mysql优化之explain 以及 索引优化
Mysql安装文档参考:https://blog.csdn.net/yougoule/article/details/56680952
Explain工具介绍
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈
在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是
执行这条SQL
注意:如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中
Explain分析示例
参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
创建表语句和数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for film_actor
-- ----------------------------
DROP TABLE IF EXISTS `film_actor`;
CREATE TABLE `film_actor` (`id` int(0) NOT NULL,`film_id` int(0) NOT NULL,`actor_id` int(0) NOT NULL,`remark` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_film_actor_id`(`film_id`, `actor_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of film_actor
-- ----------------------------
INSERT INTO `film_actor` VALUES (1, 1, 1, NULL);
INSERT INTO `film_actor` VALUES (2, 1, 2, NULL);
INSERT INTO `film_actor` VALUES (3, 2, 1, NULL);-- ----------------------------
-- Table structure for film
-- ----------------------------
DROP TABLE IF EXISTS `film`;
CREATE TABLE `film` (`id` int(0) NOT NULL AUTO_INCREMENT,`name` varchar(10) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of film
-- ----------------------------
INSERT INTO `film` VALUES (3, 'film0');
INSERT INTO `film` VALUES (1, 'film1');
INSERT INTO `film` VALUES (2, 'film2');-- ----------------------------
-- Table structure for actor
-- ----------------------------
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (`id` int(0) NOT NULL,`name` varchar(45) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL,`update_time` datetime(0) NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of actor
-- ----------------------------
INSERT INTO `actor` VALUES (1, 'aa', '2023-11-19 09:28:49');
INSERT INTO `actor` VALUES (2, 'b', '2023-11-19 09:28:49');
INSERT INTO `actor` VALUES (3, 'c', '2023-11-19 09:28:49');
INSERT INTO `actor` VALUES (4, 'a', '2023-11-19 09:28:49');SET FOREIGN_KEY_CHECKS = 1;
普通查询
explain select * from film where id = 1;

show warnings;

explain中的列
1. id列
id列的编号是 select 的序列号,有几个 select 就有几个id,id的顺序是按 select 出现的顺序增长的。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
2. select_type列
select_type 指的是查询类型,表示对应行是简单还是复杂的查询。
1)simple:简单查询。查询不包含子查询和union
explain select * from film where id = 2;
2)primary:复杂查询中最外层的 select
3)subquery:包含在 select 中的子查询(不在 from 子句中)
4)derived:包含在 from 子句中的子查询
MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
用这个例子来了解 primary、subquery 和 derived 类型
set session optimizer_switch='derived_merge=off'; #关闭mysql5.7新特性对衍生表的合并优化
explain select (select 1 from actor where id = 1) from (select * from film where id = 1) der;
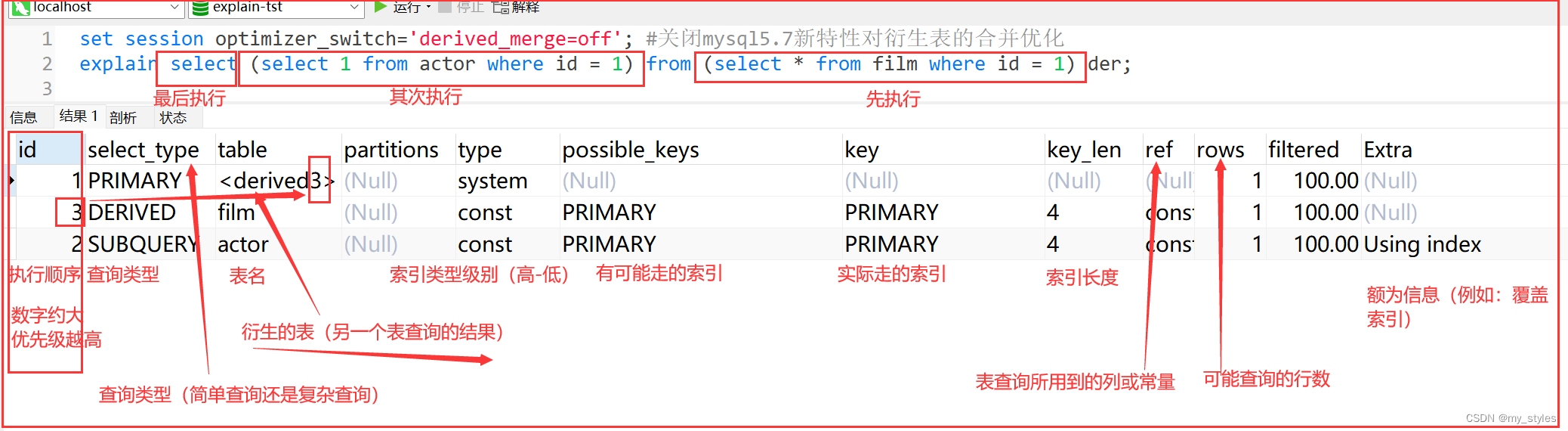
id为3的是from后面的派生表,id为2的是select中的子查询,id为1的是最外面也就是最左边的select
set session optimizer_switch='derived_merge=on'; #还原默认配置
5)union:在 union 中的第二个和随后的 select
explain select 1 union all select 1;

3. table列
这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,table列是 格式,表示当前查询依赖 id=N 的查询,于是先执行id=N 的查询。
当有 union 时,UNION RESULT 的 table 列的值为<union1,2>,1和2表示参与 union 的 select 行id。
4. type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref
NULL:
mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表
explain select min(id) from film;

