urllib之urlopen和urlretrieve的headers传入以及parse、urlparse、urlsplit的使用
urllib库是什么?
urllib库python的一个最基本的网络请求库,不需要安装任何依赖库就可以导入使用。它可以模拟浏览器想目标服务器发起请求,并可以保存服务器返回的数据。
urllib库的使用:
1、request.urlopen
(1)只能传入url的方式
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.baidu.com"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}response = request.urlopen(url) # type: HTTPResponseprint(response.read().decode("utf-8"))(2) 传入Request对象和headers的方式
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.baidu.com"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}req = Request(url, headers=headers)response = request.urlopen(req) # type: HTTPResponseprint(response.read().decode("utf-8"))
2、request.urlretrieve
(1)简单使用,不能传入headers,只能传入url和保存的路径的方式
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.baidu.com"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}# req = Request(url, headers=headers)
#
# response = request.urlopen(req) # type: HTTPResponse
#
# print(response.read().decode("utf-8"))request.urlretrieve(url, "baidu.html")
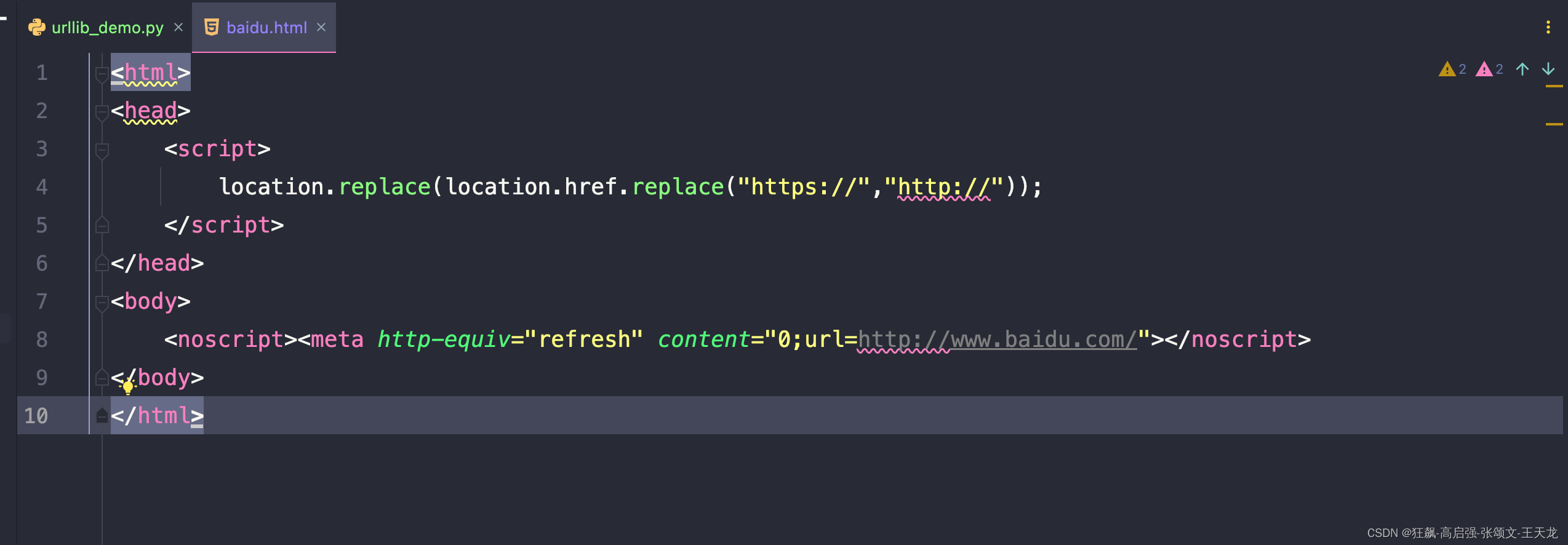
(2)复杂使用,可以传入headers,传入url和保存的路径的方式
from urllib import requesturl = "https://www.baidu.com"
opener = request.build_opener()
opener.addheaders = ([("User-Agent","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")])request.install_opener(opener)request.urlretrieve(url, "baidu.html")

