DRF-通用分页器(PageNumberPagination):ListModelMixin可以使用的通用分页器
一、ListModelMixin 和GenericAPIView源码
ListModelMixin 是一个单一功能类,必须配合GenericAPIView(或其子类)来一起使用,才能完成其视图的功能
class ListModelMixin:"""List a queryset."""def list(self, request, *args, **kwargs):#1、这里获取querysetqueryset = self.filter_queryset(self.get_queryset())#2、这里获取当前页的queryset数据,[<数据模型>]page = self.paginate_queryset(queryset)if page is not None:#3、对当前页的模型对象,进行序列化serializer = self.get_serializer(page, many=True)#4、获取到当前页的数据,里面整合了当前页的序列化数据return self.get_paginated_response(serializer.data)serializer = self.get_serializer(queryset, many=True)return Response(serializer.data)主要就按照:一步一步走就可以了,如果ListModelMixin没有的方法,就去GenericAPIView找
self.filter_queryset(self.get_queryset())--->self.paginate_queryset(queryset)-->self.get_serializer(page, many=True)-->self.get_paginated_response(serializer.data)
1、ListModelMixin : queryset = self.filter_queryset(self.get_queryset())
当前类是没有实现get_queryset和filter_queryset方法的,
配合GenericAPIView使用,调用的是GenericAPIView的get_queryset和filter_queryset方法
2、GenericAPIView: get_queryset, 拿到queryset对象
def get_queryset(self):queryset = self.querysetif isinstance(queryset, QuerySet):queryset = queryset.all()return queryset3、GenericAPIView:filter_queryset 这个是过滤器,没有配置就是空,没有做如何操作
4、GenericAPIView:paginate_queryset(queryset) :
4.1、GenericPAIView : paginator : 拿到配置的分页器类,返回分页器的实例化对象
@property
def paginator(self):if not hasattr(self, '_paginator'):if self.pagination_class is None:self._paginator = Noneelse:self._paginator = self.pagination_class()return self._paginator4.2、根据4.1,拿到的分页器对象,调用分页器的paginate_queryset 方法: 该方法就是返回当前页的queryset
def paginate_queryset(self, queryset):if self.paginator is None:return Nonereturn self.paginator.paginate_queryset(queryset, self.request, view=self)5、GenericAPIView: get_paginated_response 方法: 调用分页器对象的get_paginated_response
def get_paginated_response(self, data):assert self.paginator is not Nonereturn self.paginator.get_paginated_response(data)总结来说:
1、要满足第一个要求,符合ListModelMixin的功能,需要在自定义的分页器类中重写paginate_queryset和get_paginated_response
2、在start方法中,调用这两个方法
3、再开一个方法handle_data,在get_paginated_response中调用这个方法,后续重写handle_data来进行数据定制功能
二、自定义PageNumber的分页器
(1)自定义的基本分页器类
from rest_framework.pagination import PageNumberPaginationclass GenericPageNumberPagination(PageNumberPagination):page_size = 20page_query_param = 'page'page_size_query_param = 'page_size'max_page_size = page_size+(page_size//2)#重写父类的: 校验page_sizedef get_page_size(self, request):'''功能:校验page_size,没有传递或传递类型有问题时,按照默认的大小设置,超过最大页面大小时,设置成最大页面:param request::return: 数值'''page_size = request.GET.get(self.page_size_query_param)if not page_size:page_size = self.page_size #取的是类的page_sizeelse:try:page_size = int(page_size)except Exception:page_size = self.page_size #取的是类的page_sizeif page_size > self.max_page_size:page_size = self.max_page_size#给分页的实例对象赋值每页大小self.page_size = page_sizereturn self.page_size#自己定义: 校验pagedef get_page(self,request,queryset,page_size):'''功能:判断携带page是否合法,页码必须大于0,不能大于最大页数,页码必须是数值:param request: 当前请求对象:param queryset: 模型uqeryset:param page_size: 每页大小:return: None,{"error":'错误消息'},数值'''page = request.GET.get(self.page_query_param)if page == None:return Nonetry:page = int(page)self.page = page#判断查询的页码是否大于0if page <=0:self.page = {'error':'页码必须大于0','code':400}#总数据量self.count = len(queryset)##判断查询的数据是否有数据if self.count == 0:self.page = {'error':'查询不到相关数据','code':400}#总页数self.pages, has_number = divmod(self.count,page_size)if has_number:self.pages += 1## 判断查询的页码是否大于总页码if page > self.pages:self.page = {'error':f'查询的页码{page}大于总页码数{self.pages}','code':400}return self.pageexcept Exception:self.page = {'error':'页码必须是数值','code':400}return self.page#自定义的def has_next_page(self,page=None,pages = None):'''是否有下一页的数据:param page: 当前页:param pages: 总页数:return: 0或1'''if page == None:page = self.pageif pages == None:pages = self.pagesif page == 1:if pages <= 1:return 0else:return 1else:#page > 1if pages > page:return 1else:return 0#自定义的def has_previous_page(self,page=None,pages = None):'''功能:是否有上一页的数据:param page: 当前页:param pages: 总页数:return: 0或1'''if page == None:page = self.pageif pages == None:pages = self.pagesif pages <=1:return 0else:if page>1:return 1else:return 0#重写父类的: 获取当前页的QuerySet对象def paginate_queryset(self, queryset, request, view=None):'''功能:获取当前页的queryset对象:param queryset: 所有的queryset:param request: 当前请求:param view: 当前视图类:return: None,{’error‘:''}, QuerySet'''page_size = self.get_page_size(request)page = self.get_page(request,queryset,page_size)if isinstance(page,dict) or page == None:#page参数错误,没有传递page时return pagequeryset_len = len(queryset)if queryset_len == 0:return {'error':'查询不到相关数据','code':400}#1、总数据量,在get_page 中就设置了self.count = len(queryset)#2、总页数,在get_page 中就设置了self.pages, has_number = divmod(self.count, page_size)if has_number:self.pages += 1# 3、下一页self.next = self.has_next_page() # 有下一页,返回1,没有返回0# 4、上一页self.previous = self.has_next_page() # 有上一页时,返回1,没有返回0#5、当前页self.current_page = self.page#6、截取指定的数据if self.page == 1:self.queryset = queryset[:self.page_size]else:start = self.page_size*(self.page-1)end = self.page_size*(self.page)self.queryset = queryset[start:end]return self.queryset#重写父类的:将当前页的QuerySet对象序列化def get_paginated_response(self,page_queryset,serializer_class=None):'''功能:根据传递进来的dict,None(page没有传递,就不返回数据了),当前页的List,当前页QuerySet,:param page_queryset: dict,None,List,QuerySet:param serializer_class: 序列化器类:return: {}'''if isinstance(page_queryset,dict):#paginate_queryset的错误消息return page_querysetelif isinstance(page_queryset,list):data = {'code': 201,'msg': '获取数据成功','data': '', # 当前页数据'next': self.has_next_page(), # 是否有下一页'previous': self.has_previous_page(), # 是否有上一页'count': self.count, # 总数据量'pages': self.pages, # 总页码数'current_page': self.page, # 当前页码'page_size': self.page_size, # 每页大小}if serializer_class:#1、手动使用start方法调用时,page_ser = serializer_class(instance=page_queryset, many=True)page_data = page_ser.datadata['data'] = page_datareturn dataelse:#2、配合mixins.ListModelMixin源码使用, 其调用了paginate_queryset,拿到queryset对象,将序列化结果传递进来page_queryset = self.handle_data(page_queryset)data['data'] = page_querysetreturn dataelif page_queryset == None:return {'code':400,'error':'没有传递页码值'}else:raise Exception('分页器只支持,dict,list,QuerySet,None 类型')#自己定义的,对当前页数据,进一步的处理def handle_data(self,data_list):return data_list#手动调用时,获取结果的def start(self,request,serializer_class,queryset):#1、获取当前页的QuerySet对象page_queryset = self.paginate_queryset(queryset=queryset,request=request)if page_queryset == None:return {'code':400,'error':'页码必须携带'}if isinstance(page_queryset,dict):return page_queryset#2、将当前页的QuerySet对象传递进去,得到分页的响应结果page_data = self.get_paginated_response(page_queryset=page_queryset,serializer_class=serializer_class)return page_dataif __name__ == '__main__':'''mixins.ListModelMixin的调用逻辑:1、调用paginate_queryset2、1的返回值如果是None时,就不执行获取分页的数据,就去获取所有的数据返回3、1的返回值不为None时,就执行get_paginated_response,拿到分页的结果手动调用使用:data = page.start(request,序列化类,模型对象)'''(2)、使用
1、对于ListModelMixin,使用的逻辑是一样的,无需变化。
2、手动使用
page = GenericPageNumberPagination()
page_data = page.start(request,'序列化器类','数据库查询的queryset')
(3)、继承
对于需要特殊处理返回的数据时,可以继承分页器类,重写handle_data方法
class UserPageNumberPagination(GenericPageNumberPagination):def handle_data(self,data_list):for dic in data_list:dic['type'] = '患者'return data_list#使用
page = UserPageNumberPagination()
page_data = page.start(request,'序列化器类','数据库查询到关于用户的queryset')相关文章:
:ListModelMixin可以使用的通用分页器)
DRF-通用分页器(PageNumberPagination):ListModelMixin可以使用的通用分页器
一、ListModelMixin 和GenericAPIView源码 ListModelMixin 是一个单一功能类,必须配合GenericAPIView(或其子类)来一起使用,才能完成其视图的功能 class ListModelMixin:"""List a queryset."""d…...

