HuggingFace-利用BERT预训练模型实现中文情感分类(下游任务)
准备数据集
使用编码工具
首先需要加载编码工具,编码工具可以将抽象的文字转成数字,便于神经网络后续的处理,其代码如下:
# 定义数据集
from transformers import BertTokenizer, BertModel, AdamW
# 加载tokenizer
token = BertTokenizer.from_pretrained('bert-base-chinese')
print('token', token)
out:
token BertTokenizer(name_or_path=‘bert-base-chinese’, vocab_size=21128, model_max_length=512, is_fast=False, padding_side=‘right’, truncation_side=‘right’, special_tokens={‘unk_token’: ‘[UNK]’, ‘sep_token’: ‘[SEP]’, ‘pad_token’: ‘[PAD]’, ‘cls_token’: ‘[CLS]’, ‘mask_token’: ‘[MASK]’}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken(“[PAD]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken(“[UNK]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken(“[CLS]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken(“[SEP]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken(“[MASK]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
由上可知bert-base-chinese模型的字典中共有21128个词,编码器编码句子的最大长度为512个词,并且能够看到bert-base-chinese模型所使用的一些特殊符号,例如SEK,PAD等。
这里使用的编码工具是bert-base-chinese,编码工具和预训练模型往往是成对使用的,后续将使用同名的预训练语言模型作为backbone。
编码工具的试算
加载完成编码工具之后可以进行一次试算,观察编码工具的输入和输出,代码如下:
data = token.batch_encode_plus(batch_text_or_text_pairs=['关注博主,不迷路。','俺要带你上高速。'], truncation=True,padding='max_length',max_length=12,return_tensors='pt',return_length=True)
# 查看编码输出
for k,v in out.items():print(k,v.shape)
# 把编码还原成句子
print(token.decode(out['input_ids'][0]))
out:
input_ids torch.Size([2, 17])
token_type_ids torch.Size([2, 17])
length torch.Size([2])
attention_mask torch.Size([2, 17])
[CLS] 关 注 博 主 , 不 迷 路 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
[CLS] 俺 要 带 你 上 高 速 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
编码工具的参数说明
对于编码工具的使用,特别是参数值的含义可以参考下面的两段代码:
"""使用简单的编码"""
# 编码两个句子
out = tokenizer.encode(# 句子1text = sents[0],text_pair = sents[1],# 当句子长度大于max_length时进行截断truncation=True,# 一律补充pad到max_length长度padding = 'max_length',add_special_tokens = True,# 许多大模型的阶段也是使用512作为最终的max_lengthmax_length=30,return_tensors=None,
)
"""增强的编码函数"""
# 增强的编码函数
out = tokenizer.encode_plus(text = sents[0],text_pair = sents[1],#当句子长度大于max_length时进行截断操作truncation = True,#一律补零到max_length长度padding='max_length',max_length=30,add_special_tokens=True,#可以取值tf,pt,np,默认返回list--->tensorflow,pytorch,numpyreturn_tensors=None,#返回token_type_idsreturn_token_type_ids=True,#返回attention_maskreturn_attention_mask=True,#返回special_tokens_mask 特殊符号标识return_special_tokens_mask=True,#返回offset_mapping标识每个词的起始和结束位置---》这个参数只能BertTokenizerFast使用#return_offsets_mapping=True,#返回length 标识长度return_length=True
)
从上面的代码中的参数max_length=500可以看出经过编码后的句子的长度一定是12个词的长度。如果源句子超出则会进行截断,如果源句子不足则会进行填充PAD,其运行结果如下:
{'input_ids': tensor([[ 101, 1068, 3800, 1300, 712, 8024, 679, 6837, 6662, 511, 102, 0],[ 101, 939, 6206, 2372, 872, 677, 7770, 6862, 511, 102, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'length': tensor([11, 10]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]])}
input_ids torch.Size([2, 12])
token_type_ids torch.Size([2, 12])
length torch.Size([2])
attention_mask torch.Size([2, 12])
[CLS] 关 注 博 主 , 不 迷 路 。 [SEP] [PAD]
[CLS] 俺 要 带 你 上 高 速 。 [SEP] [PAD] [PAD]
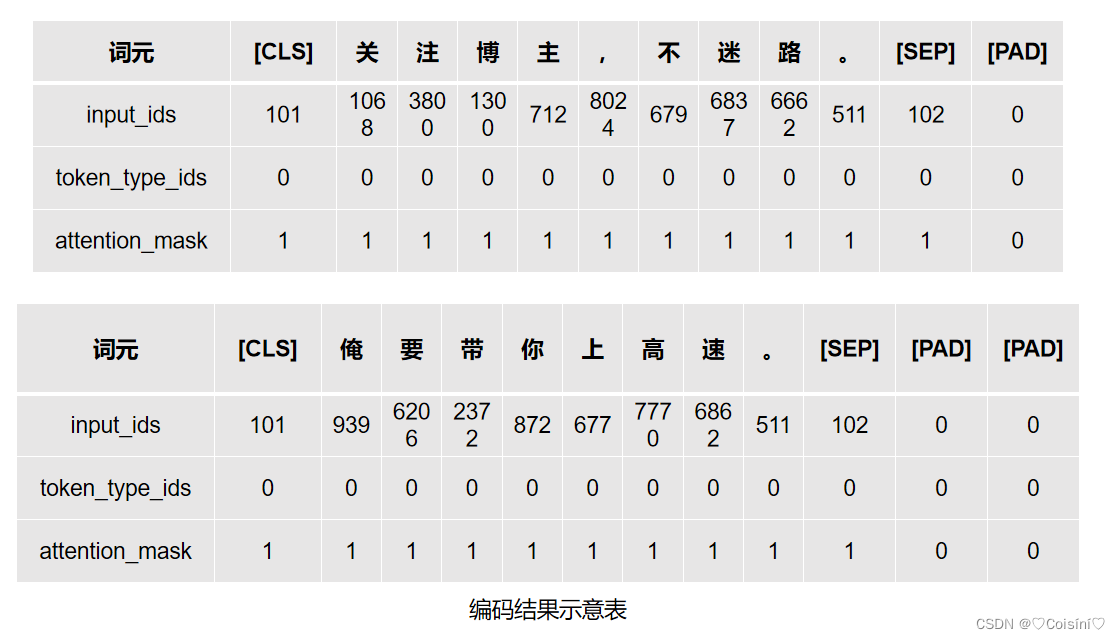
