MatrixOne实战系列回顾 | 导入导出项目场景实践
本次分享主要介绍MatrixOne导入导出以及项目场景实践。将从四个方向为大家演示MatrixOne的功能,分别是数据的导入、导出、对接数据集成工具,以及Java连接实战。
数据导入会使用三种方式将数据导入至 MatrixOne中。分别是insert语句、load data语句还有source方式。特别注意的是load data支持从远端S3文件系统上拉取文件导入。
对于json 文件,MatrixOne 也提供了导入方式,等下我们一起来尝试下。
数据导出MatrixOne 也提供了多种方式,这里我们使用select into outfile的方式和mo_dump工具来实践一下数据的导出。
作为一款HSTAP数据库,MatrixOne从一定程度上也支持了市面上比较流行的一些数据集成工具和计算引擎。本次视频会为大家演示Datax、Flink、Spark集成MatrixOne。
最后,以一个简单SpringBoot项目,将MatrixOne作为业务数据库进行CRUD功能。
我相信,通过这四部分的实践,大家应该可以基本了解MatrixOne数据库的强大功能。
接下来我们开始进入第一部分,MatrixOne 数据导入。
Part 1 数据导入
#1 insert into方式
这里需要在MatrixOne中创建一个客户表,客户表有由四个字段组成,分别是自增主键,客户名、市、国家均为Varchar类型。我们先指定列导入,然后使用批量insert方式进行导入。最后我们在创建一个客户表的备份表,采用insert into select 方式,将客户表的数据备份至客户备份表。
#2 load data方式
▶ 2.1 导入csv文件
下面我们来实践一下load data功能。先将本地已经提前准备好的customer.csv文件导入。
先看一下这个csv文件,有3行测试数据,起始行就是数据,无需去除表头,列分割符是英文逗号,行分隔符是换行符。
然后执行load data命令进行数据导入,需要注意地方就是文件的路径,如果不太确定的话就写绝对路径。
注意:如果你的数据文件与 MatrixOne 服务器在不同的机器上,即数据文件在你所使用的客户端机器上时,那么你连接 MatrixOne 服务主机需要使用Mysql Client命令需要增加一个 --local-infile 参数;并且导入的命令行需要使用 load data local infile 语法。
除此之外MatrixOne 支持使用 load data 命令从 S3 对象存储服务批量导入 csv 文件、jsonline 文件。
我这里做了一个从阿里OSS文件系统中导入csv文件至MatrixOne的测试,由于时间问题我就不在演示了,我们一起看一下语法和效果。
首先需要我们提前在OSS中创建一个桶,然后获取一下授权所需的Ak和sk以及region。
在load data 中我们依次配置OSS endpoint,ak,sk,桶名称,region,压缩格式,文件路径,别的方式和本地导入一致。
▶ 2.2 导入json文件
演示了导入csv文件,我们一起来试下导入json文件。
首先我们创建一个新表用于接收导入数据。创建一个json_line_obj.jl文件新增几条json测试数据。
然后使用使用load data命令进行导入,需要注意的是这个json文件里面的全部是object,非数组结构,字段名称和类型需要和MatrixOne表中的字段名称类型对应。
然后我们在创建一个新表t2,用来测试导入json数组的情况。
这里我们提前准备三个文件,第一个是普通的json.jl文件,第二个是一个压缩格式为bz2压缩包,解压以后可以看到里面就是一个jl文件,第三个是一个压缩格式为gz的。
我们依次执行三条导入命令,其中jsondata字段用于标识json结构,与之前区别就是这里不再是object而是填写array。
第二条命令需要注意配置压缩格式。
第三条命令再导入的时候忽略了第一行进行导入,我们执行后看下效果。
可以看到这里导入的时候没有第一行数据。
#3 source命令
最后我们采用source命令将提前准备好的sql文件导入MatrixOne。
如果数据量比较大的话,可以采用nohup配合 Mysql 客户端 -e 参数进行后台导入。
接下来给大家分享一下MatrixOne的数据导出。
首先采用select into outfile的方式。
我提前准备了一张sys_permission表,里面有一些测试数据。
我们使用SQL 进行导出。
导出完成后,可以在当前目录下看到对应产生的sys_permission.csv文件。
另外,在导出SQL中还可以指定分割符,再使用竖线作为列分隔符导出一次。
导出完成后,可以看到对应的文件中,列的分割符已经变成了竖线。
Part 2 数据导出
#1 mo-dump工具
接下来给大家介绍一下mo-dump工具。它是 MatrixOne 的一个客户端导出工具,与 mysqldump 一样,它可以被用于通过导出 .sql 类型的文件来对 MatrixOne 数据库进行备份,导出的sql文件还包含表结构创建语句。