额外的信息:
1、response的content-length
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.kuwo.cn/comment?type=get_comment&f=web&page=1&rows=5&digest=2&sid=93&uid=0&prod=newWeb&httpsStatus=1"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponsemeta = response.info()
# content-type
print(meta.get_content_type())
# content_charset
print(meta.get_content_charset())
# Content-Length
print(meta.get_all("Content-Length"))
print(response.getheader("Content-Length"))
urllib之parse模块的使用:
编码和解码
from urllib import parsedata = {"name": "王五","age": 31,"sex": "男","address": "北京市昌平区"
}# 参数编码
qs = parse.urlencode(data)
print(qs)# 解码
my_data = parse.parse_qs(qs)
print(my_data)
quote
起因:
在请求的url中,如果有汉字、空格或者特殊字符的时候,浏览器默认会将该字符进行urlencode()的处理,这样就可以正常的访问了!!!
代码实现:
错误代码:
from http.client import HTTPResponse
from urllib import parse, request
from urllib.request import Requesturl = "https://www.baidu.com/s?wd=%E6%9D%8E%E4%B8%80%E6%A1%90"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
# print(response.read().decode("utf-8"))url = "https://www.baidu.com/s?wd=李一桐"
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
print(response.read().decode("utf-8"))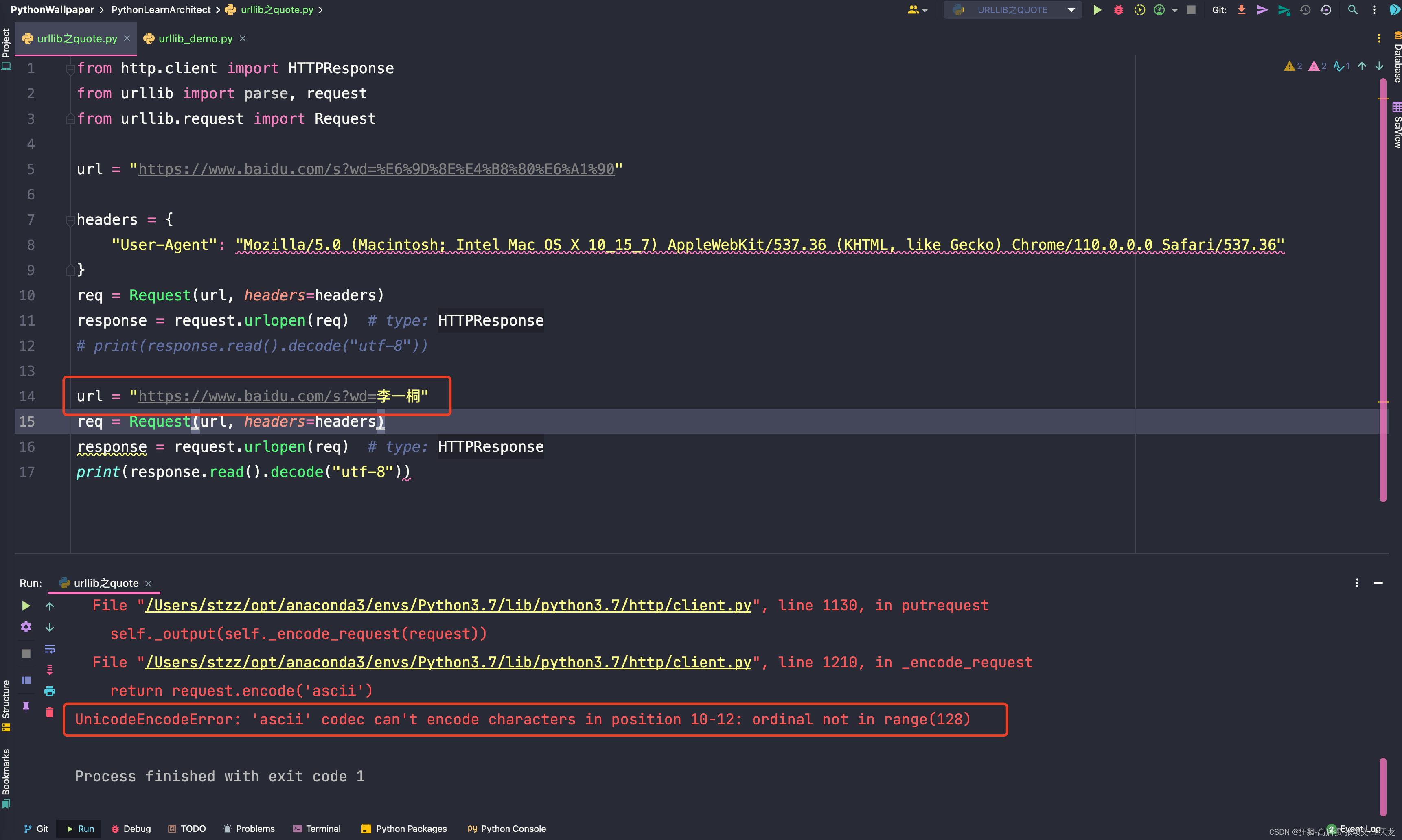
正确的代码:
from http.client import HTTPResponse
from urllib import parse, request
from urllib.request import Requesturl = "https://www.baidu.com/s?wd=%E6%9D%8E%E4%B8%80%E6%A1%90"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
# print(response.read().decode("utf-8"))url = "https://www.baidu.com/s?wd="
url = url + parse.quote("李一桐")