移动机器人,开启智能柔性制造新篇章
智能制造是当今工业发展的必然趋势,而柔性制造则是智能制造的重要组成部分。在这个快速变革的时代,如何提高生产效率、降低成本、增强灵活性成为了制造业的关键挑战。富唯智能移动机器人应运而生,为柔性制造注入了新的活力。 基于富唯智能AI-…...
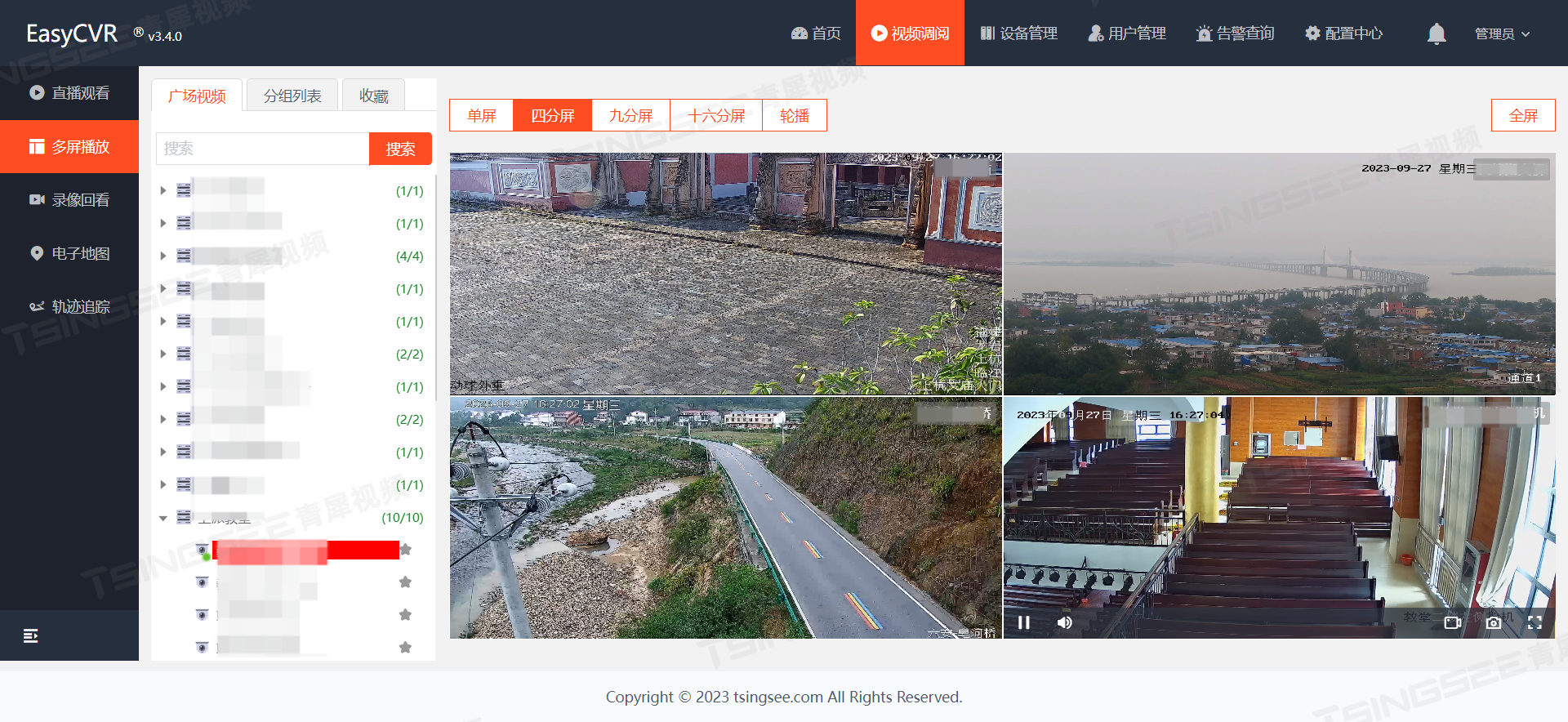
视频云存储EasyCVR平台国标接入获取通道设备未回复是什么原因?该如何解决?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...