其中可以配置这些参数:
- -u 指定连接 MatrixOne 服务器的用户名。只有具有数据库和表读取权限的用户才能使用 mo-dump,默认值 root。
- -p 指定MatrixOne 用户的密码。默认值:111。
- -h 指定MatrixOne 服务器的主机 IP 地址。默认值:127.0.0.1
- -P 指定MatrixOne 服务器的端口。默认值:6001
- -db 指定必需参数。要备份的数据库的名称。
- -net-buffer-length 指定数据包大小,即 SQL 语句字符的总大小。数据包是 SQL 导出数据的基本单位,如果不设置参数,则默认 1048576 Byte(1M),最大可设置 16777216 Byte(16M)。假如这里的参数设置为 16777216 Byte(16M),那么,当要导出大于 16M 的数据时,会把数据拆分成多个 16M 的数据包,除最后一个数据包之外,其它数据包大小都为 16M。
- -tbl是可选参数。如果参数为空,则导出整个数据库。如果要备份指定表,则可以在命令中指定多个 -tbl 和表名。
mo-dump工具需要从git上下载源码进行编译,这里由于时间原因,我就不在演示编译过程了,直接用我提前编译好的二进制包进行演示。
通过mo-dump命令将我们之前创建的test_json_load表导出。
可以看到导出的结果就是一个.sql的文件,我们查看下这个sql文件。
Part 3 对接数据集成工具
我们先通过Datax将数据从Mysql中导入至MatrixOne。这里我们用到的 Mysql 版本为8.0.32,我已经提前准备好了测试库表作为源数据。
MatrixOne 与 MySQL 8.0 高度兼容,由于 DataX 自带的 MySQL Writer 中适配的为 5.1 的 JDBC 驱动,为提升程序的兼容性,社区单独改造出基于 8.0 驱动的 MatrixOne Writer 插件。
另外注意这一句:在底层实现上, MatrixOneWriter 通过 JDBC 连接远程 MatrixOne 数据库,并执行相应的 insert into ... 的 sql 语句将数据写入MatrixOne(内部会分批次提交入库)。
Datax的部署和介绍就不在多说了。我们可以先看一下Datax 作业配置文件,这个是我们需要自己编写的。
我们配置信息全部在job这个对象里面。job对象有2个属性,分别是setting和content。
- setting中可以配一些Datax的任务参数,如这个地方的speed,表示导入速度,也就是设置的并行度。
- content中配置数据源和目标源信息,数据源信息配置在reader对象中,目标源配置在writer中,具体reader和writer的配置在后面做导入的时候根据我们自己编写的文件进行分析。
我提前准备好了Datax,并且已经把matrixOneWriter 放到了对应的plugin目录下。
接下来我们看一下自己编写的作业文件,习惯把这个文件放到Datax的job目录下。
先说一下我们的目标是从Mysql中读取数据写入MatrixOne,所以这里的reader就用Datax自带的mysqlreader就行。writer使用我们导入的matrixonewriter。
注意这个地方reader、writer名称是严格区分大小写的。
除了需要配置name,还需要在parameter中配置导入的行column,Mysql的连接信息connection,用户名,密码这些。
同理writer除了配置name,也需要在parameter中配置column,MatrixOne连接信息,用户名,密码。
除了这个,可以Datax在做导出的时候提供了preSql字段用来实现ETL。这个地方的ETL
SQL会在导入前先执行。
当配置文件编写完以后执行Datax命令,指定作业文件。这里注意作业文件的路径。
执行成功后可以看到数据已经写入到MatrixOne中了。
Part 4 Java 连接实战
接下来给大家演示一下通过Flink引擎,分别将Mysql和Kafka中的数据导入至MatrixOne。
Apache Flink 是一个分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Flink的概念我就不在过多介绍了,我们直接开始实践。
这里在多说一句,本次分享视频中使用的MatrixOne的版本均是1.0.0 RC2。
#1 Mysql
我们先将 Mysql 作为数据源,将 Mysql 中的数据通过Flink JDBC的方式导入到 MatrixOne。可以看到这里我使用的 Mysql 版本为8.0.32。
接下来,我们分别在Mysql 中创建数据源表,并新增一些数据。再到MatrixOne 中创建目标表用于接收从Mysql 中导出的数据。
在Mysql 中创建 test 数据库,并在这个数据库下面创建一个person表。通过 insert 方式新增3条数据用于演示。
同理在MatrixOne 中创建一个 motest库,在该库下创建一个与 Mysql 对应的person 表,这里注意保持数据类型一致,否则会出现问题。
