【理解ARM架构】不同方式点灯 | ARM架构简介 | 常见汇编指令 | C与汇编
🐱作者:一只大喵咪1201
🐱专栏:《理解ARM架构》
🔥格言:你只管努力,剩下的交给时间!

目录
- 🏀直接操作寄存器点亮LED灯
- 🏀地址空间
- 🏀ARM内部的寄存器
- 🏀汇编指令
- ⚽内存访问指令
- 四种栈
- ⚽数据处理指令
- ⚽跳转指令
- ⚽伪指令
- 🏀汇编和反汇编
- 🏀C与汇编
- ⚽Flash上的内容
- 🏀纯汇编点灯
- 🏀总结
🏀直接操作寄存器点亮LED灯
在学习C语言的时候,我们会写个Hello World程序来入门,当我们写ARM程序,也该有一个简单的程序引领我们入门,这个程序就是点亮LED。
查看原理图,确定控制LED的引脚:
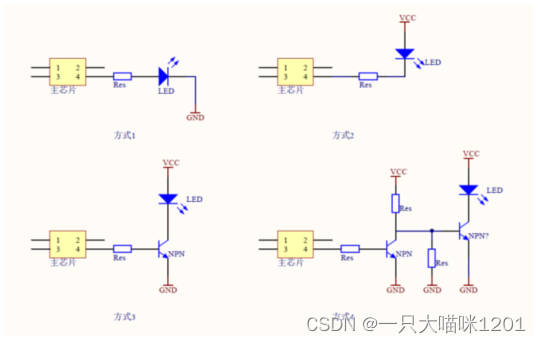
如上图是四种常见的LED驱动电路:
方式1:使用引脚输出3.3V点亮LED,输出0V熄灭LED。
方式2:使用引脚拉低到0V点亮LED,输出3.3V熄灭LED。
- 有的芯片为了省电等原因,其引脚驱动能力不足,这时可以使用三极管驱动。
方式3:使用引脚输出1.2V点亮LED,输出0V熄灭LED。
方式4:使用引脚输出0V点亮LED,输出1.2V熄灭LED。
但是对于我们写程序来说,不用关心输出的是3.3V还是1.2V,只需要知道引脚输出的是高电平还是低电平,简称输出1或0。
- 逻辑1–>高电平
- 逻辑0–>低电平
芯片操作引脚:
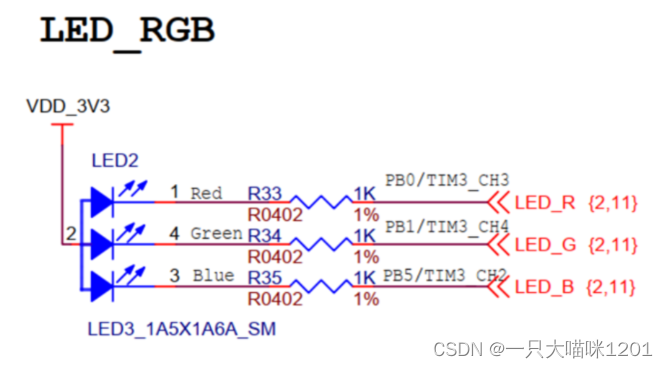
如上图,本喵的STM32F103ZET6开发板上,控制引脚输出0点亮LED灯,这里仅控制Red的LED灯,操作的引脚是PB0。
- 使能GPIOB组引脚:
从芯片手册上查找相关寄存器:

如上图是RCC_APB2ENR寄存器,用来控制不同组GPIO的使能,将该寄存器的bit3设置为1就使能了GPIOB。
那我们怎么找到这个寄存器呢?
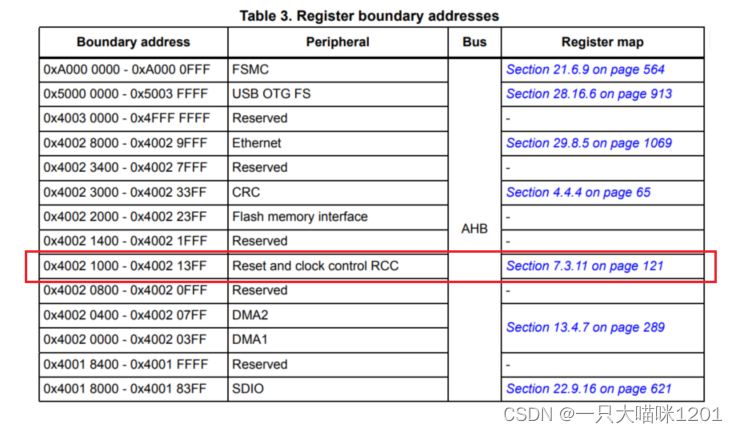
如上图是不同寄存器所在的地址范围。Reset and clock control RCC是用来使能外设时钟的,它的基地址是0x40021000。
又因为RCC_APB2ENR寄存器的偏移地址是0x18,所以该寄存器的绝对地址就是0x40021000 + 0x18。
- 设置GPIOB0为输出模式:
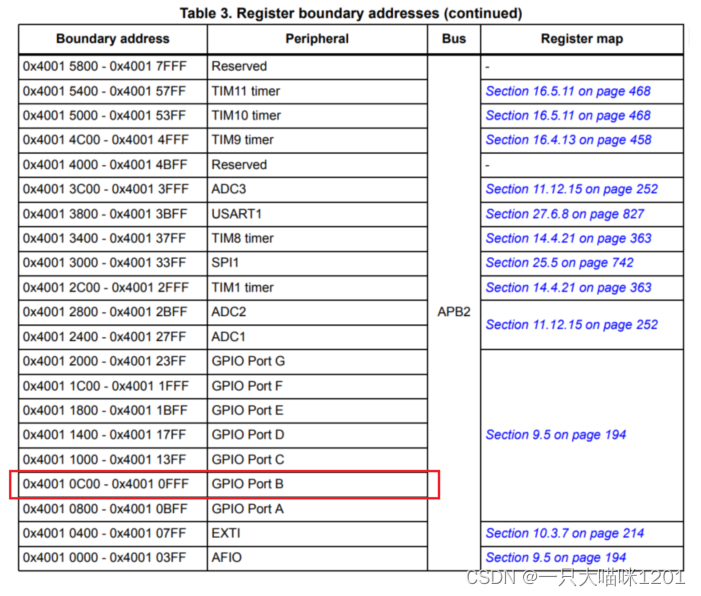
如上图,再从这张表中找到GPIOB的基地址是0x40010C00。

如上图所示是GPIOx_CRL寄存器,x是引脚编号,本喵这里使用的是PB0,所以x就是0,需要配置MODE0和CNF0。该寄存器的偏移量是0x00,所以该寄存器的绝对地址就是0x40010C00 + 0x00 。
MODE0的两个比特位配置为11,表示输出,并且输出速度设置最大,此时电平变化最快。
CNF0的两个比特位是配置输出模式的,这里仅是点灯,使用默认值即可。
- 设置引脚电平:

如上图是GPIOx_ODR寄存器,用来控制引脚的输出电平,根据偏移地址得到它的绝对地址是0x40010C00 + 0x0C。
由于是PB0,所以控制它的bit0ODR0即可,该位是1,输出1,该为是0,输出0。
要实现bit0 = 1或者bit0 = 0,不能直接GPIOx_ODR = 1,这样虽然能让bit0为1,但是该寄存器的其他位被置0了。
- 操作寄存器的某一位时,不能影响其他位。
置一:GPIOx_ODR |= (1<<0)。
置0:GPIOx_ODR &= ~(1<<0)。
这样的方式就仅在操作bit0,其他位并不影响。

如上图所示GPIOx_BSRR寄存器,它的绝对地址是0x40010C00 + 0x10,对于PB0,只需要操作BS0位和BR0位。
BS0写1,输出1,BR0写1,输出0,这些位写0没有任何影响,此时就可以仅操作这一个寄存器即可,效率较高。
- 编程:
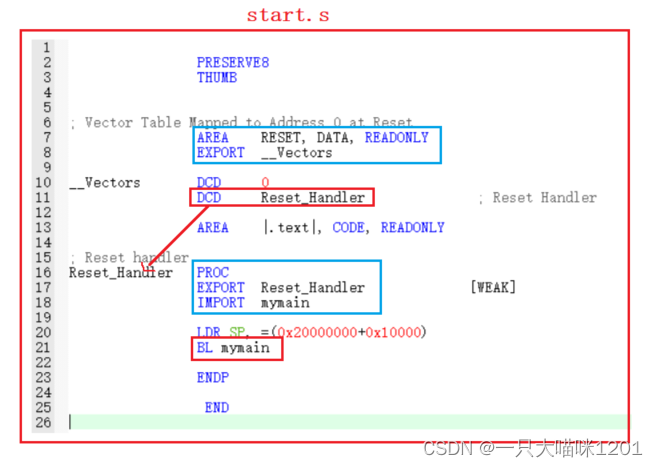
如上图所示启动文件中的汇编代码,蓝色框中的是语法规定,必须有的,暂时不用管它。
板子一上电以后会去向量表__Vectors处开始执行代码,执行到DCD Reset_Handler后会开始调用我们自己写的函数mymain,在调用之前需要设置一下栈顶SP,然后BL跳转到我们自己写的函数中去执行。

