探索用卷积神经网络实现MNIST数据集分类
问题
对比单个全连接网络,在卷积神经网络层的加持下,初始时,整个神经网络模型的性能是否会更好。
方法
模型设计
两层卷积神经网络(包含池化层),一层全连接网络。
选择 5 x 5 的卷积核,输入通道为 1,输出通道为 10:
此时图像矩阵经过 5 x 5 的卷积核后会小两圈,也就是4个数位,变成 24 x 24,输出通道为10;
选择 2 x 2 的最大池化层:
此时图像大小缩短一半,变成 12 x 12,通道数不变;
再次经过5 x 5的卷积核,输入通道为 10,输出通道为 20:
此时图像再小两圈,变成 8*8,输出通道为20;
再次经过2 x 2的最大池化层:
此时图像大小缩短一半,变成 4 x 4,通道数不变;
最后将图像整型变换成向量,输入到全连接层中:
输入一共有 4 x 4 x 20 = 320个元素,输出为 10.
代码
准备数据集
# 准备数据集
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='data’,
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='data',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
建立模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
构造损失函数+优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
训练+测试
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs,target=inputs.to(device),target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%.5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
outputs=model(inputs)
_,predicted=torch.max(outputs.data,dim=1)
total+=target.size(0)
correct+=(predicted==target).sum().item()
print('Accuracy on test set:%d %% [%d%d]' %(100*correct/total,correct,total))
if __name__ =='__main__':
for epoch in range(10):
train(epoch)
test()
运行结果
(1)batch_size:64,训练次数:10
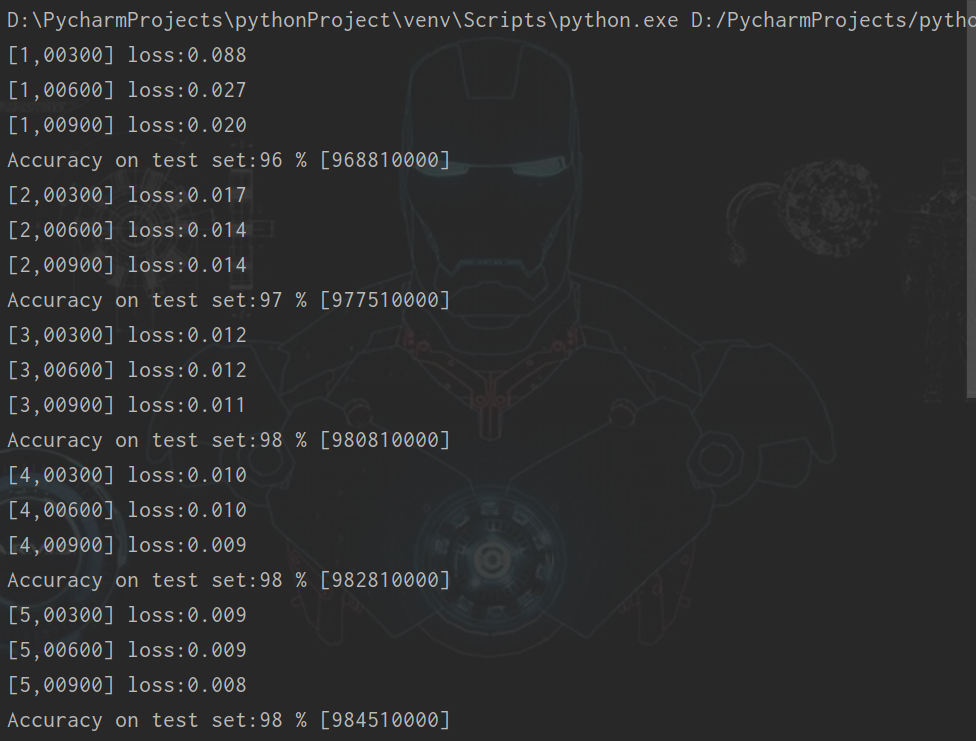
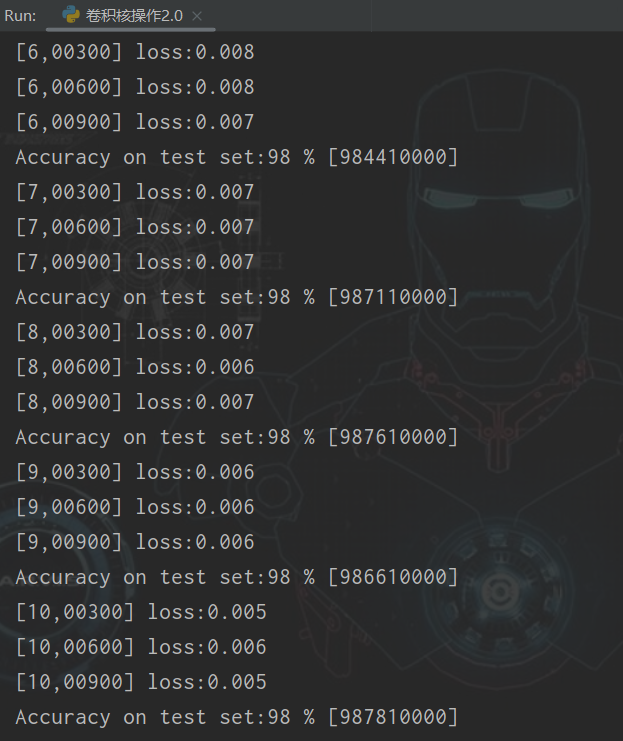
(2)batch_size:128,训练次数:10
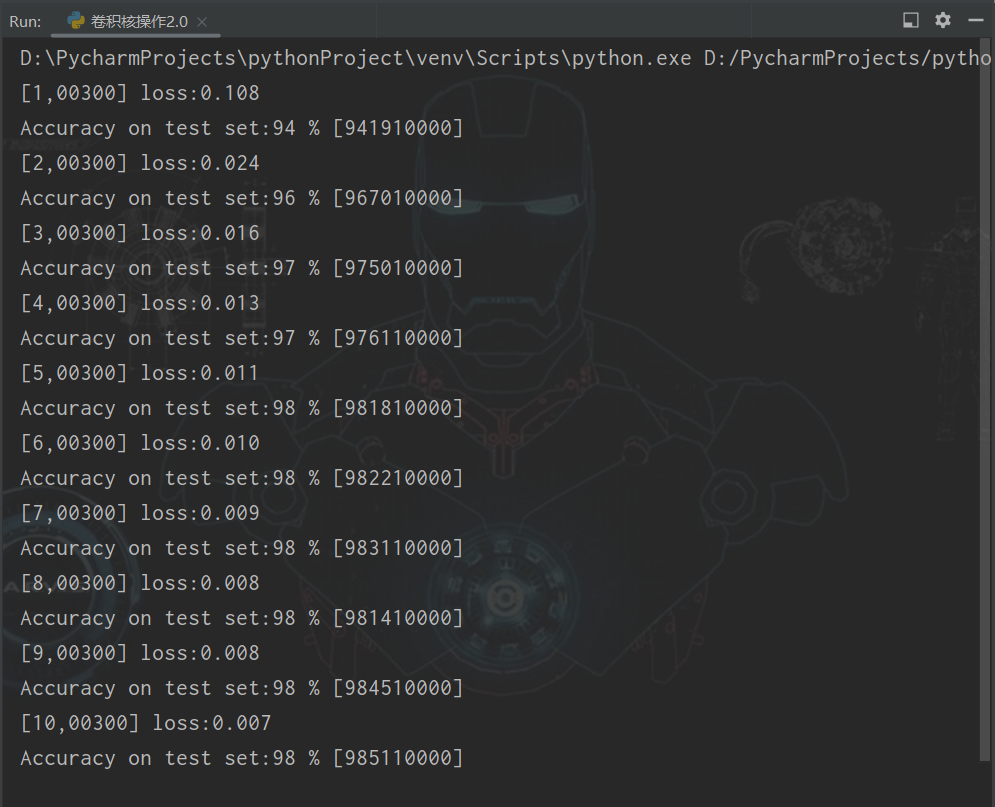
(3)batch_size:128,训练次数:10