然后,需要在本地创建一个Flink 项目。首先需要创建一个Maven 项目,把我们需要用到相关依赖配置进来。这个项目我也提前创建好了。
先看一下pom文件,需要注意的是Flink 的版本这里使用的是1.17.0,JDK的版本为1.8,还需要引入flink-connector-jdbc和mysql-connector-java,Mysql驱动版本与Mysql的版本需要兼容。
还需要编写一个实体类Person 用于映射数据库对应的数据。
当前面工作准备好以后,我们就可以编写Flink 主程序了。
创建一个叫做Mysql2Mo 的类,在 main 函数中编写Flink 程序。
总结一下编写一个Flink程序大致需要几个步骤:
- 获取执行环境。
- 设置并行度,这里我设置1表示采用一个线程去执行。
- 然后设置查询的字段类型和字段名。
- 添加Source,就是数据源,这里配置的就是Mysql 的连接信息,通过query中配置的SQL将数据查出来。
- 拿到数据源以后,可以通过Flink 程序做ETL,这里举了个简单的例子,把拿到的结果封装成Person对象。
- 配置Sink,就是数据最终写入的地址,也就是我们这里MatrixOne,配置相关参数。
- 执行 Flink 程序。
执行成功以后,我们到MatrixOne中查看到之前新增到Mysql 中的数据已经导入进来了。
#2 Kafka
然后我们将Kafka作为数据源,从Kafka中同步数据至MatrixOne。
我本地已经安装好了Kafka,用到的Kafka版本为3.0.0。
我们继续用之前的MatrixOne 创建的person表,为了更清晰的看见效果使用truncate 命令先把之前的测试数据给清理掉。
然后使用Kafka命令行脚本创建一个主题。主题名称是matrixone。
接下来我们需要编写Flink程序,主要步骤和之前一致。
我们主要看下最关键的Source和Sink。
Source这里配置的为Kafka的连接信息,包含消费者组和消费策略,然后自定义了一个序列化器,将字符串转为Person对象。
这里可以打印一下获取到的Source数据。
Sink这里配置MatrixOne的连接信息,使用JDBC connector。
然后我们启动项目,Flink程序会阻塞在这里,等待我们往Kafka中生产数据。
我们使用命令行工具,模拟一个Kafka生产者,往Kafka中写入3条数据。
然后观察MatrixOne 也会同步这3条数据。
演示完适用于流处理的Flink引擎,接下来给大家演示一下批处理引擎Spark集成MatrixOne,通过Spark将Mysql数据写入MatrixOne。
这里使用的 MatrixOne 版本为 1.0.0 RC2 这个版本。是通过mo_ctl 工具搭建的单机版本。
我们先将 Mysql 作为数据源,将 Mysql 中的数据通过Flink JDBC的方式导入到 MatrixOne。可以看到这里我使用的 Mysql 版本为8.0.32。
接下来,我们分别在Mysql 中创建数据源表,并新增一些数据。再到MatrixOne 中创建目标表用于接收从Mysql 中导出的数据。
在Mysql 中创建 test 数据库,并在这个数据库下面创建一个person表。通过 insert 方式新增3条数据用于演示。
同理在MatrixOne 中创建一个 motest库,在该库下创建一个与 Mysql 对应的person 表,这里注意保持数据类型一致,否则会出现问题。
然后,需要在本地创建一个Spark 项目。首先需要创建一个Maven 项目,把我们需要用到相关依赖配置进来。这个项目我也提前创建好了。
先看一下pom文件,需要注意的是Spark的版本这里使用的是3.2.1,JDK的版本为1.8,额外注意Mysql驱动的版本与Mysql需要兼容。
还需要编写一个实体类Person 用于映射数据库对应的数据。
当前面工作准备好以后,我们就可以编写Spark主程序了。
创建一个叫做Mysql2Mo 的类,在 main 函数中编写Spark程序。
这里总结一下编写一个Spark程序大致需要几个步骤:
- 获取Session对象,通过Session拿到Spark上下文对象。
- 设置Mysql连接信息,包含用户名、密码、驱动类。
- 使用上下文对象配置Mysql 连接URL进行数据读取。
- 4、将读取结果封装成DataSet对象。
- 通过DataSet Stream 方式进行ETL,这里筛选出id大于2的数据。
- 配置MatrixOne连接信息,将数据写入目标库。
执行成功以后,我们到MatrixOne中查看到之前新增到Mysql 中的数据已经导入进来了。
#3 SpringBoot
最后一部分,我们将以一个SpringBoot项目,用MatrixOne作为业务数据库进行CRUD功能。
首先在MatrixOne中创建用户表并新增数据。
然后在本地搭建一个Springboot和Mybatis-plus的项目。
这里需要把用到的jar包通过Maven配置进来。
