常用脚本-持续更新(文件重命名、视频抽帧、拆帧、删除冗余文件、yolo2xml、转换图片格式、修改xml)
所有代码位置:Learning-Notebook-Codes/Python/常用脚本
1. 文件重命名
- 脚本路径:
codes/files_rename.py - 脚本说明:可以自动重命名某个文件夹下指定类型的文件。
- 修改前文件名称:
img1.jpg - 修改后文件名称:
Le0v1n-20231123-X-0001.jpg
- 修改前文件名称:
import os
import tqdm
import datetime"""============================ 需要修改的地方 ==================================="""
SRC_PATH = 'Python/常用脚本/EXAMPLE_FOLDER' # 文件夹路径
file_type = ('.png', '.jpg', '.jpeg', '.gif') # 想要重命名的文件类型# -------------------重命名相关------------------
retain_previous_name = False # 是否保留之前的名称
new_name = "Le0v1n" # retain_previous_name为False时生效
use_date_stamp = True # 是否使用时间戳 -> e.g. 20231123
comment = "X" # 备注
use_serial_numbering = True # 是否使用顺序的编号 -> 1, 2, 3, 4, 5, 6, ...
start_number = 1 # 从编号几开始 -> e.g. 1: 从 0001 开始编号
numbering_placeholder = 4 # 编号保留的占位 -> e.g. 0001, 0002, 0003, ...
hyphen = '-' # 连字符 -> e.g. filename-0001.jpg
"""==============================================================================="""# 获取目录中的所有图片文件
files_list = [file for file in os.listdir(SRC_PATH) if file.lower().endswith(file_type)]"------------计数------------"
TOTAL_FILES_NUM = len(files_list) # 需要重命名的文件数量
RENAME_NUM = 0 # 重命名成功数量
"---------------------------"# 获取当前时间并格式化时间戳
timestamp = datetime.datetime.now().strftime("%Y%m%d")# 遍历文件
process_bar = tqdm.tqdm(total=TOTAL_FILES_NUM, desc="为指定格式的文件重命名", unit='file') # 创建进度条
for idx, file_name in enumerate(files_list):file_pre, file_ext = os.path.splitext(file_name) # 获得文件名和后缀process_bar.set_description(f"rename for \033[1;31m{file_name}\033[0m")# 构建新的文件名if retain_previous_name: # 保留原有的名称NEW_FILE_NAME = f"{file_pre}"elif new_name: # 不保留原有的名称且新名称存在NEW_FILE_NAME = new_nameelse: # 不保留原有的名称也没有新名称 -> 报错raise KeyError(f"不保留原有的名称也没有新名称!")if use_date_stamp: # 使用时间戳NEW_FILE_NAME += f"{hyphen}{timestamp}"if comment: # 添加备注NEW_FILE_NAME += f"{hyphen}{comment}" if use_serial_numbering: # 使用编号NEW_FILE_NAME += f"{hyphen}{idx + start_number:0{numbering_placeholder}d}"# 加上扩展名NEW_FILE_NAME += file_ext# 开始重命名文件 _src = os.path.join(SRC_PATH, file_name) # 旧文件路径_dst = os.path.join(SRC_PATH, NEW_FILE_NAME) # 新文件路径os.rename(_src, _dst) # 重命名文件RENAME_NUM += 1process_bar.update(1)
process_bar.close()print(f"👌 文件重命名完成: {RENAME_NUM}/{TOTAL_FILES_NUM}")
2. 视频抽帧
- 脚本路径:
codes/extract_frames.py - 脚本说明:根据帧间隔对某个文件夹下指定类型的视频文件进行抽帧,得到系列图片。
- 视频文件所在文件夹名称:
EXAMPLE_FOLDER - 抽帧得到的文件夹名称:
EXAMPLE_FOLDER/extract_frames_results/test_vid_0001.jpg
- 视频文件所在文件夹名称:
import cv2
import os
import tqdm
from utils import create_folder"""============================ 需要修改的地方 ==================================="""
SRC_PATH = "Python/常用脚本/EXAMPLE_FOLDER" # 原始视频路径
frame_interval = 10 # 视频采样间隔,越小采样率越高 -> 60 | 30 | 15 | 10
video_type = ['.mp4', '.avi'] # 视频格式(.mp4 | .avi)DST_PATH = "extract_frames_results" # 保存图片文件夹名称
save_img_format = '.jpg' # 保存的图片格式(.jpg | .png)
"""==============================================================================="""# 构建路径
results_imgs_path = os.path.join(SRC_PATH, DST_PATH) # 保存图片路径# 得到存放所有视频的list
video_list = [x for x in os.listdir(SRC_PATH) if os.path.splitext(x)[-1] in video_type]"------------计数------------"
TOTAL_VID_NUM = len(video_list)
SUCCEED_NUM = 0 # 完成视频的个数
TOTAL_IMG_NUM = 0 # 统计得到的所有图片数量
"---------------------------"print(f"\033[1;31m[SRC]视频路径为: {SRC_PATH}\033[0m"f"\n\t\033[1;32m视频个数: {TOTAL_VID_NUM}\033[0m"f"\n\033[1;31m[DST]图片保存路径为: {DST_PATH}\033[0m"f"\n\t\033[1;32m保存的图片格式为: {save_img_format}\033[0m"f"\n\n请输入 \033[1;31m'yes'\033[0m 继续,输入其他停止")
_INPUT = input()
if _INPUT != "yes":exit()create_folder(results_imgs_path, verbose=True) # 创建文件夹# 创建一个tqdm进度条对象
progress_bar = tqdm.tqdm(total=len(video_list), desc="视频拆帧...", unit="vid")
statistics_dict = dict() # 创建一个字典,用于统计
for vid_name in video_list: # 遍历所有的视频save_number = 1 # 记录当前视频保存的frame个数vid_pre, vid_ext = os.path.splitext(vid_name) # 获取文件名和后缀vid_path = os.path.join(SRC_PATH, vid_name) # 视频完整路径# 创建VideoCapture对象vc = cv2.VideoCapture(vid_path)# 检查视频是否成功打开if not vc.isOpened():continue# 逐帧读取视频并保存为图片frame_count = 0while True:# 读取一帧rval, frame = vc.read()# 检查是否成功读取帧if not rval: # 读取帧失败break# 每隔 frame_interval 帧保存一次图片if frame_count % frame_interval == 0:# 生成图片文件名frame_name = f"{vid_pre}_{save_number:04d}{save_img_format}"frame_path = os.path.join(results_imgs_path, frame_name) # Python\常用脚本\EXAMPLE_FOLDER\extract_frames_results\test_vid_0016.jpgprogress_bar.set_description(f"\033[1;31m{vid_name}\033[0m -> "f"\033[1;36m{save_number * frame_interval:04d}\033[0m"f" ({save_number})") # 更新tqdm的描述# 保存帧为图片cv2.imwrite(frame_path, frame)save_number += 1# 帧数加1frame_count += 1# 释放VideoCapture对象vc.release()TOTAL_IMG_NUM += save_number # 更新图片数量SUCCEED_NUM += 1statistics_dict[vid_pre] = save_number # 更新字典,记录当前视频得到的frame个数progress_bar.update()
progress_bar.close()print("------------------------------------------------------------------")
_cont = 0
for k, v in statistics_dict.items():print(f"\033[1;34m"f"👌 1. [{k}] 得到 frame 个数 -> {v}"f"\033[0m")_cont += 1
print()
print(f"\033[1;31m"f"👌👌👌 视频拆帧 ({TOTAL_VID_NUM}个)完成,总共得到[{TOTAL_IMG_NUM}]张{save_img_format}图片!"f"\033[0m")
print("------------------------------------------------------------------")
3. 根据文件A删除冗余的文件B
- 脚本路径:
codes/delete-Redundant_fileB.py - 脚本说明:根据文件 A 删除冗余文件 B。
- 用途:根据 annotations 删除冗余的 images。
- 要求:文件 A 和 文件 B 应该有相同的名字(后缀不同)。
"""
+ 脚本说明:根据文件 A 删除冗余文件 B。
+ 用途:根据 annotations 删除冗余的 images。
+ 要求:文件 A 和 文件 B 应该有相同的名字(后缀不同)。
"""
import os
import tqdm"""============================ 需要修改的地方 ==================================="""
path_A = 'Python/常用脚本/EXAMPLE_FOLDER/images' # 不删除
file_type_A = ('.jpg', '.png')path_B = 'Python/常用脚本/EXAMPLE_FOLDER/annotations' # 会删除的
file_type_B = ('.json', '.xml')
"""==============================================================================="""# 获取两种文件列表
files_A_list = [file for file in os.listdir(path_A) if file.endswith(file_type_A)]
files_B_list = [file for file in os.listdir(path_B) if file.endswith(file_type_B)]"------------计数------------"
NUM_B = len(files_A_list)
NUM_B = len(files_B_list)
SUCCEED_NUM = 0
SKIP_NUM = 0
"---------------------------"print(f"文件[A]所在文件夹路径为: {path_A}"f"\n\t文件[A]数量为: {NUM_B}"f"\n\t文件[A]的后缀为: {file_type_A}"f"\n文件[B]所在文件夹路径为: {path_B}"f"\n\t文件[B]数量为: {NUM_B}"f"\n\t文件[B]的后缀为: {file_type_B}"f"\n\n请输入 \033[1;31m'yes'\033[0m 继续,输入其他停止")
_INPUT = input()
if _INPUT != "yes":exit()# 遍历文件B
process_bar = tqdm.tqdm(total=NUM_B, desc="根据文件A删除冗余的文件B", unit='unit')