编码工具首先是对一条完整的句子进行了tokenizer,把句子分成了一个个token。同时,对于不同的编码工具,分词的结果也不一定一致。这里采用的bert-base-chinese编码工具中,它是以字为词,即把每个字当做一个词进行处理。
这些编码的结果对于预训练模型的计算十分重要,在后面将会使用编码器将所有的句子进行编码,用于输入到预训练模型中进行计算。
定义数据集
这里使用的数据集为ChnSentiCorp数据集,Dataset类如下:
# import torch
from datasets import load_dataset
class Dataset(torch.utils.data.Dataset):def __init__(self, split):self.dataset = load_dataset(path='lansinuote/ChnSentiCorp', split=split)def __len__(self):return len(self.dataset)def __getitem__(self, i):text = self.dataset[i]['text']label = self.dataset[i]['label']return text, label
dataset = Dataset('train')
print(len(dataset))
print(dataset[0])
在上述代码中加载了ChnSentiCorp数据集,并使用Pytorch中的Dataset对象进行封装,利用__getitem__()得到每一条数据,每条数据中包含text和labels两个字段,最后初始化训练数据集并查看训练数据集的长度和第一条数据样例。
out: 9600
('选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 1)
由上面的输出可知训练数据集包括9600条数据,每条数据包含一条评论文本和一个标识,表明这一条评论是好评还是差评。注意:这里的数据集是单纯的原始文本数据,并没有进行编码。
定义计算设备
这里将使用CUDA作为计算设备,这样可以极大加速模型的训练和测试的过程,代码如下:
device = 'cpu'
if torch.cuda.is_available():device = 'CUDA'
print('选用的计算设备:',device)
在该段代码中默认使用CPU进行计算,如果存在CUDA的话则选用CUDA作为计算设备。
定义数据整理函数
正如上面所述的那样,ChnSentiCorp数据集中的每一条数据是抽象的文本数据,并没有进行任何的编码操作,而预训练模型是需要编码之后的数据才能进行计算,所以需要一个将文本句子转成编码的过程。
另外,在训练模型时数据集往往很大,如果一条一条地处理则效率会太低,在现实中我们往往一批一批地处理数据,这样可以快速地处理数据集,同时从梯度下降的角度来讲,批数据的梯度方差相较于一条条数据的梯度小,可以让模型更加稳定地更新参数。
# 定义批处理函数
def collate_fn(data):sents = [i[0] for i in data]labels = [i[1] for i in data]# 编码data = token.batch_encode_plus(batch_text_or_text_pairs=sents, truncation=True,padding='max_length',max_length=500,return_tensors='pt',return_length=True)# input_ids:编码之后的数字# attention_masks:补0的位置都是0,其他位置都是1input_ids = data['input_ids']attention_mask = data['attention_mask']token_type_ids = data['token_type_ids']labels = torch.LongTensor(labels)# print(data['length'],data['length'].max())return input_ids, attention_mask, token_type_ids, labels在这段代码中,参数data表示一批数据,取出其中的句子和标识,它们都是list类型,在上述代码中会将两者分别赋给sents和labels,然后是使用编码器编码该批句子,在参数中将编码后的结果指定为固定的500个词的大小,与上面的例子同理超出500个词的部分会被截断(这里是通过truncation=True控制),同时少于500个词的句子会被[PAD]填充(这里主要是通过 padding='max_length'控制)。另外,在编码过程中通过 return_tensors='pt'参数,将编码后的结果返回torch中的tensor类型,免去了后面转换数据格式的麻烦(也就是说后面可以通过数据格式转换可以将‘tf’转成‘pt’格式)。
之后取出编码后的结果,并将labels也转成Pytorch中的Tensor格式,再把它们移动到之前已经定义好的计算设备device上,最后把这些数据全部返回,到这里数据整理函数的工作已经全部完成。
数据处理函数的例子
上述定义了数据处理函数,为了实验其效果也可使用下面的例子:(本用例已加狗头保命~)
data = [('选择新大的原因当然不是为了延毕。',1),('笔记本的内存确实小。',0),('宿舍没有风扇。其他都很好。',1),('今天才知道这本书还有第10000卷,真是太屌了。',1),('机器的背面似乎被撕了张什么标签,残胶还在。',0),('为什么有人在校园里尖叫,是疯了还是giao。',0)
]# 狗头保命版试算
input_ids,attention_mask,token_type_ids,labels = collate_fn(data)
print('input_ids.shape',input_ids.shape)
print('attention_mask.shape',attention_mask.shape)
print('token_type_ids.shape',token_type_ids.shape)
print('labels:',labels)
在该段代码中首先是模拟了一批数据,这批数据中包含4个句子,通过将该批数据输入到整理函数以后,运行结果如下:
input_ids.shape torch.Size([6, 500])
attention_mask.shape torch.Size([6, 500])
token_type_ids.shape torch.Size([6, 500])
labels: tensor([1, 0, 1, 1, 0, 0])
可见编码之后的结果都是确定的500个词的长度,并且每个结果都会被移动到可用的计算设备上,这样可以方便后续的计算。
定义数据加载器
上述代码中定义了数据集和数据整理函数以后,下面我们将定义一个数据加载器DataLoader,它可以使用数据整理函数来完成成批地处理数据集中的数据,通俗来讲每一批的数据我们可以称为batch。
# 定义数据加载器并查看数据样例
loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=16,collate_fn=collate_fn,shuffle=True,drop_last=True)
对于上述代码,我们使用了Pytorch提供的工具类定义数据集加载器,其参数说明可参考下图:

数据加载器的例子
为了更好地使用数据加载器,这里我们查看一批数据样例,将这批数据输入到数据加载器中,可以发现其结果会与数据整理函数的运行结果相似,只不过是句子的数量增多了。
上述代码依次打印了加载器中批次数目、加载器中输入数据的input_ids和掩蔽注意力的形状
attention_mask_shape、词元的ids类型形状token_type_ids_shape以及标签labels
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader):break
print(len(loader))
print('input_ids', input_ids)
print('attention_mask_shape', attention_mask.shape)
print('token_type_ids_shape', token_type_ids.shape)
print('labels', labels)
- input_ids 就是编码后的词
- token_type_ids 第一个句子和特殊符号的位置是0,第二个句子的位置是1
- attention_mask pad的位置是0,其他位置都是1
- special_tokens_mask 特殊符号的位置是1,其他位置都是0
定义模型
因为我们是要利用Huggingface的预训练语言模型,所以需要做两件事情:加载预训练模型PLM以及定义下游任务模型。
加载预训练模型
这里使用的BERT预训练模型,模型名称为bert-base-chinese,这里的名称和编码器的名称是一致的,因为往往模型和其编码工具配套使用。另外,BERT模型不是必须的模型,进行中文情感分类也可以使用其他支持中文的模型,例如BART等。
from transformers import BertModel
# 加载预训练模型
pretrained = BertModel.from_pretrained('bert-base-chinese')
# 统计参数量
sum(i.numel() for i in pretrained.parameters()) / 10000
out:10226.7648
由上可知bert-base-chinese模型的参数量超过1亿个,这个模型的体量还是比较大的。由于它的体量比较大,所以如果要训练它,对计算资源的要求较高,而对于本次的二分类任务则可以选择不训练它,只是作为一个特征提取器。这样就可以避免训练这个笨重的模型,不需要计算它的梯度,进而不更新它的参数,所以需要冻结它的参数:
# 当不进行训练时不需要计算梯度
for param in pretrained.parameters():param.requires_grad_(False)
定义好PLM后,需要进行一次试算,观察模型的输入和输出结果:
# 设定计算设备
pretrained.to(device)
# 模型试算
out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
print(out.last_hidden_state.shape)
这里可能会报错:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select)
这是因为之前我们忘了将input_ids等参数放到cuda上,所以需要改一下代码:
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader):break
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
token_type_ids = token_type_ids.to(device)
labels = labels.to(device)
print(len(loader))
print('input_ids', input_ids)
print('attention_mask_shape', attention_mask.shape)
print('token_type_ids_shape', token_type_ids.shape)
print('labels', labels)
print(input_ids.is_cuda)
这里如果有显卡的话会输出True,然后上面的程序报错也会消除,同时输出:
torch.Size([16, 500, 768])
上述代码中将我们的16个样例数据(在定义数据加载器部分)输入到预训练模型中,得到的计算结果和我们预想的是一致的。首先从第一个维度16可以看出是和我们的样例输入的句子数量有关的,随后的500是指每句话中包含了500个单词,因为max_length=500(在数据整理函数中定义),这就把之前所有的内容都串起来了。最后的768表示将每一个词抽成一个768维的向量。到此为止,我们已经通过预训练模型成功地把16句话转换成为了一个特征向量矩阵,这样就可以接入下面的下游任务模型做分类或者回归任务。
定义下游任务模型
