Hive语法,函数--学习笔记
1,排序处理
1.1cluster by排序
,在Hive中使用order by排序时是全表扫描,且仅使用一个Reduce完成。
在海量数据待排序查询处理时,可以采用【先分桶再排序】的策略提升效率。此时,
就可以使用cluster by语法。
cluster by语句可以指定根据某字段将数据进行分桶,在桶内再根据这个字段进行正序排序
通俗地说,就是根据一个字段来排序,先分桶再排序。[分桶虚拟,自动处理]
cluster by语句的语法:
select * from 表名 cluster by 字段名; # 正序排序
– 程序中动态设定reduce值
set mapreduce.job.reduces = 桶数;
– 查看reduce值
set mapreduce.job.reduces;
当然了,若数据量较小(比如小于TB),Hive处理不占优势。
-- 查看reduce值
set mapreduce.job.reduces; -- 默认值是-1
set mapreduce.job.reduces = -1;
-- order by
select *
from tb_student
order by score; -- 数据量小: 效率高, 没有分桶操作
-- cluster by
select
*
from tb_student
cluster by score; -- 海量数据查询: 排序效率高
-- 看运行时间
-- 1.先直接测试order by与cluster by操作: 排序效果一样; 2.设定桶数,
看运行时间
当要先分桶再排序处理时,可以使用hive的cluster by
一般地,cluster by仅对字段做正序排序,即升序。
1.2distribute by+sort by排序
先分组,再排序的使用
select * from 表名 distribute by 字段名 sort by 字段名;
说明:
(1)distribute by表示先按字段名执行分组;
(2)sort by用于在分组内负责对某字段进行排序;
(3)当且仅当distribute by与sort by字段名一致时,等同于cluster by效果。
创建分桶表设定排序字段
create [external] table 表名(
字段名 字段类型 [comment '注释'],
字段名 字段类型 [comment '注释'],
...
)
[clustered by (字段名) sorted by (字段名) into 分桶数 buckets]
[row format delimited
fields terminated by '指定分隔符'];
2.排序操作:
①order by 普通排序
②over(order by ^) 窗口函数
③cluster by 先分桶在排序
④distribute by+ sort by 先分表后排序
⑤clustered by + sorted by 创建分桶表+自动排序
-- 1
select
*
from tb_student
distribute by gender
sort by score;
-- 3
create table tb_bucket_student(
id int,
name string,
gender string,
score double
)
clustered by (gender) sorted by (score) into 3 buckets
row format delimited
fields terminated by ",";
show tables ;
-- 4
-- 5
load data inpath "/itheima/student_data.txt" into table
tb_bucket_student;
-- 导入数据: hdfs
select * from tb_bucket_student;
(1)distribute by+sort by语句配合一起使用时,就是先分后排序的思想观
念;
(2)注意:当要提升对海量数据的访问效率时,一般可以对表进行分区或分
桶。
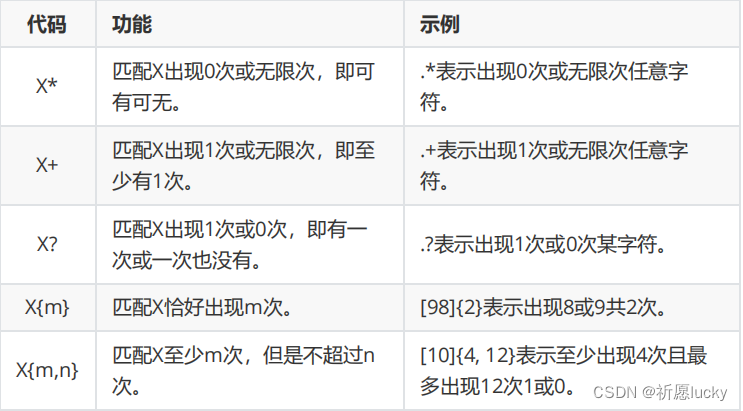
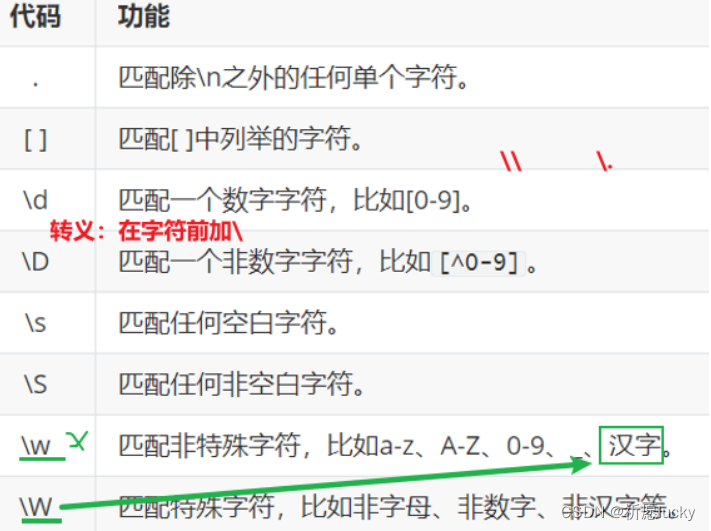
2.正则表达式
使用场景:在网站注册新用户时,对用户名、手机号等的验证就使用了正则表达式。
在Hive中,可以使用RLIKE进行正则匹配
select *|字段名1,字段名2,... from 表名 where 字段名 rlike "正则内容";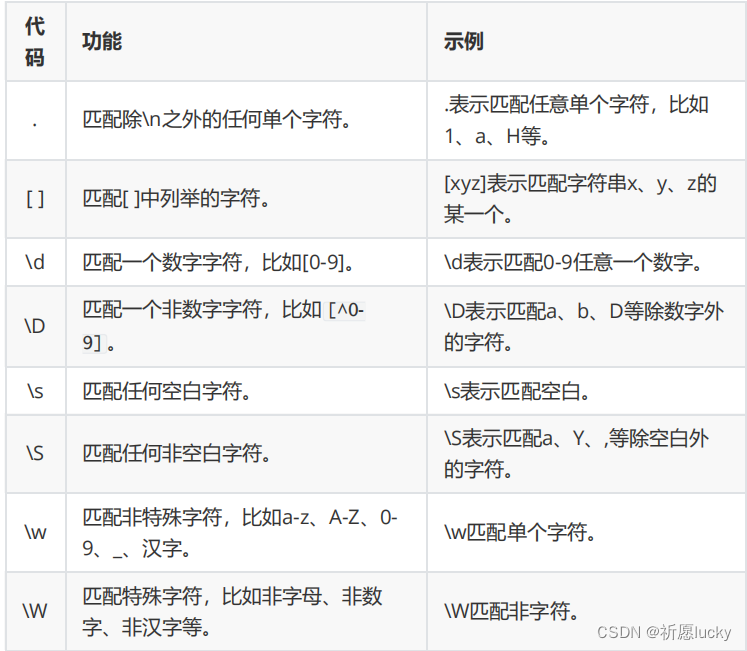

