【MySQL】查询进阶

- 👑专栏内容:MySQL
- ⛪个人主页:子夜的星的主页
- 💕座右铭:前路未远,步履不停
目录
- 一、数据库约束
- 1、约束类型
- 2、`not null`
- 3、`unique`
- 4、`default`
- 5、`primary key`
- 6、`foreign key`
- 二、新增
- 三、查询
- 1、聚合查询
- 2、分组查询
- 3、联合查询
- 内连接
- 外连接
- 自连接
- 4、合并查询
一、数据库约束
1、约束类型
not null 非空:指定某列不能存储 null 值
unique 唯一:保证某列的每行必须有唯一的值
default 默认: 规定没有给列赋值时的默认值
primary key 主键: not null 和 unique 的结合,确保某列有唯一标识,有助于更容易更快速的找到表中的一个特定值
foreign key外键:保证一个表中的数据匹配另一个表中的参照完整性
check保证列中的值符合指定的条件,对于 MySQL 数据库,堆 check 子句进行分析,但是忽略 check 子句
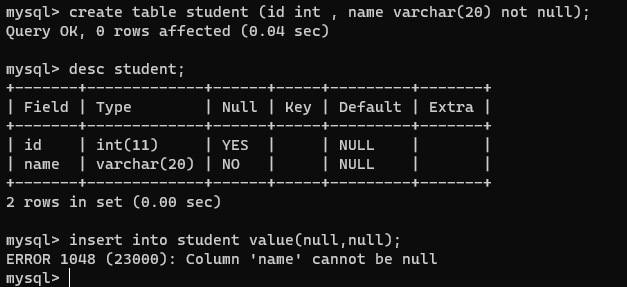
2、not null
create table student (id int , name varchar(20) not null);
3、unique
唯一,此处的限制不允许存在两行数据在指定列上重复。
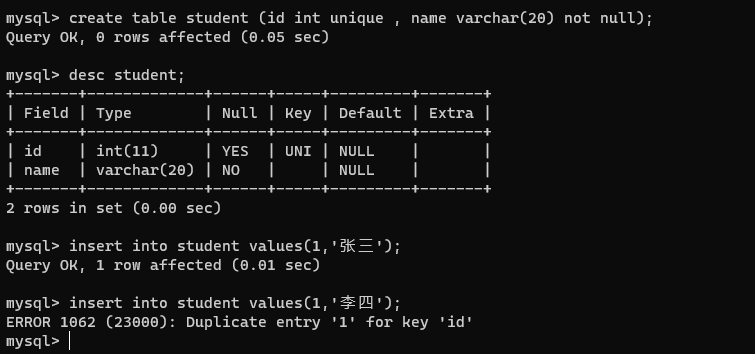
MySQL 咋找到已经有相同的数据了?
针对带有 unique 的数据,MySQL 会先进行查询,看是不是已经存在,存在就不插入了。
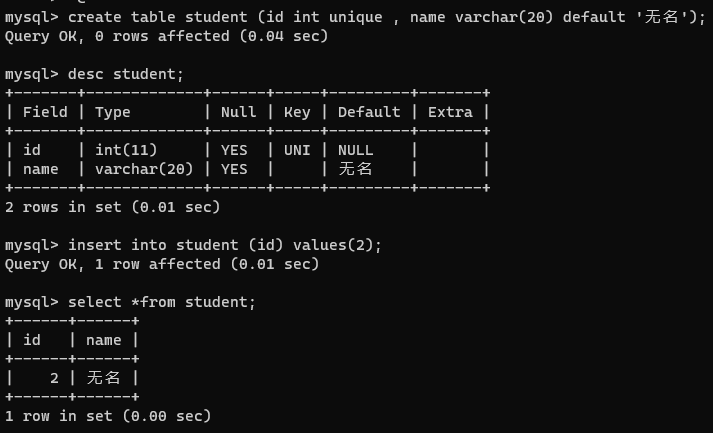
4、default
使用指定列插入的时候,未被指定的列就会按照默认值来填充。如果不修改其默认值,默认情况下的默认值就是 NULL。
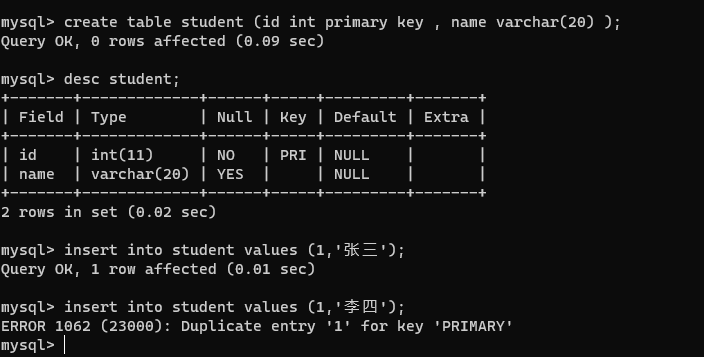
5、primary key
主键约束:一条数据的身份表示。用于区分两条数据是不是一个数据。通过这个来指定某个列作为主键。
自增主键:允许客户端在插入的时候,不指定主键的值,交给 MySQL 自己分配。
create table student (id int primary key auto_increment , name varchar(20) );
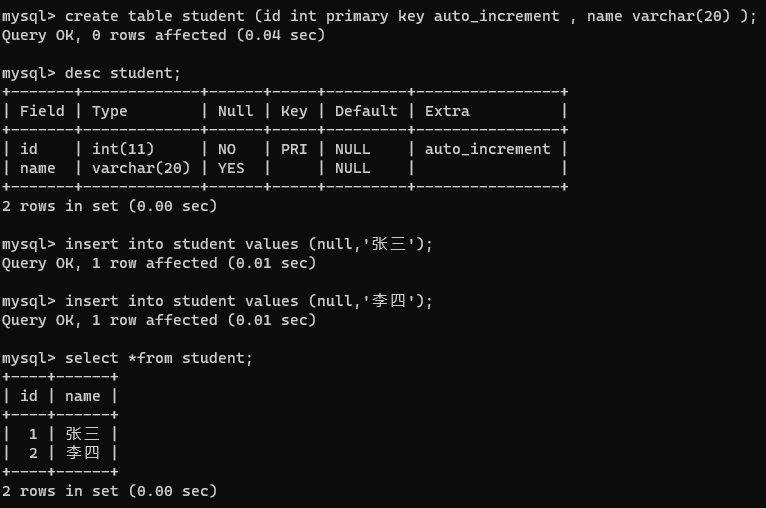
自增主键,id 用 null 是让数据库自行分配。自增主键,也是可以手动值的。下一个 分配的 id 就会在之前最大值的基础上继续自增。
当然,如果 MySQL 是单机系统,基于上面的策略是没有问题的,但是如果 MySQL 是一个分布式的系统,自增主键就没有办法保证唯一性。为了解决上述问题,也有一些分布式 id 的生成算法。把 id 作为一个字符串,字符串由下面几个部分组成:主机编号/机房编号+时间戳+随机因子。
6、foreign key
外键:涉及到两个表之间的约束。
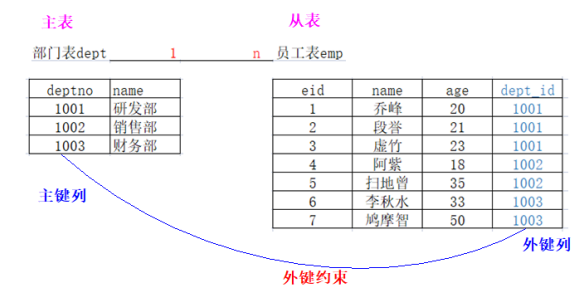
主(父)表用来约束从(子)表的。
create table dept(deptno int primary key,name varchar(20));
create table emp (id int primary key auto_increment , name varchar(20) ,
dept_id int ,foreign key(dept_id) references dept(deptno));
插入或者修改子表中受约束的这一列的数据,需要保证在父表中存在该数据。

