【黑马甄选离线数仓day04_维度域开发】
1. 维度主题表数据导出
1.1 PostgreSQL介绍
PostgreSQL 是一个功能强大的开源对象关系数据库系统,它使用和扩展了 SQL 语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能。
官方网址:PostgreSQL: The world's most advanced open source database 中文文档:http://www.postgres.cn/docs/14/index.html
PostgreSQL数据库是目前功能最强大的开源数据库,它是最接近工业标准SQL92的查询语言,至少实现了SQL:2011标准中要求的179项主要功能中的160项(注:目前没有哪个数据库管理系统能完全实现SQL:2011标准中的所有主要功能)。

1.2 PostgreSQL基本操作
-
登录客户端
#psql -h 服务器 -p 端口地址 -d 数据库 -U 用户名
psql -h 127.0.0.1 -p 5432 -d postgres -U postgres
#密码:itcast123-
基本增删改查:
select datname from pg_database; 或 \l 查看所有的库
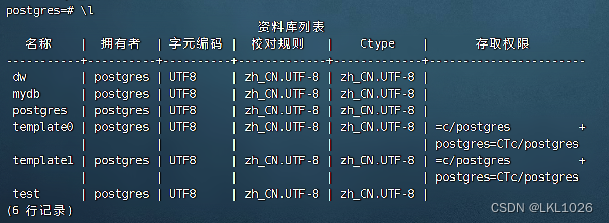
切换数据库: \c 数据库名称

查看所有表: \d

查看表结构: SELECT column_name FROM information_schema.columns WHERE table_name ='table_name';

其他操作跟MySQL大体类似。详情可参考拓展资料
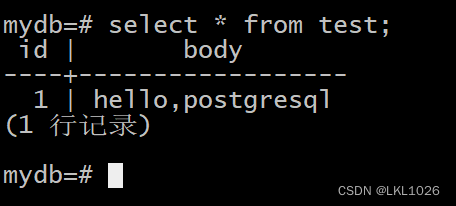
1.3 PostgreSQL中创建结果表
所有的DWD层表都需要进行导出,这里以dwd_dim_goods_i表为例,进行演示。 其他建表语句详见 资料/代码/pg建表/postsql_dw_dim.sql
创建数据库: CREATE DATABASE dw;
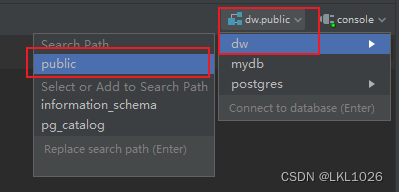
通过datagrip切换到public下: 在datagrip中,点击右上方的数据库选项
创建表操作:
建表的时候学会使用快捷键
alt+鼠标左键: 字符多选
alt+鼠标左键 然后 再ctrl+shift+右键→ : 选多个单词
home: 快速到行开头
end: 快速到行结尾
CREATE TABLE IF NOT EXISTS dwd_dim_goods_i(goods_id INT ,goods_no VARCHAR(50) ,goods_name VARCHAR(200) ,first_category_id INT ,first_category_no VARCHAR(50) ,first_category_name VARCHAR(50) ,second_category_id INT ,second_category_no VARCHAR(50) ,second_category_name VARCHAR(50) ,third_category_id INT ,third_category_no VARCHAR(50) ,third_category_name VARCHAR(50) ,brand_no VARCHAR(50) ,spec VARCHAR(50) ,sale_unit VARCHAR(50) ,life_cycle_status VARCHAR(50) ,tax_rate_status INT ,tax_rate VARCHAR(50) ,tax_value DECIMAL(27, 3),order_multiple DECIMAL(27, 2),pack_qty DECIMAL(27, 3),split_type VARCHAR(50) ,is_sell_by_piece INT ,is_self_support INT ,is_variable_price INT ,is_double_measurement INT ,is_must_sell INT ,is_seasonal INT ,seasonal_start_time VARCHAR(50) ,seasonal_end_time VARCHAR(50) ,is_deleted INT ,goods_type VARCHAR(50) ,create_time TIMESTAMP ,update_time TIMESTAMP ,PRIMARY KEY (goods_no)
);
COMMENT on table dwd_dim_goods_i is '商品表';
COMMENT on column dwd_dim_goods_i.goods_id is '商品ID';
COMMENT on column dwd_dim_goods_i.goods_no is '商品编码';
COMMENT on column dwd_dim_goods_i.goods_name is '名称';
COMMENT on column dwd_dim_goods_i.first_category_id is '一级分类ID';
COMMENT on column dwd_dim_goods_i.first_category_no is '一级分类编码';
COMMENT on column dwd_dim_goods_i.first_category_name is '一级分类';
COMMENT on column dwd_dim_goods_i.second_category_id is '二级分类ID';
COMMENT on column dwd_dim_goods_i.second_category_no is '二级分类编码';
COMMENT on column dwd_dim_goods_i.second_category_name is '二级分类';
COMMENT on column dwd_dim_goods_i.third_category_id is '三级分类ID';
COMMENT on column dwd_dim_goods_i.third_category_no is '三级分类编码';
COMMENT on column dwd_dim_goods_i.third_category_name is '三级分类';
COMMENT on column dwd_dim_goods_i.brand_no is '品牌编号';
COMMENT on column dwd_dim_goods_i.spec is '商品规格';
COMMENT on column dwd_dim_goods_i.sale_unit is '销售单位';
COMMENT on column dwd_dim_goods_i.life_cycle_status is '生命周期状态';
COMMENT on column dwd_dim_goods_i.tax_rate_status is '税率审核状态 (0:未提交审核 1:待财务审核 2:税率已审核 3:未通过)';
COMMENT on column dwd_dim_goods_i.tax_rate is '税率code';
COMMENT on column dwd_dim_goods_i.tax_value is '税率';
COMMENT on column dwd_dim_goods_i.order_multiple is '订货倍数';
COMMENT on column dwd_dim_goods_i.pack_qty is '箱装数量';
COMMENT on column dwd_dim_goods_i.split_type is '分割属性';
COMMENT on column dwd_dim_goods_i.is_sell_by_piece is '是否拆零,0:不拆;1:拆';
COMMENT on column dwd_dim_goods_i.is_self_support is '是否自营 0:非自营;1:自营';
COMMENT on column dwd_dim_goods_i.is_variable_price is '分店可变价 0:不可;1:可以';
COMMENT on column dwd_dim_goods_i.is_double_measurement is '是否双计量商品 0:否;1:是';
COMMENT on column dwd_dim_goods_i.is_must_sell is '必卖品 0:非;1:是';
COMMENT on column dwd_dim_goods_i.is_seasonal is '季节性商品 0:非;1:是';
COMMENT on column dwd_dim_goods_i.seasonal_start_time is '季节性开始时间';
COMMENT on column dwd_dim_goods_i.seasonal_end_time is '季节性结束时间';
COMMENT on column dwd_dim_goods_i.is_deleted is '是否删除0:正常;1:删除';
COMMENT on column dwd_dim_goods_i.goods_type is '商品类型 1-国产食品 2-进口食品 3-国产非食品 4-进口非食品';
COMMENT on column dwd_dim_goods_i.create_time is '该记录创建时间';
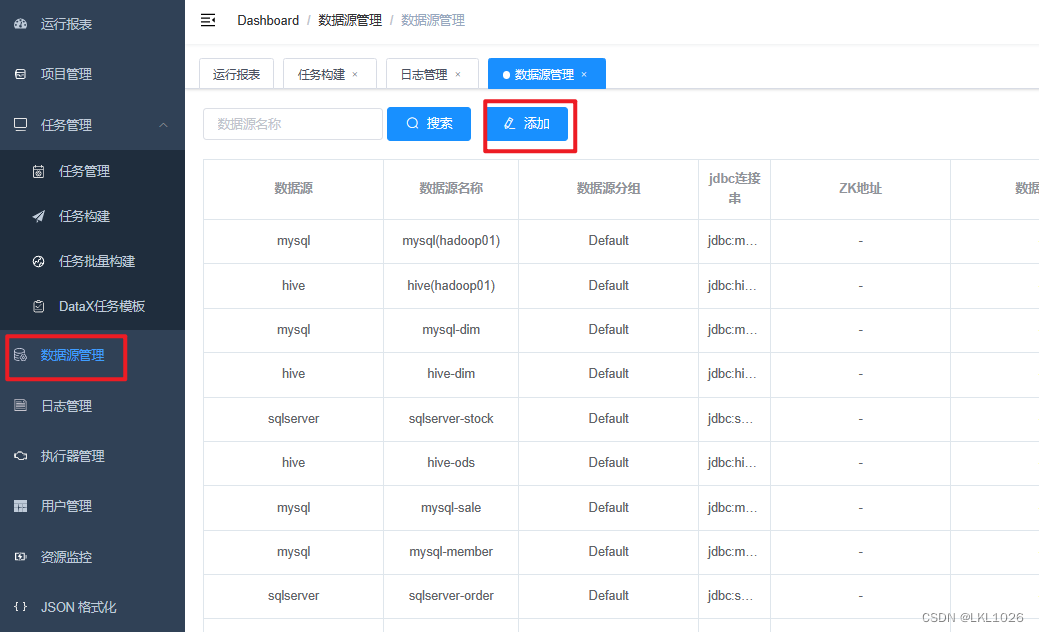
COMMENT on column dwd_dim_goods_i.update_time is '该记录最后更新时间';1.4 基于DataX完成数据导出
新建postgresql-dw数据源
构建任务
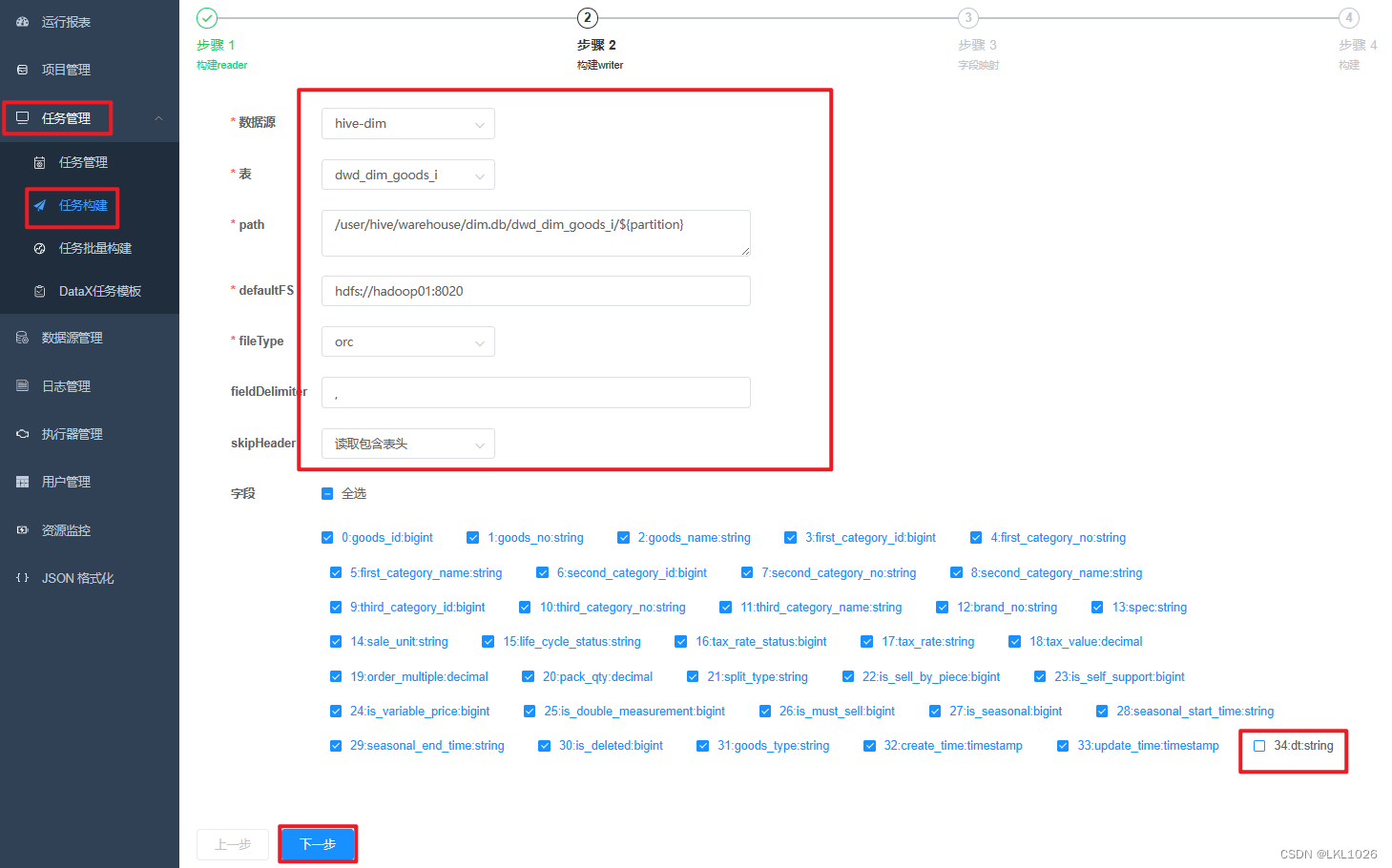
hive中以-i结尾的维表是有分区的,每个分区保存一个快照,而postgresql中只保留最新的快照数据。所以构建reader读取hive表时不需要dt字段,导入到postgresql时,默认只导入最新的快照。
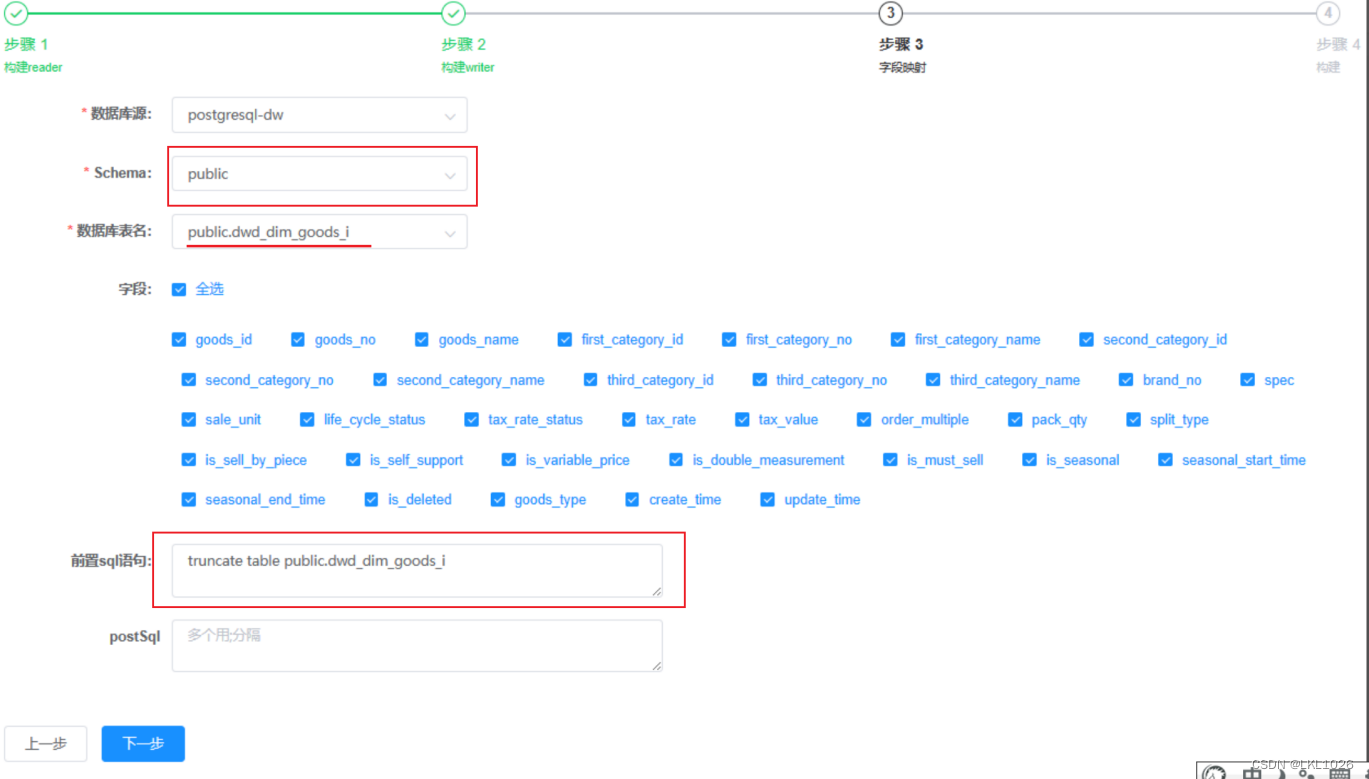
另外,为了防止postgresql中的历史数据有脏数据,在导入之前可以先清空数据。所以在构建postgresql writer时,需要加上前置sql:truncate table public.dwd_dim_goods_i。
操作如下:注意:在构建reader时,要指定导出的分区,指定的方式是在path中通过传参的方式,${partition}在运行时动态指定。
这个案例中path为:/user/hive/warehouse/dim.db/dwd_dim_goods_i/${partition}

