PyTorch学习笔记:nn.TripletMarginLoss——三元组损失
PyTorch学习笔记:nn.TripletMarginLoss——三元组损失
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='mean')
功能:创建一个三元组损失函数(triplet loss),用于衡量输入数据x1,x2,x3x_1,x_2,x_3x1,x2,x3之间的相对相似性,其中输入样本又分别称为中立样本、正样本以及负样本,具体介绍可见论文《Learning shallow convolutional feature descriptors with triplet losses》
损失函数:
L(x1,x2,x3)=max{d(x1,x2)−d(x1,x3)+margin,0}L(x_1,x_2,x_3)=\max\{d(x_1,x_2)-d(x_1,x_3)+\text{margin},0\} L(x1,x2,x3)=max{d(x1,x2)−d(x1,x3)+margin,0}
其中:
d(xi,yi)=∣∣xi−yi∣∣pd(x_i,y_i)=||x_i-y_i||_p d(xi,yi)=∣∣xi−yi∣∣p
该函数的作用就是拉进x1x_1x1与x2x_2x2的距离,使它们更加相似,同时推离x1x_1x1与x3x_3x3的距离,即使它们更加不同。
输入:
margin:边界距离,具体含义如公式所示,如果该值越大,则表明x1x_1x1与x2x_2x2期望距离越近,x1x_1x1与x3x_3x3期望距离越远。输入数据类型为浮点数(float),默认1.0;p:用于计算两个向量距离的范数,具体含义如公式所示。输入数据类型为整数(int),默认2,即欧氏距离;swap:是否使用距离交换,具体功能可见论文《Learning shallow convolutional feature descriptors with triplet losses》;size_average与reduce已被弃用,具体功能由reduction替代;reduction:指定损失输出的形式,有三种选择:none|mean|sum。none:损失不做任何处理,直接输出一个数组;mean:将得到的损失求平均值再输出,会输出一个数;sum:将得到的损失求和再输出,会输出一个数。
注意:
- 输入的三个样本数据维数必须为二维(N,D)(N,D)(N,D),其中第二个维度DDD表示向量长度;
- 如果
reduction设置为none,则输出的数组维数为1,尺寸为(N)(N)(N)
代码案例
一般用法
import torch
import torch.nn as nn# reduction设为none便于查看损失计算的结果
triplet_loss = nn.TripletMarginLoss(reduction='none')
x1 = torch.randn(20).reshape(2,10)
x2 = torch.randn(20).reshape(2,10)
x3 = torch.randn(20).reshape(2,10)
loss = triplet_loss(x1, x2, x3)
print(x1)
print(x2)
print(x3)
print(loss)
输出
tensor([[-0.1419, 0.0550, -0.2996, -1.7194, 0.5485, -0.9163, -0.6983, 0.0239,1.2940, -0.4858],[ 1.8544, -0.2349, -0.2523, -1.6167, 0.7861, -1.7627, 0.3139, -1.5112,-0.3378, 0.0059]])
tensor([[-1.5967, 0.4007, 0.1468, -1.0085, -1.4989, 1.7531, 0.0865, -0.9080,-0.4046, 0.5229],[-1.8673, -0.4958, 1.0122, -1.8696, 0.1974, -0.8017, -1.0562, -2.1461,1.7112, -0.6001]])
tensor([[-1.0008, 1.5316, 0.0078, 1.1405, -0.0629, 0.4934, -1.8050, -1.0302,0.8676, -0.1988],[ 1.3015, -0.2786, 0.4215, -0.6413, -0.0760, -0.8138, 0.2173, 1.5132,-0.6389, 0.7173]])
tensor([1.4133, 2.2473])
官方文档
nn.TripletMarginLoss:https://pytorch.org/docs/stable/generated/torch.nn.TripletMarginLoss.html?highlight=tripletmarginloss#torch.nn.TripletMarginLoss
初步完稿于:2022年3月30日
相关文章:

PyTorch学习笔记:nn.TripletMarginLoss——三元组损失
PyTorch学习笔记:nn.TripletMarginLoss——三元组损失 torch.nn.TripletMarginLoss(margin1.0, p2.0, eps1e-06, swapFalse, size_averageNone, reduceNone, reductionmean)功能:创建一个三元组损失函数(triplet loss),用于衡量输入数据x1,x…...