删除或者修改父表中的记录,就需要看这个记录是否在子表中被使用了,如果被使用了,则不能进行删除或者修改。
二、新增
新增操作:把 insert和 select两个操作合并在一起。
insert into 表名 [(colum [,colum....])] select
insert into student2 select *from student;
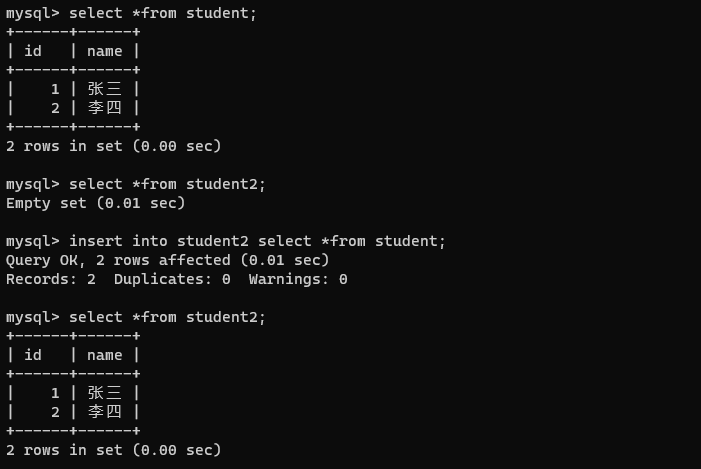
此处的select查询的结构,得到的和你插入的那个表,得能对应(列的数目、类型、约束得匹配)

三、查询
1、聚合查询
查询的时候带表达式,本质上是用在列和列之间进行运算。
还有的时候,我们需要在行和行之间进行运算,这时候表达式查询就完全不行了。我们的聚合查询就是为了解决行与行之间的查询。
| 函数 | 说明 |
|---|---|
count([distinct] expr) | 返回查询到的数据的 数量 |
sum([distinct] expr) | 返回查询到的数据的 总和 |
avg([distinct] expr) | 返回查询到的数据的 平均值 |
max([distinct] expr) | 返回查询到的数据的 最大值 |
min([distinct] expr) | 返回查询到的数据的 最小值 |
select count(*) from student_scores;
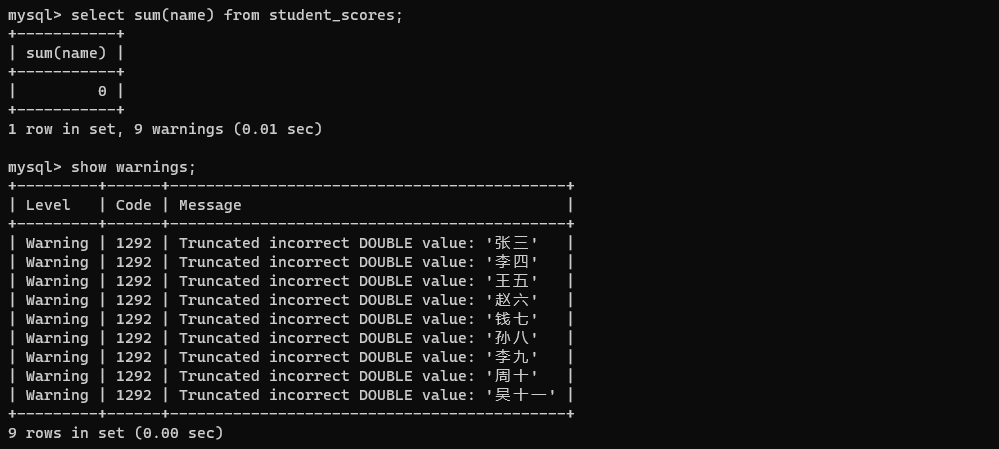
select count(name) from student_scores;
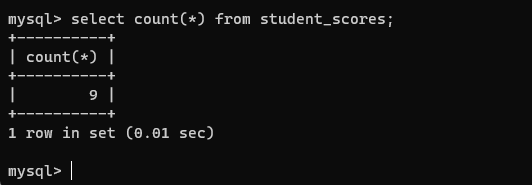
注意:在 sql 中聚合函数和()必须要紧紧的挨在一起。
select sum(math) from student_scores;
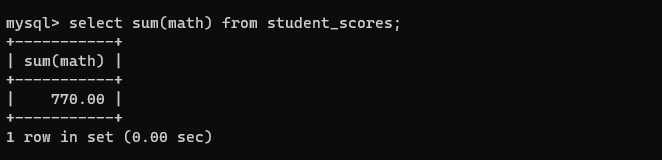
sum 是进行求和,会把这一列的若干行强行先转化为 double ,如果是字符类型就会出现问题。
 通过
通过 show warnings可以查看警告信息。
2、分组查询
group by 会指定一个列,按照这一列进行分组。这一列中,数值相同的行会被放到一组。每个分组中,都可以使用聚合函数进行计算。

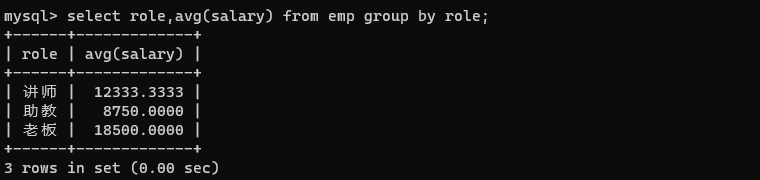
查询出每个岗位的平均薪资。此处可以用 role 进行分组,把 role 相同的放到一组。
select role,avg(salary) from emp group by role;
在分组查询中,select 中指定的列必须是当前 group by 指定的列,如果 select 中想用到其他的列,其他的列必须要放到聚合函数中,否则没有意义。
select role,name,avg(salary) from emp group by role;
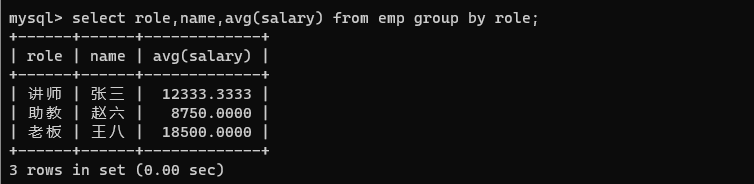
例如这样,就没有意义。role 其实只有三种情况,但是 name 有 6 个,按照上述的查询,只能现实三个结果,所以没有任何意义。此处现实的三个名字,是每组的第一个名字。没有任何意义。
分组查询也是可以搭配条件来使用的。这里的条件有两种情况
- 分组之前的条件:
where
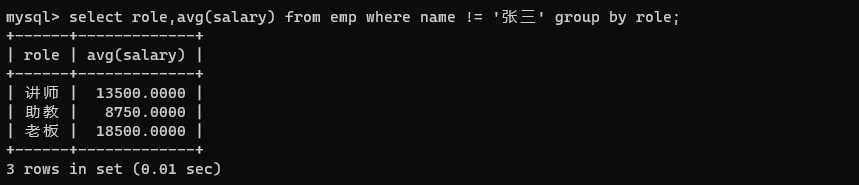
求每个岗位的平均薪资,但是除去张三的薪资。
select role,avg(salary) from emp where name != '张三' group by role;
- 分组之后的条件:
having
求每个岗位的平均薪资,除去平均薪资超过 18000 的。
select role ,avg(salary) from emp group by role having avg(salary) < 18000;