结语
对比单个全连接网络,在卷积神经网络层的加持下,初始时,整个神经网络模型的性能显著提升,准确率最低为96%。在batch_size:64,训练次数:100情况下,准确率达到99%。下一阶在平均池化,3*3卷积核,以及不同通道数的情况下,探索对模型性能的影响。
相关文章:
探索用卷积神经网络实现MNIST数据集分类
问题对比单个全连接网络,在卷积神经网络层的加持下,初始时,整个神经网络模型的性能是否会更好。方法模型设计两层卷积神经网络(包含池化层),一层全连接网络。选择 5 x 5 的卷积核,输入通道为 1&…...

MySQL 索引失效场景
1,前言 索引主要是为了提高表的查询速率,但在某些情况下,索引也会失效的情况。 2,失效场景 2.1 最左前缀法则 查询从索引最左列开始,如果跳过索引中的age列,那么age后面字段的索引都将失效,…...
Xcode开发工具,图片放入ios工程
Xcode开发工具,图片放入ios工程,有三种方式: 一:Assets Assets.xcassets 一般是以蓝色的Assets.xcassets的文件夹形式在工程中,以Image Set的形式管理。当一组图片放入的时候同时会生成描述文件Contents.jso…...

操作系统权限提升(十九)之Linux提权-SUID提权
系列文章 操作系统权限提升(十八)之Linux提权-内核提权 SUID提权 SUID介绍 SUID是一种特殊权限,设置了suid的程序文件,在用户执行该程序时,用户的权限是该程序文件属主的权限,例如程序文件的属主是root,那么执行该…...

直播 | StarRocks 实战系列第三期--StarRocks 运维的那些事
2023 年开春, StarRocks 社区重磅推出入门级实战系列直播,手把手带你从 Zero to Hero 成为一个 “StarRocks Pro”!通过实际操作和应用场景的结合,我们将帮你系统性地学习 StarRocks 这个当今最热门的开源 OLAP 数据库。本次&…...
)
KingabseES执行计划-分区剪枝(partition pruning)
概述 分区修剪(Partition Pruning)是分区表性能的查询优化技术 。在分区修剪中,优化器分析SQL语句中的FROM和WHERE子句,以在构建分区访问列表时消除不需要的分区。此功能使数据库只能在与SQL语句相关的分区上执行操作。 参数 enable_partition_pruning 设…...

Operator-sdk 在 KaiwuDB 容器云中的使用
一、使用背景KaiwuDB Operator 是一个自动运维部署工具,可以在 Kubernetes 环境上部署 KaiwuDB集群,借助 Operator 可实现无缝运行在公有云厂商提供的 Kubernetes 平台上,让 KaiwuDB 成为真正的 Cloud-Native 数据库。使用传统的自动化工具会…...

【数据挖掘】2、数据预处理
文章目录一、数据预处理的意义1.1 缺失数据1.1.1 原因1.1.2 方案1.1.3 离群点分析1.2 重复数据1.2.1 原因1.2.2 去重的方案1.3 数据转换1.4 数据描述二、数据预处理方法2.1 特征选择 Feature Selection2.2 特征提取 Feature Extraction2.2.1 PCA 主成分分析2.2.2 LDA 线性判别分…...
大白话在数据库里,哪些操作会导致在表级别加锁呢?)
(四十六)大白话在数据库里,哪些操作会导致在表级别加锁呢?
之前我们已经给大家讲解了数据库里的行锁的概念,其实还是比较简单,容易理解的,因为在讲解锁这个概念之前,对于多事务并发以及隔离,我们已经深入讲解过了,所以大家应该很容易在脑子里有一个多事务并发执行的…...
)
【Android源码面试宝典】MMKV从使用到原理分析(二)
上一章节,我们从使用入手,进行了MMKV的简单讲解,我们通过分析简单的运行时日志,从中大概猜到了一些MMKV的代码内部流程,同时,我们也提出了若干的疑问?还是那句话,带着目标(问题)去阅读一篇源码,那么往往收获的知识,更加深入&扎实。 本节,我们一起来从源码层次…...

