【LM、LLM】浅尝二叉树在前馈神经网络上的应用
前言
随着大模型的发展,模型参数量暴涨,以Transformer的为组成成分的隐藏神经元数量增长的越来越多。因此,降低前馈层的推理成本逐渐进入视野。前段时间看到本文介绍的相关工作还是MNIST数据集上的实验,现在这个工作推进到BERT上面来了,再次引起兴趣记录一下。该工作将前馈神经基于二叉树结构进行改装,加速前向传播的速度,称为:快速前馈网络(FFF),然后应用FFF,取代BERT中的前馈网络(FF),实现12个神经元加速推理。
快速前馈网络算法概述
快速前馈网络(Fast Feedforward Network,FFF)是由两部分组成的:节点网络集合 N \mathcal{N} N 和叶子网络集合 L \mathcal{L} L。
-
节点网络集合 N \mathcal{N} N 包含了一组节点网络,每个节点网络都是一个 < dim I , n , 1 > \left<\dim_I,n,1\right> ⟨dimI,n,1⟩-前馈网络,并在输出上增加了一个 sigmoid 激活函数。这些节点网络按照平衡的可微分二叉树的形式排列,其中 N m + 1 , 2 n N_{m+1,2n} Nm+1,2n 和 N m + 1 , 2 n + 1 N_{m+1,2n+1} Nm+1,2n+1 是 N m , n N_{m,n} Nm,n 的子节点。
-
叶子网络集合 L \mathcal{L} L 包含了一组叶子网络,每个叶子网络都是一个 < dim I , ℓ , dim O > \left<\dim_I,\ell,\dim_O\right> ⟨dimI,ℓ,dimO⟩-前馈网络。叶子网络没有子节点,它们的输出直接作为 FFF 的输出。
前向传播过程由下面算法控制。

算法的输入包括一个输入样本 ι \iota ι 和根节点 N 0 , 0 N_{0,0} N0,0,输出为该样本在 FFF 中的输出。
算法定义了两个函数: F o r w a r d T Forward_T ForwardT 和 F o r w a r d I {Forward}_I ForwardI。其中, F o r w a r d T {Forward}_T ForwardT 函数用于计算节点的输出,而 F o r w a r d I {Forward}_I ForwardI 函数用于计算节点的指示值(indicator value)。
- 在 F o r w a r d T {Forward}_T ForwardT 函数中,如果当前节点是叶子节点,则直接调用该节点的前馈传播函数 N m , n ( ι ) N_{m,n}(\iota) Nm,n(ι) 来计算输出。否则,首先计算当前节点的输出 c m , n = N m , n ( ι ) c_{m,n}=N_{m,n}(\iota) cm,n=Nm,n(ι),然后递归地调用 F o r w a r d T {Forward}_T ForwardT 函数来计算当前节点的两个子节点的输出,并将它们加权相加作为当前节点的输出。
- 在 F o r w a r d I {Forward}_I ForwardI 函数中,如果当前节点是叶子节点,则直接调用该节点的前馈传播函数 N m , n ( ι ) N_{m,n}(\iota) Nm,n(ι) 来计算输出。否则,首先计算当前节点的输出 c m , n = N m , n ( ι ) c_{m,n}=N_{m,n}(\iota) cm,n=Nm,n(ι),然后根据输出值的大小决定选择哪个子节点进行递归计算。
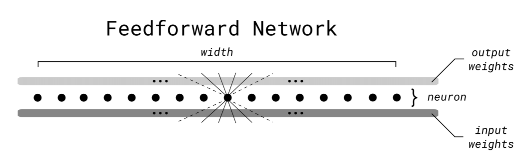
传统前馈神经网络