依次点击构建、选择模板。
编辑任务:
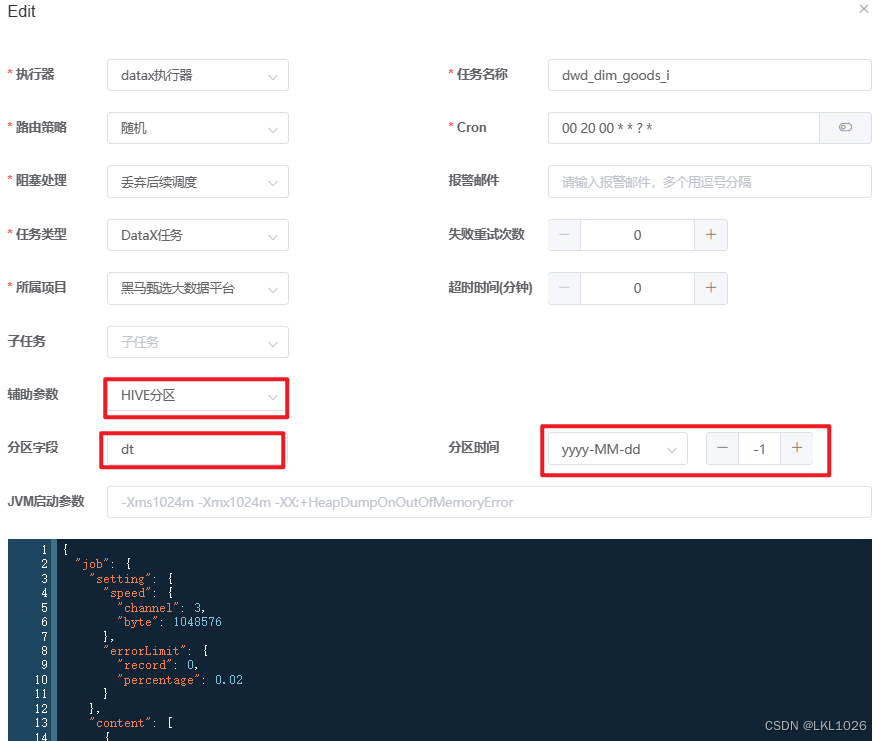
注意:如果是以-f结尾的维表,因为没有分区,在指定path路径以及在最后指定参数时,都不需要考虑分区。
执行任务:

按照以上步骤配置完dwd层所有维表导出任务的配置。
2. 基于海豚调度完成维度主题上线
2.1 DS的基本介绍
DS是apache旗下的顶级开源项目, 是一款工作流的任务调度的系统, 可以对工作流的定时周期化的调度工作, DS早期来自于国内的易观大数据公司开发, 最终贡献给Apache
2.2 DS的架构
针对DS的架构流程, 要求: 整个过程能够讲的出来
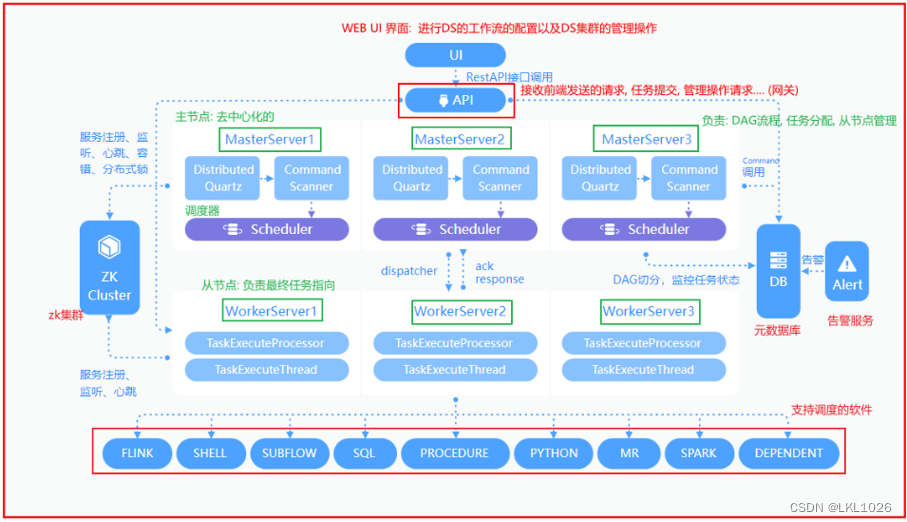
通过UI进行工作流的配置操作, 配置完成后, 将其提交执行, 此时执行请求会被API服务接收到, 接收到后, 随机选择一台Master来完成任务的处理(DAG, 任务分配, 资源处理)(底层最终是有对应scheduler具体完成)(Master是去中心化的),完成分配后, 将对应执行的任务交给对应worker(从节点)来执行, worker对应有一个logger服务进行日志的记录, 在执行过程中, 通过logger实时查看执行日志, 当执行完成后, 通知Master, Master进行状态变更,同时告警服务实时监控状态, 一旦发现状态出现异常, 会立即根据所匹配的告警方案, 通知给相关的人员
2.3 如何启动DS
cd /export/server/dolphinscheduler/
./bin/start-all.sh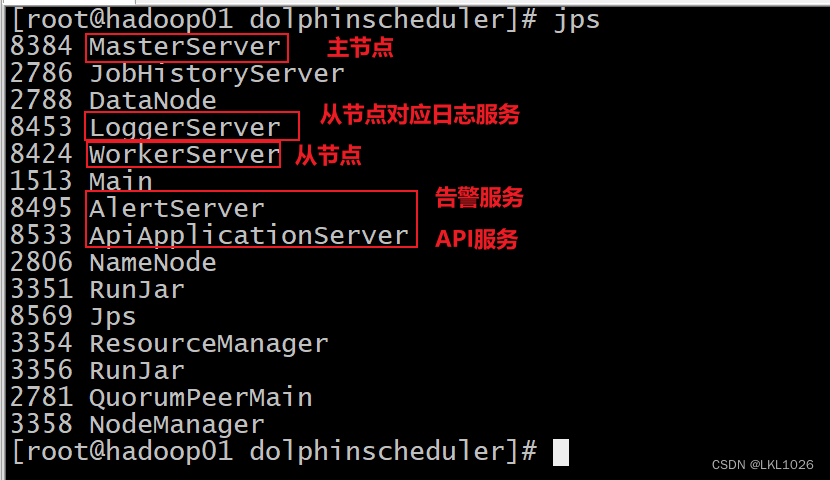
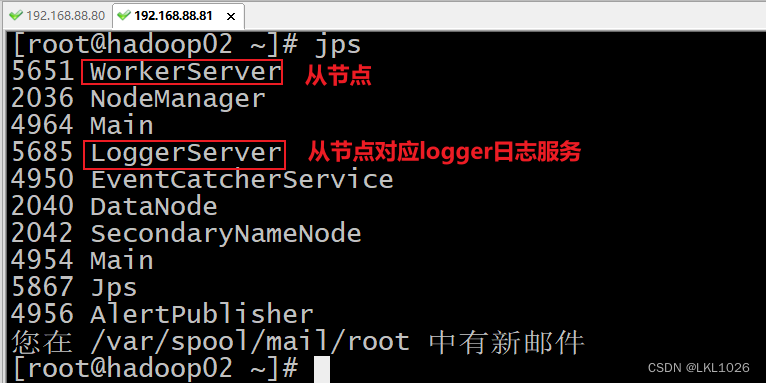
如何访问DS:
访问地址: http://192.168.88.80:12345/dolphinscheduler/ui/view/login/index.html 用户名: admin 密码: dolphinscheduler123
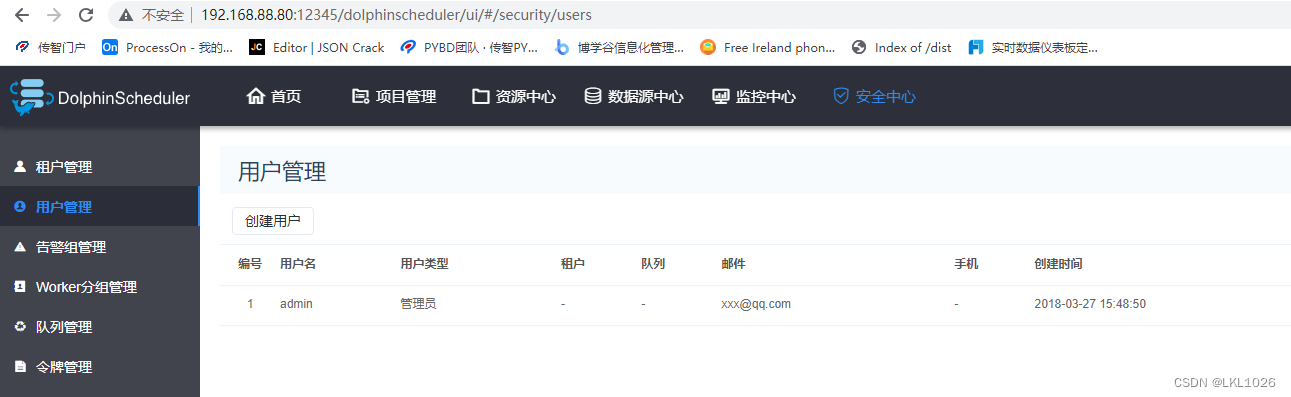
2.4 DS的安全中心
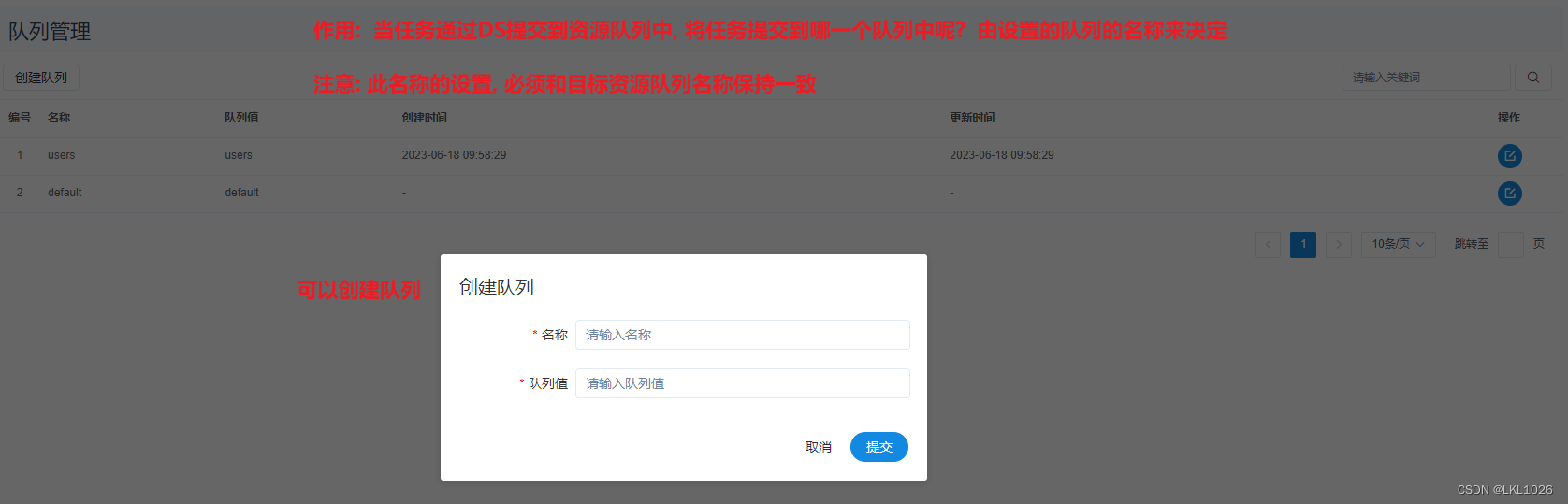
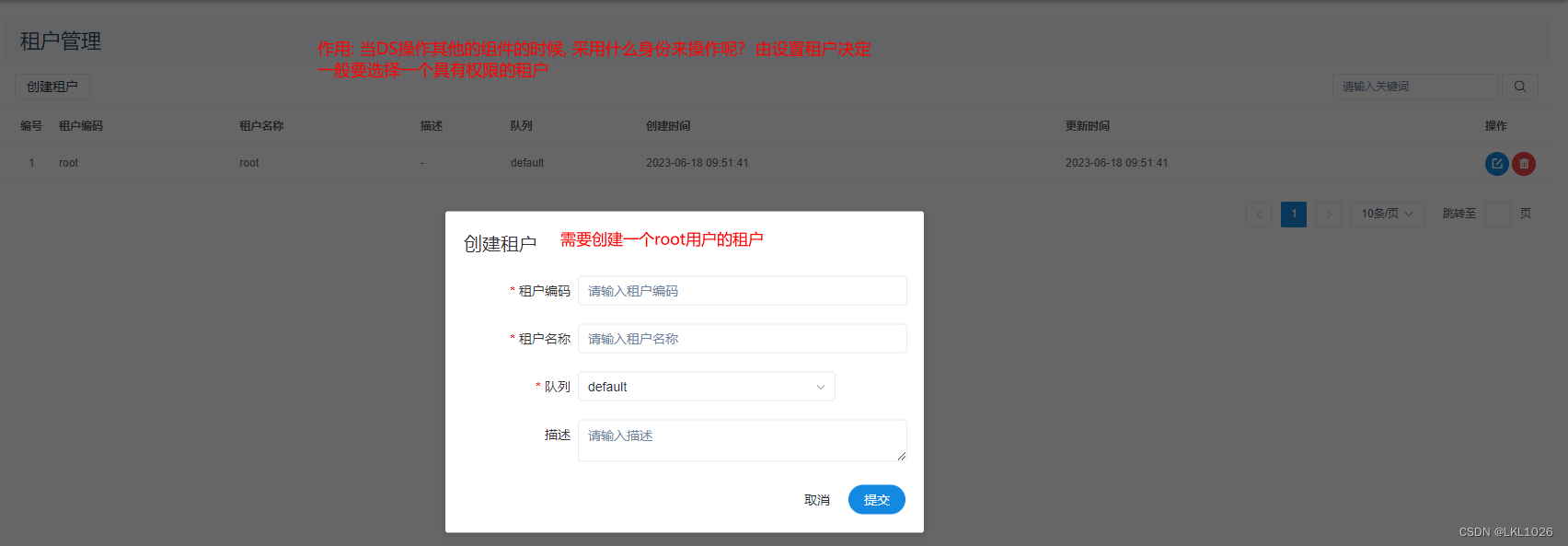
2.4.1 队列和租户
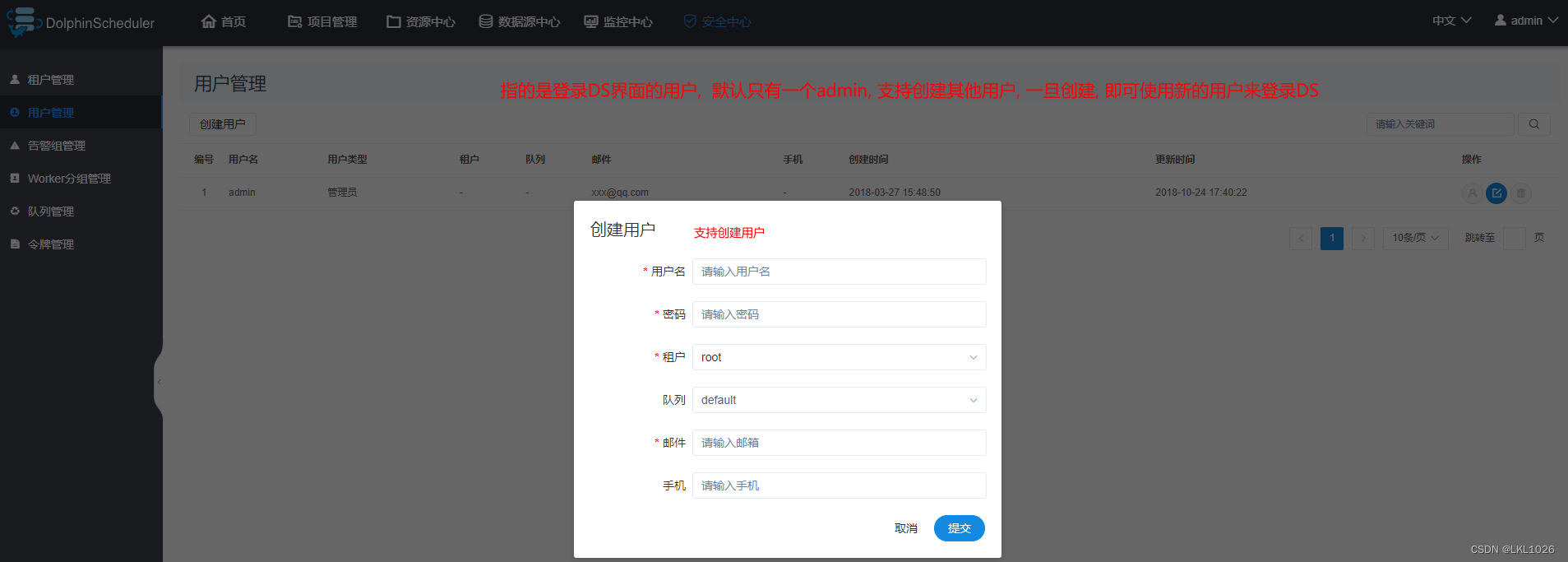
2.4.2 用户管理
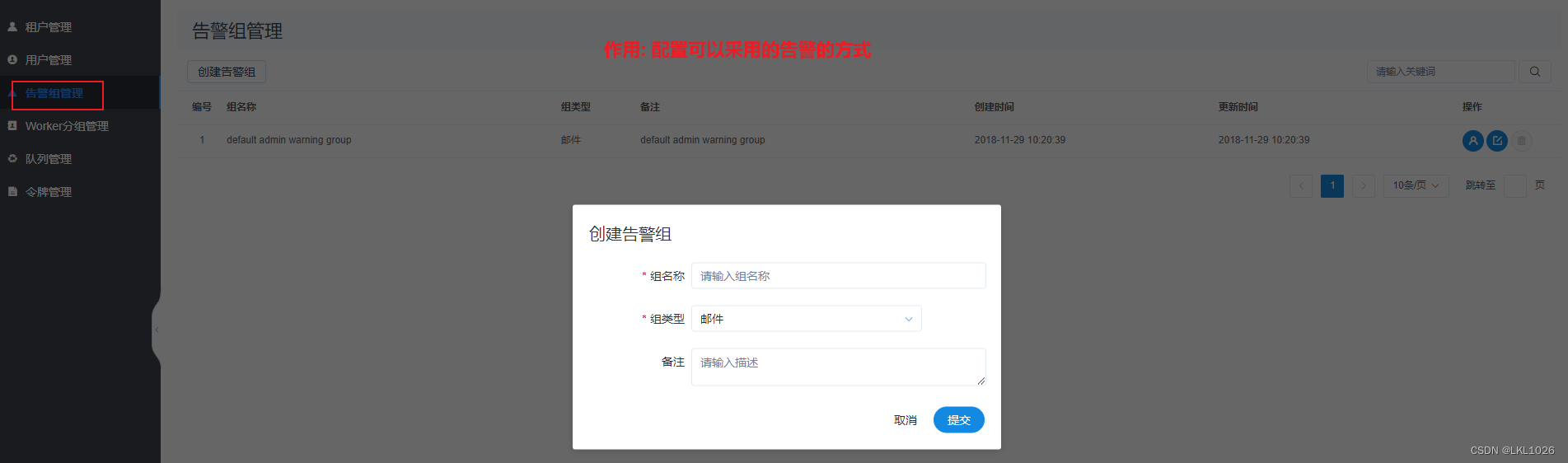
2.4.3 告警组
2.4.4 worker分组