for name_B in files_B_list:pre_B, ext_A = os.path.splitext(name_B) # 分离文件名和后缀process_bar.set_description(f"Process with \033[1;31m{name_B}\033[0m")# 判断对应的同名 A 文件是否存在,如果存在则跳过dst_path = os.path.join(path_A, pre_B) # 没有后缀_exist_flag = 0for ext_A in file_type_A: # 遍历所有格式,看是否有至少一个同名文件存在if os.path.exists(dst_path + ext_A):_exist_flag += 1if _exist_flag > 0: # 如果存在至少一个同名文件, 则跳过SKIP_NUM += 1process_bar.update()else: # 没有同名文件, 则删除文件Bdel_path = os.path.join(path_B, name_B)os.remove(del_path)SUCCEED_NUM += 1process_bar.update()
process_bar.close()print(f"👌 冗余的B文件删除已完成!"f"\n\t删除文件数量/文件B数量 = {SUCCEED_NUM}/{NUM_B}"f"\n\t跳过文件数量/文件B数量 = {SKIP_NUM}/{NUM_B}")if SUCCEED_NUM + SKIP_NUM == NUM_B:print("👌 No Problems")
else:print(f"🤡 有问题,请仔细核对!"f"\n\tSUCCEED_NUM: {SUCCEED_NUM}\tSKIP_NUM: {SKIP_NUM}"f"\n\tSUCCEED_NUM + SKIP_NUM + ERROR_NUM = {SUCCEED_NUM + SKIP_NUM}"f"\n\tTOTAL_NUM: {NUM_B}")
4. yolo2xml
- 脚本路径:
codes/D-yolo2xml.py - 脚本说明:将yolo格式txt标注文件转换为voc格式xml标注文件
- 用途:将 YOLO 格式的标签文件还原为 xml 格式
- 要求:图片和yolo标签应该有相同的名字(后缀不同)
"""
+ 脚本说明:将yolo格式txt标注文件转换为voc格式xml标注文件
+ 用途:将 YOLO 格式的标签文件还原为 xml 格式
+ 要求:图片和yolo标签应该有相同的名字(后缀不同)
"""
from xml.dom.minidom import Document
import os
import cv2
import tqdm"""============================ 需要修改的地方 ==================================="""
IMAGE_PATH = "EXAMPLE_FOLDER/images" # 原图文件夹路径
TXT_PATH = "EXAMPLE_FOLDER/labels-yolo" # 原txt标签文件夹路径
XML_PATH = "EXAMPLE_FOLDER/labels-xml" # 保存xml文件夹路径
image_type = '.jpg'
create_empty_xml_for_neg = True # 是否为负样本生成对应的空的xml文件classes_dict = {'0': "cat",'1': 'dog'
}
"""==============================================================================="""os.makedirs(XML_PATH) if not os.path.exists(XML_PATH) else Nonetxt_file_list = [file for file in os.listdir(TXT_PATH) if file.endswith(".txt") and file != 'classes.txt']"------------计数------------"
TOTAL_NUM = len(txt_file_list)
SUCCEED_NUM = 0 # 成功创建xml数量
SKIP_NUM = 0 # 跳过创建xml文件数量
OBJECT_NUM = 0 # object数量
"---------------------------"process_bar = tqdm.tqdm(total=TOTAL_NUM, desc="yolo2xml", unit='.txt')
for i, txt_name in enumerate(txt_file_list):process_bar.set_description(f"Process in \033[1;31m{txt_name}\033[0m")txt_pre, txt_ext = os.path.splitext(txt_name) # 分离前缀和后缀xmlBuilder = Document() # 创建一个 XML 文档构建器annotation = xmlBuilder.createElement("annotation") # 创建annotation标签xmlBuilder.appendChild(annotation)# 打开 txt 文件txtFile = open(os.path.join(TXT_PATH, txt_name))txtList = txtFile.readlines() # 以一行的形式读取txt所有内容if not txtList and not create_empty_xml_for_neg: # 如果 txt 文件内容为空且不允许为负样本创建xml文件SKIP_NUM += 1process_bar.update()continue# 读取图片img = cv2.imread(os.path.join(IMAGE_PATH, txt_pre) + image_type)H, W, C = img.shape# folder标签folder = xmlBuilder.createElement("folder") foldercontent = xmlBuilder.createTextNode('images')folder.appendChild(foldercontent)annotation.appendChild(folder) # folder标签结束# filename标签filename = xmlBuilder.createElement("filename") filenamecontent = xmlBuilder.createTextNode(txt_pre + image_type)filename.appendChild(filenamecontent)annotation.appendChild(filename) # filename标签结束# size标签size = xmlBuilder.createElement("size") width = xmlBuilder.createElement("width") # size子标签widthwidthcontent = xmlBuilder.createTextNode(str(W))width.appendChild(widthcontent)size.appendChild(width) # size子标签width结束height = xmlBuilder.createElement("height") # size子标签heightheightcontent = xmlBuilder.createTextNode(str(H))height.appendChild(heightcontent)size.appendChild(height) # size子标签height结束depth = xmlBuilder.createElement("depth") # size子标签depthdepthcontent = xmlBuilder.createTextNode(str(C))depth.appendChild(depthcontent)size.appendChild(depth) # size子标签depth结束annotation.appendChild(size) # size标签结束# 读取 txt 内容,生成 xml 文件内容for line in txtList: # 正样本(txt内容不为空)# .strip()去除行首和行尾的空白字符(如空格和换行符)oneline = line.strip().split(" ") # oneline是一个list, e.g. ['0', '0.31188484251968507', '0.6746135899679205', '0.028297244094488208', '0.04738990959463407']# 开始 object 标签object = xmlBuilder.createElement("object") # object 标签# 1. name标签picname = xmlBuilder.createElement("name") namecontent = xmlBuilder.createTextNode(classes_dict[oneline[0]]) # 确定是哪个类别picname.appendChild(namecontent)object.appendChild(picname) # name标签结束# 2. pose标签pose = xmlBuilder.createElement("pose") posecontent = xmlBuilder.createTextNode("Unspecified")pose.appendChild(posecontent)object.appendChild(pose) # pose标签结束# 3. truncated标签truncated = xmlBuilder.createElement("truncated") truncatedContent = xmlBuilder.createTextNode("0")truncated.appendChild(truncatedContent)object.appendChild(truncated) # truncated标签结束# 4. difficult标签difficult = xmlBuilder.createElement("difficult") difficultcontent = xmlBuilder.createTextNode("0")difficult.appendChild(difficultcontent)object.appendChild(difficult) # difficult标签结束# 5. bndbox标签bndbox = xmlBuilder.createElement("bndbox") ## 5.1 xmin标签xmin = xmlBuilder.createElement("xmin") mathData = int(((float(oneline[1])) * W + 1) - (float(oneline[3])) * 0.5 * W)xminContent = xmlBuilder.createTextNode(str(mathData))xmin.appendChild(xminContent)bndbox.appendChild(xmin) # xmin标签结束## 5.2 ymin标签ymin = xmlBuilder.createElement("ymin") # ymin标签mathData = int(((float(oneline[2])) * H + 1) - (float(oneline[4])) * 0.5 * H)yminContent = xmlBuilder.createTextNode(str(mathData))ymin.appendChild(yminContent)bndbox.appendChild(ymin) # ymin标签结束## 5.3 xmax标签xmax = xmlBuilder.createElement("xmax") # xmax标签mathData = int(((float(oneline[1])) * W + 1) + (float(oneline[3])) * 0.5 * W)xmaxContent = xmlBuilder.createTextNode(str(mathData))xmax.appendChild(xmaxContent)bndbox.appendChild(xmax) # xmax标签结束## 5.4 ymax标签ymax = xmlBuilder.createElement("ymax") # ymax标签mathData = int(((float(oneline[2])) * H + 1) + (float(oneline[4])) * 0.5 * H)ymaxContent = xmlBuilder.createTextNode(str(mathData))ymax.appendChild(ymaxContent)bndbox.appendChild(ymax) # ymax标签结束object.appendChild(bndbox) # bndbox标签结束annotation.appendChild(object) # object标签结束OBJECT_NUM += 1# 创建 xml 文件f = open(os.path.join(XML_PATH, txt_pre) + '.xml', 'w')# 为 创建好的 xml 文件写入内容xmlBuilder.writexml(f, indent='\t', newl='\n',addindent='\t', encoding='utf-8')f.close() # 关闭xml文件SUCCEED_NUM += 1process_bar.update()
process_bar.close()print(f"👌yolo2xml已完成, 详情如下:"f"\n\t成功转换文件数量/总文件数量 = \033[1;32m{SUCCEED_NUM}\033[0m/{TOTAL_NUM}"f"\n\t跳过转换文件数量/总文件数量 = \033[1;31m{SKIP_NUM}\033[0m/{TOTAL_NUM}"f"\n\t所有样本的 object 数量/总文件数量 = \033[1;32m{OBJECT_NUM}\033[0m/{TOTAL_NUM}"f"\n\t平均每个xml文件中object的数量为: {int(OBJECT_NUM / SUCCEED_NUM)}")if SUCCEED_NUM + SKIP_NUM == TOTAL_NUM:print(f"\n👌 \033[1;32mNo Problem\033[0m")
else:print(f"\n🤡 \033[1;31m貌似有点问题, 请仔细核查!\033[0m")
5. 转换图片格式
- 脚本路径:
codes/E-转换图片格式 - 脚本说明:对指定文件夹下所有的图片进行格式转换
