MySQL 事务的底层原理和 MVCC(二)
7.2. undo 日志
7.2.1. 事务回滚的需求
我们说过事务需要保证原子性,也就是事务中的操作要么全部完成,要么什么也不做。但是偏偏有时候事务执行到一半会出现一些情况,比如:
情况一:事务执行过程中可能遇到各种错误,比如服务器本身的错误,操作系统错误,甚至是突然断电导致的错误。
情况二:程序员可以在事务执行过程中手动输入 ROLLBACK 语句结束当前的事务的执行。
这两种情况都会导致事务执行到一半就结束,但是事务执行过程中可能已经修改了很多东西,为了保证事务的原子性,我们需要把东西改回原先的样子,这个过程就称之为回滚(英文名:rollback),这样就可以造成这个事务看起来什么都没做,所以符合原子性要求。
每当我们要对一条记录做改动时(这里的改动可以指 INSERT、DELETE、UPDATE),都需要把回滚时所需的东西都给记下来。比方说:
你插入一条记录时,至少要把这条记录的主键值记下来,之后回滚的时候只需要把这个主键值对应的记录删掉。
你删除了一条记录,至少要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入到表中。
你修改了一条记录,至少要把修改这条记录前的旧值都记录下来,这样之后回滚时再把这条记录更新为旧值。
这些为了回滚而记录的这些东西称之为撤销日志,英文名为 undo log/undo日志。这里需要注意的一点是,由于查询操作(SELECT)并不会修改任何用户记录,所以在查询操作执行时,并不需要记录相应的 undo 日志。
当然,在真实的 InnoDB 中,undo 日志其实并不像我们上边所说的那么简单,不同类型的操作产生的 undo 日志的格式也是不同的。
7.2.2. 事务 id
7.2.2.1. 给事务分配 id 的时机
一个事务可以是一个只读事务,或者是一个读写事务:
我们可以通过 START TRANSACTION READ ONLY 语句开启一个只读事务。
在只读事务中不可以对普通的表(其他事务也能访问到的表)进行增、删、改操作,但可以对用户临时表做增、删、改操作。
我们可以通过 START TRANSACTION READ WRITE 语句开启一个读写事务,或者使用 BEGIN、START TRANSACTION 语句开启的事务默认也算是读写事务。
在读写事务中可以对表执行增删改查操作。
如果某个事务执行过程中对某个表执行了增、删、改操作,那么 InnoDB 存储引擎就会给它分配一个独一无二的事务 id,分配方式如下:
对于只读事务来说,只有在它第一次对某个用户创建的临时表执行增、删、改操作时才会为这个事务分配一个事务 id,否则的话是不分配事务 id 的。
我们前边说过对某个查询语句执行 EXPLAIN 分析它的查询计划时,有时候在Extra 列会看到 Using temporary 的提示,这个表明在执行该查询语句时会用到内部临时表。这个所谓的内部临时表和我们手动用 CREATE TEMPORARY TABLE 创建的用户临时表并不一样,在事务回滚时并不需要把执行 SELECT 语句过程中用到的内部临时表也回滚,在执行 SELECT 语句用到内部临时表时并不会为它分配事务 id。
对于读写事务来说,只有在它第一次对某个表(包括用户创建的临时表)执行增、删、改操作时才会为这个事务分配一个事务 id,否则的话也是不分配事务id 的。
有的时候虽然我们开启了一个读写事务,但是在这个事务中全是查询语句,并没有执行增、删、改的语句,那也就意味着这个事务并不会被分配一个事务 id。
上边描述的事务 id 分配策略是针对 MySQL 5.7 来说的,前边的版本的分配方式可能不同。
7.2.2.2. 事务 id 生成机制
这个事务 id 本质上就是一个数字,它的分配策略和我们前边提到的对隐藏列 row_id(当用户没有为表创建主键和 UNIQUE 键时 InnoDB 自动创建的列)的分配策略大抵相同,具体策略如下:
服务器会在内存中维护一个全局变量,每当需要为某个事务分配一个事务 id时,就会把该变量的值当作事务 id 分配给该事务,并且把该变量自增 1。
每当这个变量的值为 256 的倍数时,就会将该变量的值刷新到系统表空间的页号为 5 的页面中一个称之为 Max Trx ID 的属性处,这个属性占用 8 个字节的存储空间。
当系统下一次重新启动时,会将上边提到的 Max Trx ID 属性加载到内存中,将该值加上 256 之后赋值给我们前边提到的全局变量(因为在上次关机时该全局变量的值可能大于 Max Trx ID 属性值)。
这样就可以保证整个系统中分配的事务 id 值是一个递增的数字。先被分配id 的事务得到的是较小的事务 id,后被分配 id 的事务得到的是较大的事务 id。
7.2.3. trx_id 隐藏列
我们在学习 InnoDB 记录行格式的时候重点强调过:聚簇索引的记录除了会保存完整的用户数据以外,而且还会自动添加名为 trx_id、roll_pointer 的隐藏列,
如果用户没有在表中定义主键以及 UNIQUE 键,还会自动添加一个名为 row_id的隐藏列。