如上图本喵自己实现的mymain.c函数中,先创建一个32位的指针变量pReg,用来访问寄存器。
- 让指针指向
RCC_APB2ENR寄存器的地址0x40021000 + 0x18,将该寄存器的bit3置一,使能GPIOB。 - 让指针指向
GPIOx_CRL寄存器的地址0x40010C00 + 0x00,将该寄存器的bit0置一,设置PB0为输出模式。 - 让指针指向
ODR寄存器的地址0x40010C00 + 0x0C,将该寄存器的bit0设置为1,让PB0输出1,然后延时,再将bit0设置为0,然后再延时,如此反复。
然后编译工程,并将程序烧录到开发板中,可以看到板子上红色的LED灯在闪烁,本喵这里就不贴图了。
🏀地址空间
ARM架构:
在上面点灯的过程中,本喵在访问寄存器的时候,完全就是在使用C语言的指针来访问内存地址,为什么这样做就可以访问到寄存器呢?
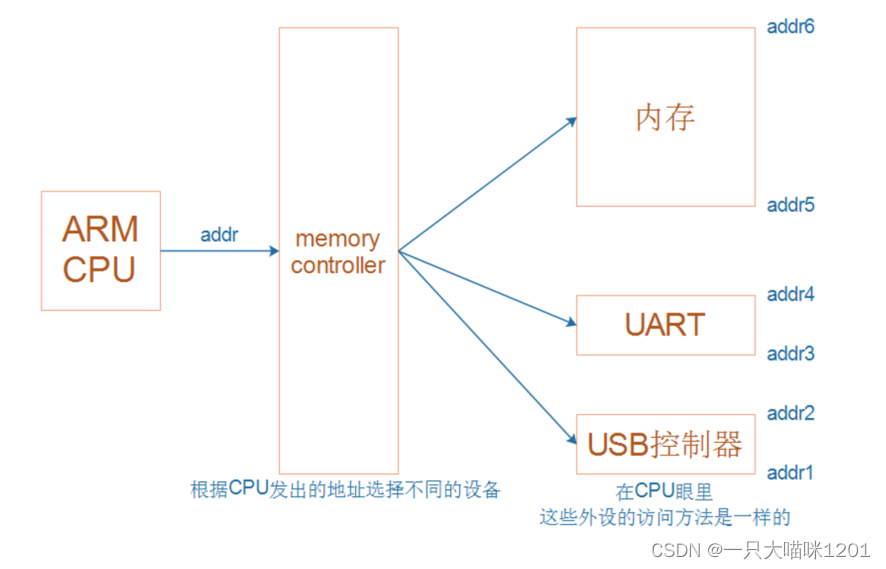
如上图示意图所示,在ARM架构的CPU中,内存RAM,各种片内外设,如UART,USB控制器等都是统一编址的,它们的地址是连续的,从add1到add6。
CPU在访问不同的地址时,会将地址先发给内存控制器memeory controller,由内存控制器去访问地址读取数据。
- 所以在CPU眼里,这些外设以及内存的访问方法都是一样的。
x86架构:
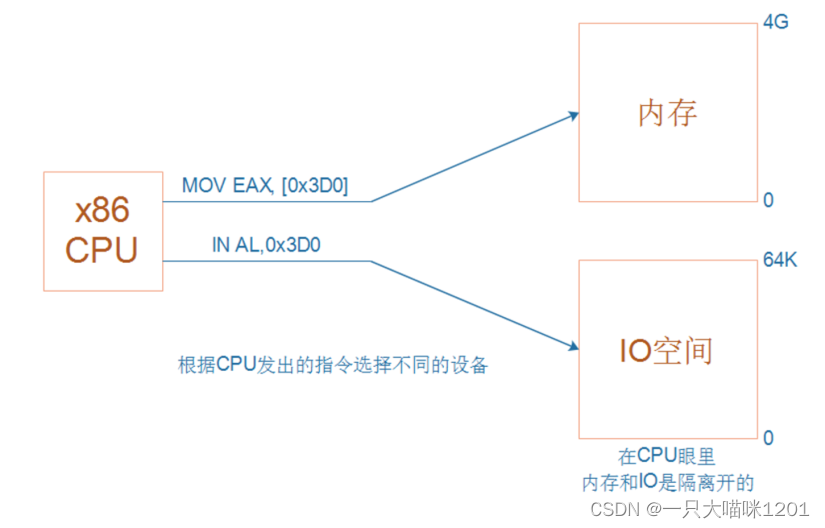
如上图所示是x86架构CPU访问内存和外设的示意图,这里的内存和IO空间中的外设就不是统一编址的,而是分隔开的。
内存的地址范围是0~4GB,IO空间的范围是0~64k,这两个空间在0~64K的地址范围是重复的,CPU通过不同指令来访问不同的空间。
当CPU要访问内存空间的时候,就使用MOV指令,当CPU要访问IO空间的时候,就使用IN指令。
精简指令集计算机:
ARM芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
① 对内存只有读、写指令
② 对于数据的运算是在CPU内部实现
③ 使用RISC指令的CPU复杂度小一点,易于设计
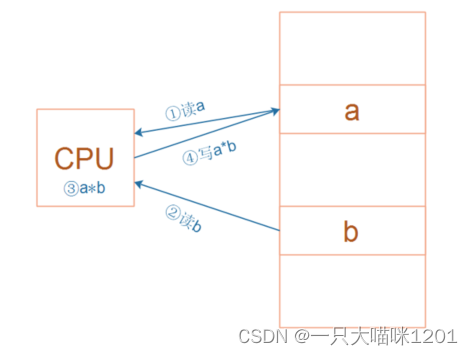
如上图所示的乘法运算a = a * b,RISC中要使用4条汇编指令:
① 读内存a
② 读内存b
③ 计算a*b
④ 把结果写入内存
复杂指令集计算机:
x86属于复杂指令集计算机(CISC:Complex Instruction Set Computing),
它所用的指令比较复杂,比如某些复杂的指令,它是通过“微程序”来实现的。
比如执行乘法指令时,实际上会去执行一个“微程序”,在“微程序”里,
一样是去执行这4不操作:
① 读内存a
② 读内存b
③ 计算a*b
④ 把结果写入内存
但是对于程序员来说,他看不到“微程序”,他好像用一条指令就搞定了这一切!
这里提到x86架构以及CISC仅仅是为了和ARM架构以及RISC作一个对比,我们使用的是ARM架构以及RISC。
🏀ARM内部的寄存器
ARM架构中对于数据的运算是在CPU内部实现的,在内部用什么来保存上面乘法运算中的a,b,以及a * b的结果呢?
cortex-M3/M4中寄存器示意图:
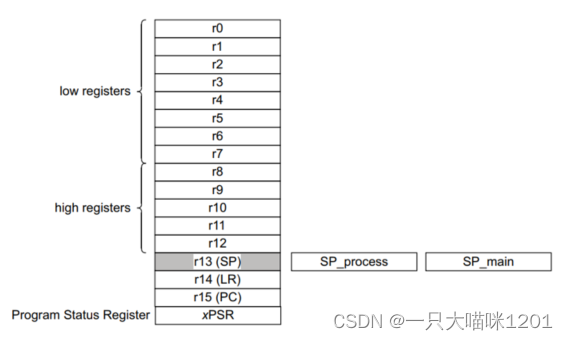
如上图所示是CPU中寄存器示意图。
CPU内部都有R0、R1、……、R15寄存器,它们可以用来“暂存”数据。
对于R13、R14、R15,还另有用途:
- R13:别名SP(Stack Pointer),栈指针。
- R14:别名LR(Link Register),用来保存返回地址。
- R15:别名PC(Program Counter),程序计数器,表示当前指令地址,写入新值即可跳转。
其中R13就是汇编指令里使用的SP,但是它有两个寄存器,一般情况下使用的是SP_main寄存器,运行RTOS的时候,任务使用的是SP_process寄存器。
- 在编程的时候直接使用SP,根据不同情况会自动调用相应的栈寄存器。
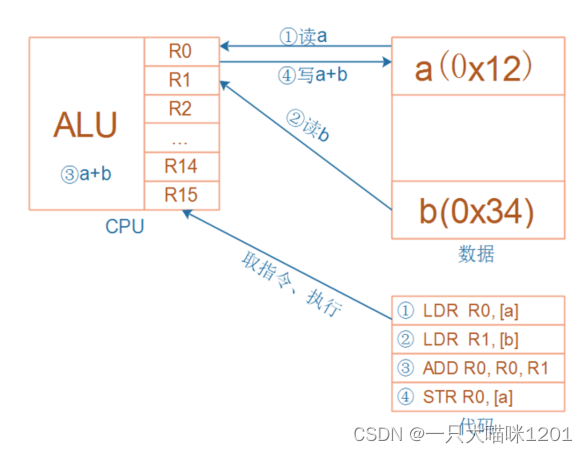
如上图所示,在程序执行的过程中,PC寄存器会按照顺序读取指令并去执行。
这16个寄存器之外还有一个xPSR寄存器,用来保存程序状态,保存上一条指令的执行结果,比如比较结果。还有一些控制作用,比如屏蔽中断、使能中断。
对于cortex-M3/M4来说,xPSR实际上对应3个寄存器:
① APSR:Application PSR,应用PSR
② IPSR:Interrupt PSR,中断PSR
③ EPSR:Exectution PSR,执行PSR
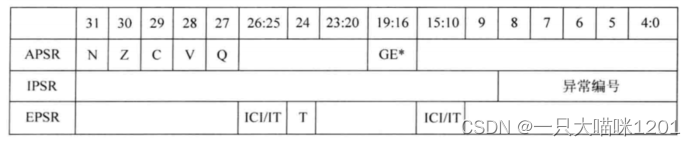
这3个寄存器的含义如上图所示,其实就是3个寄存器使用32位中的不同比特位,所以就用一个程序状态寄存器xPSR来表示了3个寄存器。