一般在安装DS的时候会直接配置好
2.4.5 权限管理
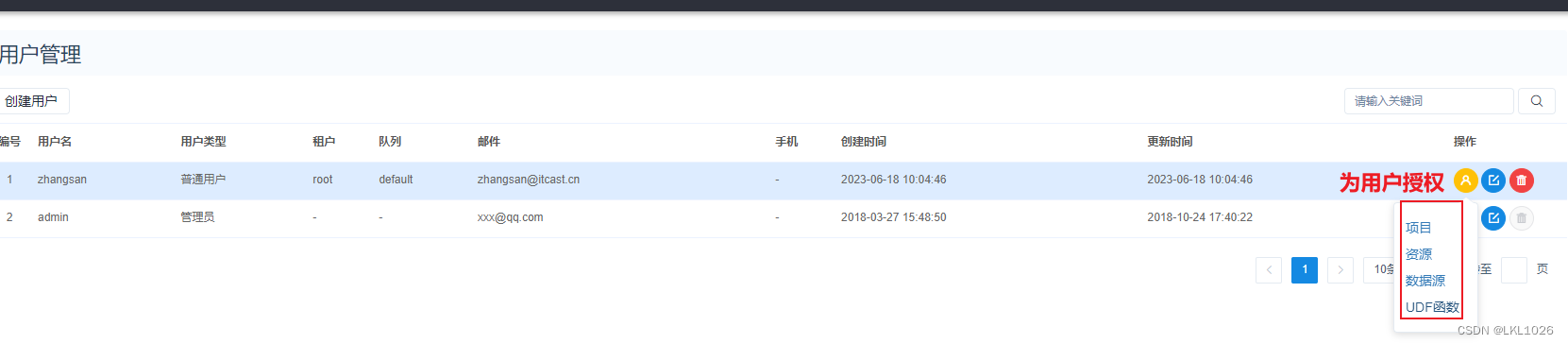
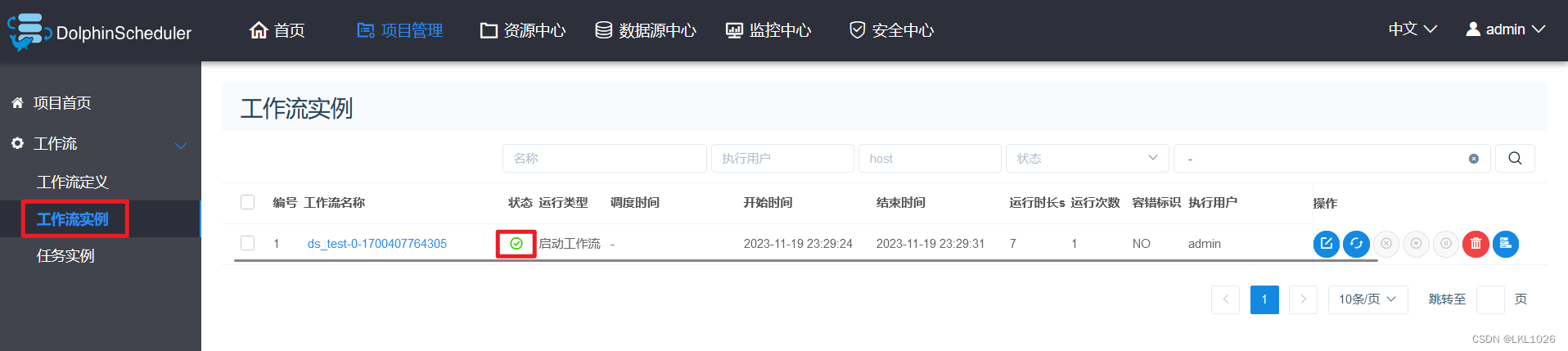
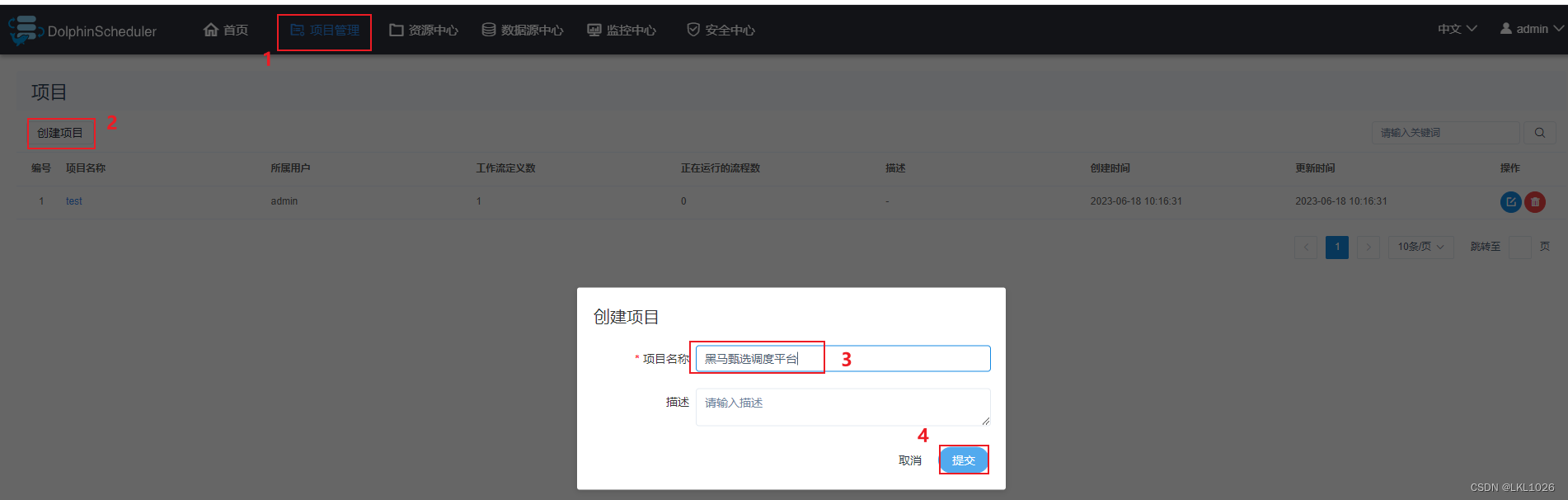
2.5 项目和调度操作[练习]
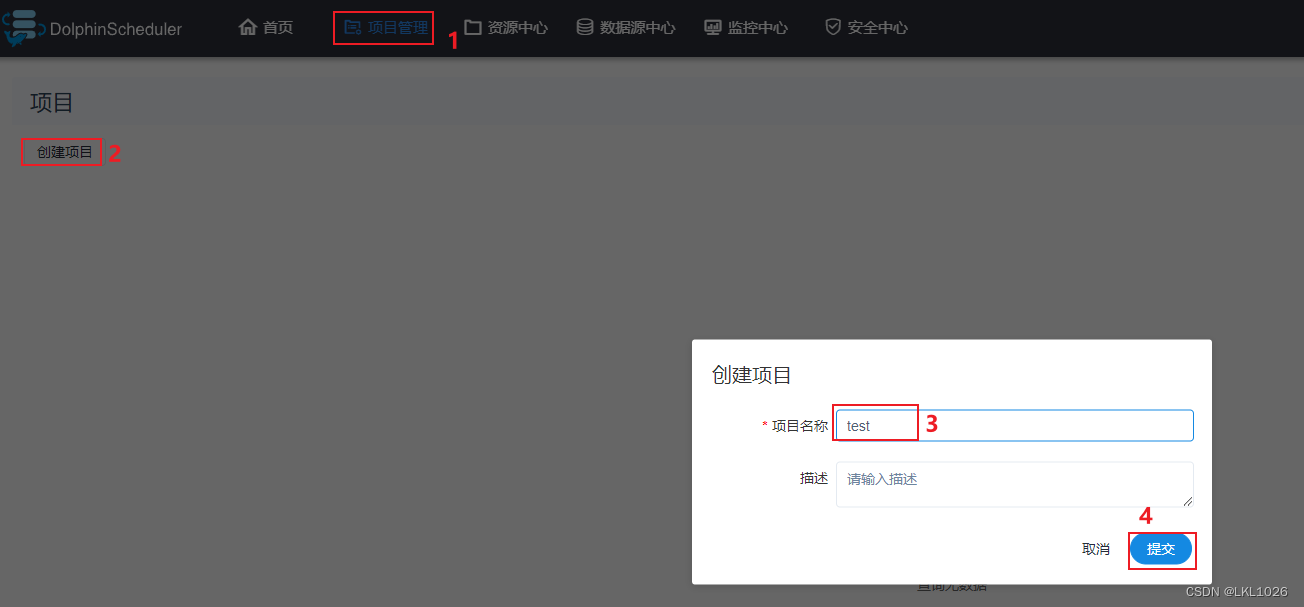
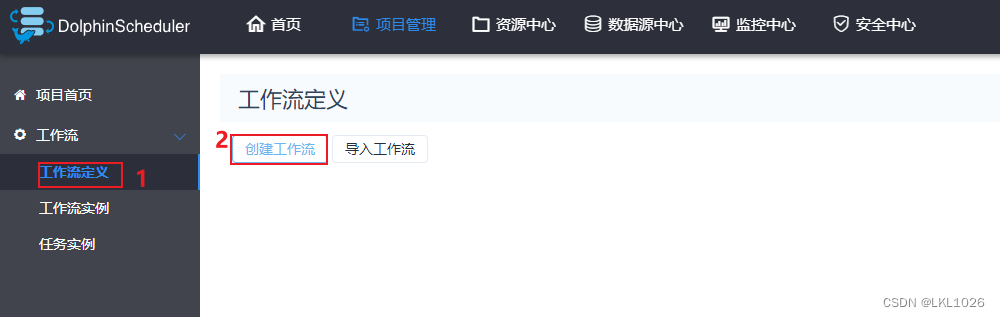
创建项目
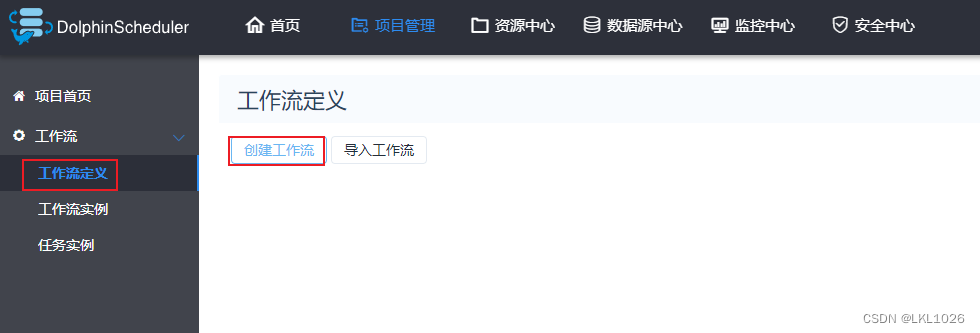
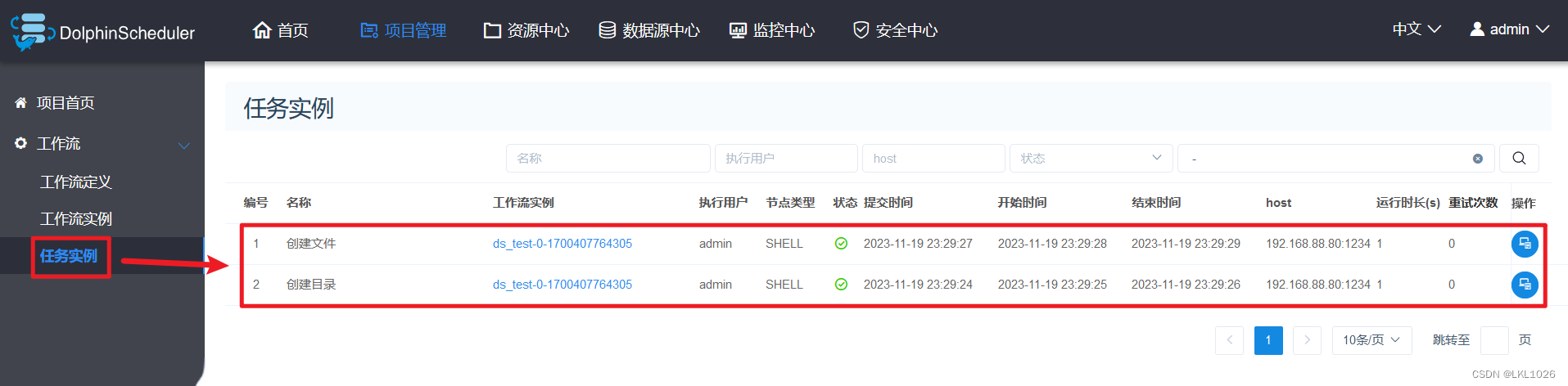
创建工作流
-
创建目录节点:
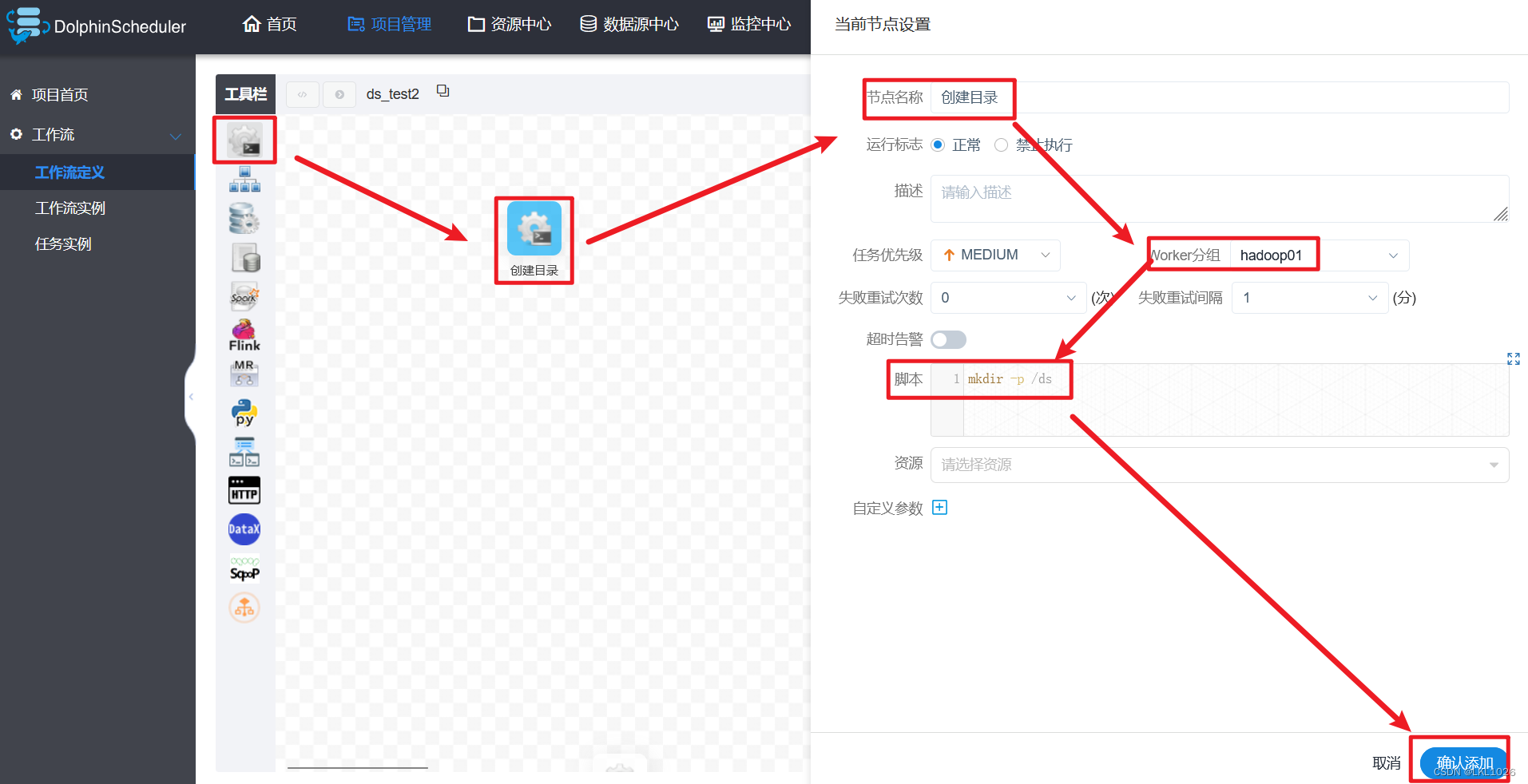
-
创建文件节点:

-
建立连接:
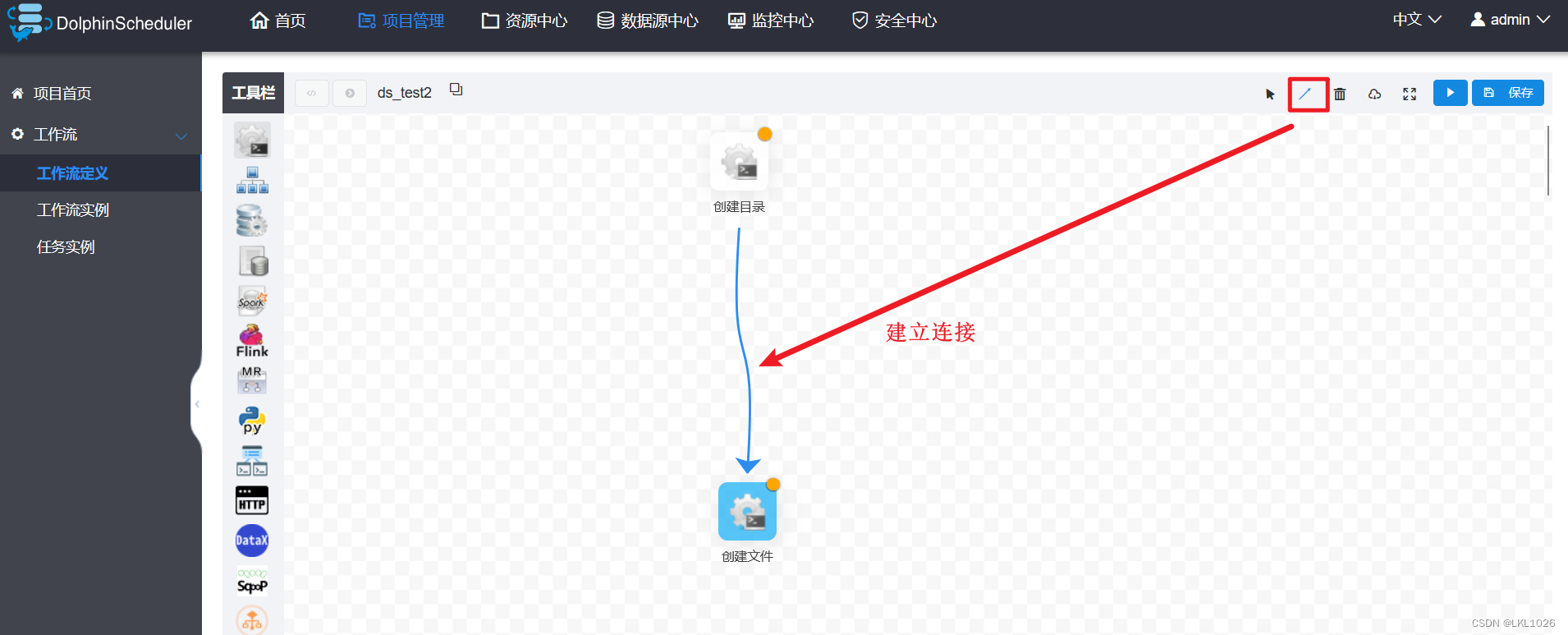
保存工作流:

上线运行工作流
-
注意如下配置选项:
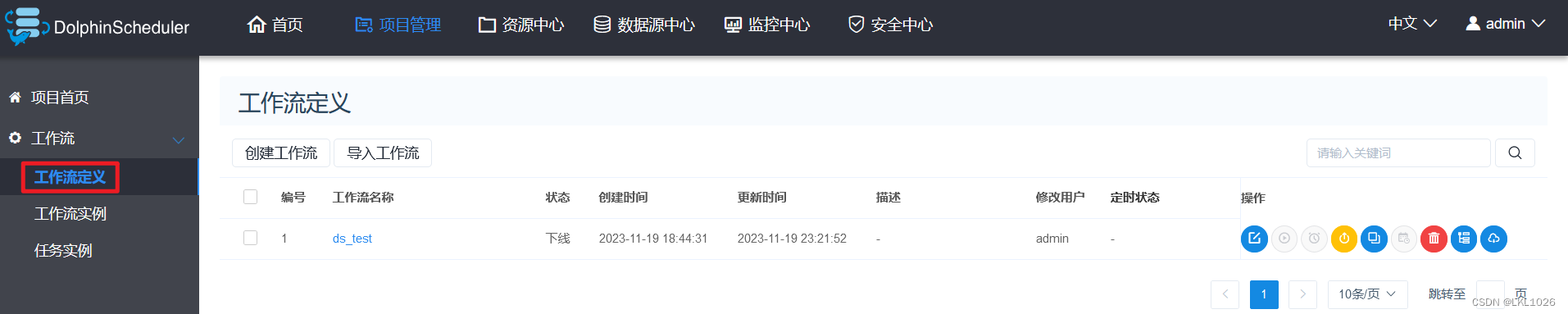
配置解释如下:

点击上线工作流
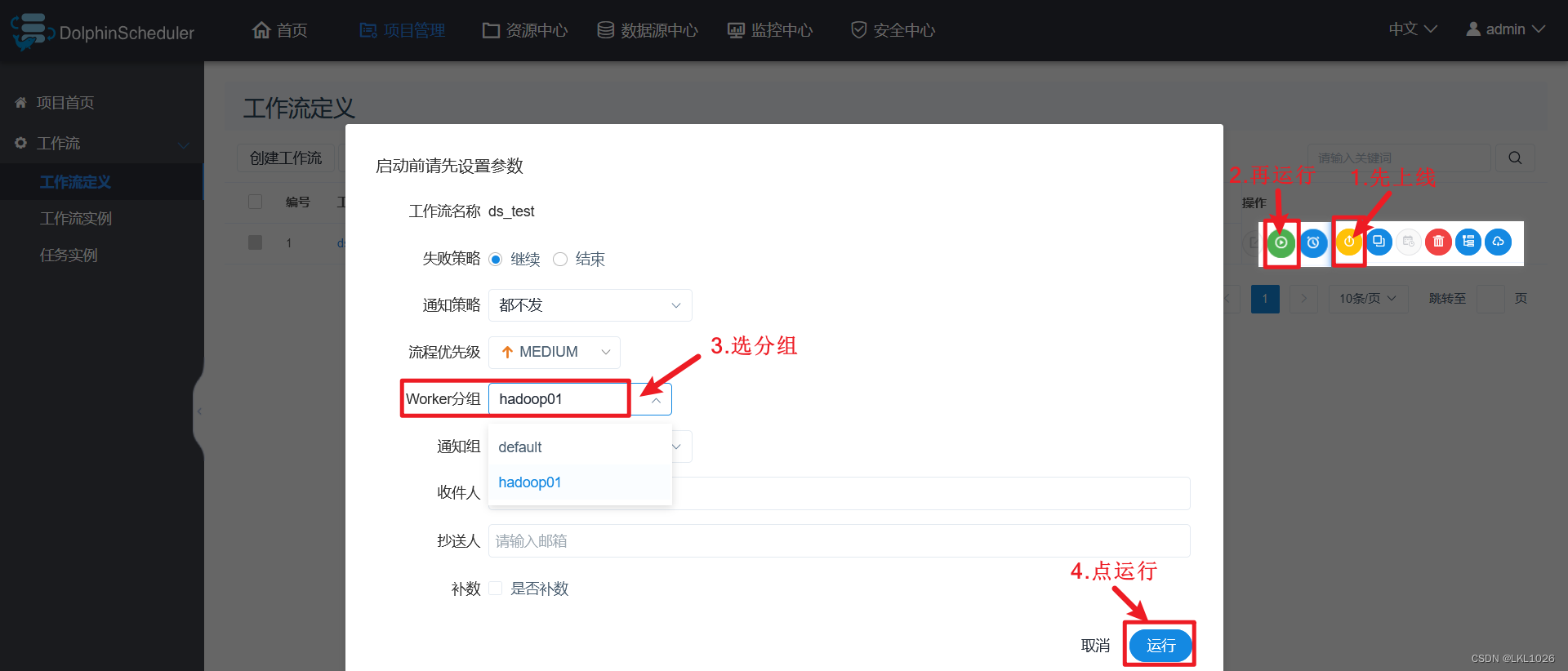
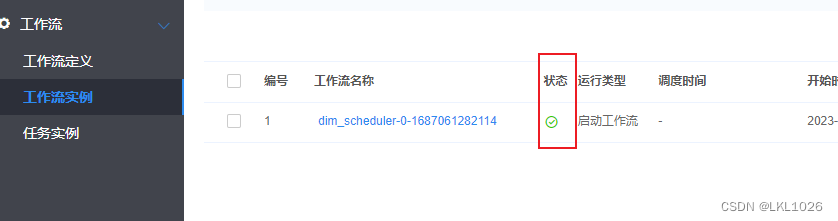
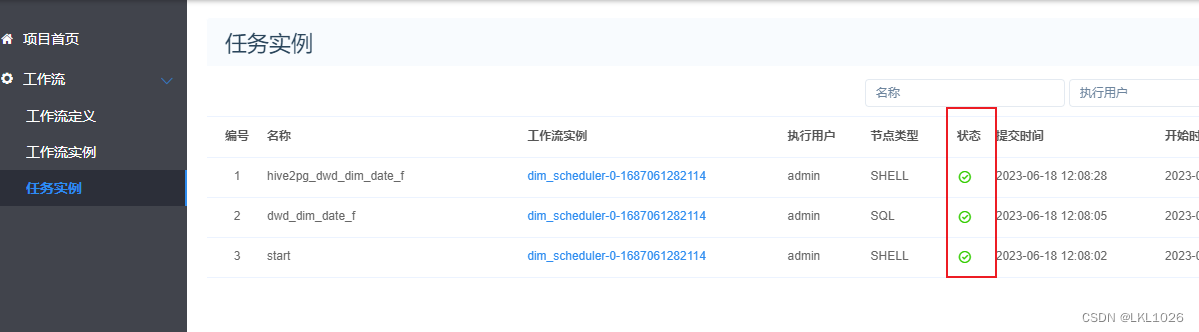
查看工作流状态:
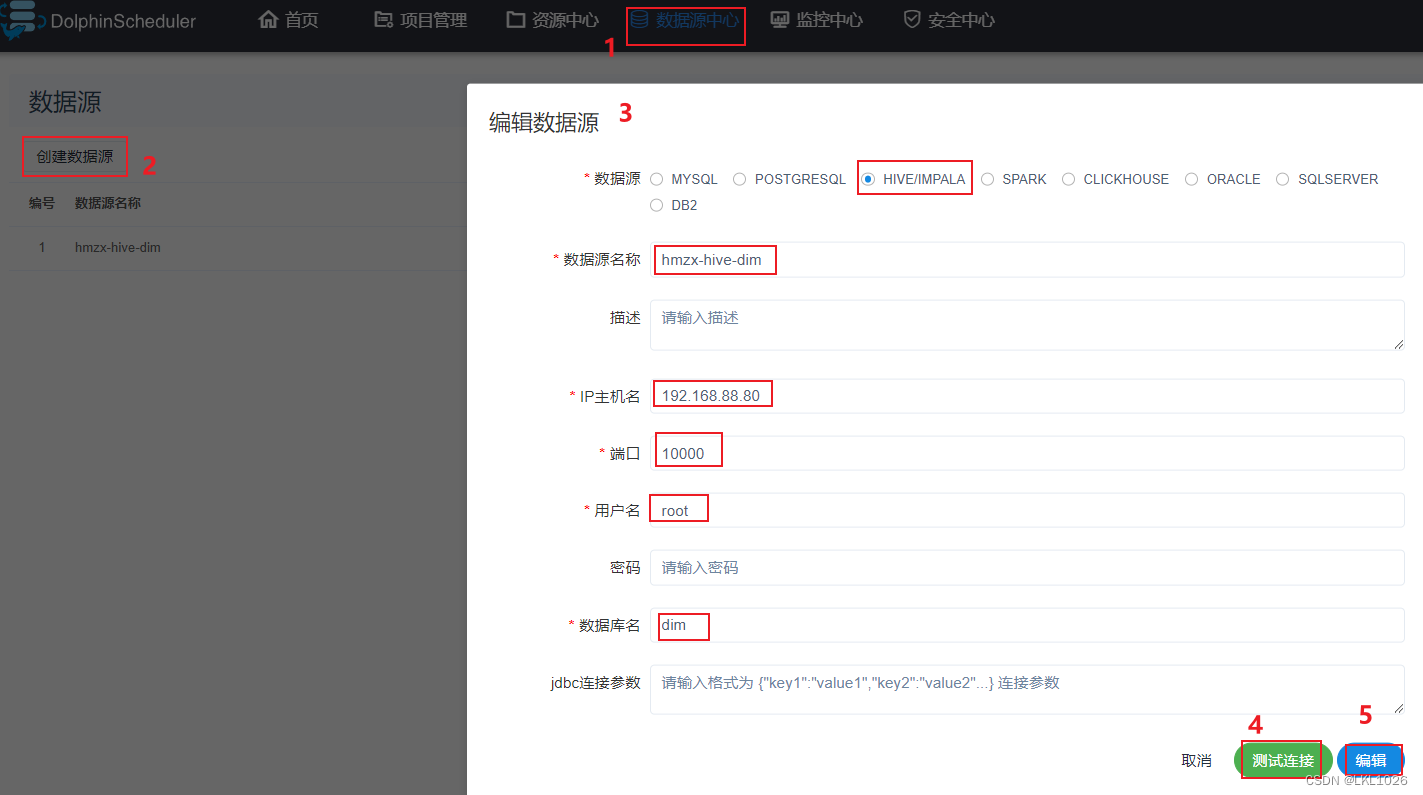
2.6 数据源中心
作用: 用于配置在工作流中需要连接各个数据源信息
比如: 工作流中需要直接连接HIVE,那么我们就可以配置一个HIVE的数据源
连接HIVE的数据源:
2.7 进行部署上线操作
注意: 从业务库 –> ODS层操作, 是由DataX-Web进行周期调度执行处理, 每天凌晨20分开始运行, 此部分我们不需要在DS中配置
本次上线: 需要将从ODS –> DWD –> 数据导出 整个流程需要在DS中进行配置
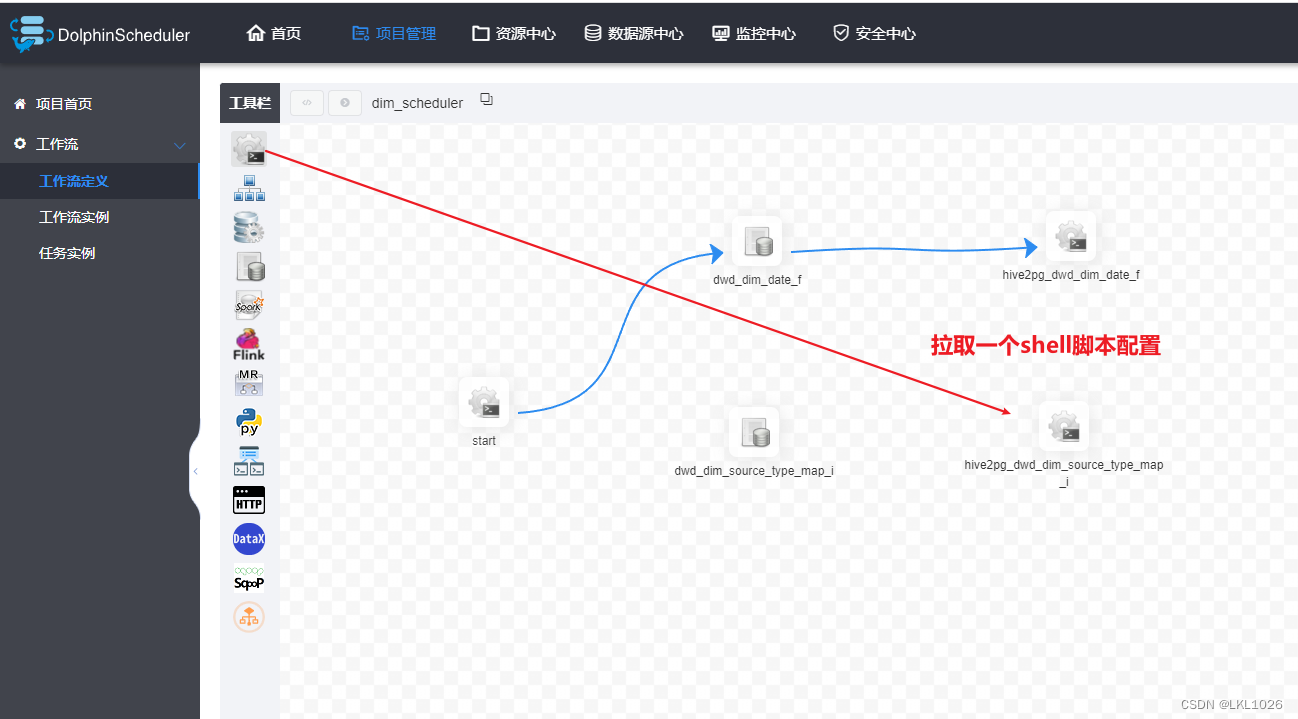
注意: worker分组, 必须只能选择hadoop01(因为DataX Hive 都在Hadoop01节点上, Hadoop02没有的)
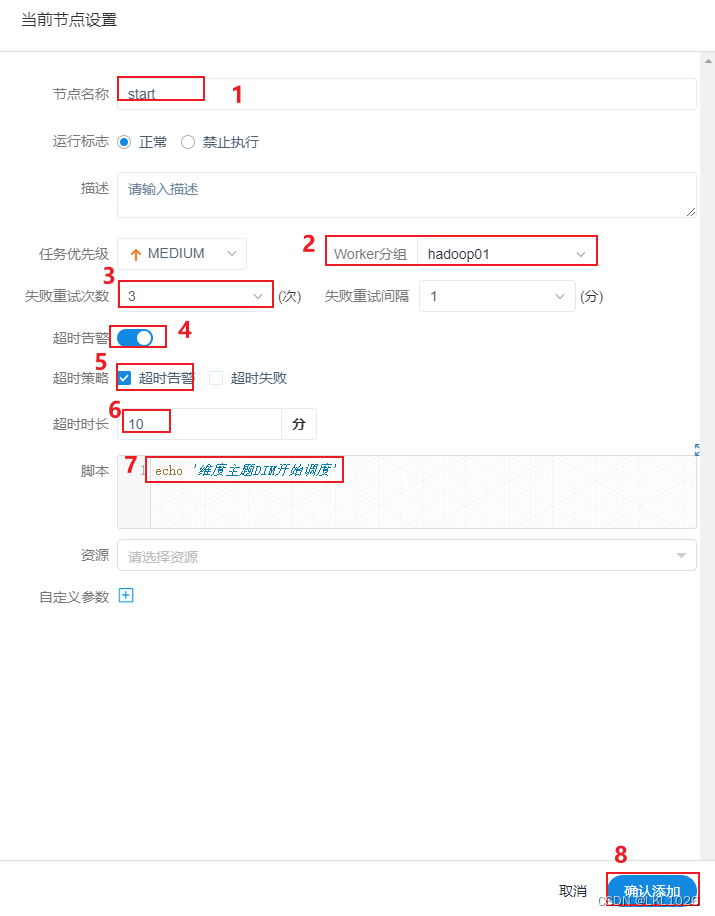
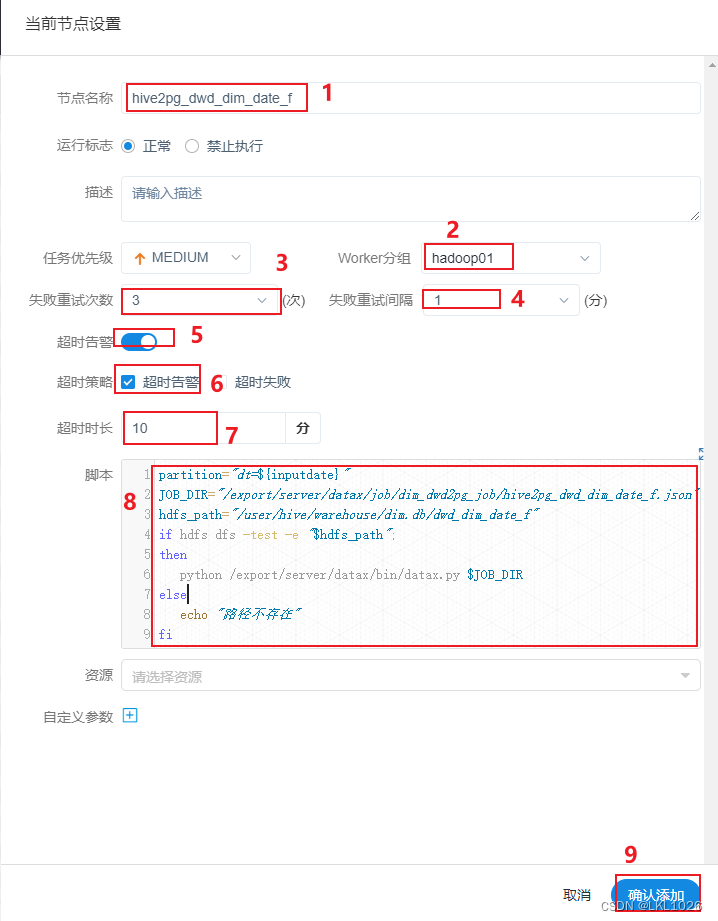
start的shell节点
-
1- 创建一个 start的shell节点, 表示整个工作流的开始

