(Transfer Learning)迁移学习在IMDB上训练情感分析模型
1. 背景
有些场景下,开始的时候数据量很小,如果我们用一个几千条数据训练一个全新的深度机器学习的文本分类模型,效果不会很好。这个时候你有两种选择,1.用传统的机器学习训练,2.利用迁移学习在一个预训练的模型上训练。本博客教你怎么用tensorflow Hub和keras 在少量的数据上训练一个文本分类模型。
2. 实践
2.1. 下载IMDB 数据集,参考下面博客。
Imdb影评的数据集介绍与下载_imdb影评数据集-CSDN博客
2.2. 预处理数据
替换掉imdb目录 (imdb_raw_data_dir). 创建dataset目录。
import numpy as np
import os as osimport re
from sklearn.model_selection import train_test_splitvocab_size = 30000
maxlen = 200
imdb_raw_data_dir = "/Users/harry/Documents/apps/ml/aclImdb"
save_dir = "dataset"def get_data(datapath =r'D:\train_data\aclImdb\aclImdb\train' ):pos_files = os.listdir(datapath + '/pos')neg_files = os.listdir(datapath + '/neg')print(len(pos_files))print(len(neg_files))pos_all = []neg_all = []for pf, nf in zip(pos_files, neg_files):with open(datapath + '/pos' + '/' + pf, encoding='utf-8') as f:s = f.read()s = process(s)pos_all.append(s)with open(datapath + '/neg' + '/' + nf, encoding='utf-8') as f:s = f.read()s = process(s)neg_all.append(s)print(len(pos_all))# print(pos_all[0])print(len(neg_all))X_orig= np.array(pos_all + neg_all)# print(X_orig)Y_orig = np.array([1 for _ in range(len(pos_all))] + [0 for _ in range(len(neg_all))])print("X_orig:", X_orig.shape)print("Y_orig:", Y_orig.shape)return X_orig, Y_origdef generate_dataset():X_orig, Y_orig = get_data(imdb_raw_data_dir + r'/train')X_orig_test, Y_orig_test = get_data(imdb_raw_data_dir + r'/test')X_orig = np.concatenate([X_orig, X_orig_test])Y_orig = np.concatenate([Y_orig, Y_orig_test])X = X_origY = Y_orignp.random.seed = 1random_indexs = np.random.permutation(len(X))X = X[random_indexs]Y = Y[random_indexs]X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)print("X_train:", X_train.shape)print("y_train:", y_train.shape)print("X_test:", X_test.shape)print("y_test:", y_test.shape)np.savez(save_dir + '/train_test', X_train=X_train, y_train=y_train, X_test= X_test, y_test=y_test )def rm_tags(text):re_tag = re.compile(r'<[^>]+>')return re_tag.sub(' ', text)def clean_str(string):string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)string = re.sub(r"\'s", " \'s", string) # it's -> it 'sstring = re.sub(r"\'ve", " \'ve", string) # I've -> I 'vestring = re.sub(r"n\'t", " n\'t", string) # doesn't -> does n'tstring = re.sub(r"\'re", " \'re", string) # you're -> you arestring = re.sub(r"\'d", " \'d", string) # you'd -> you 'dstring = re.sub(r"\'ll", " \'ll", string) # you'll -> you 'llstring = re.sub(r"\'m", " \'m", string) # I'm -> I 'mstring = re.sub(r",", " , ", string)string = re.sub(r"!", " ! ", string)string = re.sub(r"\(", " \( ", string)string = re.sub(r"\)", " \) ", string)string = re.sub(r"\?", " \? ", string)string = re.sub(r"\s{2,}", " ", string)return string.strip().lower()def process(text):text = clean_str(text)text = rm_tags(text)#text = text.lower()return textif __name__ == '__main__':generate_dataset()执行完后,产生train_test.npz 文件
2.3. 训练模型
1. 取数据集
