Spring Cloud学习(十一)【深入Elasticsearch 分布式搜索引擎03】
文章目录
- 数据聚合
- 聚合的种类
- DSL实现聚合
- RestAPI实现聚合
- 自动补全
- 拼音分词器
- 自定义分词器
- 自动补全查询
- completion suggester查询
- RestAPI实现自动补全
- 数据同步
- 数据同步思路分析
- 实现elasticsearch与数据库数据同步
- 集群
- 搭建ES集群
- 创建es集群
- 集群状态监控
- 创建索引库
- 1)利用kibana的DevTools创建索引库
- 2)利用cerebro创建索引库
- 查看分片效果
- ES集群的节点角色
- 集群脑裂问题
- 集群分布式存储
- 集群分布式查询
- 集群故障转移
数据聚合
聚合的种类
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
可以类比mysql数据库,(桶=》group by 分组,度量=》聚合函数,管道=》)
参与聚合的字段类型必须是:
- keyword
- 数值
- 日期
- 布尔
DSL实现聚合
DSL实现Bucket聚合
现在,我们要统计所有数据中的酒店品牌有几种,此时可以根据酒店品牌的名称做聚合。
类型为 term 类型,DSL示例:
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}
Bucket聚合-聚合结果排序
默认情况下,Bucket 聚合会统计 Bucket 内的文档数量,记为 _count,并且按照 _count 降序排序。
我们可以修改结果排序方式:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "asc" // 按照_count升序排列},"size": 20}}}
}
Bucket聚合-限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加 query 条件即可:
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 // 只对200元以下的文档聚合}}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
DSL实现Metrics 聚合
例如,我们要求获取每个品牌的用户评分的 min、max、avg 等值.
我们可以利用 stats 聚合:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算"score_stats": { // 聚合名称"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // 聚合字段,这里是score}}}}}
}
RestAPI实现聚合
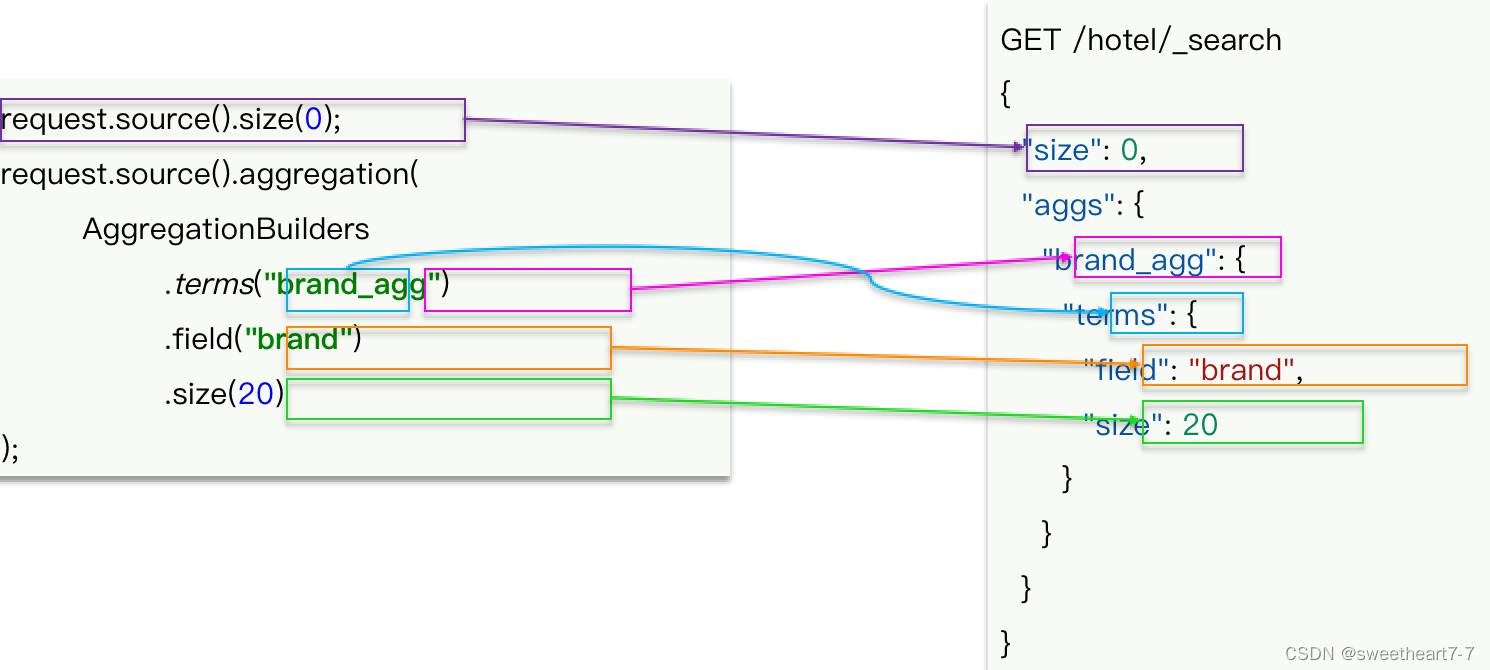
我们以品牌聚合为例,演示下 Java 的 RestClient 使用,先看请求组装:
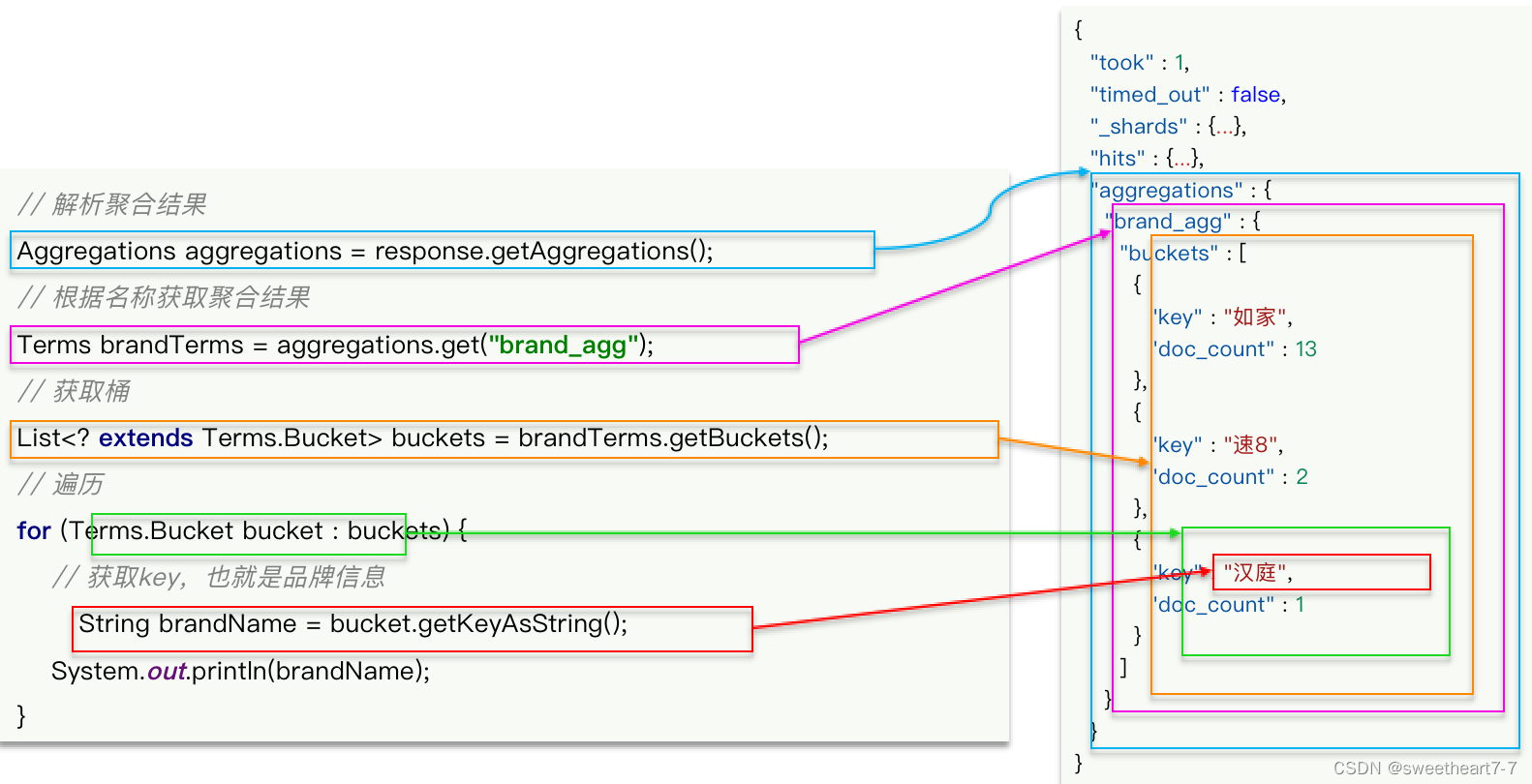
再看下聚合结果解析
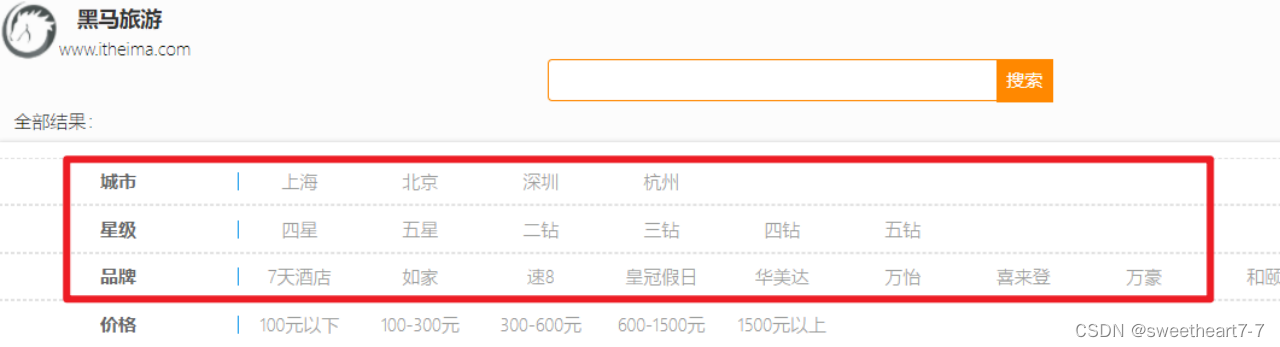
在IUserService中定义方法,实现对品牌、城市、星级的聚合
需求:搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:
在IUserService中定义一个方法,实现对品牌、城市、星级的聚合,方法声明如下:

对接前端接口
前端页面会向服务端发起请求,查询品牌、城市、星级等字段的聚合结果:
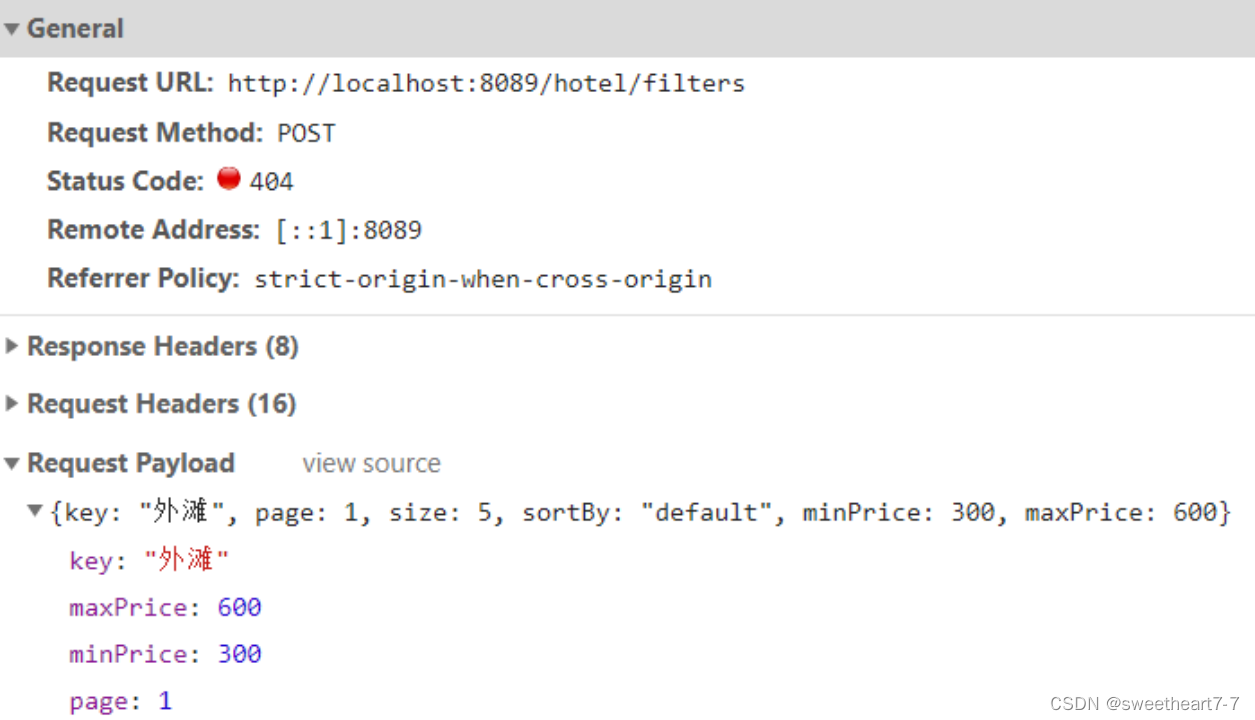
可以看到请求参数与之前search时的RequestParam完全一致,这是在限定聚合时的文档范围。
例如:用户搜索“外滩”,价格在300~600,那聚合必须是在这个搜索条件基础上完成。
因此我们需要:
- 编写controller接口,接收该请求
- 修改IUserService#getFilters()方法,添加RequestParam参数
- 修改getFilters方法的业务,聚合时添加query条件
@Test
void testAggregation() throws IOException {// 1. 准备RequestSearchRequest request = new SearchRequest("hotel");// 2. 准备DSL// 2.1 设置sizerequest.source().size(0);// 2.2 聚合request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10));// 3. 发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析结果Aggregations aggregations = response.getAggregations();// 4.1 根据聚合名称获取聚合结果Terms brandTerms = aggregations.get("brandAgg");// 4.2 获取 bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();System.out.println(key);}
}
Controller
@PostMapping("filters")
public Map<String, List<String>> getFilters(@RequestBody RequestParams params){return hotelService.filters(params);
}
Service接口
@Override
public Map<String, List<String>> filters(RequestParams params) {try {// 1. 准备RequestSearchRequest request = new SearchRequest("hotel");// 2. 准备DSL// 2.1 querybuildBasicQuery(params, request);// 2.2 设置sizerequest.source().size(0);// 2.3 聚合buildAggregation(request);// 3. 发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析结果Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 4.1 根据品牌名称,获取品牌结果List<String> brandList = getAggByName(aggregations, "brandAgg");// 4.2 根据城市名称,获取城市结果List<String> cityList = getAggByName(aggregations, "cityAgg");// 4.3 根据星级名称,获取星级结果List<String> starList = getAggByName(aggregations, "starAgg");// 4.4 放入mapresult.put("品牌", brandList);result.put("城市", cityList);result.put("星级", starList);return result;} catch (IOException e) {throw new RuntimeException(e);}
}private List<String> getAggByName(Aggregations aggregations, String aggName) {// 4.1 根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2 获取 bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3 遍历List<String> brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();brandList.add(key);}return brandList;
}private void buildAggregation(SearchRequest request) {request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));request.source().aggregation(AggregationBuilders.terms("starAgg").field("star").size(100));
}private void buildBasicQuery(RequestParams params, SearchRequest request) {// 1. 构建BooleanQueryBoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 关键字搜索String key = params.getKey();if(key == null || "".equals(key)){boolQuery.must(QueryBuilders.matchAllQuery());}else{boolQuery.must(QueryBuilders.matchQuery("all", key));}// 条件过滤// 城市条件if (params.getCity() != null && !params.getCity().equals("")){boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));}// 品牌条件if (params.getBrand() != null && !params.getBrand().equals("")){boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));}// 星级条件if (params.getStarName() != null && !params.getStarName().equals("")){boolQuery.filter(QueryBuilders.termQuery("starName", params.getBrand()));}// 价格if (params.getMinPrice() != null && params.getMaxPrice() != null){boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}// 2. 算分控制FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(// 原始查询,相关性算分查询boolQuery,// function score 的数组new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{// 其中的一个 function score 元素new FunctionScoreQueryBuilder.FilterFunctionBuilder(// 过滤条件QueryBuilders.termQuery("isAD", true),// 算分函数ScoreFunctionBuilders.weightFactorFunction(10))});request.source().query(functionScoreQuery);
}
自动补全
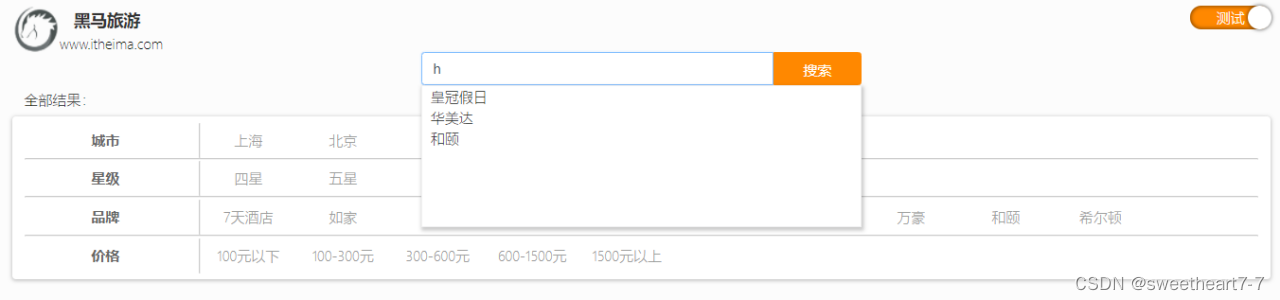
自动补全需求说明
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:https://github.com/medcl/elasticsearch-analysis-pinyin
安装方式与IK分词器一样,分三步:
- 解压
- 上传到虚拟机中,elasticsearch的plugin目录
- 重启elasticsearch
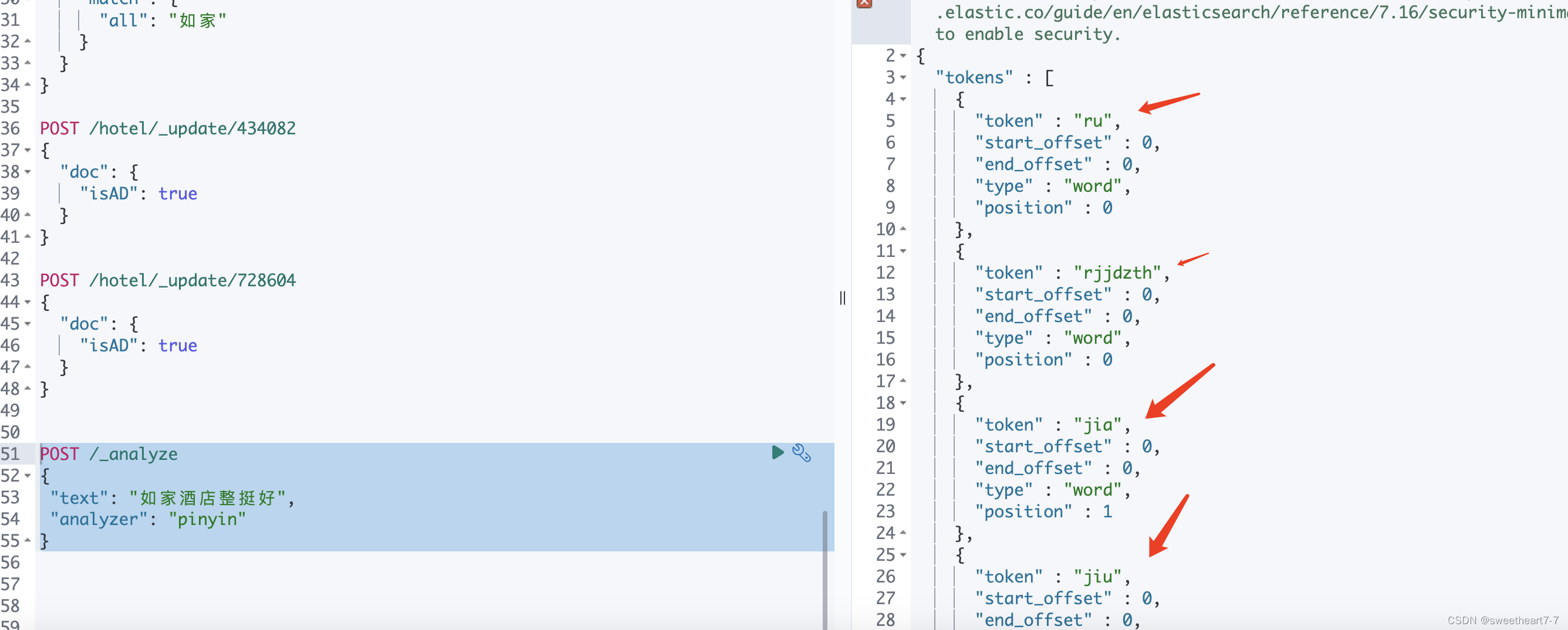
- 测试
POST /_analyze
{"text": "如家酒店整挺好","analyzer": "pinyin"
}
自定义分词器
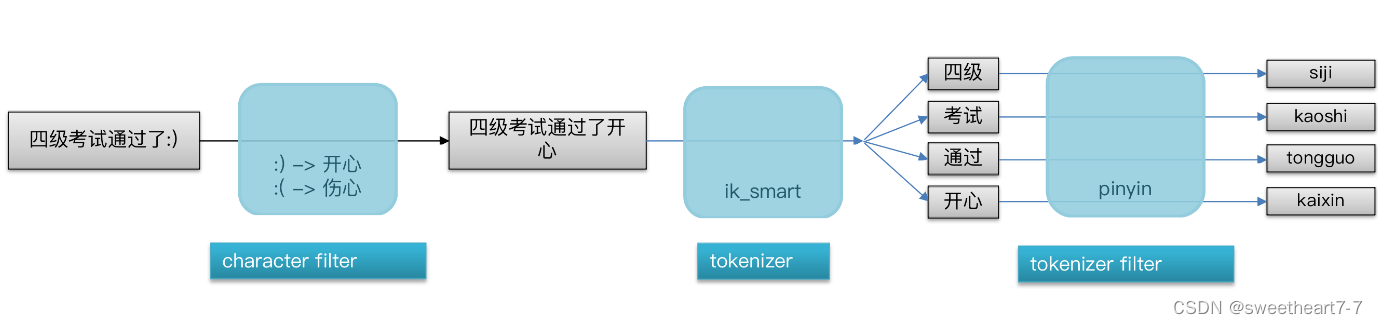
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
我们可以在创建索引库(自定义分词器只对指定的索引库适用)时,通过settings来配置自定义的analyzer(分词器):

拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
创建倒排索引时:
因此字段在创建倒排索引时应该用 my_analyzer 分词器;字段在搜索时应该使用 ik_smart 分词器;

DELETE /test# 自定义拼音分词器
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name":{"type": "text","analyzer": "my_analyzer", "search_analyzer": "ik_smart"}}}
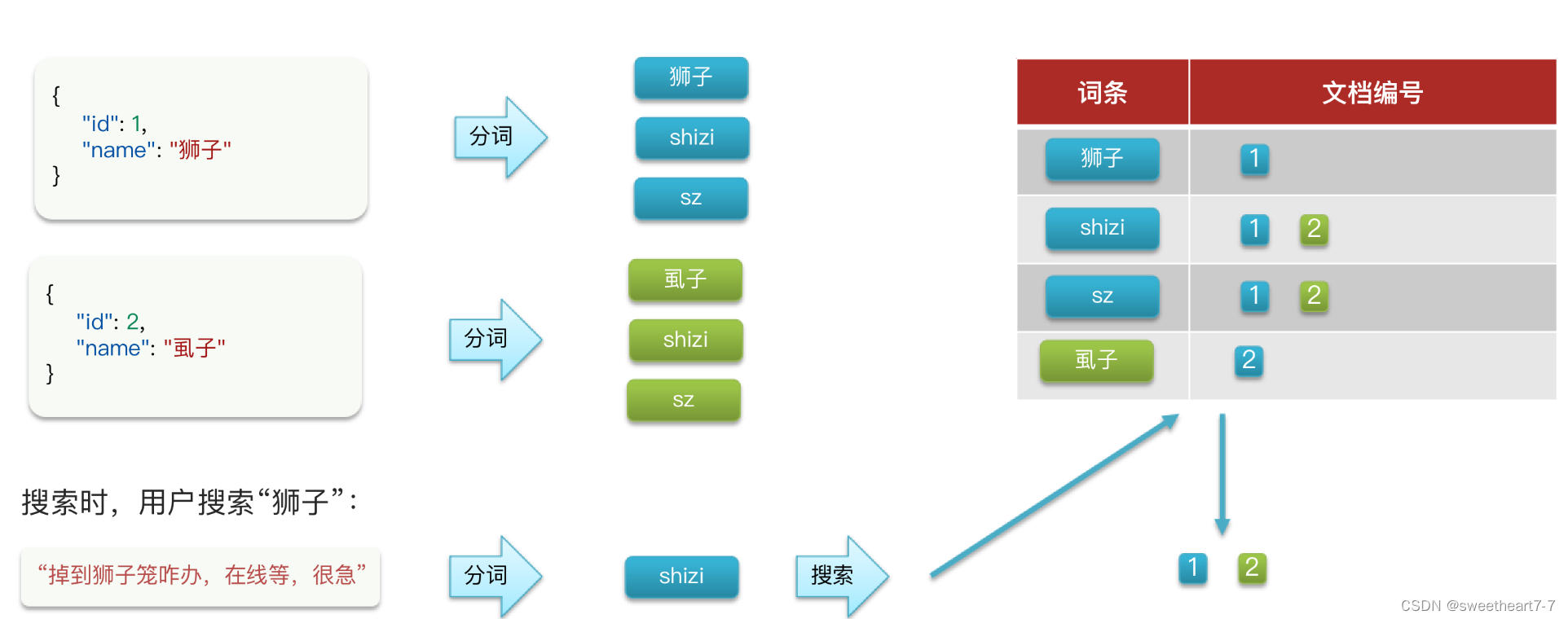
}POST /test/_doc/1
{"id": 1,"name": "狮子"
}
POST /test/_doc/2
{"id": 2,"name": "虱子"
}GET /test/_search
{"query": {"match": {"name": "掉入狮子笼咋办"}}
}
如何使用拼音分词器?
- 下载pinyin分词器
- 解压并放到elasticsearch的plugin目录
- 重启即可
如何自定义分词器?
- 创建索引库时,在settings中配置,可以包含三部分
- character filter
- tokenizer
- filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
自动补全查询
completion suggester查询
elasticsearch提供了Completion Suggester 查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是completion类型。
- 字段的内容一般是用来补全的多个词条形成的数组。

查询语法如下:

# 自动补全的索引库
PUT test2
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
# 示例数据
POST test2/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{"title": ["Nintendo", "switch"]
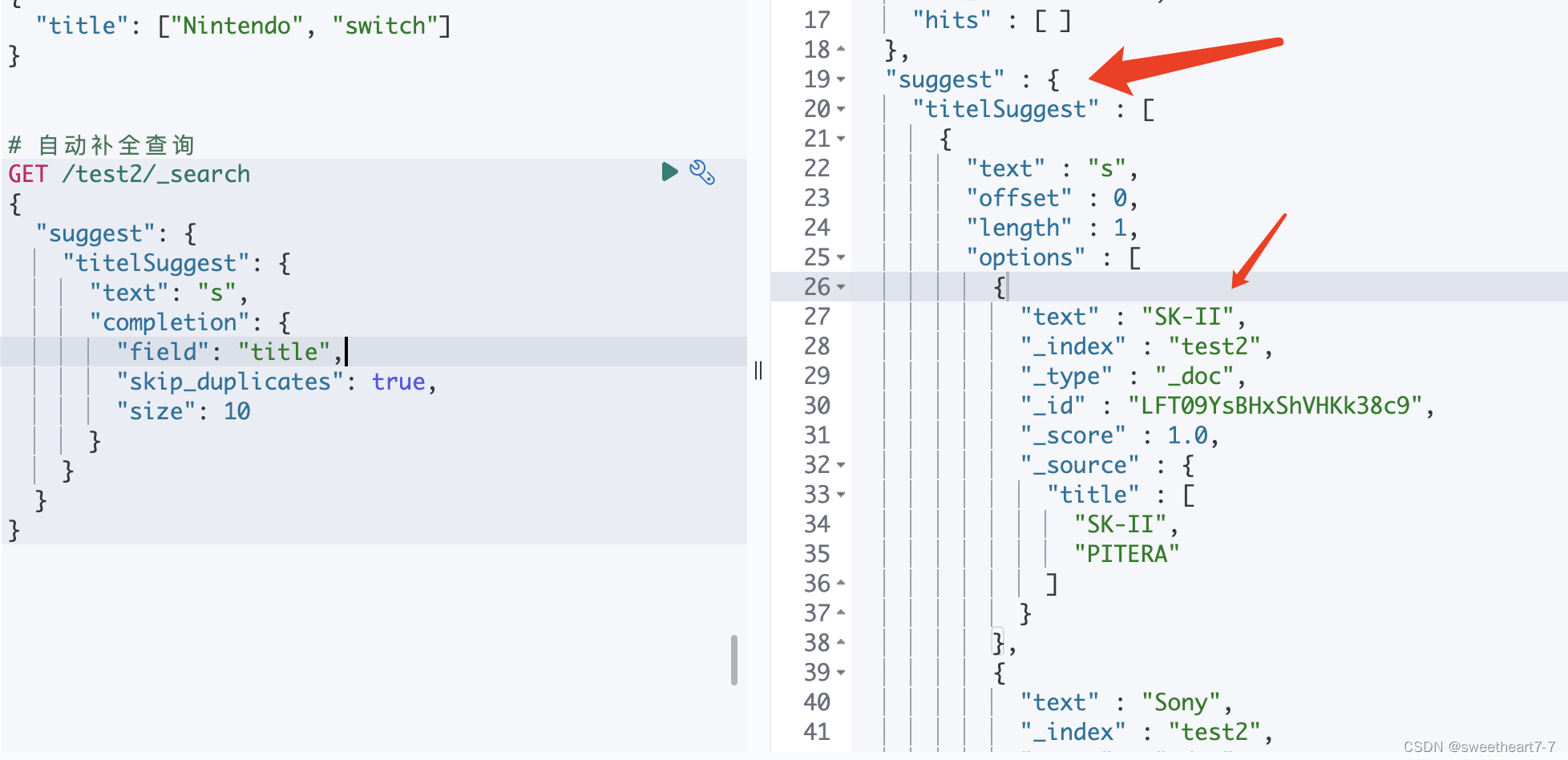
}# 自动补全查询
GET /test2/_search
{"suggest": {"titelSuggest": {"text": "s","completion": {"field": "title","skip_duplicates": true,"size": 10}}}
}
自动补全对字段的要求:
- 类型是completion类型
- 字段值是多词条的数组
酒店数据自动补全
实现hotel索引库的自动补全、拼音搜索功能
实现思路如下:
- 修改hotel索引库结构,设置自定义拼音分词器
- 修改索引库的name、all字段,使用自定义分词器
- 索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
- 给HotelDoc类添加suggestion字段,内容包含brand、business
- 重新导入数据到hotel库
注意:name、all是可分词的,自动补全的brand、business是不可分词的,要使用不同的分词器组合
# 酒店数据索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}GET /hotel/_search
{"query": {"match_all": {}}
}GET /hotel/_search
{"suggest": {"titelSuggest": {"text": "h","completion": {"field": "suggestion","skip_duplicates": true,"size": 10}}}
}
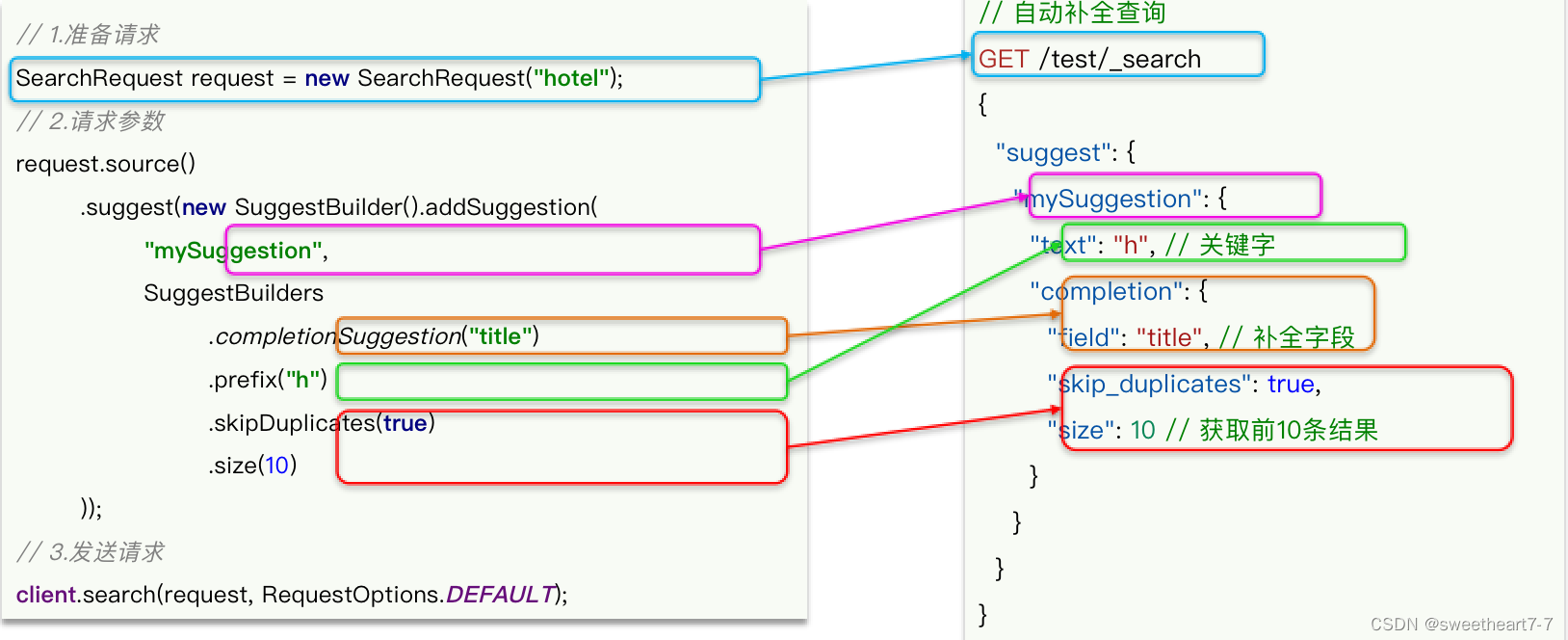
RestAPI实现自动补全
先看请求参数构造的API:
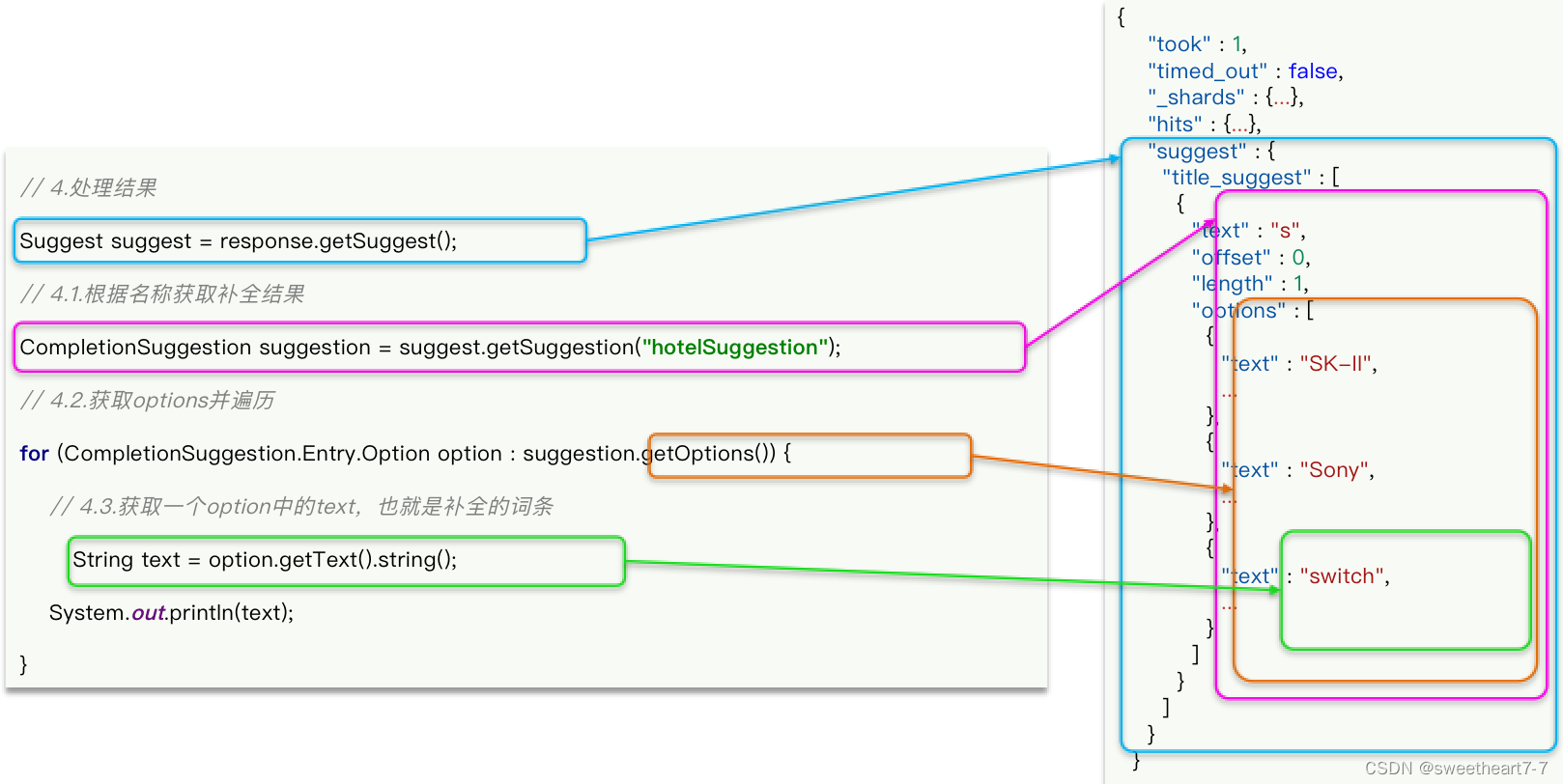
再来看结果解析:
实现酒店搜索页面输入框的自动补全
查看前端页面,可以发现当我们在输入框键入时,前端会发起ajax请求:
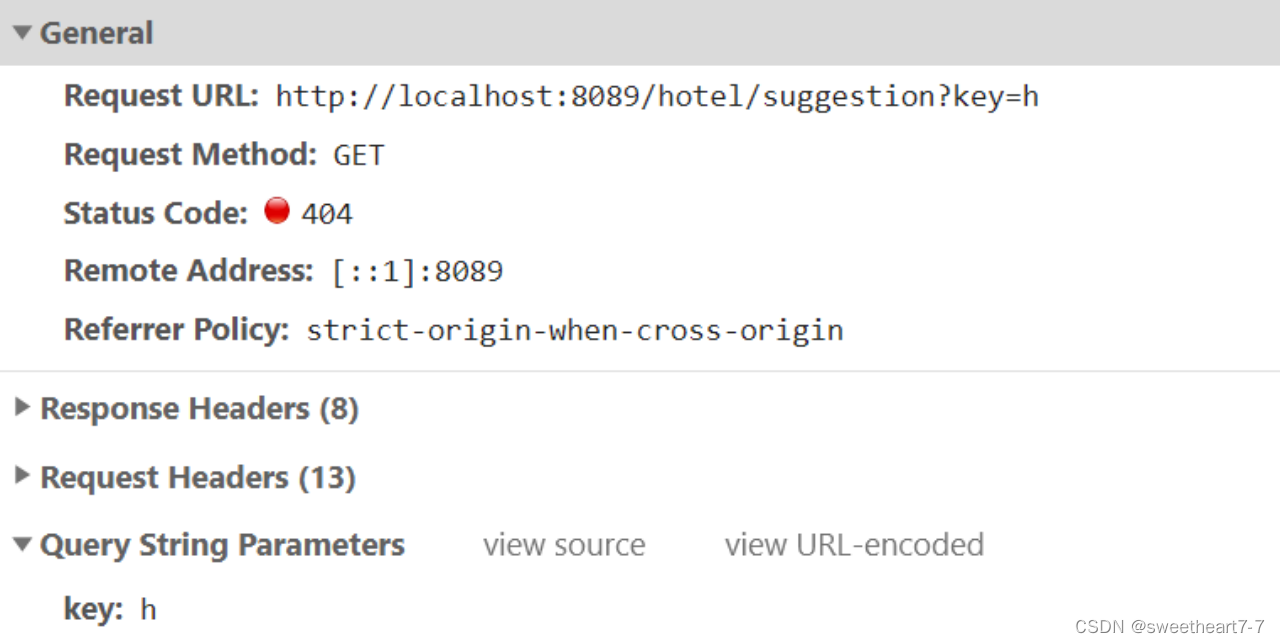
在服务端编写接口,接收该请求,返回补全结果的集合,类型为List<String>
controller
@GetMapping("suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix){return hotelService.getSuggestions(prefix);
}
service
@Override
public List<String> getSuggestions(String prefix) {try {// 1. 准备RequestSearchRequest request = new SearchRequest("hotel");// 2. 准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));// 3. 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析结果Suggest suggest = response.getSuggest();// 4.1 根据补全查询名称,获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");// 4.2 获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();// 4.3 遍历List<String> list = new ArrayList<>(options.size());for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}return list;} catch (IOException e) {throw new RuntimeException();}
}
数据同步
数据同步思路分析
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。

