【Python基础】数据类型(元组、列表)
文章目录
- 二. 数据类型
- 2.1 元组 tuple
- 2.1.1 定义特性
- 2.1.2 拼接拷贝
- 2.1.3 元组拆包
- 2.1.4 元组方法 count
- 2.2 列表 list
- 2.2.1 基础定义
- 2.2.2 增删操作
- 2.2.3 连接联合
- 2.2.4 其他常规操作
- 2.2.5 列表推导式
- 2.2.6 生成器表达式
- 2.x 小结:何时使用元组或列表
二. 数据类型
Python内置的数据类型远不止元组和列表,本篇介绍元组和列表。
Python中的内置数据类型有:
- 数字:int(整数)、float(浮点数)、complex(复数)
- 字符串:str(字符串)
- 列表:list(列表)
- 元组:tuple(元组)
- 集合:set(集合)、frozenset(不可变集合)
- 字典:dict(字典)
- 布尔值:bool(布尔值)
- None:None(空)
2.1 元组 tuple
2.1.1 定义特性
元组是一种固定长度、不可变的Python对象序列。
定义:最简单的方法是用逗号分隔,复杂的表达式需要通过括号将值包起来。
# 定义1:简单元组
tup = 4,5,6
# 定义2:生成元素是元组的元组
nested_tup = (4,5,6),(8,9)
转化:可以使用tuple将任意序列或迭代器转换为元组:
tup = tuple([4,0,2])
# tup => (4,0,2)
tup = tuple('str')
# tup => ('s','t','r')
获取:元组的元素可以通过中括号[]获取,从0开始。
tup[0] # 's'
不变特性:各位置上的对象是无法被修改的。
tup = tuple(['foo',[1,2],True])
tup[2] = False # TypeError: 'tuple' object does not support item assignment
可变特性:但是元组内的一个对象是可变的,则可以从内部修改:
tup[1].append(3)
tup # ('foo', [1, 2, 3], True)
2.1.2 拼接拷贝
拼接:可以使用 + 号拼接元组。
tup2 = 11,22,33
tup = tup + tup2 # ('foo', [1, 2, 3], True, 11, 22, 33)
拷贝:元组也可以通过乘一个整数,生成含有多份拷贝的元组。注意:对象自身未复制,只是复制引用。
tup = 1,2
tup = tup * 3
tup # (1, 2, 1, 2, 1, 2)
2.1.3 元组拆包
元组拆包:即便是嵌套元组也可以拆包。(Javascript里面的说法是 解构 )
tup = (4,5,(6,7))
a,b,(c,d) = tup
b # 5
c # 6
拆包优势:更轻易地交换变量名。
# 常规方法
tmp = a
a = b
b = tmp
# 拆包方法
a,b = b,a
当然,还可以用于遍历元组或列表组成的序列:
seq = [(1,2,3),(4,5,6),(7,8,9)]
for a,b,c in seq: //...
更高级的拆包:使用特殊语法 * ,从元组的起始位置采集一些元素。
values = 1,2,3,4,5,6
a,b,*rest = values
a,b # (1, 2)
rest # [3, 4, 5, 6]
2.1.4 元组方法 count
使用count计量某个数值在元组中出现的次数:
a = (1,2,2,2,3,2)
a.count(2) # 4
2.2 列表 list
2.2.1 基础定义
与元组不同,列表的长度是可变的,包含的内容也可以修改。
定义:可以使用[] ,list , 类型函数来定义列表。
a_list = [2,3,4,None]tup = ('foo','bar')
b_list = list(tup)
b_list[1] = 'boo'
b_list # ['foo','boo']gen = range(10)
gen # range(0, 10)
2.2.2 增删操作
尾部增加:使用append方法可以将元素添加到列表的尾部。
b_list.append('cool')
b_list # ['foo', 'boo', 'cool']
指定位置增加:使用insert方法可以将元素插入到指定的列表位置。
b_list.insert(1,'red')
b_list # ['foo', 'red', 'boo', 'cool']
指定位置删除:使用pop操作移除特定位置的元素并返回。
b_list.pop(2) # 'boo'
指定元素删除:使用remove方法可以定位第一个符合要求的值并移除。
b_list.append('foo')
b_list # ['foo', 'red', 'cool', 'foo']