如上图所示就是组后和的真实寄存器。
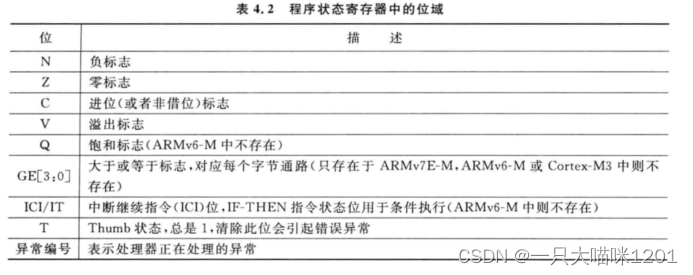
如上图所示是xPSR寄存器中不同位所表示的意义。
这3个寄存器,可以单独访问,使用下面汇编指令:
- MRS R0, APSR :读APSR
- MRS R0, IPSR :读IPSR
- MSR APSR, R0 :写APSR
这3个寄存器,也可以一次性访问:
- MRS R0, PSR :读组合程序状态
- MSR PSR, R0 :写组合程序状态
🏀汇编指令
一开始,ARM公司发布两类指令集:
① ARM指令集,这是32位的,每条指令占据32位,高效,但是太占空间。
② Thumb指令集,这是16位的,每条指令占据16位,节省空间。
要节省空间时用Thumb指令,要效率时用ARM指令。
一个CPU既可以运行Thumb指令,也能运行ARM指令。通过程序状态寄存器中有一位,名为“T”,它等于1时表示当前运行的是Thumb指令。
现在有一种情况,函数A是使用Thumb指令写的,函数B是使用ARM指令写的,可以往PC寄存器里写入函数A或B的地址,就可以调用A或B。
但是怎么让CPU在执行A函数是进入Thumb状态,在执行B函数时进入ARM状态?
- 调用函数A时,让PC寄存器的BIT0等于1,即:PC=函数A地址+(1<<0);
- 调用函数B时,让PC寄存器的BIT0等于0:,即:PC=函数B地址
根据函数地址的bit0位来判断这是用Thumb指令写的还是用ARM指令写的。
这样做非常的麻烦,所以后来又引入了Thumb2指令集,它支持16位指令、32位指令混合编程。
有那么多指令集:ARM、Thumb、Thumb2,难道都要记住它们的指令吗?当然不会,ARM公司推出了UAL(Unified Assembly Language),统一汇编语言,你不需要去区分这些指令集。
在程序前面用CODE32/CODE16/THUMB表示指令集:ARM/Thumb/Thumb2
我们在使用中不需要记住多少汇编指令,没必要写很复杂的汇编程序,因为在设置栈后就用C语言来写函数了。
常用的汇编指令只有几类:内存访问、数据处理、跳转、其他指令。
以“数据处理”指令为例,UAL汇编格式为:
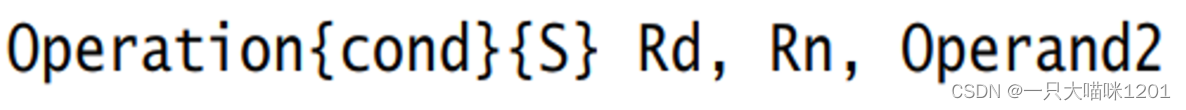
- Operation表示各类汇编指令,比如ADD、MOV;
- cond表示conditon,即该指令执行的条件,条件符合就执行,不符合就不执行,该选项可写可不写,条件有:
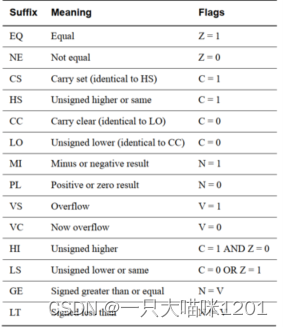
如上图,这些条件都和程序状态寄存器xPSR中的值有关,使用条件的指令之前一定得有改变xPSR寄存器的指令。
{S}表示该指令执行后会去修改程序状态寄存器,也是可写可不写。
- Rd为目的寄存器,用来存储运算的结果;
- Rn、Operand2是两个源操作数
下面本喵用一款神器VisUAL来讲解一下常用汇编指令的用法,这是一款ARM汇编模拟器。
⚽内存访问指令
LDR:Load Register

如上图所示是该指令的用法,作用就是从内存中读取数据到寄存器中,其中{type}表示读取数据的类型,如B就是无符号的一个字节数据,该选项可写可不写。
STR:Store Register

如上图所示就是该指令的用法,作用就是将数据从寄存器中写入到内存中。
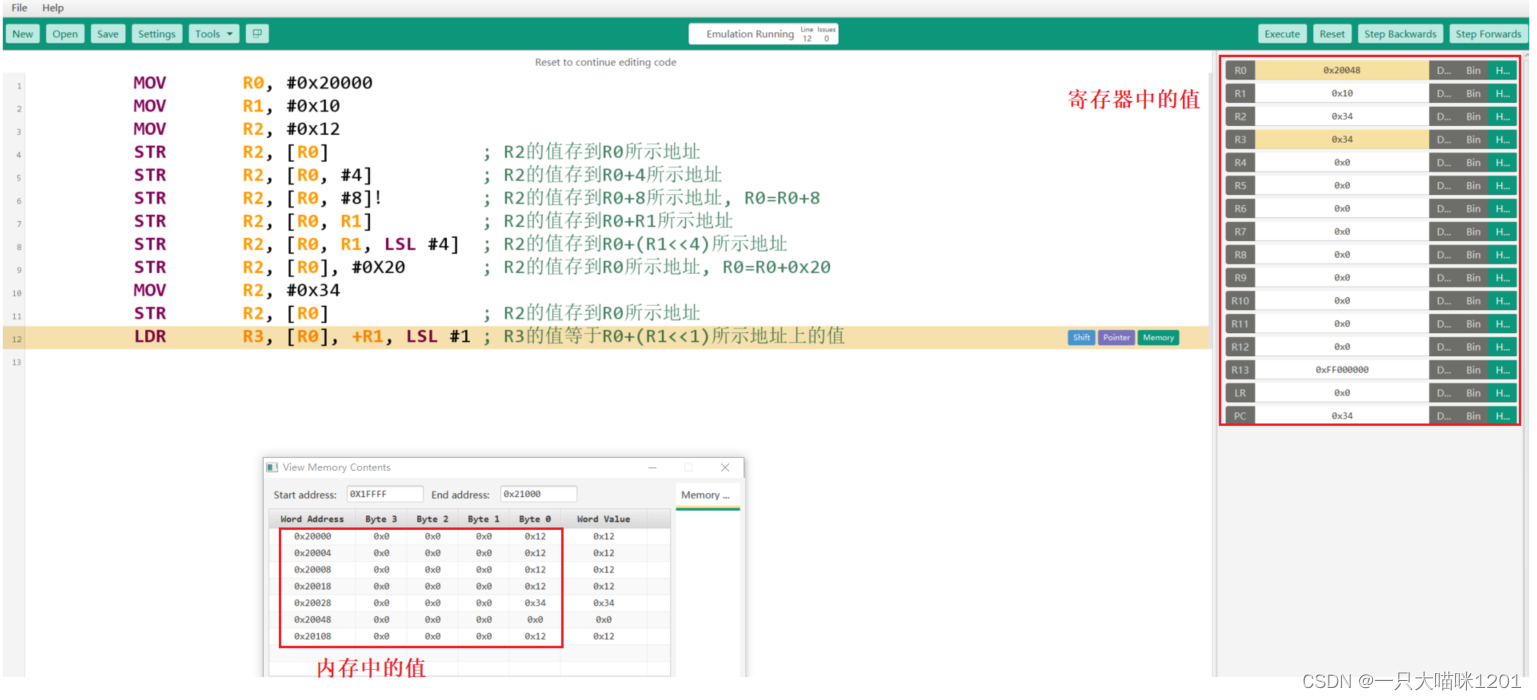
如上图所示汇编代码,在执行的过程中在右侧的红色框中可以看到寄存器中值的变化,在下侧的框中可以看到内存中的值。根据回调代码中的注释很容易看懂意思。
MOV是一个最基本的汇编指令,表示数据的移动,从源操作数移动到目的操作数,如上面中的MOV R0, #0x20000中,将0x20000移动到寄存器R0中。
!表示R0=R0+8,就是运算完以后要改变R0寄存器中的值。
LSL是一个数据左移指令,就相当于C语言中的<<操作符,如上面的STR R2, [R0, R1, LSL #4]表示将R1中的值左移4位然后加到R0上,最后将R2寄存器中的值存放到R0中值所代表的地址处。
LDM:Load Multiple Register