select
*
from tb_orders
where
userAddress rlike ".*广东省.*"
and
totalMoney > 5000;
-- 5
select
*
from tb_orders
where userAddress rlike ".*省 .*市 .*区.*";
正则就是一段特殊的字符串,而正则语法规范,需要多实践、多思考,才能更加熟练化。
3,union与CTE语法
3.1union联合
连接查询的特点是多个表进行【横向】合并在一起!
也可以完成纵向合并或追加数据操作。
union联合可用于将多个SELECT语句的结果集,组合形成单个完全结果集。
一起看看union联合,语法:
select 语句1
union [ all | distinct ]
select 语句2
[ union select 语句 ...];
说明:
(1)union all不对数据内容进行去重,默认使用union all;
(2)union distinct可实现数据去重,但必须添加distinct关键字;
(3)每个select语句返回的列数量、名称必须一致,否则,将引发字段架构错误。
-- 显示所有
select * from tb_course1
union all
select * from tb_course2;
select * from tb_course1 union select * from tb_course2; --
默认去重
-- 去掉重复
select * from tb_course1
union distinct
select * from tb_course2;-- 先联合, 再根据条件筛选数据
select
*
from
(select * from tb_course1
union all
select * from tb_course2) temp_course
where name in ("周杰轮", "王力鸿");
-- where name="周杰轮" or name="王力鸿";
(1)union可以用于将多个SELECT结果集合并,但要注意结果集的字段名、类型等架构要一致;
当使用union语句完成自动去除数据重复值时,记得设定为union distinct
3.2CTE语法
CTE(Common Table Expressions的缩写)公用表表达式,表示临时结果集。
CTE是一个在查询中,定义的临时命名结果集,并可在from子句中使用它。语法:
with 别名 as
(select查询语句)
[别名 as (select查询语句), ...]
select查询语句;
说明:
(1)每个CTE仅被定义一次,可被引用任意次,但是一旦此查询语句结束,cte
就失效;
(2)注意,CTE表达式仅在单个语句的执行范围内定义,并取别名。[from前置]
with stu as (
select * from tb_student
)
select * from stu;
-- 3
-- 先取别名, 引用, 再过滤
with stu as (
select * from tb_student
)
select * from stu where stu.gender="男"; // 好理解
with stu as (
select * from tb_student
)
select * from stu where gender="男";
with语句可以配合union一起使用
为了便于掌握union关键字,我们会发现:当union联合多表时,可以当成是一张完整数据表
4. 抽样、虚拟列
4.1抽样tablesample
解决的问题:
当数据量特别大时,对全体数据进行处理存在困难时,就可以抽取部分数据来进行处理,则显得尤为重要。
我们已知晓,在大数据体系且是真实的企业环境中,很容易出现超大数据容量的表,比如体积达到TB/PB级别。
对这种表一个简单的SELECT * 都会非常的慢,
哪怕LIMIT 10想要看10条数据,
我们发现,有可能也会走MapReduce计算流程。
这种时间等待是漫长且不合适的......
Hive支持抽样,需要使用tablesample语法:
select * from 表名 tablesample (bucket x out of y [on colname字段名|rand()]);
说明:(1)y表示桶的数量,比如设定为值5,则表示5桶;
(2)x是要抽样的桶编号,桶编号从1开始计算,colname字段名表示抽样的列(也就是按照那个字段分桶);
(3)使用rand()表明在整个行中抽取样本而不是单个列;
(4)翻译为:按照colname字段名分成y桶,抽取其中的第x桶。
select
*
from tb_orders
-- tablesample ( bucket 1 out of 6 on userName); -- 数据倾斜
tablesample ( bucket 2 out of 6 on userName); -- 数据倾斜
-- 3
select
*
from tb_orders
tablesample ( bucket 4 out of 5 on orderNo);
-- 4
select
*
from tb_orders
tablesample ( bucket 2 out of 10 on rand());
当要快速从海量数据表中采样部分数据量,可以使用tablesample();函数;
(2)使用部分数据采样形式,能提升获取局部数据量的效率,便于在调试海量数据的程序时使用。
4.2虚拟列
虚拟列表示未在表中真正存在的字段,在创建分区表中,分区列就是虚拟列的一个体现!
为了将Hive中的表进行分区(partition),这对每日增长的海量数据存储而言,是非常有用的。
为了保证HiveQL的高效运行,强烈推荐在where语句后,使用虚拟列(分区列)作为限定。[拿Web日志举例说明。]
2,Hive中有3个可用的虚拟列:
(1)INPUT__FILE__NAME
显示数据行所在的具体文件
(2)BLOCK__OFFSET__INSIDE__FILE
显示数据行所在文件的偏移量
(3)ROW__OFFSET__INSIDE__BLOCK # 没提示, 且默认不开启-需设置参数
[单独说明]
显示数据所在HDFS块的偏移量
# 偏移量指的是获取数据时,指针所在位置
对于 ROW__OFFSET__INSIDE__BLOCK 虚拟列,要设置参数:
-- 查看数据在HDFS块的偏移量设置是否开启
set hive.exec.rowoffset;
-- 设置开启
set hive.exec.rowoffset=true;
-- 若要关闭, 则需要重新设置为false-- 若要关闭, 则需要重新设置为false
set hive.exec.rowoffset=false;
-- 5
use sz41db_bucket;
show tables ;
select
*,
INPUT__FILE__NAME,
BLOCK__OFFSET__INSIDE__FILE
from bucket_id_course;
(1)简单地说,虚拟列就是Hive内置在查询语句中的几个特殊标记,可直接取用
(2)当要在查询结果中显示数据文件名信息,可以使用 INPUT__FILE__NAME虚拟列。
5,Hive基础函数
了解Hive函数有哪些分类?
在Hive中,有一些能直接被调用使用,比如类似于current_database()调用方式:
Hive的函数,可分为两大类:
(1)内置函数(Built-in Functions)
数学函数
日期函数
字符串函数
条件函数
类型转换函数
数据脱敏函数
(2)用户定义函数(User-Defined Functions)
UDF(User Defined Functions)用户定义功能函数
UDAF(User Defined Aggregate Functions)用户定义聚合函数
UDTF(User Defined Table-generating Functions)用户定义表生成函数
内置函数属于Hive基础函数、用户定义函数属于Hive进阶函数。
-- 查看可用的所有函数
show functions;
-- 查看函数的使用方式
desc function extended 函数名;
当要查看某函数如何使用时,可以使用desc function extended 函数名语句查看帮助信息
在Hive中,当要使用函数时, 语法为[select 函数名(xx);]。
5.1]数学函数
rand() 获取一个完全随机数,取值范围0-1。 double
round(x [, y]) 取整/设置小数精度(四舍五入)。 double
select round(3.141592654,2);
select round(3.141592654);
-- 3
select rand()*100;
select round(rand()*100);
当要保留浮点数后几位小数时,推荐使用round()函数
一般地,数学函数主要是用于处理各类数值型内容项
5.2日期函数
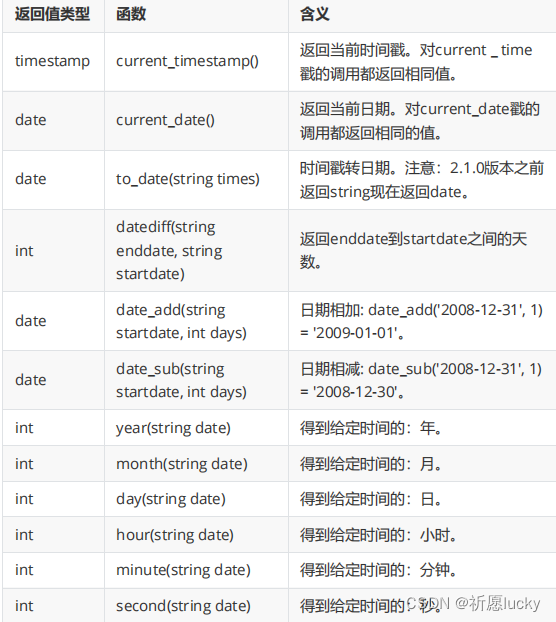
select current_date();
desc function extended year; -- 有用
select year(`current_date`());
select year(`current_timestamp`());
select year("2023-11-14");
-- desc function extended month;
select month(current_date());
select day(current_date());
desc function extended hour;
select hour(current_timestamp());
select minute(current_timestamp());
select second(current_timestamp());
(2)通常情况下,当要处理时间日期时,要想到Hive中常用的日期函数。
5.3字符串函数
在Hive中,常用的字符串函数有:

-- 1
select concat("hello","WORLD");
select concat_ws("=","hello","WORLD");
-- 1-10-100-20
select split("1-10-100-20","-");
select split("1-10-100-20","-")[0];
-- 2
-- Hello Heima
select length("Hello Heima");
select lower("Hello Heima");
select upper("Hello Heima");
-- 3
-- 2022-08-22 17:28:01
-- 通过日期函数year()
select year("2022-08-22 17:28:01");
-- 截取
select substr("2022-08-22 17:28:01",0,3); // 无法截取到结束位end
select substr("2022-08-22 17:28:01",0,4);
-- select substring()
-- 分割, 提取
select split("2022-08-22 17:28:01","-")[0];
字符串函数通常用于处理string、varchar等字符串类型的数据结果。
5.4条件函数、转换类型
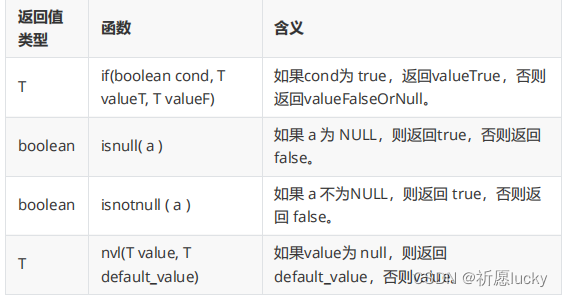
1,类型转换函数有:
cast(expras) 将expr值强制转换为给定类型type。例如,cast(‘1’ as int会将字符串 ‘1’ 转换为整数。
select current_database();
-- if
select if(1=1,"男","女");
select if(1=0,"男","女"); -- 等号 =; 后期编程语言中, 等号==
-- isnull
select isnull(null);
select isnull("hello"); -- 没约束, 判断
-- isnotnull
select isnotnull(null);
select isnotnull("hello");
select nvl(null,18); -- 没有年龄值, 则默认为18岁
select nvl(20,18);
-- cast
select cast("100" as int);
select cast(12.14 as string); -- double
select cast("hello" as int);
-- 1700096276154
select cast(1700096276154/1000 as int); -- 1700096276 秒[10位数]-格式
强制类型转换在Hive中不一定成功,若不成功,则会返回null值。
5.5 数据脱敏函数
我们知道,当把元数据存储在MySQL中,需要将元数据中敏感部分(如身份证、电话号码等)进行脱敏处理,再供用户使用
通俗地说,就是进行掩码处理,或者加密处理。