b_list.remove('foo')
b_list # ['red', 'cool', 'foo']
查询:可以使用in关键字检查值是否在列表中,前面加not关键字 表示”不在“。
'foo' in b_list # True
'foo' not in b_list # False
2.2.3 连接联合
同元组,可以使用+进行连接,如果存在一个列表,可以使用extend方法向该列表增加多个元素:
list1=["喷火龙","杰尼龟"]
list2=["妙蛙种子","皮卡丘"]
list1.extend(list2)
print(list1) # ['喷火龙', '杰尼龟', '妙蛙种子', '皮卡丘']
易错点:append
注意:如果list1拼接list2时使用了方法append(),最后得到的结果并不是一个线性扁平化的列表,而是将list2作为一个元素放入列表中。其形式如下:
list1.append(list2)
# ['喷火龙', '杰尼龟',['妙蛙种子', '皮卡丘']]
2.2.4 其他常规操作
列表还有其他常见的操作:
- index: 查找列表中第一个匹配的元素的索引
- count: 统计列表中指定元素出现的次数
- sort: 对列表进行排序
- reverse: 对列表进行反转
除此之外,元组所支持的切片,列表也支持。
2.2.5 列表推导式
列表还支持一些高级特性,如列表推导式和生成器表达式。列表推导式是一种简洁的方式来创建列表,而生成器表达式则可以在不创建完整的列表的情况下生成列表中的元素。
列表推导式(List Comprehension)是Python中一种简洁的创建列表的方法。它可以用来快速地创建一个新列表,并在创建过程中对元素进行过滤和转换。
列表推导式的语法如下:
new_list = [expression for item in old_list if condition]
其中,expression表示对item的转换,condition表示对item的过滤条件。
例如,下面的代码使用列表推导式创建一个新列表,其中包含原列表中所有奇数的平方:
old_list = [1, 2, 3, 4, 5]
new_list = [x**2 for x in old_list if x % 2 != 0]
print(new_list) # 输出[1, 9, 25]
列表推导式非常简洁,可以简化很多常规代码,在处理数据时非常方便。除此之外还有字典推导式和集合推导式,都是用来简化创建字典和集合的代码的。
2.2.6 生成器表达式
生成器表达式(Generator Expression)是Python中一种可以在不创建完整的列表的情况下生成列表中元素的方法。它与列表推导式非常类似,但是使用小括号() 来代替方括号 []。
生成器表达式的语法如下:
gen = (expression for item in old_list if condition)
例如,下面的代码使用生成器表达式生成一个生成器,其中包含原列表中所有奇数的平方:
old_list = [1, 2, 3, 4, 5]
gen = (x**2 for x in old_list if x % 2 != 0)
print(next(gen)) # 输出 1
print(next(gen)) # 输出 9
print(next(gen)) # 输出 25
生成器表达式在创建时并不会立即生成整个列表,而是在迭代时才生成元素。因此它可以节省内存空间,对于处理大量数据时非常有用。生成器表达式还可以和其他迭代器结合使用,如与itertools库中的函数组合使用。
2.x 小结:何时使用元组或列表
元组和列表都是Python中的内置数据类型,用于存储一组元素。但是它们在语义和使用方面有很大的不同。
使用元组:当需要存储的数据是固定不变的,或者希望保证数据不会被意外修改时,使用元组。
- 元组中的元素是有序的,在遍历元组时,元素的顺序是固定不变的。
- 元组的语法更加简洁,代码更加整洁。
- 元组可以被用作字典的键或集合的元素,因为它们是不可变的。
使用列表:当需要经常添加、删除、修改数据时,使用列表。
- 列表中的元素是有序的,可以通过索引随意访问元素。
- 列表支持sort方法,可以很方便地对列表中的元素进行排序。
- 列表支持extend和append方法,可以方便地扩展列表。
总体来说,元组适用于存储不变的数据,列表适用于存储可变的数据。选择使用哪种数据结构,取决于你的需求。
相关文章:
)
【Python基础】数据类型(元组、列表)
文章目录二. 数据类型2.1 元组 tuple2.1.1 定义特性2.1.2 拼接拷贝2.1.3 元组拆包2.1.4 元组方法 count2.2 列表 list2.2.1 基础定义2.2.2 增删操作2.2.3 连接联合2.2.4 其他常规操作2.2.5 列表推导式2.2.6 生成器表达式2.x 小结:何时使用元组或列表二. 数据类型 Py…...