def get_dataset_to_train():train_test = np.load('dataset/train_test.npz', allow_pickle=True)x_train = train_test['X_train']y_train = train_test['y_train']x_test = train_test['X_test']y_test = train_test['y_test']return x_train, y_train, x_test, y_test2. 创建模型
基于nnlm-en-dim50/2 预训练的文本嵌入向量,在模型外面加了两层全连接。
def get_model():hub_layer = hub.KerasLayer(embedding_url, input_shape=[], dtype=tf.string, trainable=True)# Build the modelmodel = Sequential([hub_layer,Dense(16, activation='relu'),Dropout(0.5),Dense(2, activation='softmax')])print(model.summary())model.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(),metrics=[keras.metrics.SparseCategoricalAccuracy()])return model还可以使用来自 TFHub 的许多其他预训练文本嵌入向量:
- google/nnlm-en-dim128/2 - 基于与 google/nnlm-en-dim50/2 相同的数据并使用相同的 NNLM 架构进行训练,但具有更大的嵌入向量维度。更大维度的嵌入向量可以改进您的任务,但可能需要更长的时间来训练您的模型。
- google/nnlm-en-dim128-with-normalization/2 - 与 google/nnlm-en-dim128/2 相同,但具有额外的文本归一化,例如移除标点符号。如果您的任务中的文本包含附加字符或标点符号,这会有所帮助。
- google/universal-sentence-encoder/4 - 一个可产生 512 维嵌入向量的更大模型,使用深度平均网络 (DAN) 编码器训练。
还有很多!在 TFHub 上查找更多文本嵌入向量模型。
3. 评估你的模型
def evaluate_model(test_data, test_labels):model = load_trained_model()# Evaluate the modelresults = model.evaluate(test_data, test_labels, verbose=2)print("Test accuracy:", results[1])def load_trained_model():# model = get_model()# model.load_weights('./models/model_new1.h5')model = tf.keras.models.load_model('models_pb')return model4. 测试几个例子
def predict(real_data):model = load_trained_model()probabilities = model.predict([real_data]);print("probabilities :",probabilities)result = get_label(probabilities)return resultdef get_label(probabilities):index = np.argmax(probabilities[0])print("index :" + str(index))result_str = index_dic.get(str(index))# result_str = list(index_dic.keys())[list(index_dic.values()).index(index)]return result_strdef predict_my_module():# review = "I don't like it"# review = "this is bad movie "# review = "This is good movie"review = " this is terrible movie"# review = "This isn‘t great movie"# review = "i think this is bad movie"# review = "I'm not very disappoint for this movie"# review = "I'm not very disappoint for this movie"# review = "I am very happy for this movie"#neg:0 postive:1s = predict(review)print(s)if __name__ == '__main__':x_train, y_train, x_test, y_test = get_dataset_to_train()model = get_model()model = train(model, x_train, y_train, x_test, y_test)evaluate_model(x_test, y_test)predict_my_module()完整代码
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Dropout
import keras as keras
from keras.callbacks import EarlyStopping, ModelCheckpoint
import tensorflow_hub as hubembedding_url = "https://tfhub.dev/google/nnlm-en-dim50/2"index_dic = {"0":"negative", "1": "positive"}def get_dataset_to_train():train_test = np.load('dataset/train_test.npz', allow_pickle=True)x_train = train_test['X_train']y_train = train_test['y_train']x_test = train_test['X_test']y_test = train_test['y_test']return x_train, y_train, x_test, y_testdef get_model():hub_layer = hub.KerasLayer(embedding_url, input_shape=[], dtype=tf.string, trainable=True)# Build the modelmodel = Sequential([hub_layer,Dense(16, activation='relu'),Dropout(0.5),Dense(2, activation='softmax')])print(model.summary())model.