一个 sql 中可以同时包含分组前的条件和分组后的条件。
求每个岗位的平均薪资,除去张三和平均薪资超过 18000 的。
select role ,avg(salary) from emp where name !='张三' group by role having avg(salary) < 18000;

3、联合查询
查询中最复杂的写法。联合查询也叫多表查询,是针对多张表进行查询。
【笛卡尔积】数学上的运算,描述了多表查询的基本执行逻辑。
笛卡尔积,其实就是把两个表里的记录,按照排列组合的方式,构造成了一个更大的表了,笛卡尔积的列数,其实就说原来两个表的列数之和。笛卡尔积的行数,就是原来两个表的行数之积。
笛卡尔积是一个非常低效的操作,所以联合查询也是一个非常低效的操作。
实际开发中,使用联合查询一定要非常慎重。
-- 创建班级表
CREATE TABLE Classes (ClassID INT PRIMARY KEY,ClassName VARCHAR(50) NOT NULL,CreateDate DATE
);-- 插入班级数据
INSERT INTO Classes (ClassID, ClassName, CreateDate) VALUES
(1, '高一1班', '2023-01-01'),
(2, '高一2班', '2023-02-01'),
(3, '高二1班', '2023-03-01');-- 创建学生表
CREATE TABLE Students (StudentID INT PRIMARY KEY,Name VARCHAR(100) NOT NULL,ClassID INT,EnrollmentDate DATE,FOREIGN KEY (ClassID) REFERENCES Classes(ClassID)
);-- 插入学生数据
INSERT INTO Students (StudentID, Name, ClassID, EnrollmentDate) VALUES
(1, '王小明', 1, '2023-01-15'),
(2, '李芳', 1, '2023-01-20'),
(3, '张强', 2, '2023-02-10'),
(4, '刘婷', 3, '2023-03-05');-- 创建课程表
CREATE TABLE Courses (CourseID INT PRIMARY KEY,CourseName VARCHAR(50) NOT NULL
);-- 插入课程数据
INSERT INTO Courses (CourseID, CourseName) VALUES
(1, '数学'),
(2, '历史'),
(3, '物理');-- 创建分数表
CREATE TABLE Scores (StudentID INT,CourseID INT,Score INT,PRIMARY KEY (StudentID, CourseID),FOREIGN KEY (StudentID) REFERENCES Students(StudentID),FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);-- 插入分数数据
INSERT INTO Scores (StudentID, CourseID, Score) VALUES
(1, 1, 85),
(1, 2, 90),
(2, 1, 78),
(2, 2, 88),
(3, 2, 92),
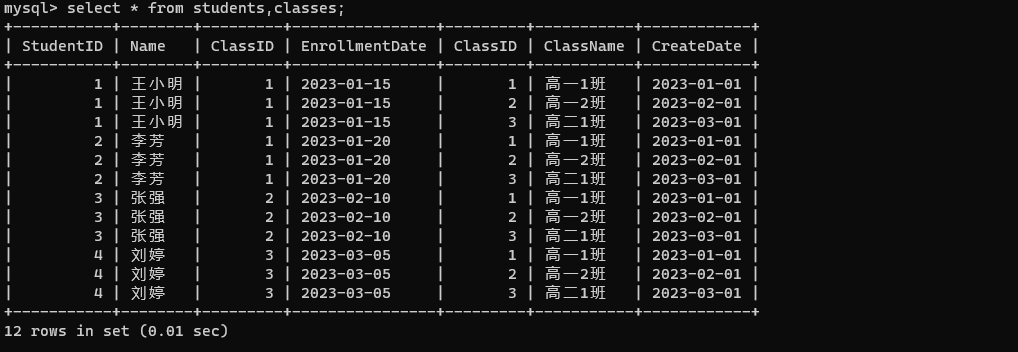
(4, 3, 80);查看学生表和班级表进行笛卡尔积的结果。
内连接
select * from students,classes;
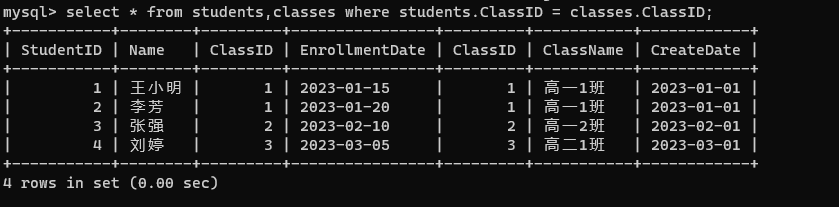
如果是单个表,条件中直接写列名即可。如果是多个表进行查询,那么条件中最好是写 表名.列名。
进行联合查询的这两个表中,有些列名可能是一样的。如果列名没有重复的,此时直接写列名也不是不行,但是最好是带上表名。
select * from students,classes where students.ClassID = classes.ClassID;
笛卡尔积 + 必要的条件 => 多表联合查询
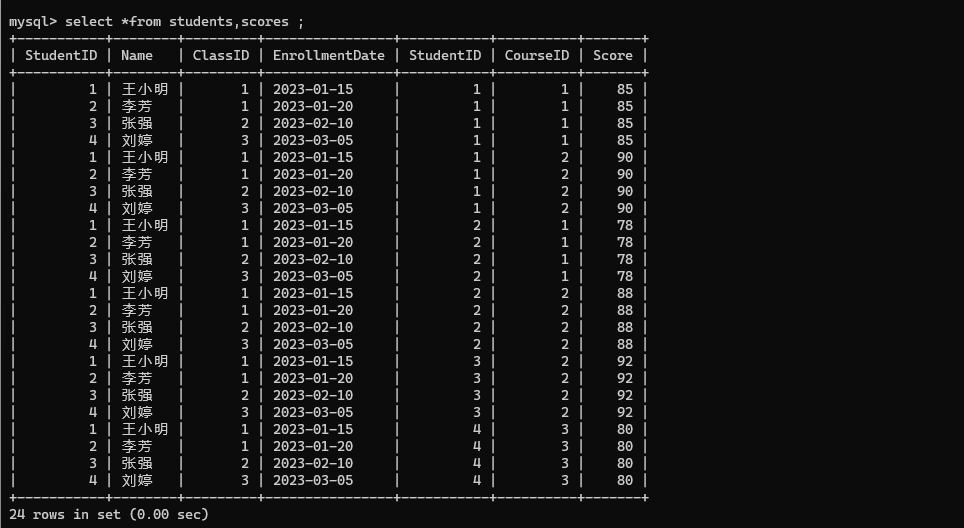
查询王小明同学的成绩:
- 先计算学生表和成绩表的笛卡尔积。
select *from students,scores ;
- 指定连接条件: StudentID 是存在对应关系的,按照 ID 进行筛选。
select *from students,scores where students.StudentID = scores.StudentID;
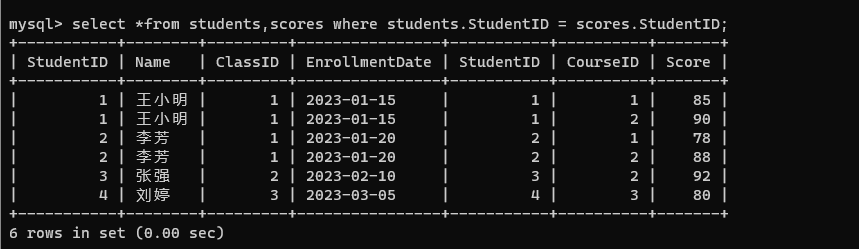
当前筛选后的就是每个同学每门课的成绩。
- 根据需求添加条件,按照名字为王小明再进行筛选。
select *from students,scores where students.StudentID = scores.StudentID and students.name = '王小明';

