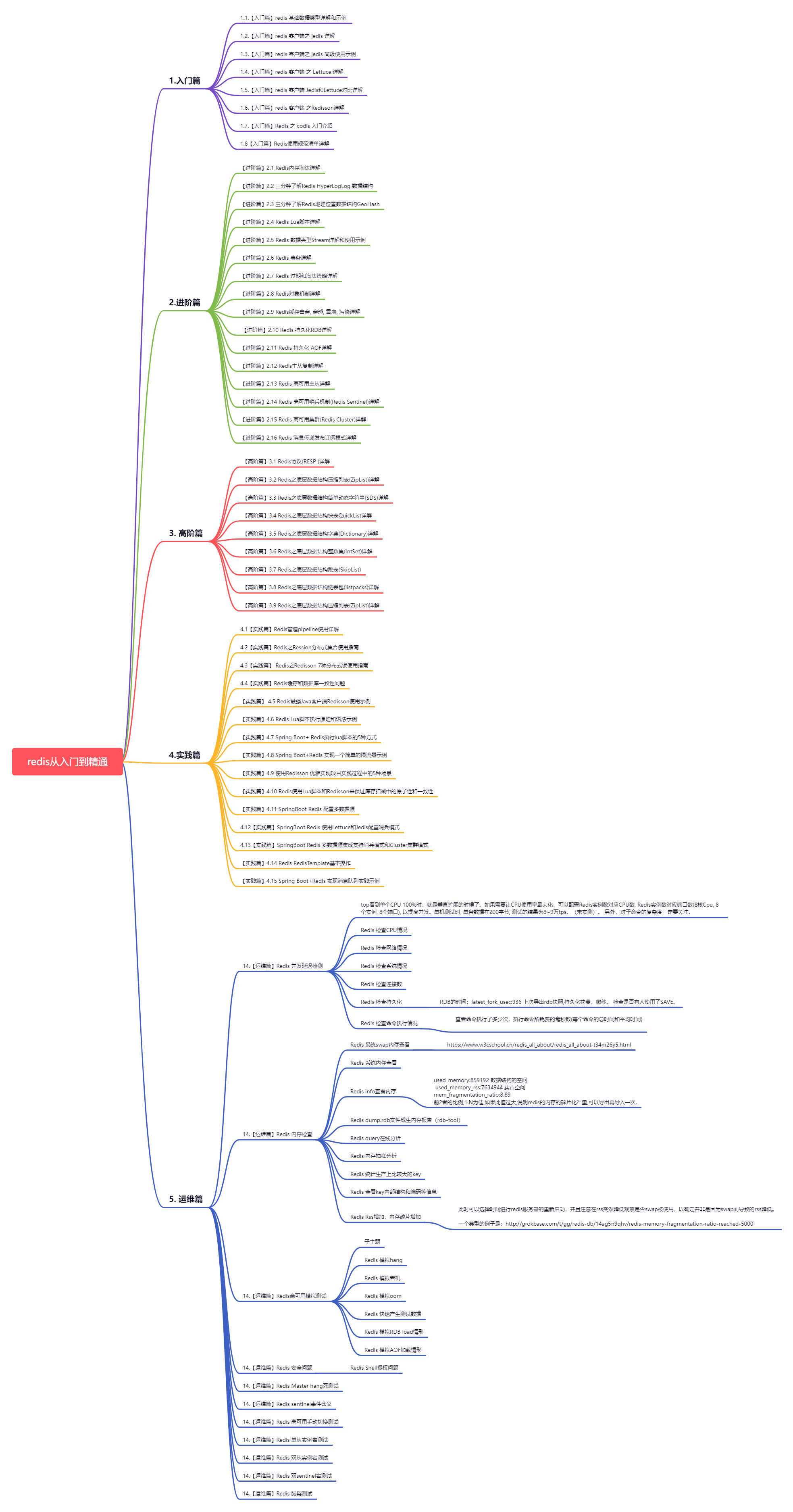
Redis从入门到精通(二)- 入门篇
文章目录 0. 前言1. 入门篇[【入门篇】1.1 redis 基础数据类型详解和示例](https://icepip.blog.csdn.net/article/details/134438573)[【入门篇】1.2 Redis 客户端之 Jedis 详解和示例](https://icepip.blog.csdn.net/article/details/134440061)[【入门篇】1.3 redis客户端之…...
SpringDoc基础配置和集成OAuth2登录认证教程
本期内容 学会通过注解和Java代码的方式添加SpringDoc配置。在swagger-ui提供的页面上提供OAuth2登录认证,在集成Security的情况下便捷获取access_token并在请求时按照OAuth2规范携带。 为什么集成OAuth2登录认证? 现在大部分教程是在swagger-ui页面添…...