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(),metrics=[keras.metrics.SparseCategoricalAccuracy()])return modeldef train(model , train_data, train_labels, test_data, test_labels):# train_data, train_labels, test_data, test_labels = get_dataset_to_train()train_data = [tf.compat.as_str(tf.compat.as_bytes(str(x))) for x in train_data]test_data = [tf.compat.as_str(tf.compat.as_bytes(str(x))) for x in test_data]train_data = np.asarray(train_data) # Convert to numpy arraytest_data = np.asarray(test_data) # Convert to numpy arrayprint(train_data.shape, test_data.shape)early_stop = EarlyStopping(monitor='val_sparse_categorical_accuracy', patience=4, mode='max', verbose=1)# 定义ModelCheckpoint回调函数# checkpoint = ModelCheckpoint( './models/model_new1.h5', monitor='val_sparse_categorical_accuracy', save_best_only=True,# mode='max', verbose=1)checkpoint_pb = ModelCheckpoint(filepath="./models_pb/", monitor='val_sparse_categorical_accuracy', save_weights_only=False, save_best_only=True)history = model.fit(train_data[:2000], train_labels[:2000], epochs=45, batch_size=45, validation_data=(test_data, test_labels), shuffle=True,verbose=1, callbacks=[early_stop, checkpoint_pb])print("history", history)return modeldef evaluate_model(test_data, test_labels):model = load_trained_model()# Evaluate the modelresults = model.evaluate(test_data, test_labels, verbose=2)print("Test accuracy:", results[1])def predict(real_data):model = load_trained_model()probabilities = model.predict([real_data]);print("probabilities :",probabilities)result = get_label(probabilities)return resultdef get_label(probabilities):index = np.argmax(probabilities[0])print("index :" + str(index))result_str = index_dic.get(str(index))# result_str = list(index_dic.keys())[list(index_dic.values()).index(index)]return result_strdef load_trained_model():# model = get_model()# model.load_weights('./models/model_new1.h5')model = tf.keras.models.load_model('models_pb')return modeldef predict_my_module():# review = "I don't like it"# review = "this is bad movie "# review = "This is good movie"review = " this is terrible movie"# review = "This isn‘t great movie"# review = "i think this is bad movie"# review = "I'm not very disappoint for this movie"# review = "I'm not very disappoint for this movie"# review = "I am very happy for this movie"#neg:0 postive:1s = predict(review)print(s)if __name__ == '__main__':x_train, y_train, x_test, y_test = get_dataset_to_train()model = get_model()model = train(model, x_train, y_train, x_test, y_test)evaluate_model(x_test, y_test)predict_my_module()相关文章:
(Transfer Learning)迁移学习在IMDB上训练情感分析模型
1. 背景 有些场景下,开始的时候数据量很小,如果我们用一个几千条数据训练一个全新的深度机器学习的文本分类模型,效果不会很好。这个时候你有两种选择,1.用传统的机器学习训练,2.利用迁移学习在一个预训练的模型上训练…...
蓝桥杯每日一题2023.11.20
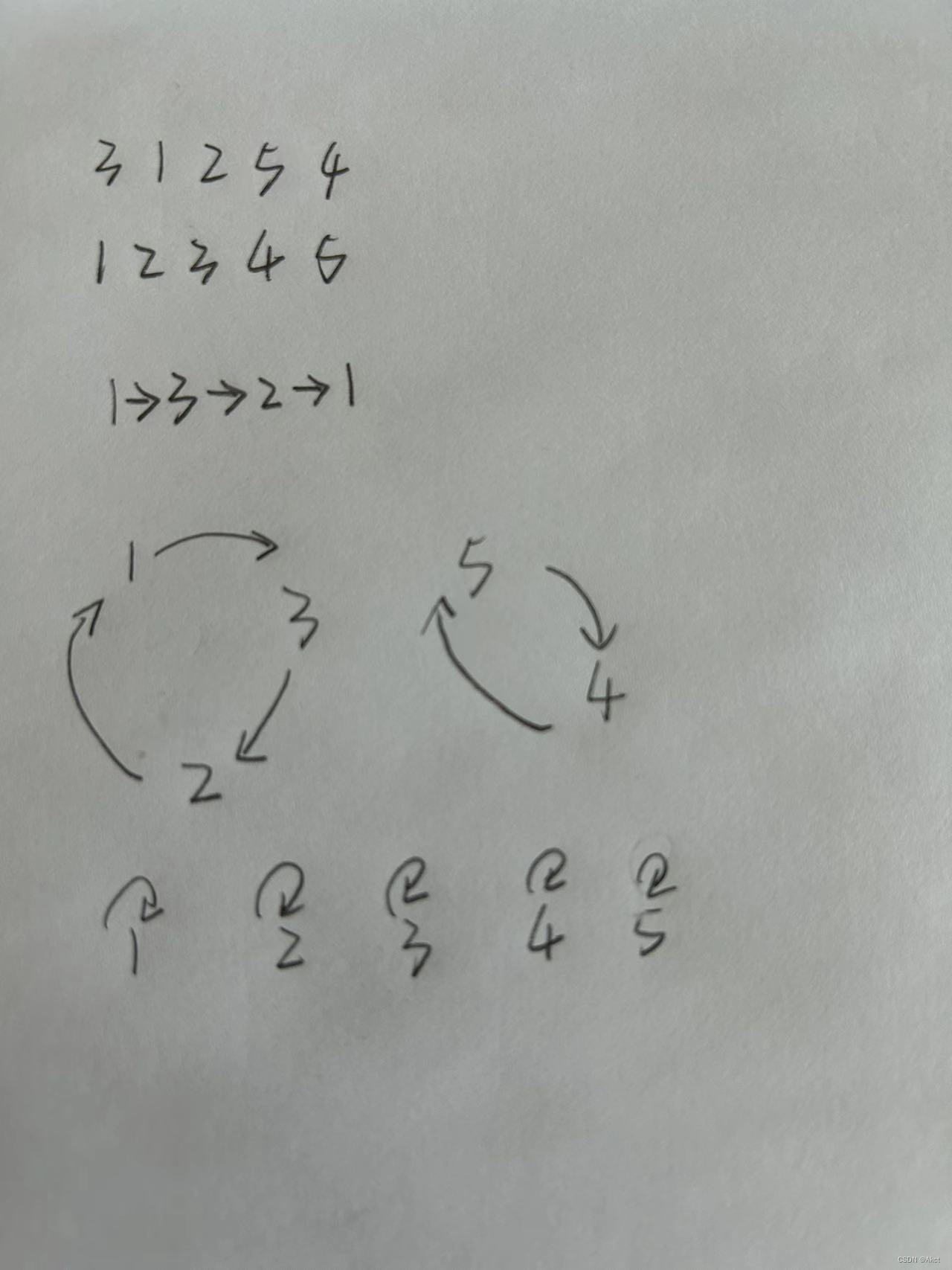
题目描述 “蓝桥杯”练习系统 (lanqiao.cn) 题目分析 方法一:暴力枚举,如果说数字不在正确的位置上也就意味着这个数必须要改变,进行改变记录即可 #include<bits/stdc.h> using namespace std; const int N 2e5 10; int n, a[N], …...

