【论文阅读笔记】Emu Edit: Precise Image Editing via Recognition and Generation Tasks
【论文阅读笔记】Emu Edit: Precise Image Editing via Recognition and Generation Tasks
- 论文阅读笔记
- 论文信息
- 摘要
- 背景
- 方法
- 结果
- 额外
- 关键发现
- 作者动机
- 相关工作
- 1. 使用输入和编辑图像的对齐和详细描述来执行特定的编辑
- 2. 另一类图像编辑模型采用输入掩码作为附加输入 。
- 3. 为了提供更直观和用户友好的界面,并显着增强了人类易用性
- 方法/模型
- 任务分类
- 指令生成
- 图像对生成
- Grounded Precise Editing
- Region-Based Editing Tasks
- Free-Form Editing Tasks
- Vision tasks
- 数据过滤
- Method
- 网络架构
- 学习任务嵌入
- 任务反转
- Sequential Edit Thresholding序列修改阈值
- 实验设计
- 指标
- 评价
- baseline
- 消融研究
- 讨论
- 展望
- 启发
- 训练代价
- 总结
论文阅读笔记
- Emu edit是一篇图像编辑Image Editing的文章,和instruct pix2pix类似,选择了合成数据作为训练数据,不是zero-shot任务,并进一步将多种任务都整合为生成任务,从而提高模型的编辑能力。本篇文章的效果应该目前最好的,在local和global编辑甚至其他代理任务(分割、边缘检测等)上都取得了比较惊艳的效果。
- 个人比较关注合成数据的制作流程,能够很好的解决现有真实数据数量和泛化能力受限的问题。
- 文章的很多细节在附录,值得好好研究。
- 数据集制造的工程量太大了!!!
论文信息
- 论文标题:Emu Edit: Precise Image Editing via Recognition and Generation Tasks
- 作者:GenAI. Meta
- 发表年份:2023
- 期刊/会议:暂无
- 项目主页(更多可视化结果):https://emu-edit.metademolab.com/
- 数据集(验证):https://huggingface.co/datasets/facebook/emu_edit_test_set_generations
- code:未发布

摘要
背景
基于指令的图像编辑需求很大,但是在编辑准确性上还受限。
方法
提出了一种多任务图像编辑模型Emu Edit,将多种任务(基于区域的编辑、自由形式的编辑和计算机视觉任务)表述为生成任务,并学习任务嵌入(有点类似unicontrolnet指示不同任务的编码)以指导生成过程走向正确的编辑类型。
结果
我们表明 Emu Edit 可以推广到新任务,例如图像修复、超分辨率和编辑任务的组合,并在图像编辑任务中取得了最先进水平
额外
发布了一个新的具有挑战性和通用的基准,其中包括7个不同的图像编辑任务。
关键发现
- 多任务学习,为每个任务开发不同的数据处理pipeline,允许搜集更为多样化和精确的训练集。
- 在所有任务上训练单个模型比在每个任务上独立训练专家模型产生更好的结果。
- 检测、分割等计算机视觉任务显着提高了图像编辑性能。(ps. 可以在其他任务上进行尝试)
- 证明了学习到的任务嵌入显着提高了我们的模型从自由形式指令中准确推断适当的编辑类型并执行正确的编辑的能力
- 任务嵌入可以在训练好的模型上面经过few-shot训练进行更新,如超分,轮廓检测
作者动机
InstructPix2Pix这样的基于指令的图像编辑模型旨在处理任何给定的指令,但它们通常难以准确解释和执行此类指令。此外,它们的泛化是有限的,往往缺乏对与他们接受过培训的任务的轻微偏差。
为了解决这些差距,引入了 Emu Edit,第一个在大量多样的任务上训练的图像编辑模型,包括图像编辑和计算机视觉任务。
Emu Edit 在遵守编辑指令和保留原始图像的视觉保真度方面都提供了实质性的改进。
两个基准上的自动度量和人类主观评价表示Emu Edit在基于指令的图像编辑中取得了最先进的结果。
相关工作
(很好地总结了一些有影响力的工作)
1. 使用输入和编辑图像的对齐和详细描述来执行特定的编辑
- Prompt2prompt(P2P)将输入标题注意力图注入目标标题注意力图。
- Null-Text Inversion 使用零文本嵌入反转输入图像以支持使用p2p进行真实图像的编辑。
- Plug-and-Play(PNP)除了注意图外,还注入空间特征,并在全局编辑上获得了更好的性能。
- Imagic 微调扩散模型以支持复杂的文本指令。
- EDICT提出了一种基于两个噪声向量的图像反演,以实现更好的图像重建和文本忠实度。
2. 另一类图像编辑模型采用输入掩码作为附加输入 。
- blended diffusion通过在未屏蔽区域混合输入图像来修改扩散步骤。
- Imagen Editor 和 SmartBrush 微调文本到图像模型以输入图像和掩码为条件。
虽然上面详述的基于文本的图像编辑方法使人类能够编辑图像,但它们经常表现出不一致的性能,并且需要多个输入,例如输入图像和目标图像的对齐和详细描述,或者有时是输入掩码。
3. 为了提供更直观和用户友好的界面,并显着增强了人类易用性
- InstructPix2Pix 引入了一个可指示的图像编辑模型。他们通过利用 GPT-3和 Prompt-to-Prompt开发了这个模型,以生成用于基于指令的图像编辑的大型合成数据集,并使用数据集来训练可指示的图像编辑模型。
- MagicBrush通过要求人类使用在线图像编辑工具开发了一个手动注释的指令引导图像编辑数据集。在这个数据集上微调 InstructPix2Pix 可以提高图像编辑能力。
最先进的图像编辑模型仍然难以准确解释和精确地执行编辑指令。
Emu Edit与仅关注图像编辑(pix2pix, magicbrush)的先前工作不同,训练模型执行各种任务并学习非常多样化能力。训练过程和数据集的质量和多功能性,以及改进的多任务学习架构,使其能够在性能上取得很大的飞跃,并区别于该领域的先前工作。
方法/模型
- 训练一个健壮和准确的图像编辑模型需要高度多样化的输入图像数据集、编辑指令和输出编辑的图像。
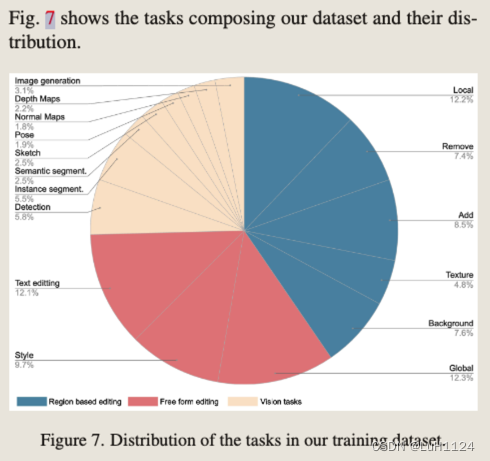
- 构建了一个包含 16 个不同的任务和 10 亿个示例的新数据集。数据集中的每个示例 (cI , cT , x, i) 都包含一个输入图像 cI 、文本指令 cT 、目标图像 x 和任务索引 i(16个不同任务 )。
任务分类