冒泡排序详解
冒泡排序是初学C语言的噩梦,也是数据结构中排序的重要组成部分,本章内容我们一起探讨冒泡排序,从理论到代码实现,一步步深入了解冒泡排序。排序算法作为较简单的算法。它重复地走访过要排序的数列,一次比较两个元素&am…...
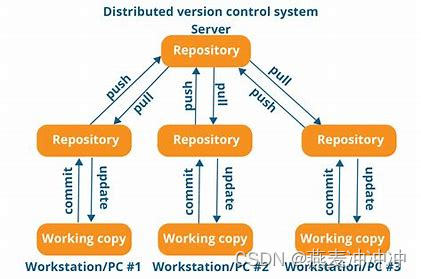
git极快上手指南超级精简版
注:本文参考https://www.liaoxuefeng.com/wiki/896043488029600 原文非常值得一读,作者学识渊博,补充了很多有意思的知识。我仅仅是拾人牙慧。 git是最先进的分布式版本控制系统。 版本控制系统——自动记录系统中文件的改动情况࿰…...
蓝桥杯-最长公共子序列(线性dp)
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 已知有两个数组a,b。已知每个数组的长度。要求求出两个数组的最长公共子序列 序列 1 2 3 4 5 序列 2 3 2 1 4 5 子序列:从其中抽掉某个或多个元素而产生的新…...

GO的并发模式Context
GO的并发模式Context 文章目录GO的并发模式Context一、介绍二、Context三、context的衍生四、示例:Google Web Search4.1 server程序4.2 userip 包4.3 google 包五、使用context包中程序实体实现sync.WaitGroup同样的功能(1)使用sync.WaitGro…...
《Redis实战篇》六、秒杀优化
6、秒杀优化 6.0 压力测试 目的:测试1000个用户抢购优惠券时秒杀功能的并发性能~ ①数据库中创建1000用户 这里推荐使用开源工具:https://www.sqlfather.com/ ,导入以下配置即可一键生成模拟数据 {"dbName":"hmdp",…...
)
《C++ Primer Plus》第16章:string类和标准模板库(11)
其他库 C 还提供了其他一些类库,它们比本章讨论前面的例子更为专用。例如,头文件 complex 为复数提供了类模板 complex,包含用于 float、long 和 long double 的具体化。这个类提供了标准的复数运算及能够处理复数的标准函数。C11 新增的头文…...

声明和定义
前言 很多编程语言的语法中都有关于声明和定义的概念,这种概念一般会应用于函数或变量的创建和使用中,但是为什么要这么做? 以C语言为例,一些书籍或教程会要求读者在程序文件开头写上函数和变量的声明,然后再在后面对…...

Python获取最小路径,查找元素在list中的坐标
# codingutf-8__author__ Jeff.xiedef t(li):pass获取最小路径def minPathSum(grid):if not grid:return 0m len(grid) #m列n len(grid[0]) #n行print(grid[0])print("m: ",m)print("n: ",n)#创建一个二维数组dp [[0]*n for _ in range(m)]print(dp) #这…...

数据采集协同架构,集成马扎克、西门子、海德汉、广数、凯恩帝、三菱、海德汉、兄弟、哈斯、宝元、新代、发那科、华中各类数控以及各类PLC数据采集软件
文章目录 前言一、采集协同架构是什么?可以做什么(数控、PLC配置采集)?二、使用步骤 1.打开软件,配置MQTT或者数据库(支持sqlserver、mysql等)存储转发消息规则2.配置数控系统所采集的参数、转…...
Allegro172版本如何用自带的功能实现快速在1MMBGA下方等距放置电容
Allegro172版本如何用自带的功能实现快速在1MMBGA下方等距放置电容 在做PCB设计的时候,在1MM中心间距的BGA背面放置电容,是非常常见的设计,如何快速把电容等距放在BGA下方,除了借助辅助工具外,在Allegro升级到了172版本的时候,可以借助本身自带的功能实现快速放置,以下图…...

一种简单的统计pytorch模型参数量的方法
nelememt()函数Tensor.nelement()->引自Tensor.numel()->引自torch.numel(input)三者的作用是相同的Returns the total number of elements in the inputtensor.返回当前tensor的元素数量利用上面的函数刚好可以统计模型的参数数量parameters()函数Module.parameters(rec…...