- 针对查询的结果的列进行精简。
select students.name,scores.score from students,scores where students.StudentID = scores.StudentID and students.name = '王小明';

查询所有同学的总成绩:
每个同学可以有很多课程,这几门课的成绩是按行来组织的。
- 先计算学生表和成绩表的笛卡尔积。
select * from students,scores;
- 指定连接条件: StudentID 是存在对应关系的,按照 ID 进行筛选。
select *from students,scores where students.StudentID = scores.StudentID;
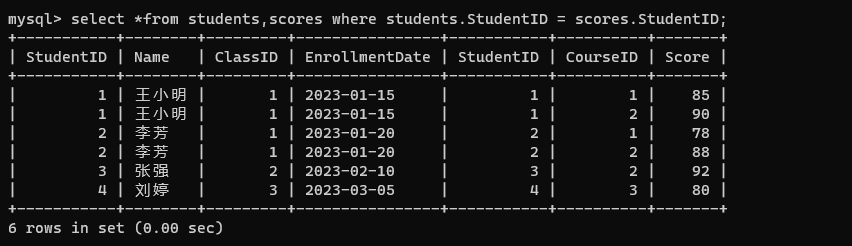
- 根据需求添加条件,按照学生维度进行 group by
select *from students,scores where students.StudentID = scores.StudentID group by students.name ;
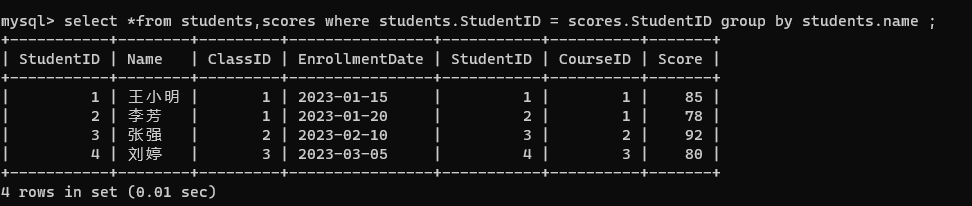
- 搭配聚合函数,针对分数进行计算
select name,sum(scores.score) from students,scores where students.StudentID = scores.StudentID group by students.
name ;
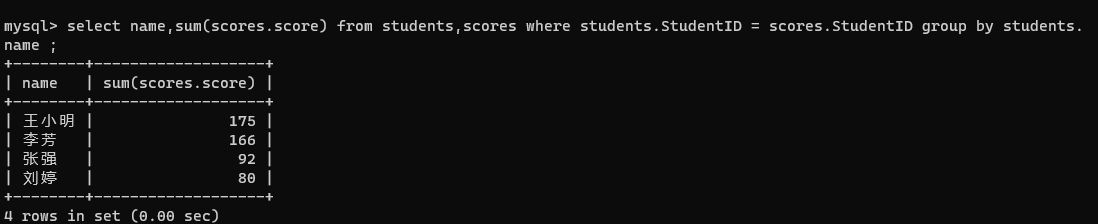
查询所有同学的总成绩,及同学的个人信息(列出名字、课程、分数):
- 先计算学生表和成绩表,课程表的笛卡尔积。
select * from courses,scores,students;
- 指定连接条件: 分数表是学生表和课程表的关联表。此处三个表进行笛卡尔积筛选数据,就需要两个连接条件。
select * from courses,scores,students where scores.StudentID = students.StudentID and scores.CourseID = courses.C
ourseID;
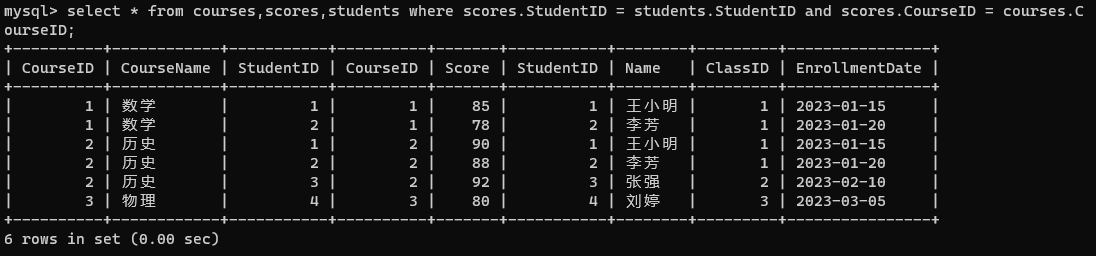
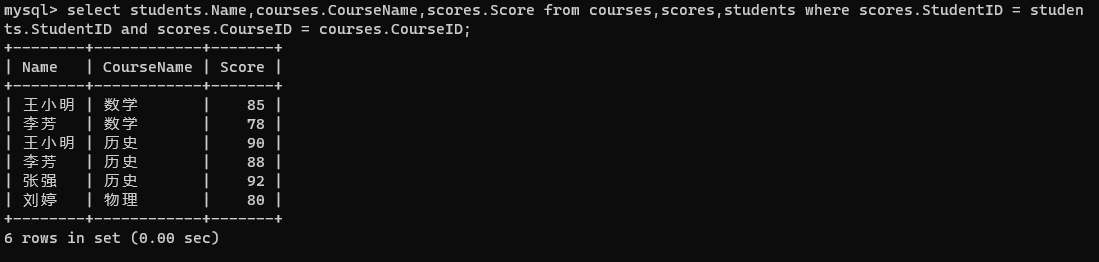
- 根据需求添加条件
select students.Name,courses.CourseName,scores.Score from courses,scores,students where scores.StudentID = studen
ts.StudentID and scores.CourseID = courses.CourseID;
select students.Name as '姓名',courses.CourseName as '课程',scores.Score as '分数'from courses,scores,students wh
ere scores.StudentID = students.StudentID and scores.CourseID = courses.CourseID;
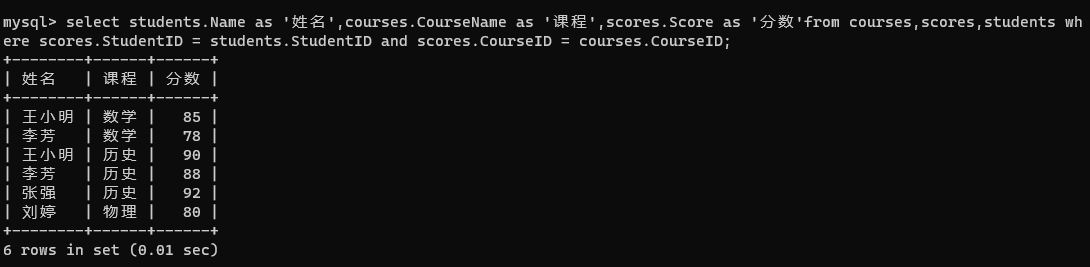
前面的写法都是内连接的写法,内连接除了这种写法外还有一种写法,那就是使用 inner join 其中 inner可以省略。前面使用 ,分割,现在使用 join分割,前面的连接方式使用 where,现在使用 on来指定。
查询王小明同学的成绩:
- 直接只写 join 没有 on 则是一个完整的笛卡尔积
select * from student join score;
- 使用
on表示连接条件