指令生成
- 通过Llama2利用上下文学习为每个任务创建一个特定于任务的代理。具体来说,我们向LLM提供了一个任务描述、一些特定于任务的范例和一个真实的图像标题。为了增加多样性,我们对样本进行采样并随机化它们的顺序。给定这样的输入,我们期望LLM输出(1)编辑指令,(2)理想输出图像的输出标题,(3)应该更新或添加到原始图像中
通过以下方式提供 LLM:(1)描述输入和输出格式的系统消息,(2)介绍消息,其中我们概述了输出中每个键的问题和目标,以及 (3) 与 LLM 的对话历史上下文包含可能输出的示例。然后,我们用一个新的输入标题提示LLM,并要求它提供一个新的指令。为了鼓励 LLM 生成的指令中更多的方差和随机性,我们对历史上下文执行以下:(1)示例之间的混洗,(2)随机抽样 60% 的示例,以及(3)从一组单词中随机更改示例中的动词。
图像对生成阶段使用图像标题,以及指令生成阶段生成的LLM对应的输出标题“原始对象”和“编辑对象”
图像对生成
- 目标是生成符合编辑指令的输入和编辑图像对,并保留应该保持完整的图像元素
- 为应对不同任务所需的数据集,为每个任务开发了一种新的生成技术
Grounded Precise Editing
P2P 依赖于输入图像标题和编辑图像标题中的词对词对齐来构建掩码修改注意力图,但词对词的约束并不强,无法保留结构和身份。Emu edit提出了一种掩码提取方法,该方法应用于编辑过程之前。
(i)通过 LLM 从编辑指令中识别编辑区域并在图像生成之前创建相应的掩码
基于区域的编辑包括所有在有限区域内对图像进行更改的编辑指令,其余图像保持不变。为了在保留其余细节的同时调整特定对象或位置,我们在编辑过程中利用了局部区域的掩码。我们利用DINO来检测需要屏蔽的区域,使用LLM中提取出的Object字段对应的“原始对象”和“编辑对象”字段。
使用基于掩码的注意力控制来生成编辑图像时,它通常用相似的对象类型替换对象,而不是删除它。例如,当屏蔽狗周围的区域时,我们将编辑限制在该特定区域,从而产生狗的新变体。我们通过创建三种不同类型的掩码来解决这个问题。第一个采用由DINO和SAM创建的原始精确掩码。第二个涉及通过膨胀将掩码扩展到添加的对象之外,然后使用高斯模糊对其进行细化。最后,第三种方法使用对象周围的边界框(由 DINO 创建),从而消除了特定形状的约束。我们生成多个图像,每个图像都有不同的掩码,然后过滤。
在某些情况下,LLM 生成的“原始对象”和“编辑对象”包含所有格词(例如,“狗的尾巴”)。我们观察到,在许多情况下,DINO 在这些情况下很难检测到对象。为此,我们对LLM使用额外的提示来识别没有拥有的对象。
(ii)在编辑过程中集成这些掩码,以确保编辑区域与原始图像无缝融合。
基于掩码的注意力控制:保持非编辑区域的噪声来自原图,编辑区域的噪声图像注意力影响之后的。遵循 P2P 并在所有标记上注入自注意力层。交叉注意力层注入输入和输出字幕之间的公共标记
此外:面对不同的编辑挑战,例如添加或删除对象,需要量身定制的解决方案。(见附录的7.2.3-5)
Region-Based Editing Tasks
1.Local/Texture
给定输入标题,我们首先生成输入图像。然后,我们利用“原始对象”(如第 7.2 节所述)来提取局部掩码(使用第 7.2.2 节)。最后,我们使用获得的掩码应用基于掩码的注意力控制来生成编辑的图像。我们重复这个过程 10 次迭代,在每次迭代中,我们从 [4, 8] 中采样引导尺度,从 [0.3, 0.9] 中采样 Nc 和 Ns(执行交叉注意力和自注意力的步骤N),并从 [0.02, 0.2] (在这个阶段执行混合操作)混合。
2.添加
提取“编辑对象”(在这种情况下添加的对象)的掩码是不可能的,因为输入图像中不存在对象。
为了克服这一挑战,我们解决这个问题如下: 1. 我们使用输出标题生成输出图像 y。请注意,图像 y 包含“编辑对象”。2.提取y中“编辑对象”的掩码m。3.我们应用基于掩码的注意力控制使用输入标题、图像 y 和掩码 m 生成输入图像 x 这种方法的主要问题是,在某些情况下,我们生成对象的不同版本,而不是消除它
3.删除
生成数据的过程类似于 Add 任务的过程。唯一的区别是我们首先生成图像 x(使用输入标题),然后提取对象的掩码 m 以去除,最后使用输出标题、图像 x 和掩码 m 生成图像 y。
4.背景
给定一个输入图像、输入标题和编辑的对象(在这种情况下,替代背景),我们首先提取背景掩码。为了消除轮廓中的伪影,我们应用了扩展背景掩码的最小滤波器,然后使用高斯滤波对其进行平滑处理。接下来,我们将图像和生成的掩码作为输入提供给修复模型,该模型创建一个新的背景。最后,我们将输入图像和编辑后的图像混合在掩码区域。我们生成了 10 张编辑图像,具有不同的噪声和引导尺度,并根据 CLIP 指标选择最佳图像。
Free-Form Editing Tasks