你了解互联网APP搜索和推荐的背后逻辑么?
1.搜索和推荐无处不在我们习惯了百度、Google、360搜索的便捷,输入你想要搜索的关键词,立马呈现给你一批对应的结果,供你筛选。我们也经常上淘宝、京东、拼多多购物,输入想买的商品,瞬间列出一页一页的商品清单供我们选…...

Bug的级别,按照什么划分
Bug分类和定级一、bug的定义二、bug的类型三、bug的等级四、bug的优先级一、bug的定义一般是指不满足用户需求的则可以认为是bug,狭义指软件程序的漏洞或缺陷,广义指测试工程师或用户提出的软件可改进的细节、或与需求文档存在差异的功能实现等对应三个测…...
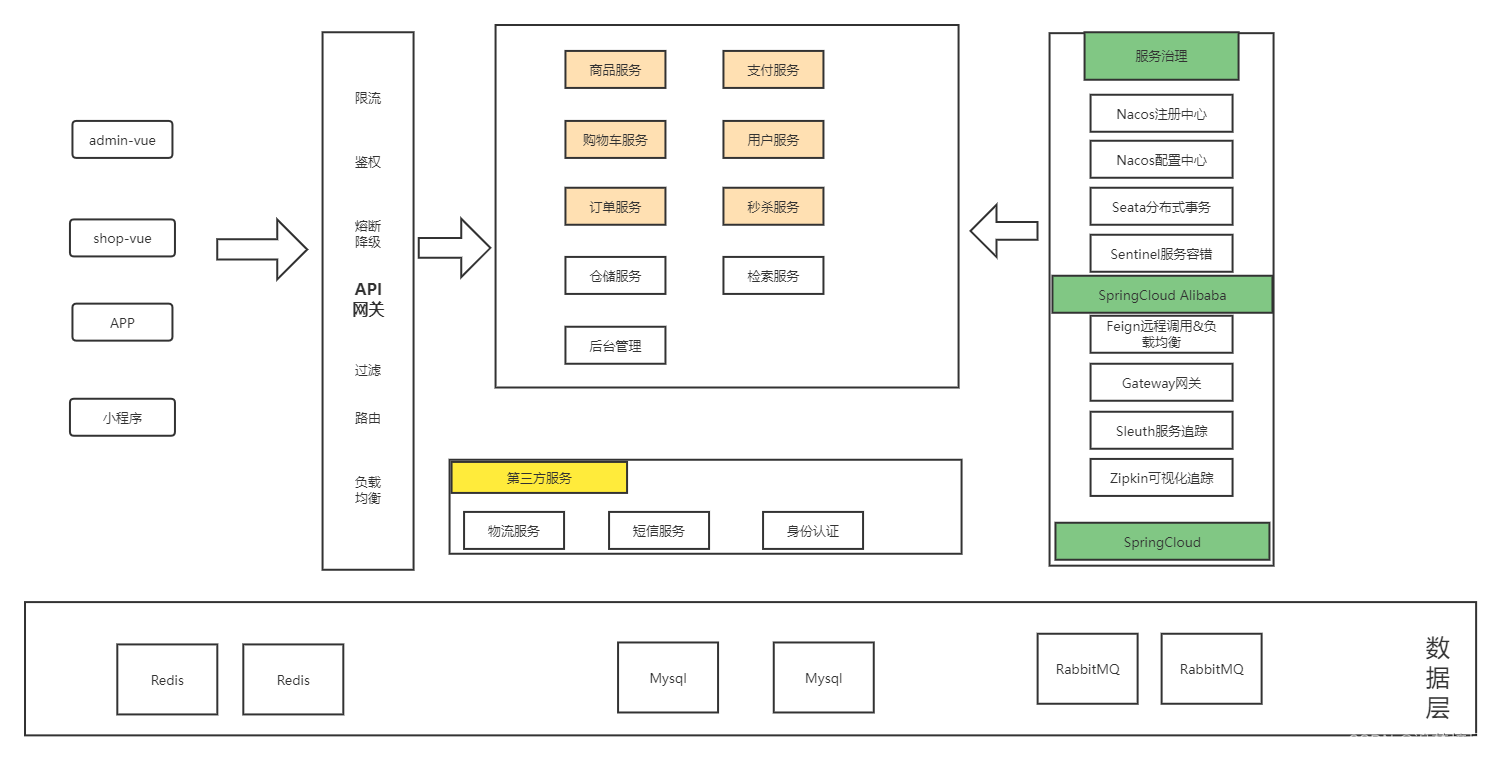
微服务项目简介
项目简介 项目模式 电商模式:市面上有5种常见的电商模式,B2B、B2C、 C2B、 C2C、O2O; 1、B2B模式 B2B (Business to Business),是指 商家与商家建立的商业关系。如:阿里巴巴 2、B2C 模式 B2C (Business to Consumer), 就是我们经常看到的供…...