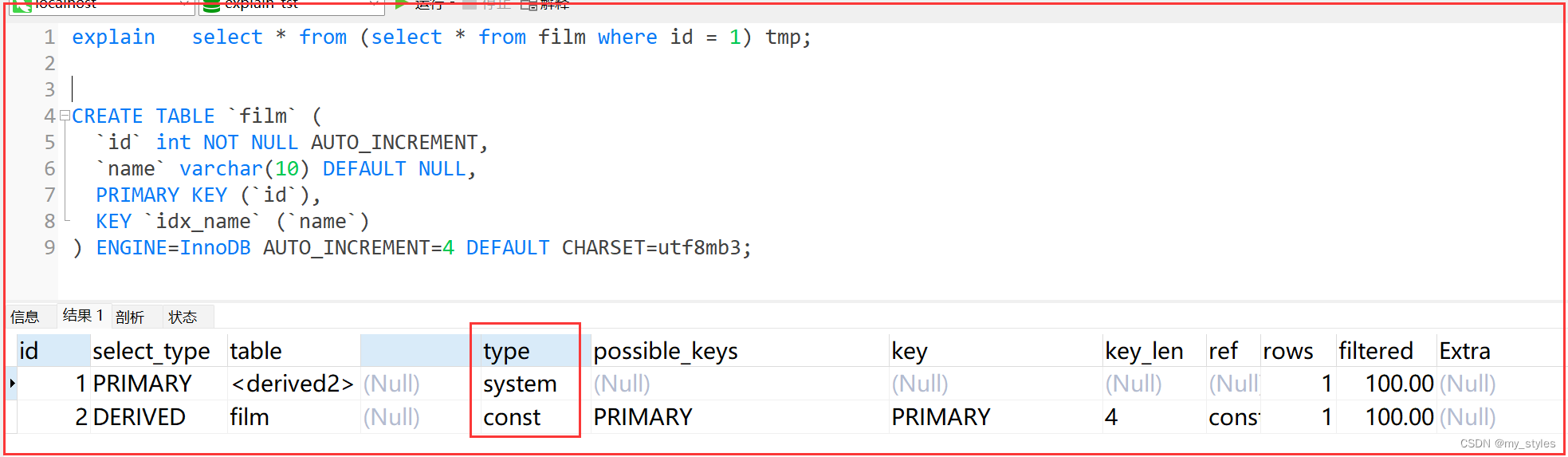
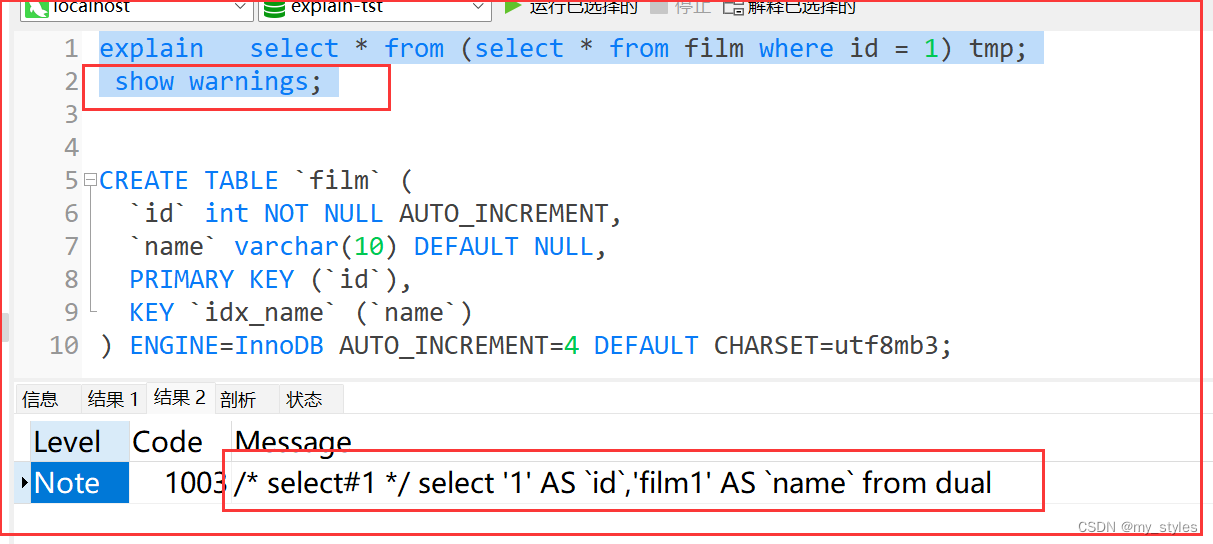
const, system:
mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。system是const的特例,表里只有一条元组匹配时为system
explain extended select * from (select * from film where id = 1) tmp;
explain select * from (select * from film where id = 1) tmp;
eq_ref:
primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能是在const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。
explain select * from film_actor left join film on film_actor.film_id = film.id;

ref:
相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
- 简单 select 查询,name是普通索引(非唯一索引)
explain select * from film where name = 'film1';

- 关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。
explain select film_id from film left join film_actor on film.id = film_actor.film_id;

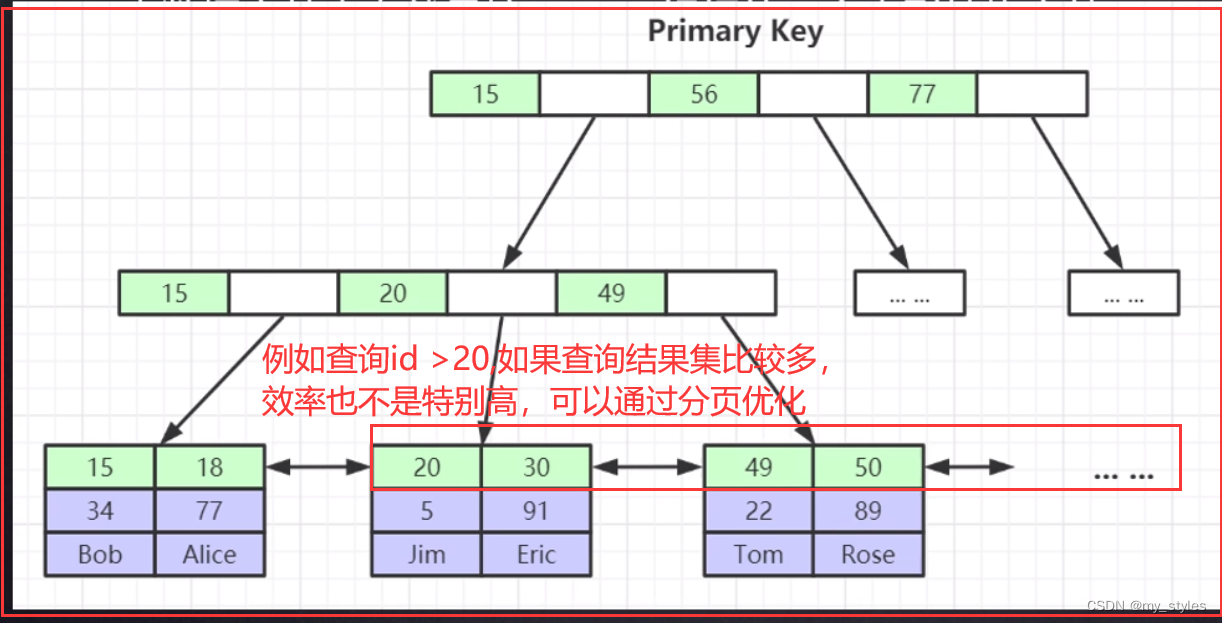
range:
范围扫描通常出现在 in(), between ,> ,<, >= 等操作中。使用一个索引来检索给定范围的行。
explain select * from actor where id > 1;