select * from students join scores on students.StudentID = scores.StudentID;
- 根据需求添加条件
select * from students join scores on students.StudentID = scores.StudentID and students.name = '王小明';
- 对列进行精简
select students.name,scores.score from students join scores on students.StudentID = scores.StudentID and students.name = '王小明';
外连接
join on还可以用来表示外连接。
内连接和外连接有什么区别?内连接(Inner Join)和外连接(Outer Join)是 SQL 中用于联接表格的两种主要方法。它们之间的主要区别在于如何处理未匹配的行。
- 内连接(Inner Join):
- 内连接只返回两个表之间匹配的行,即满足连接条件的行。
- 如果在一个表中找不到匹配的行,那么这些行将被忽略,不会出现在结果集中。
- 内连接使用 INNER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
INNER JOIN Classes ON Students.ClassID = Classes.ClassID;
- 左外连接(Left Outer Join):
- 左外连接返回左边表(即在 FROM 关键字之前的表)中的所有行,以及右边表中与左边表匹配的行。
- 如果在右边表中找不到匹配的行,那么将在结果中显示 NULL 值。
- 左外连接使用 LEFT JOIN 或 LEFT OUTER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
LEFT JOIN Classes ON Students.ClassID = Classes.ClassID;
- 右外连接(Right Outer Join):
- 右外连接与左外连接相反,返回右边表中的所有行,以及左边表中与右边表匹配的行。
- 如果在左边表中找不到匹配的行,那么将在结果中显示 NULL 值。
- 右外连接使用 RIGHT JOIN 或 RIGHT OUTER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
RIGHT JOIN Classes ON Students.ClassID = Classes.ClassID;
- 全外连接(Full Outer Join):
- 全外连接返回左右两个表中的所有行,如果没有匹配的行,将在结果中显示 NULL 值。
- 全外连接使用 FULL JOIN 或 FULL OUTER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
FULL JOIN Classes ON Students.ClassID = Classes.ClassID;
总的来说,内连接只返回匹配的行,而外连接则返回匹配的行以及未匹配的行,用 NULL 值表示未匹配的部分。选择使用哪种连接取决于你的需求和数据关系。
内连接产生的结果,一定是两个表中都存在的数据(公共部分)
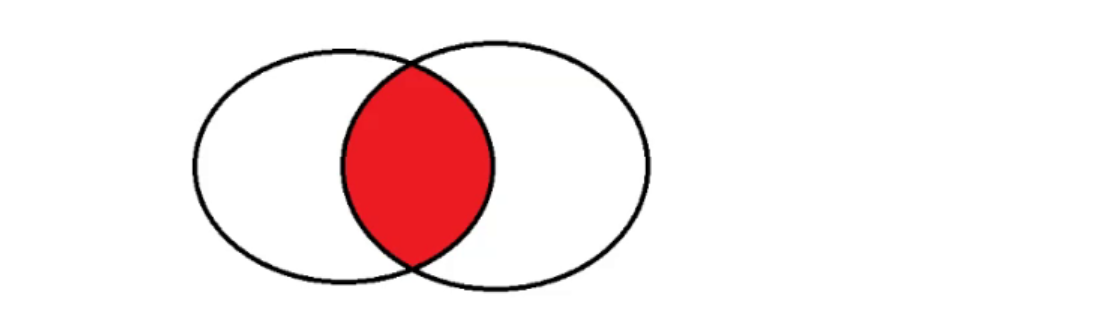
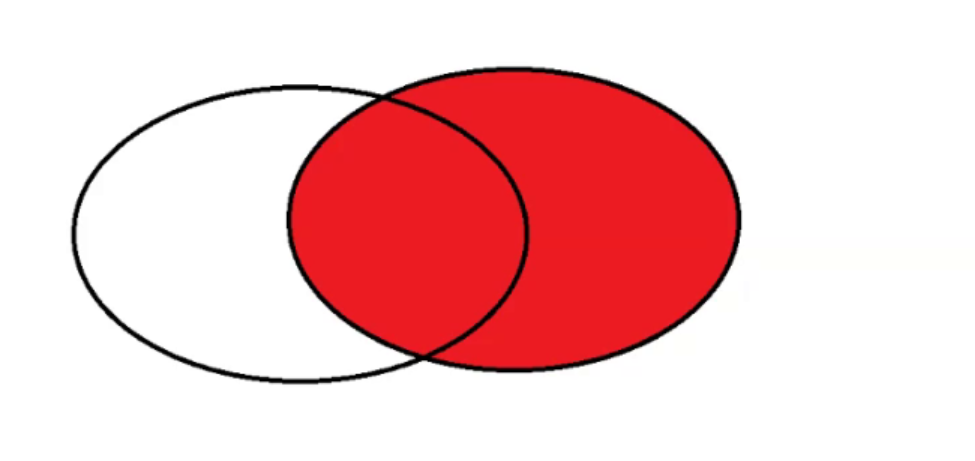
外连接中,在 MySQL 里面有两种情况。左外连接 left join 和右外连接 right join。
左外连接就是以左侧的表为主,左侧表的每一个记录值都会存在于结果中,如果遇到了左侧表存在,但是右侧表不存在的值,此时就会把对应的列变为空值。
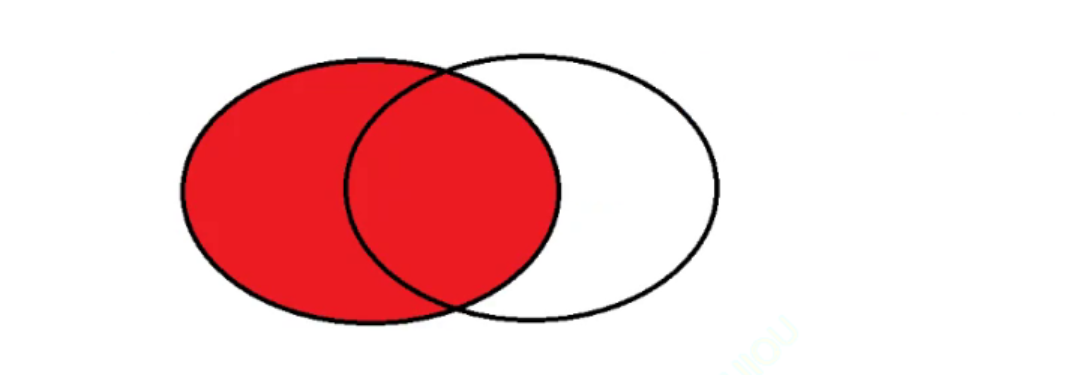
右外连接,就是以右侧为主。