4.全局
全局任务包括不限于特定区域的编辑指令。因此,我们使用带有空白掩码的基于掩码的注意力控制生成图像对。混合是从 [0.1, 0.2] 中采样的,以鼓励更好的图像忠实度。我们从 [0.4, 0.9] 中采样 Nc 和 Ns。
5.风格
我们使用即插即用(PNP)来生成风格化的编辑图像。该任务的目标是在保留图像结构的同时,根据编辑指令改变图像样式。我们使用DDIM反演将PNP应用于真实的输入图像。对于每个样本,我们生成 10 个编辑图像,每个图像都具有以下采样参数:从 [6.5, 110] 中采样的引导尺度,Ns 从 [0.5, 1.0] 中采样,并且要共享的空间特征部分设置为 0.8。
6.文本编辑
文本编辑任务包括向图像添加文本,从图像中删除文本,并用另一个文本替换一个文本。此外,我们允许用户选择添加文本的字体和颜色。我们使用 OCR [7] 生成输入图像 x 中找到的文本的掩码 m。我们利用掩码 m 来修复图像,表示新图像 y。为了添加文本,我们使用 y 作为输入图像,x 作为编辑图像。为了删除文本和替换文本,我们使用反向。在替换文本时,我们将图像 y 中的内嵌区域与特定字体和颜色的文本叠加。
Vision tasks
7.检测/分割
给定一个输入图像,我们使用DINO检测“编辑对象”。为了将检测形式化为生成任务,我们通过绘制检测到的边界框来创建一个新的图像 y。对于分割,我们绘制检测到的对象像素。
8.颜色
我们将颜色任务定义为对图像整体颜色的修改。我们通过应用以下过滤器生成样本:(1)颜色过滤器——随机改变图像的亮度、对比度、饱和度和色调,(2)模糊——应用随机大小的高斯核,以及(3)锐化和散焦。
9.Image Translation
涉及从条件图像到目标图像的双向映射。例如,草图到图像和图像到草图。我们遵循ControlNet来生成深度图、分割图、人体姿势、法线图和草图。
数据过滤
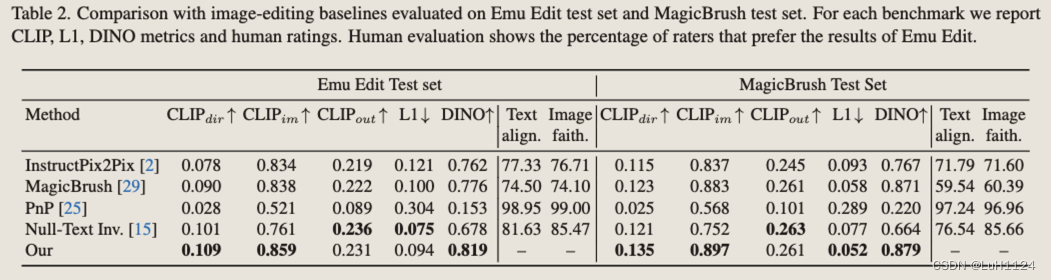
(i)使用任务预测器用应该属于另一个任务的指令重新分配样本,(ii)应用 CLIP 过滤指标
(iii)采用基于输入图像深度图和编辑图像之间的 L1 距离的结构保留过滤
(iv)应用图像检测器来验证元素的存在(在 Add 任务中),根据指令中指定的对象,元素的缺失(在 Remove 任务中)或替换(在 Local 任务中)。
此过程过滤掉 70% 的数据,从而产生 1000 万个样本的最终数据集。
Method
- 为了为模型提供将生成过程引导到正确任务的强条件,建议为每个任务学习一个唯一的任务嵌入,我们将其集成到模型中。
- 在训练期间,任务嵌入与模型权重一起学习。训练后,Emu Edit 能够通过小样本学习新任务嵌入来适应新任务,其余模型被冻结。
- 最后,介绍了一种在多轮编辑场景中保持生成图像质量的方法。
网络架构
- 基于Emu扩散模型
- 为了将Emu转换为基于指令的图像编辑模型,我们将其限制在待修改的cI和指令cT上(类似pix2pix,调整输入Uner的输入通道数,新的权重被初始化为0,使用a zero signalto-noise ratio (SNR)技术) min θ E y , ϵ , t [ ∥ ϵ − ϵ θ ( z t , t , E ( c I ) , c T ) ∥ 2 2 ] \min _\theta \mathbb{E}_{y, \epsilon, t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, E\left(c_I\right), c_T\right)\right\|_2^2\right] θminEy,ϵ,t[∥ϵ−ϵθ(zt,t,E(cI),cT)∥22]
学习任务嵌入
在训练期间,给定我们数据集中的样本,我们使用任务索引 i 从嵌入表中获取任务的嵌入向量 vi,并将其与模型权重联合优化。我们通过将任务嵌入通过 U-Net、εθ 的附加条件引入来做到这一点。具体来说,我们通过交叉注意交互将任务嵌入集成到 U-Net 中,并将其添加到时间步嵌入中。优化问题更新为
min θ E y , ϵ , t [ ∥ ϵ − ϵ θ ( z t , t , E ( c I ) , c T , v i ) ∥ 2 2 ] \min _\theta \mathbb{E}_{y, \epsilon, t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, E\left(c_I\right), c_T, v_i\right)\right\|_2^2\right] θminEy,ϵ,t[∥ϵ−ϵθ(zt,t,E(cI),cT,vi)∥22]
(1)当需要纹理编辑时,没有任务条件的模型可能会执行全局编辑
(2)当需要全局编辑时,它可能会选择分割
(3)在本地编辑更适合的情况下实现样式编辑。