【迅搜02】究竟什么是搜索引擎?正式介绍XunSearch
究竟什么是搜索引擎?正式介绍XunSearch 啥?还要单独讲一下啥是搜索引擎?不就是百度、Google嘛,这玩意天天用,还轮的到你来说? 额,好吧,虽然大家天天都在用,但是我发现&am…...
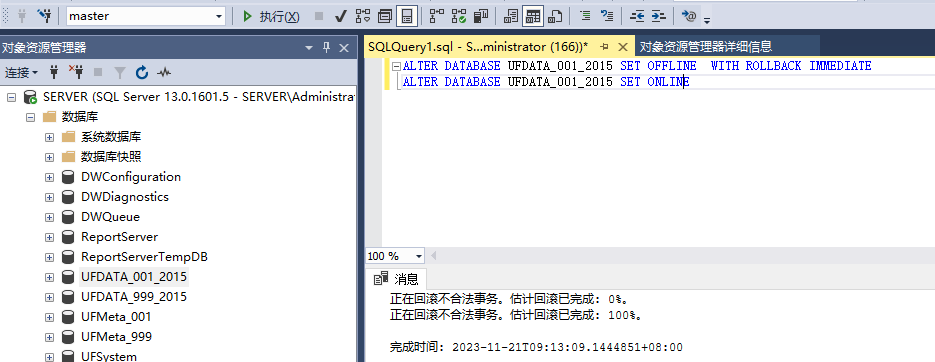
【Sql】sql server还原数据库的时候,提示:因为数据库正在使用,所以无法获得对数据库的独占访问权。
【问题描述】 sql server 还数据库的时候,提示失败。 点击左下角进度位置,可以得到详细信息: 因为数据库正在使用,所以无法获得对数据库的独占访问权。 【解决方法】 针对数据库先后执行下述语句,获得独占访问权后&a…...
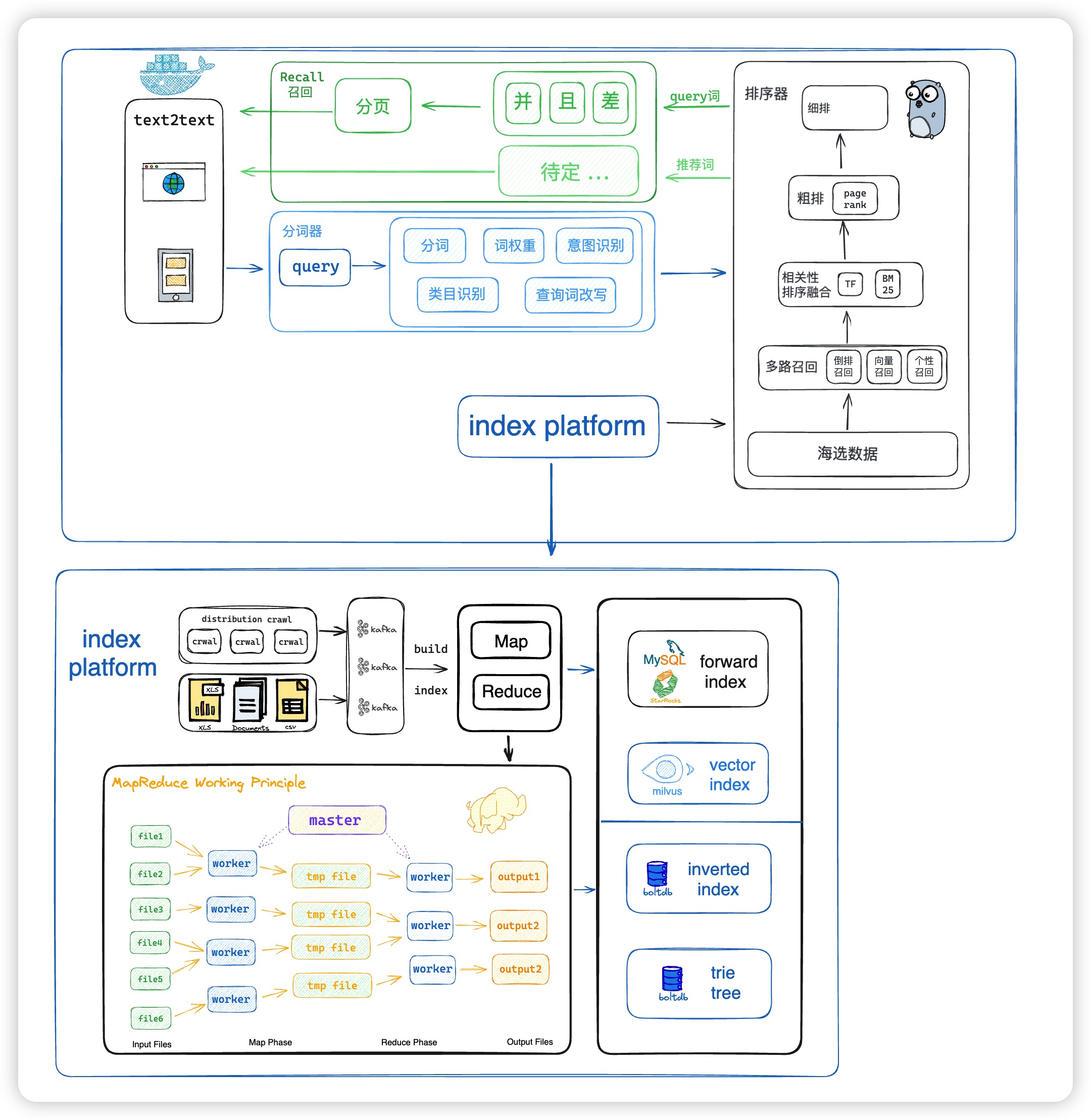