如上图所示是LDM的用法,作用是从多个地址处将数据读取到多个寄存器中。
addr_mode:
IA - Increment After, 每次传输后才增加Rn的值(默认,可省)
IB - Increment Before, 每次传输前就增加Rn的值(ARM指令才能用)
DA – Decrement After, 每次传输后才减小Rn的值(ARM指令才能用)
DB – Decrement Before, 每次传输前就减小Rn的值
! : 表示修改后的Rn值会写入Rn寄存器,
如果没有"!", 指令执行完后Rn恢复/保持原值
^ : 会影响CPSR, 在讲异常时再细讲
这里的Rn表示地址,如LDMIA R0, {R1-R3}表示将R0,R0+4,R0+8地址处的数据读取到R1,R2,R3寄存器中。
STM:Store Multiple Register

如上图所示是STM的用法,作用是将多个寄存器中的值写到多个地址处。这里Rn也表示地址。选项和LDM的用法一样。
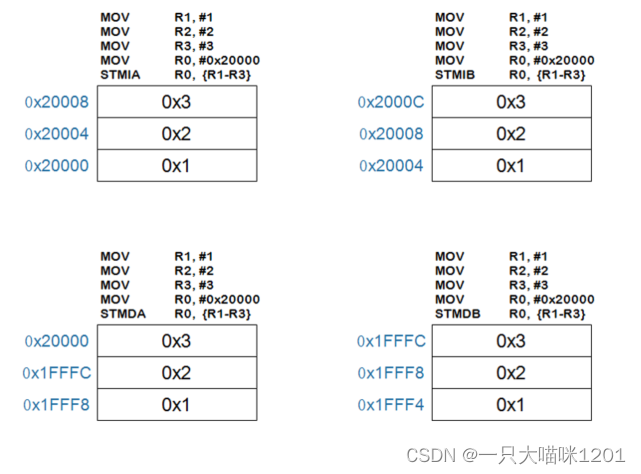
如上图所示是将寄存器中R1,R2,R3中的1,2,3放入到R0中的起始地址0x20000处时,使用的四种addr_mode方式。
上面是汇编代码,下面是执行完毕后内存中的值,这个过程中,高地址放编号高的寄存器中值。
四种栈
根据栈指针指向,可分为满(Full)/空(Empty):
-
满SP指向最后一个入栈的数据,需要先修改SP再入栈。
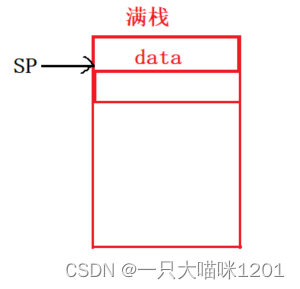
-
空SP指向下一个空位置,先入栈再修改SP。
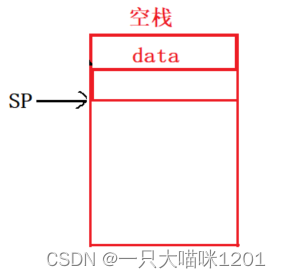
根据压栈时SP的增长方向,可分为增/减: -
增(Ascending):SP变大。
-
减(Descending):SP变小。
- 组合后,就有4种栈:满增、满减,空增,空减。
常用的的栈为“满减”:
- 入栈时用STMDB,也可以用STMFD,作用一样,表示入栈之前先减小SP。
- 出栈时用LDMIA,也可以用LDMFD,作用一样,表示出栈之后再增加SP。
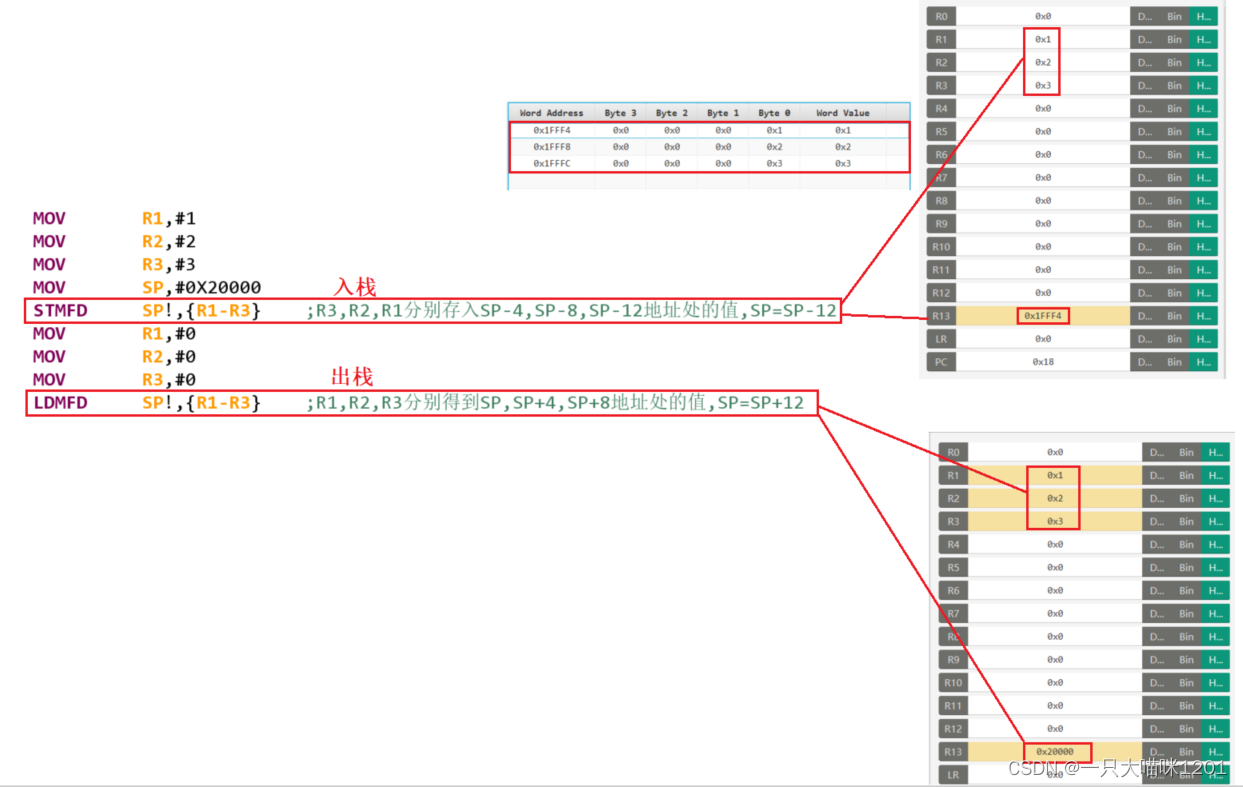
如上图代码所示,使用STMFD将数字1,2,3入栈,此时R13也就是SP寄存器的值是0x1FFF4,因为从0x2000开始减了12个字节,此时内存中的值也符合。
然后将R1,R2,R3寄存器中的值清0,然后再使用LDMFD将栈中的1,2,放入到寄存器中。
⚽数据处理指令
加法指令:
ADD R1, R2, R3 ; R1 = R2 + R3
ADD R1, R2, #0x12 ; R1 = R2 + 0x12
减法指令:
SUB R1, R2, R3 ; R1 = R2 - R3SUB R1, R2, #0x12 ; R1 = R2 - 0x12
进行减法运算的时候,发生借位时会改变程序状态寄存器xPSR中的N位。
位操作:
AND R1, R2, #(1<<4) ; 位与,R1 = R2 & (1<<4)
AND R1, R2, R3 ; 位与,R1 = R2 & R3
BIC R1, R2, #(1<<4) ; 清除某位,R1 = R2 & ~(1<<4)
BIC R1, R2, R3 ; 清除某位,R1 = R2 & ~R3
ORR R1, R2, R3 ;位或,R1 = R2 | R3
VisUAL里不支持(1<<4)这样的写法,写成0x10。
比较:
CMP R0, R1 ; 比较R0-R1的结果
CMP R0, #0x12 ; 比较R0-0x12的结果
TST R0, R1 ; 测试 R0 & R1的结果
TST R0, #(1<<4) ; 测试 R0 & (1<<4)的结果
比较的本质就是在做减法,用第一个操作数减去第二个操作数,比较的结果会改变程序状态寄存器xPSR中的N位和Z位。
⚽跳转指令
void A()
{int a = 10;B(a);printf(“ok”);
}
C程序中,函数A调用函数B的实质是:跳转去执行函数B的代码,函数B执行完后,还要回到函数A继续执行后面的代码。
对应的汇编指令就是跳转指令:
- B:Branch,跳转
- BL:Branch with Link,跳转前先把返回地址保持在LR寄存器中
- BX:Branch and eXchange,根据跳转地址的BIT0切换为ARM或Thumb状态(0:ARM状态,1:Thumb状态)。
- BLX:Branch with Link and eXchange,跳转前先把返回地址保持在LR寄存器中,根据跳转地址的BIT0切换为ARM或Thumb状态(0:ARM状态,1:Thumb状态)。
由于使用的是Thumb2指令集,所以只使用B和BL两条跳转指令。