快速前馈神经网络
与传统的前馈神经网络算法相比,该算法的主要区别在于引入了一个计算节点的指示值。指示值表示了当前节点的输出是否大于等于阈值(这里的阈值为0.5),根据指示值的大小来确定选择哪个子节点进行计算。这种方式可以大大减少计算量,提高前向传播的效率。同时,FFF 是一种具有平衡二叉树结构的前馈神经网络,其中节点网络和叶子网络分别用于处理中间层和输出层的计算。通过利用二叉树结构和递归计算,FFF 可以实现快速的前向传播。
UltraFastBERT
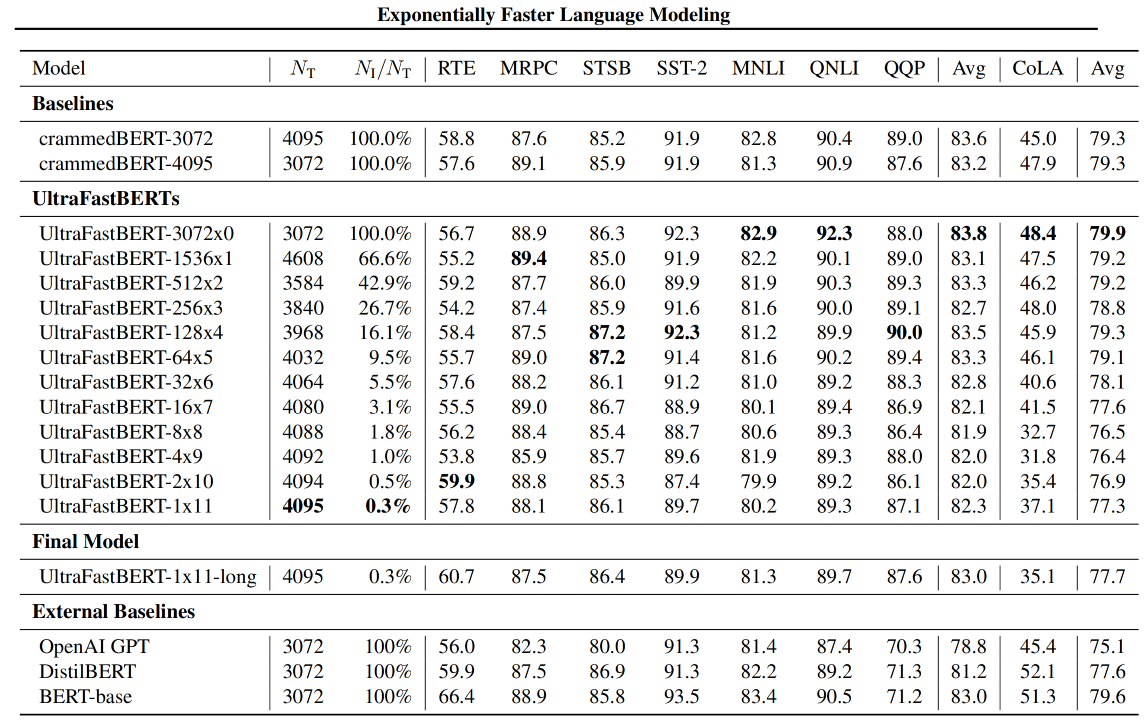
UltraFastBERT,一种BERT变体,在推理过程中使用0.3%的神经元,同时表现 与类似的BERT模型相当。UltraFastBERT选择性地使用4095个神经元中的12个(有选择的执行矩阵乘法(CMM))进行每层推理。这是通过用快速前馈网络(FFFs)取代前馈网络来实现的。