index:
explain select * from film;
explain select * from film WHERE name = 'aa'
扫描全索引就能拿到结果,一般是扫描某个二级索引(除主键索引的其他索引),这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
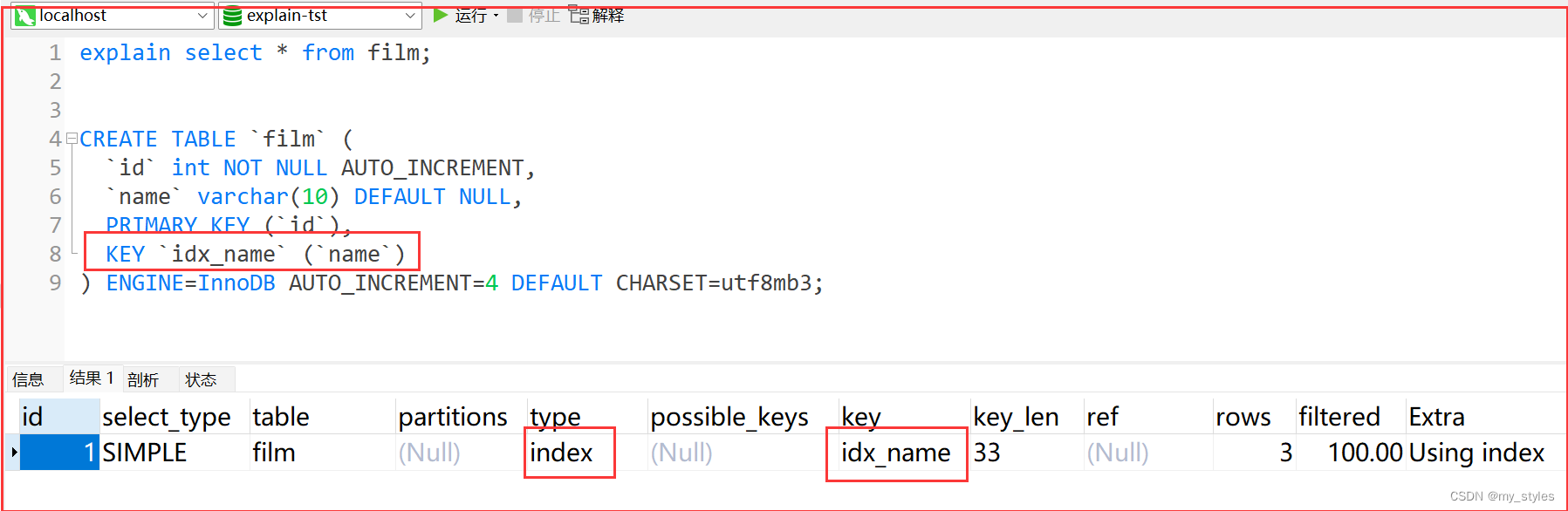
index 场景实际是需要优化的,虽然走了索引,但性能不是很高,最好达到ref级别;因为index级别是从左到右遍历索引(磁盘io),例如可以通过分页;如果不添加分页,一次全表查询,若数据量比较大内存有可能会暴掉,
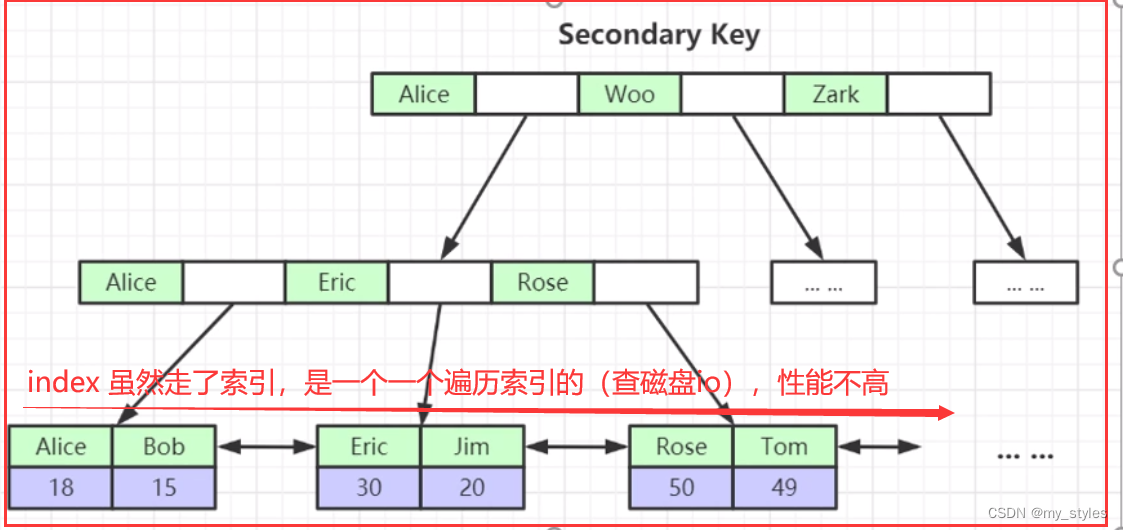
explain select * from film WHERE name = 'aa'
添加查询条件 所有类型走了ref 级别 比 index 级别高很多;

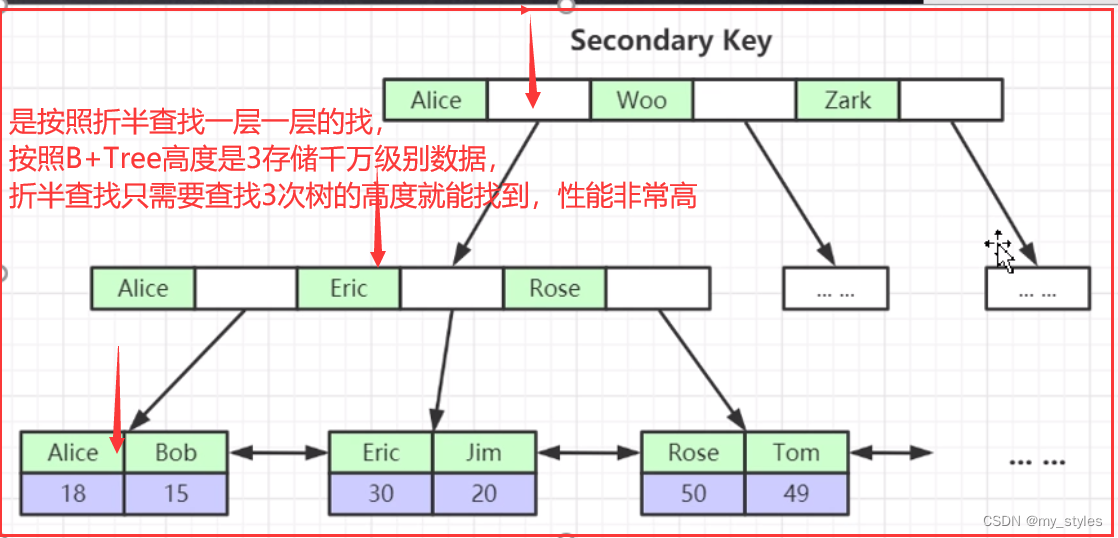
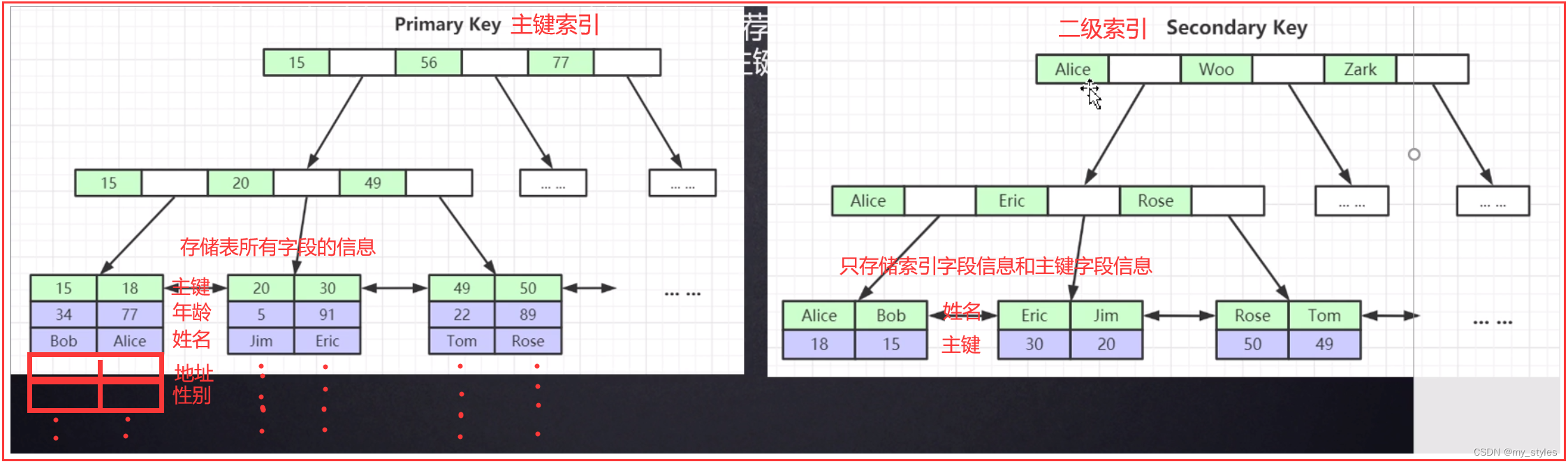
mysql 内部优化原则;主键索引(聚簇索引)
二级索引(普通索引)里面有索引字段和主键id;当select 后边所查询的字段在主键索引里面有 在二级索引里面也有,( 例如:select id,name from 表 (id:主键索引 和name:普通索引)),此时会优先使用二级索引;原因:普通索引要比主键索引小;这里的小 指的是普通索引只存了索引字段的数据,而主键索引存了全部字段的数据;(例如一个表10个字段,主键索引是存储这10个字段的数据,而二级索引只存储主键索引和普通索引所对应的数据);
如果查询是字段部分在二级索引,部分不在二级索引 此时会优先使用主键索引,以为部分没有的字段信息是需要回表二次查询,性能会降低,
ALL:
即全表扫描,扫描你的聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。
explain select * from actor;