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
print(response.read().decode("utf-8"))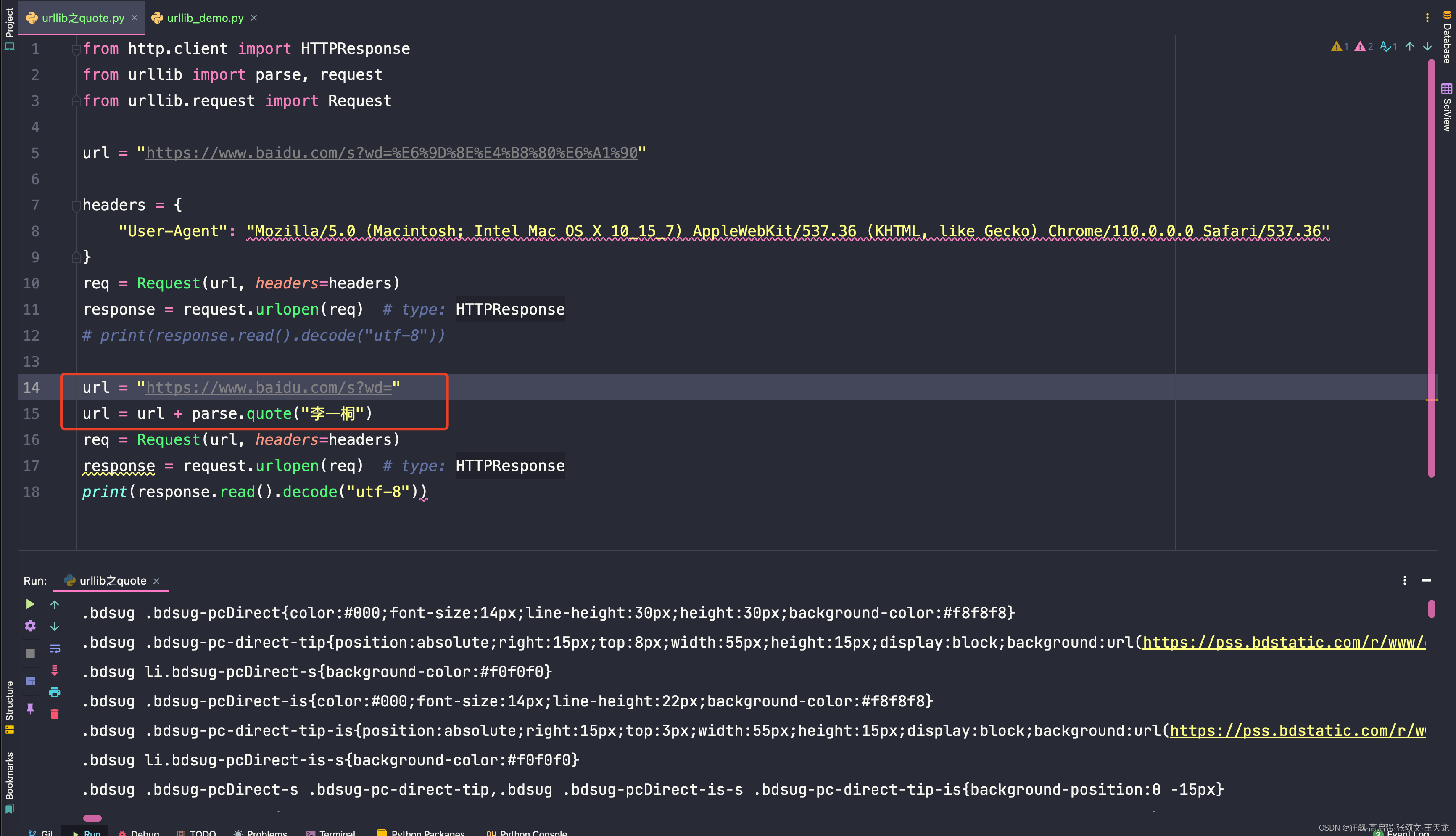
urlparse、urlsplit的使用:
from urllib import parseurl = "https://www.baidu.com/login/title?id=123456&wd=hello#nav"
result = parse.urlparse(url)
print(result)
print("*" * 140)
print(result.scheme)
print(result.netloc)
print(result.path)
print(result.params)
print(result.fragment)
print(result.hostname)
print(result.port)print("*" * 140)result = parse.urlsplit(url)
print(result.scheme)
print(result.netloc)
print(result.path)
print(result.fragment)
print(result.hostname)
print(result.port)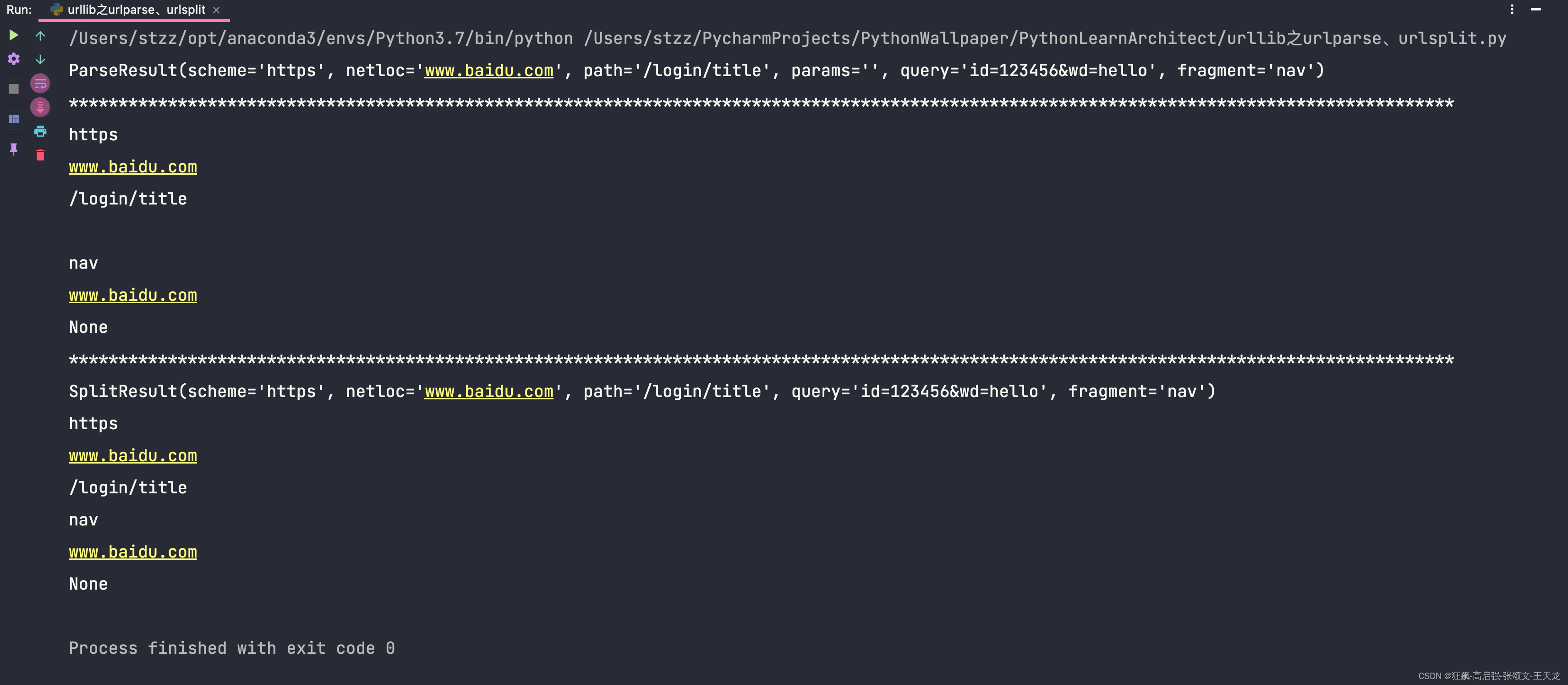
相关文章:
urllib之urlopen和urlretrieve的headers传入以及parse、urlparse、urlsplit的使用