【Web题】狼追兔问题
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

4-Docker命令之docker info
后续为大家逐个讲解一下docker常用命令及其相关用法。docker常用命令查看如下: [root@centos79 ~]# docker --helpUsage: docker [OPTIONS] COMMANDA self-sufficient runtime for containersCommon Commands:run Create and run a new container from an imageexec…...

QT 中的元对象系统
作为一名十几年的 C 程序员,最近一段时间使用 QT 开发程序,发现 QT 中还是有许多值得深入理解的技术。QT 不仅仅是一个应用程序开发框架,还有一些对标准 C 的扩充。本文和大家一起探讨 QT 中的元对象系统。 在分析 QT 中的元对象系统之前&…...
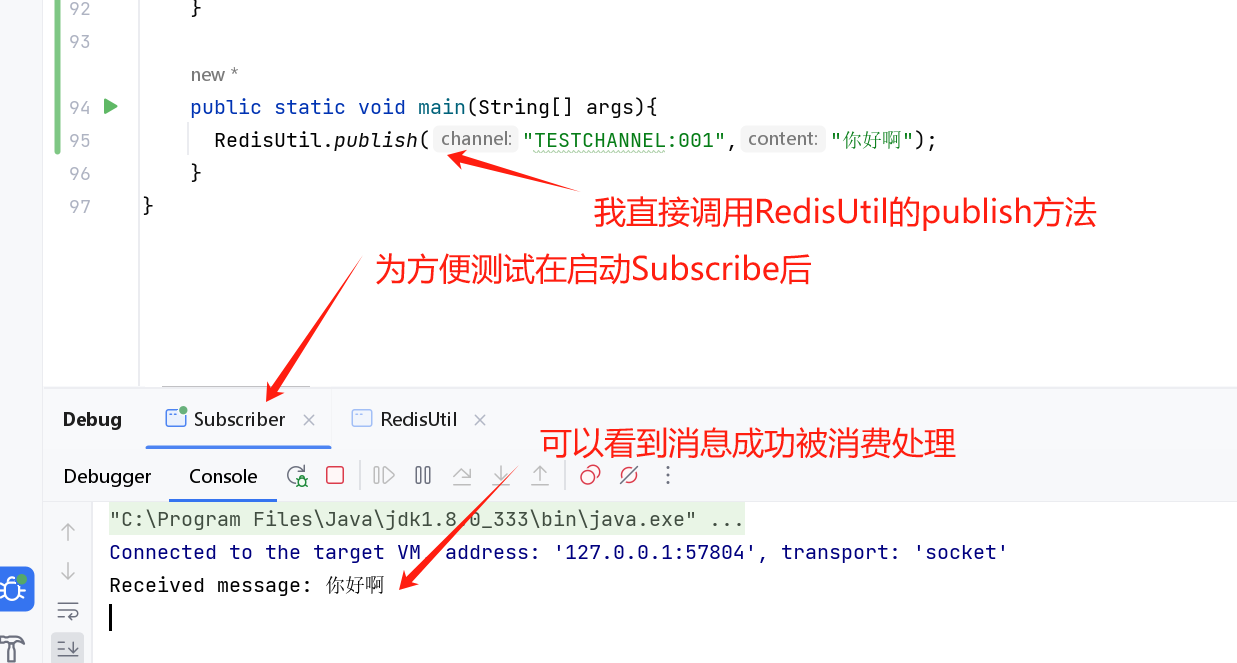
在两个java项目中实现Redis的发布订阅模式
如何在两个java项目中实现Redis的发布订阅模式? 1. Redis简介2. 发布订阅模式介绍3. 实现思路4. 代码实现及详细解释4.1. RedisUtil4.2. Publisher4.3. Subscriber4.4. 运行程序 目录: Redis简介发布订阅模式介绍实现思路代码实现及详细解释 1. Redis简…...