- 用途:统一数据集图片的格式
- 要求:无
- 注意:
- 不需要转换的则跳过
- 不是图片的文件会扔到指定位置 RECYCLE_BIN_PATH
"""
+ 脚本说明:对指定文件夹下所有的图片进行格式转换
+ 用途:统一数据集图片的格式
+ 要求:无
+ 注意:1. 不需要转换的则跳过2. 不是图片的文件会扔到指定位置 RECYCLE_BIN_PATH
"""
import os
import tqdm
from PIL import Image
import shutil"""============================ 需要修改的地方 ==================================="""
# 定义文件夹路径
IMG_PATH = "EXAMPLE_FOLDER/images" # 输入图片所在文件夹路径
wanna_convert_image_type = '.jpg' # 想要转换的图片格式
other_image_type = ['.png', '.jpeg'] # 什么格式的图片将会被转换
"""==============================================================================="""# 确定回收站位置
RECYCLE_BIN_PATH = os.path.join(os.path.dirname(IMG_PATH), "recycle_bin")# 获取文件夹内所有文件
all_files = os.listdir(IMG_PATH)"------------计数------------"
TOTAL_NUM = len(all_files)
SUCCEED_CONVERT_NUM = 0
SKIP_CONVERT_NUM = 0
OTHER_FILE_NUM = 0
"---------------------------"# 遍历所有的图片
process_bar = tqdm.tqdm(total=TOTAL_NUM, desc=f"将所有图片转换为{wanna_convert_image_type}格式", unit='file')
for file_name in all_files:# 分离文件名和后缀file_pre, file_ext = os.path.splitext(file_name)process_bar.set_description(f"Process in \033[1;31m{file_name}\033[0m")# 构建文件完整路径file_path = os.path.join(IMG_PATH, file_name)# 检查文件是否为.jpg格式if file_ext == wanna_convert_image_type: # 如果是 jpg 则跳过SKIP_CONVERT_NUM += 1process_bar.update()continueelif file_ext in other_image_type: # 如果是其他图片格式with Image.open(file_path) as img:# 构建输出文件路径dst_save_path = os.path.join(IMG_PATH, file_pre) + wanna_convert_image_typeimg.save(dst_save_path) # 保存为.jpg格式# 将原有的图片移动到其他文件夹下dst_move_path = os.path.join(RECYCLE_BIN_PATH, file_name)shutil.move(src=file_path, dst=dst_move_path)SUCCEED_CONVERT_NUM += 1process_bar.update()else: # 既不是 jpg 也不是 png、jpeg,则移动到其他文件夹下if not os.path.exists(RECYCLE_BIN_PATH):os.mkdir(RECYCLE_BIN_PATH)dst_move_path = os.path.join(RECYCLE_BIN_PATH, file_name)shutil.move(src=file_path, dst=dst_move_path)OTHER_FILE_NUM += 1process_bar.update()
process_bar.close()print(f"👌 所有图片已转换为jpg, 详情如下:"f"\n\t成功转换数量/总文件数量 = \033[1;32m{SUCCEED_CONVERT_NUM}\033[0m/{TOTAL_NUM}"f"\n\t跳过文件数量/总文件数量 = \033[1;34m{SKIP_CONVERT_NUM}\033[0m/{TOTAL_NUM}"f"\n\t其他格式文件数量/总文件数量 = \033[1;31m{OTHER_FILE_NUM}\033[0m/{TOTAL_NUM}")if SUCCEED_CONVERT_NUM + SKIP_CONVERT_NUM + OTHER_FILE_NUM == TOTAL_NUM:print("👌 No Problems")
else:print(f"🤡 貌似有点问题, 请仔细核查!"f"\n\tSUCCEED_NUM: {SUCCEED_CONVERT_NUM}"f"\n\tSKIP_NUM: {SKIP_CONVERT_NUM}"f"\n\tOTHER_FILE_NUM = {OTHER_FILE_NUM}"f"\nSUCCEED_NUM + SKIP_NUM + OTHER_FILE_NUM = {SUCCEED_CONVERT_NUM + SKIP_CONVERT_NUM + OTHER_FILE_NUM}"f"\nTOTAL_NUM: {TOTAL_NUM}")
6. 根据图片修改xml文件中的size尺寸信息
- 脚本路径:
codes/F-根据图片修改xml文件中的size尺寸信息.py - 脚本说明:根据图片修改xml文件中的size尺寸信息
- 用途:修正数据集标签的信息
- 要求:无
- 注意:
- 不是in-place操作
- 不需要转换的也会复制到新的文件夹下
- 如果遇到xml没有对应图片的,则会记录该错误,并生成 ERROR_LOG.txt 文件
"""
+ 脚本说明:根据图片修改xml文件中的size尺寸信息
+ 用途:修正数据集标签的<size>信息
+ 要求:无
+ 注意:1. 不是in-place操作2. 不需要转换的也会复制到新的文件夹下3. 如果遇到xml没有对应图片的,则会记录该错误,并生成 ERROR_LOG.txt 文件
"""
from PIL import Image
import os
import xml.etree.ElementTree as ET
import tqdm
import sys"""============================ 需要修改的地方 ==================================="""
# 输入和输出文件夹路径
XML_PATH = "EXAMPLE_FOLDER/labels-xml" # 修正前的 xml 文件夹路径
SAVE_PATH = "EXAMPLE_FOLDER/labels-xml-fixed" # 修正后的 xml 文件夹路径
IMG_PATH = "EXAMPLE_FOLDER/images" # 同名图片文件夹路径
img_type = '.jpg' # 图片的格式
"""==============================================================================="""# 确保输出文件夹存在
if not os.path.exists(SAVE_PATH):os.makedirs(SAVE_PATH, exist_ok=True)# 获取xml文件列表
annotation_files = [file for file in os.listdir(XML_PATH) if file.lower().endswith('.xml')]"------------计数------------"
TOTAL_NUM = len(annotation_files) # 需要处理的 .xml 文件数量
SUCCEED_NUM = 0 # 成功修改的数量
SKIP_NUM = 0 # 跳过的数量
ERROR_NUM = 0 # 出错的数量
ERROR_LIST = [] # 出错的logging
"---------------------------"# 遍历所有的xml文件
process_bar = tqdm.tqdm(total=TOTAL_NUM, desc="根据图片修正 xml 文件的尺寸 <size> 信息", unit='xml')
for xml_file in annotation_files:xml_name, xml_ext = os.path.splitext(xml_file) # 分离文件名和后缀process_bar.set_description(f"Process in \033[1;31m{xml_file}\033[0m")# 读取 xml 文件xml_path = os.path.join(XML_PATH, xml_file) # 获取完整路径tree = ET.parse(xml_path) # 解析 xml 树root = tree.getroot() # 获取 xml 树的根# 获取同名图片文件名image_path = os.path.join(IMG_PATH, xml_name) + img_type# 判断对应的同名图片文件是否存在,如果不存在则记录错误if not os.path.exists(image_path):ERROR_NUM += 1ERROR_LIST.append(xml_path)process_bar.update()continue# 使用PIL获取图片尺寸image = Image.open(image_path)width, height = image.size# 判断 xml 中的 <size> 标签是否和图片尺寸对应size_elem = root.find("size")if size_elem.find("width").text == str(width) and size_elem.find("height").text == str(height):# 不需要修正,直接保存文件output_path = os.path.join(SAVE_PATH, xml_file)tree.write(output_path, encoding="utf-8")SKIP_NUM += 1process_bar.update()continueelse:# 更新xml中的<size>标签size_elem.find("width").text = str(width)size_elem.find("height").text = str(height)# 保存修正后的xml文件output_path = os.path.join(SAVE_PATH, xml_file)tree.write(output_path, encoding="utf-8")SUCCEED_NUM += 1process_bar.update()
process_bar.close()print(f"👌 xml 文件的 size 信息修正已完成, 详情如下:"f"\n\t成功修正数量/总xml数量 = \033[1;32m{SUCCEED_NUM}\033[0m/{TOTAL_NUM}"f"\n\t跳过数量/总xml数量 = \033[1;34m{SKIP_NUM}\033[0m/{TOTAL_NUM}"f"\n\t出错数量/总xml数量 = \033[1;31m{ERROR_NUM}\033[0m/{TOTAL_NUM}")if SUCCEED_NUM + SKIP_NUM == TOTAL_NUM:print("👌 \033[1;32mNo Problems\033[0m")
else:print(f"🤡 貌似有点问题, 请仔细核查!"f"\n\tSUCCEED_NUM: {SUCCEED_NUM}"f"\n\tSKIP_NUM: {SKIP_NUM}"f"\n\tERROR_NUM = {ERROR_NUM}"f"\nSUCCEED_NUM + SKIP_NUM + ERROR_NUM = {SUCCEED_NUM + SKIP_NUM + ERROR_NUM}"f"\nTOTAL_NUM: {TOTAL_NUM}")if ERROR_LIST: # 如果有出错信息program_path = sys.argv[0] # 获取程序完整路径program_name = os.path.basename(program_path) # 获取程序名称program_parent_path = os.path.dirname(program_path) # 获取程序所在文件夹路径ERROR_LOG_PATH = os.path.join(program_parent_path, f"ERROR_LOG-[{program_name}].txt")with open(ERROR_LOG_PATH, "w") as file: # 打开文本文件以写入模式file.write(f"Program: {program_path}\n") # 写入程序名称file.write(f"🤡 出错了 -> 出错数量/总文件数量 = {ERROR_NUM}/{TOTAL_NUM}\n") # 写入总体出错信息file.write('=' * 50 + '\n') # 写入分隔线# 遍历出错信息列表,写入文件for e in ERROR_LIST:file.write(f"{e}\n")# 写入分隔线file.write('=' * 50 + '\n')print(f"\033[1;31m出错信息\033[0m已写入到 [\033[1;34m{ERROR_LOG_PATH}\033[0m] 文件中, 请注意查看!")
相关文章:
)
常用脚本-持续更新(文件重命名、视频抽帧、拆帧、删除冗余文件、yolo2xml、转换图片格式、修改xml)
所有代码位置:Learning-Notebook-Codes/Python/常用脚本 1. 文件重命名 脚本路径:codes/files_rename.py脚本说明:可以自动重命名某个文件夹下指定类型的文件。 修改前文件名称: img1.jpg修改后文件名称: Le0v1n-20231123-X-0001.jpg imp…...
百度文心一言(千帆大模型)聊天API使用指导
开篇不得不吐槽下百度,百度智能云平台首页跳转千帆大模型平台的按钮太多了,不同按钮跳转不同的子页面,不熟悉的,能把人找懵。入口太多,就导致用户不知道从何开始。本文就从一个前端开发人员的角度,教大家快…...