因为mysql的 innoDB 引擎是 .ibd 文件的聚簇索引(主键索引树);全表扫描实际是扫描这个聚簇索引的根节点;从第一个节点开始扫描;
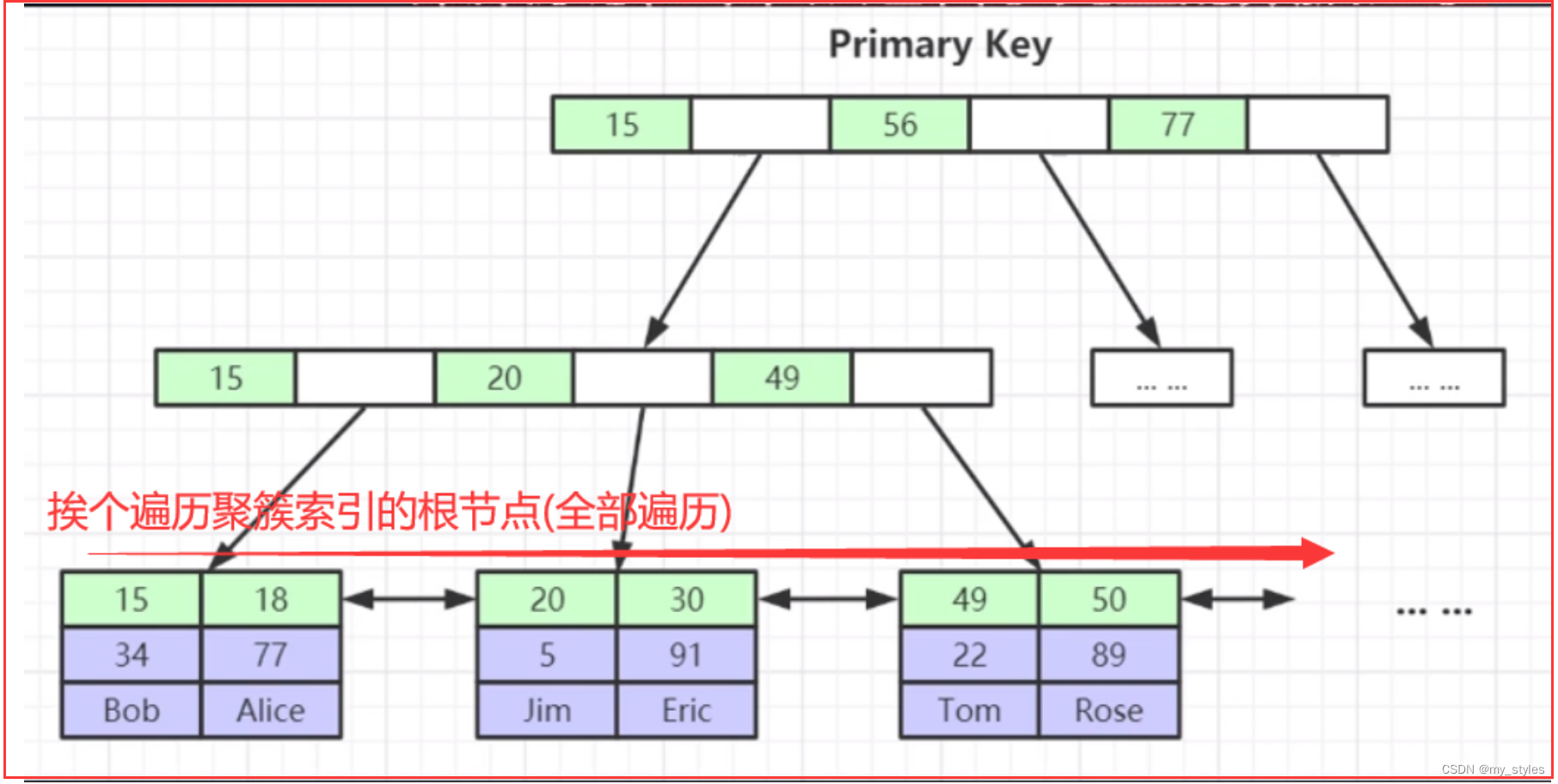
explain select * from actor where id = 1;

5. possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
6. key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 forceindex、ignore index。
7. key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
举例来说,film_actor的联合索引 idx_film_actor_id 由 film_id 和 actor_id 两个int列组成,并且每个int是4字节。通过结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找。
explain select * from film_actor where film_id = 2;

key_len计算规则如下:
-
字符串,char(n)和varchar(n),5.0.3以后版本中,n均代表字符数,而不是字节数,如果是utf-8,一个数字或字母占1个字节,一个汉字占3个字节
char(n):如果存汉字长度就是 3n 字节
varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长度,因为varchar是变长字符串
-
数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigint:8字节
-
时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
-
如果字段允许为 NULL,需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
8. ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
9. rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数
10. Extra列
这一列展示的是额外信息。常见的重要值如下:
1)Using index:使用覆盖索引
覆盖索引定义:mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说是用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值。(不需要回表)
explain select film_id from film_actor where film_id = 1;
CREATE TABLE `film_actor` (
`id` int NOT NULL,
`film_id` int NOT NULL,
`actor_id` int NOT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;

2)Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖;这种需要给name 字段添加索引进行优化
explain select * from actor where name = 'a';

3)Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围
explain select * from film_actor where film_id > 1;

4)Using temporary:mysql需要创建一张临时表来处理查询
- actor.name没有索引,此时创建了张临时表来distinct
explain select distinct name from actor;

actor.name没有索引;是将所有数据未通过索引查出来然后放入一个临时表,通过临时表再去重;
2. film.name建立了idx_name索引,此时查询时extra是using index,没有用临时表
explain select distinct name from film;