任务反转
给定新任务的几个示例,我们学习了一个新的任务嵌入 vnew。冻结模型权重,并且仅通过任务嵌入将其适应任务。(实验证明不学习也能泛化新任务)
min θ E y , ϵ , t [ ∥ ϵ − ϵ θ ( z t , t , E ( c I ) , c T , v n e w ) ∥ 2 2 ] \min _\theta \mathbb{E}_{y, \epsilon, t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, E\left(c_I\right), c_T, v_{new}\right)\right\|_2^2\right] θminEy,ϵ,t[∥ϵ−ϵθ(zt,t,E(cI),cT,vnew)∥22]
Sequential Edit Thresholding序列修改阈值
多次对同一图像进行序列化编辑会由于累计error产生伪影,Emu Edit设置了一个像素编辑阈值,超过一定程度才使用上次编辑结果,否则还使用上次的输入图像。文章中的fig12展示了该项更详细的消融实验。


实验设计
- 评估方法在基于指令的图像编辑任务上的性能
- 一项全面的消融研究,以评估不同贡献的有效性(消除了计算机视觉任务对图像编辑任务模型性能的贡献、学习任务嵌入的重要性以及多任务学习对基于指令的图像编辑的影响)
- 数据生成管道消融实验
- 学习新任务的能力
指标
(i) CLIP文本图像方向相似度(CLIPdir) -测量字幕变化与图像变化之间的一致性
(ii) CLIP图像相似度(CLIPimg) -测量编辑图像和输入图像之间的变化
(iii) CLIP输出相似度(CLIPout) -测量编辑后的图像与输出标题的相似度
(iv)输入图像和编辑图像之间的L1像素距离
(v) DINO输入和编辑图像的DINO嵌入之间的相似性。
(vi)人类评估者评估文本对齐和图像忠实度
评价
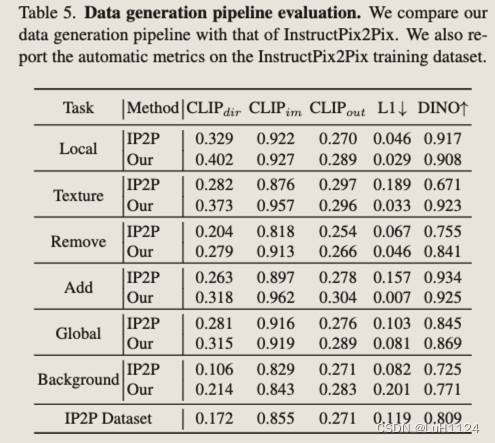
MagicBrush 测试集和Emu Edit 基准测试的结果,认为pix2pix的评价基准并不友好
- MagicBrush使用来自MS-COCO基准和注释器定义的指令的不同真实输入图像集。在数据收集期间,注释者旨在使用DALLE-2 图像编辑平台来生成编辑的图像,基准偏向于 DALLE-2 编辑器可以成功遵循的编辑指令,这可能会损害其多样性和复杂性。
- Emu 编辑基准。收集偏差降低且多样性较高的数据集,首先定义了七种不同类别的潜在图像编辑操作:背景更改(背景)、全面的图像更改(全局)、样式更改(样式)、对象删除(Remove)、对象添加(Add)、本地化修改(Local)和颜色/纹理更改(Texture)。利用MagicBrush基准的不同输入图像集,对于每个编辑操作,人工设计相关、创造性和具有挑战性的指令。人工过滤具有不相关指令的示例。最后,为了支持对需要输入和输出标题的方法的评估,我们还收集了输入标题和输出标题。这样做时,我们要求注释者确保字幕捕获图像中的两个重要元素,以及应该根据指令更改的元素。已公开发布以支持更好地评估基于指令的图像编辑模型。
baseline
InstructPix2Pix
MagicBrush
PNP
P2P 的 Null-Text 反演修改