FFF_BMM代码
import torch
from torch import nn
import mathclass FFF(nn.Module):def __init__(self, input_width: int, depth: int, output_width: int, *args, **kwargs):super().__init__(*args, **kwargs)self.input_width = input_widthself.depth = depthself.output_width = output_widthself.n_nodes = 2 ** (depth + 1) - 1self.initialise_weights()def initialise_weights(self):init_factor_l1 = 1.0 / math.sqrt(self.input_width)init_factor_l2 = 1.0 / math.sqrt(self.depth + 1)self.w1s = nn.Parameter(torch.empty(self.n_nodes, self.input_width).uniform_(-init_factor_l1, +init_factor_l1), requires_grad=True)self.w2s = nn.Parameter(torch.empty(self.n_nodes, self.output_width).uniform_(-init_factor_l2, +init_factor_l2), requires_grad=True)def forward(self, x):# the shape of x is (batch_size, input_width)# retrieve the indices of the relevant elementsbatch_size = x.shape[0]current_nodes = torch.zeros((batch_size,), dtype=torch.long, device=x.device)all_nodes = torch.zeros(batch_size, self.depth+1, dtype=torch.long, device=x.device)all_logits = torch.empty((batch_size, self.depth+1), dtype=torch.float, device=x.device)for i in range(self.depth+1):all_nodes[:, i] = current_nodesplane_coeffs = self.w1s.index_select(dim=0, index=current_nodes) # (batch_size, input_width)plane_coeff_score = torch.bmm(x.unsqueeze(1), plane_coeffs.unsqueeze(-1)) # (batch_size, 1, 1)plane_score = plane_coeff_score.squeeze(-1).squeeze(-1) # (batch_size,)all_logits[:, i] = plane_scoreplane_choices = (plane_score >= 0).long() # (batch_size,)current_nodes = current_nodes * 2 + plane_choices + 1 # (batch_size,)# get the weightsselected_w2s = self.w2s.index_select(0, index=all_nodes.flatten()) \.view(batch_size, self.depth+1, self.output_width) # (batch_size, depth+1, output_width)# forward passmlp1 = torch.nn.functional.gelu(all_logits) # (batch_size, depth+1)mlp2 = torch.bmm(mlp1.unsqueeze(1), selected_w2s) # (batch_size, output_width)# donereturn mlp2从代码可以看出,与传统的批矩阵乘法(BMM)不同的是,在forward中,基于二叉树的结构,通过迭代计算节点的索引和权重,使用激活函数(GeLU)对结果进行处理,并最终得到输出。
结果
在推理过程中仅使用0.3%的神经元,同时表现与类似的BERT模型相当(下游任务没有降很多点);实现78倍CPU加速,实现40倍PyTorch加速。
总结
该工作很有趣,将传统前馈神经网络定义成一棵二叉树,其叶子是小型神经网络,在每个非叶子节点处都有一个微小的神经网络(单个神经元也可以工作)来决定走哪条路径取决于在输入上。在训练期间,它们对所选路径进行加权平均值,从而得出树的所有叶子(在输入上评估为神经网络)的总加权平均值,但在推理过程中,它们可以只遵循投票最高的分支,从而得出建议的结果指数加速。并且,基于FFF的思想,将工作推到BERT这种语言模型上,初步证明了大模型的前馈层的神经元并不是都需要参与推理。
文章及公开的代码还介绍了条件矩阵乘法的详细细节,因此感兴趣可以深入研究一下。
参考文献
【1】paper:Exponentially Faster Language Modelling,https://arxiv.org/abs/2311.10770
【2】code:https://github.com/pbelcak/fastfeedforward
【3】paper:Fast Feedforward Networks,https://arxiv.org/abs/2308.14711
【4】code:https://github.com/pbelcak/UltraFastBERT
【5】model:https://huggingface.co/pbelcak/UltraFastBERT-1x11-long
相关文章:
【LM、LLM】浅尝二叉树在前馈神经网络上的应用
前言 随着大模型的发展,模型参数量暴涨,以Transformer的为组成成分的隐藏神经元数量增长的越来越多。因此,降低前馈层的推理成本逐渐进入视野。前段时间看到本文介绍的相关工作还是MNIST数据集上的实验,现在这个工作推进到BERT上…...
鸿蒙4.0开发笔记之ArkTs语言基础与基本组件结构(四)
文章声明:本文关于HarmonyOS系统的部分内容和描述借鉴于华为官网的“HarmonyOS开发者学堂”,有需要的也可以进入官网查看。<HarmonyOS第一课>ArkTS开发语言介绍 一、ArkTs语言介绍 ArkTS是鸿蒙系统(HarmonyOS)优选的主力应…...

Another app is currently holding the yum lock; waiting for it to exit...
今天使用yum进行下载的时候报错 解决办法: 执行 rm -f /var/run/yum.pid 然后重新运行yum指令即可,发现已经可以正常下载啦!...