执行shell脚本提示syntax error: unexpected end of file
具体报错如下: ./test.sh: line 36: syntax error: unexpected end of file执行命令时需将test.sh替换为实际的脚本文件名称。 情形一: shell脚本在Windows下编写,上传到Linux上执行,由于 fileformat 类型不同,所以报…...

信也科技发布2023年Q3财报:数字金融服务业务增长稳健,持续拉动实体消费
11月21日,信也科技(NYSE:FINV)公布2023年第三季度未经审计的财务报告。财报显示,信也科技三季度在国内、国际市场延续稳健增长态势,实现季度营收31.98亿元(人民币,下同)&…...
Springcloud可视化物联网智慧工地云SaaS平台源码 支持二开和私有化部署
智慧工地平台围绕建筑施工人、物、事的安全管理为核心,对应研发了劳务实名制、视频监控、扬尘监测、起重机械安全监测、安全帽监测等功能一体化管理的解决方案。 智慧工地是聚焦工程施工现场,紧紧围绕人、机、料、法、环等关键要素,综合运用物…...

51单片机应用从零开始(七)·循环语句(if语句,swtich语句)
51单片机应用从零开始(一)-CSDN博客 51单片机应用从零开始(二)-CSDN博客 51单片机应用从零开始(三)-CSDN博客 51单片机应用从零开始(四)-CSDN博客 51单片机应用从零开始(…...

Web服务器(go net/http) 处理Get、Post请求
大家好 我是寸铁👊 总结了一篇Go Web服务器(go net/http) 处理Get、Post请求的文章✨ 喜欢的小伙伴可以点点关注 💝 前言 go http请求如何编写简单的函数去拿到前端的请求(Get和Post) 服务器(后端)接收到请求后,又是怎么处理请求,…...

Unity中颜色空间Gamma与Linear
文章目录 前言一、人眼对光照的自适应1、光照强度与人眼所见的关系2、巧合的是,早期的电子脉冲显示屏也符合这条曲线3、这两条曲线都巧合的符合 y x^2.2^(Gamma2.2空间) 二、Gamma矫正1、没矫正前,人眼看电子脉冲显示屏ÿ…...

Word/PPT/PDF怎么免费转为JPG图片?
1、打开金鸣表格文字识别网站。 2、点击导航条上的“软件下载” 3、安装并打开金鸣表格文字识别软件。 4、点击顶部导航栏的“文件转图片”。 5、选择需要转换成图片的文件(支持Word/PPT/PDF). 6、点“打开”程序将自动分页转换为图片。...

使用docker命令_进入容器_登录mysql服务_并执行sql语句---Docker工作笔记005
今天就用到了,不得不说用docker用到的还是少,记录一下,常用的也就这些吧. 首先执行: docker ps [root@localhost dataease-1.18.9]# docker ps CONTAINER ID IMAGE COMMAND CREATED …...
PMP 考试的含金量怎么样?
这里可以三个思考题和三个价值点帮你认识PMP考试。 三个思维题 1.工作环境 PMP证书含金量的一个很大因素,就是考证的人是否对PMP证书有比较强的实际需求。相反,如果只是听别人说,PMP证书很好,不管工作中是否有需要,…...