消融研究
-
视觉任务的重要性
(i)检测和分割任务可以增强局部编辑能力(ii)图像到图像翻译任务可以增强自由模式下的编辑 -
任务嵌入的重要性,任务嵌入有助于明确编辑目标

-
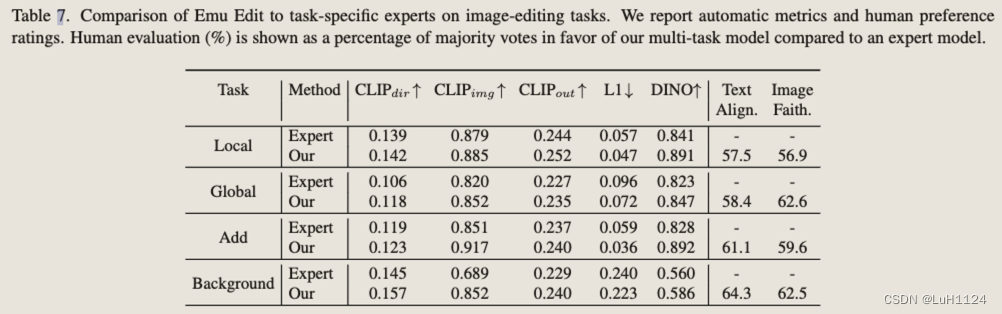
多任务与专家模型比较,几乎全面超越
-
消融了参与多任务训练方案的任务数量,任务数越多,效果提升越好
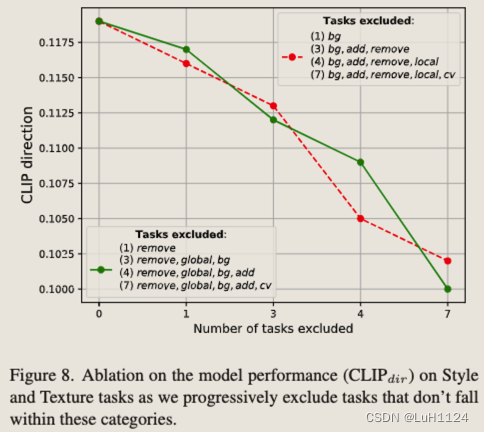
-
新任务的few-shot fintune,100个样本下的finetune足以比肩专家模型
讨论
展望
更好地和LLM相结合,这种增强对于编辑任务特别有用,这些任务需要从输入图像中进行更复杂的推理,例如计数对象或执行复杂的、高度详细的任务。
启发
- 多任务学习有助于模型更好地理解自然语言指令以执行更精准的编辑
- 它能够以最小的示例推广到图像修复和超分辨率等新任务,进一步证明了其多功能性和高级理解。
训练代价
使用Emu的缩小版本,该版本以 CLIP ViT-L [18] 和 T5-XL [19] 为条件,并以 512 × 512 的分辨率生成图像。通过连接到pix2pix之后的输入通道来调整它以获得图像输入。通过交叉注意和时间步嵌入来调节文本和任务嵌入。对于训练,使用批量大小为 512 的 Adam 优化器。我们使用 2e-5 的学习率为,余弦衰减时间表和 2,000 次迭代的线性预热。训练跨越 48,000 步。
总结
总的来说,证明了多任务学习对于图像编辑有着正向的提升,能够更好的理解文本指令。同时更类似于一个backbone,few-shot的finetuning就可以迁移到其他新任务。
相关文章:
【论文阅读笔记】Emu Edit: Precise Image Editing via Recognition and Generation Tasks
【论文阅读笔记】Emu Edit: Precise Image Editing via Recognition and Generation Tasks 论文阅读笔记论文信息摘要背景方法结果额外 关键发现作者动机相关工作1. 使用输入和编辑图像的对齐和详细描述来执行特定的编辑2. 另一类图像编辑模型采用输入掩码作为附加输入 。3. 为…...