其中的 trx_id 列就是某个对这个聚簇索引记录做改动的语句所在的事务对应的事务 id 而已(此处的改动可以是 INSERT、DELETE、UPDATE 操作)。至于roll_pointer 隐藏列我们后边分析。
7.2.4. undo 日志的格式
为了实现事务的原子性,InnoDB 存储引擎在实际进行增、删、改一条记录时,都需要先把对应的 undo 日志记下来。一般每对一条记录做一次改动,就对应着一条 undo 日志,但在某些更新记录的操作中,也可能会对应着 2 条 undo日志。
一个事务在执行过程中可能新增、删除、更新若干条记录,也就是说需要记录很多条对应的 undo 日志,这些 undo 日志会被从 0 开始编号,也就是说根据生成的顺序分别被称为第 0 号 undo 日志、第 1 号 undo 日志、…、第 n 号 undo日志等,这个编号也被称之为 undo no。
这些 undo 日志是被记录到类型为 FIL_PAGE_UNDO_LOG 的页面中。这些页面可以从系统表空间中分配,也可以从一种专门存放 undo 日志的表空间,也就是所谓的 undo tablespace 中分配。先来看看不同操作都会产生什么样子的 undo日志。
7.2.4.1. INSERT 操作对应的 undo 日志
当我们向表中插入一条记录时最终导致的结果就是这条记录被放到了一个
数据页中。如果希望回滚这个插入操作,那么把这条记录删除就好了,也就是说在写对应的 undo 日志时,主要是把这条记录的主键信息记上。InnoDB 的设计了一个类型为 TRX_UNDO_INSERT_REC 的 undo 日志。
如果记录中的主键只包含一个列,那么在类型为 TRX_UNDO_INSERT_REC 的undo 日志中只需要把该列占用的存储空间大小和真实值记录下来,如果记录中的主键包含多个列,那么每个列占用的存储空间大小和对应的真实值都需要记录下来。
当我们向某个表中插入一条记录时,实际上需要向聚簇索引和所有的二级索引都插入一条记录。不过记录 undo 日志时,我们只需要考虑向聚簇索引插入记录时的情况就好了,因为其实聚簇索引记录和二级索引记录是一一对应的,我们在回滚插入操作时,只需要知道这条记录的主键信息,然后根据主键信息做对应的删除操作,做删除操作时就会顺带着把所有二级索引中相应的记录也删除掉。
后边说到的 DELETE 操作和 UPDATE 操作对应的 undo 日志也都是针对聚簇索引记录而言的。
roll_pointer 的作用
roll_pointer 本质上就是一个指向记录对应的 undo 日志的一个指针。比方说我们向表里插入了 2 条记录,每条记录都有与其对应的一条 undo 日志。记录被存储到了类型为 FIL_PAGE_INDEX 的页面中(就是我们前边一直所说的数据页),undo 日志被存放到了类型为FIL_PAGE_UNDO_LOG 的页面中。roll_pointer 本质就是一个指针,指向记录对应的 undo 日志。
7.2.4.2. DELETE 操作对应的 undo 日志
我们知道插入到页面中的记录会根据记录头信息中的 next_record 属性组成一个单向链表,我们把这个链表称之为正常记录链表;被删除的记录其实也会根据记录头信息中的 next_record 属性组成一个链表,只不过这个链表中的记录占用的存储空间可以被重新利用,所以也称这个链表为垃圾链表。Page Header 部分有一个称之为 PAGE_FREE 的属性,它指向由被删除记录组成的垃圾链表中的头节点。
假设此刻某个页面中的记录分布情况是这样的
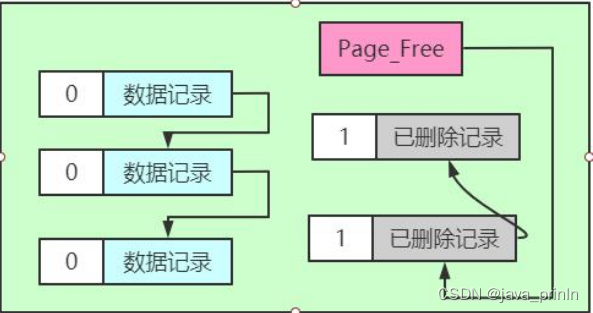