select mask_hash("123ABC");
select mask("123ABC");
select mask("AB12aa"); -- XXnnxx
-- 2
select mask_first_n("AA11nn8989AAAAAAA",4);
select mask_last_n("AA11nn8989AAAAAAA",4);
select mask_show_first_n("it66ABCDE",3);
select mask_show_last_n("it66ABCDE",3);
,要做数据脱敏操作,可以根据mask单词看DataGrip的快捷提示,并选择使用某个。
5.6其他函数
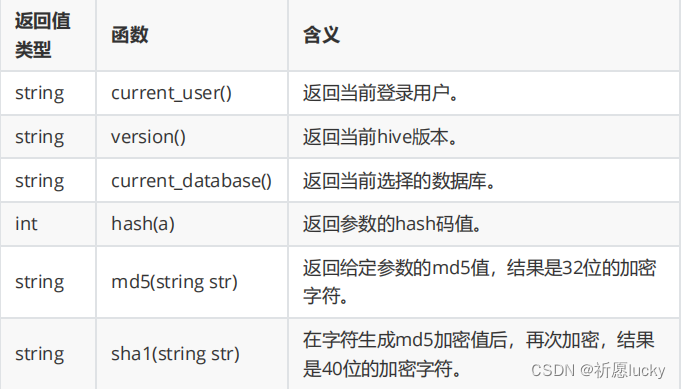
select hash("123456"); -- hash 哈希算法(散列算法) = 哈希码
select md5("123456"); -- e10adc3949ba59abbe56e057f20f883e
32位/不可逆的 动态值绑定了结果?
select sha1("123456"); --
7c4a8d09ca3762af61e59520943dc26494f8941b
-- 3
select length("e10adc3949ba59abbe56e057f20f883e");
select length("7c4a8d09ca3762af61e59520943dc26494f8941b");
-- 4 转换日期格式 转换为年月日 1700096276154
desc function date_format;
desc function from_unixtime;
-- a.把毫秒转换为秒, int
select cast(1700096276154/1000 as int);
-- b.使用函数即可
select from_unixtime(cast(1700096276154/1000 as int),"yyyyMM-dd");
select year(from_unixtime(cast(1700096276154/1000 as int),"yyyy-MM-dd"));
对于Hive函数的使用,若在应用中,还发现有新需求,可以通过查阅Hive函数资料来解决。
6.Hive高阶函数
用户自定义函数有:
用户定义函数(User-Defined Functions)
(1)UDF(User Defined Functions)用户定义功能函数
(2)UDTF(User Defined Table-generating Functions)用户定义表生成函数
(3)UDAF(User Defined Aggregate Functions)用户定义聚合函数
说明:
(1)最初,UDF、UDAF、UDTF这3个标准,是针对用户自定义函数分类的;
(2)目前,可以将这个分类标准直接扩大到Hive中的所有函数,包括内置函数和自定义函数
(1)UDF(User Defined Functions)用户定义功能函数
UDF函数可以理解为:普通函数。用于一进一出,即当输入一行数据时,则输出一行数据。比较常见的有split()分割函数。
select split("10-20-30-40","-");
-- 结果: ["10","20","30","40"]
(2)UDTF(User Defined Table-generating Functions)用户定义表生成函数
UDTF用于表生成函数。用于一进多出,即当输入一行时,则输出多行数据。比较常见的有:explode()。
(3)UDAF(User Defined Aggregate Functions)用户定义聚合函数
UDAF可表示为:聚合函数。用于多进一出,即当输入多行时,则输出一行数据。
6.1窗口函数
select
字段名, …
窗口函数() over([partition by xx order by xx [asc | desc]])
from 表名;
说明:
(1)窗口函数名可以是聚合函数,例如sum()、count()、avg()等,也可以是分
析函数;
(2)聚合函数有count()、sum()、avg()、min()、max();
(3)分析函数有row_number、rank、dense_rank等;
(4)partition by用于分组、order by用于排序。
当要把某数据列添加到数据表时,可以使用窗口函数over()关键字
6.2json数据处理
JSON的全称是:JavaScript Object Notation,即JS对象标记法。在很多开发场景里,JSON数据传输很常见!
(1)数组(Array)用中括号[ ]表示;
(2)对象(0bject)用大括号{ }表示。
说明:在Hive中,没有json类的存在,一般使用string类型来修饰,叫做json字符串。
get_json_object(json_txt, path) 用于解析json字符串
说明:path参数通常可用于获取json中的数据内容,语法:“$.key”。
select
get_json_object(data,"$.device")
from json_device;
select
get_json_object(data,"$.device") device,
get_json_object(data,"$.deviceType") divece_type,
get_json_object(data,"$.signal") signal,
get_json_object(data,"$.time") int_time
from json_device;split(from_unixtime(cast(get_json_object(data,"$.time")/1000
as int),"yyyy/MM/dd"),"/")[0] year,
6.3 炸裂函数
explode()可用于表生成函数,一进多出,即当输入一行时,则输出多行数据。
通俗地说,就是可以使用explode()炸开数据。
explode(array | mapdata)
用于炸裂数据内容,并分开数据结果。
通常情况下,炸裂函数会与侧视图配合一起使用。
侧视图(lateral view)原理是:
(1)将UDTF的结果构建成一个类似于视图的表;
(2)然后,将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。
ateral view侧视图语法:
select ... from 表A 别名
lateral view
UDTF(xxx) 别名 as 列名1, 列名2, 列名3, ...;
create table table_nba(
team_name string,
champion_year array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';select * from tb_nba;
-- a.单独获取到冠军年份
select
explode(champion_year)
from tb_nba;
-- b.显示出来??
select
*,
explode(champion_year) //报错了
from tb_nba;-- 对year进行一个升序排序处理
select
*
from
(select
a.team_name,
b.year
from tb_nba a
lateral view
explode(champion_year) b as year) temp_nba
order by temp_nba.year;
select
*
from
(select
a.team_name,
b.year
from tb_nba a
lateral view
explode(champion_year) b as year) temp_nba
order by cast(temp_nba.year as int);
炸裂函数把数据炸开后,若在处理时遇到一些问题,可以考虑引入侧视图配合使用
相关文章:
Hive语法,函数--学习笔记
1,排序处理 1.1cluster by排序 ,在Hive中使用order by排序时是全表扫描,且仅使用一个Reduce完成。 在海量数据待排序查询处理时,可以采用【先分桶再排序】的策略提升效率。此时, 就可以使用cluster by语法。 cluster…...