【Go语言实战】(26) 分布式搜索引擎
Tangseng 基于Go语言的搜索引擎 github地址:https://github.com/CocaineCong/tangseng 详细介绍地址:https://cocainecong.github.io/tangseng 这两周我也抽空录成视频发到B站的~ 本来应该10月份就要发了,结果一鸽就鸽到现在hh…...
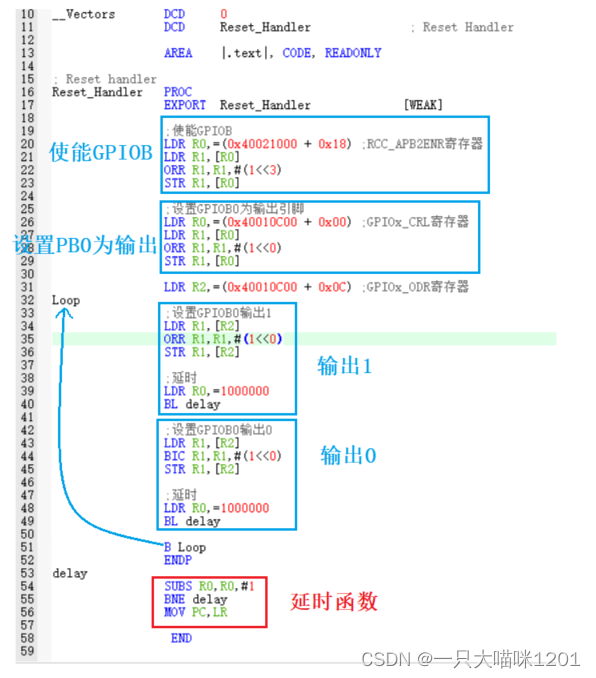
【理解ARM架构】不同方式点灯 | ARM架构简介 | 常见汇编指令 | C与汇编
🐱作者:一只大喵咪1201 🐱专栏:《理解ARM架构》 🔥格言:你只管努力,剩下的交给时间! 目录 🏀直接操作寄存器点亮LED灯🏀地址空间🏀ARM内部的寄存…...