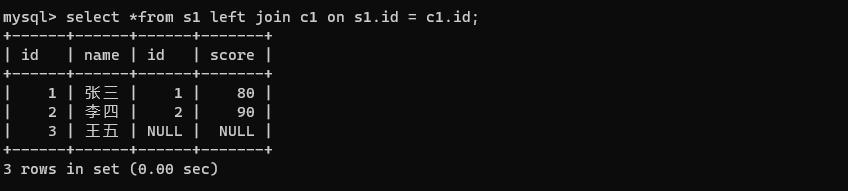
select *from s1 join c1 on s1.id = c1.id;

select *from s1 left join c1 on s1.id = c1.id;
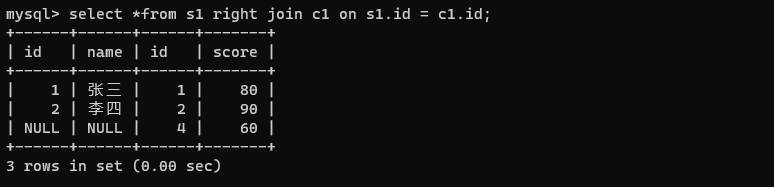
select *from s1 right join c1 on s1.id = c1.id;
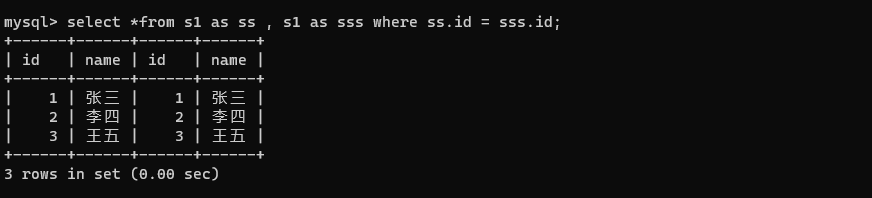
自连接
本质上是自己和自己做笛卡尔积。
自连接本质是把行之间的关系,转化为列之间的关系。SQL 中,编写条件,条件都是列和列之间进行比较。但是 SQL 无法直接进行行和行之间的比较。
select *from s1 as ss , s1 as sss;
select多个表的时候,名字不能相同,以此需要取别名进行区分。

select *from s1 as ss , s1 as sss where ss.id = sss.id;
4、合并查询
把多个select查询得到的结果集合合并成一个集合。
关键字:union和 union all
select * from s1 union select * from s2;
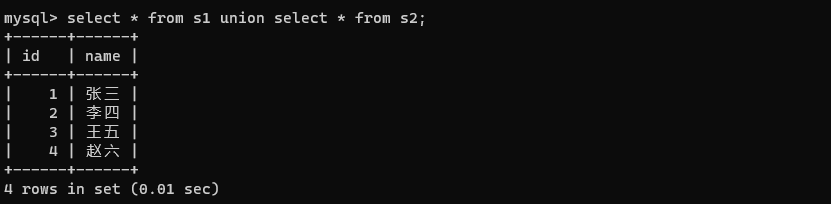
能合并的前提是这两个查询的结果集是对应的。
select * from s1 union all select * from s2;
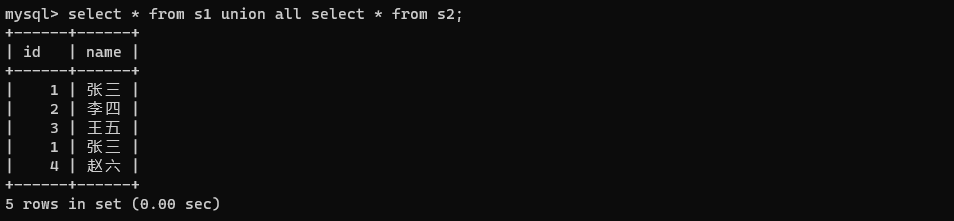
union all不会去重,而union会进行去重。
相关文章:
【MySQL】查询进阶
👑专栏内容:MySQL⛪个人主页:子夜的星的主页💕座右铭:前路未远,步履不停 目录 一、数据库约束1、约束类型2、not null3、unique4、default5、primary key6、foreign key 二、新增三、查询1、聚合查询2、分组…...
C++学习之路(五)C++ 实现简单的文件管理系统命令行应用 - 示例代码拆分讲解
简单的文件管理系统示例介绍: 这个文件管理系统示例是一个简单的命令行程序,允许用户进行文件的创建、读取、追加内容和删除操作。这个示例涉及了一些基本的文件操作和用户交互。 功能概述: 创建文件 (createFile()): 用户可以输入文件名和内…...

Node.js下载安装及配置镜像源
一、进入官网地址下载安装包 https://nodejs.org/dist 选择对应你系统的Node.js版本 这里我选择的是Windows系统、64位 二、安装程序 (1)下载完成后,双击安装包,开始安装Node.js (2)直接点【Next】按钮,此处可根据…...