LeetCode热题100——动态规划
动态规划 1. 爬楼梯2. 杨辉三角3. 打家劫舍 1. 爬楼梯 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? // 题解:每次都有两种选择,1或者2 int climbStairs(int n) {if (n …...
初识树(c语言)
树 定义:树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。 有一个特殊的结点,称为根结点,根节点没有前驱结点 除根节点外,其余结点被分成M(M>0)个互不相交…...

听GPT 讲Rust源代码--src/librustdoc(2)
题图来自 Chromium项目将支持Rust编程语言[1] File: rust/src/librustdoc/html/render/search_index.rs 在Rust源代码中,rust/src/librustdoc/html/render/search_index.rs文件的作用是生成搜索索引,用于在Rust文档页面上进行关键字搜索。该文件实现了一…...
多目标应用:基于非支配排序的蜣螂优化算法NSDBO求解微电网多目标优化调度(MATLAB)
一、微网系统运行优化模型 微电网优化模型介绍: 微电网多目标优化调度模型简介_IT猿手的博客-CSDN博客 二、基于非支配排序的蜣螂优化算法NSDBO 基于非支配排序的蜣螂优化算法NSDBO简介: https://blog.csdn.net/weixin46204734/article/details/128…...

泉盛UV-K5/K6全功能中文固件
https://github.com/wu58430/uv-k5-firmware-chinese/releases 主要功能: 中文菜单 许多来自 OneOfEleven 的模块: AM 修复,显著提高接收质量长按按钮执行 F 操作的功能复制快速扫描菜单中的频道名称编辑频道名称 频率显示选项扫描列表分配…...