python:列表的拷贝详解
python:列表的拷贝详解 文章目录 python:列表的拷贝详解方法1:直接赋值()方法2:浅拷贝(.copy方法)格式原理注意 方法3:深拷贝(.deepcopy方法)格式…...

zip4j压缩使用总结
一、引入依赖 <dependency><groupId>net.lingala.zip4j</groupId><artifactId>zip4j</artifactId><version>1.3.1</version></dependency>二、使用添加文件(addFiles)的方式生成压缩包 /*** Author wan…...
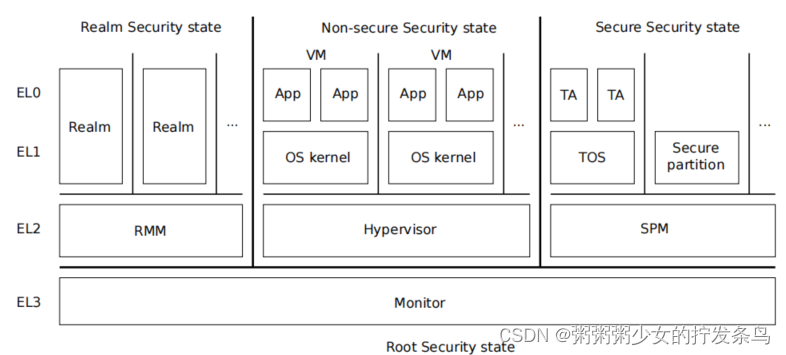
【第一部分:概述】ARM Realm Management Monitor specification
目录 概述机密计算系统软件组成MonitorRealmRealm Management Monitor (RMM)Virtual Machine (VM)HypervisorSecure Partition Manager (SPM)Trusted OS (TOS)Trusted Application (TA) Realm Management Monitor 参考文献 概述 RMM是一个软件组件,它构成了实现ARM…...
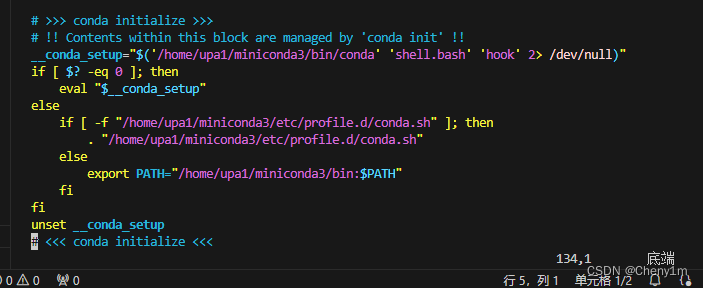
切换服务器上自己用户目录下的 conda 环境和一个外部的 Conda 环境
如果我们有自己的 Miniconda 安装和一个外部的 Conda 环境(比如一个全局安装的 Anaconda),我们可以通过修改 shell 环境来切换使用它们。这通常涉及到更改 PATH 环境变量,以便指向你想要使用的 Conda 安装的可执行文件:…...

移动端的自动化基于类实现启动一次应用跑全部用例
1.unittest框架 class TestStringMethods(unittest.TestCase): def setUp(self) -> None: # 每一条测试用例开始前执行 print("setup") def tearDown(self) -> None: # 每一条测试用例结束后执行 print("teardown") …...

Python与设计模式--抽象工厂模式
Python与设计模式–抽象工厂模式 一、快餐点餐系统 想必大家一定见过类似于麦当劳自助点餐台一类的点餐系统吧。在一个大的触摸显示屏上,有三类可以选择的上餐品:汉堡等主餐、小食、饮料。当我们选择好自己需要的食物,支付完成后࿰…...
JSP:MVC
一个好的Web应用: 功能完善、易于实现和维护易于扩展等的体系结构 一个Web应用通常分为两个部分: 1. 由界面设计人员完成的表示层(主要做网页界面设计) 2. 由程序设计人员实现的行为层(主要完成本Web应用的各种功能…...