接下来在Springboot的配置文件中配置一下datasource,这里的配置和配置Mysql一致。
然后编译一个mapper,继承Myabtis-plus根接口BaseMapper,就可以使用自带的基础的增删改查功能,无需自己编写。
这里我没有编写Service层,方便起见直接在controller层调用mapper。
最后编写一下controller层,对外提供四个接口,分别是查询用户列表接口、新增用户接口、修改用户接口、删除用户接口。
然后我们启动项目,通过Http测试工具直接访问。
分享到此结束,感谢大家观看。
Q&A环节
感谢大家和我一起学习导入导出项目场景实践的相关知识,下面进入Q&A环节。
Q:请问我想通过mo-dump工具只导出表结构,而不要数据,怎么导呢?
A:可以在导出命令后跟-no-data参数,指定不导出数据。
Q:使用load data导入的json 对象中缺少某些字段,导入会报错吗?
A:导入会报错,导入json中字段多余表中字段,可以正常导入不过多出字段会被忽略,如果少于的话,则无法导入。
Q:我在执行source导入的时候导入文件是否可以写相对路径?
A:可以写相对路径,是相对于您使用mysql客户端的当前路径的,这里还是建议写全路径,防止出错,另外注意文件权限问题。
Q:使用load data命令导入一个大文件时比较耗时,有时候就会断掉又得重新来一遍,能否优化呢?
A:您可以在导入时候指定PARALLEL为true开启并行导入,例如,对于 2 个 G 的大文件,使用两个线程去进行加载,第 2 个线程先拆分定位到 1G 的位置,然后一直往后读取并进行加载。这样就可以做到两个线程同时读取大文件,每个线程读取 1G 的数据。也可以自己切分数据文件。
Q:Load data导入有事务吗?
A:所有的load语句都是有事务的。
Q:source导入sql时涉及触发器和存储过程会执行生效吗?
A:目前如果sql中存在不兼容的数据类型、触发器、函数或存储过程,仍需要手动修改否则执行会报错。
Q:mo-dump支持批量导出多个数据库吗?
A:仅支持导出单个数据库的备份,如果你有多个数据库需要备份,需要手动运行 mo-dump 多次。
Q:MatrixOne支持从Minio导入数据吗?
A:是支持的,load data 命令支持从本地文件、S3 对象存储服务以及S3 兼容的对象存储服务中导入数据到matrixone中,
而Minio也是基于S3协议的,所以也是支持的,具体参考文档:https://docs.matrixorigin.cn/1.0.0/MatrixOne/Deploy/import-data-from-minio-to-mo/
Q:MatrixOne 导入导出数据时,如果出现编码问题,导致数据乱码,我们一般是怎么解决的?
A:由于matrixone默认只支持UTF8这一种编码且无法更改;所以在导入数据时如果出现了乱码,我们就不能通过修改数据库和表的字符集来解决,可以试着转换数据编码为UTF8。常见的转换工具有 iconv 和 recode,比如:将 GBK 编码的数据转换为 UTF-8 编码:iconv -f GBK -t UTF8 t1.sql > t1_utf8.sql。
Q:MatrixOne导入导出时 ,需要哪些权限?
A:租户管理员的话,通过默认角色可以直接进行导入、导出操作。普通用户的话,导入时,需要导入表的'insert'权限;select...into outfile方式导出时,需要导出表的'select'权限;mo-dump导出时,需要所有表(table *.*)的'select'权限和所有库(database *.*)的'show tables'权限。
关于MatrixOne
MatrixOne 是一款基于云原生技术,可同时在公有云和私有云部署的多模数据库。该产品使用存算分离、读写分离、冷热分离的原创技术架构,能够在一套存储和计算系统下同时支持事务、分析、流、时序和向量等多种负载,并能够实时、按需的隔离或共享存储和计算资源。云原生数据库MatrixOne能够帮助用户大幅简化日益复杂的IT架构,提供极简、极灵活、高性价比和高性能的数据服务。
MatrixOne企业版和MatrixOne云服务自发布以来,已经在互联网、金融、能源、制造、教育、医疗等多个行业得到应用。得益于其独特的架构设计,用户可以降低多达70%的硬件和运维成本,增加3-5倍的开发效率,同时更加灵活的响应市场需求变化和更加高效的抓住创新机会。在相同硬件投入时,MatrixOne可获得数倍以上的性能提升。
MatrixOne秉持开源开放、生态共建的理念,核心代码全部开源,全面兼容MySQL协议,并与合作伙伴打造了多个端到端解决方案,大幅降低用户的迁移和使用成本,也帮助用户避免了供应商锁定风险。
MatrixOrigin 官网:新一代超融合异构开源数据库-矩阵起源(深圳)信息科技有限公司 MatrixOne
Github 仓库:GitHub - matrixorigin/matrixone: Hyperconverged cloud-edge native database
关键词:超融合数据库、多模数据库、云原生数据库、国产数据库
相关文章:

MatrixOne实战系列回顾 | 导入导出项目场景实践
本次分享主要介绍MatrixOne导入导出以及项目场景实践。将从四个方向为大家演示MatrixOne的功能,分别是数据的导入、导出、对接数据集成工具,以及Java连接实战。 数据导入会使用三种方式将数据导入至 MatrixOne中。分别是insert语句、load data语句还有s…...

Find My音箱|苹果Find My技术与音箱结合,智能防丢,全球定位
音箱市场规模正在不断扩大。随着人们生活品质的提高,对音乐体验的需求也在不断升级。消费者对于蓝牙音箱的需求,已经从单纯的音质扩展到了功能、设计和价格等多个方面。随着移动化、即时化的视听娱乐需求的增长,蓝牙音箱性能、质量、外观设计…...

51单片机应用
目录 编辑 1. C51的数据类型 1.1 C51中的基本数据类型 1.2 特殊功能寄存器类型 2. C51的变量 2.1 存储种类 1. C51的数据类型 C51是一种基于8051架构的单片机,它支持以下基本数据类型: 位(Bit):可以表…...

系列三、ThreadLocal vs synchronized
一、ThreadLocal vs synchronized 虽然ThreadLocal与synchronized关键字都能用于处理多线程并发访问变量的问题,但是两者处理问题的角度和思路是不一样的。区别如下: 小总结:虽然上一篇中的案例都实现了线程隔离,但是使用ThreadLo…...