RAC 下expdp impdp 并行 parallel FK
1. dump 文件非共享下的并行 Customer receives the following errors: ORA-31693: Table data object "<SCHEMA_NAME>"."<TABLE_NAME>" failed to load/unload and is being skipped due to error: ORA-31617: unable to open dump file &qu…...
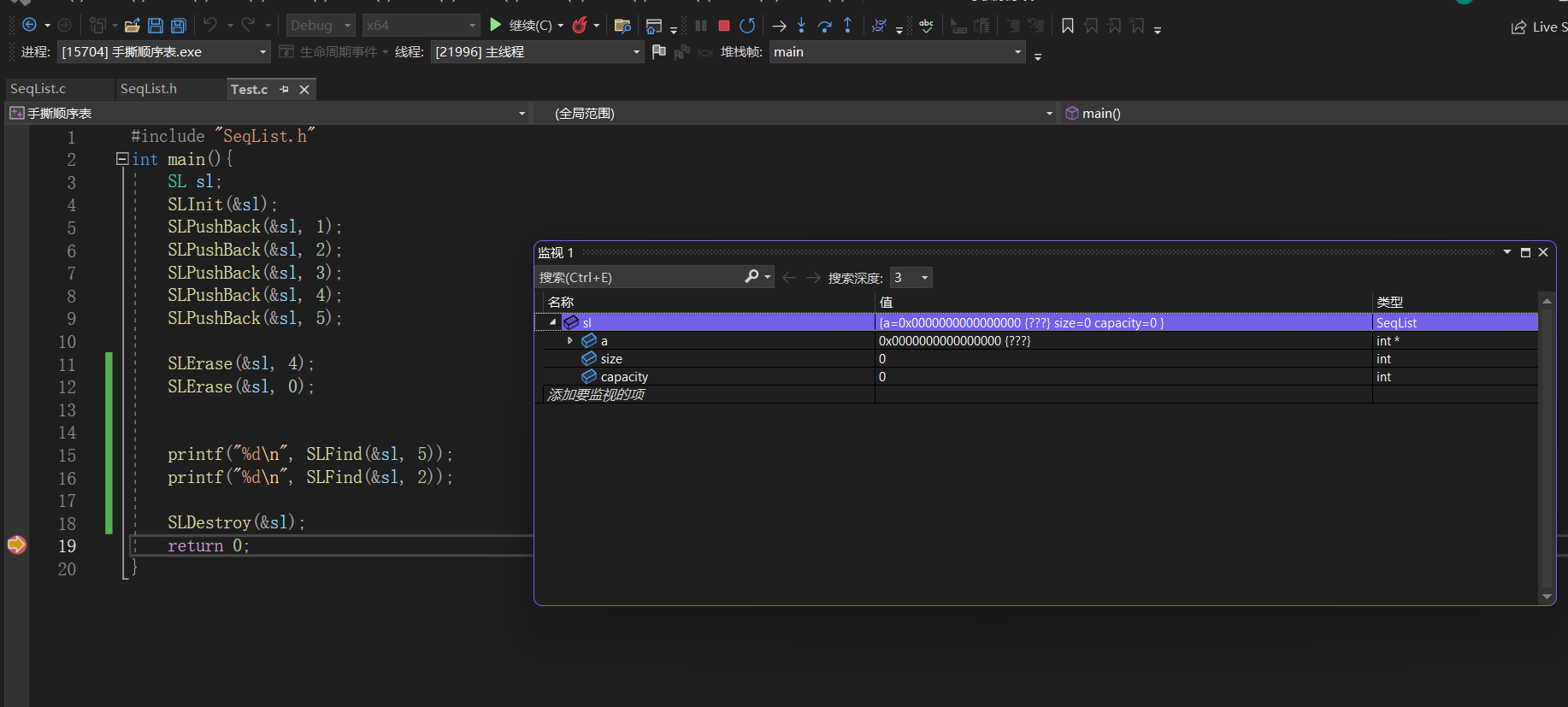
【数据结构】动态顺序表详解
目录 1.顺序表的概念及结构 2.动态顺序表的实现 2.1创建新项目 2.2动态顺序表的创建 2.3接口的实现及测其功能 2.3.1初始化 2.3.2尾插 2.3.3头插 2.3.4尾删&头删 2.3.5打印&从任意位置插入 2.3.6删除任意位置的数据 2.3.7查找 2.3.8销毁顺序表 3.结语 He…...

Nginx代理https请求的操作过程
理论很简单,过程很曲折,版本适配的问题要小心。 场景: 要和前端进行联调,我本地后端用了https,证书是自制的,主要是页面里面有一些oauth2认证的地方,需要跳转。 比如https://aaa.com/profile.h…...

Linux 面试题(一)
目录 1、绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令? 2、怎么查看当前进程?怎么执行退出?怎么查看当前路径? 3、怎么清屏?怎么退出当前命…...

HIVE SQL取整函数汇总
目录 int()round(double a)round(double a,int d)floor()ceil() int() 向零取整,即向接近零的方向取整。 int(5.6)输出:5 int(-5.6)输出:-5 round(double a) 四舍五入取整 select round(5.6)输出:6 select round(-5.6)输出&…...

VMware 虚拟机设置静态IP
1.桥接模式:无线网卡虚拟机可以桥接的,Vmware0是虚拟机默认进入的虚拟网络,打开虚拟网络编辑器把Vmware0桥接到具体的无线网卡上,再打开网卡设置选择桥接模式即可。 2、.NAT模式下 :window下VMnet8: IPv4 地址 . . . …...

pandas 如何获取dataframe的行的数量
pandas的dataframe提供了多种方法获取其中数据的行的数量,本偏文章就是介绍几种获取dataframe行和列出量的方法。 为了能够详细说明如何通过代码获取dataframe的行数和列数,需要先创建一个dataframe如下: import pandas as pdtechnologies …...

css实现图片绕中心旋转,鼠标悬浮按钮炫酷展示
vue模板中代码 <div class"contentBox clearfix home"><div class"circle"><img class"in-circle" src"../../assets/img/in-circle.png" alt""><img class"out-circle" src"../../as…...

C++11的线程
线程的创建 用std::thread创建线程非常简单,只需要提供线程函数或者线程对象即可,并可以同时指定线程函数的参数。下面是创建线程的示例: #include <thread> #include <iostream> using namespace std;void func() {cout <<…...

Deepmind开发音频模型Lyria 用于生成高品质音乐;创建亚马逊新产品评论摘要
🦉 AI新闻 🚀 Deepmind开发音频模型Lyria 用于生成高品质音乐 摘要:Deepmind推出名为Lyria的音频模型,可生成带有乐器和人声的高品质音乐。Lyria模型针对音乐生成的挑战,解决了音乐信息密度高、音乐序列中的连续性维…...
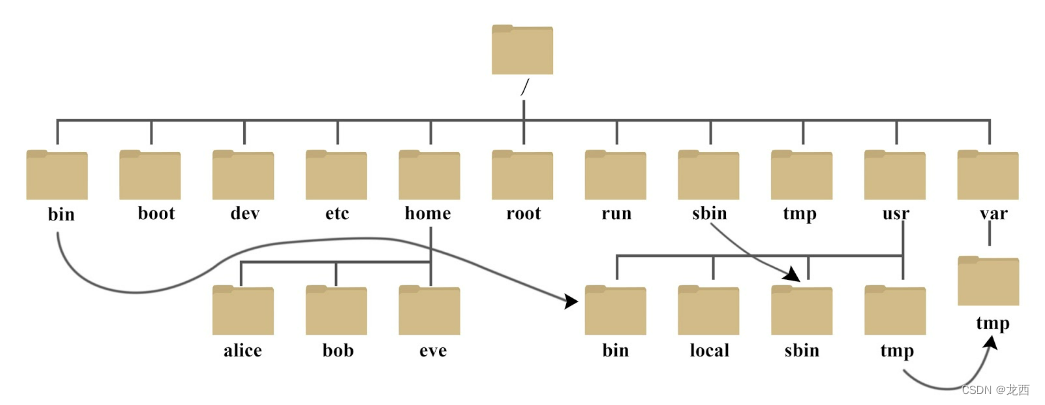
Liunx系统使用超详细(一)
目录 一、Liunx系统的认识 二、Liunx和Windows区别 三、Liunx命令提示符介绍 四、Liunx目录结构 一、Liunx系统的认识 Linux系统是一种开源的、类Unix操作系统内核的实现,它基于Unix的设计原理和思想,并在全球范围内广泛应用。以下是对Linux系统的详…...
C语言标准
1、概述 C语言标准是由ANSI(美国国家标准协会)和ISO(国际标准化组织)共同制定的一种语言规范。标准经历过如下更新: C89/C90标准C99标准C11标准C17标准 2、C89/C90标准 (1)这是1989年正式发布的C语言标准࿰…...