C++知识点总结(7):玩转高精度除法
一、复习高低精度 一个数分为两种类型: 1. 高精度数,即一个长度特别长的数,使用 long long 也无法存储的一类数字。 2. 低精度数,即一个普通的数,可以使用 long long 来存储。 由于高精度除法比较简单,…...
|LeetCode1049. 最后一块石头的重量 II、LeetCode494. 目标和)
LeetCode算法题解(动态规划,背包问题)|LeetCode1049. 最后一块石头的重量 II、LeetCode494. 目标和
一、LeetCode1049. 最后一块石头的重量 II 题目链接:1049. 最后一块石头的重量 II 题目描述: 有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。 每一回合,从中选出任意两块石头,然后将…...

使用Pytorch从零开始构建LSTM
长短期记忆(LSTM)网络已被广泛用于解决各种顺序任务。让我们了解这些网络如何工作以及如何实施它们。 就像我们一样,循环神经网络(RNN)也可能很健忘。这种与短期记忆的斗争导致 RNN 在大多数任务中失去有效性。不过&a…...
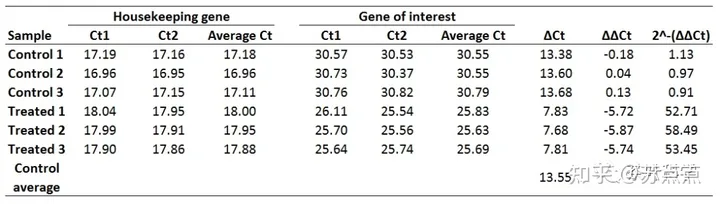
qRT-PCR相对定量计算详解qPCR相对定量计算方式——2^-(∆∆Ct) deta t
做完转录组分析之后,一般都要求做qRT-PCR来验证二代测序得到的转录本表达是否可靠。荧光定量PCR是一种相对表达定量的方法,他的计算方法有很多,常用的相对定量数据分析方法有双标曲线法,ΔCt法,2^-ΔΔCt法(Livak法)&a…...