size和shape的区别与联系
对于Numpy数据类型 shape和size都是属于Numpy的属性 arr.shape 将返回一个包含两个元素的元组,例如 (m, n),其中 m 表示数组的行数,n 表示数组的列数。arr.size 将返回数组中元素的总数。 举例: 输入: import numpy as np# 创…...
浅谈STL中的分配器
分配器是STL中的六大部件之一,是各大容器能正常运作的关键,但是对于用户而言确是透明的,它似乎更像是一个幕后英雄,永远也不会走到舞台上来,观众几乎看不到它的身影,但是它又如此的重要。作为用户ÿ…...
禁止指定电脑程序运行的2种方法
你可能要问了,为什么要禁止电脑程序运行呢,因为有的公司要净化公司的工作环境,防止某些刺头员工在公司电脑上瞎搞。也有部分家长,是为了防止自己家的孩子利用电脑乱下载东西。 今天就分享2种禁止指定电脑程序运行的方法࿱…...
【Redis】前言--redis产生的背景以及过程
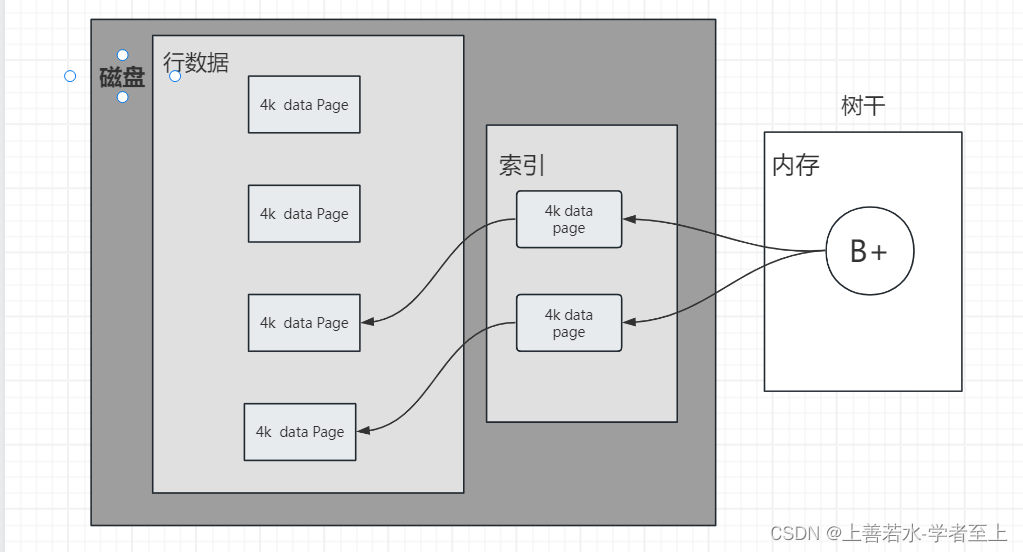
一.介绍 为什么会出现Redis这个中间件,从原始的磁盘存储到Redis中间又发生了哪些事,下面进入正题 二.发展史 2.1 磁盘存储 最早的时候都是以磁盘进行数据存储,每个磁盘都有一个磁道。每个磁道有很多扇区,一个扇区接近512Byte。…...