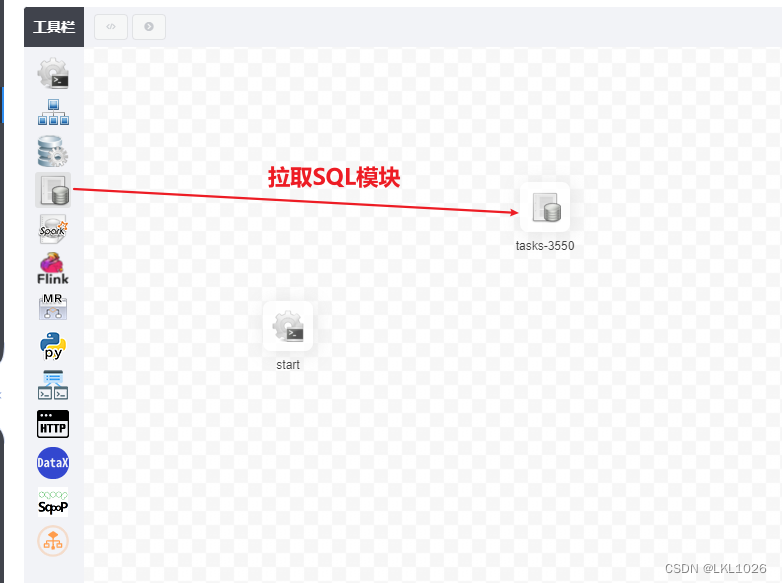
无分区表
ODS层到DWD层
-
2- 配置 ODS层 到 DWD层相关SQL语句 (以其中一个表详细记录)
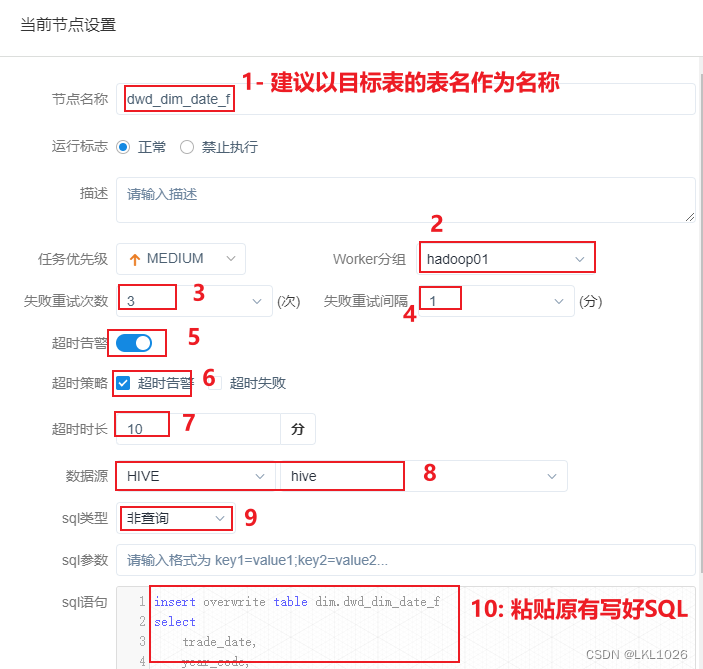
insert overwrite table dim.dwd_dim_date_f
selecttrade_date,year_code,month_code,day_code,quanter_code,quanter_name,week_trade_date,month_trade_date,week_end_date,month_end_date,last_week_trade_date,last_month_trade_date,last_week_end_date,last_month_end_date,year_week_code,week_day_code,day_year_num,month_days,is_weekend,days_after1,days_after2,days_after3,days_after4,days_after5,days_after6,days_after7
from dim.ods_dim_date_f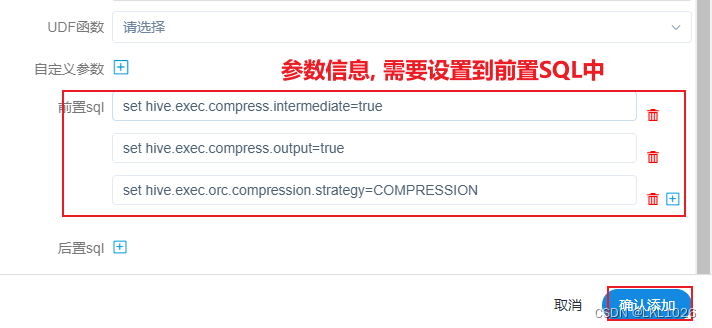
-- 开启动态分区方案
-- 开启非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 开启动态分区支持(默认true)
set hive.exec.dynamic.partition=true;
-- 设置各个节点生成动态分区的最大数量: 默认为100个 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions.pernode=10000;
-- 设置最大生成动态分区的数量: 默认为1000 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions=100000;
-- hive一次性最大能够创建多少个文件: 默认为10w
set hive.exec.max.created.files=150000;
--hive压缩
--开启中间结果压缩
set hive.exec.compress.intermediate=true;
--开启最终结果压缩
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;连线:

DWD层导出到PG
思路: 在DataX中配置每一个表从dwd到PG的Json文件, 然后通过shell命令执行调度即可
cd /export/server/datax/job/
mkdir -p dim_dwd2pg_job
cd dim_dwd2pg_job/配置json文件:
vim hive2pg_dwd_dim_date_f.json输入 i 进入插入模式:对应的Json内容, 可以直接从datax-web中获取对应json内容 (注意: 需要将密码修改回来, 不要使用加密, 因为加密的是datax-web加的, 与datax没关系)

接下来直接在DS中配置使用即可

JOB_DIR="/export/server/datax/job/自己job目录名称/自己json文件名称.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_date_f"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py $JOB_DIR
elseecho "路径不存在"
fi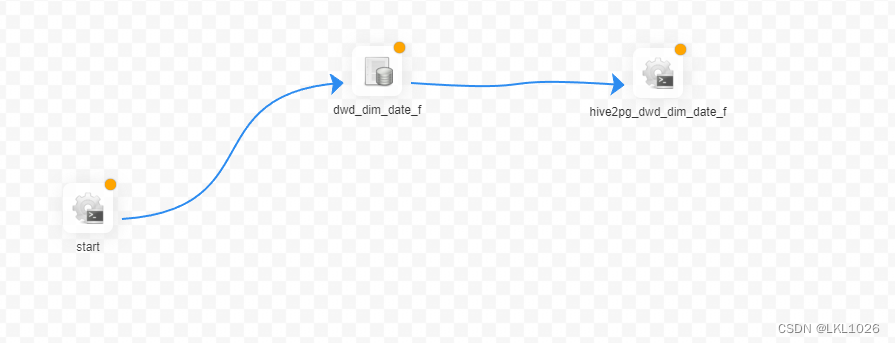
上线运行
尝试上线运行, 查看是否可以导入以及是否可以导出数据
建议: 可以将pg中对应表数据清空表以及HIVE中表数据清空掉
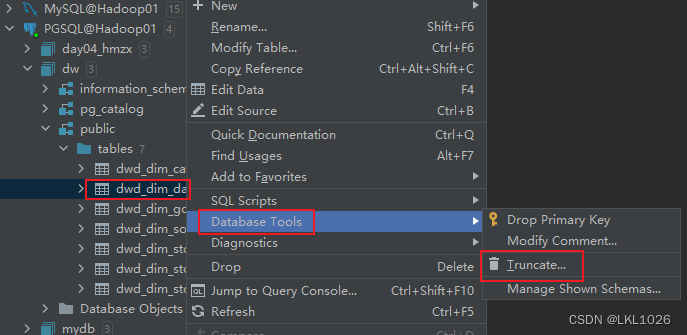
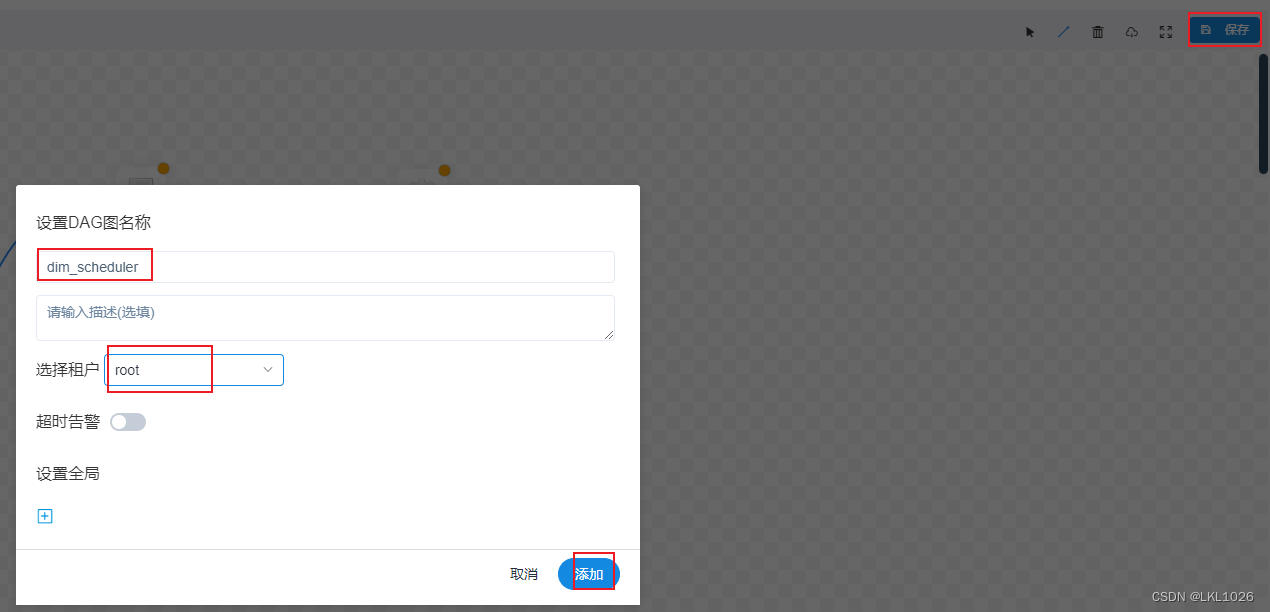
保存上线, 运行


验证: 通过DS的状态以及通过hive表和pg表查看是否成功
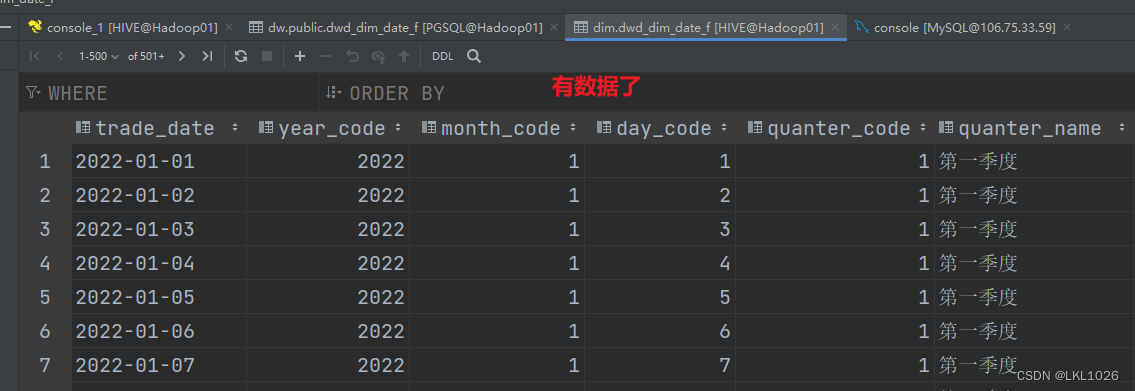
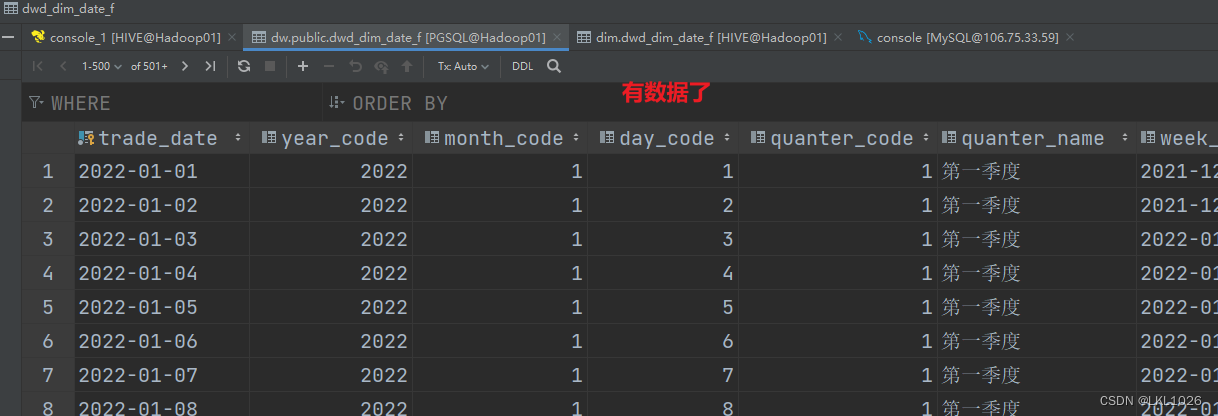
有分区表
ODS层到DWD层:

DWD层导出到PG
cd /export/server/datax/job/dim_dwd2pg_job/vim hive2pg_dwd_dim_source_type_map_i.json输入i进入插入模式添加json配置: 此配置直接从datax-web中获取, 注意更改用户和密码
partition="dt=${inputdate}"
JOB_DIR="/export/server/datax/job/自己job目录名称/自己json文件名称.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_source_type_map_i/${partition}"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py -p "-Dpartition=$partition" $JOB_DIR
elseecho "路径不存在"
fi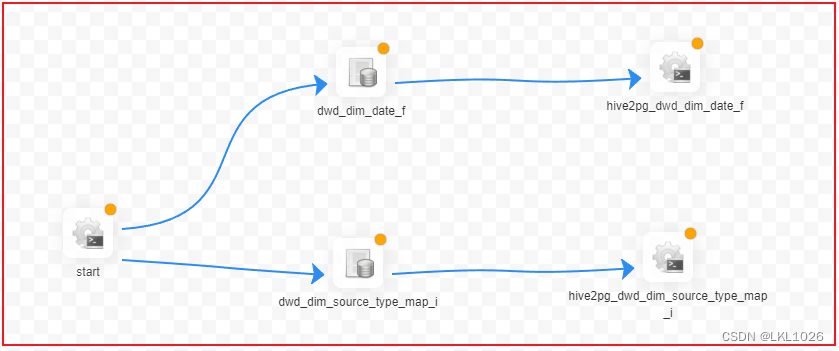
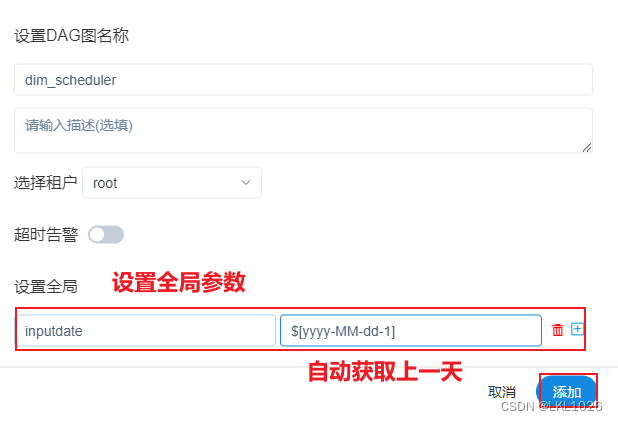
点击保存, 设置全局参数: inputdate
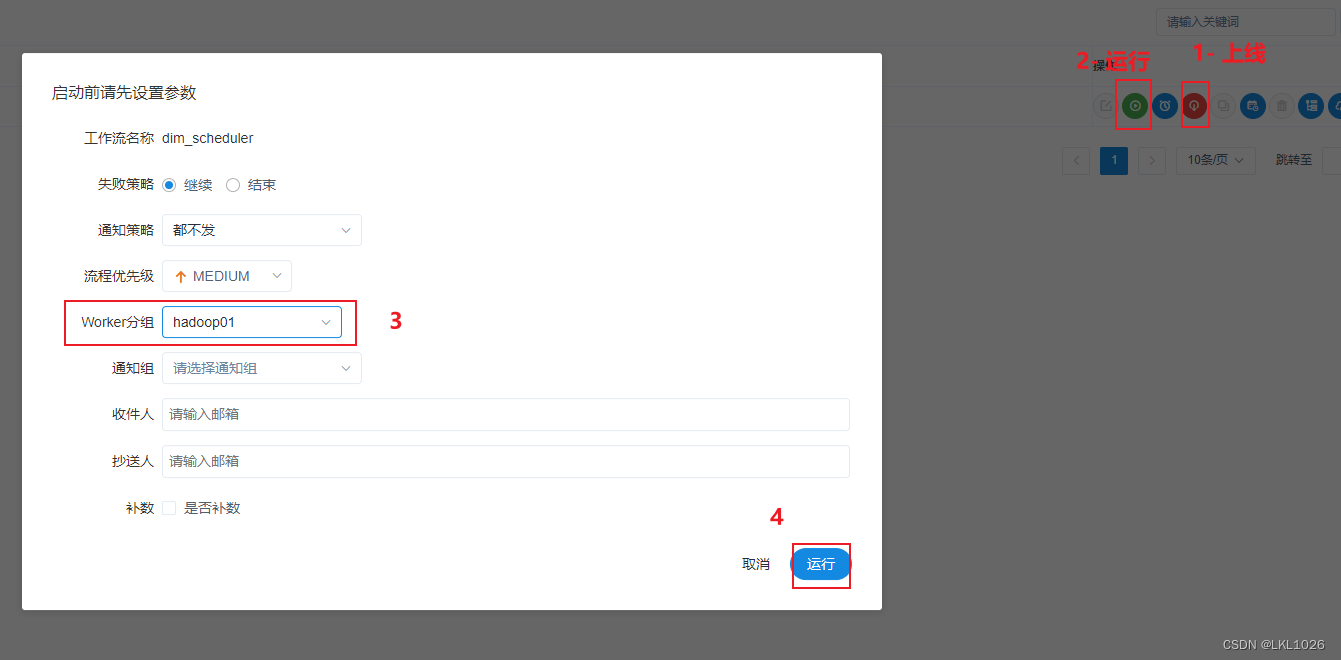
上线运行
上线, 测试 查看是否可以正常导入:
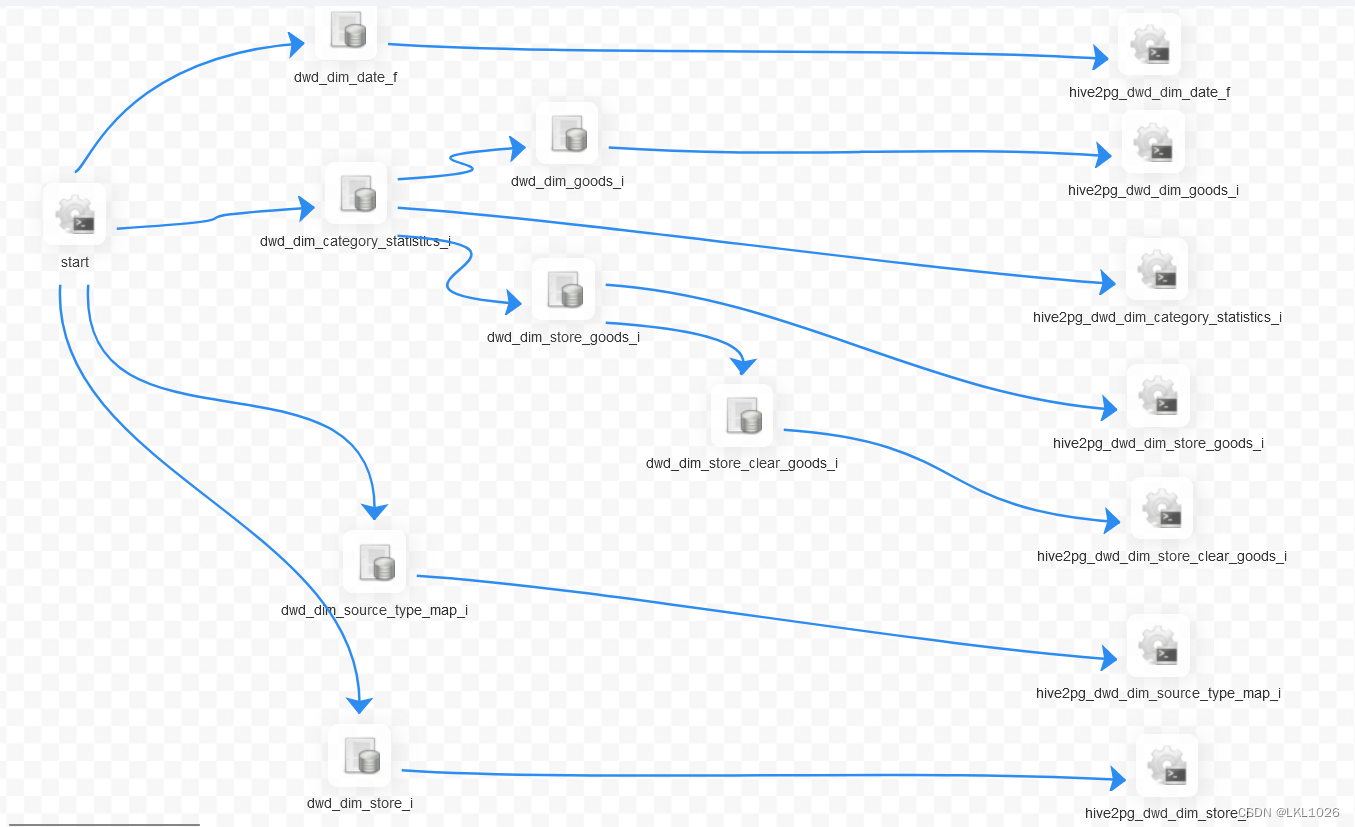
完整工作流图
DS的定时操作:
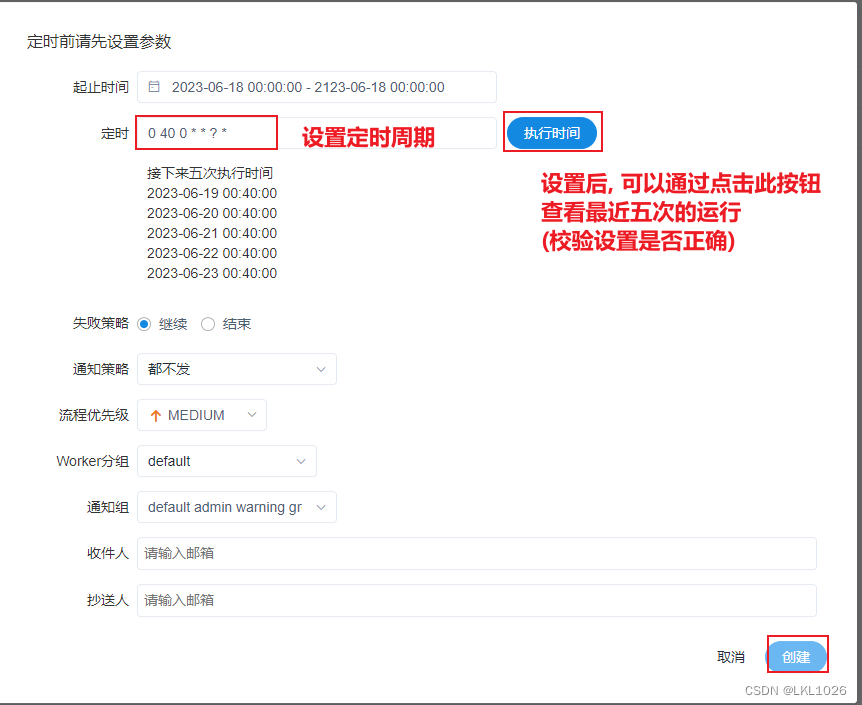
设置, 定时的状态是下线状态, 需要将其调整为上线

附录:
hive参数配置
说明: 发现在执行数据导入到各个层次的时候, 需要在执行SQL之前, 添加很多的set的参数, 而且每个表的参数基本是一样的, 此时可以尝试将其配置到HIVE的公共部分
-
选择Hive,点击配置,搜索hive-site,然后选择hive-site.xml 的 HiveServer2 高级配置代码段(安全阀),然后点击加号,将参数进行一个一个的配置
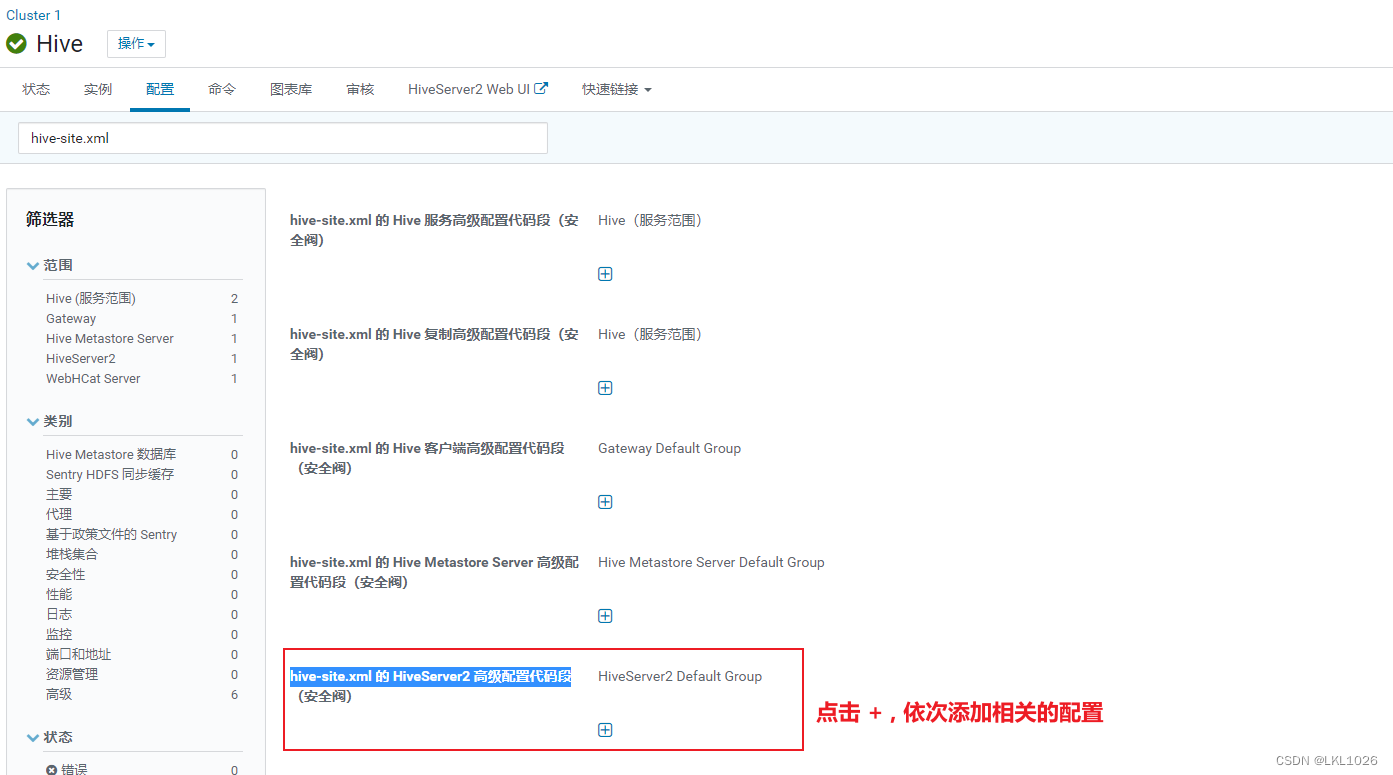

配置后, 点击保存更改,然后重启相关服务
pg所有脚本
以job目录为: dim_job为例
hive2pg_dwd_dim_date_f
JOB_DIR="/export/server/datax/job/dim_job/dwd_dim_date_f.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_date_f"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py $JOB_DIR
elseecho "路径不存在"
fihive2pg_dwd_dim_category_statistics_i
partition="dt=${inputdate}"
JOB_DIR="/export/server/datax/job/dim_job/dwd_dim_category_statistics_i.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_category_statistics_i/${partition}"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py -p "-Dpartition=$partition" $JOB_DIR
elseecho "路径不存在"
fihive2pg_dwd_dim_goods_i
partition="dt=${inputdate}"
JOB_DIR="/export/server/datax/job/dim_job/dwd_dim_goods_i.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_goods_i/${partition}"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py -p "-Dpartition=$partition" $JOB_DIR
elseecho "路径不存在"
fihive2pg_dwd_dim_store_goods_i
partition="dt=${inputdate}"
JOB_DIR="/export/server/datax/job/dim_job/dwd_dim_store_goods_i.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_store_goods_i/${partition}"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py -p "-Dpartition=$partition" $JOB_DIR
elseecho "路径不存在"
fihive2pg_dwd_dim_store_clear_goods_i
partition="dt=${inputdate}"
JOB_DIR="/export/server/datax/job/dim_job/dwd_dim_store_clear_goods_i.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_store_clear_goods_i/${partition}"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py -p "-Dpartition=$partition" $JOB_DIR
elseecho "路径不存在"
fihive2pg_dwd_dim_source_type_map_i
partition="dt=${inputdate}"
JOB_DIR="/export/server/datax/job/dim_job/dwd_dim_source_type_map_i.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_source_type_map_i/${partition}"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py -p "-Dpartition=$partition" $JOB_DIR
elseecho "路径不存在"
fihive2pg_dwd_dim_store_i
partition="dt=${inputdate}"
JOB_DIR="/export/server/datax/job/dim_job/dwd_dim_store_i.json"
hdfs_path="/user/hive/warehouse/dim.db/dwd_dim_store_i/${partition}"
if hdfs dfs -test -e "$hdfs_path";
thenpython /export/server/datax/bin/datax.py -p "-Dpartition=$partition" $JOB_DIR
elseecho "路径不存在"
fi相关文章:
【黑马甄选离线数仓day04_维度域开发】
1. 维度主题表数据导出 1.1 PostgreSQL介绍 PostgreSQL 是一个功能强大的开源对象关系数据库系统,它使用和扩展了 SQL 语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能。 官方网址:PostgreSQL: The worlds most advanced open s…...

C# 中using关键字的使用
在C#中我们还是很有必要掌握using关键字的。 比如这样: string path “D:\data.txt”; if (!File.Exists(path )) {File.Create(path); File.WriteAllText(path,"OK"); } 首先我创建…...

16 redis高可用读写分离方案
在前面说的JedisSentinelPool只能实现主从的切换,而无法实现读写的分离。 1.哨兵的客户端实现主从切换方案 <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</arti…...
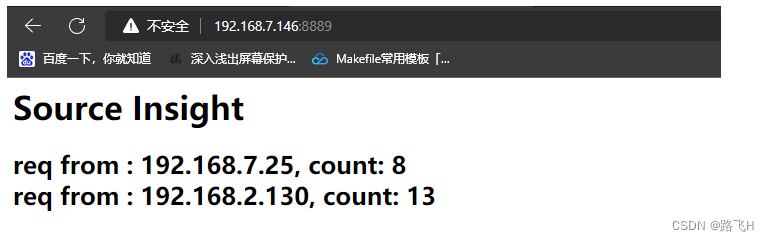
Nginx模块开发之http handler实现流量统计(2)
文章目录 一、概述二、Nginx handler模块开发2.1、代码实现2.2、编写config文件2.3、编译模块到Nginx源码中2.4、修改conf文件2.5、执行效果 总结 一、概述 上一篇【Nginx模块开发之http handler实现流量统计(1)】使用数组在单进程实现了IP的流量统计&a…...
案例012:Java+SSM+uniapp基于微信小程序的科创微应用平台设计与实现
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...

vue3+elementPlus登录向后端服务器发起数据请求Ajax
后端的url登录接口 先修改main.js文件 // 导入Ajax 前后端数据传输 import axios from "axios"; const app createApp(App) //vue3.0使用app.config.globalProperties.$http app.config.globalProperties.$http axios app.mount(#app); login.vue 页面显示部分…...

存储区域
将应用程序加载到内存空间执行时,操作系统负责代码段、数据段和BSS段的加载,并在内存中为这些段分配空间。 栈段亦由操作系统分配和管理,而不需要程序员显示地管理;堆段由程序员自己管理,即显示地申请和释放空间。 进…...
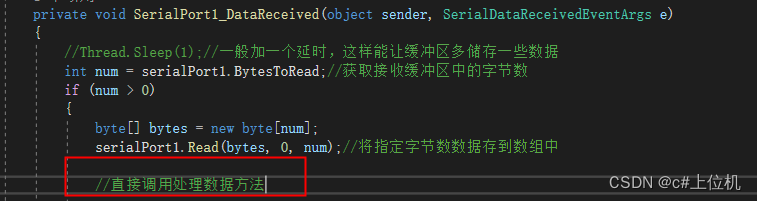
C#串口通信从入门到精通(27)——高速通信下解决数据处理慢的问题(20ms以内)
前言 我们在开发串口通信程序时,有时候会遇到比如单片机或者传感器发送的数据速度特别快,比如10ms、20ms发送一次,并且每次发送的数据量还比较大,如果按照常规的写法,我们会发现接收的数据还没处理完,新的数据又发送过来了,这就会导致处理数据滞后,软件始终处理的不是…...