2023亚太杯数学建模A题思路代码分析
已经完成A题完整思路代码,文末名片查看获取 A题就是我们机器学习中的一个图像识别,他是水果图像识别,就是苹果识别的一个问题,我们用到的方法基本是使用深度学习中的卷积神经网络来进行识别和分类 问题一:基于附件1中…...
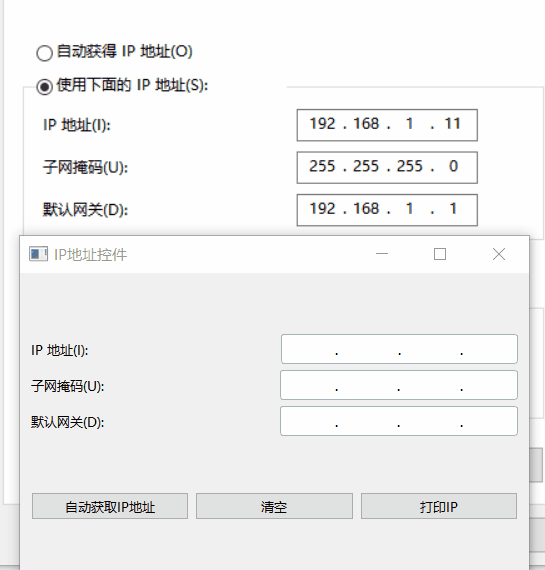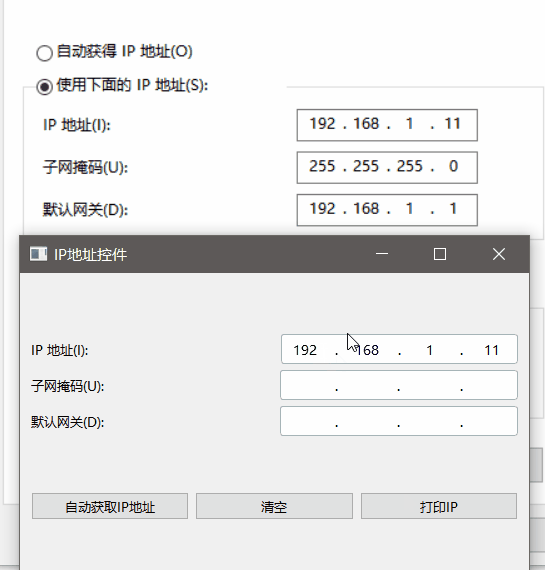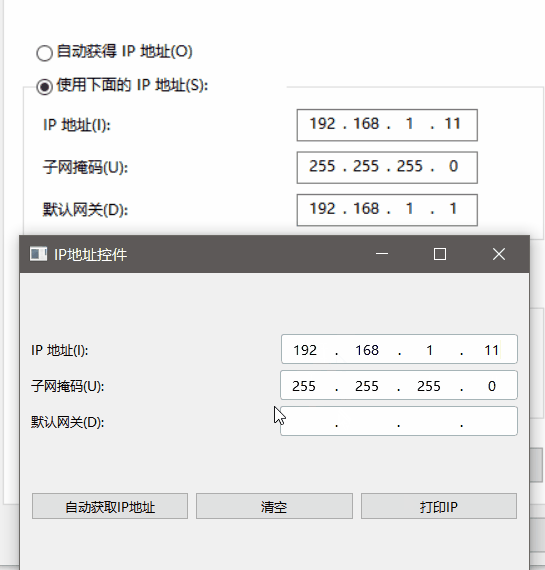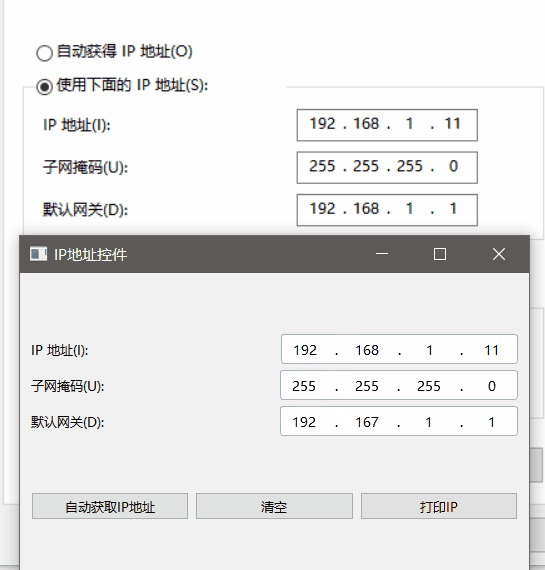
Qt实现自定义IP地址输入控件(百分百还原Windows 10网络地址输入框)
在开发网络相关的程序时,我们经常需要输入IP地址,例如源地址和目标地址。Qt提供了一些基础的控件,如QLineEdit,但是它们并不能满足我们对IP地址输入的要求,例如限制输入的格式、自动跳转到下一个输入框、处理回车和退格键等。因此,我们需要自己编写一个自定义的IP地址输入…...