如上图,跳转时可以加条件{cond},{.W}不用写。
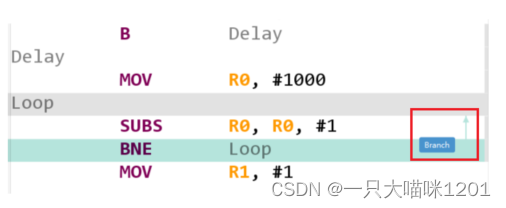
如上图,使用B跳转指令跳转到延时函数Delay中,然后让R0减1,再使用BNE来判断跳转到哪里,当R0不为0时,在BNE和SUBS之间执行。
SUBS在SUB减法指令的基础上增加了S,表示执行完后会影响程序状态寄存器xPSR的值。

在运行过程中,xPSR中的Z位始终为0,表示R0的值不为0。BNE是在跳转指令B的基础上增加了条件NE,代表的条件就是xPSR中的Z为0。
此时符合BNE条件,所以跳转到loop继续执行,从而实现延时。但是这个延时函数执行完毕后无法获得返回地址,因为B跳转指令不会保存返回地址到LR寄存器中。

如上图所示,使用BL跳转指令,在跳转之前会将返回地址存入到LR寄存器中,如上图所示,LR中的值是0x04,由于当前地址是第一行,返回地址就是下一条指令的地址,也就是第2行,又因为BL指令是32位指令,所以增加4。
当延时结束以后,将LR中的返回地址直接赋值给PC寄存器,程序从第2行开始执行。
⚽伪指令
这样一条指令:MOV R0, #VAL意图是把VAL这个值存入R0寄存器,那么VAL可以是任意值吗?不可以
- 直接给寄存器赋值的数必须是立即数。
假设VAL可以是任意数,MOV R0, #VAL本身是16位或32位,哪来的空间保存任意数值的VAL?所以,VAL必须符合立即数的规定:

如上图是立即数必须符合的规则,但是由我们去判断一个数是否是立即数会比较麻烦,并且我就想把任意数值赋值给R0,这时就可以使用伪指令。
LDR伪指令:
LDR R0, =VAL
“伪指令”,就是假的、不存在的指令。编译器会把“伪指令”替换成真实的指令,比如:
-
LDR R0, =0x12中0x12是立即数,那么替换为:MOV R0, #0x12。 -
LDR R0, =0x12345678中0x12345678不是立即数,那么替换为:LDR R0, [PC, #offset]使用LDR读内存指令读出值,offset是链接程序时确定的。
编译器在程序某个地方保存有这个非立即数的值,需要赋值的时候就来这个地府读取。
- 注意
LDR作为“伪指令”时,指令中有一个“=”,否则它就是真实的LDR(load regisgter)指令了。
ADR伪指令:
ADR R0, Loop
比如ADR R0, Loop,要将标号Loop的地址读取到R0中,它是伪指令,会被转换成真实的指令ADD R0,PC,#VAL,VAL在连接的时候确定。

如上图,之前的延时程序可以使用伪指令ADR直接将返回地址赋值给LR寄存器,将函数Delay的地址直接赋值给PC寄存器,去执行延时函数。
🏀汇编和反汇编
我们的第1个LED程序涉及2个文件:start.s、main.c,它们的处理过程如下:

如上图所示是程序编译的步骤,最后面的红色框是反汇编,就是将生成的可执行二进制文件变成汇编代码。
- 汇编:汇编文件转换为目标文件(里面是机器码)。
- 反汇编:可执行文件(目标文件,里面是机器码),转换为汇编文件。
KEIL中反汇编:
fromelf --bin --output=led.bin Objects\led.axf
fromelf --text -a -c --output=led.dis Objects\led.axf
在KEIL的User选项中,如下图添加这两项:
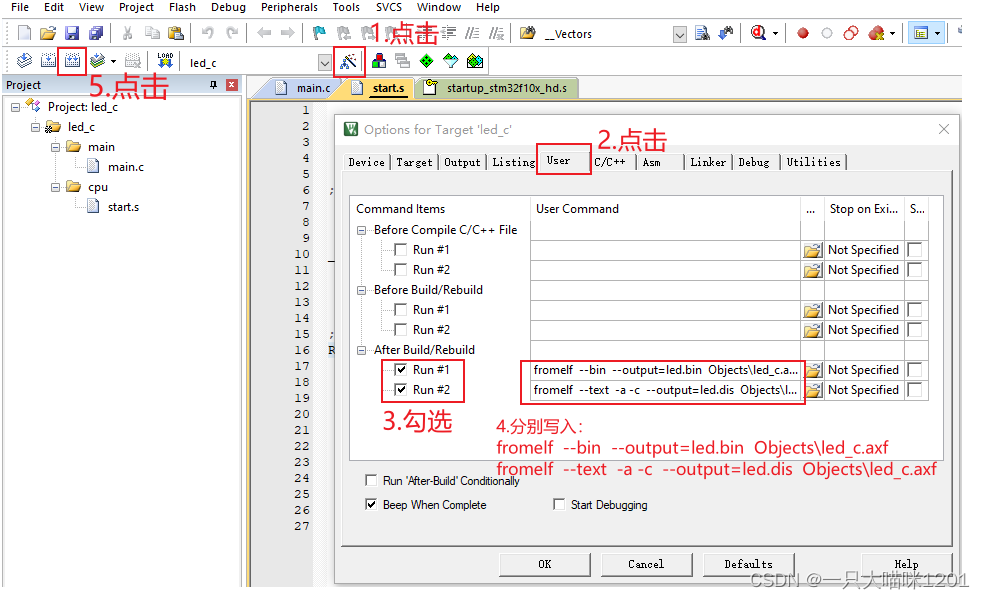
然后重新编译,即可得到二进制文件led.bin(以后用到)、反汇编文件led.dis。