封装Redis工具类
基于StringRedisTemplate封装一个缓存工具类,满足下列需求: 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间 方法2:将任意Java对象序列化为json并存储在string类型的key中&…...
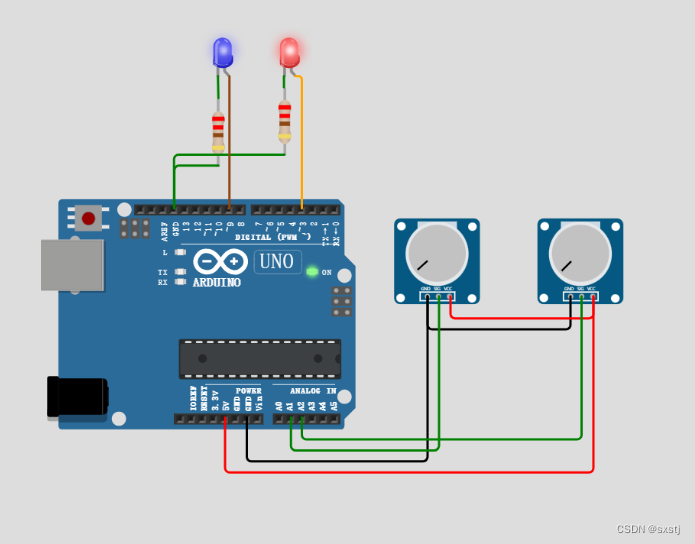
使用 millis() 函数作为延迟的替代方法(电位器控制延迟时间)
接线图: 代码: unsigned long currentMillis 0; unsigned long previousMillis_LED1 0; unsigned long LED1_delay0; unsigned long previousMillis_LED2 0; unsigned long LED2_delay0; #define LED1 3 #define LED2 9 #define P1 A2 …...
MySQL之BETWEEN AND包含范围查询总结
一、时间范围 查询参数格式与数据库类型相对应时,between and包含头尾,否则依情况 当数据库字段中存储的是yyyy-MM-dd格式,即date类型: 用between and查询, 参数yyyy-MM-dd格式时,包含头尾,相当…...
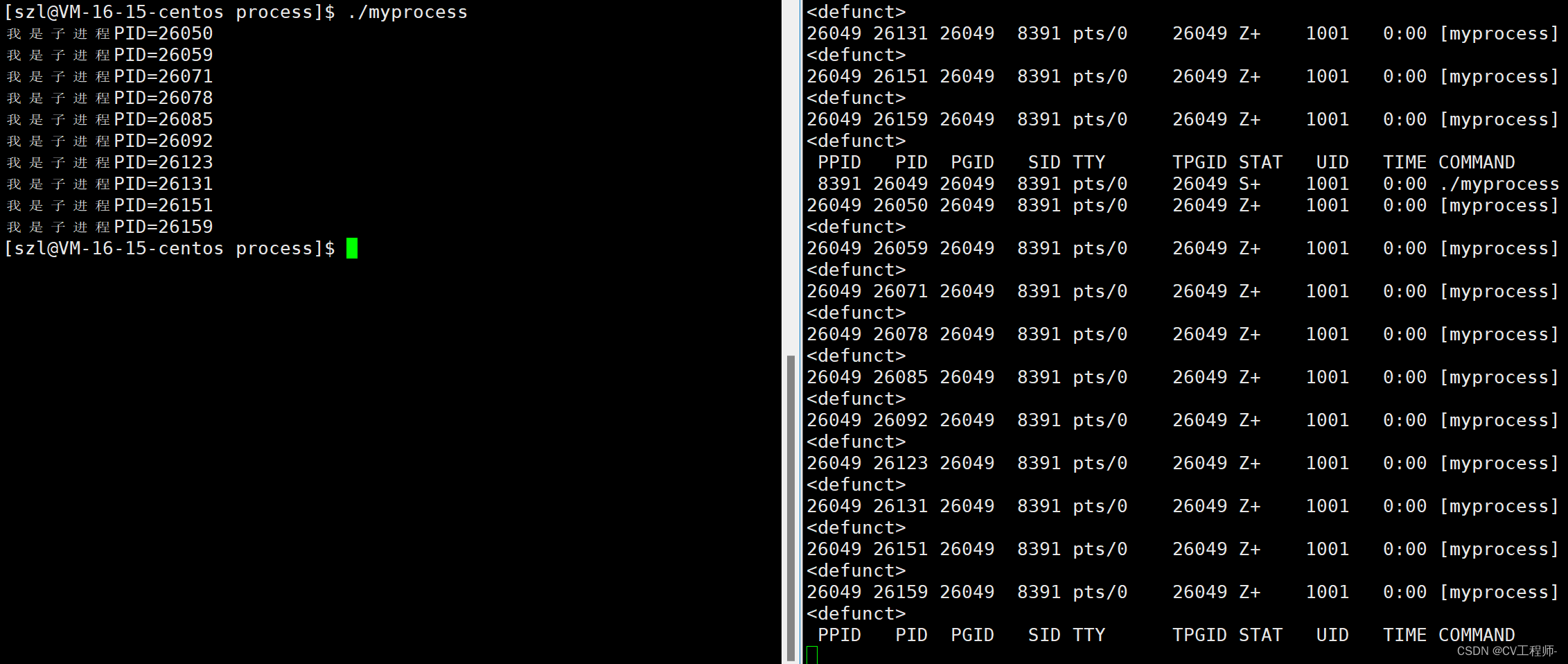
4.3、Linux进程(2)
个人主页:Lei宝啊 愿所有美好如期而遇 通过系统调用创建进程--fork函数 结果是什么呢? 为什么会出来三个打印呢? 就是因为父进程调用了fork函数创建出了子进程的task_struct,但是一个进程不止task_struct,还有代码和数据,他们…...
)
element-ui组件输入框之放大镜(搜索图标)
element-ui组件输入框之放大镜(搜索图标 前言一、解决suffix-icon"el-icon-search"绑定事件问题 前言 在使用element-ui组件时想给输入框组件中的放大镜图标也就是搜索图标绑定事件,可以进行如下操作: 一、解决suffix-icon"el-icon-sear…...
[oeasy]python001_先跑起来_python_三大系统选择_windows_mac_linux
先跑起来 🥊 Python 什么是 Python? Python [ˈpaɪθɑ:n]是 一门 适合初学者 的编程语言 类库 众多 几行代码 就能 出 很好效果 应用场景丰富 在 各个应用领域 都有 行内人制作的 python 工具类库 非常专业、 好用 特别是 人工智能领域 pytho…...