基于JPBC的无证书聚合签名方案实现
基于JPBC的无证书聚合签名方案实现 摘要 一开始签名方案是基于PKI的,无证书签名起源于 基于身份密码体制, 2009 年第一篇无证书签名方案1被提出,随后出现了一些列方案2,3;包括无配对的无证书聚合签名方案4,更多内容参考文献5. 暂时没有看见…...
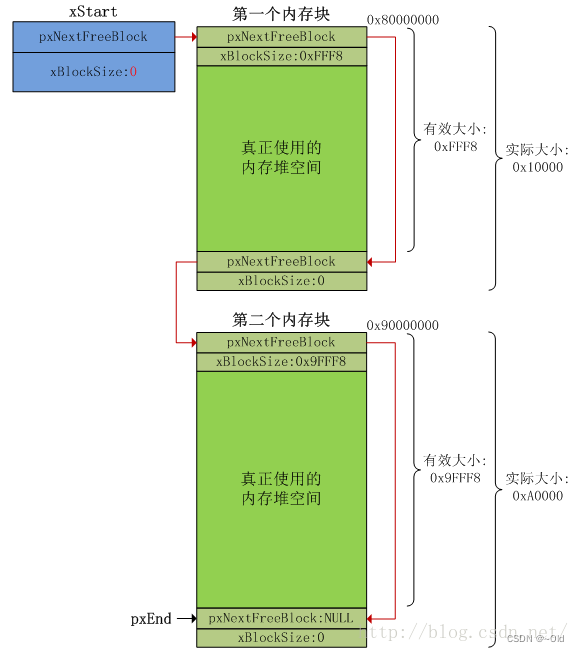
FreeRTOS内存管理分析
目录 heap_1.c内存管理算法 heap_2.c内存管理算法 heap_3.c内存管理算法 heap_4.c内存管理算法 heap_5.c内存管理算法 内存管理对应用程序和操作系统来说非常重要,而内存对于嵌入式系统来说是寸土寸金的资源,FreeRTOS操作系统将内核与内存管理分开实…...

hashMap索引原理
平日里面经常使用map这种数据结构,令人称奇的是他的访问速度为什么那么快?为什么可以通过key以接近O(1)的速度查找? 一、基础数据结构特点分析 1.1数组 查找的时间复杂度为O(1) 插入时间复杂度为O(n) 1.2链表 查找的时间复杂度为O(n) 插…...

qcow2、raw、vmdk等镜像格式工具
如果没有qemu,可以从这里下载安装:https://qemu.weilnetz.de/w64/...
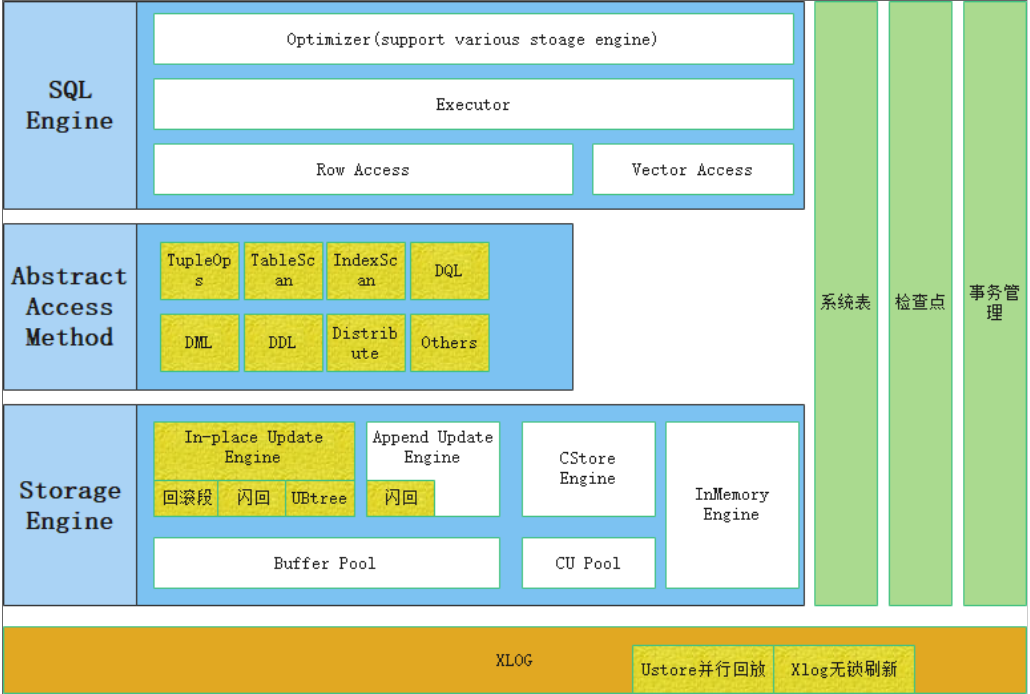
GaussDB新特性Ustore存储引擎介绍
1、 Ustore和Astore存储引擎介绍 Ustore存储引擎,又名In-place Update存储引擎(原地更新),是openGauss 内核新增的一种存储模式。此前的版本使用的行存储引擎是Append Update(追加更新)模式。相比于Append…...
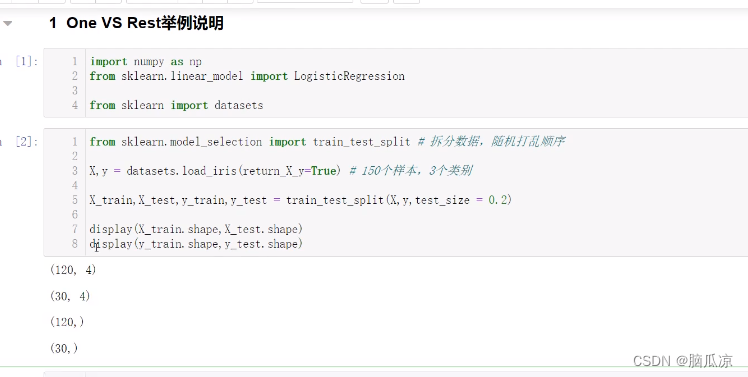
人工智能基础_机器学习046_OVR模型多分类器的使用_逻辑回归OVR建模与概率预测---人工智能工作笔记0086
首先我们来看一下什么是OVR分类.我们知道sigmoid函数可以用来进行二分类,那么多分类怎么实现呢?其中一个方法就是使用OVR进行把多分类转换成二分类进行计算. OVR,全称One-vs-Rest,是一种将多分类问题转化为多个二分类子问题的策略。在这种策略中,多分类问题被分解为若干个二…...
【LeetCode刷题-链表】--23.合并K个升序链表
23.合并K个升序链表 方法:顺序合并 在前面已经知道合并两个升序链表的前提下,用一个变量ans来维护以及合并的链表,第i次循环把第i个链表和ans合并,答案保存到ans中 /*** Definition for singly-linked list.* public class List…...