如上图,只截取led.dis中前面一小段,第一列是地址,第二列是机器码,第三列是汇编代码。
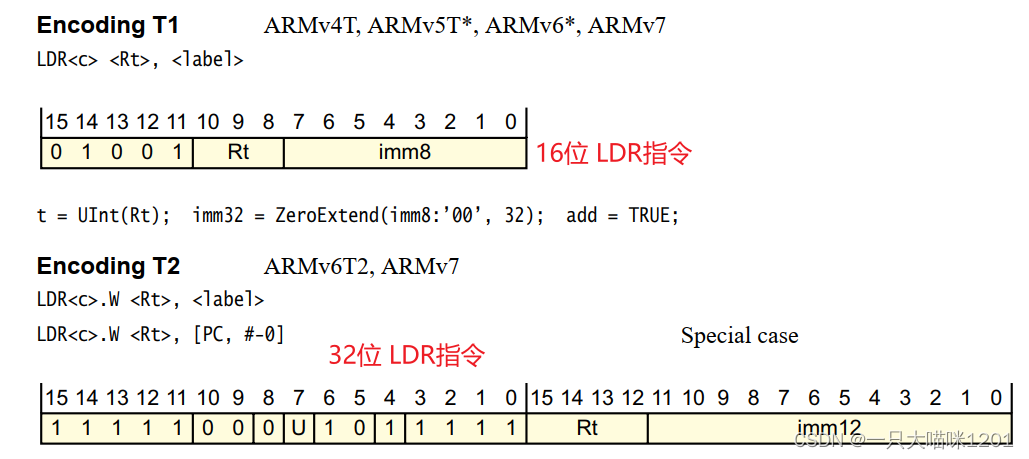
如上图所示是Thumb/Thumb2指令集中LDR指令的机器码生成规则,和前面反汇编文件中LDR对应的机器码做对比,可以发现,完全可以对的上。
🏀C与汇编
汇编代码中调用C函数时使用BL mymain,那如果我想给mymain函数传参呢?在前面编译过程中可以看到,.c源文件也会被编译成汇编文件,然后所有汇编文件再进行汇编生成目标文件,然后再进行连接。
此时start.s中调用main.s中的mymain函数,这两个文件都是汇编文件,汇编调用汇编传参就容易实现了。在ARM中使用寄存器来传参:
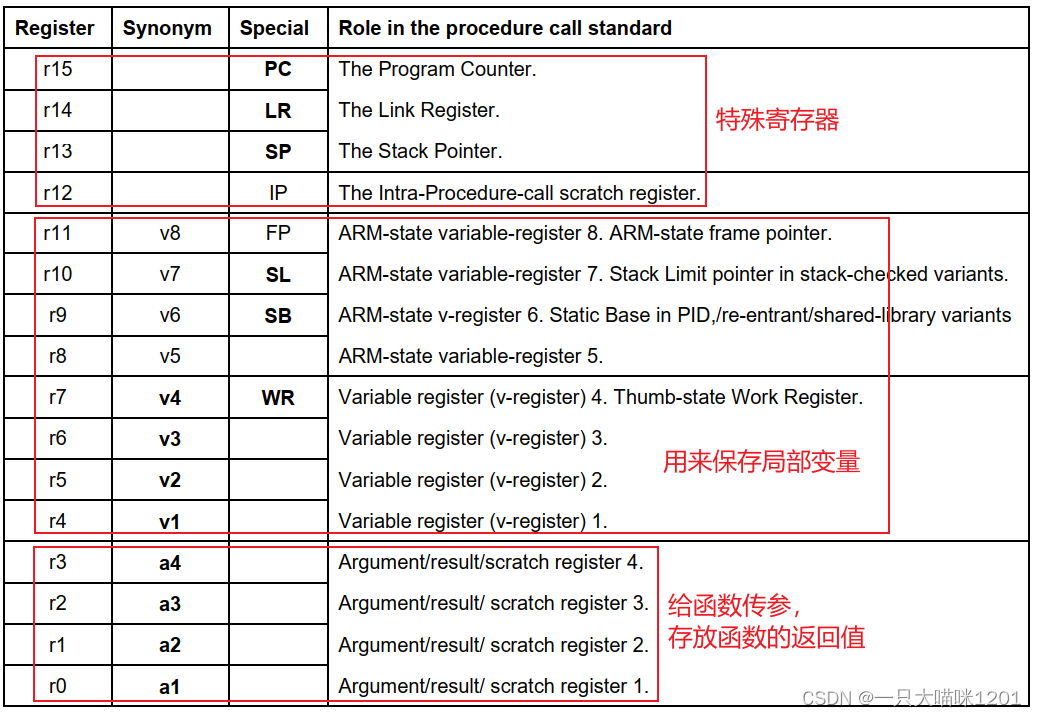
如上图,r0-r3用于调用者和被调用者之间传参数。
r4-r11用来保存局部变量,函数可能使用它们,所以在函数的入口保存它们,在函数的出口恢复它们。
r12-r15是特殊用途的寄存器。
int delay(unsigned int d)
{while (d--);return 0;
}int mymain()
{delay(1000000);return 0;
}
上面的C代码转换成汇编后调用delay时如下:
LDR R0, =1000000 /* 给delay函数传参数,保存在r0里 */
BL delay
CMP R0, #0 /* 返回值保存在r0中 */
可以看到,在调用delay之前,直接将1000000赋给寄存器R0,然后使用BL调用delay,此时就通过R0进行了传参。
函数调用结束后,delay函数的返回值也保存在寄存器R0中。
⚽Flash上的内容
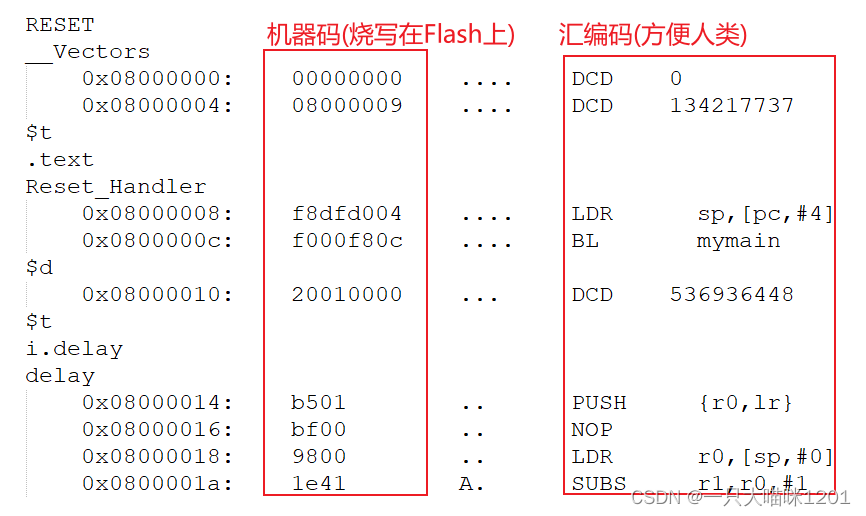
如上图是我们生成的反汇编文件,其中机器码是烧写到Flash上的,汇编码只是为了方便我们阅读。
每条指令会对应一个地址,如上图中的0x08000000,这个地址在Flash中是真实存在的,Flash中的地址也是按照上图中指令的地址这样分布的。
烧到Flash上
| 地址 | Flash内容 |
|---|---|
| 0x08000000 | 00000000 |
| 0x08000004 | 08000009 |
| 0x08000008 | f8dfd004 |
| 0x0800000c | f000f80c |
| 0x08000010 | 20010000 |
| 0x08000014 | bf00b501 |
| 0x08000018 | 1e419800 |
| …… | …… |
如上表所示,烧到Flash上的内容只有机器码,它自动放在与每条指令相对应的地址上。
启动流程:
上电后:
- 设置栈:CPU会从0x08000000读取值,用来设置SP(我们的程序里在调用mymain之前设置了SP)
- 跳转:CPU从0x08000004得到地址值,根据它的BIT0切换为ARM状态或Thumb状态,然后跳转
- 对于cortex M3/M4,它只支持Thumb状态,所以0x08000004上的值bit0必定是1
- 0x08000004上的值 = Reset_Handler + 1
- 从Reset_Handler继续执行,使用BL调用我们的mymain函数开始执行C代码。
🏀纯汇编点灯
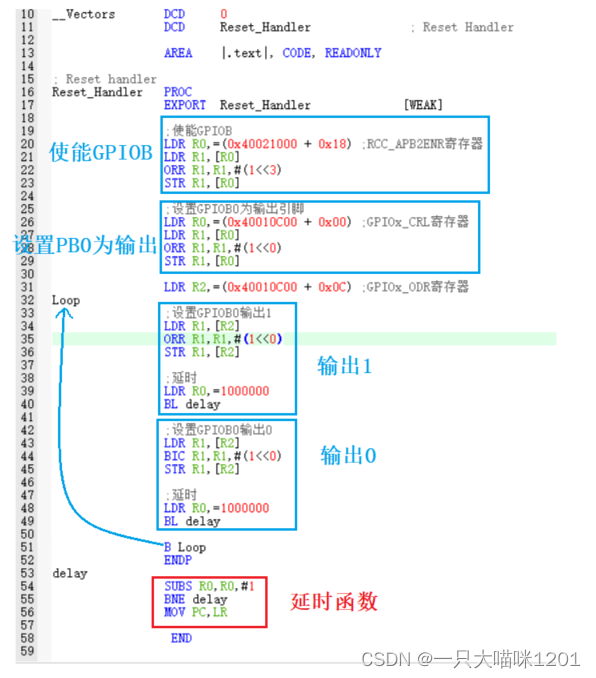
如上图所示汇编代码,上电后,程序会执行Reset_Handler处,开始执行汇编代码,步骤和C语言的一样。
- 将RCC_APB2ENR寄存器的绝对地址赋值给R0,然后将bit3置为1,使能GPIOB。
- 将GPIOx_CRL寄存器的绝对地址赋值给R0,然后将bit0置位1,设置PB0为输出模式。
- 将GPIOx_ODR寄存器的绝对地址赋值给R2,然后控制它的bit0位来控制引脚输出0和1。
- 将bit0设置成1,LED灯点亮,然后延时
- 将bit0设置成0,熄灭LED灯,然后延时
- 再使用
B指令跳转回Loop处,循环点亮
在调用延时函数delay时使用的是BL指令,在延时函数中,使用BNE判断R0中的值是否为0,延时结束后将LR中的返回地址赋值给PC寄存器。
调用延时函数delay时,通过寄存器R0传参。
将程序编译并烧录到开发板中,可以看到LED灯在闪烁,本喵这里也不贴图了。
🏀总结
这篇文章中,要对ARM架构有一个框架性的认识,知道CPU是怎么访问内存的,还有要记住这几条常用的汇编指令,其他复杂的指令遇到时自行百度查阅即可。
要明白调用函数是如何传参的,以及板子上电后,程序的执行流程,包括Flash中存放的是什么。
相关文章:
【理解ARM架构】不同方式点灯 | ARM架构简介 | 常见汇编指令 | C与汇编
🐱作者:一只大喵咪1201 🐱专栏:《理解ARM架构》 🔥格言:你只管努力,剩下的交给时间! 目录 🏀直接操作寄存器点亮LED灯🏀地址空间🏀ARM内部的寄存…...