我们只把记录的 delete_mask 标志位展示了出来。从图中可以看出,正常记录链表中包含了 3 条正常记录,垃圾链表里包含了 2 条已删除记录。页面的 PageHeader 部分的 PAGE_FREE 属性的值代表指向垃圾链表头节点的指针。
假设现在我们准备使用 DELETE 语句把正常记录链表中的最后一条记录给删除掉,其实这个删除的过程需要经历两个阶段:
阶段一:将记录的delete_mask标识位设置为1,这个阶段称之为delete mark。
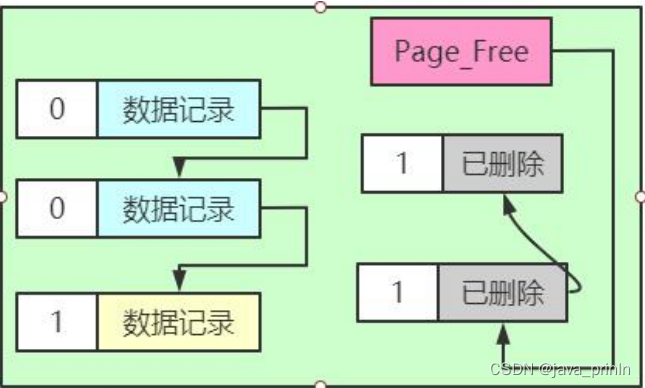
可以看到,正常记录链表中的最后一条记录的 delete_mask 值被设置为 1,但是并没有被加入到垃圾链表。也就是此时记录处于一个中间状态。在删除语句所在的事务提交之前,被删除的记录一直都处于这种所谓的中间状态。
为啥会有这种奇怪的中间状态呢?其实主要是为了实现一个称之为 MVCC的功能,稍后再介绍。
阶段二:当该删除语句所在的事务提交之后,会有专门的线程后来真正的把记录删除掉。所谓真正的删除就是把该记录从正常记录链表中移除,并且加入到垃圾链表中,然后还要调整一些页面的其他信息,比如页面中的用户记录数量PAGE_N_RECS、上次插入记录的位置PAGE_LAST_INSERT、垃圾链表头节点的指针 PAGE_FREE、页面中可重用的字节数量 PAGE_GARBAGE、还有页目录的一些信息等等。这个阶段称之为 purge。
把阶段二执行完了,这条记录就算是真正的被删除掉了。这条已删除记录占用的存储空间也可以被重新利用了。
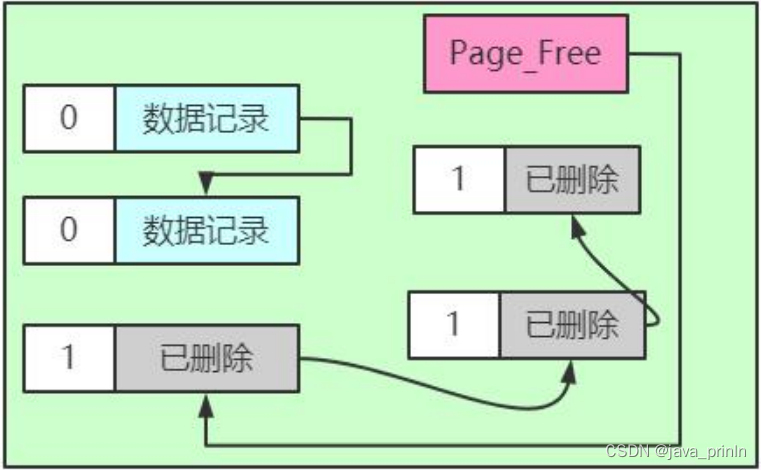
从上边的描述中我们也可以看出来,在删除语句所在的事务提交之前,只会经历阶段一,也就是 delete mark 阶段(提交之后我们就不用回滚了,所以只需考虑对删除操作的阶段一做的影响进行回滚)。InnoDB 中就会产生一种称之为TRX_UNDO_DEL_MARK_REC 类型的 undo 日志。
版本链
同时,在对一条记录进行 delete mark 操作前,需要把该记录的旧的 trx_id和 roll_pointer 隐藏列的值都给记到对应的 undo 日志中来,就是我们图中显示的old trx_id 和 old roll_pointer 属性。这样有一个好处,那就是可以通过 undo 日志的 old roll_pointer 找到记录在修改之前对应的 undo 日志。比方说在一个事务中,我们先插入了一条记录,然后又执行对该记录的删除操作,这个过程的示意图就是这样:
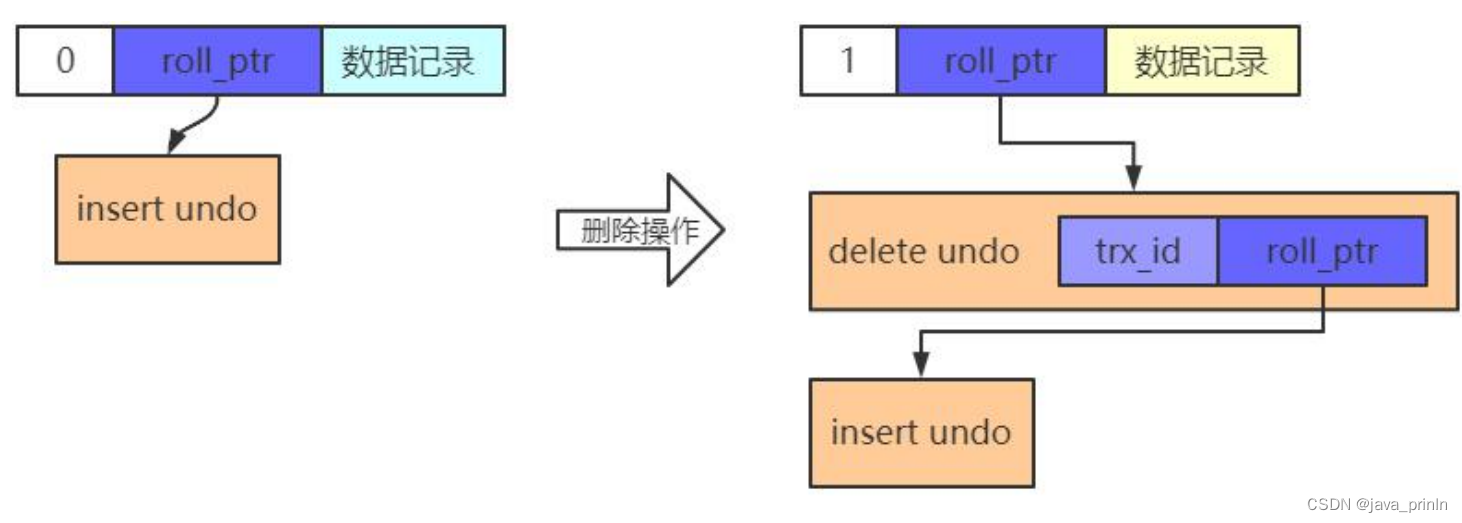
从图中可以看出来,执行完delete mark操作后,它对应的undo日志和INSERT操作对应的 undo 日志就串成了一个链表。这个链表就称之为版本链。
7.2.4.3. UPDATE 操作对应的 undo 日志
在执行 UPDATE 语句时,InnoDB 对更新主键和不更新主键这两种情况有截然不同的处理方案。
不更新主键的情况
在不更新主键的情况下,又可以细分为被更新的列占用的存储空间不发生变化和发生变化的情况。
就地更新(in-place update)
更新记录时,对于被更新的每个列来说,如果更新后的列和更新前的列占用的存储空间都一样大,那么就可以进行就地更新,也就是直接在原记录的基础上修改对应列的值。再次强调一边,是每个列在更新前后占用的存储空间一样大,有任何一个被更新的列更新前比更新后占用的存储空间大,或者更新前比更新后占用的存储空间小都不能进行就地更新。
先删除掉旧记录,再插入新记录