BART non-Cartesian 重建:并行成像 压缩感知
本文主要使用并行成像和压缩感知方法实现non-Cartesian MRI 数据的重建。 目录 1 自定义MRI kspace trajectory 2 自定义该 trajectory下的多通道MRI数据 3 使用NUFFT 直接做欠采样数据的重建...

UDP客户端使用connect与UDP服务器使用send函数和recv函数收发数据
服务器代码编译运行 服务器udpconnectToServer.c的代码如下: #include<stdio.h> #include<stdlib.h> #include<string.h> #include<unistd.h> #include<arpa/inet.h> #include<sys/socket.h> #include<errno.h> #inclu…...
闭环检测器)
SLAM ORB-SLAM2(9)闭环检测器
SLAM ORB-SLAM2(9)闭环检测器 1. LoopClosing2. 成员变量2.1. 系统成员变量2.2. 关键帧2.3. 共视关系2.4. 闭环检测2.5. 全局 BA(光束法平差)2.6. 其他操作3. 成员函数3.1. 构造函数3.2. 主要函数3.3. 更新操作3.4. 标识设置和查询接口1. LoopClosing 在《SLAM ORB-SLAM2(…...
(二))
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】SLAM(基础篇)(二)
目录 知识储备 概率论基础 边缘概率 联合概率和独立 独立与条件独立...