JS服务端技术—Node.js知识点锦集
【版权声明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权) https://blog.csdn.net/m0_69908381/article/details/134544523 出自【进步*于辰的博客】 接触Node.js挺长时间了,工作也经常使用…...
界面控件DevExpress WPF流程图组件,完美复制Visio UI!(一)
DevExpress WPF Diagram(流程图)控件帮助用户完美复制Microsoft Visio UI,并将信息丰富且组织良好的图表、流程图和组织图轻松合并到您的下一个WPF项目中。 P.S:DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至…...
为什么选择B+树作为数据库索引结构?
背景 首先,来谈谈B树。为什么要使用B树?我们需要明白以下两个事实: 【事实1】 不同容量的存储器,访问速度差异悬殊。以磁盘和内存为例,访问磁盘的时间大概是ms级的,访问内存的时间大概是ns级的。有个形象…...
什么是神经网络(Neural Network,NN)
1 定义 神经网络是一种模拟人类大脑工作方式的计算模型,它是深度学习和机器学习领域的基础。神经网络由大量的节点(或称为“神经元”)组成,这些节点在网络中相互连接,可以处理复杂的数据输入,执行各种任务…...

15 Go的并发
概述 在上一节的内容中,我们介绍了Go的类型转换,包括:断言类型转换、显式类型转换、隐式类型转换、strconv包等。在本节中,我们将介绍Go的并发。Go语言以其强大的并发模型而闻名,其并发特性主要通过以下几个元素来实现…...

管理体系标准
管理体系标准 什么是管理体系? 管理体系是组织管理其业务的相互关联部分以实现其目标的方式。这些目标可能涉及许多不同的主题,包括产品或服务质量、运营效率、环境绩效、工作场所的健康和安全等等。 系统的复杂程度取决于每个组织的具体情况。对于某…...

【Java 进阶篇】揭秘 Jackson:Java 对象转 JSON 注解的魔法
嗨,亲爱的同学们!欢迎来到这篇关于 Jackson JSON 解析器中 Java 对象转 JSON 注解的详细解析指南。JSON(JavaScript Object Notation)是一种常用于数据交换的轻量级数据格式,而 Jackson 作为一款优秀的 JSON 解析库&am…...

②【Hash】Redis常用数据类型:Hash [使用手册]
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ Redis Hash ②Redis Hash 操作命令汇总1. hset…...

十七、SpringAMQP
目录 一、SpringAMQP的介绍: 二、利用SpringAMQP实现HelloWorld中的基础消息队列功能 1、因为publisher和consumer服务都需要amqp依赖,因此这里把依赖直接放到父工程mq-demo中 2、编写yml文件 3、编写测试类,并进行测试 三、在consumer…...
的调优技巧和实战)
Java虚拟机(JVM)的调优技巧和实战
JVM是Java应用程序的运行环境,它负责管理Java应用程序的内存分配、垃圾收集等重要任务。然而,JVM的默认设置并不总是适合所有应用程序,因此需要根据应用程序的需求进行调优。通过对JVM进行调优,可以大大提高Java应用程序的性能和可…...
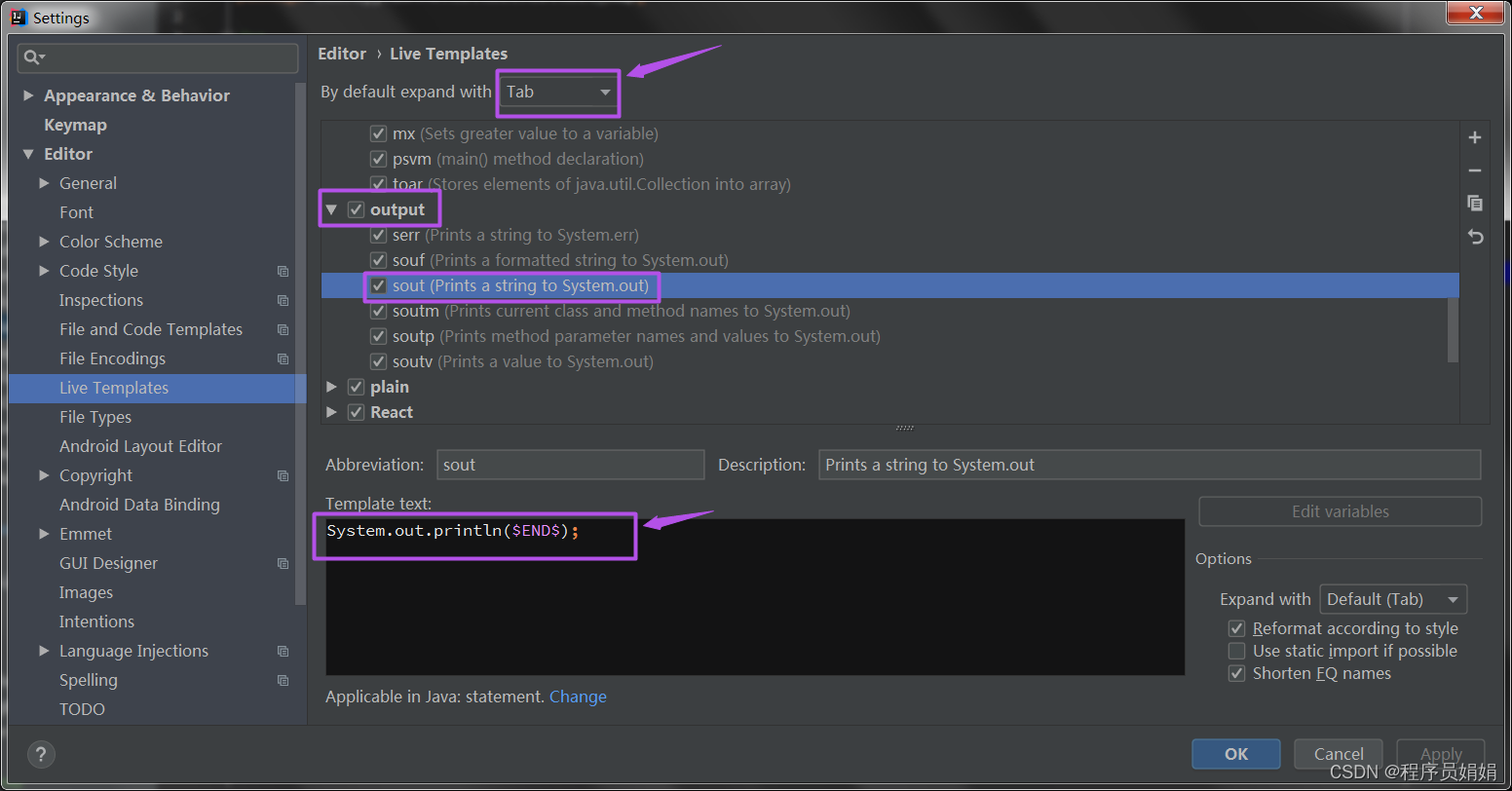
idea中的sout、psvm快捷键输入,不要太好用了
目录 一、操作环境 二、psvm、sout 操作介绍 2.1 psvm,快捷生成main方法 2.2 sout,快捷生成打印方法 三、探索 psvm、sout 底层逻辑 一、操作环境 语言:Java 工具: 二、psvm、sout 操作介绍 2.1 psvm,快捷生成m…...

shell脚本字典创建遍历打印
解释: 代码块中包含了每个用法的详细解释 #!/bin/bash# 接收用户输入的两个数 echo "请输入第一个数:" read num1 echo "请输入第二个数:" read num2# 创建一个关联数组 declare -A dict1 declare -A dict2# 定义键和值…...