吴恩达《机器学习》9-4-9-6:实现注意:展开参数、梯度检验、随机初始化
一、实现注意:展开参数 在上一个视频中,讨论了使用反向传播算法计算代价函数的导数。在本视频中,将简要介绍一个实现细节,即如何将参数从矩阵展开为向量。这样做是为了在高级最优化步骤中更方便地使用这些参数。 二、梯度检验 在神经网络中…...

软信天成:如何利用大数据提高客户体验?
当今社会,市场均势正在发生变化,消费者拥有更多的选择和更高的决定权,传统的市场营销技巧注重提高品牌认知度和吸引潜在客户,现在早已过时。经济不确定性弥漫,数字化转型仍是大多数企业的优先选择,新的竞争…...
Vue 路由缓存 防止路由切换数据丢失 路由的生命周期
在切换路由的时候,如果写好了一丢数据在去切换路由在回到写好的数据的路由去将会丢失,这时可以使用路由缓存技术进行保存,这样两个界面来回换数据也不会丢失 在 < router-view >展示的内容都不会被销毁,路由来回切换数据也…...
基于ubuntu20.04安装ros系统搭配使用工业相机
基于ubuntu20.04安装ros系统搭配使用工业相机 1. ROS系统安装部署1.1更新镜像源1.1.1 备份源文件1.1.2 更新阿里源1.1.3 更新软件源 1.2 ros系统安装1.2.1 添加ros软件源1.2.2 添加秘钥1.2.3 更新软件源1.2.4 配置及更换最佳软件源1.2.5 ROS安装1.2.6 初始化rosdep1.2.7 设置环…...
网络运维与网络安全 学习笔记2023.11.20
网络运维与网络安全 学习笔记 第二十一天 今日目标 交换网路径选择、Eth-Trunk原理、动态Eth-Trunk配置 Eth-Trunk案例实践、MUX VLAN原理、MUX VLAN配置 交换网路径选择 STP的作用 在交换网络中提供冗余/备份路径 提供冗余路径的同时,防止环路的产生 影响同网…...

银行业数据分析算法应用汇总
数据分析在银行业的应用及具体案例 一、欺诈检测二、客户细分三、风险建模四、营销优化五、信用评分六、客户流失预测七、推荐引擎八、客户生命周期价值预测 一、欺诈检测 欺诈检测即通过分析交易模式,检测可能的欺诈行为,主要有以下几个方面 1.跨机构开…...

搜索引擎trick:成为搜索高手的秘籍
诸神缄默不语-个人CSDN博文目录 文章目录 1. 搜索指令1.1 "完全匹配搜索"1.2 -1.3 site1.4 filetype1.5 * 模糊搜索1.6 intitle1.7 inurl1.8 related1.9 inanchor 2. 组合搜索技巧3. 搜索引擎的选择4. 使用高级搜索功能4.1 时间限定搜索4.2 语言限定搜索4.3 使用搜索…...