urllib库是什么?urllib库python的一个最基本的网络请求库,不需要安装任何依赖库就可以导入使用。它可以模拟浏览器想目标服务器发起请求,并可以保存服务器返回的数据。urllib库的使用:1、request.urlopen(1)只能传入url的方式from http.clie…...
【C++】二叉搜索树的模拟实现
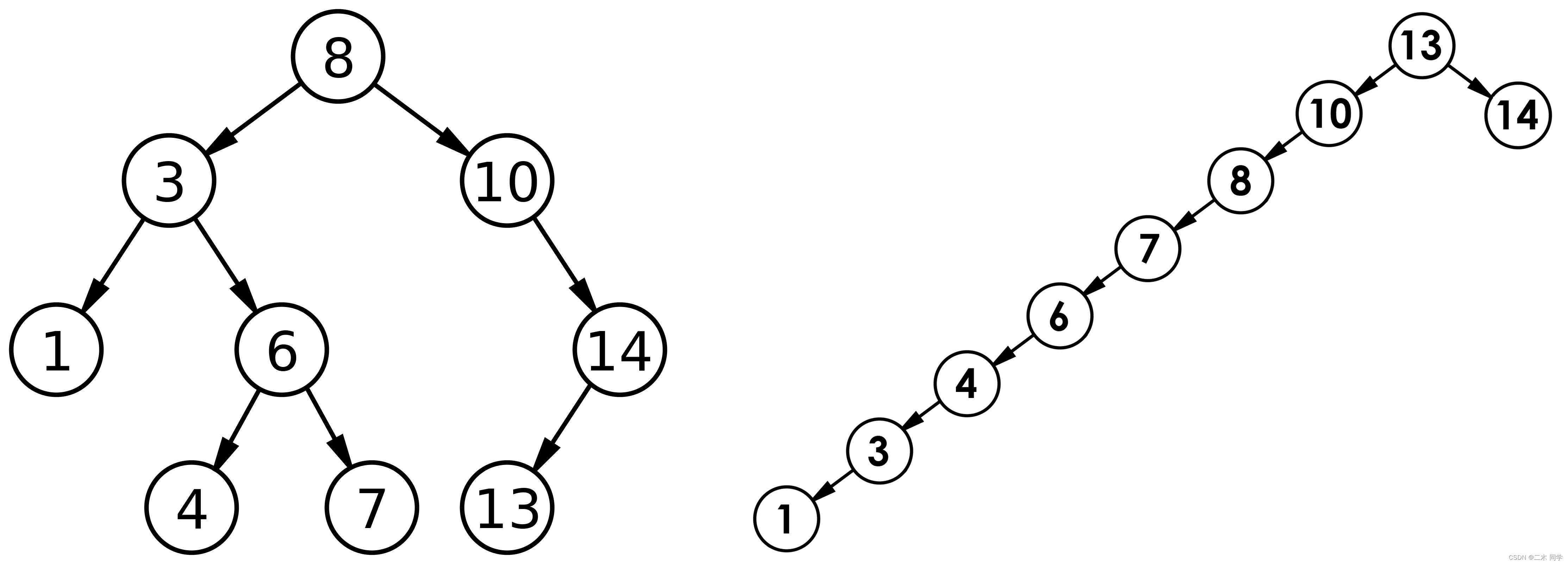
一、概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值若它的右子树不为空,则右子树上所有节点的值都大于根节点的值它的左右子树也分别…...
HNU工训中心:元器件及测量基础实验报告
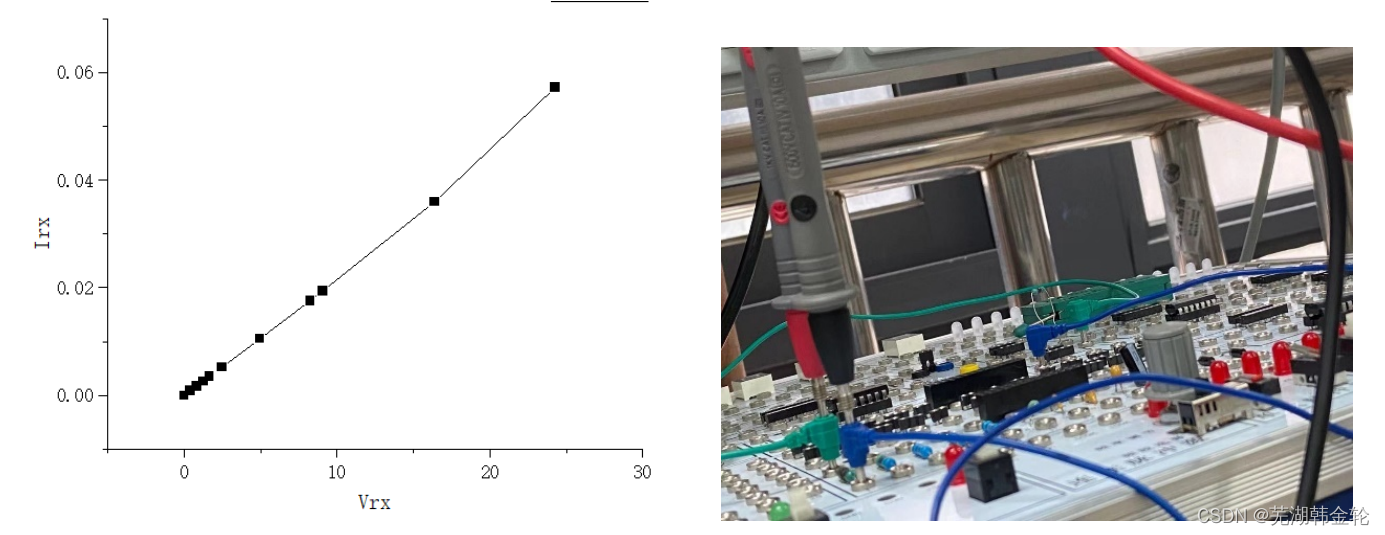
工训中心的牛马实验 1.实验目的 1.熟悉测量验证常用元器件参数、 并采用替代法(测量回路电流)测量其伏安特性的方法。 2.熟悉测量误差及减小测量误差注意事项 2.实验仪器和器材 1.实验仪器. 直流稳压电源型号:IT6302 台式多用表型号:UT805A 2.实验( 箱)器材 电路实验箱…...
博客系统--自动化测试
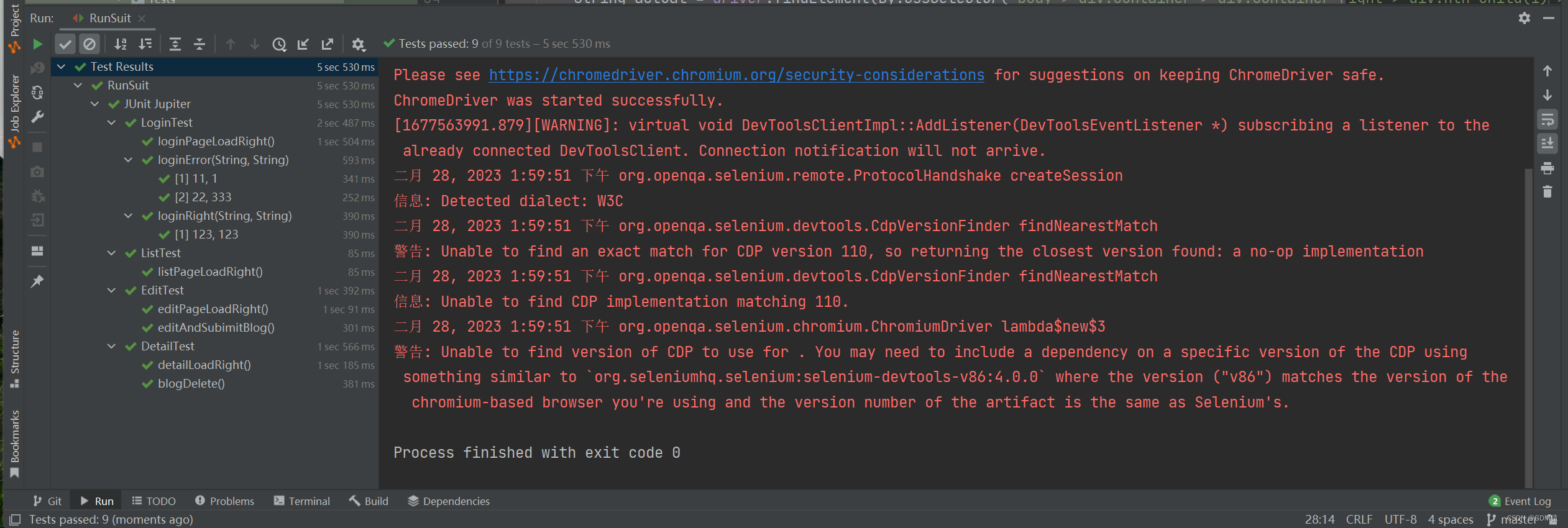
项目体验地址(账号:123,密码:123)http://120.53.20.213:8080/blog_system/login.html项目后端说明:http://t.csdn.cn/32Nnv项目码云Gitee地址:https://gitee.com/GoodManSS/project/tree/master…...