TikTok 将开源“云中和”边缘加速器
“从某种意义上说,我们正在努力破解云的骨干网,以造福于我们,”TikTok产品管理基础设施经理Vikram Siwach指出,他解释了该公司即将开源的“全球服务加速器”的好处,这是一个可编程的边缘平台,可将应用程序需…...
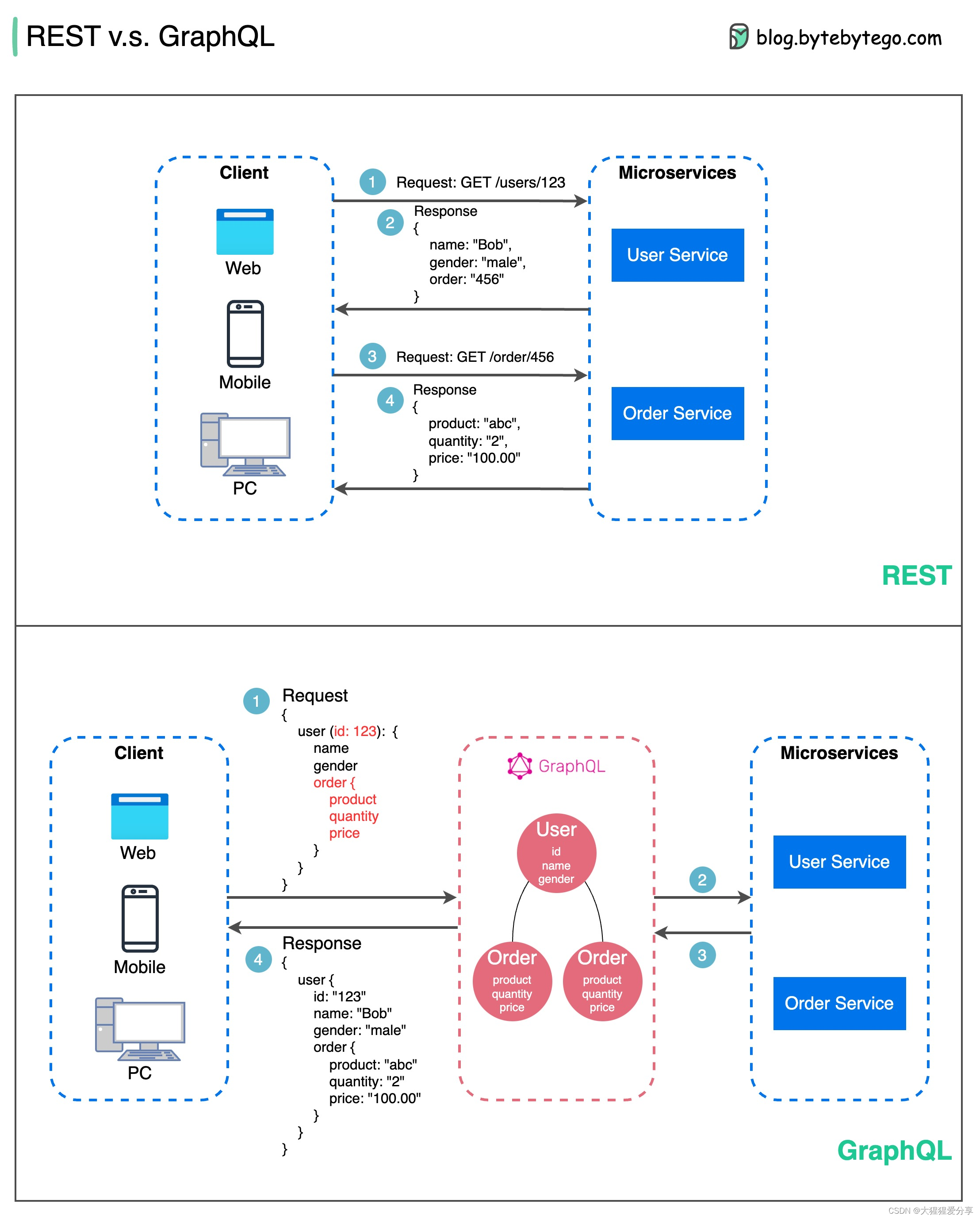
【通讯协议】REST API vs GraphQL
在API设计方面,REST和GraphQL各有缺点。下图显示了 REST 和 GraphQL 之间的快速比较。 REST 使用标准 HTTP 方法(如 GET、POST、PUT、DELETE)进行 CRUD 操作。当您需要在单独的服务/应用程序之间提供简单、统一的接口时,效果很好…...