强化学习笔记
这里写自定义目录标题 参考资料基础知识16.3 有模型学习16.3.1 策略评估16.3.2 策略改进16.3.3 策略迭代16.3.3 值迭代 16.4 免模型学习16.4.1 蒙特卡罗强化学习16.4.2 时序差分学习Sarsa算法:同策略算法(on-policy):行为策略是目…...

经典双指针算法试题(一)
📘北尘_:个人主页 🌎个人专栏:《Linux操作系统》《经典算法试题 》《C》 《数据结构与算法》 ☀️走在路上,不忘来时的初心 文章目录 一、移动零1、题目讲解2、讲解算法原理3、代码实现 二、复写零1、题目讲解2、讲解算法原理3、…...
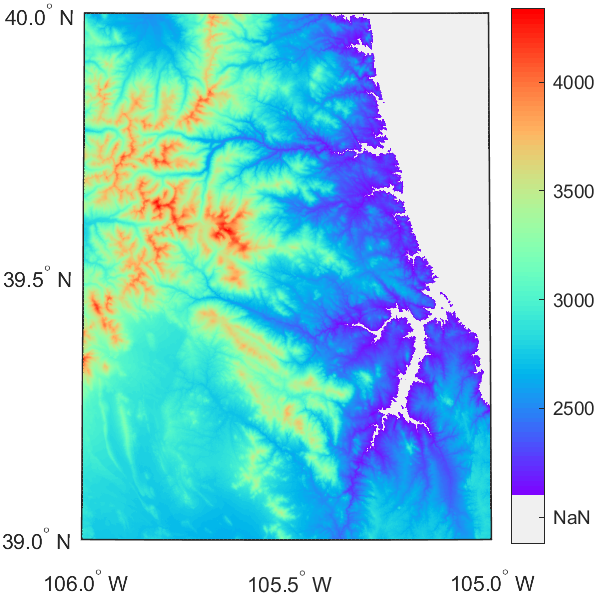
MATLAB | 绘图复刻(十三) | 带NaN图例的地图绘制
有粉丝问我地图绘制如何添加NaN,大概像这样: 或者这样: 直接上干货: 原始绘图 假设我们有这样的一张图地图,注意运行本文代码需要去matlab官网下载Mapping Toolbox工具箱,但是其实原理都是相似的&…...

netty整合websocket(完美教程)
websocket的介绍: WebSocket是一种在网络通信中的协议,它是独立于HTTP协议的。该协议基于TCP/IP协议,可以提供双向通讯并保有状态。这意味着客户端和服务器可以进行实时响应,并且这种响应是双向的。WebSocket协议端口通常是80&am…...