Day903.自增主键不能保证连续递增 -MySQL实战
自增主键不能保证连续递增 Hi,我是阿昌,今天学习记录的是关于自增主键不能保证连续递增的内容。 MySql保证了主键是自增,但不相对连续;帮助开发人员快速识别每个行的唯一性,并提高查询效率。 自增主键可以让主键索引…...
02-MyBatis查询-
文章目录Mybatis CRUD练习1,配置文件实现CRUD1.1 环境准备Debug01: 别名mybatisx报错1.2 查询所有数据1.2.1 编写接口方法1.2.2 编写SQL语句1.2.3 编写测试方法1.2.4 起别名解决上述问题1.2.5 使用resultMap解决上述问题1.2.6 小结1.3 查询详情1.3.1 编写接口方法1.…...

外盘国际期货招商:2023年3月关注日历,把握重要投资机会
2023年3月大事件日历 关注大事日历,把握重要投资机会 3月1日:马斯克推出特斯拉宏图第三篇章 3月1-2日:G20外长会议 3月4-5日:全国两会召开 3月9日:中国2月CPI、PPI数据 待定(前次进行日期:…...
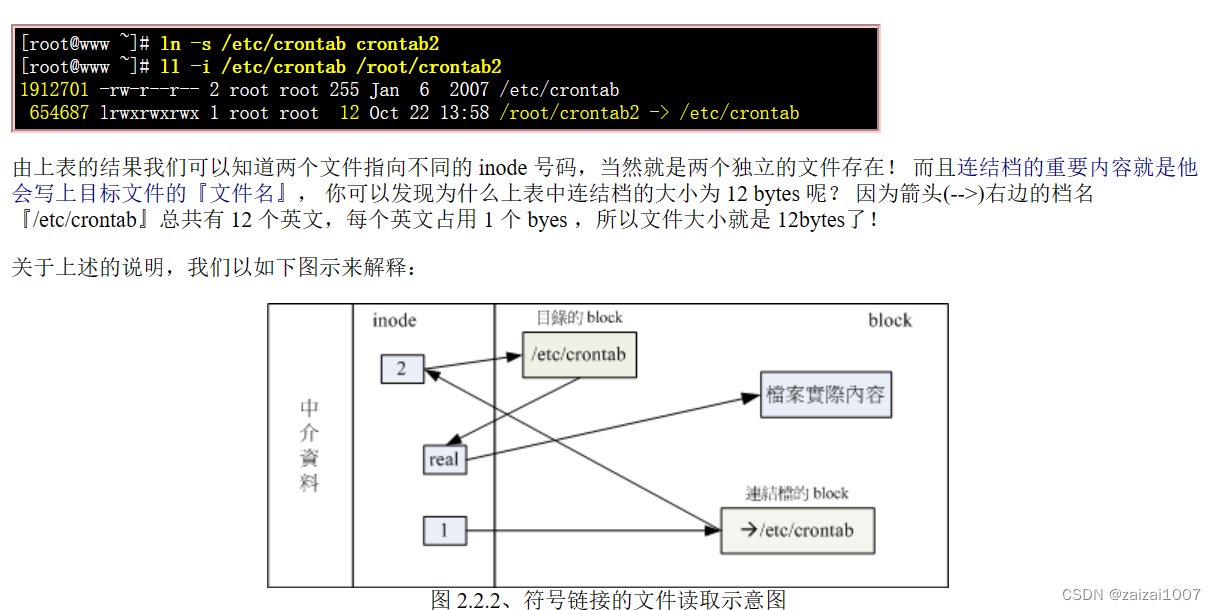
Linux学习(9.1)文件系统的简单操作
以下内容转载自鸟哥的Linux私房菜 原文:鸟哥的 Linux 私房菜 -- Linux 磁盘与文件系统管理 (vbird.org) 磁盘与目录的容量 df:列出文件系统的整体磁盘使用量;du:评估文件系统的磁盘使用量(常用在推估目录所占容量) df du 实体…...