JS服务端技术—Node.js知识点锦集
【版权声明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权) https://blog.csdn.net/m0_69908381/article/details/134544523 出自【进步*于辰的博客】 接触Node.js挺长时间了,工作也经常使用…...
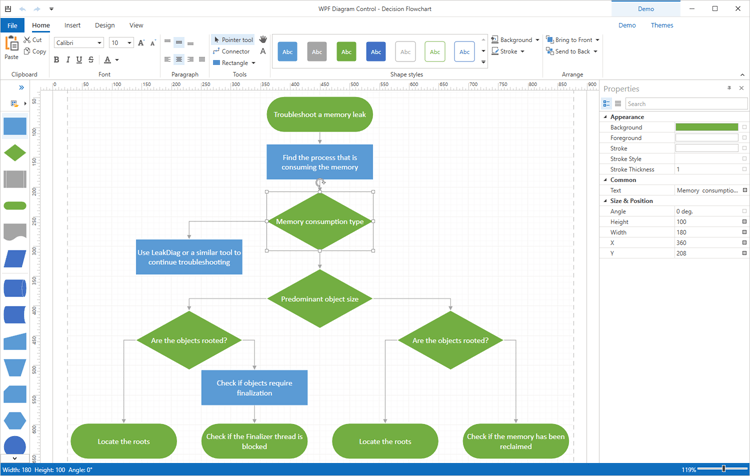
界面控件DevExpress WPF流程图组件,完美复制Visio UI!(一)
DevExpress WPF Diagram(流程图)控件帮助用户完美复制Microsoft Visio UI,并将信息丰富且组织良好的图表、流程图和组织图轻松合并到您的下一个WPF项目中。 P.S:DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至…...
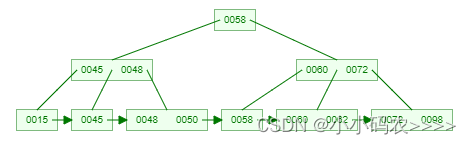
为什么选择B+树作为数据库索引结构?
背景 首先,来谈谈B树。为什么要使用B树?我们需要明白以下两个事实: 【事实1】 不同容量的存储器,访问速度差异悬殊。以磁盘和内存为例,访问磁盘的时间大概是ms级的,访问内存的时间大概是ns级的。有个形象…...
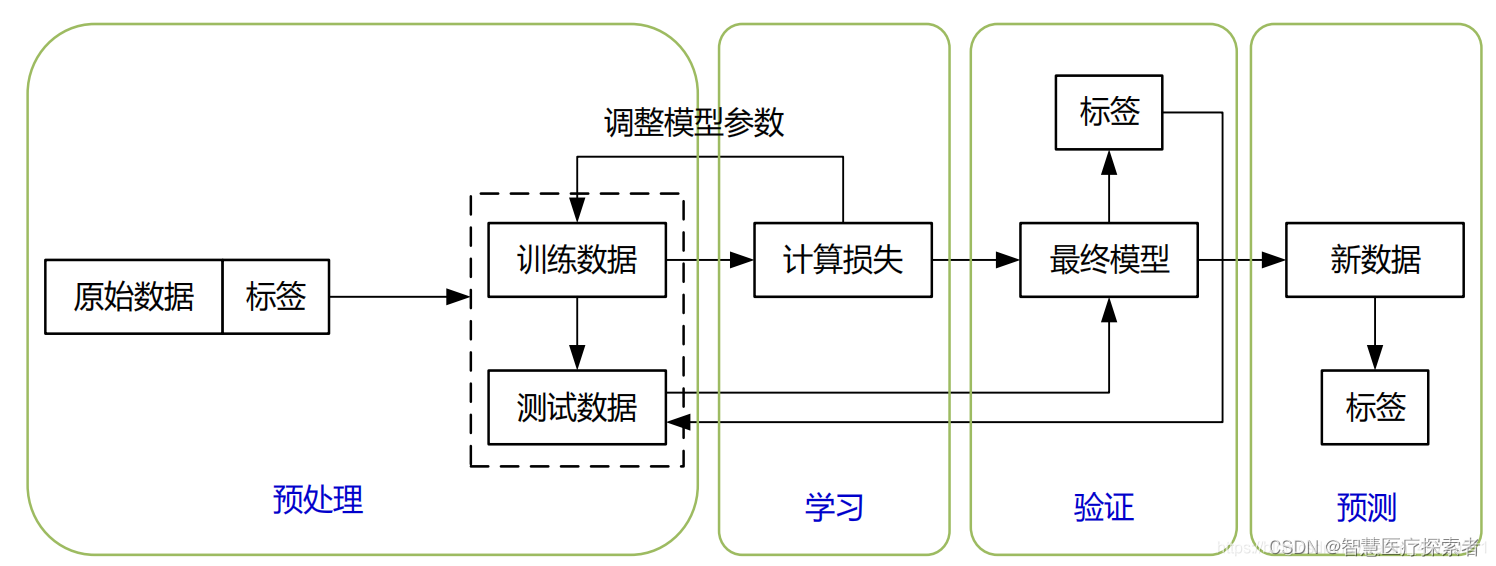
什么是神经网络(Neural Network,NN)
1 定义 神经网络是一种模拟人类大脑工作方式的计算模型,它是深度学习和机器学习领域的基础。神经网络由大量的节点(或称为“神经元”)组成,这些节点在网络中相互连接,可以处理复杂的数据输入,执行各种任务…...