Linux在安装epel-release时,报错epel-release-7-14.noarch.rpm 的公钥尚未安装
Linux在安装epel-release时报错: [rootXWDBDEV01 ~]# yum install epel-release 已加载插件:fastestmirror, langpacks, product-id, search-disabled-repos, subscription-managerThis system is not registered with an entitlement server. You can …...

在 STM32 上实现温度补偿和校正
本文介绍了如何在 STM32 微控制器上实现温度补偿和校正,以提高温度传感器的测量精度。首先,我们将简要介绍温度补偿和校正的原理和目的。然后,我们将详细讨论在 STM32 上实现温度补偿和校正的步骤和方法。同时,提供了一个简单的示…...
PasteNow for mac剪贴板工具
PasteNow 是一款简单易用的剪贴板管理工具,可帮助用户快速存储和管理剪贴板上的文本和图片内容。用户可以使用 PasteNow 软件快速将文本内容保存到不同的笔记或页面中,也可以方便地将剪贴板上的图片保存到本地或分享给其他应用程序。 此外,P…...

Spark---补充算子
一、Spark补充Transformation算子 1、join,leftOuterJoin,rightOuterJoin,fullOuterJoin 作用在K,V格式的RDD上。根据K进行连接,对(K,V)join(K,W)返回(K,&a…...

第一百八十回 介绍两种阴影效果
文章目录 1. 概念介绍2. 实现方法3. 代码与效果3.1 示例代码3.2 运行效果 4. 内容总结 我们在上一章回中介绍了"自定义SlideImageSwitch组件"相关的内容,本章回中将介绍两种阴影效果.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在…...
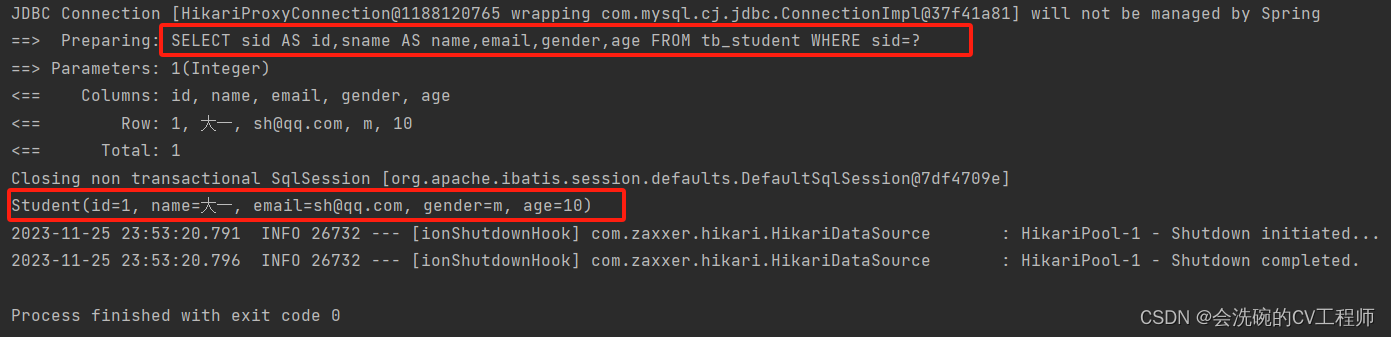
MyBatisPlus入门介绍
目录 一、MyBatisPlus介绍 润物无声 效率至上 丰富功能 二、Spring集成MyBatisPlus 三、SpringBoot集成MyBatisPlus 一、MyBatisPlus介绍 MyBatis-Plus(简称 MP)是一个MyBatis的增强工具,在MyBatis的基础上只做增强不做改变,…...