SLAM中坐标轴旋转及ros的接口解释
读完几个loam算法,满篇的坐标轴旋转,还是手写的(作者,用eigen写不好嘛。。。),我滴天适应了好久…,今天就总结一下坐标轴旋转问题。 一、首先,我们看一下ros中关于欧拉角旋转的函数:setRPY、set…...
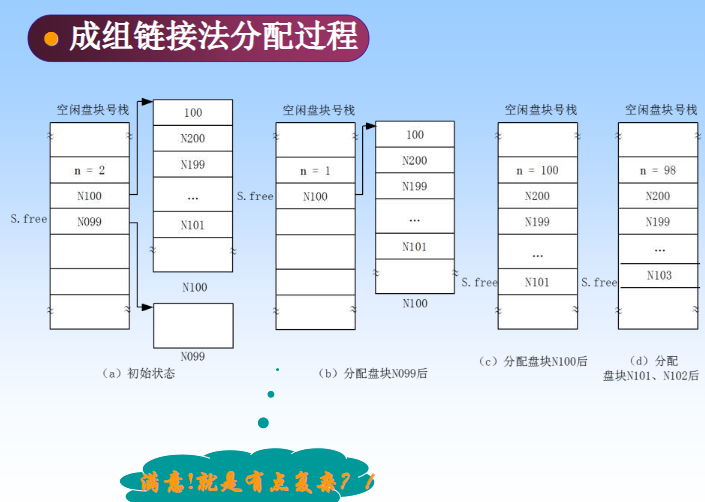
文件管理(9)
文件管理 0 引言 为什么要引入文件系统? 信息管理的需要:用户面前提供一种规格化的机制,方便用户对文件的存取、提高效率。操作系统本身需要–操作系统本身也不是常驻内存的,也有大量的信息需要存于外存。 1 文件定义 文件&a…...

PyTorch学习笔记:nn.TripletMarginLoss——三元组损失
PyTorch学习笔记:nn.TripletMarginLoss——三元组损失 torch.nn.TripletMarginLoss(margin1.0, p2.0, eps1e-06, swapFalse, size_averageNone, reduceNone, reductionmean)功能:创建一个三元组损失函数(triplet loss),用于衡量输入数据x1,x…...