15 Go的并发
概述 在上一节的内容中,我们介绍了Go的类型转换,包括:断言类型转换、显式类型转换、隐式类型转换、strconv包等。在本节中,我们将介绍Go的并发。Go语言以其强大的并发模型而闻名,其并发特性主要通过以下几个元素来实现…...

管理体系标准
管理体系标准 什么是管理体系? 管理体系是组织管理其业务的相互关联部分以实现其目标的方式。这些目标可能涉及许多不同的主题,包括产品或服务质量、运营效率、环境绩效、工作场所的健康和安全等等。 系统的复杂程度取决于每个组织的具体情况。对于某…...

【Java 进阶篇】揭秘 Jackson:Java 对象转 JSON 注解的魔法
嗨,亲爱的同学们!欢迎来到这篇关于 Jackson JSON 解析器中 Java 对象转 JSON 注解的详细解析指南。JSON(JavaScript Object Notation)是一种常用于数据交换的轻量级数据格式,而 Jackson 作为一款优秀的 JSON 解析库&am…...

②【Hash】Redis常用数据类型:Hash [使用手册]
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ Redis Hash ②Redis Hash 操作命令汇总1. hset…...

十七、SpringAMQP
目录 一、SpringAMQP的介绍: 二、利用SpringAMQP实现HelloWorld中的基础消息队列功能 1、因为publisher和consumer服务都需要amqp依赖,因此这里把依赖直接放到父工程mq-demo中 2、编写yml文件 3、编写测试类,并进行测试 三、在consumer…...
的调优技巧和实战)
Java虚拟机(JVM)的调优技巧和实战
JVM是Java应用程序的运行环境,它负责管理Java应用程序的内存分配、垃圾收集等重要任务。然而,JVM的默认设置并不总是适合所有应用程序,因此需要根据应用程序的需求进行调优。通过对JVM进行调优,可以大大提高Java应用程序的性能和可…...
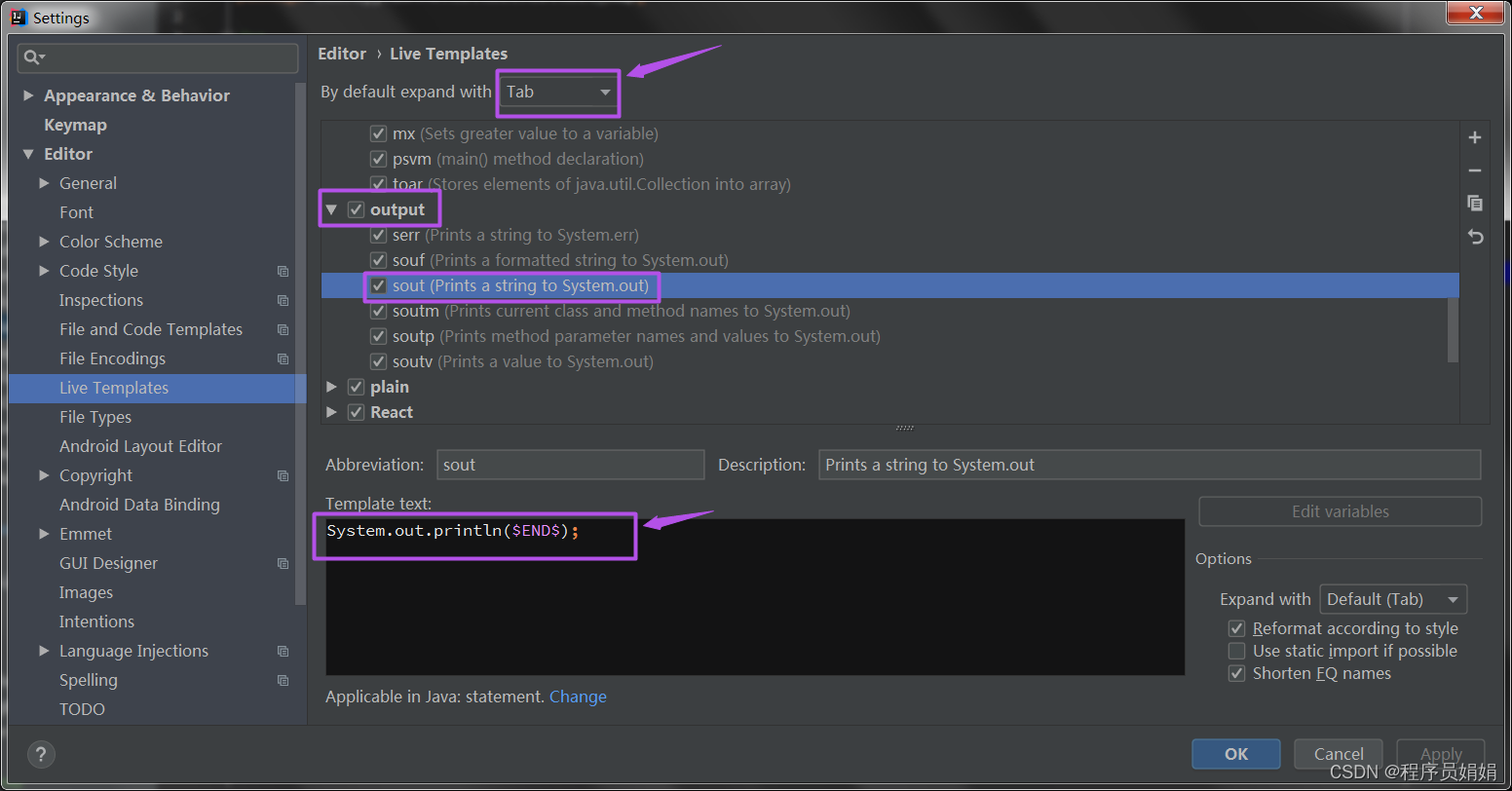
idea中的sout、psvm快捷键输入,不要太好用了
目录 一、操作环境 二、psvm、sout 操作介绍 2.1 psvm,快捷生成main方法 2.2 sout,快捷生成打印方法 三、探索 psvm、sout 底层逻辑 一、操作环境 语言:Java 工具: 二、psvm、sout 操作介绍 2.1 psvm,快捷生成m…...

shell脚本字典创建遍历打印
解释: 代码块中包含了每个用法的详细解释 #!/bin/bash# 接收用户输入的两个数 echo "请输入第一个数:" read num1 echo "请输入第二个数:" read num2# 创建一个关联数组 declare -A dict1 declare -A dict2# 定义键和值…...