详解分布式微服务架构
目录 一、微服务简介 1、分布式微服务架的诞生 2、微服务架构与SOA架构的区别 3、微服务框架引来的问题 二、服务通信 RESTful API: 消息队列(如RabbitMQ、Kafka): gRPC: GraphQL: Service Mesh&…...
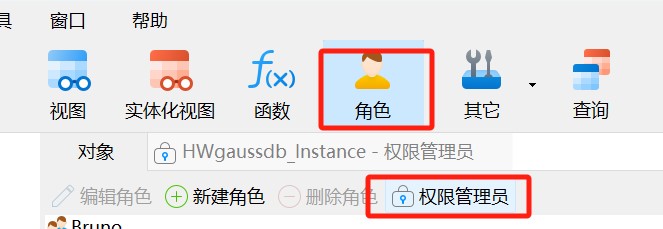
Navicat 技术指引 | 适用于 GaussDB 的用户权限设置
Navicat Premium(16.2.8 Windows版或以上) 已支持对 GaussDB 主备版的管理和开发功能。它不仅具备轻松、便捷的可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构同步、协同合作、数据迁移等),这…...

5分钟搞定Docker私有仓库:Nexus3最新版搭建与镜像上传全流程
5分钟搞定Docker私有仓库:Nexus3最新版搭建与镜像上传全流程 在当今云原生技术快速发展的背景下,企业级容器镜像管理已成为DevOps流程中不可或缺的一环。对于中小团队而言,直接使用公共镜像仓库既存在安全风险,又难以满足定制化需…...

从NCLT Dataset到ROS:高效转换rosbag的实战指南
1. NCLT Dataset简介与ROS环境准备 NCLT Dataset是由密歇根大学发布的长期自动驾驶数据集,包含激光雷达、IMU、GPS等多种传感器在校园环境持续采集的数据。这个数据集特别适合SLAM算法开发和传感器融合研究,但原始数据格式需要转换才能与ROS兼容。 我在…...

泛微ECOLOGY9-基于建模与ESB的角色成员动态同步与缓存即时刷新方案
1. 为什么需要角色成员动态同步与缓存刷新 在企业日常运营中,权限管理是个让人头疼的问题。想象一下这样的场景:某位员工刚被调岗到财务部门,理论上应该立即获得财务系统的访问权限,但实际上可能要等上几个小时甚至一天才能正常使…...

K8s 单节点 Java 微服务 OOM Kill 循环排查实战 — MaxRAMPercentage=100% 的坑
测试环境 14 个 Java 微服务频繁异常,每次都要手动重启整台机器才能恢复。排查发现是 JVM MaxRAMPercentage=100% + 容器内存限制严重超卖导致的 OOM Kill 循环。 前言 运维同事反馈:测试环境的一台 K8s 节点"老是异常,手动重启才好"。每隔一两天就要重启一次,重…...

避坑指南:ESP8266连接腾讯云物联网平台的7个常见错误及解决方法
ESP8266连接腾讯云物联网平台的7个实战避坑指南 1. 三元组配置:那些容易被忽略的细节 在ESP8266连接腾讯云物联网平台时,设备三元组(ProductID、DeviceName、DeviceSecret)的配置错误占据了连接失败案例的47%。很多开发者容易犯以…...

鸿蒙开发板编译:hb set命令的选择项是怎么来的
我用的代码是小熊派开源社区/BearPi-HM_Micro_small: https://gitee.com/bearpi/bearpi-hm_micro_small/blob/hcip/applications/BearPi/BearPi-HM_Micro/docs/device-dev/%E5%A6%82%E4%BD%95%E7%83%A7%E5%BD%95%E5%9B%BA%E4%BB%B6%E5%B9%B6%E5%90%AF%E5%8A%A8.md 在…...

智慧树刷课插件终极指南:5分钟实现自动化学习
智慧树刷课插件终极指南:5分钟实现自动化学习 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的繁琐操作而烦恼吗?智慧树刷课插…...

深度解析Jasminum:Zotero中文文献元数据智能抓取与PDF大纲管理解决方案
深度解析Jasminum:Zotero中文文献元数据智能抓取与PDF大纲管理解决方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum …...

3步解决Zotero中文文献管理难题:Jasminum插件完整指南
3步解决Zotero中文文献管理难题:Jasminum插件完整指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 作为一名中文研…...

从TSDK到温度矩阵:大疆热红外图像解析实战
1. 大疆热红外图像处理基础 大疆H20系列无人机搭载的热成像相机能够拍摄JPG格式的红外图像,但这些图像并非普通的可见光照片,而是包含了丰富的温度信息。要真正利用这些数据,我们需要理解几个关键概念: 首先,热红外图像…...