film 表采用了覆盖索引(查询字段通过覆盖索引),先通过索引查询的时候过滤重复数据,然后再加载到内存,数据是去重后的,通过索引查询效率高;
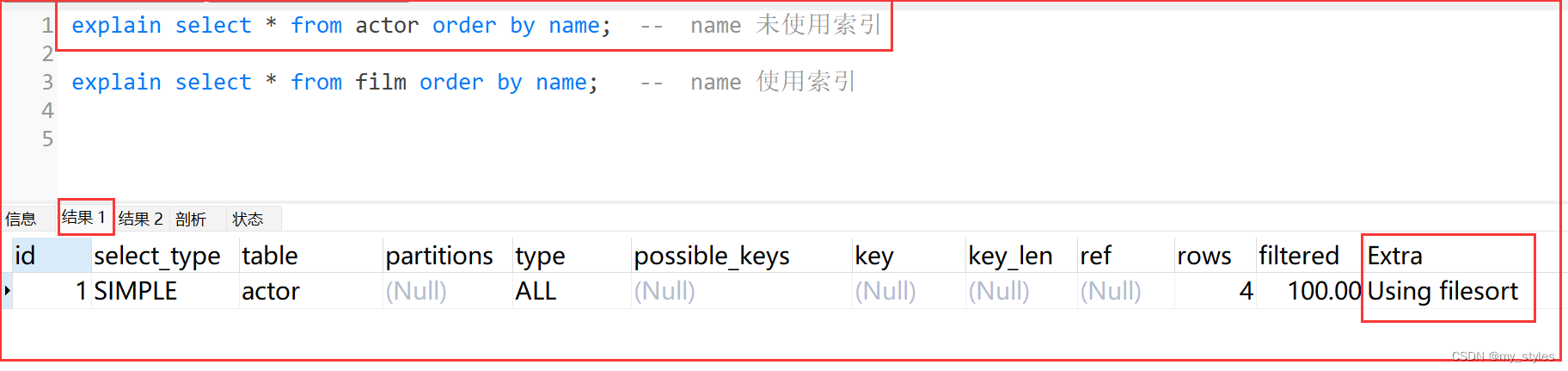
5)Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。
这种情况下一般也是要考虑使用索引来优化的。
- actor.name未创建索引,会浏览actor整个表,保存排序关键字name和对应的id,然后排序name并检索行记录
explain select * from actor order by name;
未使用索引,需要先加载到内存或者磁盘,然后再排序,效率低的多;
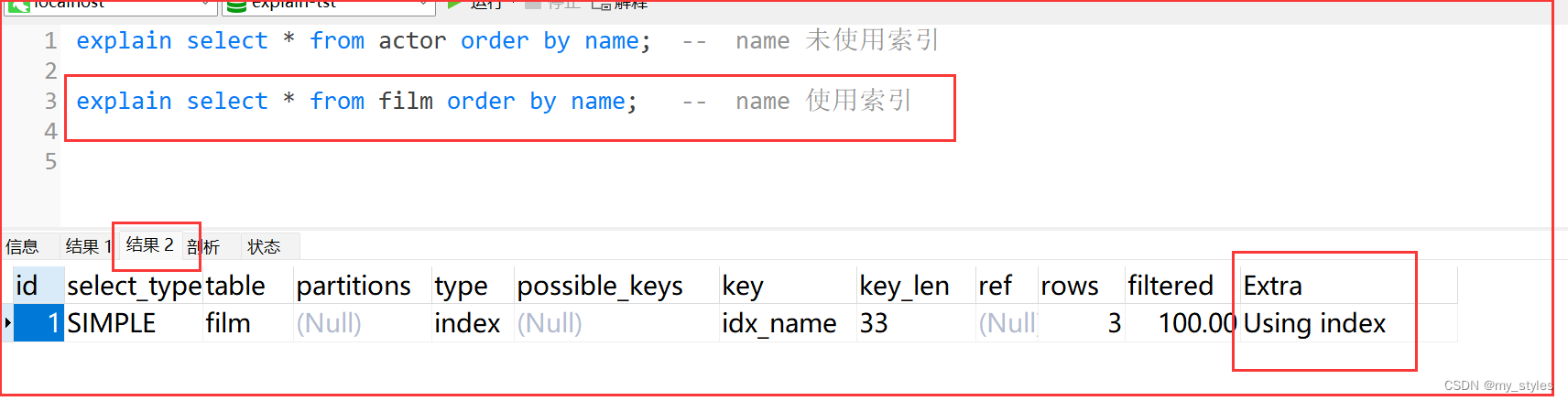
2. film.name建立了idx_name索引,此时查询时extra是using index
explain select * from film order by name;
使用索引;因为索引已经是拍好序的,所有直接拿出来就可以,不需要再排序;
二、索引最佳实践
示例表
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='员工记录表';INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei',23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
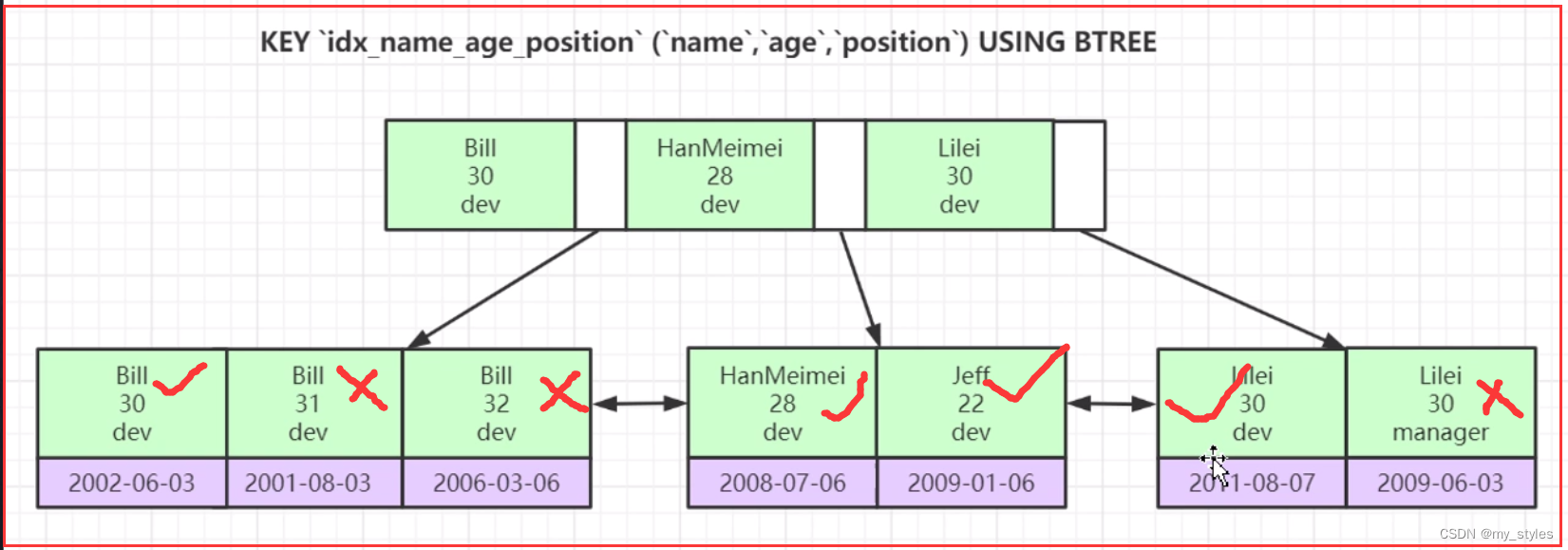
1.全值匹配
匹配索引的第一个列
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei';
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22;
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';

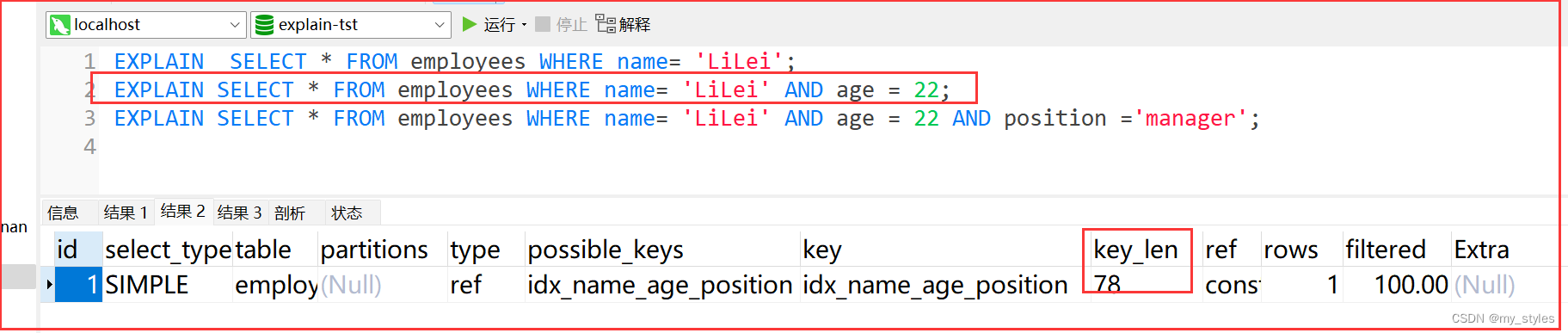

联合索引字段 `name`,`age`,`position`(需要遵循最左前缀原则,)
// 按照 `name`,`age`,`position` 的顺序拼接条件,是走索引的
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
顺序倒过来 `position` ,`age`,`name`, 任然会走索引,因为mysql 优化器会给优化(这也是遵循最左前缀原则,所谓最左前缀原则是针对b+树的结构,第一层先是按照name排序,第二层按照 age排序,第三层按照 position 排序,如果没有第一层,那么二三层排序毫无意义)
EXPLAIN SELECT * FROM employees WHERE position ='manager' AND age = 22 AND name= 'LiLei';
2.最左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
下面只有第一个走索引
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';
3.不在索引列上做任何操作
计算、函数、(自动或手动)类型转换,会导致索引失效而转向全表扫描(8.0函数索引可以解决函数操作使索引失效的问题)(截取name3位数,索引里面都没有,怎么可能回走索引呢)
EXPLAIN SELECT * FROM employees WHERE left(name,3) = 'LiLei';