在不更新主键的情况下,如果有任何一个被更新的列更新前和更新后占用的存储空间大小不一致,那么就需要先把这条旧的记录从聚簇索引页面中删除掉,然后再根据更新后列的值创建一条新的记录插入到页面中。
请注意一下,我们这里所说的删除并不是 delete mark 操作,而是真正的删除掉,也就是把这条记录从正常记录链表中移除并加入到垃圾链表中,并且修改页面中相应的统计信息(比如 PAGE_FREE、PAGE_GARBAGE 等这些信息)。由用户线程同步执行真正的删除操作,真正删除之后紧接着就要根据各个列更新后的值创建的新记录插入。
这里如果新创建的记录占用的存储空间大小不超过旧记录占用的空间,那么可以直接重用被加入到垃圾链表中的旧记录所占用的存储空间,否则的话需要在页面中新申请一段空间以供新记录使用,如果本页面内已经没有可用的空间的话,那就需要进行页面分裂操作,然后再插入新记录。
针对 UPDATE 不更新主键的情况(包括上边所说的就地更新和先删除旧记录再插入新记录),InnoDB 设计了一种类型为TRX_UNDO_UPD_EXIST_REC 的 undo日志。
更新主键的情况
在聚簇索引中,记录是按照主键值的大小连成了一个单向链表的,如果我们更新了某条记录的主键值,意味着这条记录在聚簇索引中的位置将会发生改变,比如你将记录的主键值从 1 更新为 10000,如果还有非常多的记录的主键值分布在 1 ~ 10000 之间的话,那么这两条记录在聚簇索引中就有可能离得非常远,甚至中间隔了好多个页面。针对 UPDATE 语句中更新了记录主键值的这种情况,InnoDB 在聚簇索引中分了两步处理:
将旧记录进行 delete mark 操作
也就是说在 UPDATE 语句所在的事务提交前,对旧记录只做一个 delete mark操作,在事务提交后才由专门的线程做 purge 操作,把它加入到垃圾链表中。这里一定要和我们上边所说的在不更新记录主键值时,先真正删除旧记录,再插入新记录的方式区分开!
之所以只对旧记录做 delete mark 操作,是因为别的事务同时也可能访问这条记录,如果把它真正的删除加入到垃圾链表后,别的事务就访问不到了。这个功能就是所谓的 MVCC。
创建一条新记录
根据更新后各列的值创建一条新记录,并将其插入到聚簇索引中(需重新定位插入的位置)。
由于更新后的记录主键值发生了改变,所以需要重新从聚簇索引中定位这条记录所在的位置,然后把它插进去。
针对 UPDATE 语句更新记录主键值的这种情况,在对该记录进行 delete mark操作前,会记录一条类型为 TRX_UNDO_DEL_MARK_REC 的 undo 日志;之后插入新记录时,会记录一条类型为 TRX_UNDO_INSERT_REC 的 undo 日志,也就是说每对一条记录的主键值做改动时,会记录 2 条 undo 日志。
7.2.5. FIL_PAGE_UNDO_LOG 页面
我们前边说明表空间的时候说过,表空间其实是由许许多多的页面构成的,页面默认大小为 16KB。这些页面有不同的类型,比如类型为 FIL_PAGE_INDEX 的页面用于存储聚簇索引以及二级索引,类型为 FIL_PAGE_TYPE_FSP_HDR 的页面用于存储表空间头部信息的,还有其他各种类型的页面,其中有一种称之为FIL_PAGE_UNDO_LOG 类型的页面是专门用来存储 undo 日志的。
相关文章:
MySQL 事务的底层原理和 MVCC(二)
7.2. undo 日志 7.2.1. 事务回滚的需求 我们说过事务需要保证原子性,也就是事务中的操作要么全部完成,要么什么也不做。但是偏偏有时候事务执行到一半会出现一些情况,比如: 情况一:事务执行过程中可能遇到各种错误&a…...