Java面试-微服务篇-SpringCloud
Java面试-微服务篇-SpringCloud SpringCloud 常见组件注册中心Eureka, Nacos负载均衡Ribbon服务雪崩, 熔断降级微服务的监控来源 SpringCloud 常见组件 通常情况下 Eureka: 注册中心Ribbon: 负载均衡Feign: 远程调用Hystrix: 服务熔断Zuul/Gateway: 网关 SpringCloudAlibaba…...
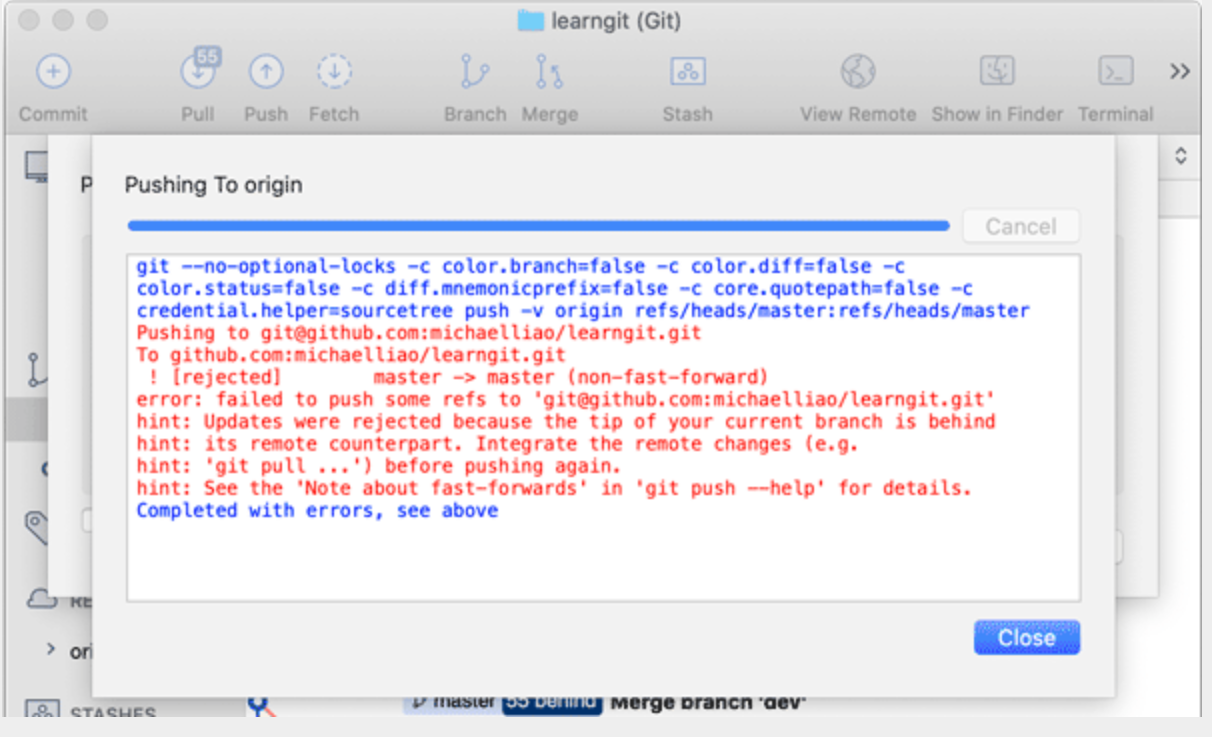
Git使用详解
文章目录 ⭐️写在前面的话⭐️📌What is it?Git的诞生 🌈Why learn it?集中式vs分布式 🧲Who does it?🎈When to use it? And Where to use it?💊How to use it?(重点)1、安装Git在Linux…...
智慧楼宇可视化视频综合管理系统,助力楼宇高效安全运行
随着互联网技术的进步和发展,智能化的楼宇建设也逐步成为人们选择办公场所是否方便的一个重要衡量因素。在智能化楼宇中,安全管理也是重要的一个模块。得益于互联网新兴技术的进步,安防视频监控技术也得到了快速发展并应用在楼宇的安全管理中…...

【opencv】计算机视觉:实时目标追踪
目录 前言 解析 深入探究 前言 目标追踪技术对于民生、社会的发展以及国家军事能力的壮大都具有重要的意义。它不仅仅可以应用到体育赛事当中目标的捕捉,还可以应用到交通上,比如实时监测车辆是否超速等!对于国家的军事也具有一定的意义&a…...

生态对对碰|华为OceanStor闪存存储与OceanBase完成兼容性互认证!
近日,北京奥星贝斯科技有限公司 OceanBase 数据库与华为技术有限公司 OceanStor Dorado 全闪存存储系统、OceanStor 混合闪存存储系统完成兼容性互认证。 OceanBase 数据库挂载 OceanStor 闪存存储做为数据盘和日志盘,在 OceanStor 闪存存储系统卓越性能…...

微服务负载均衡器Ribbon
1.什么是Ribbon 目前主流的负载方案分为以下两种: 集中式负载均衡,在消费者和服务提供方中间使用独立的代理方式进行负载,有硬件的(比如 F5),也有软件的(比如 Nginx)。 客户端根据…...
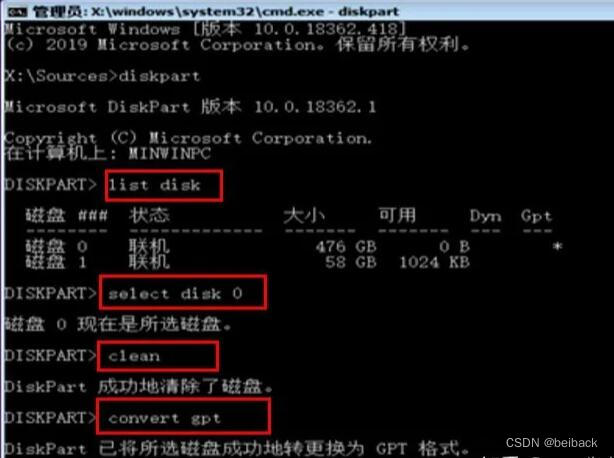
win10戴尔电脑安装操作系统遇到的问题MBR分区表只能安装GPT磁盘
首先按F2启动boot管理界面 调整启动盘的启动顺序,这里启动U盘为第一顺序。 第一步 选择安装程序的磁盘 第二步 转换磁盘为GPT磁盘 一般出现 磁盘0和1,说明存在两个盘 ,这里两个盘不是说的是C盘和D盘的问题,而是在物理上实际存在…...