日期转化为范围查询可能走索引,可以用这种方式优化下面的查询:
1.给hire_time增加一个普通索引:
ALTER TABLE `employees` ADD INDEX `idx_hire_time` (`hire_time`) USING BTREE ;
EXPLAIN select * from employees where date(hire_time) ='2018‐09‐30';
不走索引

2.转化为日期范围查询
就可能走索引了,key没有值是优化器认为不用索引更快,但是有可能走索引的
EXPLAIN select * from employees where hire_time >='2023-10-19 12:22:26' and hire_time <='2023-12-19 12:22:26';

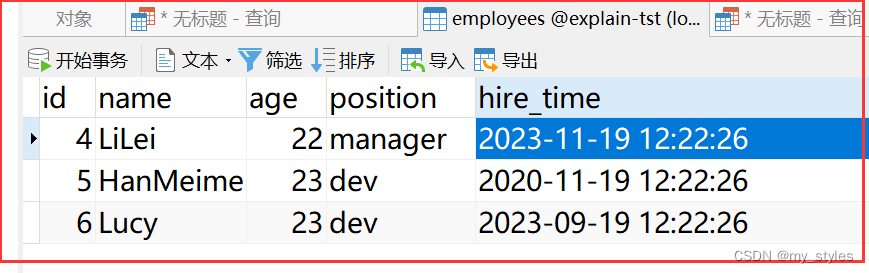
4.范围查询的索引列放到最后
因为存储引擎不能使用索引中范围条件右边的列
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age > 22 AND position ='manager';

索引列是name,age,position,上面key_len没有等于140,说明索引未被充分使用。因为当第二个列是范围,从索引树中可看出第三个列就可能不是顺序的了,所以第三列不能被使用,建议范围查询的索引列放到最后,改成name,position,age
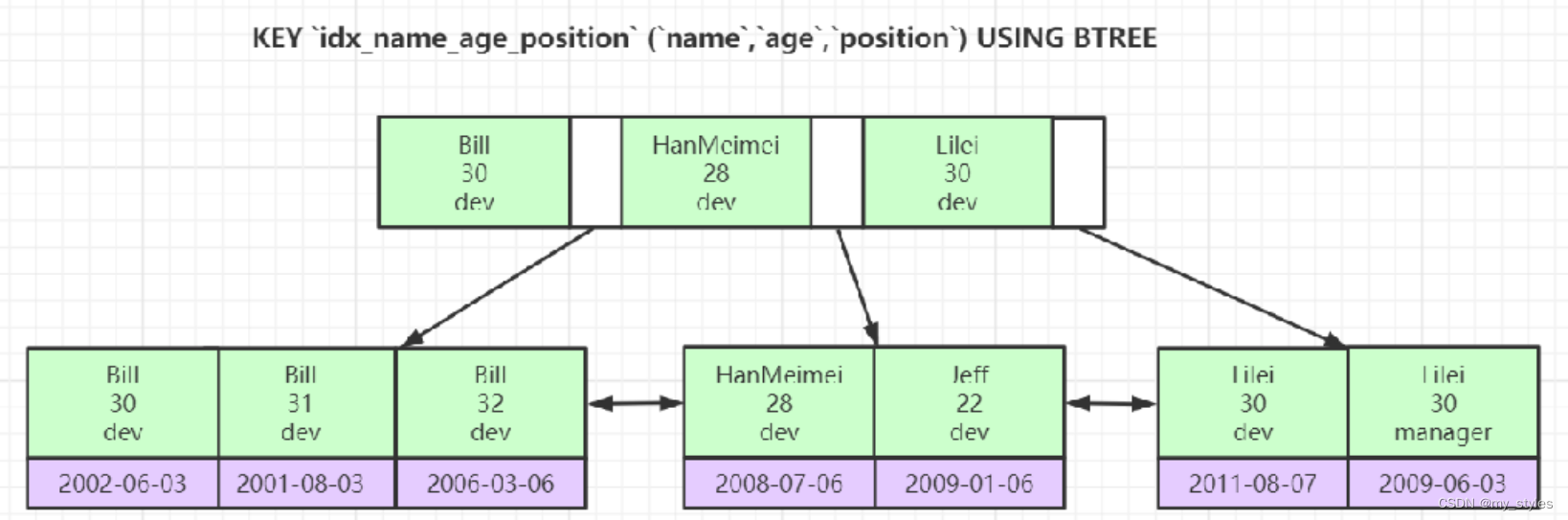
5.尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少 select * 语句
使用覆盖索引可以避免回表的开销
第一个Extra显示使用到了覆盖索引,第二个未使用到;
EXPLAIN SELECT name,age FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';

EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';

6.mysql在使用不等于(!=或者<>),not in ,not exists 的时候可能无法使用索引会导致全表扫描
EXPLAIN SELECT * FROM employees WHERE name != 'LiLei';

< 小于、 > 大于、 <=、>= 这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引
7.is null,is not null 一般情况下也无法使用索引
EXPLAIN SELECT * FROM employees WHERE name is null

8.like以通配符开头(‘$abc…’)mysql索引失效会变成全表扫描操作
EXPLAIN SELECT * FROM employees WHERE name like '%Lei'

前面没 %的走索引 取值索引去前面几个字符,这些字符是有序的;
取值索引去前面几个字符,这些字符是有序的;
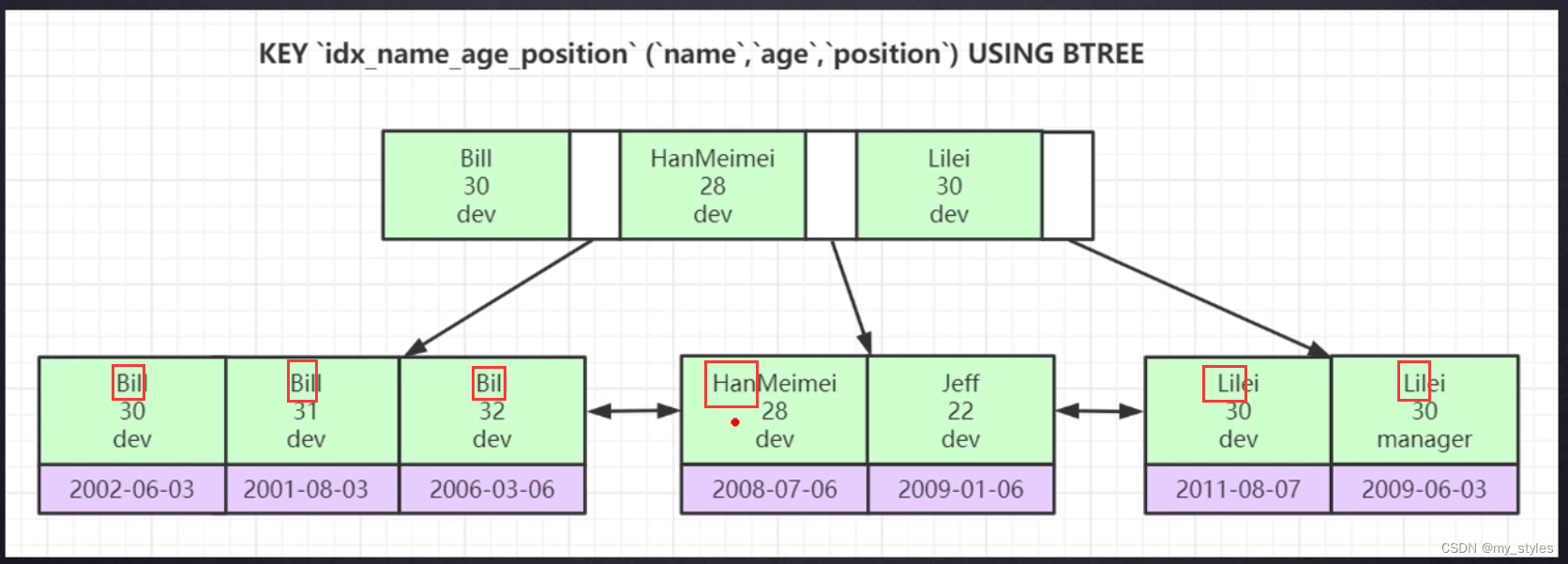
EXPLAIN SELECT * FROM employees WHERE name like 'Lei%'
 问题:解决like’%字符串%'索引不被使用的方法?
问题:解决like’%字符串%'索引不被使用的方法?
a)使用覆盖索引,查询字段必须是建立覆盖索引字段
EXPLAIN SELECT name,age,position FROM employees WHERE name like '%Lei%';