下游任务模型的任务是对backbone抽取的特征进行进一步的计算,得到符合业务需求的计算结果,这里做的是一个二分类的结果,因为我们数据集中的labels只有两种。
# 定义下游任务模型
class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.fc = torch.nn.Linear(768, 2).to(device)def forward(self, input_ids, attention_mask, token_type_ids):with torch.no_grad():out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)out = self.fc(out.last_hidden_state[:, 0])out = out.softmax(dim=1)return outmodel = Model()
# 设置计算设备
model.to(device)
在这段代码中,定义了一个下游任务模型,该模型包括一个全连接的LinearModel,权重矩阵是768x2,所以它能够将一个768维度的向量转换成一个二维空间中。
上述的下游任务模型的计算流程为:
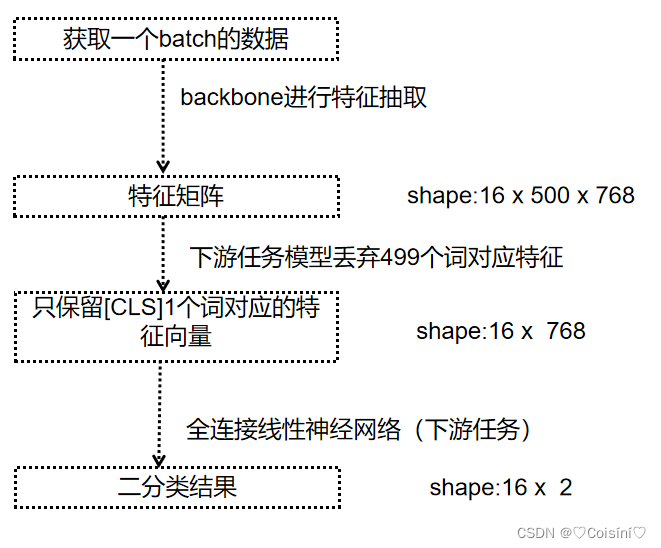
这里之所以丢弃后面466个词的特征,是因为BERT模型所致,具体的内容可以参考BERT模型的论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
下游任务模型试算
在最后我们使用刚才使用的batch=16的数据进行试算:
# 试算
print(model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids).shape)
其输出结果为:
torch.Size([16, 2])
由此可见这就是我们一开始所要求的16句话进行二分类的结果。
训练和测试
模型训练
模型定义完成之后,我们就可以对该模型进行训练了~代码如下:
from transformers import AdamW
from transformers.optimization import get_scheduler
def train():# 定义优化器optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4)# 定义损失函数criterion = torch.nn.CrossEntropyLoss()# 定义学习率调节器scheduler = get_scheduler(name='linear',num_warmup_steps=0,num_training_steps=len(loader),optimizer=optimizer)# 将模型切换到训练模式model.train()# 按批次进行遍历训练数据集中的数据for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader):input_ids = input_ids.to(device)attention_mask = attention_mask.to(device)token_type_ids = token_type_ids.to(device)labels = labels.to(device)# 模型计算out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids).to(device)# 计算损失并使用梯度下降法优化模型参数loss = criterion(out, labels)loss.backward()optimizer.step()scheduler.step()optimizer.zero_grad()# 输出各项数据的情况,便于观察if i % 10 == 0:out = out.argmax(dim=1)accuracy = (out == labels).sum().item() / len(labels)lr = optimizer.state_dict()['param_groups'][0]['lr']print(i, loss.item(),lr, accuracy)
train()
在上述的代码中首先定义了优化器、损失函数、学习率调节器。其中优化器使用了HuggingFace提供的AdamW优化器,这是传统的Adam优化器的改进版本,在自然语言处理任务中,该优化器往往取得了比Adam优化器更加好的成绩,并且计算效率高。学习率调节器使用了HuggingFace提供的线性学习率调节器,它能够在训练过程中让学习率缓慢下降,而不是始终使用一致的学习率,因为在训练的后期阶段往往需要更小的学习率来微调参数,有利于损失函数下降到最低点。这里的损失函数采用了分类任务中常用的CrossEntropyLoss交叉熵损失函数。
然后将下游任务模型切换到训练模式即可开始训练。最后每当优化10次模型参数时,就计算一次当前模型预测结果的正确率,并输出模型的损失函数、学习率,最终训练完毕的结果如下所示:

由上图可见在训练到大约200个steps时,模型已经能够达到85%左右的正确率,损失函数也如同预期一样随着训练过程不断下降,学习率亦如此。
模型测试
对于已经训练好的模型进行测试,以便验证训练的有效性,其测试代码如下:
def test():# 定义测试数据加载器loader_test = torch.utils.data.DataLoader(dataset = Dataset('test'),batch_size = 32,collate_fn = collate_fn,shuffle = True,drop_last = True)# 将下游任务模型切换到运行模式model.eval()correct = 0total = 0for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader_test):# 计算5个批次即可,不需要全部遍历input_ids = input_ids.to(device)attention_mask = attention_mask.to(device)token_type_ids = token_type_ids.to(device) labels = labels.to(device) if i == 5:breakprint(i)# 计算with torch.no_grad():out = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids).to(device)# 统计正确率out = out.argmax(dim=1)correct += (out==labels).sum().item()total += len(labels)print(correct/total)test()
在上述的代码中首先定义了测试数据集及其加载器,同时取出5个批次的数据让模型进行预测,最后将统计的正确率输出,运行结果为:
0
1
2
3
4
0.88125
最终模型取得了88.125%的正确率,这个正确率虽然不是很高,但是验证了下游任务模型即使在不训练basebone的情况下也可以达到一定的成绩。
省流版-全部代码