微服务-京东秒杀
1 项目介绍 技术栈 后端 SpringCloud 中Netflix 五大组件: EurekaRibbonHystrixOpenfeignZuul SpringBootSpringSpringMVCMyBatis 数据库 MySQLRedis 前端 html5cssjsjQuery 消息中间件 RabbitMQ 2 项目搭建 项目分析 后端 shop-parent [pom] (商…...
「MACOS限定」 如何将文件上传到GitHub仓库
介绍 本期讲解:如何在苹果电脑上上传文件到github远程仓库 注:写的很详细 方便我的朋友可以看懂操作步骤 第一步 在电脑上创建一个新目录(文件夹) 注:创建GitHub账号、新建github仓库、git下载的步骤这里就不过多赘…...
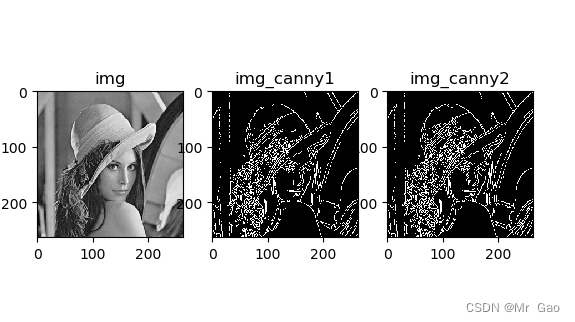
python opencv 边缘检测(sobel、沙尔算子、拉普拉斯算子、Canny)
python opencv 边缘检测(sobel、沙尔算子、拉普拉斯算子、Canny) 这次实验,我们分别使用opencv 的 sobel算子、沙尔算子、拉普拉斯算子三种算子取进行边缘检测,然后后面又使用了Canny算法进行边缘检测。 直接看代码,代…...

【Unity入门】鼠标输入和键盘输入
Unity的Input类提供了许多监听用户输入的方法,比如我们常见的鼠标,键盘,手柄等。我们可以用Input类的接口来获取用户的输入信息 一、监听鼠标输入 GetMouseButtonUp 、GetMouseButtonDown、GetMouseButton input.GetMouseButtonDown和 inp…...

芯知识 | MP3语音芯片IC的优势特征及其在现代科技应用中的价值
随着科技的飞速发展,MP3语音芯片作为一种高度集成的音频处理解决方案,在现代电子产品中发挥着越来越重要的作用。本文将分析MP3语音芯片的优势特征,并探讨其在各个领域的应用价值。 一、MP3语音芯片的优势特征 MP3语音芯片具有多种显著的优…...

C语言进阶之路-基本数据小怪篇
目录 一、学习目标: 二、数据基本类型 整型 浮点型 / 实型 字符 字符串 布尔型数据 三、重要的杂七杂八知识点 常量与变量 标准输入 sizeof运算符: 类型转换 数据类型的本质 整型数据尺寸 可移植性整型 拿下第一个C语言程序 总结 一、学…...
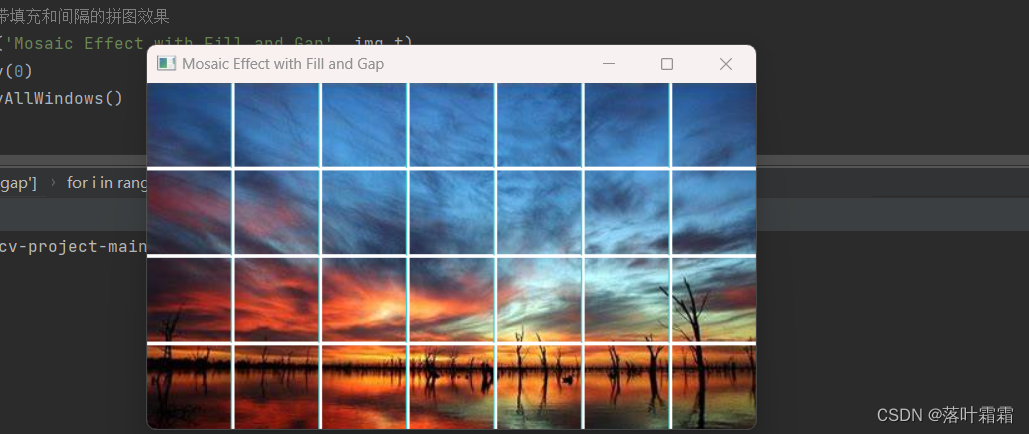
【OpenCV实现图像:使用OpenCV生成拼图效果】
文章目录 概要通用配置不考虑间隔代码实现考虑间隔代码实现小结 概要 概要: 拼图效果是一种将图像切割为相邻正方形并重新排列的艺术效果。在生成拼图效果时,可以考虑不同的模式,包括是否考虑间隔和如何处理不能整除的部分。 不考虑间隔&a…...
【AOSP】生成签名文件release key,通过Android源码对apk进行签名
简介 现在apk都需要签名,Flutter做的项目官方规定编译apk必须签名。 签名的好处: 应用来源验证: 应用签名允许Android系统验证应用的来源。每个应用都使用开发者的私钥进行签名,而应用的签名信息包含在应用的APK文件中。当用户尝…...