基于springboot实现冬奥会科普平台系统【项目源码+论文说明】计算机毕业设计
基于SpringBoot实现冬奥会科普平台系统演示 摘要 随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理平台应运而生&…...

用C++标准库生成制定范围内的整数随机数
2023年11月22日,周三上午 #include <iostream> #include <random>int main() {std::random_device rd; // 随机设备,用于获取种子值std::mt19937 gen(rd()); // 使用 Mersenne Twister 引擎作为随机数生成器std::uniform_int_distribution&…...

使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。 ExLlamaV2是一个旨在从…...

ESPTool高级使用指南:5个技巧解决90%的固件烧录难题
ESPTool高级使用指南:5个技巧解决90%的固件烧录难题 【免费下载链接】esptool Serial utility for flashing, provisioning, and interacting with Espressif SoCs 项目地址: https://gitcode.com/gh_mirrors/es/esptool ESPTool是Espressif官方提供的串行工…...

MIT App Inventor终极指南:零代码打造专业移动应用的完整方案
MIT App Inventor终极指南:零代码打造专业移动应用的完整方案 【免费下载链接】appinventor-sources MIT App Inventor Public Open Source 项目地址: https://gitcode.com/gh_mirrors/ap/appinventor-sources 你是否曾梦想开发自己的手机应用,却…...

洛谷-算法2-5-进阶搜索4
P2960 [USACO09OCT] Invasion of the Milkweed G 题目描述 农夫约翰一直尽力保持牧场里长满丰盛、美味且健康的草供奶牛食用。然而,他输掉了这场战斗,因为邪恶的乳草在他的农场西北部站稳了脚跟。 牧场通常被划分为一个直角网格,高度为 Y&…...

AI代理上下文精准检索:Konteks-Skill项目实战与RAG优化
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫jamesalmeida/konteks-skill。乍一看这个名字,可能有点摸不着头脑,但如果你对AI助手、智能代理或者RAG(检索增强生成)技术感兴趣,那这个项目绝对…...
)
Git Restore命令介绍(撤销工作区修改、恢复多个文件、取消暂存:--staged、同时恢复暂存区和工作区:--worktree、-SW、从指定commit恢复文件--source)
文章目录Git Restore 命令详解:安全恢复文件内容的新方式一、git restore 是什么?二、Git 中三个重要区域三、git restore 最常见用途1. 撤销工作区修改四、恢复多个文件五、取消暂存(Unstage)六、同时恢复工作区 暂存区七、从指…...
)
AISMM基准数据首次全球统一发布(SITS2026核心机密解封)
更多请点击: https://intelliparadigm.com 第一章:SITS2026发布:AISMM行业基准数据 SITS2026 是面向智能交通系统(ITS)与多模态感知融合领域发布的全新行业基准数据集,由 AISMM(Autonomous In…...

现代前端模式库实践:从原子设计到工程化落地
1. 项目概述:从“pattern8”看现代前端开发中的模式库实践最近在梳理团队内部的前端资产时,又翻出了这个名为“pattern8”的项目。它不是一个独立的应用,而是一个基于特定设计系统(比如NVFivem)构建的、用于沉淀和复用…...

跨部门协作:如何让“水火不容“的开发与运维团队“并肩作战“?
作者身份:10年运维总监,亲历DevOps转型全链路前言做了十年运维,我见过太多团队在"开发与运维"的边界问题上反复拉扯——开发说运维不懂业务需求,运维说开发不考虑生产环境稳定性;开发嫌运维响应慢࿰…...

ASRock SBC-262M-WT工业主板解析与应用指南
1. ASRock SBC-262M-WT工业级主板深度解析在工业自动化和嵌入式系统领域,主板的选择往往决定了整个项目的稳定性和扩展性。ASRock Industrial最新推出的SBC-262M-WT 3.5英寸单板计算机,搭载Intel Atom x7433RE Amston Lake四核处理器,为工业场…...

SpringBoot项目优化技巧:让你的应用更高效、更稳定
在当今快速发展的软件开发领域,Spring Boot 以其简洁的配置和强大的功能,成为了构建企业级应用的首选框架。然而,随着应用规模的扩大和用户量的增长,如何确保 Spring Boot 项目在高并发、大数据量场景下的高效与稳定,成…...