【设计模式】聊聊职责链模式
原理和实现 模板模式变化的是其中一个步骤,而责任链模式变化的是整个流程。 将请求的发送和接收解耦合,让多个接收对象有机会可以处理这个请求,形成一个链条。不同的处理器负责自己不同的职责。 定义接口 public interface Filter {/*** …...
【C++进阶之路】第五篇:哈希
文章目录 一、unordered系列关联式容器1.unordered_map(1)unordered_map的介绍(2)unordered_map的接口说明 2. unordered_set3.性能对比 二、底层结构1.哈希概念2.哈希冲突3.哈希函数4.哈希冲突解决(1)闭散…...

wxauto架构深度解析:从UI自动化原理到企业级应用实战
wxauto架构深度解析:从UI自动化原理到企业级应用实战 【免费下载链接】wxauto Windows版本微信客户端(非网页版)自动化,可实现简单的发送、接收微信消息,简单微信机器人 项目地址: https://gitcode.com/gh_mirrors/w…...

别再只用Swiper做普通轮播了!用Vue3+Vite+TS实现这个‘异形’轮播,让你的H5页面瞬间高级
突破常规:用Vue3Swiper打造高级异形轮播组件 在移动端H5页面设计中,轮播图几乎是标配元素。但你是否注意到,90%的轮播图都采用千篇一律的横向滑动效果?这种设计虽然实用,却难以在用户心中留下深刻印象。今天ÿ…...

别再只盯着算力了!聊聊显卡供电:从GS7210A芯片看入门显卡的电源设计门道
显卡供电设计的微观密码:从GS7210A芯片看入门级显卡的电源哲学 当大多数玩家沉迷于算力对比和跑分竞赛时,显卡PCB上那些不起眼的供电元件正在默默书写着另一种性能语言。以AMD Radeon 520这张入门级显卡为例,它的单相Buck电源方案就像一本打开…...

不只是关窗口:深入理解Linux polkit与xrdp的权限博弈,一劳永逸配置你的远程桌面
深入解析Linux远程桌面权限机制:从xrdp认证弹窗到polkit安全架构 当你通过xrdp连接到Linux桌面时,那个反复弹出的"Authentication Required"窗口是否让你感到困扰?这不仅仅是简单的权限提示,而是Linux桌面环境中复杂的权…...

利用 Taotoken 统一 API 简化多智能体系统的模型管理
利用 Taotoken 统一 API 简化多智能体系统的模型管理 在构建一个包含多种职能智能体的复杂系统时,一个常见的工程挑战是模型管理。不同的智能体可能根据其任务特性,需要调用不同的大语言模型。如果每个智能体都直接对接多个原厂 API,开发团队…...

计算机教材策划与编程教学实践指南
1. 计算机教材策划的核心逻辑计算机教材不同于普通技术文档,它需要构建从认知到实践的完整学习路径。我在参与多本国家级规划教材编写时,总结出"3D"策划原则:Depth(深度)——每个知识点必须穿透表象…...

多终端命令历史实时同步工具multicli的设计与部署指南
1. 项目概述:一个命令,多端同步如果你和我一样,日常开发需要在多个终端环境之间频繁切换——比如本地的 macOS 终端、远程的 Linux 服务器,甚至 Windows 上的 WSL——那你一定对“命令历史不同步”这件事深恶痛绝。在服务器上敲了…...

AISMM模型能否救活你的创新 pipeline?5分钟自测当前成熟度等级,超86%团队卡在Level 2.4→2.5死区
更多请点击: https://intelliparadigm.com 第一章:AISMM模型与产品创新能力 AISMM(Artificial Intelligence-enabled Software Maturity Model)是一种面向AI原生产品的成熟度评估框架,聚焦于将大模型能力深度融入软件…...

Dodecylamine-CdSe QDs,十二胺稳定化CdSe量子点的应用方向
名称信息 英文名称:Dodecylamine-CdSe QDs 中文名称:十二胺稳定化CdSe量子点 组成结构:CdSe Semiconductor Quantum Dots 表面配体:Dodecylamine(十二胺) 外观状态:红色至深红色分散液或粉末 常…...

vscode-dark-islands的命令面板美化:玻璃态边框与圆角设计
vscode-dark-islands的命令面板美化:玻璃态边框与圆角设计 【免费下载链接】vscode-dark-islands VSCode theme based off the easemate IDE and Jetbrains islands theme 项目地址: https://gitcode.com/GitHub_Trending/vs/vscode-dark-islands vscode-dar…...