冒泡排序详解
冒泡排序是初学C语言的噩梦,也是数据结构中排序的重要组成部分,本章内容我们一起探讨冒泡排序,从理论到代码实现,一步步深入了解冒泡排序。排序算法作为较简单的算法。它重复地走访过要排序的数列,一次比较两个元素&am…...
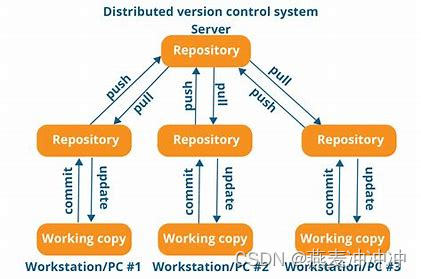
git极快上手指南超级精简版
注:本文参考https://www.liaoxuefeng.com/wiki/896043488029600 原文非常值得一读,作者学识渊博,补充了很多有意思的知识。我仅仅是拾人牙慧。 git是最先进的分布式版本控制系统。 版本控制系统——自动记录系统中文件的改动情况࿰…...
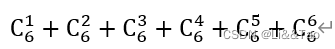
蓝桥杯-最长公共子序列(线性dp)
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 已知有两个数组a,b。已知每个数组的长度。要求求出两个数组的最长公共子序列 序列 1 2 3 4 5 序列 2 3 2 1 4 5 子序列:从其中抽掉某个或多个元素而产生的新…...

GO的并发模式Context
GO的并发模式Context 文章目录GO的并发模式Context一、介绍二、Context三、context的衍生四、示例:Google Web Search4.1 server程序4.2 userip 包4.3 google 包五、使用context包中程序实体实现sync.WaitGroup同样的功能(1)使用sync.WaitGro…...
《Redis实战篇》六、秒杀优化
6、秒杀优化 6.0 压力测试 目的:测试1000个用户抢购优惠券时秒杀功能的并发性能~ ①数据库中创建1000用户 这里推荐使用开源工具:https://www.sqlfather.com/ ,导入以下配置即可一键生成模拟数据 {"dbName":"hmdp",…...
)
《C++ Primer Plus》第16章:string类和标准模板库(11)
其他库 C 还提供了其他一些类库,它们比本章讨论前面的例子更为专用。例如,头文件 complex 为复数提供了类模板 complex,包含用于 float、long 和 long double 的具体化。这个类提供了标准的复数运算及能够处理复数的标准函数。C11 新增的头文…...

声明和定义
前言 很多编程语言的语法中都有关于声明和定义的概念,这种概念一般会应用于函数或变量的创建和使用中,但是为什么要这么做? 以C语言为例,一些书籍或教程会要求读者在程序文件开头写上函数和变量的声明,然后再在后面对…...

Python获取最小路径,查找元素在list中的坐标
# codingutf-8__author__ Jeff.xiedef t(li):pass获取最小路径def minPathSum(grid):if not grid:return 0m len(grid) #m列n len(grid[0]) #n行print(grid[0])print("m: ",m)print("n: ",n)#创建一个二维数组dp [[0]*n for _ in range(m)]print(dp) #这…...

数据采集协同架构,集成马扎克、西门子、海德汉、广数、凯恩帝、三菱、海德汉、兄弟、哈斯、宝元、新代、发那科、华中各类数控以及各类PLC数据采集软件
文章目录 前言一、采集协同架构是什么?可以做什么(数控、PLC配置采集)?二、使用步骤 1.打开软件,配置MQTT或者数据库(支持sqlserver、mysql等)存储转发消息规则2.配置数控系统所采集的参数、转…...
Allegro172版本如何用自带的功能实现快速在1MMBGA下方等距放置电容
Allegro172版本如何用自带的功能实现快速在1MMBGA下方等距放置电容 在做PCB设计的时候,在1MM中心间距的BGA背面放置电容,是非常常见的设计,如何快速把电容等距放在BGA下方,除了借助辅助工具外,在Allegro升级到了172版本的时候,可以借助本身自带的功能实现快速放置,以下图…...

一种简单的统计pytorch模型参数量的方法
nelememt()函数Tensor.nelement()->引自Tensor.numel()->引自torch.numel(input)三者的作用是相同的Returns the total number of elements in the inputtensor.返回当前tensor的元素数量利用上面的函数刚好可以统计模型的参数数量parameters()函数Module.parameters(rec…...

【PyTorch】教程:对抗学习实例生成
ADVERSARIAL EXAMPLE GENERATION 研究推动 ML 模型变得更快、更准、更高效。设计和模型的安全性和鲁棒性经常被忽视,尤其是面对那些想愚弄模型故意对抗时。 本教程将提供您对 ML 模型的安全漏洞的认识,并将深入了解对抗性机器学习这一热门话题。在图像…...