阿里云服务器(vgn7i-vws) anaconda(py39)+pytorch1.12.0(cu113)
用xshell连接ip地址,端口号22,输入用户密码 安装anaconda 2022 10 py3.9 wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh sha256sum Anaconda3-2022.10-Linux-x86_64.sh #校验数据完整性 chmod ux Anaconda3-2022.10-…...

使用 STM32F7 和 TensorFlow Lite 开发低功耗人脸识别设备
本文旨在介绍如何使用 STM32F7 和 TensorFlow Lite框架开发低功耗的人脸识别设备。首先,我们将简要介绍 STM32F7 的特点和能力。接下来,我们将讨论如何使用 TensorFlow Lite 在 STM32F7 上实现人脸识别算法。然后,我们将重点关注如何优化系统…...
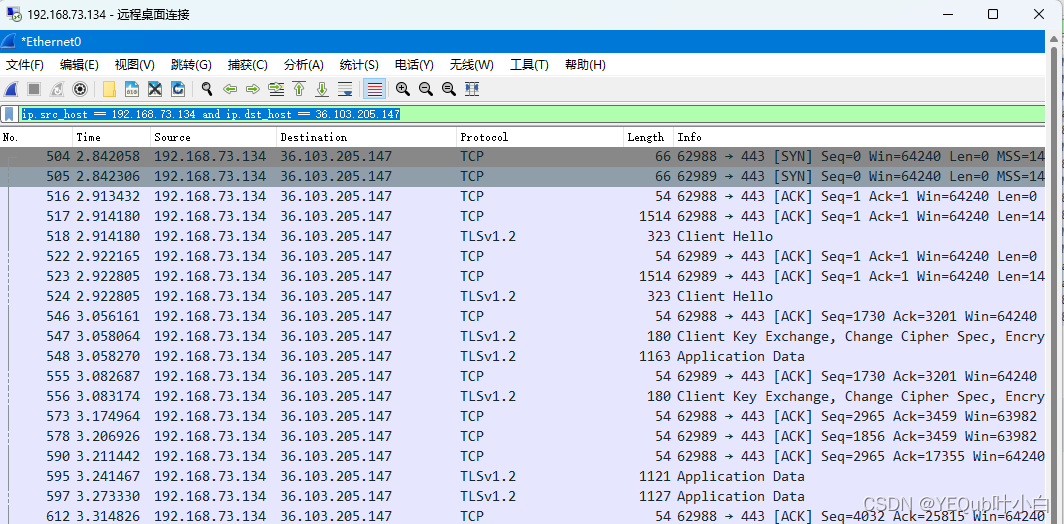
【wireshark】基础学习
TOC 查询tcp tcp 查询tcp握手请求的代码 tcp.flags.ack 0 确定tcp握手成功的代码 tcp.flags.ack 1 确定tcp连接请求的代码 tcp.flags.ack 0 and tcp.flags.syn 1 3次握手后确定发送成功的查询 tcp.flags.fin 1 查询某IP对外发送的数据 ip.src_host 192.168.73.134 查询某…...

使用Java连接Hbase
我在网上试 了很多代码,但是大部分都不能实现,Java连接Hbase,一直报一个错 java.util.concurrent.ExecutionException: org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode NoNode for /hbase/hbaseid一直也不清楚为什…...
OCR是什么意思,有哪些好用的OCR识别软件?
1. 什么是OCR? OCR(Optical Character Recognition)是一种光学字符识别技术,它可以将印刷体文字转换为可编辑的电子文本。OCR技术通过扫描和分析图像中的文字,并将其转化为计算机可识别的文本格式,从而…...
Springmvc实现增删改差
一、包结构 二、各层代码 (1)数据User public class User {private Integer id;private String userName;private String note;public User() {super();}public User(Integer i, String userName, String note) {super();this.id i;this.userName userName;this.note note;…...