链路聚合-静态和动态区别
链路聚合之动静态聚合方式 链路聚合组是由一组相同速率、以全双工方式工作的网口组成。 1、动态聚合: 动态聚合对接的双方通过交互LACP(链路聚合控制协议)协议报文,来协商聚合对接。 优点:对接双方相互交互端口状态信息,使端口…...
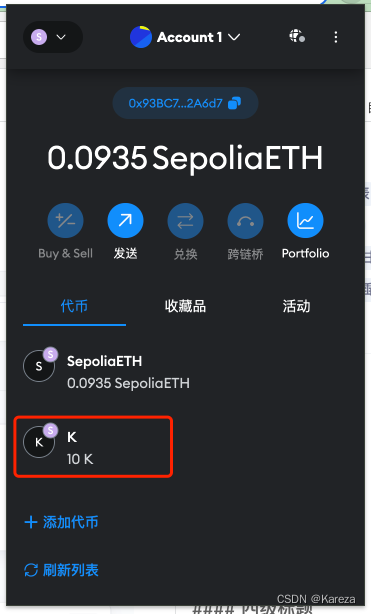
发币成功,记录一下~
N年前就听说了这样一种说法——“一个熟练的区块链工程师,10分钟就可以发出一个新的币” 以前仅仅是有这么一个认识,但当时并不特别关注这个领域。 最近系统性学习中,今天尝试发币成功啦,记录一下~ 发在 Sepolia Tes…...
一个完备的手游地形实现方案
一、地形几何方案:Terrain 与 Mesh 1.1 目前手游主流地形几何方案分析 先不考虑 LOD 等优化手段,目前地形的几何方案选择有如下几种: 使用 Unity 自带的 Terrain使用 Unity 自带的 Terrain,但是等美术资产完成后使用工具转为 M…...
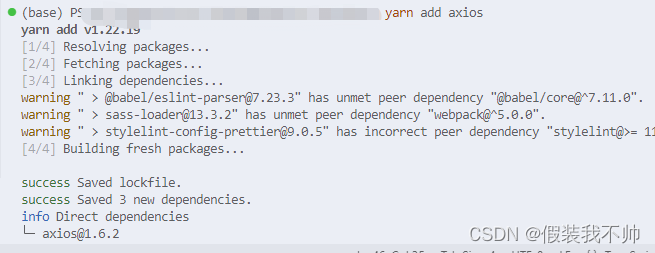
vite vue3配置axios
准备 参考 安装axios yarn add axios中文官网 src下新建request文件夹,该文件下新建index.ts import axios from axios; import { ElMessage } from element-plus;// const errorCodeType function (code: number): string { // let errMessage: string 未知…...

CANN双三次上采样算子
aclnnUpsampleBicubic2d 【免费下载链接】ops-cv 本项目是CANN提供的图像处理、目标检测相关的算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-cv 📄 查看源码 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT…...

在线生成背景:字号层级怎么做才像「正式物料」
🎨 在线生成背景:字号层级怎么做才像「正式物料」在信息爆炸的时代,一份 「看起来就专业」 的物料能迅速赢得信任。当您在线生成报告、海报或演示文稿背景时,文字排版的字号层级是塑造这种正式感与专业度的隐形骨架。它无声地组织…...

AArch64指针认证机制与QARMA算法解析
1. AArch64指针认证机制概述指针认证(Pointer Authentication,简称PAC)是Armv8.3-A架构引入的关键安全特性,旨在防御内存破坏攻击如ROP(Return-Oriented Programming)和JOP(Jump-Oriented Progr…...

从零构建操作系统内核:nokodo-labs/os1项目核心架构与实现解析
1. 项目概述:一个开源操作系统内核的诞生最近在开源社区里,一个名为nokodo-labs/os1的项目引起了我的注意。乍一看,这只是一个托管在代码平台上的仓库名,但“os1”这个后缀,对于任何一个有经验的开发者来说,…...

构建个人代码片段库:命令行工具snip的设计原理与实战应用
1. 项目概述:一个轻量级、可扩展的代码片段管理工具在开发日常中,我们总会遇到一些需要反复使用的代码片段:可能是某个框架的初始化配置,一个复杂的正则表达式,或者是一段处理特定业务逻辑的通用函数。把这些片段随手记…...

Sorcerer:AI应用开发的模块化工具箱,快速构建生产级智能系统
1. 项目概述:Sorcerer,一个面向AI应用开发的“魔法”工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫aetherci-hq/sorcerer。光看名字“Sorcerer”(巫师/术士),就透着一股神秘和强大的气…...

Qwen3-4B-Thinking入门必看:Gemini 2.5 Flash蒸馏模型本地化部署详解
Qwen3-4B-Thinking入门必看:Gemini 2.5 Flash蒸馏模型本地化部署详解 1. 模型概述 Qwen3-4B-Thinking-2507-Gemini-2.5-Flash-Distill是基于通义千问Qwen3-4B官方模型进行优化的版本。这个模型经过特殊训练,能够输出带有推理过程的思考链,特…...

深入V4L2内核:当DQBUF卡在wait_event时,我们该如何调试与自救?
深入V4L2内核:当DQBUF卡在wait_event时的调试与解决方案 在Linux视频开发领域,V4L2框架是连接用户空间和摄像头驱动的核心桥梁。然而,当用户态应用调用VIDIOC_DQBUF时,有时会遇到进程永久阻塞的情况,特别是在设备异常状…...

Embed-RL:强化学习优化多模态嵌入的智能框架
1. 项目概述Embed-RL是一个融合强化学习与多模态嵌入技术的智能推理框架。我在去年参与一个跨模态检索项目时,发现传统嵌入方法在处理视频-文本匹配任务时准确率始终卡在72%左右。经过三个月迭代,我们将强化学习引入嵌入空间优化过程,最终在相…...

Pydantic-Resolve:声明式数据组装解决N+1查询与API性能优化
1. 项目概述:用声明式思维解决嵌套数据组装难题如果你在开发后端API,尤其是需要聚合多个数据源的BFF(Backend for Frontend)层时,肯定遇到过这样的场景:前端需要一个包含用户详情、任务列表、评论等嵌套数据…...