中国区使用Open AI账号试用Chat GPT指南
最近推出强大的ChatGPT功能,各大程序员使用后发出感叹:程序员要失业了 不过在国内并不支持OpenAI账号注册,多数会提示: OpenAI’s services are not available in your country. 经过一番搜索后,发现如下方案可以完…...

如何快速解放双手:MaaYuan游戏日常任务自动化完整指南
如何快速解放双手:MaaYuan游戏日常任务自动化完整指南 【免费下载链接】MaaYuan 代号鸢 / 如鸢 一键长草小助手 项目地址: https://gitcode.com/gh_mirrors/ma/MaaYuan 厌倦了每天花费大量时间在重复的游戏日常任务上吗?MaaYuan作为一款免费开源的…...

GluonCV版本升级指南:从0.8到0.11的10大新特性详解
GluonCV版本升级指南:从0.8到0.11的10大新特性详解 【免费下载链接】gluon-cv dmlc/gluon-cv: GluonCV 是由DMLC(Apache MXNet背后的社区)开发的一个计算机视觉库,为研究人员和工程师提供了大量预训练模型、基准测试和工具&#x…...

如何免费获取专业级多语言字体:Poppins字体完整使用秘籍
如何免费获取专业级多语言字体:Poppins字体完整使用秘籍 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins Poppins字体是一款完全开源免费的专业级几何无衬线字体&…...

PP-DocLayoutV3快速调用:10行Python代码实现文档解析
PP-DocLayoutV3快速调用:10行Python代码实现文档解析 你是不是经常遇到一堆扫描的PDF或者图片文档,想快速提取里面的文字、表格和图片,却不知道从何下手?手动整理不仅费时费力,还容易出错。今天,我就来分享…...

【笔试真题】- 阿里系列-2026.03.25-研发岗
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围在线刷题 bishipass.com 阿里系列-2026.03.25-研发岗 1. K小姐的仓位配货表 问题描述 说明:阿里系列近期多条业务线笔试题基本共用同一套公开机试,淘天、阿里云等方向都可参考本场。…...

基于vue+springboot框架的社区居民诊疗健康管理系统设计与实现
目录技术选型与架构设计核心功能模块划分开发阶段规划关键问题解决方案测试与部署文档规范项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与架构设计 前端框架:Vue 3(Composition APIÿ…...

页游党必看!传奇、篮球、策略全都有,点击即玩
对于喜欢玩网页游戏的朋友来说,找一个靠谱、福利多、游戏全的平台太重要了!不用下载、点击即玩,还能安心挂机不担心跑路,这样的平台才是真刚需~ 今天就给大家安利一个深耕页游十余载的老牌平台——602游戏平台&#x…...

OpenClaw浏览器自动化:Qwen3-VL:30B爬取图文数据到Notion
OpenClaw浏览器自动化:Qwen3-VL:30B爬取图文数据到Notion 1. 为什么需要自动化数据收集 上周我需要整理一批行业报告中的关键图表和结论,手动复制粘贴了3个小时后,突然意识到:这种重复性工作正是AI该解决的问题。于是我开始尝试…...

零基础玩转OpenClaw:星图GPU百川2-13B量化镜像体验报告
零基础玩转OpenClaw:星图GPU百川2-13B量化镜像体验报告 1. 为什么选择星图平台的OpenClaw镜像 作为一个长期关注AI工具但苦于本地配置复杂度的普通用户,当我发现星图平台提供预装OpenClaw和百川2-13B量化模型的"开箱即用"镜像时,…...
小白也可以安装成功!)
【2026 最新】 MySQL 数据库安装教程(超详细图文版-纯享版)小白也可以安装成功!
一、前言 MySQL 作为开源关系型数据库的标杆,广泛应用于 Web 开发、数据分析等场景,是程序员必备的基础工具之一。很多新手安装MySQL时都会陷入“版本选择困难症”——版本太高怕兼容出问题,版本太低又缺功能、不支持主流框架,甚…...