总结
本文通过一个情感分类的例子说明了使用BERT预训练模型抽取文本特征数据的方法,使用BERT作为backbone,相对于传统的RNN而言其计算量会稍稍大一些,但是BERT抽取的文本特征将更加完整,更容易被下游任务模型识别总结出数据之间的规律。所以在不对BERT预训练模型进行训练,而是简单应用于下游任务时也可以表现一个比较好的结果。

相关文章:
HuggingFace-利用BERT预训练模型实现中文情感分类(下游任务)
准备数据集 使用编码工具 首先需要加载编码工具,编码工具可以将抽象的文字转成数字,便于神经网络后续的处理,其代码如下: # 定义数据集 from transformers import BertTokenizer, BertModel, AdamW # 加载tokenizer token Ber…...
PSP - 从头搭建 抗原类别 (GPCR) 的 蛋白质结构预测 项目流程
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/134595717 GPCRs(G Protein-Coupled Receptors,G蛋白偶联受体),又称为7次跨膜受体,是细…...

城市NOA加速落地,景联文科技高质量数据标注助力感知系统升级
当前,自动驾驶技术的演进正在经历着从基础L2到L3过渡的重要阶段,其中NOA(自动辅助导航驾驶)扮演着至关重要的角色。城市NOA(L2.9)作为城市场景下的NOA,被看作是车企向更高阶自动驾驶迈进的必经之…...
是什么?)
控制反转(IoC)是什么?
文章目录 控制反转(Inversion of Control,IoC)传统的程序设计中:应用程序控制程序流程控制反转设计中:由框架或容器控制程序流程IoC 的作用 举例生活例子软件工程例子 控制反转(Inversion of Control&#…...

Redisson分布式锁源码解析、集群环境存在的问题
一、使用Redisson步骤 Redisson各个锁基本所用Redisson各个锁基本所用Redisson各个锁基本所用 二、源码解析 lock锁 1) 基本思想: lock有两种方法 一种是空参 另一种是带参 * 空参方法:会默认调用看门狗的过期时间30*1000&…...

2016年10月4日 Go生态洞察:HTTP追踪介绍
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

分布式篇---第四篇
系列文章目录 文章目录 系列文章目录前言一、分布式ID生成有几种方案?二、幂等解决方法有哪些?三、常见负载均衡算法有哪些?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给…...
从零开始的C++(十九)
红黑树: 一种接近平衡的二叉树,平衡程度低于搜索二叉树。 特点: 1.根节点为黑 2.黑色结点的子结点可以是红色结点或黑色结点。 3.红色结点的子结点只能是黑色结点。 4.每个结点到其所有叶子结点的路径的黑色结点个数相同。 5.指向空的…...
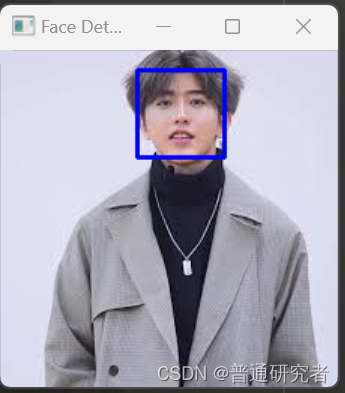
opencv-使用 Haar 分类器进行面部检测
Haar 分类器是一种用于对象检测的方法,最常见的应用之一是面部检测。Haar 分类器基于Haar-like 特征,这些特征可以通过计算图像中的积分图来高效地计算。 在OpenCV中,Haar 分类器被广泛用于面部检测。以下是一个简单的使用OpenCV进行面部检测…...

C++纯虚函数和抽象类 制作饮品案例(涉及知识点:继承,多态,实例化继承抽象类的子类,多文件实现项目)
一.纯虚函数的由来 在多态中,通常父类中虚函数的实现是毫无意义的,主要都是调用子类重写的内容。例如: #include<iostream>using namespace std;class AbstractCalculator { public:int m_Num1;int m_Num2;virtual int getResult(){r…...

什么是网关和链路追踪,以及怎么使用?
在云计算中,网关和链路追踪也是非常重要的。云服务提供商通常会提供网关和链路追踪等相关服务来帮助用户管理和优化云计算网络。 云计算中的网关通常包括以下几种: 虚拟网络网关:用于将云中不同虚拟网络之间相互连接,实现云内不同…...