Linux下的C++ socket编程实例
服务端: 服务器端先初始化socket,然后与端口绑定,对端口进行监听,调用accept阻塞,等待客户端连接。 socket() -> bind() -> listen() -> accept() 客户端: 客户端先初始化socket,然后…...
4.常见面试题--操作系统
特点:并发性、共享性、虚拟性、异步性。 Windows 和 Linux 内核差异 对于内核的架构⼀般有这三种类型: ● 宏内核,包含多个模块,整个内核像⼀个完整的程序; ● 微内核,有⼀个最⼩版本的内核࿰…...

终极静音方案:5步掌握FanControl免费风扇控制软件
终极静音方案:5步掌握FanControl免费风扇控制软件 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fan…...
避坑指南:Unity Sprite描边Shader的5个常见错误与优化技巧(附完整可运行代码)
Unity Sprite描边Shader深度优化:从原理到工业级解决方案 在2D游戏开发中,Sprite描边效果是提升视觉表现力的重要手段,但许多开发者都会遇到描边断裂、锯齿明显、性能低下等问题。本文将深入分析这些问题的根源,并提供一套完整的优…...

智能任务流引擎TaskFlow:Java并发编程与MCP集成的开发实践
1. 项目概述:一个为现代开发者打造的智能任务流引擎最近在折腾一个挺有意思的玩意儿,叫taskflow。这名字听起来平平无奇,对吧?市面上任务管理工具一抓一大把,从 Trello 到 Todoist,从 Jira 到 Notion 的看板…...

从医学诊断到风控模型:DeLong检验的‘跨界’应用指南,附R语言与Stata实操对比
从医学诊断到风控模型:DeLong检验的‘跨界’应用指南,附R语言与Stata实操对比 在数据科学领域,经典统计方法的跨学科迁移往往能带来意想不到的突破。1988年由DeLong等人提出的ROC曲线比较方法,最初用于评估卵巢癌诊断模型的性能差…...

终极Black性能基准:建立客观的Python代码格式化速度评估标准体系
终极Black性能基准:建立客观的Python代码格式化速度评估标准体系 【免费下载链接】black The uncompromising Python code formatter 项目地址: https://gitcode.com/GitHub_Trending/bl/black Black作为一款备受欢迎的Python代码格式化工具,以其…...

从‘tuple‘报错聊Python设计哲学:为什么字符串、整数也不能改?一份给进阶者的可变/不可变类型深度指南
从元组报错透视Python设计哲学:可变与不可变类型的本质思考 当你第一次在Python中尝试修改元组元素时,那个刺眼的TypeError: tuple object does not support item assignment错误可能让你困惑不已。但这不是一个简单的错误提示,而是Python设计…...
:单集群支撑500+异构边缘节点的实战验证)
Docker+WASM双引擎边缘架构设计(附eBPF流量调度代码):单集群支撑500+异构边缘节点的实战验证
更多请点击: https://intelliparadigm.com 第一章:DockerWASM双引擎边缘架构设计概览 在资源受限、低延迟敏感的边缘计算场景中,单一容器运行时已难以兼顾安全性、启动速度与跨平台兼容性。DockerWASM双引擎架构应运而生——它将 Docker 的成…...

3步掌控笔记本性能:GHelper让ROG设备告别噪音与高温困扰
3步掌控笔记本性能:GHelper让ROG设备告别噪音与高温困扰 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, …...

终极指南:如何用Genesis实现仿生肌肉模拟与生物力学控制
终极指南:如何用Genesis实现仿生肌肉模拟与生物力学控制 【免费下载链接】Genesis A generative world for general-purpose robotics & embodied AI learning. 项目地址: https://gitcode.com/GitHub_Trending/genesi/Genesis Genesis是一个强大的通用机…...
)
中文地址智能解析 API 实战指南(地址结构化一步到位)
在做博客或者个人站点时,经常会遇到一个问题:页面内容比较“硬”,缺少一点点灵性。尤其是在涉及表单填写、用户收货地址、资料管理等场景时,如果能把一整段地址自动拆分成结构化信息,不仅体验更好,也能减少…...