(C++)验证回文字符串
愿所有美好如期而遇 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/valid-pali…...

代码随想录算法训练营第25天|216.组合总和III 17.电话号码的字母组合
JAVA代码编写 216. 组合总和III 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。 示例 1: 输入: k …...

Kotlin学习——hello kotlin 函数function 变量 类 + 泛型 + 继承
Kotlin 是一门现代但已成熟的编程语言,旨在让开发人员更幸福快乐。 它简洁、安全、可与 Java 及其他语言互操作,并提供了多种方式在多个平台间复用代码,以实现高效编程。 https://play.kotlinlang.org/byExample/01_introduction/02_Functio…...

打印lua输出日志
日志级别: ngx.STDERR 标准输出ngx.EMERG 紧急报错ngx.ALERT 报警ngx.CRIT 严重,系统故障, 触发运维告警系统ngx.ERR 错误,业务不可恢复性错误ngx.WARN 提醒, 业务中可忽略错误ngx.NOTICE 提醒, 业务中比较…...

HTML新手入门笔记整理:HTML基本介绍
网页 静态页面 仅可供用户浏览,不具备与服务器交互的功能。 动态页面 可供用户浏览,具备与服务器交互的功能。 HTML HTML,全称HyperText Markup Language(超文本标记语言),是一种用于创建网页的标准标记语言。用于…...
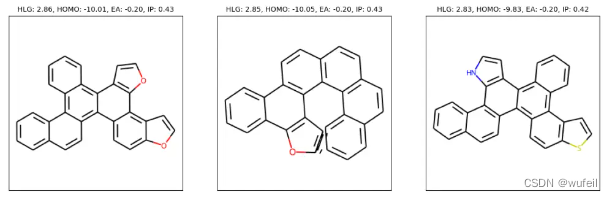
梯度引导的分子生成扩散模型- GaUDI 评测
GaUDI模型来自于以色列理工Tomer Weiss的2023年发表在预印本ChemRxiv上的工作 《Guided Diffusion for Inverse Molecular Design》。原文链接:Guided Diffusion for Inverse Molecular Design | Materials Chemistry | ChemRxiv | Cambridge Open Engage GaUDI模型…...