git 文件被莫名其妙的或略且无论如何都查不到哪个.gitignore文件忽略的
先说解决办法:git check-ignore -v [文件路径] 这个命令会返回一个忽略规则,以及该规则在哪个文件中定义的,该规则使得指定的文件被忽略。 1.遇到的问题 同项目组,其他同学都可以正常的提交.meta文件,我的提交就出现以…...
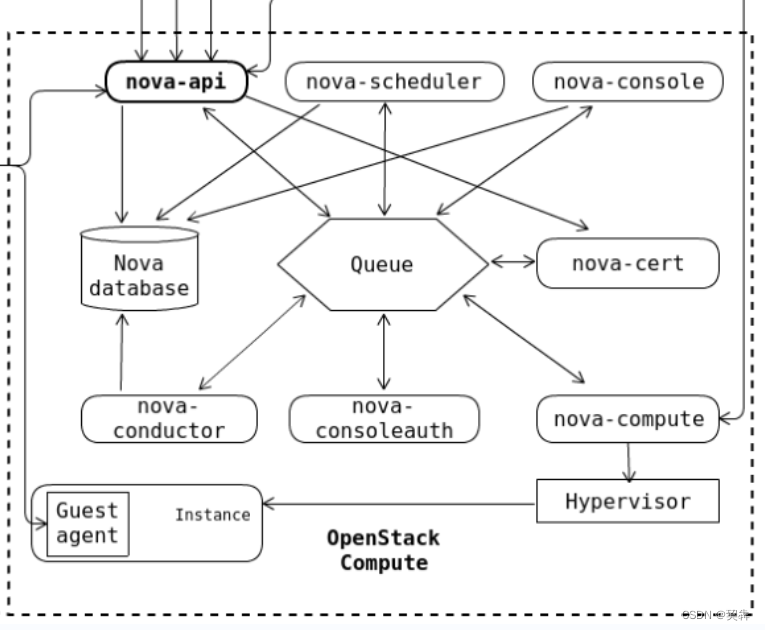
nova组件简介
目录 组件关系图 controller节点 openstack-nova-api.service: openstack-nova-conductor.service: openstack-nova-consoleauth.service: openstack-nova-novncproxy.service: openstack-nova-scheduler.service: openstack-nova-conductor.service详解 作用和功能&…...

【Vue】响应式与数据劫持
Vue.js 是一个渐进式的 JavaScript 框架,其中最重要的一个特性就是响应式(Reactivity)。Vue 借助数据劫持(Data Observation)技术实现了对数据的响应式更新,当数据发生变化时,它会自动重新渲染视…...

Modbus RTU转Profinet网关连接PLC与变频器通讯在机床上应用案例
背景:以前在机床加工车间里,工人们忙碌地操作着各种机床设备。为了使整个生产过程更加高效、流畅,进行智能化改造。 方案:在机床上,PLC通过Modbus RTU转Profinet网关连接变频器进行通讯:PLC作为整个生产线…...

Autoware 整体架构
Autoware 整体架构 测试...

【maven】手动指定jar推送
说明 为了推送第三方的jar,有时需要指定对应的jar推送到私有仓库。 示例 mvn deploy:deploy-file --settings /home/xxx/.m2/settings.xml -DgroupIdgroupId的值 -DartifactIdartifactId的值 -Dversionjar包的版本号 -Dpackagingjar -Dfilejar的路径 -Durlhttp:/…...

算法---定长子串中元音的最大数目
题目 给你字符串 s 和整数 k 。 请返回字符串 s 中长度为 k 的单个子字符串中可能包含的最大元音字母数。 英文中的 元音字母 为(a, e, i, o, u)。 示例 1: 输入:s “abciiidef”, k 3 输出:3 解释:…...
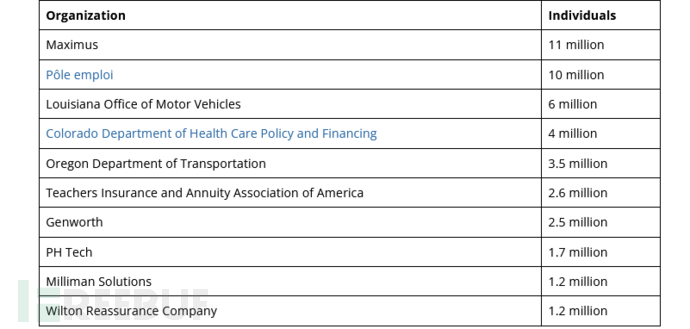
美国汽车零部件巨头 AutoZone 遭遇网络攻击
Security Affairs 网站披露,美国汽车配件零售商巨头 AutoZone 称其成为了 Clop MOVEit 文件传输网络攻击的受害者,导致大量数据泄露。 AutoZone 是美国最大的汽车零配件售后市场经销商之一,在美国、墨西哥、波多黎各、巴西和美属维尔京群岛经…...