Qwen3.5-9B-GGUF基础教程:llama-cpp-python callback函数实现流式进度
Qwen3.5-9B-GGUF基础教程:llama-cpp-python callback函数实现流式进度 1. 项目概述与模型介绍 Qwen3.5-9B-GGUF是阿里云开源的Qwen3.5-9B模型经过GGUF格式量化后的版本。这个90亿参数的稠密模型采用了创新的Gated Delta Networks架构和混合注意力机制(…...

论文“焕新术”:书匠策AI,降重降AIGC的秘密武器大揭秘!
在学术的浩瀚宇宙中,每一篇论文都是研究者智慧的结晶,它们如同星辰般璀璨,照亮着知识的殿堂。然而,当这些星辰在查重的天空中闪烁时,重复率过高却成了不少研究者心中的“暗礁”。别怕,今天我要带你走进一个…...

【产教融合,协同育人】Altium 出席第七届全国高校自动化类专业教学论坛
2026年4月10日至12日,第七届全国高校自动化类专业教学论坛在西安盛大启幕。作为合作伙伴,Altium 教育生态负责人宋斌出席了此次大会,与在场代表们共话自动化类专业高质量发展新路径、新形态与新实践。Altium 教育生态负责人宋斌进行主题演讲依…...

图片格式转换革命:如何用右键菜单实现三秒智能适配
图片格式转换革命:如何用右键菜单实现三秒智能适配 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors/sa/Save-Imag…...

Nunchaku FLUX.1 CustomV3部署案例:高校AI艺术实验室本地化部署实施纪要
Nunchaku FLUX.1 CustomV3部署案例:高校AI艺术实验室本地化部署实施纪要 1. 项目背景与需求 去年秋天,我受邀为本地一所高校的艺术设计学院提供技术支持。学院的王教授找到我,说他们想建立一个AI艺术实验室,让学生能亲手实践前沿…...

华硕a豆 I1403ZA_ADOL14ZA 原厂Win11 22H2系统分享下载-宇程系统站
华硕a豆I1403ZA_ADOL14ZA笔记本预装了Windows 11 22H2家庭版系统,并配备了一键恢复功能,可在系统故障或更换硬盘后通过原厂工厂文件轻松恢复。用户仅需准备一个容量大于20G的U盘,按照提供的安装教程操作即可完成系统恢复,确保设备…...

tao-8k开源Embedding模型实测:对比BGE、text2vec等主流模型效果
tao-8k开源Embedding模型实测:对比BGE、text2vec等主流模型效果 1. 引言:为什么需要长文本Embedding模型 在日常的文本处理任务中,我们经常需要将文字转换为数值向量,这就是Embedding模型的作用。传统的Embedding模型通常只能处…...
Pixel Dream Workshop效果实测:FLUX.1-dev在低显存设备上的像素保真度表现
Pixel Dream Workshop效果实测:FLUX.1-dev在低显存设备上的像素保真度表现 1. 引言:像素艺术的新纪元 在数字艺术创作领域,像素艺术一直保持着独特的魅力。传统的像素创作往往需要艺术家手动绘制每个像素点,过程耗时且对技术要求…...
)
辅助医生能力成长与患者个体化治疗方案生成系统(上)
摘要 本文档详细阐述了一套面向基层医疗机构的辅助医生能力成长与患者个体化治疗方案生成系统的设计与实现。系统以“规则驱动为基、数据驱动为翼”为核心思想,通过症状-疾病映射、指南依据匹配、用药禁忌筛查、个体化调整与风险预警等模块,为临床医生提供实时、可解释的决策…...

Rust的匹配中的项目大型维护性
Rust语言以其卓越的安全性和性能著称,而其中的模式匹配(match)机制更是其核心特性之一。在大型项目的长期维护中,模式匹配的合理使用不仅能提升代码的可读性,还能显著降低维护成本。本文将围绕Rust匹配在项目大型维护性…...