【PyTorch】教程:对抗学习实例生成
ADVERSARIAL EXAMPLE GENERATION 研究推动 ML 模型变得更快、更准、更高效。设计和模型的安全性和鲁棒性经常被忽视,尤其是面对那些想愚弄模型故意对抗时。 本教程将提供您对 ML 模型的安全漏洞的认识,并将深入了解对抗性机器学习这一热门话题。在图像…...

中国区使用Open AI账号试用Chat GPT指南
最近推出强大的ChatGPT功能,各大程序员使用后发出感叹:程序员要失业了 不过在国内并不支持OpenAI账号注册,多数会提示: OpenAI’s services are not available in your country. 经过一番搜索后,发现如下方案可以完…...
STM32开发(9)----CubeMX配置外部中断
CubeMX配置外部中断前言一、什么是中断1.STM32中断架构体系2.外部中断/事件控制器(EXTI)3.嵌套向量中断控制器(NIVC)二、实验过程1.CubeMX配置2.代码实现3.硬件连接4.实验结果总结前言 本章介绍使用STM32CubeMX对引脚的外部中断进…...
Nextjs了解内容
目录Next.jsnext.js的实现1,nextjs初始化2, 项目结构3, 数据注入getInitialPropsgetServerSidePropsgetStaticProps客户端注入3,CSS Modules4,layout组件5,文件式路由6,BFF层的文件式路由7&…...

从事功能测试1年,裸辞1个月,找不到工作的“我”怎么办?
做功能测试一年多了裸辞职一个月了,大部分公司都要求有自动化测试经验,可是哪来的自动化测试呢? 我要是简历上写了吧又有欺诈性,不写他们给的招聘又要自动化优先,将项目带向自动化不是一个容易的事情,很多…...

机器学习基本原理总结
本文大部分内容参考《深度学习》书籍,从中抽取重要的知识点,并对部分概念和原理加以自己的总结,适合当作原书的补充资料阅读,也可当作快速阅览机器学习原理基础知识的参考资料。 前言 深度学习是机器学习的一个特定分支。我们要想…...
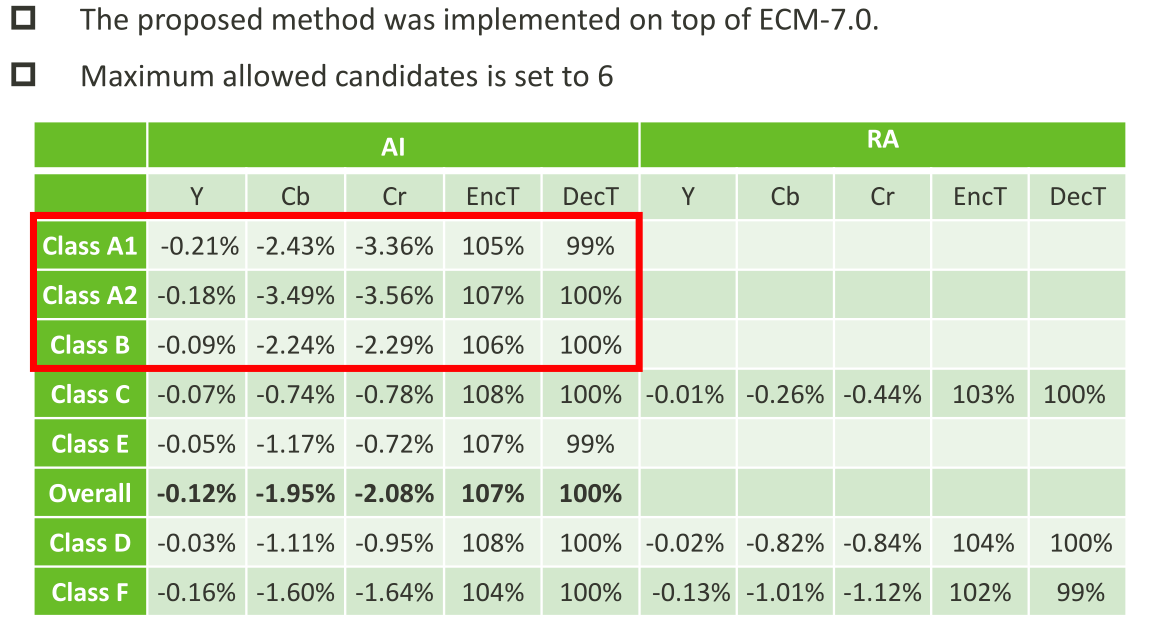
JVET-AC0315:用于色度帧内预测的跨分量Merge模式
ECM采用了许多跨分量的预测(Cross-componentprediction,CCP)模式,包括跨分量包括跨分量线性模型(CCLM)、卷积跨分量模型(CCCM)和梯度线性模型(GLM)࿰…...
)
Session与Cookie的区别(二)
脸盲症的困扰 小明身为杂货店的店长兼唯一的店员,所有大小事都是他一个人在处理。传统杂货店跟便利商店最大的差别在哪里?在于人情味。 就像是你去菜市场买菜的时候会被说帅哥或美女,或者是去买早餐的时候老板会问你:「一样&#…...