【设计模式】聊聊职责链模式
原理和实现 模板模式变化的是其中一个步骤,而责任链模式变化的是整个流程。 将请求的发送和接收解耦合,让多个接收对象有机会可以处理这个请求,形成一个链条。不同的处理器负责自己不同的职责。 定义接口 public interface Filter {/*** …...
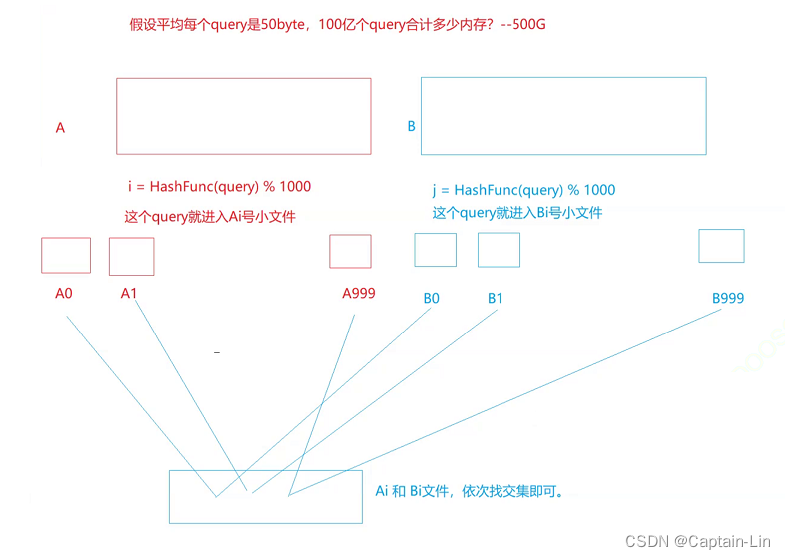
【C++进阶之路】第五篇:哈希
文章目录 一、unordered系列关联式容器1.unordered_map(1)unordered_map的介绍(2)unordered_map的接口说明 2. unordered_set3.性能对比 二、底层结构1.哈希概念2.哈希冲突3.哈希函数4.哈希冲突解决(1)闭散…...

CentOS基Docker容器时区配置解决方案
配置Docker容器的时区对于确保应用程序正确处理日期和时间至关重要。当使用CentOS作为基础镜像时,可以通过以下两种方法配置时区: 方法一:在Dockerfile中设置时区 这种方法涉及在构建Docker镜像的过程中设置时区。 步骤 选择基础镜像&…...
探索 Material 3:全新设计系统和组件库的介绍
探索 Material 3:全新设计系统和组件库的介绍 一、Material 3 简介1.1 Material 3 的改进和更新1.2 Material 3 的优势特点 二、Material 3 主题使用2.1 使用 Material3 主题2.2 使用 Material3 主题颜色 三、Material 3 组件使用3.1 MaterialButton:支持…...
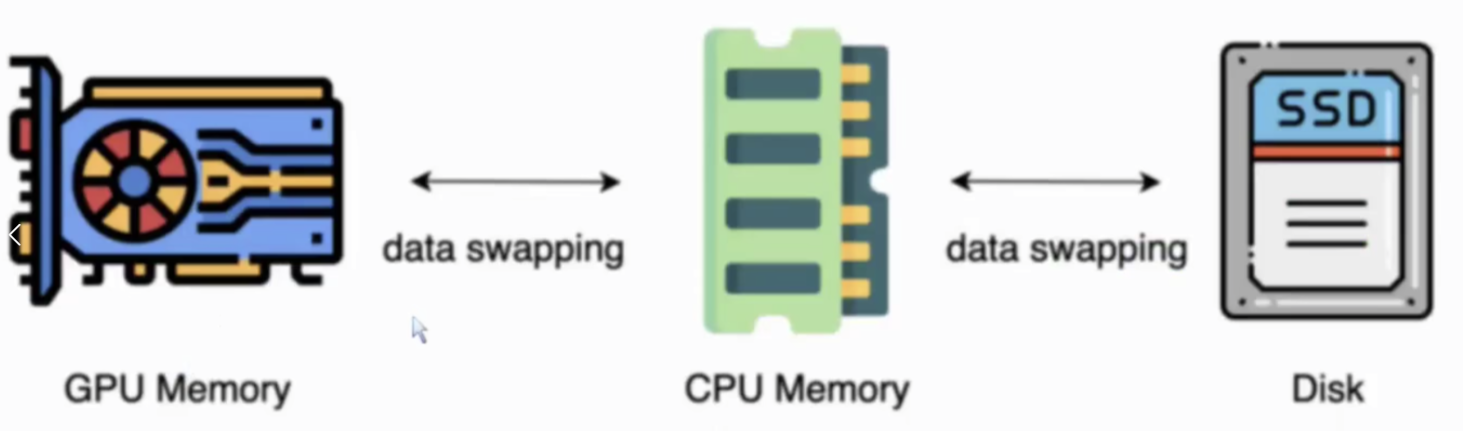
《多GPU大模型训练与微调手册》
全参数微调 Lora微调 PTuning微调 多GPU微调预备知识 1. 参数数据类型 torch.dtype 1.1 半精度 half-precision torch.float16:fp16 就是 float16,1个 sign(符号位),5个 exponent bits(指数位),10个 ma…...
)
【C++】const与类(const修饰函数的三种位置)
目录 const基本介绍 正文 前: 中: 后: 拷贝构造使用const 目录 const基本介绍 正文 前: 中: 后: 拷贝构造使用const const基本介绍 const 是 C 中的修饰符,用于声明常量或表示不可修改的对象、函数或成员函数。 我们已经了解了const基本用法,我们先进行…...

深度学习在图像识别中的革命性应用
深度学习在图像识别中的革命性应用标志着计算机视觉领域的重大进步。以下是深度学习在图像识别方面的一些革命性应用: 1. **卷积神经网络(CNN)的崭新时代**: - CNN是深度学习在图像识别中的核心技术,通过卷积层、池化…...
)
告别NeRF的漫长等待:用3DGS+SAM实现毫秒级3D物体分割(附SAGA开源代码解读)
告别NeRF的漫长等待:用3DGSSAM实现毫秒级3D物体分割(附SAGA开源代码解读) 在3D视觉领域,实时交互式分割一直是个棘手的问题。想象一下,当你需要从复杂的3D场景中快速提取某个特定物体时,传统基于NeRF的方法…...

3步解锁Windows原生HEIC预览:告别格式转换的终极方案
3步解锁Windows原生HEIC预览:告别格式转换的终极方案 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你是否曾经在Wi…...

Godot ECS框架实战:数据导向设计提升游戏性能与代码组织
1. 项目概述:为什么要在Godot里引入ECS?如果你在Godot里做过稍微复杂点的项目,尤其是那种有成百上千个需要实时更新状态的对象(比如RTS的单位、弹幕游戏的子弹、模拟经营里的市民),你大概率会遇到一个头疼的…...

为Claude Code配置稳定大模型服务解决封号与token不足
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定大模型服务解决封号与token不足 对于依赖Claude Code这类编程助手的开发者而言,服务中断和token…...

ComfyUI ControlNet预处理器:5分钟掌握AI图像精准控制技术
ComfyUI ControlNet预处理器:5分钟掌握AI图像精准控制技术 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 想要让AI图像生成完全按照你的想法来…...

基于MCP协议与Pydantic-AI构建智能代理:网页抓取与联网搜索实践
1. 项目概述:一个基于MCP协议的智能代理工具 最近在折腾AI应用开发,发现一个挺有意思的项目,来自GitHub上的 malminhas/mcp 。这是一个基于Python的智能代理工具,核心是利用了Model Context Protocol(MCP࿰…...

LangChian实现最小可运行的 RAG示例解析
下面代码是一个可用的 LangChain 阿里云通义千问 RAG 最小示例。其逻辑非常清晰,就是:加载 → 切分 → 向量化 → 检索 → QA。 https://item.jd.com/15261772.html # -*- coding: utf-8 -*- """ Created on Thu Jul 24 21:03:45 2025…...

2026年高口碑单北斗GNSS位移监测产品推荐榜单
2026年,单北斗GNSS位移监测系统在各类场景中越来越受欢迎,特别是在地质灾害监测和基础设施维护等领域。该系统依靠高精度的监测设备,能够实时捕捉位移变化,为用户提供数据支持。单北斗形变监测一体机的设计便于安装和维护、使其适…...

VESTA绘图进阶:从默认球棍到精美配位多面体,手把手教你调出科研级晶体图
VESTA科研绘图进阶:从基础球棍到专业配位多面体的视觉升级指南 在材料科学与化学领域的研究中,晶体结构图是论文发表和学术报告中不可或缺的视觉语言。许多科研人员虽然掌握了VESTA软件的基础操作,却常常陷入"能用但不好看"的困境—…...

Advanced-Deep-Learning-with-Keras语义分割:FCN和PSPNet架构详解
Advanced-Deep-Learning-with-Keras语义分割:FCN和PSPNet架构详解 【免费下载链接】Advanced-Deep-Learning-with-Keras Advanced Deep Learning with Keras, published by Packt 项目地址: https://gitcode.com/gh_mirrors/ad/Advanced-Deep-Learning-with-Kera…...