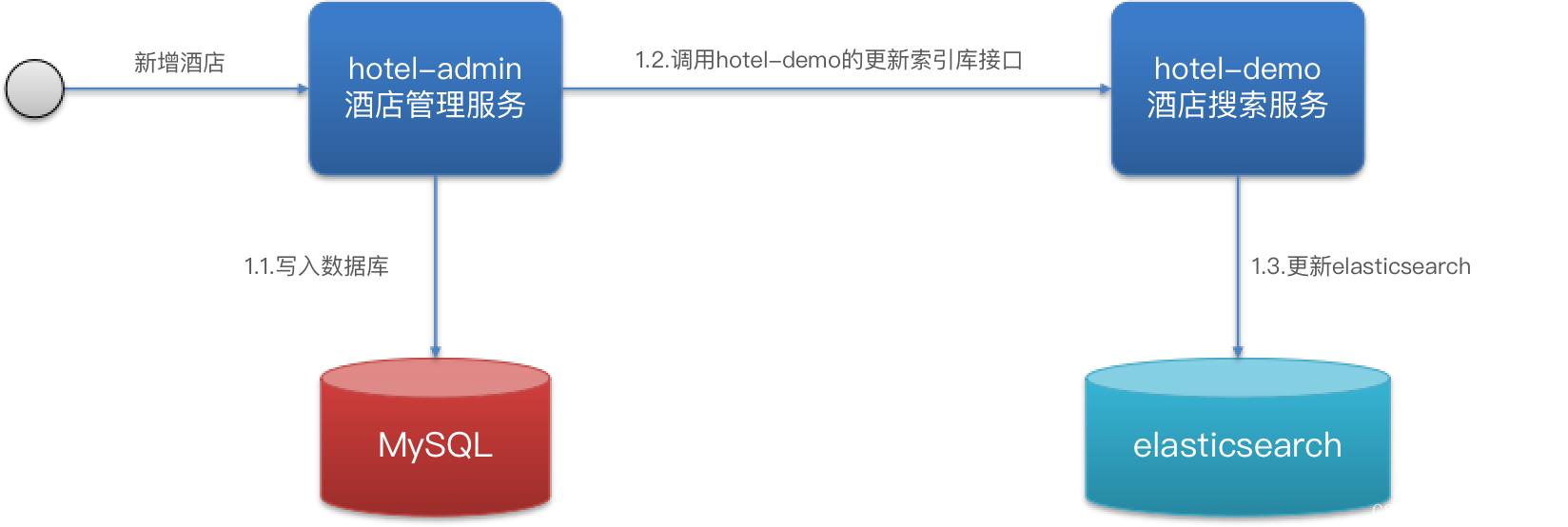
方案一:同步调用
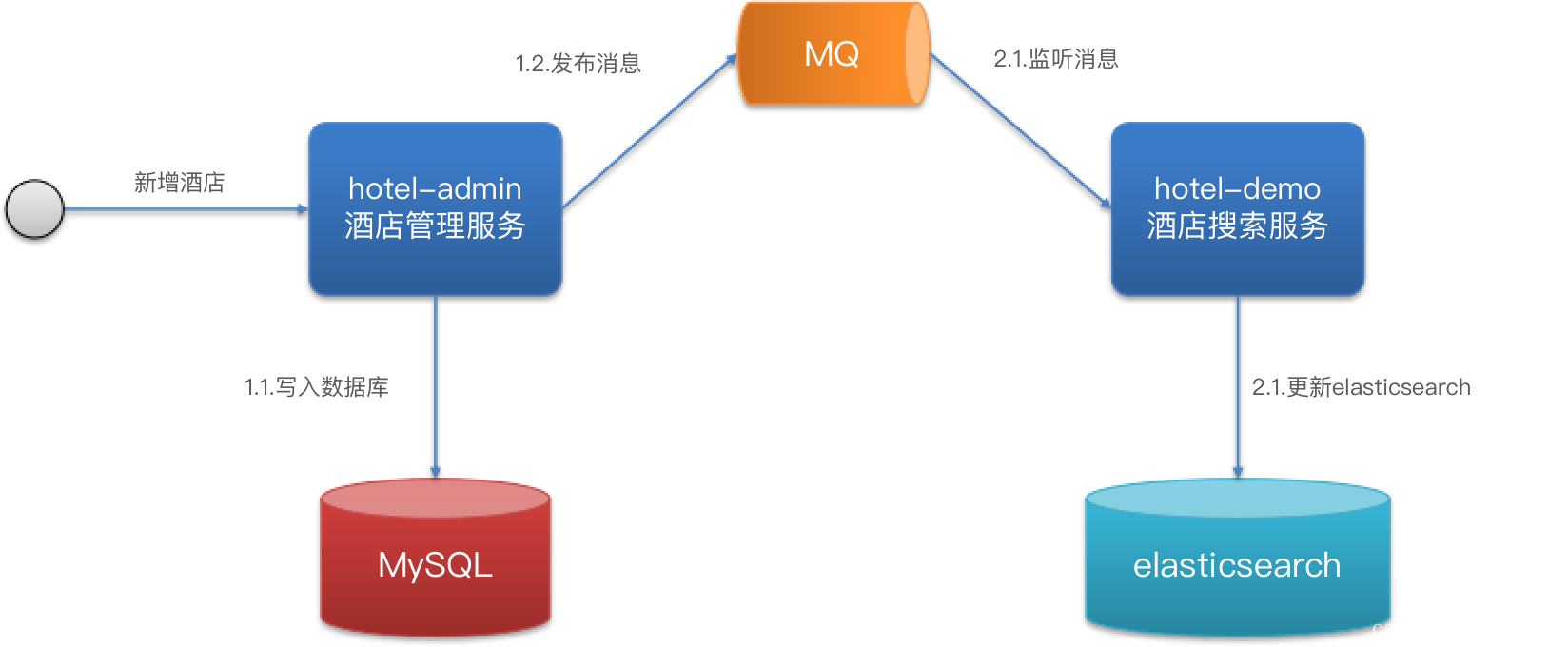
方案二:异步通知
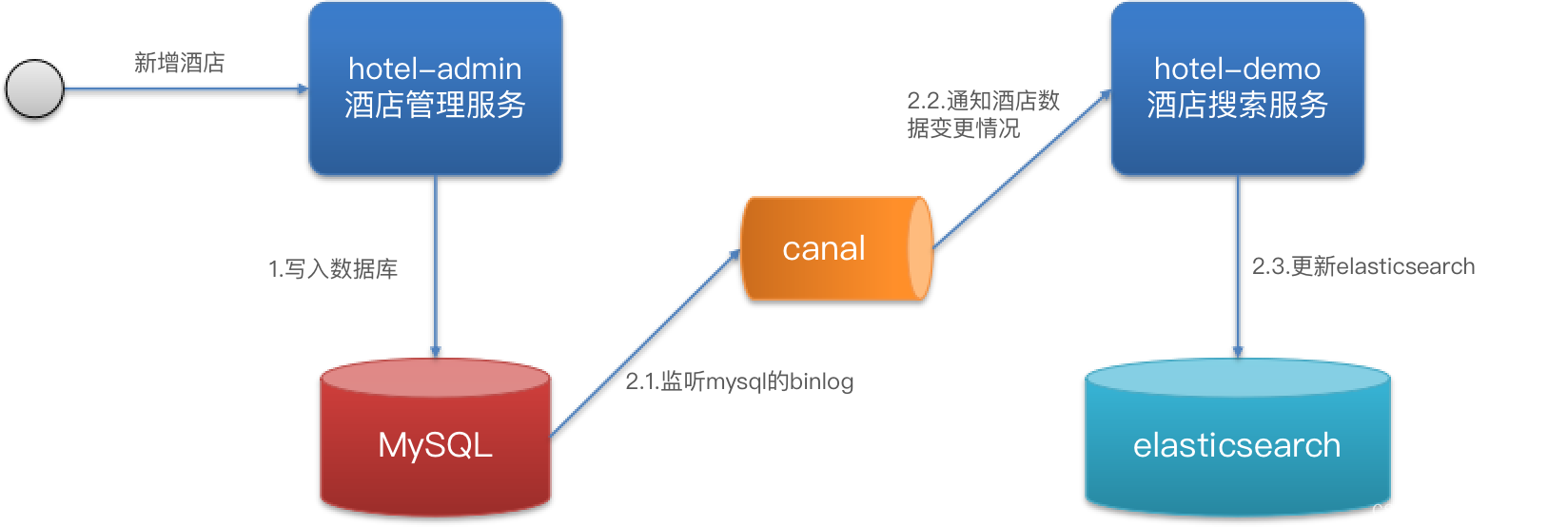
方案三:监听binlog
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
实现elasticsearch与数据库数据同步
利用MQ实现mysql与elasticsearch数据同步
利用课前资料提供的hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作。
步骤:
- 导入课前资料提供的hotel-admin项目,启动并测试酒店数据的CRUD
- 声明exchange、queue、RoutingKey
- 在hotel-admin中的增、删、改业务中完成消息发送
- 在hotel-demo中完成消息监听,并更新elasticsearch中数据
- 启动并测试数据同步功能
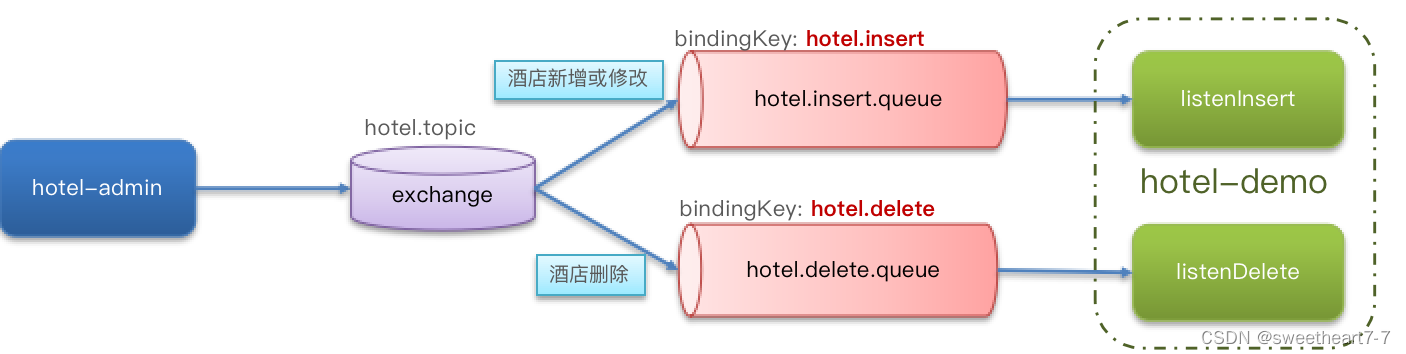
- 导入项目
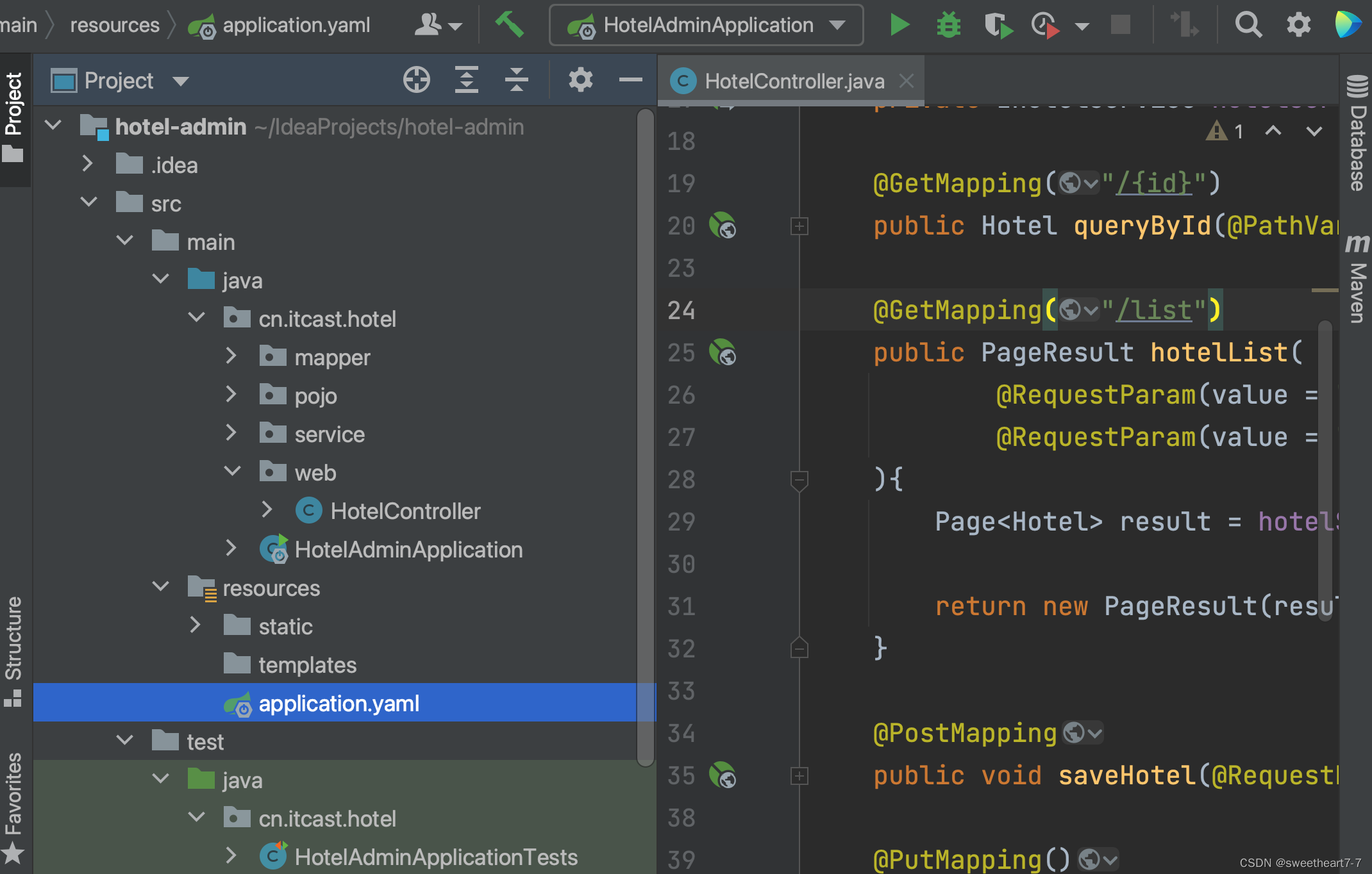
- 声明exchange、queue、RoutingKey(两类消息,两种队列)
导入amqp依赖
<!--amqp-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
yaml文件中配置rabbitmq
spring:rabbitmq:host: 10.211.55.6port: 5672username: itcastpassword: 123321virtual-host: /
MqConstants.java
public class MqConstants {/*** 交换机*/public final static String HOTEL_EXCHANGE = "hotel.topic";/*** 监听新增和修改的队列*/public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";/*** 监听删除的队列*/public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";/*** 新增或修改的RoutingKey*/public final static String HOTEL_INSERT_KEY = "hotel.insert";/*** 删除的RoutingKey*/public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
MqConfig.java
@Configuration
public class MqConfig {@Beanpublic TopicExchange topicExchange(){return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);}@Beanpublic Queue insertQueue(){return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);}@Beanpublic Queue deleteQueue(){return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);}@Beanpublic Binding insertQueueBinding(){return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);}@Beanpublic Binding deleteQueueBinding(){return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);}
}
- 在hotel-admin中的增、删、改业务中完成消息发送
导入依赖,配置 yaml 文件
controller中
@RestController
@RequestMapping("hotel")
public class HotelController {@Autowiredprivate IHotelService hotelService;@Autowiredprivate RabbitTemplate rabbitTemplate;@GetMapping("/{id}")public Hotel queryById(@PathVariable("id") Long id){return hotelService.getById(id);}@GetMapping("/list")public PageResult hotelList(@RequestParam(value = "page", defaultValue = "1") Integer page,@RequestParam(value = "size", defaultValue = "1") Integer size){Page<Hotel> result = hotelService.page(new Page<>(page, size));return new PageResult(result.getTotal(), result.getRecords());}@PostMappingpublic void saveHotel(@RequestBody Hotel hotel){hotelService.save(hotel);rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_INSERT_KEY, hotel.getId());}@PutMapping()public void updateById(@RequestBody Hotel hotel){if (hotel.getId() == null) {throw new InvalidParameterException("id不能为空");}hotelService.updateById(hotel);rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_INSERT_KEY, hotel.getId());}@DeleteMapping("/{id}")public void deleteById(@PathVariable("id") Long id) {hotelService.removeById(id);rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_DELETE_KEY, id);}
}
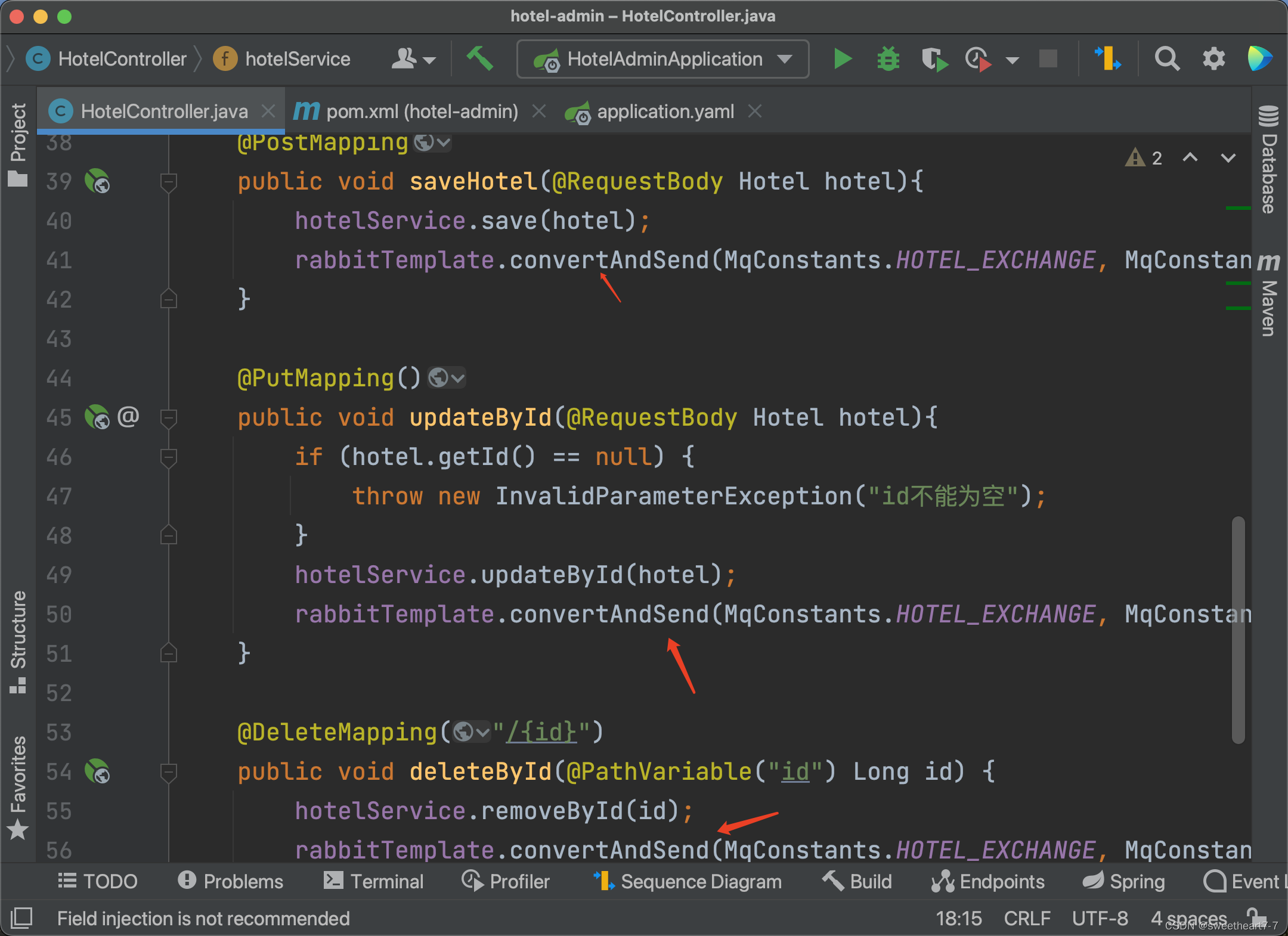
- 在hotel-demo中完成消息监听,并更新elasticsearch中数据
HotelListener.java
@Component
public class HotelListener {@Autowiredprivate IHotelService hotelService;/*** 监听酒店新增或修改的业务* @param id*/@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)public void listenHotelInsertOrUpdate(Long id){hotelService.insertById(id);}/*** 监听酒店新删除的业务* @param id*/@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)public void listenHotelDelete(Long id){hotelService.deleteById(id);}
}
service
@Override
public void deleteById(Long id) {try {// 1. 准备RequestDeleteRequest request = new DeleteRequest("hotel", id.toString());// 2. 准备发送请求client.delete(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}@Override
public void insertById(Long id) {try {// 0. 根据id查询酒店数据Hotel hotel = getById(id);// 转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 1. 准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());// 2. 准备Json文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 3. 发送请求client.index(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}
集群
ES集群结构
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica )
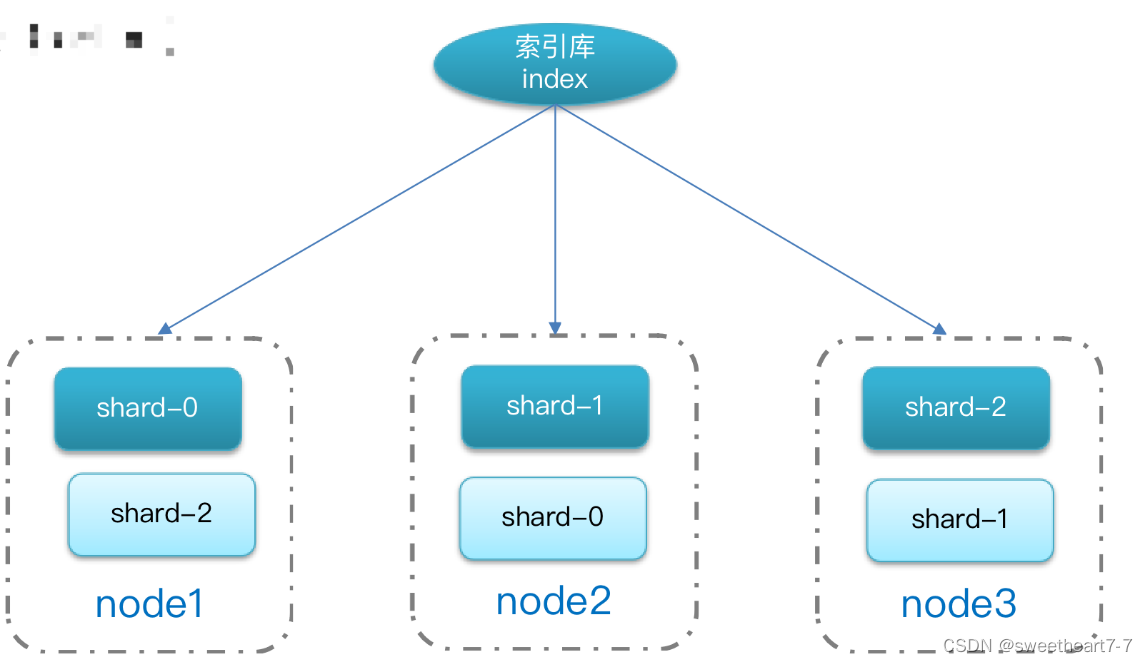
搭建ES集群
我们会在单机上利用docker容器运行多个es实例来模拟es集群。不过生产环境推荐大家每一台服务节点仅部署一个es的实例。
部署es集群可以直接使用docker-compose来完成,但这要求你的Linux虚拟机至少有4G的内存空间
创建es集群
首先编写一个docker-compose文件,内容如下:
version: '2.2'
services:es01:image: elasticsearch:7.12.1container_name: es01environment:- node.name=es01- cluster.name=es-docker-cluster- discovery.seed_hosts=es02,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data01:/usr/share/elasticsearch/dataports:- 9200:9200networks:- elastices02:image: elasticsearch:7.12.1container_name: es02environment:- node.name=es02- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data02:/usr/share/elasticsearch/dataports:- 9201:9200networks:- elastices03:image: elasticsearch:7.12.1container_name: es03environment:- node.name=es03- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es02- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data03:/usr/share/elasticsearch/datanetworks:- elasticports:- 9202:9200
volumes:data01:driver: localdata02:driver: localdata03:driver: localnetworks:elastic:driver: bridge
es运行需要修改一些linux系统权限,修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
添加下面的内容:
vm.max_map_count=262144
然后执行命令,让配置生效:
sysctl -p
通过docker-compose启动集群:
docker-compose up -d
集群状态监控
kibana可以监控es集群,不过新版本需要依赖es的x-pack 功能,配置比较复杂。
这里推荐使用cerebro来监控es集群状态,官方网址:https://github.com/lmenezes/cerebro
解压即可使用,非常方便。
解压好的目录如下:

进入对应的bin目录:
双击其中的cerebro.bat文件即可启动服务。
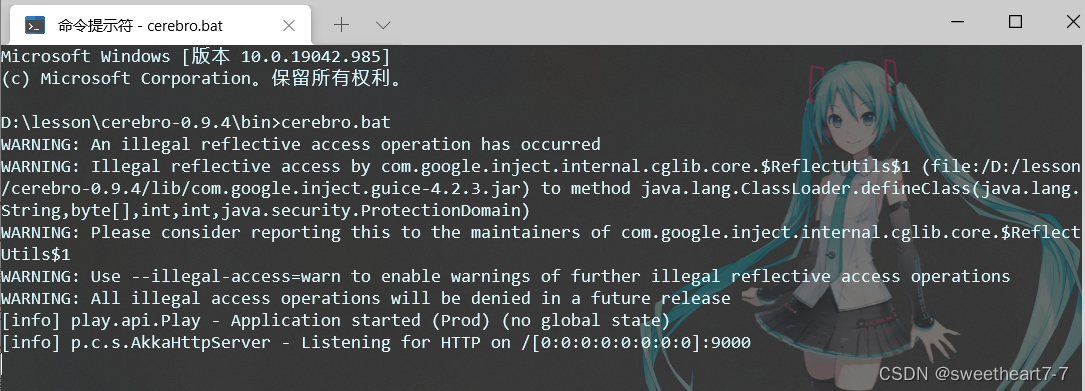
访问http://localhost:9000 即可进入管理界面:
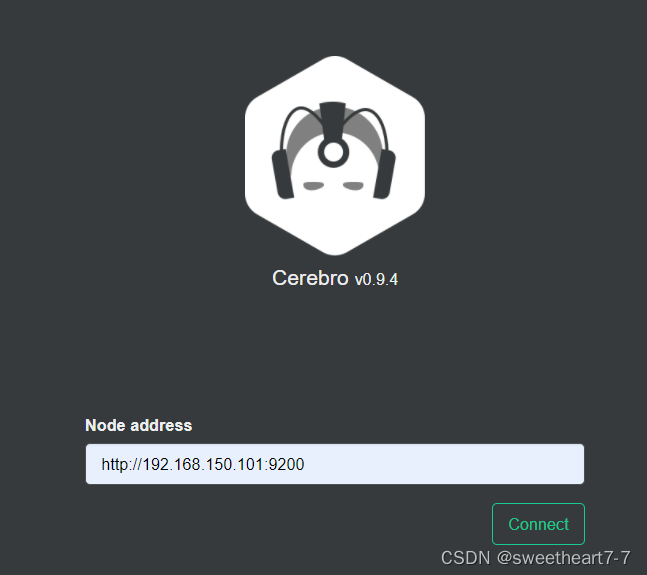
输入你的elasticsearch的任意节点的地址和端口,点击connect即可:
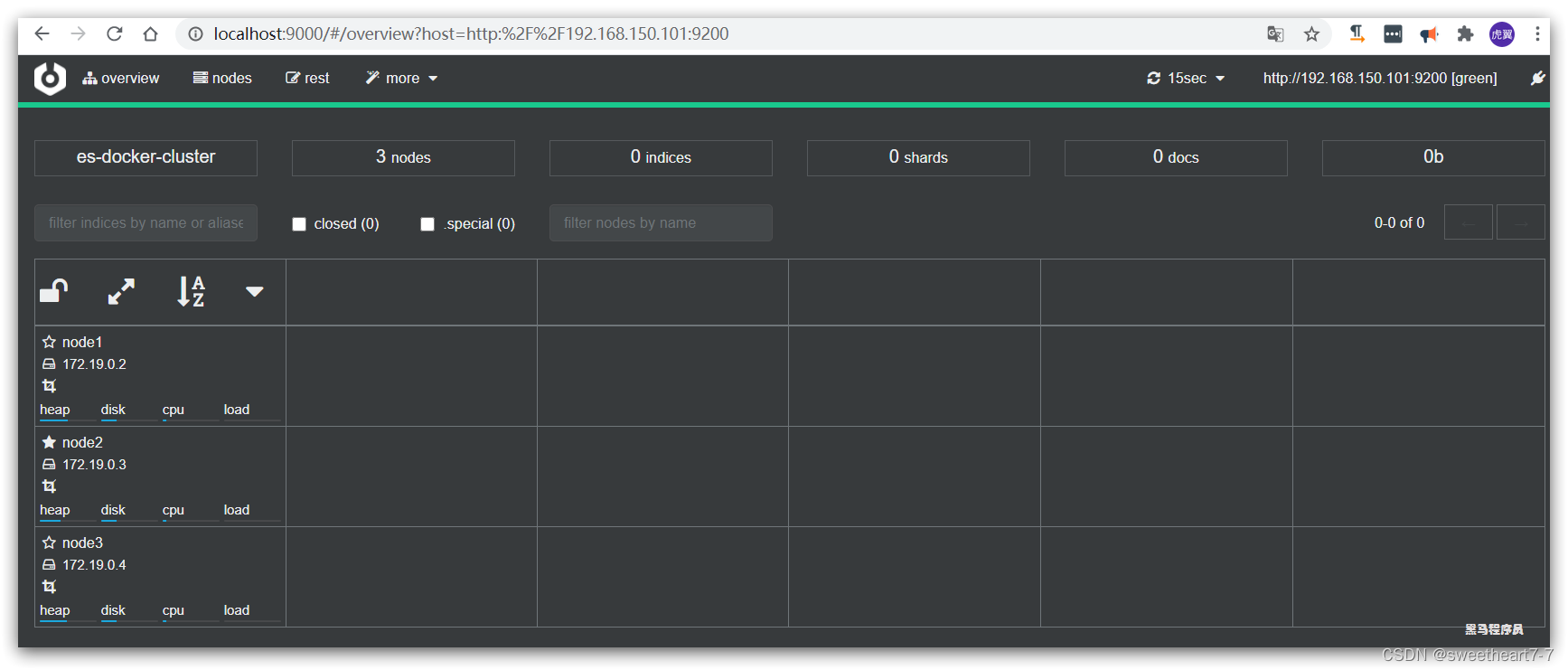
绿色的条,代表集群处于绿色(健康状态)。
创建索引库
1)利用kibana的DevTools创建索引库
在DevTools中输入指令:
PUT /itcast
{"settings": {"number_of_shards": 3, // 分片数量"number_of_replicas": 1 // 副本数量},"mappings": {"properties": {// mapping映射定义 ...}}
}
2)利用cerebro创建索引库
利用cerebro还可以创建索引库:
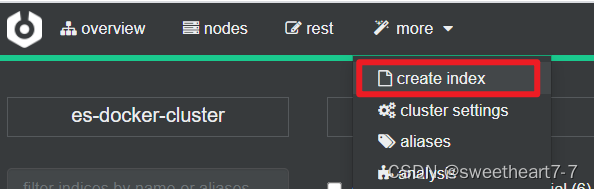
填写索引库信息:
点击右下角的create按钮:

查看分片效果
回到首页,即可查看索引库分片效果:
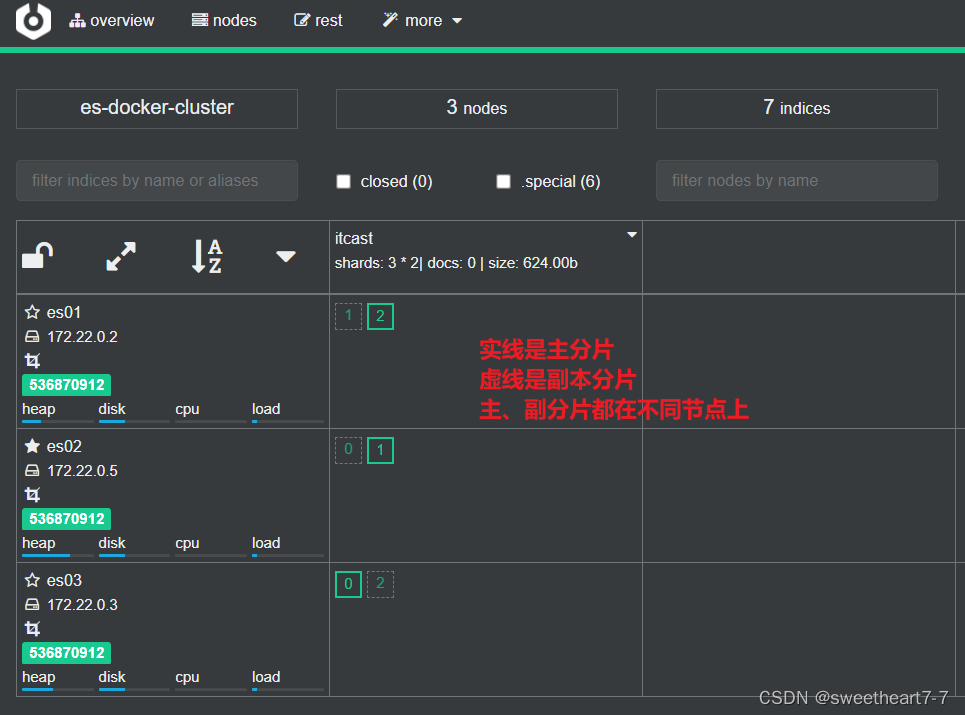
每个索引库的分片数量、副本数量都是在创建索引库时指定的,并且分片数量一旦设置以后无法修改。语法如下:

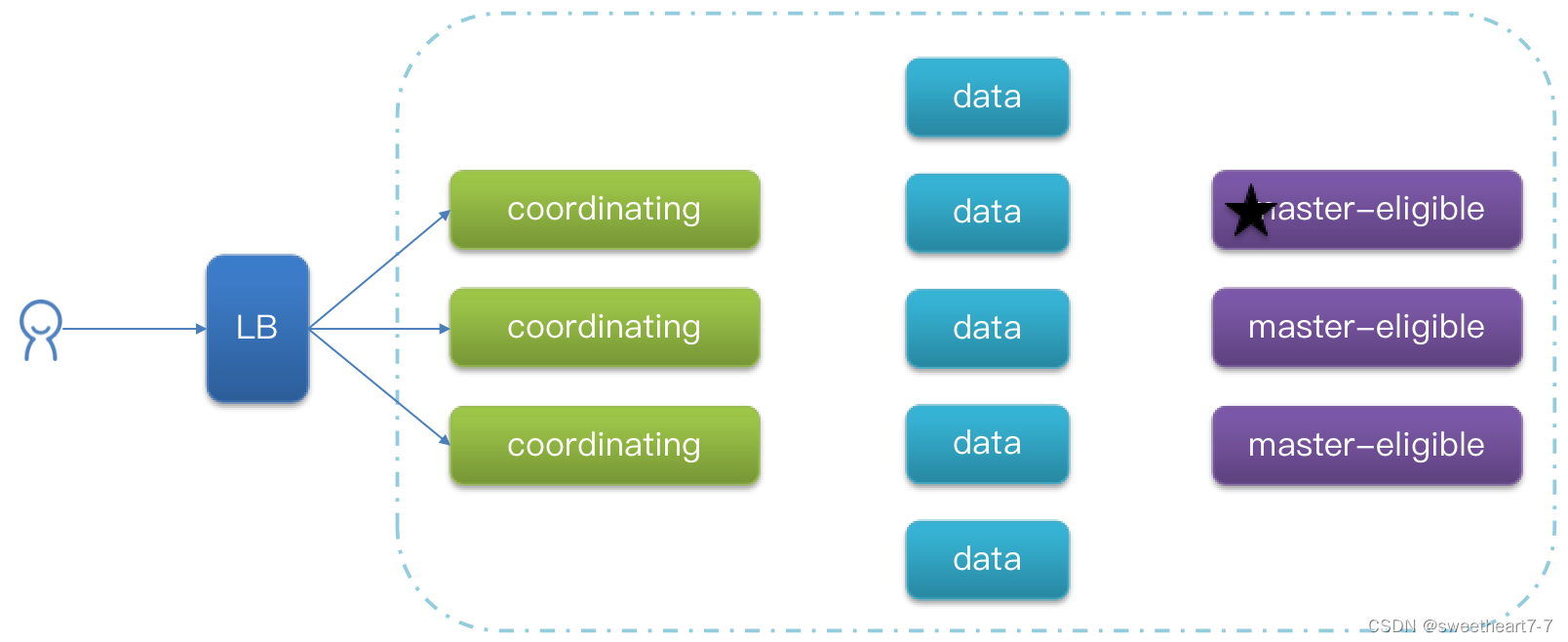
ES集群的节点角色
elasticsearch中集群节点有不同的职责划分:
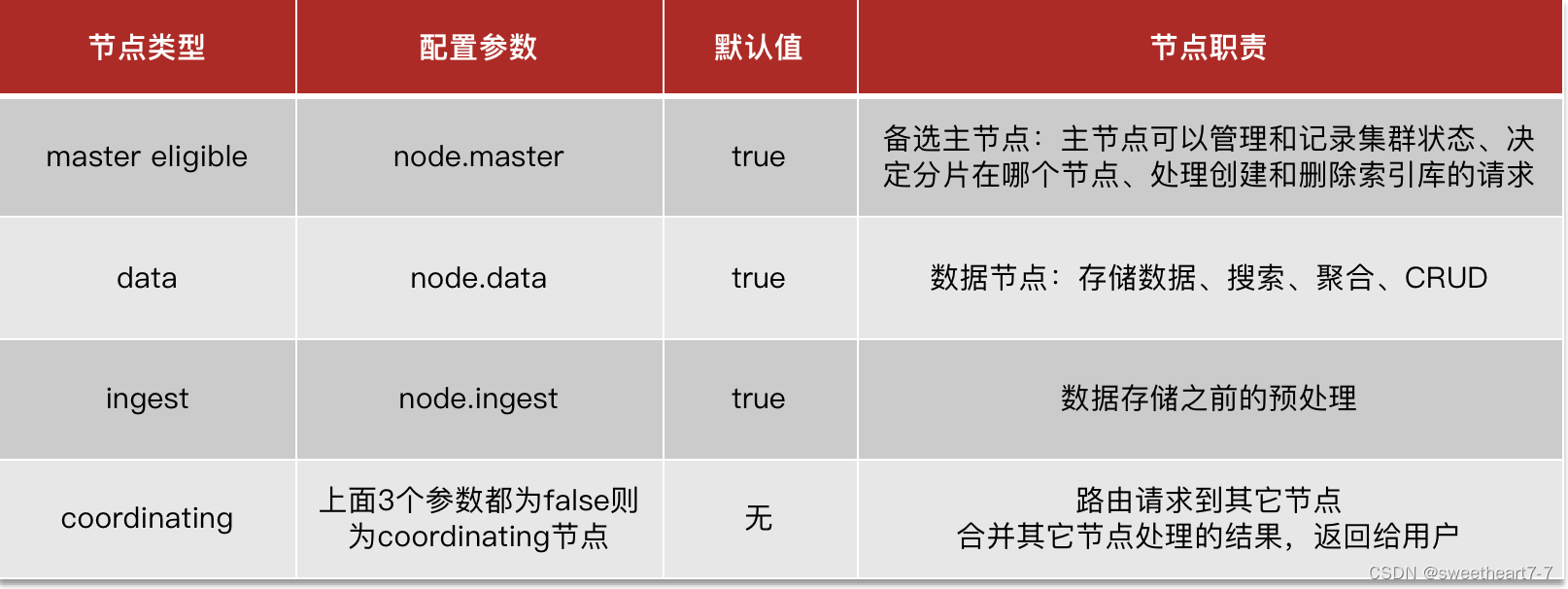
elasticsearch中的每个节点角色都有自己不同的职责,因此建议集群部署时,每个节点都有独立的角色。
集群脑裂问题
默认情况下,每个节点都是master eligible节点,因此一旦master节点宕机,其它候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能发生脑裂问题。
为了避免脑裂,需要要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
- 数据的CRUD
coordinator节点的作用是什么?
- 路由请求到其它节点
- 合并查询到的结果,返回给用户
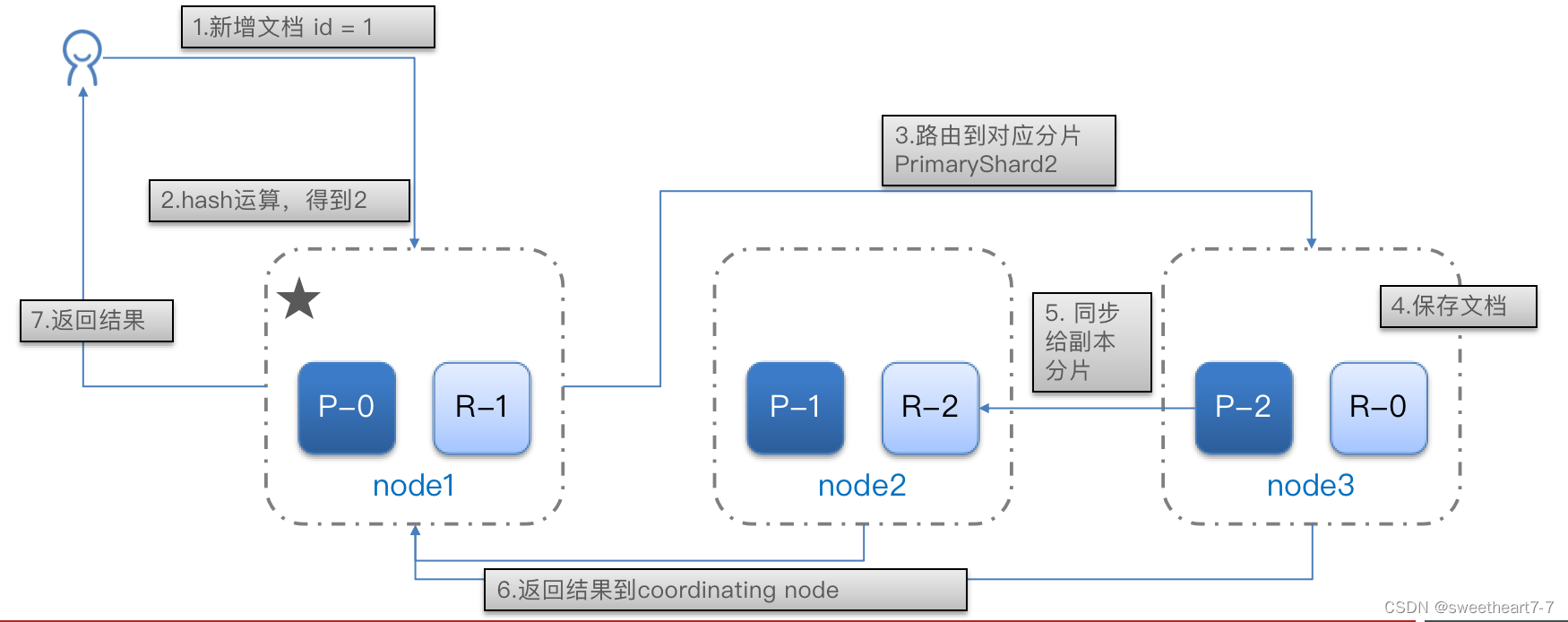
集群分布式存储
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:

说明:
- _routing默认是文档的id
- 算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档流程:
集群分布式查询
elasticsearch的查询分成两个阶段:
- scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
- gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
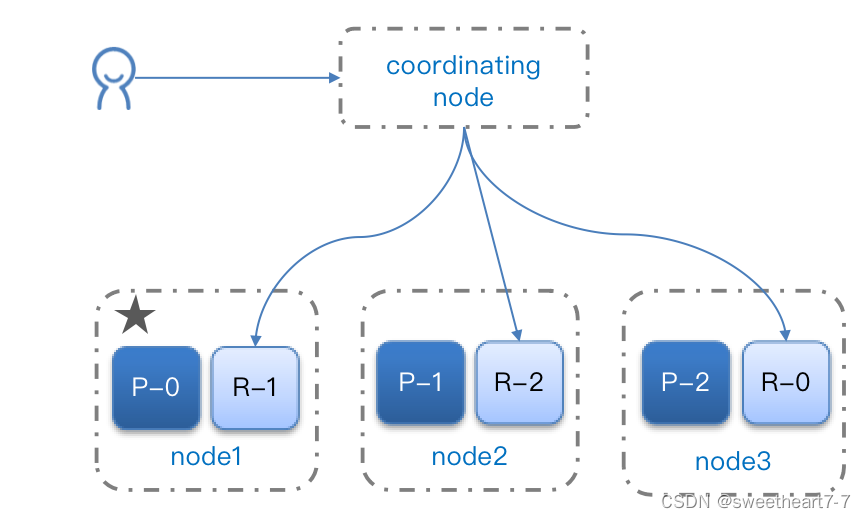
分布式新增如何确定分片?
- coordinating node根据id做hash运算,得到结果对shard数量取余,余数就是对应的分片
分布式查询的两个阶段
- 分散阶段: coordinating node将查询请求分发给不同分片
- 收集阶段:将查询结果汇总到coordinating node ,整理并返回给用户
集群故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
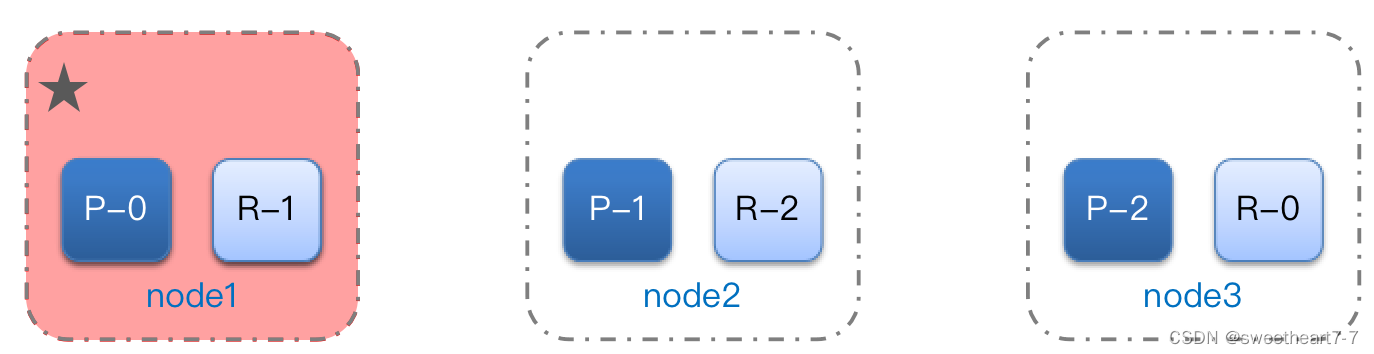
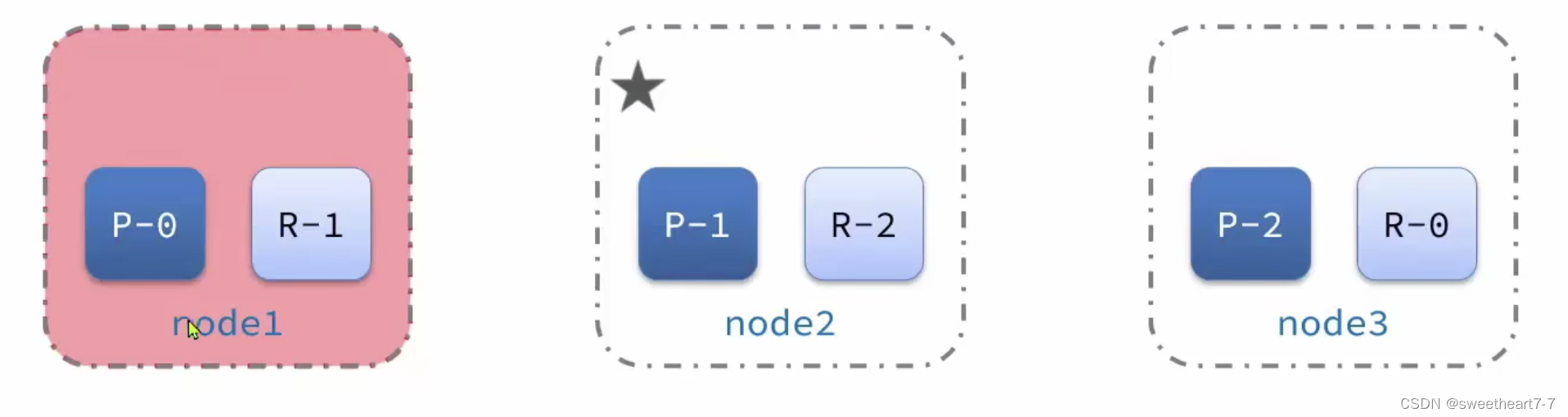
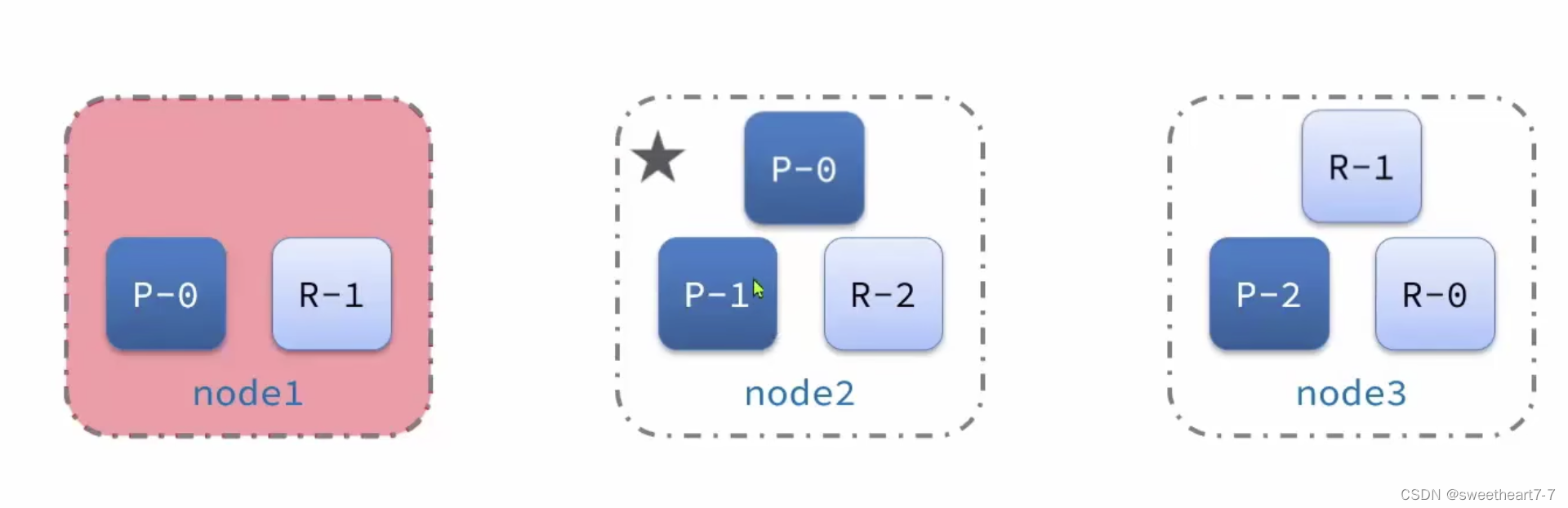
故障转移:
- master宕机后,EligibleMaster选举为新的主节点。
- master节点监控分片、节点状态,将故障节点上的分片转移到正常节点,确保数据安全。
相关文章:
Spring Cloud学习(十一)【深入Elasticsearch 分布式搜索引擎03】
文章目录 数据聚合聚合的种类DSL实现聚合RestAPI实现聚合 自动补全拼音分词器自定义分词器自动补全查询completion suggester查询RestAPI实现自动补全 数据同步数据同步思路分析实现elasticsearch与数据库数据同步 集群搭建ES集群创建es集群集群状态监控创建索引库1)…...

【gitlab初始密码登录失败】
gitlab初始密码登录失败 修改密码 修改密码 [rootlocalhost ~]# gitlab-rake "gitlab:password:reset[root]" Enter password: Confirm password: Password successfully updated for user with username root. # 再重新配置gitlab [rootlocalhost ~]# gitlab-ctl…...

2017年全国硕士研究生入学统一考试管理类专业学位联考数学试题——解析版
文章目录 2017 级考研管理类联考数学真题解析一、问题求解(本大题共 5 小题,每小题 3 分,共 45 分)下列每题给出 5 个选项中,只有一个是符合要求的,请在答题卡上将所选择的字母涂黑。真题(2017-…...

2、基础入门——web应用架构搭建漏洞HTTP数据包代理服务器
Web应用环境架构类 开发语言:php、java、python、ASP、ASPX等程序源码:用的人多了,就成CMS了。中间件容器:IIS、Apache、Nginx、Tomcat、Weblogic、Jboos、glasshfish等数据库类型:Access、Mysql、Mssql、Oracle、Red…...

【精选】OpenCV多视角摄像头融合的目标检测系统:全面部署指南&源代码
1.研究背景与意义 随着计算机视觉和图像处理技术的快速发展,人们对于多摄像头拼接行人检测系统的需求日益增加。这种系统可以利用多个摄像头的视角,实时监测和跟踪行人的活动,为公共安全、交通管理、视频监控等领域提供重要的支持和帮助。 …...

力扣算法练习BM45—滑块窗口的最大值
题目 给定一个长度为 n 的数组 num 和滑动窗口的大小 size ,找出所有滑动窗口里数值的最大值。 例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6,5}; 针…...