Go语言依赖管理:从GOPATH到Go Modules
Go语言依赖管理:从GOPATH到Go Modules 作为一个写了十几年代码的Go后端老兵,我经历了Go语言依赖管理的从GOPATH到Go Modules的转变,踩了不少坑。今天就来分享一下Go语言依赖管理的实践经验。 一、依赖管理的演进 1. GOPATH时代 在Go 1.11之前…...

【ybtoj】【KMP】【例题1】子串查找
【例题1】子串查找Link解题思路CodeLink 传送门 题目 解题思路 kmp模板题 找了超级多篇KMP的博客,一直都看不懂 直到……直到我找到了光(bushi) 这篇博客直接把我升华 Code #include <iostream> #include <cstring> #include…...
)
终极指南:如何在Chainer中构建强大的循环神经网络(RNN)
终极指南:如何在Chainer中构建强大的循环神经网络(RNN) 【免费下载链接】chainer A flexible framework of neural networks for deep learning 项目地址: https://gitcode.com/gh_mirrors/ch/chainer 想要掌握深度学习中的序列建模吗?Chainer框架…...

从零开始:OCAT图形化配置工具让OpenCore黑苹果安装变得简单
从零开始:OCAT图形化配置工具让OpenCore黑苹果安装变得简单 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 还在为复杂的…...

APKMirror:安卓应用安全管理的终极解决方案
APKMirror:安卓应用安全管理的终极解决方案 【免费下载链接】APKMirror 项目地址: https://gitcode.com/gh_mirrors/ap/APKMirror 您是否曾在寻找安卓应用的特定版本时感到无从下手?是否担忧从第三方渠道下载的APK文件可能存在安全隐患ÿ…...

避坑指南:运行YooAsset 2.3.9官方Demo时,你可能会遇到的Sprite白块和退出报错
避坑指南:YooAsset 2.3.9官方Demo运行时的Sprite白块与退出报错深度解析 当Unity开发者初次接触YooAsset资源管理系统时,官方Demo往往是快速上手的最佳途径。然而在YooAsset 2.3.9版本的示例项目中,不少开发者反馈遇到了两个典型问题&#x…...

macOS歌词解决方案:LyricsX从安装到精通的全方位指南
macOS歌词解决方案:LyricsX从安装到精通的全方位指南 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX 在数字音乐体验中,歌词同步显示是提升沉浸感的关键要素。然而…...

AI算法Excel可视化终极指南:如何用电子表格深度解析人工智能原理
AI算法Excel可视化终极指南:如何用电子表格深度解析人工智能原理 【免费下载链接】ai-by-hand-excel 项目地址: https://gitcode.com/gh_mirrors/ai/ai-by-hand-excel 你是否曾被复杂的AI算法公式和抽象概念困扰,想要找到一种更直观的学习方式&a…...

当服务器内存足够大时:为什么我建议你在CentOS 8上彻底禁用Swap?
大内存时代:CentOS 8禁用Swap的云原生性能优化实践 在云计算与容器化技术席卷全球的今天,服务器硬件配置正经历着革命性变化。128GB、256GB甚至TB级内存已成为现代服务器的标配,而传统Linux内存管理机制中的Swap分区在这种新硬件环境下是否还…...

AdGuard浏览器扩展:企业级隐私保护与广告拦截解决方案
AdGuard浏览器扩展:企业级隐私保护与广告拦截解决方案 【免费下载链接】AdguardBrowserExtension AdGuard browser extension 项目地址: https://gitcode.com/gh_mirrors/ad/AdguardBrowserExtension AdGuard浏览器扩展是一款专注于隐私保护和广告拦截的开源…...