Hadoop综合案例 - 聊天软件数据
目录1、聊天软件数据分析案例需求2、基于Hive数仓实现需求开发2.1 建库2.2 建表2.3 加载数据2.4 ETL数据清洗2.5 需求指标统计---都很简单3、FineBI实现可视化报表3.1 FineBI介绍3.2 FineBI配置数据3.3 构建可视化报表1、聊天软件数据分析案例需求 MR速度慢—引入hive 背景&a…...

Python进阶-----面向对象1.0(对象和类的介绍、定义)
目录 前言: 面向过程和面向对象 类和对象 Python中类的定义 (1)类的定义形式 (2)深层剖析类对象 前言: 感谢各位的一路陪伴,我学习Python也有一个月了,在这一个月里我收获满满…...

天猫淘宝企业服务为中小微企业打造供应链智能协同网络,让采购不再将就!丨爱分析报告
编者按:近日天猫淘宝企业服务&爱分析联合发布《2023中小微企业电商采购白皮书》,为中小微企业采购数字化带来红利。 某水泵企业:线上客户主要是中小微企业,线上业绩遇到瓶颈,如何突破呢?某焊割设备企业…...

基于四信网络摄像机的工业自动化应用
方案背景 随着数控机床被广泛的应用在工业生产中,数控技术发展成为制造业的核心。 鉴于数控机床的复杂性,以及企业人力储备有限,设备的监控和维护必须借助外部力量,而如何实现车间实时监测成了目前迫切解决的问题。 方案需求 ①兼…...

软件测试2
一 web掐断三大核心技术 HTML:负责网页的结构 CSS:负责网页的美化 JS:负责网页的行为 二 工具的使用 改变HBuilder文字的大小: 工具-视觉主题设置-大小22-确定 三 html简介 中文定义:超文本标记语言 新建一个html…...
leetcode162. 寻找峰值)
(二分查找)leetcode162. 寻找峰值
文章目录一、题目1、题目描述2、基础框架3、原题链接二、解题报告1、思路分析2、时间复杂度3、代码详解三、本题小知识一、题目 1、题目描述 峰值元素是指其值严格大于左右相邻值的元素。 给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值…...
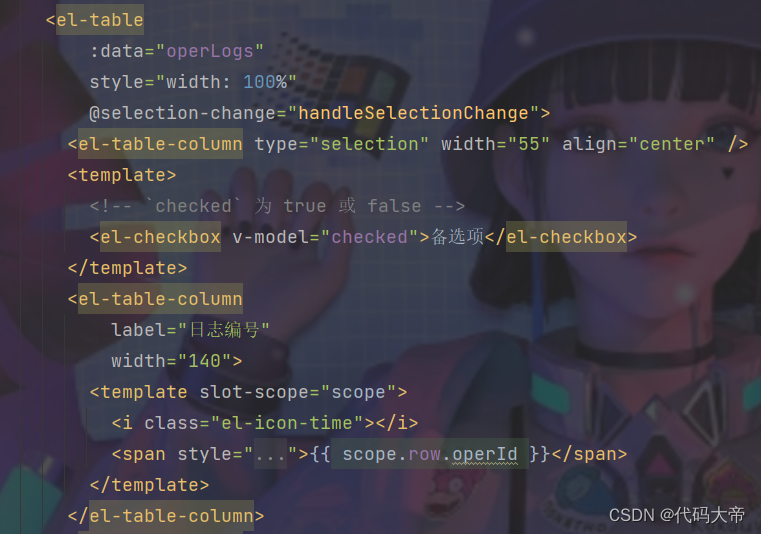
spring boot 配合element ui vue实现表格的批量删除(前后端详细教学,简单易懂,有手就行)
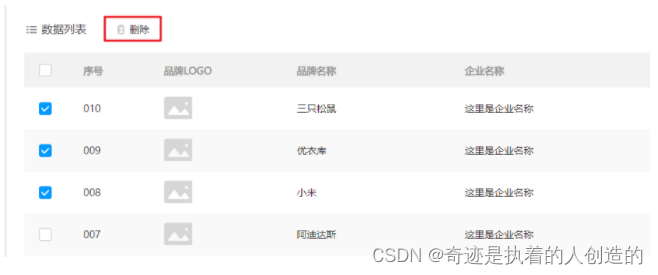
目录 一.前言: 二. 前端代码: 2.1.element ui组件代码 2.2删除按钮 2.3.data 2.4.methods 三.后端代码: 一.前言: 研究了其他人的博客,找到了一篇有含金量的,进行了部分改写实现前后端分离࿰…...
hiveSQL开窗函数详解
hive开窗函数 文章目录hive开窗函数1. 开窗函数概述1.1 窗口函数分类1.2 窗口函数和普通聚合函数的区别2. 窗口函数的基本用法2.1 基本用法2.2 设置窗口的方法2.2.1 window_name2.2.2 partition by2.2.3 order by 子句2.2.4 rows指定窗口大小窗口框架2.3 开窗函数中加 order by…...