最小二乘估计及与极大似然估计的关系
最小二乘估计(Least Squares Estimation)和极大似然估计(Maximum Likelihood Estimation)是统计学中常用的参数估计方法,它们在某些情况下是等价的,但在一般情况下并不总是相同的。 最小二乘估计ÿ…...
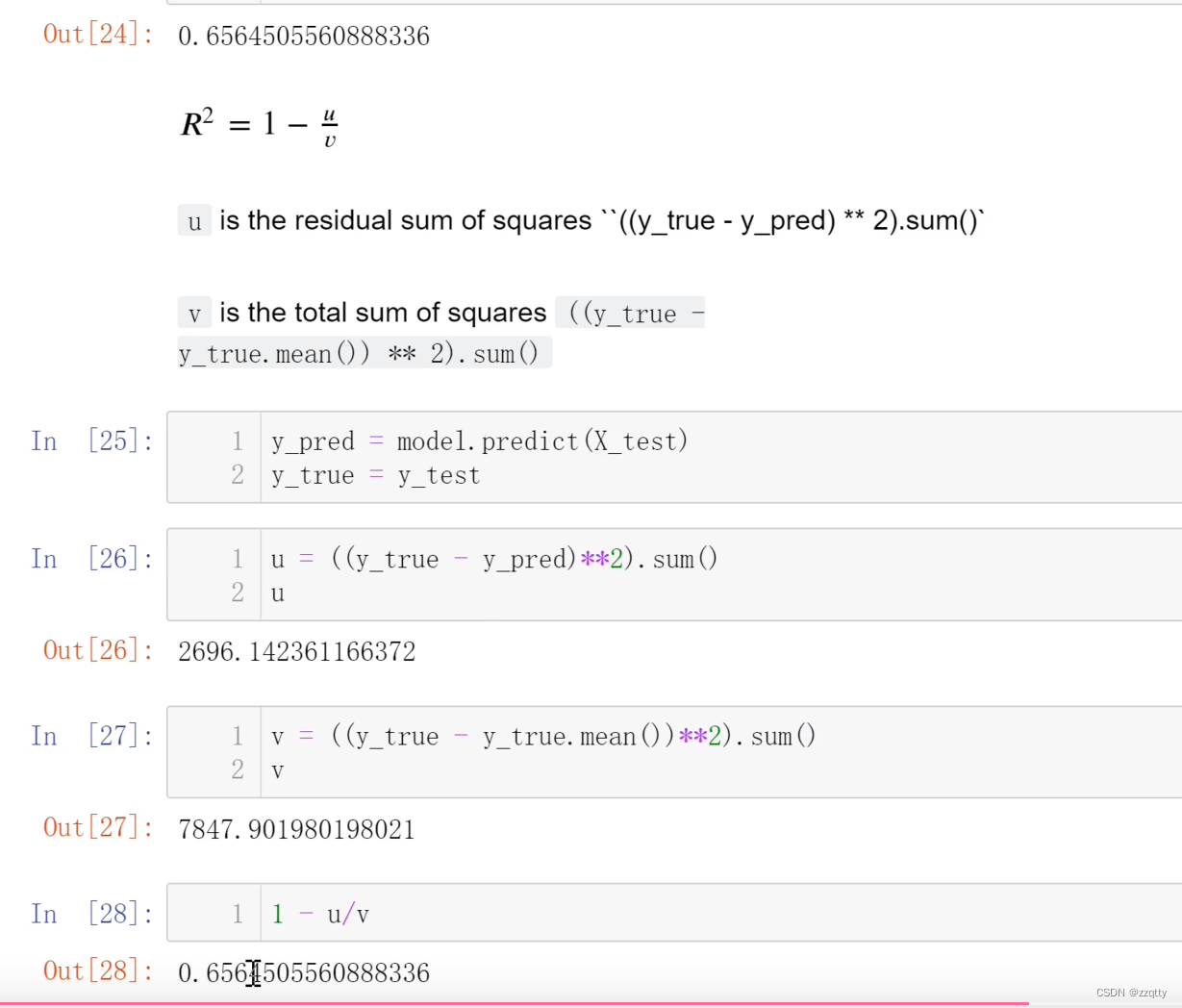
02房价预测
目录 代码 评分算法: 代码 import numpy as np from sklearn import datasets from sklearn.linear_model import LinearRegression# 指定版本才有数据集 # C:\Users\14817\PycharmProjects\pythonProject1\venv\Scripts\activate.bat # pip install scikit-le…...

【Springboot】pom.xml中的<build>标签详解
默认值及其标签解释 <build><!-- 指定最终构建产物的名称, 例如生成的 JAR 文件的名称 --><finalName>${artifactId}-${version}</finalName><!-- 指定源代码文件的目录路径 --><sourceDirectory>src/main/java</sourceDirectory>&l…...
智能驾驶产品开发中如何贯彻“正向开发”理念
摘要: 基于演绎法的正向开发理念,能够让智能驾驶产品在充分满足用户需求,保证产品质量的同时,确保开发目标合理且得到落实。 前段时间,微博CEO吐槽理想L9智能驾驶“行驶轨迹不居中”,在网上引发了热烈讨论…...
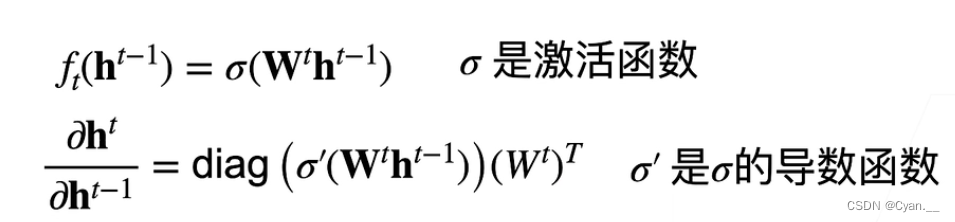
【机器学习】038_梯度消失、梯度爆炸
一、原因 神经网络梯度 假设现在有一个 层的神经网络,每层的输出为一个对输入作 变换的函数结果 用 来表示第 层的输出,那么有下列公式: 链式法则计算损失 关于某一层某个参数 的梯度: 注意到, 为向量&am…...
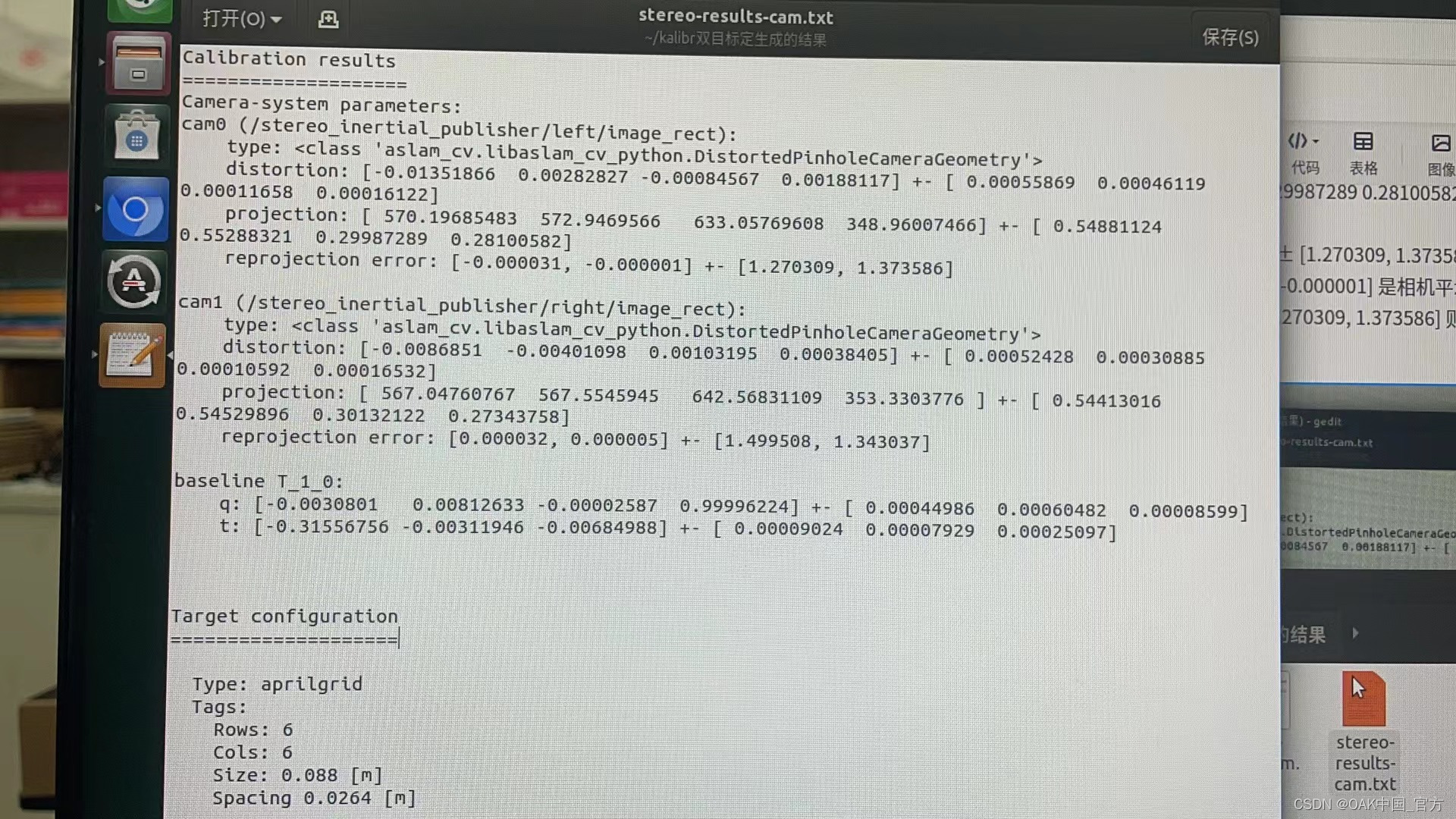
【转】OAK-D双目相机进行标定及标定结果说明
编辑:OAK中国 首发:A. hyhCSDN 喜欢的话,请多多👍⭐️✍ 内容来自用户的分享,如有疑问请与原作者交流! ▌前言 Hello,大家好,这里是OAK中国,我是助手君。 近期在CSDN刷…...

whip和whep
原文为runner365.git大佬的文章 原文链接:https://blog.csdn.net/sweibd/article/details/124552793 WHIP接口 什么是whip 全称: WebRTC-HTTP ingestion protocol (WHIP). rfc地址: rfc-draft-murillo-whip-00 简单说,就是通过HTTP接口能导入webrtc媒…...

SpringBoot集成jjwt和使用
1.引入jwt依赖(这里以jjwt为例,具体其他jwt产品可以参见jwt官网) <dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>0.9.1</version> </dependency>…...

RedisConnectionFactory is required已解决!!!!
1.起因🤶🤶🤶🤶 redis搭建完成后,准备启动主程序,异常兴奋,结果报错了!!!! 2.究竟是何原因 😭😭😭…...

redis的高可用之持久化
1、redis的高可用考虑指标 (1)正常服务 (2)数据容量的扩展 (3)数据的安全性 2、redis实现高可用的四种方式 (1)持久化 (2)主从复制 (3&…...
onnx模型转换opset版本和固定动态输入尺寸
背景:之前我想把onnx模型从opset12变成opset12,太慌乱就没找着,最近找到了官网上有示例的,大爱onnx官网,分享给有需求没找着的小伙伴们。 1. onnx模型转换opset版本 官网示例: import onnx from onnx im…...
远程运维如何更高效的远程管理?向日葵的这几项功能会帮到你
远程运维如何更高效的远程管理?向日葵的这几项功能会帮到你 具备一定规模的企业,其IT运维需求普遍会面临设备数量众多、难以统一高效管理、始终存在安全敞口等问题,尤其是针对分部广泛的无人值守设备时,更是如此。 举一个简单的例…...

python BDD 的相关概念
在Python 语言中进行BDD的规格和测试文件的编写的时候,常常会遇到下面的概念: Fixture : 测试设施。设定测试环境的预设状态或值的机制。Background: 背景。所有场景的公共部分。Scenario: 场景。Given : 前置条件Whe…...

【Exception】Error: Dynamic require of “path“ is not supported
Talk is cheap, show me the code. 环境 | Environment kversionOSwindows 11Node.jsv18.14.2npm9.5.0vite5.0.0vue3.3.8 报错日志 | Error log >npm run dev> app10.0.0 dev > viteERROR failed to load config from C:\code\frontend\app1\vite.config.js …...

C++中派生类对象如何调用实现覆盖后基类的虚函数
C中派生类重写了基类的虚函数,当基类指针指向派生类空间时,只能调用重写的派生类函数。如果要调用基类的虚函数,可以直接使用派生类对象,因为派生类对象构造时,会先隐式调用基类的构造函数,构造出基类成员。…...

5分钟快速上手:Windows系统iperf3网络性能测试完整指南
5分钟快速上手:Windows系统iperf3网络性能测试完整指南 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds iperf3是业界公认的专业网络性能…...

DoL-Lyra整合包终极指南:如何轻松安装游戏Mod增强体验
DoL-Lyra整合包终极指南:如何轻松安装游戏Mod增强体验 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS DoL-Lyra是一款专为Degrees of Lewdity游戏设计的Mod整合包,通过自动化…...

Honey Select 2终极增强补丁:200+插件一键安装的完整解决方案
Honey Select 2终极增强补丁:200插件一键安装的完整解决方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》游戏体验不够…...

终极免费PLC编程工具:OpenPLC Editor完全指南
终极免费PLC编程工具:OpenPLC Editor完全指南 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor 在工业自动化领域,寻找一款既专业又免费的开源PLC编程工具曾经是一个挑战。OpenPLC Editor正是为解…...

【Java 25密封类模式实战指南】:20年架构师亲授5大高危误用场景与3步安全迁移法
更多请点击: https://intelliparadigm.com 第一章:Java 25密封类模式的核心演进与设计哲学 Java 25 将密封类(Sealed Classes)从预览特性正式升格为标准语言特性,并深度整合至类型系统与模式匹配生态中。其设计哲学不…...

DevOps工具集成终极指南:基于DevOps-Roadmap的Jenkins+Ansible实战方案
DevOps工具集成终极指南:基于DevOps-Roadmap的JenkinsAnsible实战方案 【免费下载链接】DevOps-Roadmap DevOps Roadmap for 2026. with learning resources 项目地址: https://gitcode.com/GitHub_Trending/de/DevOps-Roadmap DevOps-Roadmap项目提供了2025…...

RDP Wrapper Library:Windows远程桌面多用户连接的技术实现方案
RDP Wrapper Library:Windows远程桌面多用户连接的技术实现方案 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 技术问题背景分析 Windows操作系统从Vista版本开始,在家庭版和基础版中限制…...

3大核心功能深度解析:faster-whisper-GUI 专业语音转文字实战指南
3大核心功能深度解析:faster-whisper-GUI 专业语音转文字实战指南 【免费下载链接】faster-whisper-GUI faster_whisper GUI with PySide6 项目地址: https://gitcode.com/gh_mirrors/fa/faster-whisper-GUI faster-whisper-GUI 是一款基于 PySide6 开发的图…...

别再一条条敲命令了!手把手教你修改Anaconda的.condarc文件,一劳永逸换清华源
彻底告别下载卡顿:Anaconda镜像源终极配置指南 每次安装Python包时都要忍受缓慢的下载速度?那些临时添加的镜像源命令是否让你感到繁琐?作为数据科学和Python开发的基础工具,Anaconda的包管理效率直接影响着我们的工作体验。本文将…...