2023 年 亚太赛 APMCM ABC题 国际大学生数学建模挑战赛 |数学建模完整代码+建模过程全解全析
当大家面临着复杂的数学建模问题时,你是否曾经感到茫然无措?作为2022年美国大学生数学建模比赛的O奖得主,我为大家提供了一套优秀的解题思路,让你轻松应对各种难题。 以五一杯 A题为例子,以下是咱们做的一些想法呀&am…...
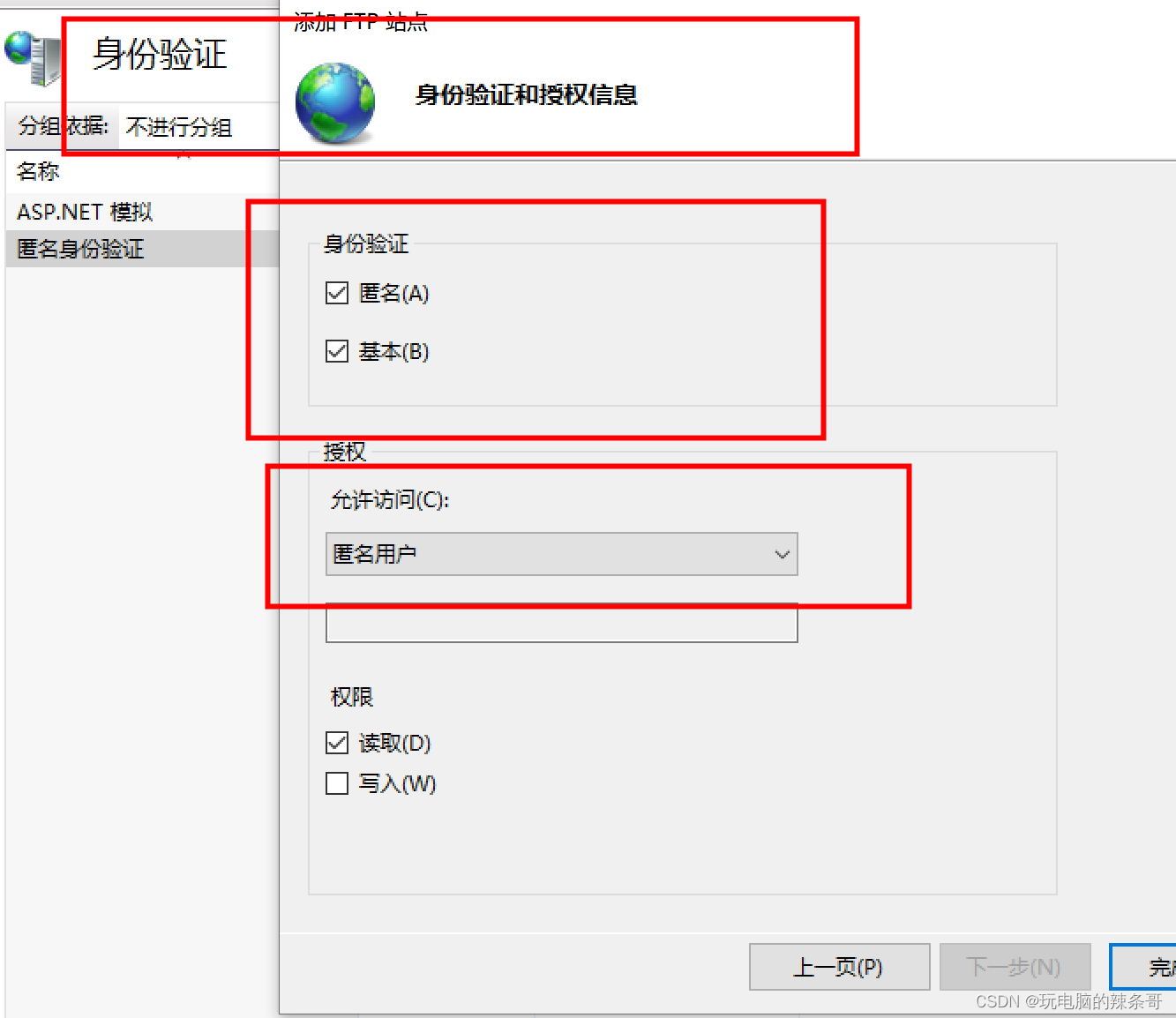
如何用cmd命令快速搭建FTP服务
环境: Win10专业版 问题描述: 如何用cmd命令快速搭建FTP服务 解决方案: 1.输入以下命令来安装IIS(Internet Information Services): dism /online /enable-feature /featurename:IIS-FTPServer /all …...
数据结构学习笔记——多维数组、矩阵与广义表
目录 一、多维数组(一)数组的定义(二)二维数组(三)多维数组的存储(四)多维数组的下标的相关计算 二、矩阵(一)特殊矩阵和稀疏矩阵(二)…...
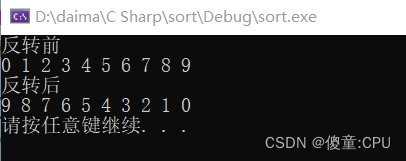
C++之常用的排序算法
C之常用的排序算法 sort #include<iostream> using namespace std; #include<vector> #include<algorithm> #include<functional> void Myptint(int val) {cout << val << " "; }void test() {vector<int> v;v.push_back(…...
Mac中LaTex无法编译的问题
最近在使用TexStudio时,遇到一个棘手的问题: 无法编译,提示如下: kpathsea: Running mktexfmt xelatex.fmt /Library/TeX/texbin/mktexfmt: kpsewhich -var-valueTEXMFROOT failed, aborting early. BEGIN failed–compilation a…...
【Python爬虫】8大模块md文档集合从0到scrapy高手,第7篇:selenium 数据提取详解
本文主要学习一下关于爬虫的相关前置知识和一些理论性的知识,通过本文我们能够知道什么是爬虫,都有那些分类,爬虫能干什么等,同时还会站在爬虫的角度复习一下http协议。 爬虫全套笔记地址: 请移步这里 共 8 章&#x…...