Redis-Redis高可用集群之水平扩展
Redis3.0以后的版本虽然有了集群功能,提供了比之前版本的哨兵模式更高的性能与可用性,但是集群的水平扩展却比较麻烦,今天就来带大家看看redis高可用集群如何做水平扩展,原始集群(见下图)由6个节点组成,6个节点分布在三…...

2023全球数字贸易创新大赛-人工智能元宇宙-4-10
目录 竞赛感悟: 创业的话 好的项目 数字工厂,智慧制造:集群控制的安全问题...

go defer用法_类似与python_java_finially
defer 执行 时间 defer 一般 定义在 函数 开头, 但是 他会 最后 被执行 A defer statement defers the execution of a function until the surrounding function returns. 如果说 为什么 不在 末尾 定义 defer 呢, 因为 当 错误 发生时, 程序 执行 不到 末尾 就会 崩溃. d…...

Log4j2.xml不生效:WARN StatusLogger Multiple logging implementations found:
背景 将 -Dlog4j.debug 添加到IDEA的类的启动配置中 运行上图代码,这里log4j2.xml控制的日志级别是info,很明显是没生效。 DEBUG StatusLogger org.slf4j.helpers.Log4jLoggerFactory is not on classpath. Good! DEBUG StatusLogger Using Shutdow…...
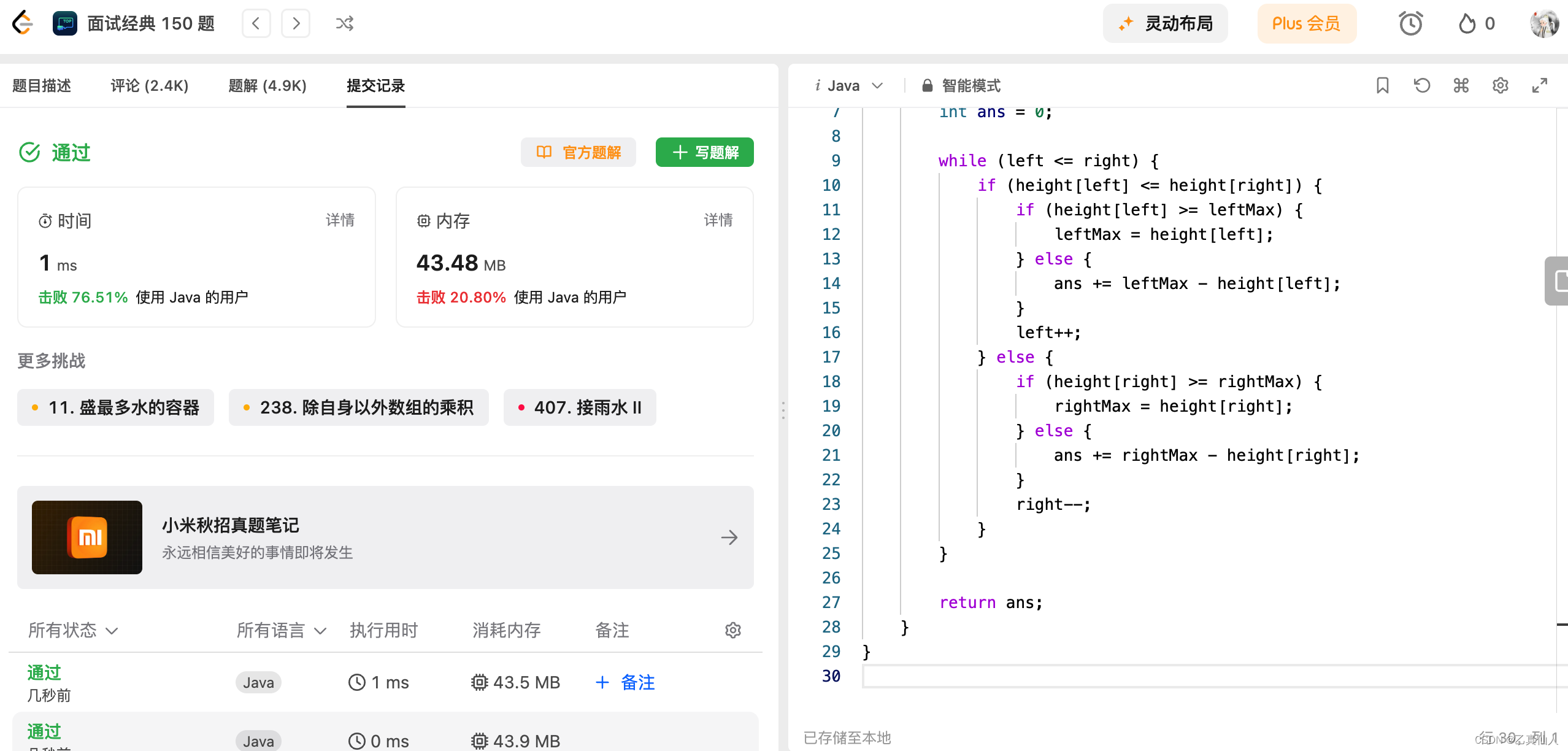
【LeetCode】挑战100天 Day14(热题+面试经典150题)
【LeetCode】挑战100天 Day14(热题面试经典150题) 一、LeetCode介绍二、LeetCode 热题 HOT 100-162.1 题目2.2 题解 三、面试经典 150 题-163.1 题目3.2 题解 一、LeetCode介绍 LeetCode是一个在线编程网站,提供各种算法和数据结构的题目&…...
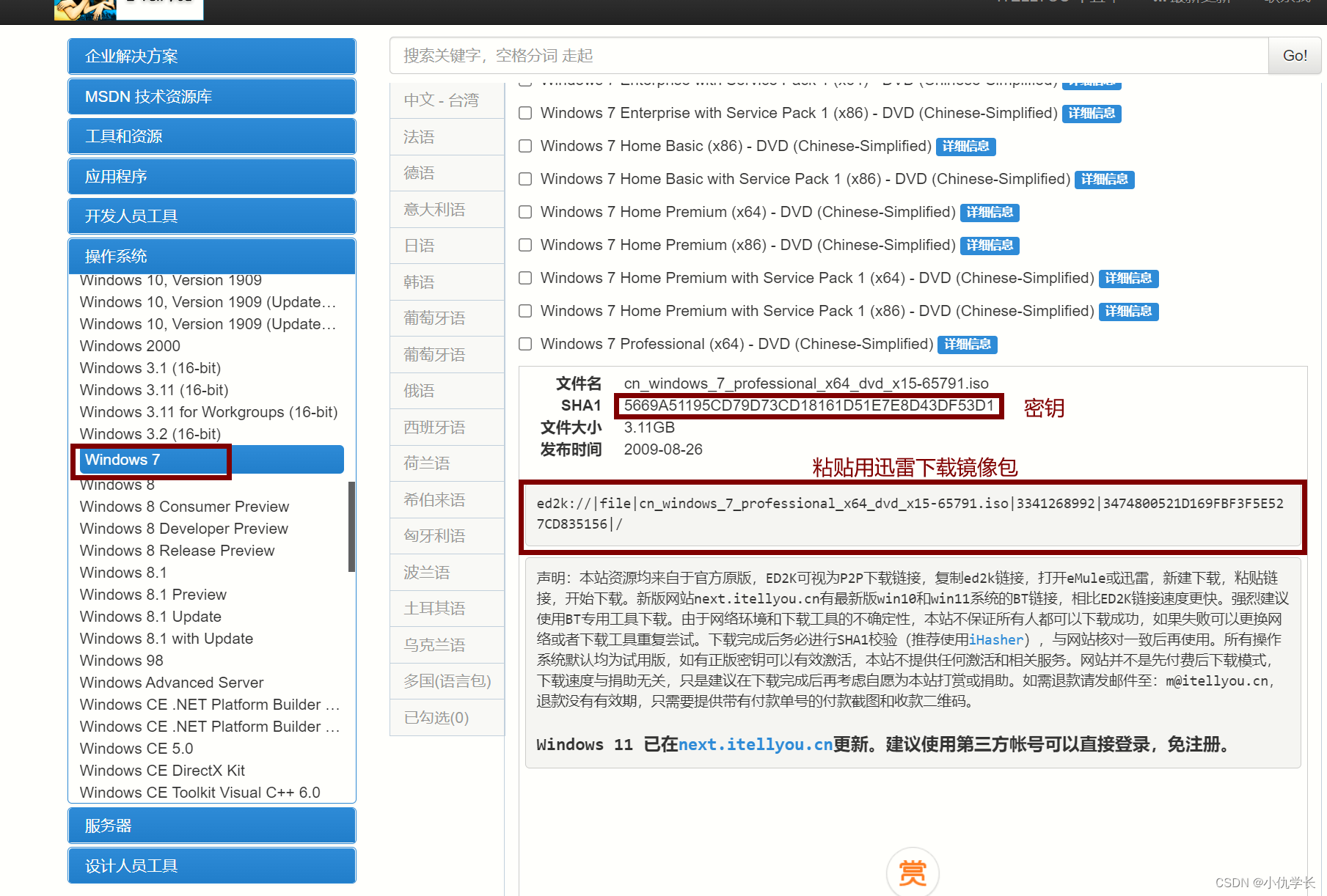
VMware安装windows操作系统
一、下载镜像包 地址:镜像包地址。 找到需要的版本下载镜像包。 二、安装 打开VMware新建虚拟机,选择用镜像文件。将下载的镜像包加载进去即可。...

历时半年,我发布了一款习惯打卡小程序
半年多前,我一直困扰于如何记录习惯打卡情况,在参考了市面上绝大多数的习惯培养程序后,终于创建并发布了这款习惯打卡小程序。 “我的小日常打卡”小程序主要提供习惯打卡和专注训练功能。致力于培养用户养成一个个好的习惯,改掉…...

被DDOS了怎么办 要如何应对
DDoS攻击的特点和类型 1. 特点 DDoS攻击的特点是通过大量合法的请求或者无效的请求,消耗目标服务器的网络带宽和系统资源,使其无法正常运行。攻击者通常使用多个主机发起攻击,以达到更高的攻击效果。 2. 常见类型 (1)S…...

时间序列预测实战(十七)PyTorch实现LSTM-GRU模型长期预测并可视化结果(附代码+数据集+详细讲解)
一、本文介绍 本文给大家带来的实战内容是利用PyTorch实现LSTM-GRU模型,LSTM和GRU都分别是RNN中最常用Cell之一,也都是时间序列预测中最常见的结构单元之一,本文的内容将会从实战的角度带你分析LSTM和GRU的机制和效果,同时如果你…...

【免费使用】基于PaddleSeg开源项目开发的人像抠图Web API接口
基于PaddleSeg开源项目开发的人像抠图API接口,服务器不存储照片大家可放心使用。 1、请求接口 请求地址:http://apiseg.hysys.cn/predict_img 请求方式:POST 请求参数:{"image":"/9j/4AAQ..."} 参数是jso…...

Centos7 Python环境和yum修复
1、删除现有残余包 [rootlocalhost ]# rpm -qa|grep python|xargs rpm -ev --allmatches --nodeps[rootlocalhost ]# rpm -qa|grep yum|xargs rpm -ev --allmatches --nodeps[rootlocalhost ]# whereis python |xargs rm -frv[rootlocalhost ]# whereis python ##验证清除&…...
Ubuntu下使用protoBuf
一、protobuf简介: 1.1 protobuf的定义: protobuf是用来干嘛的? protobuf是一种用于 对结构数据进行序列化的工具,从而实现 数据存储和交换。 (主要用于网络通信中 收发两端进行消息交互。所谓的“结构数据”是指类…...

【新手攻略】2026年OpenClaw/Hermes Agent京东云4分钟快速集成方法
【新手攻略】2026年OpenClaw/Hermes Agent京东云4分钟快速集成方法。OpenClaw(前身为Clawdbot/Moltbot)作为开源、本地优先的AI助理框架,凭借724小时在线响应、多任务自动化执行、跨平台协同等核心能力,成为个人办公与轻量团队协作…...

电话号码精确定位:免费开源工具的实用指南与深度解析
电话号码精确定位:免费开源工具的实用指南与深度解析 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirro…...
)
Vue2.0 + ElementUI登录页开发避坑指南:我踩过的5个坑(路由守卫、样式冲突、表单验证)
Vue2.0 ElementUI登录页开发避坑指南:我踩过的5个坑 去年接手公司后台管理系统重构时,我负责的第一个模块就是登录页。本以为照着ElementUI文档复制粘贴就能搞定,结果从路由守卫到样式污染,踩的坑比写的代码还多。今天就把这些&q…...
配置与避坑指南)
RTK定位中的RTCM3.2:GPS、BDS、Galileo多系统MSM电文(1074/1124等)配置与避坑指南
RTK定位中的RTCM3.2:GPS、BDS、Galileo多系统MSM电文配置实战 在无人机航测、自动驾驶高精定位和精准农业机械控制等场景中,工程师们常遇到这样的困境:明明使用了多模GNSS接收机,RTK固定率却始终达不到预期。去年我们在新疆某智慧…...

告别find命令卡顿!为ARM路由器打造超轻量fd静态链接版本
告别find命令卡顿!为ARM路由器打造超轻量fd静态链接版本 【免费下载链接】fd A simple, fast and user-friendly alternative to find 项目地址: https://gitcode.com/GitHub_Trending/fd/fd 在嵌入式设备如ARM架构路由器上使用传统find命令时,你…...

一念成仙 攻略 核心地图移动与高级传送技巧完全指南
在众多文字修仙爱好者寻找优质玩法体验时,一念成仙凭借其庞大且真实的地图交互系统脱颖而出。为了帮助新手与进阶玩家在广袤的修仙世界中高效跑图,本篇一念成仙 攻略将结合深度的实际游玩经验,为您提供最专业、最可靠的地图移动与传送系统解析…...

CUDA 11.7 自定义安装避坑指南:如何把临时文件和核心组件都请出C盘
CUDA 11.7 自定义安装避坑指南:如何把临时文件和核心组件都请出C盘 每次安装CUDA工具包时,C盘空间总会神秘消失几个GB——这几乎是所有深度学习开发者的共同困扰。尤其当你的C盘是256GB甚至更小的SSD时,这种"空间吞噬"现象足以让人…...
)
Excel数据分析师必看:从入门到精通Power Pivot的5个核心DAX函数实战(含CALCULATE、RELATED避坑指南)
Excel数据分析师进阶指南:5个核心DAX函数实战精解与避坑手册 当你第一次在Power Pivot中看到DAX公式时,可能会被它看似简单的语法迷惑——直到你尝试构建第一个复杂计算指标。与Excel函数不同,DAX的真正威力隐藏在筛选上下文这个核心概念中。…...

5分钟掌握HsMod:炉石传说终极优化插件完全指南
5分钟掌握HsMod:炉石传说终极优化插件完全指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 如果你是一名炉石传说玩家,是否曾为繁琐的开包过程而烦恼?…...

手机号码定位革命性工具:从陌生来电到精准地理定位的智能解决方案
手机号码定位革命性工具:从陌生来电到精准地理定位的智能解决方案 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.…...