如何使用ADFSRelay分析和研究针对ADFS的NTLM中继攻击
关于ADFSRelay ADFSRelay是一款功能强大的概念验证工具,可以帮助广大研究人员分析和研究针对ADFS的NTLM中继攻击。 ADFSRelay这款工具由NTLMParse和ADFSRelay这两个实用程序组成。其中,NTLMParse用于解码base64编码的NTLM消息,并打印有关消…...
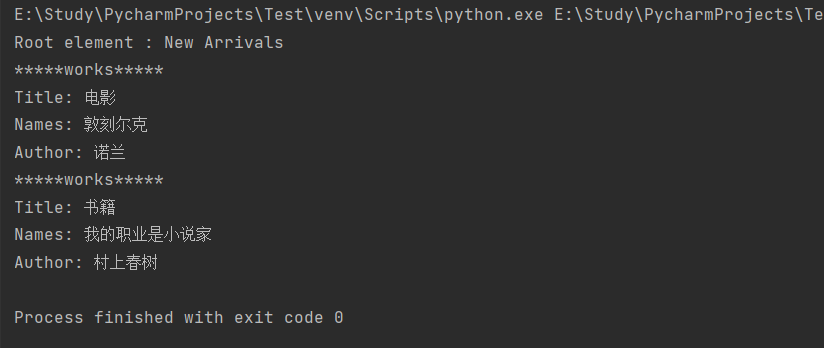
【Python学习笔记】第二十二节 Python XML 解析
一、什么是XMLXML即ExtentsibleMarkup Language(可扩展标记语言),是用来定义其它语言的一种元语言。XML 被设计用来传输和存储数据。XML 是一套定义语义标记的规则,它没有标签集(tagset),也没有语法规则(grammatical rule)。任何XML文档对任何…...

5分钟轻松拿下Java枚举
文章目录一、枚举(Enum)1.1 枚举概述1.2 定义枚举类型1.2.1 静态常量案例1.2.2 枚举案例1.2.3 枚举与switch1.3 枚举的用法1.3.1 枚举类的成员1.3.2 枚举类的构造方法1)枚举的无参构造方法2)枚举的有参构造方法1.3.3 枚举中的抽象方法1.4 Enum 类1.4.1 E…...

华为OD机试【独家】提供C语言题解 - 最小传递延迟
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明最小…...

【Web前端】关于JS数组方法的一些理解
一、具备栈特性的方法unshift(...items: T[]) : number将一个或多个元素添加到数组的开头,并返回该数组的新长度。shift(): T | undefined从数组中删除第一个元素,并返回该元素的值。此方法更改数组的长度。二、具备队列特性的方法push(...items: T[]): …...

多智能体集群协同控制笔记(1):线性无领航多智能体系统的一致性
对于连续时间高阶线性多智能体系统的状态方程为: x˙i(t)Axi(t)Bui(t),i1,2..N\dot {\mathbf{x}}_i(t)A\mathbf{x}_i(t)B\mathbf{u}_i(t),i1,2..N x˙i(t)Axi(t)Bui(t),i1,2..N 下标iii代表第iii个智能体,ui(t)∈Rq1\mathbf{u}_i(t)\in R^{q \time…...

hadoop-Yarn资源调度器【尚硅谷】
大数据学习笔记 Yarn资源调度器 Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行与操作系统之上的应用程序。 (也就是负责MapTask、ReduceTask等任…...