【python基础(三)】操作列表:for循环、正确缩进、切片的使用、元组
文章目录 一. 遍历整个列表1. 在for循环中执行更多操作2. 在for循环结束后执行一些操作 二. 避免缩进错误三. 创建数值列表1. 使用函数range()2. 使用range()创建数字列表3. 指定步长。4. 对数字列表执行简单的统计计算5. 列表解析 五. 使用列表的一部分-切片1. 切片2. 遍历切片…...

使用VSCode调试全志R128的C906 RISC-V核心
使用 VSCode 调试 调试 XuanTie C906 核心 准备工具 T-Head DebugServer(CSkyDebugServer) - 搭建调试服务器 下载地址:T-Head DebugServer手册:T-Head Debugger Server User Guide驱动:cklink_dirvers VSCode - 开…...

Node.js之http模块
http模块是什么? http 模块是 Node,js 官方提供的、用来创建 web 服务器的模块。通过 http 模块提供的 http.createServer() 方法,就能方便的把一台普通的电脑,变成一台Web 服务器,从而对外提供 Web 资源服务。 如果我们想在node…...
golang 断点调试
1.碰见如下报错,调试器没有打印变量信息 Delve is too old for Go version 1.21.2 (maximum supported version 1.19) 2. 解决办法 升级delve delve是go语言的debug工具。 go install github.com/go-delve/delve/cmd/dlvlatest报错 Get “https://proxy.golang.org/github…...

定时器如何计算触发频率?
定时器触发频率的计算公式为:定时器时钟频率/(预分频系数*计数周期1)。其中,定时器时钟频率是指定时器所连接的总线频率,预分频系数和计数周期需要根据具体的需求进行设置。预分频系数用于将总线频率分频,计…...