选择PC示波器的10种理由!
PC示波器(PCs)在测试仪器领域中的关键项目上正迅速地取代传统的数字存储示波器(DSOs),其中有十个理由: 小巧和便携示波器利用你的PC显示器实现大屏幕和精细彩色显示信号存储只受限于你的PC存储器大小捕捉波…...
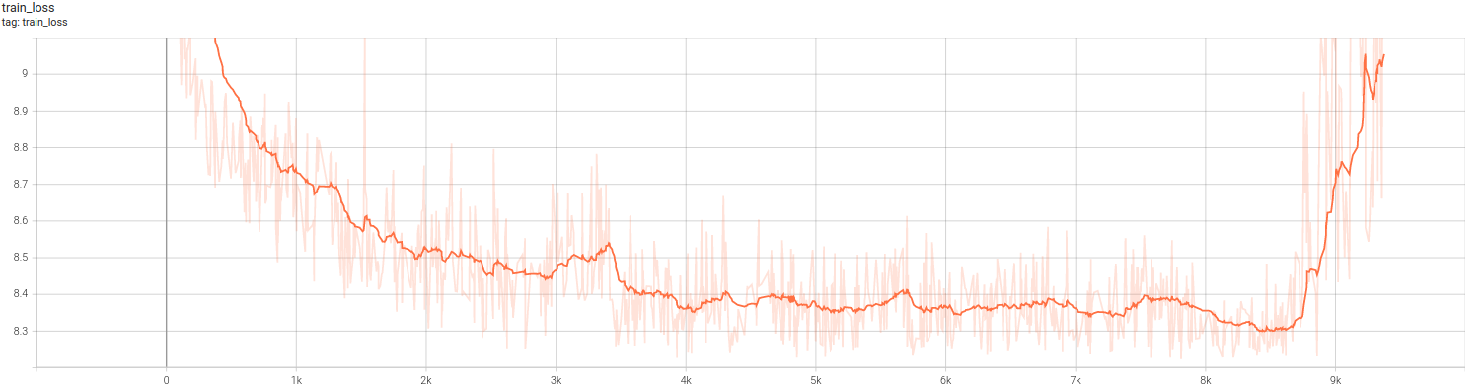
【pytorch深度学习 应用篇02】训练中loss图的解读,训练中的问题与经验汇总
文章目录 loss图解析train loss ↘ \searrow ↘ ↗ \nearrow ↗ 先降后升 loss图解析 train loss ↘ \searrow ↘ 不断下降,test loss ↗ \nearrow ↗ 不断上升:原因很多,我是把workers1,batchSize8192train loss ↘ \searro…...

uniapp 微信小程序如何实现多个item列表的分享
以下代码是某个循环里面的item <button class"cu-btn" style"background-color: transparent;padding: 0;"open-type"share" :data-tree"item.treeId" :data-project"item.projectId"v-if"typeId1 && userI…...

Redis分布式锁进阶第三十五篇
Redis分布式锁进阶第二十五篇:联锁深度拆解 多资源交叉死锁根治 复杂业务多级加锁绝对有序方案一、本篇前置衔接 第二十四篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实…...

模拟信号数字化中的混叠现象与抗混叠滤波器设计
1. 模拟信号数字化中的混叠现象解析 在工业测量和数据采集领域,我们经常需要将现实世界中的连续模拟信号转换为离散的数字信号进行处理。这个看似简单的过程却隐藏着一个关键陷阱——混叠(Aliasing)。就像老式西部片中马车轮子看似倒转的视觉…...

SiC晶圆CMP工艺革新:如何攻克高硬度材料平坦化难题并降低综合成本
1. 项目概述:CMP如何重塑SiC晶圆制造的经济账在第三代半导体,尤其是碳化硅(SiC)的制造领域,成本一直是制约其大规模应用的关键瓶颈。一块高质量的SiC晶圆,其价格远高于传统的硅晶圆,这背后是复杂…...

突破OBS音频局限:揭秘如何为直播软件添加专业级VST插件支持
突破OBS音频局限:揭秘如何为直播软件添加专业级VST插件支持 【免费下载链接】obs-vst Use VST plugins in OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-vst 想要在OBS Studio中实现专业级的音频处理,却受限于内置的基础滤镜?…...

小米Agent岗二面:RAG知识库文档更新,不重建全量就搞不定?
👔面试官:你们 RAG 知识库上线之后,文档更新了怎么办?总不能每次改个文档就把整个知识库重建一遍吧。 🙋♂️我:可以直接找到变了的那个 chunk,更新它的向量就行了。 👔面试官&a…...

从SITS2026看AISMM评估拐点:为什么头部企业已在Q2完成差距分析与基线对标?
更多请点击: https://intelliparadigm.com 第一章:SITS2026演讲:AISMM评估的行业影响 在2026年系统智能与可信安全国际峰会(SITS2026)上,AISMM(AI Security Maturity Model)评估框架…...

HST-Bench:人类解题耗时评估数据集构建与应用
1. 项目背景与核心价值去年参与某智能体评估项目时,我们团队曾陷入一个尴尬境地——现有基准测试集无法真实反映人类解决问题的实际耗时。当算法在标准数据集上跑出"5秒完成"的漂亮成绩时,实际业务场景中用户可能需要花费3分钟才能解决相同问题…...

Zsh-Ask:在终端无缝集成ChatGPT的极简AI助手插件
1. 项目概述与核心价值 如果你和我一样,是个重度命令行用户,每天大部分时间都泡在终端里,那么你一定遇到过这样的场景:写脚本时卡在一个正则表达式上,想不起来某个命令的某个参数怎么用,或者突然想不起来某…...

别只盯着YOLOv8检测!用Comake D1的IPU解锁人体姿态估计,实测40ms一帧的落地效果
边缘AI新选择:Comake D1开发板实战YOLOv8-pose人体姿态估计 当YOLOv8在目标检测领域大放异彩时,它的"孪生兄弟"YOLOv8-pose却鲜少被边缘计算开发者关注。这款专为人体姿态估计优化的算法,配合Comake D1开发板的IPU加速,…...

当你的Android设备‘睡不醒’:wakelock机制详解与常见问题排查
当你的Android设备“睡不醒”:wakelock机制详解与常见问题排查 你是否遇到过这样的情况:明明已经锁屏了,但手机电量却消耗得异常快?或者设备在应该休眠的时候依然保持活跃,导致发热和续航缩水?这些问题很可…...