9.字符串不加单引号索引失效
EXPLAIN SELECT * FROM employees WHERE name = 1000;

10.少用or或in,用它查询时,mysql不一定使用索引
mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引,详见范围查询优化
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' or name = 'HanMeimei';

11.范围查询优化
给年龄添加单值索引
ALTER TABLE `employees` ADD INDEX `idx_age` (`age`) USING BTREE ;
explain select * from employees where age >=1 and age <=2000;

没走索引原因:mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引。比如这个例子,可能是由于单次数据量查询过大导致优化器最终选择不走索引
优化方法:可以将大的范围拆分成多个小范围
explain select * from employees where age >=1 and age <=1000;
explain select * from employees where age >=1001 and age <=2000;


还原最初索引状态
ALTER TABLE `employees` DROP INDEX `idx_age`;
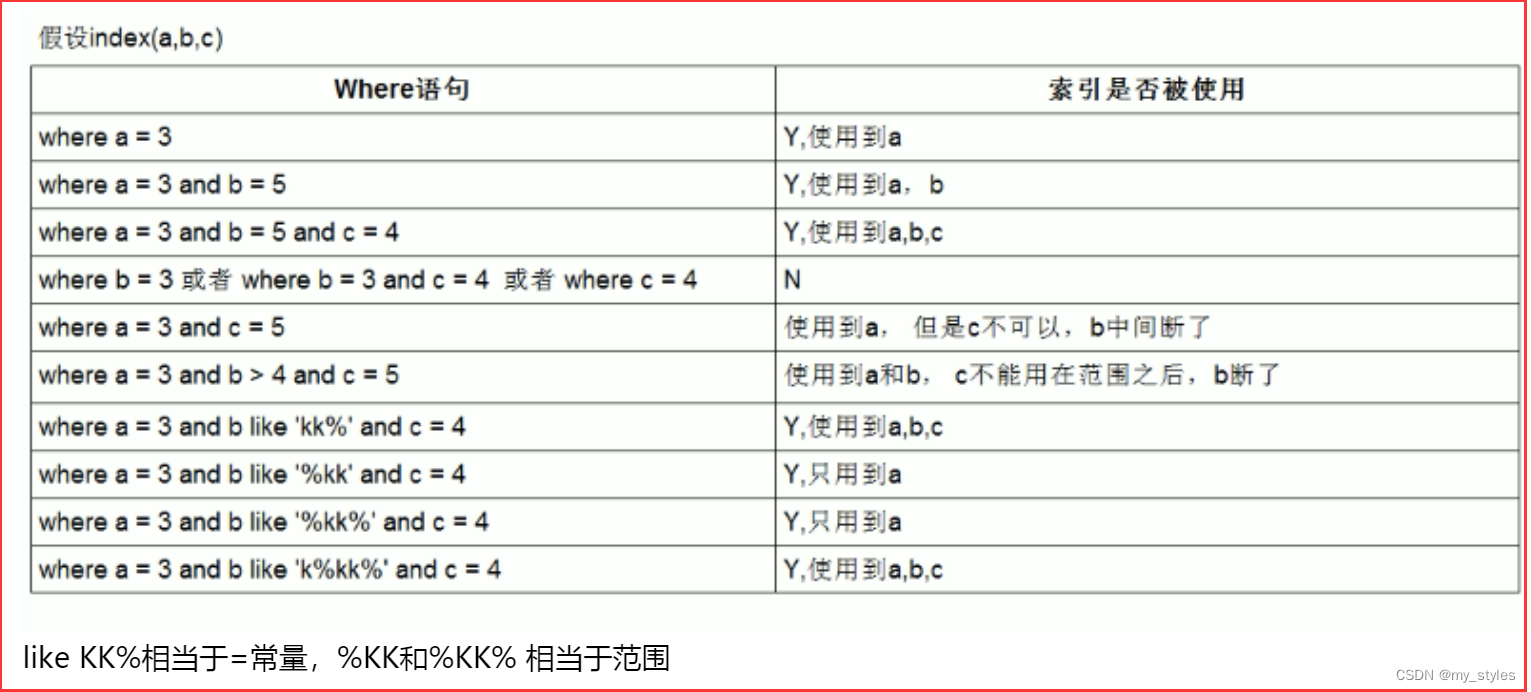
三、索引总结表
‐‐m ysql5.7关闭ONLY_FULL_GROUP_BY报错
select version(),@@sql_mode;SET sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''))

相关文章:
mysql优化之explain 以及 索引优化
Mysql安装文档参考:https://blog.csdn.net/yougoule/article/details/56680952 Explain工具介绍 使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈 在 select 语句之前增加 explain 关键字,MySQL 会在查询上设…...
)
WebSocket --- ws模块源码解析(详解)
摘要 在这一篇文章中,写了如何在node端和web端,实现一个WebSocket通信。 WebSocket在node端和客户端的使用 而在node端里面,我们使用了ws模块来创建WebSocket和WebSocketServer,那ws模块是如何做到可以和客户端进行双向通信的呢…...

一文带你拿下MySQL之增删查改(基础)
✏️✏️✏️今天给各位带来的是关于数据库增删查改基础方面的知识。 清风的CSDN博客 😛😛😛希望我的文章能对你有所帮助,有不足的地方还请各位看官多多指教,大家一起学习交流! 动动你们发财的小手…...

2023亿发数字化智能工单,专业管理工单处理全流程,助力企业转型腾飞
伴随着智能化和信息化的不断深入,企业数字化转型势如腾飞。在这个过程中,工单管理成为生产、家电、后勤等多个管理场景下频繁应用的关键环节。如何满足管理方对设备、服务等智能化管理的需求,提升工单管理效率、规范管理流程,并实…...

JavaScript 常用符号
JavaScript是一门基础性的编程语言,常用于web开发中。JS中有许多特殊的符号,这些符号的用法十分重要,直接影响代码的正确性和可读性。在日常编写中,我们会频繁使用以下几个符号。 一、等于号() 等于号在JS…...

GPT-4:论文阅读笔记
GPT-4的输入和输出:输入的内容是文本或图片,输出的内容是文本。因此,GPT-4是一种输入端多模态的模型。GPT-4的效果:在真实世界中还是比不上人类,但是在很多专业性的任务上已经达到了人类的水平,甚至超过人类…...

hm商城微服务远程调用及拆分
RequiredArgsConstructor是Lombok库中的一个注解 它会自动在类中生成一个构造函数,这个构造函数会接收类中所有被标记为final的字段,并将其作为参数。这个注解可以帮助我们减少样板代码,例如手动编写构造函数。 eg: public fin…...
设置指定时间之前的时间不可选
1、el-date-picker设置今天之前的日期不可选 <el-date-picker style"width: 100%" type"date" v-model"form.resetDate" align"right" :value-format"yyyy-MM-dd" placeholder"选择调整日期":disabled"t…...