【数据库】数据库中的检查点Checkpoint,数据落盘的重要时刻
检查点(checkpoint) 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定…...
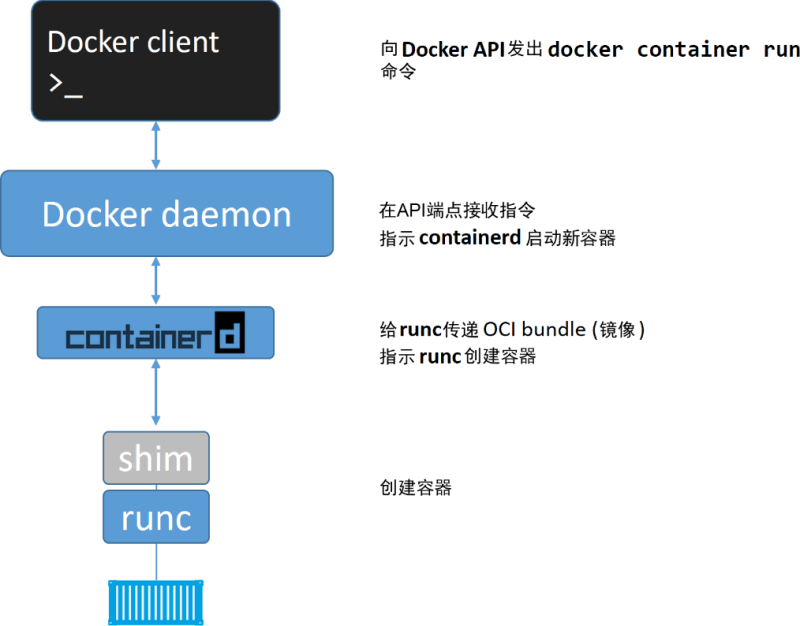
关于 Docker
关于 Docker 1. 术语Docker Enginedockerd(Docker daemon)containerdOCI (Open Container Initiative)runcDocker shimCRI (Container Runtime Interface)CRI-O 2. 容器启动过程在 Linux 中的实现daemon 的作用 Docker 是个划时代的开源项目,…...

CANN/asc-tools NPU检查工具
npu_check 【免费下载链接】asc-tools Ascend C Tools仓是CANN基于Ascend C编程语言推出的配套调试工具仓。 项目地址: https://gitcode.com/cann/asc-tools 概述 Ascend C Tools提供的孪生调试分为debug功能和npu check功能,debug功能包含诸如是否合法使用…...

如何5分钟搞定抖音无水印视频下载:douyin-downloader完整指南
如何5分钟搞定抖音无水印视频下载:douyin-downloader完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

AzurLaneAutoScript:碧蓝航线全自动管理解决方案深度解析
AzurLaneAutoScript:碧蓝航线全自动管理解决方案深度解析 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 在当今…...

ROS2 Control实战:从URDF到控制器,手把手教你搭建一个可动的仿真机器人
ROS2 Control实战:从URDF到控制器,手把手教你搭建一个可动的仿真机器人 当你已经完成了机器人的URDF建模,看着屏幕上精美的3D模型,是否迫不及待想让它动起来?ROS2 Control正是连接虚拟模型与真实运动的桥梁。不同于简单…...

基于Groq LPU与Llama 3.1的极速AI聊天工具全解析
1. 项目概述:一个跑在浏览器里的极速AI聊天工具 最近在折腾AI应用的时候,发现了一个挺有意思的开源项目,叫 Groq Chat 。这玩意儿本质上是一个基于浏览器的聊天界面,但它背后用的不是我们常见的OpenAI API或者本地部署的大模型…...

终极CubeFS社区贡献指南:从新手到核心贡献者的完整路径
终极CubeFS社区贡献指南:从新手到核心贡献者的完整路径 【免费下载链接】cubefs cloud-native distributed storage 项目地址: https://gitcode.com/gh_mirrors/cu/cubefs CubeFS 作为一款云原生分布式存储系统,凭借其高可用、弹性扩展和多场景适…...

时差这个东西,熬的是命
做跨境代购的人,都知道时差的苦。客户在海外,你在中国。客户醒着的时候,你该睡了;客户睡了,你又醒了。为了不错过消息,手机永远不敢静音。凌晨三点被震醒是常态。一个月下来,黑眼圈比熊猫还重。…...

科沃斯年营收190亿:净利17.6亿 钱东奇家族获现金红利3.5亿
雷递网 雷建平 4月24日科沃斯机器人股份有限公司(公司代码:603486 公司简称:科沃斯)今日发布截至2025年的财报。财报显示,科沃斯2025年营收为190亿元,较上年同期的165亿元增长15.1%。科沃斯2025年归属于上市…...

Phi-4-mini-reasoning开源大模型教程:FP16量化与显存占用优化技巧
Phi-4-mini-reasoning开源大模型教程:FP16量化与显存占用优化技巧 1. 模型概述 Phi-4-mini-reasoning是微软推出的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这款模型主打"小参数、强推理、长上下文、低延迟&qu…...

工业控制系统安全补丁管理:IT与OT差异、实战流程与深度防御
1. 工业安全补丁管理的核心困境:当IT思维遇上OT现实如果你在IT部门工作,习惯了每周二凌晨的自动补丁更新,或者对“零日漏洞”的响应时间以小时计,那么当你第一次接触工业控制系统(ICS)或运营技术࿰…...