深度学习之基于Tensorflow银行卡号码识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介银行卡号码识别的步骤TensorFlow的优势 二、功能三、系统四. 总结 一项目简介 # 深度学习基于TensorFlow的银行卡号码识别介绍 深度学习在图像识别领域取得…...

第95步 深度学习图像目标检测:Faster R-CNN建模
基于WIN10的64位系统演示 一、写在前面 本期开始,我们学习深度学习图像目标检测系列。 深度学习图像目标检测是计算机视觉领域的一个重要子领域,它的核心目标是利用深度学习模型来识别并定位图像中的特定目标。这些目标可以是物体、人、动物或其他可识…...

设计模式—里氏替换原则
1.概念 里氏代换原则(Liskov Substitution Principle LSP)面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。 LSP是继承复用的基石,只有当衍生类可以替换掉基类,软件单位的功能不受到影…...

PyTorch包
进入PyTorch的官网: pytorch GitHub 点击GitHub: 进入PyTorch的主目录: 进入Vision reference: detection: 这就是我们在训练过程中会使用到的文件了:...

告别内核打印:用devmem2在嵌入式Linux上直接读写寄存器的保姆级教程
嵌入式Linux寄存器调试利器:devmem2从编译到实战全解析 调试嵌入式Linux驱动时,最让人头疼的莫过于反复修改内核代码、添加打印语句来查看寄存器状态。这种传统方法不仅效率低下,还会拖慢整个开发流程。想象一下,当你需要快速验证…...
)
从Slab到内存池:深入拆解Linux内核如何高效管理‘碎片化’小内存(以task_struct为例)
从Slab到内存池:深入拆解Linux内核如何高效管理‘碎片化’小内存(以task_struct为例) 在操作系统内核的开发中,内存管理一直是性能优化的核心战场。尤其对于像task_struct这样频繁创建和销毁的小内存对象,传统的内存分…...

Flink 1.14 SQL Client 集成 Hive 3.x 全流程踩坑与终极解决方案
Flink 1.14 SQL Client 集成 Hive 3.x 全流程踩坑与终极解决方案 当企业级数据平台需要同时处理实时流计算和历史批处理时,Flink与Hive的深度集成成为刚需。然而在实际部署中,特别是面对CDH/HDP等商业发行版的Hive 3.x环境时,版本兼容性和依赖…...

从毕业设计到实战:手把手教你用SolidWorks复现一个220V电动扳手的传动系统
从毕业设计到实战:手把手教你用SolidWorks复现220V电动扳手传动系统 在机械设计领域,毕业设计往往停留在理论计算和二维图纸阶段,而实际工程应用需要将理论转化为可制造的三维模型。本文将带你完整走完这个转化过程,使用SolidWork…...

Python机器学习怎么防止数据泄漏_确保Scaler在Pipeline内拟合
StandardScaler 单独调用 fit 会泄漏数据,因其在 Pipeline 外对整个训练集拟合,导致交叉验证中各 fold 使用了其他 fold 的统计信息,造成评估虚高;必须将其嵌入 Pipeline,确保每次 fit 仅基于当前 fold 数据。为什么 S…...

用Python玩转相控阵天线:稀布阵列与稀疏阵列的实战代码与效果对比
用Python玩转相控阵天线:稀布阵列与稀疏阵列的实战代码与效果对比 相控阵天线技术正从军工领域加速渗透至5G通信和卫星互联网等民用场景。与传统机械扫描天线相比,相控阵通过电子控制波束指向的特性,使其在响应速度和多目标追踪能力上具有革…...

Snap.Hutao终极使用指南:免费开源的原神工具箱完全攻略
Snap.Hutao终极使用指南:免费开源的原神工具箱完全攻略 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hu…...
)
用MSP430和Cyclone IV FPGA实现单相逆变电源的PID闭环控制(附完整代码)
MSP430FPGA架构下的单相逆变电源PID闭环控制实战解析 在电力电子控制领域,实现高精度电压输出一直是工程师面临的挑战。当MSP430微控制器遇上Cyclone IV FPGA,这种混合架构为单相逆变电源的控制带来了独特优势——MCU负责复杂算法运算,FPGA专…...

构建跨设备游戏流媒体技术栈:Sunshine自托管服务器全解析与实践指南
构建跨设备游戏流媒体技术栈:Sunshine自托管服务器全解析与实践指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一个开源的自托管游戏流媒体服务器&…...

Hunyuan-MT Pro安全审计:本地部署杜绝数据出境与隐私泄露风险
Hunyuan-MT Pro安全审计:本地部署杜绝数据出境与隐私泄露风险 1. 为什么翻译数据安全如此重要 在日常工作和学习中,我们经常需要处理各种语言的文档和内容。无论是商业合同、技术文档、还是个人通信,这些材料往往包含敏感信息。传统的在线翻…...