深度学习基础实例与总结
一、神经网络 1 深度学习 1 什么是深度学习? 简单来说,深度学习就是一种包括多个隐含层 (越多即为越深)的多层感知机。它通过组合低层特征,形成更为抽象的高层表示,用以描述被识别对象的高级属性类别或特征。 能自生成数据的中…...

在 WIndows 下安装 Apache Tinkerpop (Gremlin)
一、安装 JDK 首先安装 Java JDK,这个去官网下载即可,我下载安装的 JDK19(jdk-19_windows-x64_bin.msi),细节不赘述。 二、去 Tinkerpop 网站下载 Gremlin 网址:https://tinkerpop.apache.org/ 点击下面…...

从软件的角度看待PCI和PCIE(一)
1.最容易访问的设备是什么? 是内存! 要读写内存,知道它的地址就可以了,不需要什么驱动程序; volatile unsigned int *p 0xffff8811; unsigned int val; *p val; val *p;只有内存能这样简单、方便的使用吗…...

DSP_TMS320F28377D_ADC学习笔记
前言 DSP各种模块的使用,基本上就是 GPIO复用配置、相关控制寄存器的配置、中断的配置。本文主要记录本人对ADC模块的学习笔记。TMS320F28377D上面有24路ADC专用IO,这意味着不需要进行GPIO复用配置。 只需要考虑相关控制寄存器和中断的配置。看代码请直…...

码农的职业天花板:30岁前必须突破的5个瓶颈
在软件行业的快速迭代浪潮中,软件测试从业者作为质量保障的核心力量,正面临着愈发严峻的职业挑战。30岁,不仅是人生的重要分水岭,更是测试人职业发展的关键节点。如果不能在这个阶段突破潜藏的瓶颈,很可能会陷入“经验…...

Meshroom终极指南:免费开源3D重建软件,从照片到三维模型的完整解决方案 [特殊字符]
Meshroom终极指南:免费开源3D重建软件,从照片到三维模型的完整解决方案 🚀 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom Meshroom是一款革命性的开源3D重…...

在Google Cloud上构建OpenAI兼容API网关:无缝对接Vertex AI模型
1. 项目概述:在Google Cloud上搭建你自己的OpenAI兼容API网关 如果你正在寻找一种方法,能够让你手头那些原本为OpenAI ChatGPT设计的应用,无缝对接上Google Cloud Vertex AI的强大模型,比如Gemini Pro、PaLM 2或者Codeyÿ…...

Understat终极指南:免费获取足球数据的Python异步神器
Understat终极指南:免费获取足球数据的Python异步神器 【免费下载链接】understat An asynchronous Python package for https://understat.com/. 项目地址: https://gitcode.com/gh_mirrors/un/understat 想要快速获取专业足球数据?厌倦了手动爬…...
)
别再乱点鼠标了!用netsh advfirewall命令搞定Windows防火墙,效率翻倍(附常用场景命令清单)
Windows防火墙命令行实战:netsh advfirewall高阶应用指南 每次看到同事在图形界面里一层层点击"控制面板→系统和安全→Windows Defender防火墙→高级设置"时,我都忍不住想递给他一个命令行窗口。作为IT运维老手,我早已习惯用netsh…...
)
告别天书:用Python+NumPy手把手实现Turbo码的迭代译码(附完整代码)
告别天书:用PythonNumPy手把手实现Turbo码的迭代译码(附完整代码) 在通信系统的演进历程中,Turbo码的出现犹如一场静默的革命。1993年,当Berrou等人首次公开这项技术时,其接近香农极限的性能让整个学术界为…...

淘宝淘金币自动脚本:每天15分钟解放双手的终极指南
淘宝淘金币自动脚本:每天15分钟解放双手的终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 淘宝淘金…...

别再死记硬背了!用STM32H7的USB CDC类实战,反向理解USB协议栈核心概念
从实战出发:用STM32H7的USB CDC类逆向掌握协议栈精髓 当开发板上的LED第一次随着串口指令闪烁时,我意识到USB协议栈不再是手册里晦涩的名词——端点成了数据管道,描述符变身设备身份证,而曾经令人头疼的HID报告突然有了具象意义。…...

从AlexNet到R-CNN:我是如何用迁移学习在VOC数据集上实现目标检测精度翻倍的
从AlexNet到R-CNN:迁移学习在目标检测中的工程实践与精度突破 当我们在2012年第一次看到AlexNet在ImageNet竞赛中碾压传统方法时,很少有人能预见这个突破会如何彻底改变计算机视觉的格局。但就在一年后,R-CNN的诞生将这一变革延伸到了目标检测…...
)
别再折腾Bootloader了!STM32H7内部Flash+QSPI Flash混合运行实战(MDK配置详解)
STM32H7混合存储架构开发实战:告别Bootloader的繁琐时代 在嵌入式开发领域,STM32H7系列凭借其高性能Cortex-M7内核和丰富的外设资源,已成为工业控制、智能设备和图形界面应用的宠儿。然而,传统开发模式中Bootloader与应用程序分离…...