聊聊如何避免多个jar通过maven打包成一个jar,多个同名配置文件发生覆盖问题
前言 不知道大家在开发的过程中,有没有遇到这种场景,外部的项目想访问内部nexus私仓的jar,因为私仓不对外开放,导致外部的项目没法下载到私仓的jar,导致项目因缺少jar而无法运行。 通常遇到这种场景,常用…...

Flume 使用小案例
案例一:采集文件内容上传到HDFS 1)把Agent的配置保存到flume的conf目录下的 file-to-hdfs.conf 文件中 # Name the components on this agent a1.sources r1 a1.sinks k1 a1.channels c1 # Describe/configure the source a1.sources.r1.type spoo…...

DLO-SLAM代码阅读
文章目录DLO-SLAM点评代码解析OdomNode代码结构主函数 main激光回调函数 icpCB初始化 initializeDLO重力对齐 gravityAlign点云预处理 preprocessPoints关键帧指标 computeMetrics设定关键帧阈值setAdaptiveParams初始化目标数据 initializeInputTarget设置源数据 setInputSour…...

Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南
Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

硬件感知虚拟原型技术:软硬件协同设计的关键
1. 硬件感知虚拟原型技术概述在当今电子系统设计中,软件所占比重持续攀升。从通信设备到汽车电子,再到消费类产品,嵌入式软件已成为实现产品差异化的核心要素。这种转变源于软件实现的显著优势:低成本的设计变更、现场更新能力、快…...

5个简单步骤:在Windows电脑上直接安装Android应用的终极指南
5个简单步骤:在Windows电脑上直接安装Android应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在Windows电脑上使用Android模拟器…...

macOS百度网盘SVIP破解完整指南:3步实现无限速下载
macOS百度网盘SVIP破解完整指南:3步实现无限速下载 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘的龟速下载而烦恼吗&…...

RedwoodJS数据备份与恢复终极指南:10个技巧保护你的应用数据安全 [特殊字符]
RedwoodJS数据备份与恢复终极指南:10个技巧保护你的应用数据安全 🔒 【免费下载链接】redwood RedwoodGraphQL 项目地址: https://gitcode.com/gh_mirrors/re/redwood RedwoodJS作为一款强大的全栈JavaScript框架,其数据安全保护机制对…...

增量式编码器驱动开发实战:从原理到FPGA高速计数
1. 增量式编码器核心原理剖析 第一次接触增量式编码器时,我完全被它精妙的设计震撼到了。这种看似简单的装置,竟然能同时测量转速、转向和位置信息。拆开我们实验室的欧姆龙E6B2编码器,你会发现它的核心就是三个部分:发光二极管、…...

ARM GICv3虚拟中断处理:GICV_IAR寄存器详解
1. GICV_IAR寄存器概述GICV_IAR(Virtual Machine Interrupt Acknowledge Register)是ARM GICv3架构中虚拟CPU接口的关键寄存器,主要用于虚拟机环境下的中断确认机制。当虚拟中断信号到达处理器时,通过读取该寄存器可以获取当前最高…...

终极Windows右键菜单管理神器:ContextMenuManager让你的桌面效率提升300%
终极Windows右键菜单管理神器:ContextMenuManager让你的桌面效率提升300% 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾经在Windows右键菜…...
)
Serverless平台为何总让人“又爱又恨”?揭秘Lovable设计的3层情感化架构(开发者体验×运维韧性×业务敏捷)
更多请点击: https://intelliparadigm.com 第一章:Serverless平台为何总让人“又爱又恨”? Serverless 架构在现代云原生开发中已成为主流选择,它承诺“无需管理服务器”,让开发者专注业务逻辑。然而,在真…...

VMDE终极指南:如何快速检测虚拟机环境的完整教程
VMDE终极指南:如何快速检测虚拟机环境的完整教程 【免费下载链接】VMDE Source from VMDE paper, adapted to 2015 项目地址: https://gitcode.com/gh_mirrors/vm/VMDE VMDE(Virtual Machine Detection Enhanced)是一款强大的开源虚拟…...