WPF面试题入门篇
入门篇[2] 1. 谈谈什么是WPF? WPF(Windows Presentation Foundation)是微软公司开发的一种用于创建Windows应用程序的用户界面框架。它是.NET Framework的一部分,提供了一种基于XAML(可扩展应用程序标记语言…...
)
【2026量子开发必装插件】:VSCode原生支持Q# v1.4+、OpenQASM 4.0与Quil 3.2高亮(仅限前2000名获微软量子实验室白名单认证)
更多请点击: https://intelliparadigm.com 第一章:VSCode 2026量子编程语法高亮概览 VSCode 2026 引入了原生支持量子编程语言(Q#、OpenQASM 3.0、Quil)的语法高亮引擎,基于 LSP 1.20 协议与量子语义分析器深度集成&a…...
【浩博电池】)
机器人锂电池完整方案(选型 + 设计 + 厂家推荐)【浩博电池】
机器人锂电池完整方案(选型 设计 厂家推荐)机器人锂电池是机器人系统的核心动力单元,直接影响设备的续航能力、运动性能、安全性与稳定性。不同类型机器人(AGV、巡检机器人、四足机器人、服务机器人、消防机器人等)对…...

AgentBench:大语言模型智能体综合评估平台深度解析与实践指南
1. 项目概述:AgentBench是什么,以及它为何重要如果你最近在关注大语言模型(LLM)和智能体(Agent)领域,大概率已经听过“THUDM/AgentBench”这个名字。这不仅仅是一个GitHub上的开源项目ÿ…...

Qwen3-ForcedAligner-0.6B多场景应用:在线教育录播课自动生成知识点时间戳
Qwen3-ForcedAligner-0.6B多场景应用:在线教育录播课自动生成知识点时间戳 你有没有遇到过这种情况?给学生上完一节录播课,想整理出这节课的知识点时间轴,方便学生快速定位重点内容。结果发现,要手动听完一小时的课程…...
:GPU显存泄漏排查效率下降65%?一文掌握3种LLM训练场景下的精准定位法)
CUDA 13内存模型重大变更(Unified Virtual Memory默认启用):GPU显存泄漏排查效率下降65%?一文掌握3种LLM训练场景下的精准定位法
更多请点击: https://intelliparadigm.com 第一章:CUDA 13内存模型演进与Unified Virtual Memory本质解析 CUDA 13 对统一虚拟内存(Unified Virtual Memory, UVM)进行了关键性增强,核心在于将 GPU 内存管理从显式分页…...
)
AI算子上线即崩?揭秘CUDA 13生产集群中93%隐性PTX兼容性故障的3层诊断法(含cuobjdump逆向校验脚本)
更多请点击: https://intelliparadigm.com 第一章:AI算子上线即崩?揭秘CUDA 13生产集群中93%隐性PTX兼容性故障的3层诊断法(含cuobjdump逆向校验脚本) 当AI算子在CUDA 13.2集群中突然触发cudaErrorInvalidPtx或静默降…...

基于PPO与CNN的DoomNet:从像素输入到游戏AI的深度强化学习实战
1. 项目概述:DoomNet,一个基于像素的强化学习智能体如果你对游戏AI或者深度强化学习感兴趣,那你大概率听说过DeepMind的Atari游戏AI,或者OpenAI的Dota 2智能体。这些项目通常需要庞大的计算资源和复杂的工程架构。今天我想分享一个…...

量子误差缓解NIL框架:原理、实现与应用
1. 量子误差缓解与NIL框架概述量子计算硬件在近期内仍将受到噪声的严重影响,这使得量子误差缓解(QEM)技术成为实现实用量子算法的关键。传统QEM方法如零噪声外推(ZNE)和概率误差消除(PEC)虽然有…...

C++网关吞吐量卡在8GB/s?教你用NUMA绑定+SIMD解析+RingBuffer批处理突破硬件瓶颈
更多请点击: https://intelliparadigm.com 第一章:C高吞吐量MCP网关的设计目标与性能瓶颈全景 核心设计目标 高吞吐量MCP(Message Control Protocol)网关需在微秒级延迟约束下支撑每秒百万级消息路由,同时保障端到端…...

量子-经典混合计算框架在PDE求解中的应用
1. 量子与经典计算融合框架概述 偏微分方程(PDE)求解一直是科学计算领域的核心挑战。从流体力学到材料科学,高分辨率PDE模拟往往需要消耗巨大的计算资源,特别是当需要同时考虑精细空间分辨率和长时间积分时。传统数值方法如有限差分、有限元和谱方法虽然…...