Java使用Redis来实现分布式锁
Java使用Redis来实现分布式锁 在单节点服务中,我们可以使用synchronized来保证同一时间内只允许一个线程执行限定的代码块。但是如果我们是多节点服务呢,因为synchronized是针对服务内部的,其他服务是无法受到他的干预的。那么如何保证多个节…...
移动端表格分页uni-app
使用uni-app提供的uni-table表格 网址:https://uniapp.dcloud.net.cn/component/uniui/uni-table.html#%E4%BB%8B%E7%BB%8D <uni-table ref"table" :loading"loading" border stripe type"selection" emptyText"暂无更多数据…...

全志R128芯片RTOS调试指南
RTOS 调试指南 此文档介绍 FreeRTOS 系统方案支持的常用软件调试方法,帮助相关开发人员快速高效地进行软件调试,提高解决软件问题的效率。 栈回溯 栈回溯是指获取程序的调用链信息,通过栈回溯信息,能帮助开发者快速理清程序执行…...

超级实用的程序员接单平台,看完少走几年弯路,强推第一个!
“前途光明我看不见,道路曲折我走不完。” 兜兜转转,心心念念,念念不忘,必有回响。终于找到了… 网络上好多人都在推荐程序员线上接单,有人说赚得盆满钵满,有的人被坑得破口大骂,还有的人甚至还…...

前端字符串方法汇总
1、length属性 const sss lengthconsole.log(字符串长度是, sss.length) 2、chartAt() charAt()和charCodeAt()方法都可以通过索引来获取指定位置的值: charAt() 方法获取到的是指定位置的字符;charCodeAt()方法获取的是指定位置字符的Unicode值。 …...

12 分布式锁加入看门狗
1、看门狗的流程图 2、看门狗的代码实现 /****类说明:Redis的key-value结构*/ public class LockItem {private final String key;private final String value;public LockItem(String key, String value) {this.key key;this.value value;}public String getKey…...

怎么判断list是否为null
List<Entity> baseMess new ArrayList<>(); baseMess motiveService.getBaseMessage(machine.get(i),preDate,nowDate); System.out.println("获取Size"baseMess.size()); baseMess.removeIf(Objects::isNull); System.out.println("获取Size"…...

11.数据公式中使用2个 $$ a =b $$,是什么意思?
在 LaTeX 中,双美元符号 $$ 用于进入和退出独立的数学模式,也就是数学公式模式。在 $$ 中的文本将被视为数学公式,并以数学排版的方式显示。 具体地说,$$ 的使用是为了在文档中创建居中显示的独立数学公式。这意味着公式将单独占…...

设计模式-14-迭代器模式
经典的设计模式有23种,但是常用的设计模式一般情况下不会到一半,我们就针对一些常用的设计模式进行一些详细的讲解和分析,方便大家更加容易理解和使用设计模式。 1-原理和实现 迭代器模式(Iterator Design Pattern)&a…...

防雷接地+防雷工程施工综合方案
一、地凯科技防雷工程接地概述 防雷接地工程是指在建筑物或其他设施上安装防雷装置,以防止雷电对人员、设备和建筑物造成危害的工程。防雷装置主要包括避雷针(网)、引下线、接地体(网)等部分,其中接地体&a…...

排序算法--选择排序
实现逻辑 ① 第一轮从下标为 1 到下标为 n-1 的元素中选取最小值,若小于第一个数,则交换 ② 第二轮从下标为 2 到下标为 n-1 的元素中选取最小值,若小于第二个数,则交换 ③ 依次类推下去…… void print_array(int a[], int n){f…...

【Web】Ctfshow SSRF刷题记录1
核心代码解读 <?php $url$_POST[url]; $chcurl_init($url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $resultcurl_exec($ch); curl_close($ch); ?> curl_init():初始curl会话 curl_setopt():会…...

技能进化系统:用数据可视化与网状图谱管理个人知识成长
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“skill-evolution”。光看这个名字,你可能会联想到技能树、能力进化或者某种学习系统。没错,这个项目本质上就是一个个人技能管理与进化追踪系统。它不是那种简单的待办清单&a…...

自托管AI记忆系统Mnemonic:为智能体构建本地化记忆中枢
1. 项目概述:为AI智能体构建本地化记忆中枢 在AI智能体(Agent)的开发与使用过程中,一个长期存在的核心痛点就是“健忘症”。无论是基于OpenAI GPT还是其他大语言模型的Agent,在默认状态下,每次对话都是全新…...

【2026奇点智能技术大会权威解码】:AISMM改进路线图的5大颠覆性演进与企业落地时间窗
更多请点击: https://intelliparadigm.com 第一章:2026奇点智能技术大会:AISMM改进路线图 在2026奇点智能技术大会上,AISMM(Autonomous Intelligent System Meta-Model)正式发布v3.2核心规范,聚…...

Davinci Resolve/达芬奇 21安装教程及下载
软件介绍: DaVinci Resolve Studio 是一款世界上第一个结合了专业离线和在线编辑,色彩校正,音频后期制作和Fusion视觉特效于一体的软件工具的解决方案!你可以获得无限的创作灵活性,因为 DaVinci Resolve 让个体艺术家更容易探索不…...

交互式代码重构工具refrag:平衡自动化与人工判断的智能辅助实践
1. 项目概述:一个用于代码重构的智能辅助工具最近在和一些资深开发朋友交流时,大家普遍提到一个痛点:面对遗留代码库,重构工作既重要又令人头疼。手动重构耗时费力,还容易引入新Bug;而完全依赖自动化工具&a…...
)
别再只用fft了!Matlab里pspectrum画频谱图的5个隐藏技巧(附代码)
别再只用FFT了!Matlab里pspectrum画频谱图的5个隐藏技巧(附代码) 频谱分析是信号处理中最基础也最常用的技术之一。对于已经掌握FFT基础操作的Matlab用户来说,pspectrum函数就像一把瑞士军刀,能快速实现从简单频谱到复…...

2026年必看:八款热门AI编程工具横评
AI技术深度重构开发流程,高效AI编程工具已成为开发者提升效率、降低门槛的核心利器。以下精选2026年全球主流AI编程工具,从功能、体验、场景适配度展开全面评测。一、Trae(字节跳动旗下AI原生IDE)作为字节跳动自主研发的AI原生集成…...

IT 领导者如何衡量 agentic AI 项目的 ROI
作者:来自 Elastic Devin Rhoades 随着组织从生成式 AI 实验阶段迈向运营级部署,一个新的机会正在逐渐清晰:代理式 AI(agentic AI)。具备感知、决策和行动能力的 AI agent 正在快速普及。根据 Gartner 的数据ÿ…...

opencv 和opencv_contrib官网 不同版本的下载地址
opencv Releases opencv/opencv https://github.com/opencv/opencv_contrib/releases/tag/4.0.1 Release 3.4.13 opencv/opencv_contrib GitHubhttps://github.com/opencv/opencv_contrib/releases/tag/3.4.13 4.0.1 和3.4.13 都是版本号。下载就行。...
)
Install-TidGi-Windows-x64安装步骤详解(附TidGi知识库搭建教程)
Install-TidGi-Windows-x64.exe是 TidGi(太记) 桌面知识管理软件的 Windows 64位 安装包。这玩意儿是基于 TiddlyWiki 做的笔记和知识管理工具,带自动 Git 备份、能当博客用,搞个人知识库的人用得挺多。 一、准备工作 下载安装包…...