TI 毫米波雷达开发系列之mmWave Studio 和 Visuiallizer 的异同点雷达影响因素分析
TI 毫米波雷达开发之mmWave Studio 和 Visuiallizer 的异同点 引入整个雷达系统研究的目标分析影响这个目标的因素硬件影响因素 —— 雷达系统的硬件结构(主要是雷达收发机)AWR1642芯片硬件系统组成MSS 和 DSS 概述MSS 和 DSS 分工BSS的分工AWR1642 组成…...
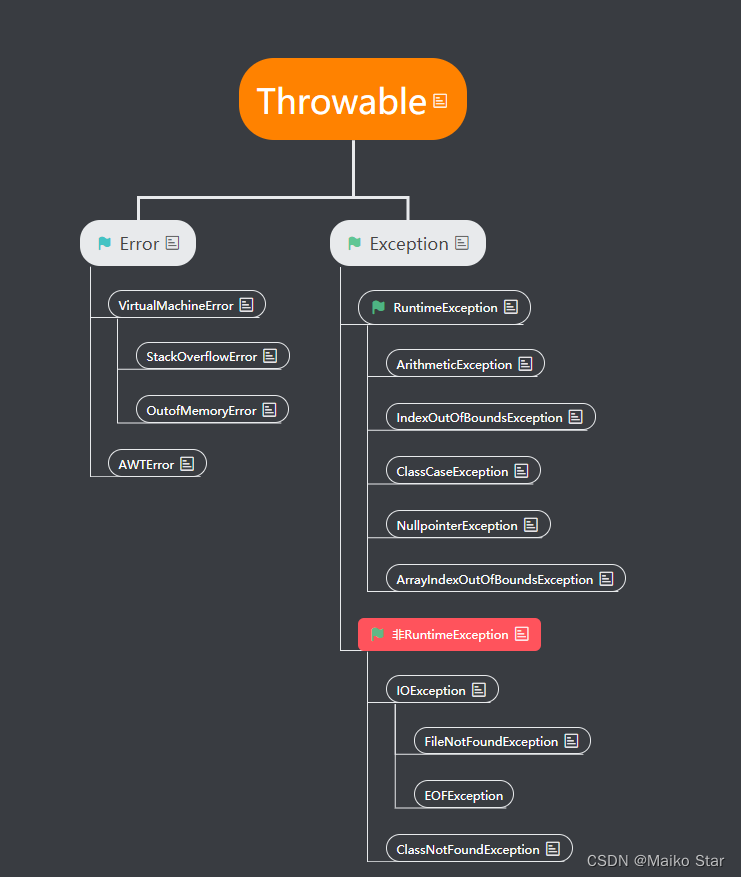
SpringBoot事务处理
一、事务回顾 回顾地址: 深入理解数据库事务(超详细)_数据库事务操作_Maiko Star的博客-CSDN博客 事务: 是一组操作的集合,是一个不可分割的工作单位,这些操作要么同时成功,要么同时失败 事…...

网络安全—自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...
)
首页以卡片形式来展示区块链列表数据(Web3项目一实战之五)
我们已然在 Web3 分布式存储 IPFS(Web3项目一实战之四) 介绍了什么是IPFS,以及在本地电脑如何安装它。虽然在上一篇讲解了该怎么安装IPFS,也做了相应的配置,但在本地开发阶段,前端总是无法避免跨域这个远程请求api的”家常便饭的通病“。 很显然,对于出现跨域这类常见问…...
)
opencv使用pyinstaller打包错误:‘can‘t find starting number (in the name of file)
使用Python语言和opencv模块在pycharm中编辑的代码运行没问题,但是在使用pyinstaller打包后出现错误can‘t find starting number (in the name of file) [ERROR:0] global C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-q3d_8t8e\opencv\modules\videoi…...

前端性能排查实战:Chrome Network面板里Timing那7个阶段到底怎么看?
Chrome Network面板Timing分析实战:从指标到性能优化 页面加载缓慢时,Chrome DevTools的Network面板中的Timing指标就像犯罪现场的指纹,每个数字背后都隐藏着性能问题的真相。但面对Queueing、Stalled、TTFB这些专业术语,很多开发…...

【51 单片机入门到进阶】10 入门:51单片机模块化编程
一,什么是模块化设计 把一个大程序,按功能拆成一个个独立的小文件、小函数,分开写、分开管理。 例如: led.c / led.h → 负责 LEDkey.c / key.h → 负责按键uart.c / uart.h → 负责串口hc_sr04.c / hc_sr04.c → 负责超声波main.…...

服务发现延迟飙升2300ms?深度解析大模型动态路由下Consul/Etcd/Nacos在千节点规模下的注册抖动瓶颈
第一章:大模型工程化服务发现与注册机制 2026奇点智能技术大会(https://ml-summit.org) 在大模型工程化落地过程中,服务发现与注册机制是实现弹性扩缩容、多实例协同推理及灰度发布的关键基础设施。不同于传统微服务,大模型服务具有高内存占…...

告别单调点云!用Open3D玩转点云上色:单色、概率映射与局部高亮实战
告别单调点云!用Open3D玩转点云上色:单色、概率映射与局部高亮实战 点云数据作为三维空间信息的直观载体,在自动驾驶、工业检测、数字孪生等领域扮演着关键角色。然而,当面对数以百万计的原始点云时,单调的灰色点阵往往…...
---HITL(Human In The Loop)邪)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---HITL(Human In The Loop)邪
插件化架构 v3 版本最大的变化是引入了模块化插件系统。此前版本中集成在核心包里的原生功能,现在被拆分成独立的插件。 每个插件都是一个独立的 Composer 包,包含 Swift 和 Kotlin 代码、权限清单以及原生依赖。开发者只需安装实际用到的插件࿰…...

27,000张卫星影像:EuroSAT如何重塑遥感图像分类新标准
27,000张卫星影像:EuroSAT如何重塑遥感图像分类新标准 【免费下载链接】EuroSAT EuroSAT: Land Use and Land Cover Classification with Sentinel-2 项目地址: https://gitcode.com/gh_mirrors/eu/EuroSAT EuroSAT是一个基于Sentinel-2卫星影像的开源遥感数…...
)
Mac终端玩转OpenSSL:3分钟搞定RSA密钥对生成(附PKCS8格式转换技巧)
Mac终端玩转OpenSSL:3分钟搞定RSA密钥对生成(附PKCS8格式转换技巧) 在数字安全领域,RSA算法一直是加密通信的基石。对于Mac用户而言,系统自带的OpenSSL工具链让密钥管理变得异常简单。本文将带你用终端快速生成RSA密钥…...

FastAPI项目里那个烦人的favicon.ico 404报错,3分钟教你彻底搞定它
FastAPI开发中favicon.ico报错的深度解决方案与技术内幕 当你启动FastAPI开发服务器时,控制台突然跳出GET /favicon.ico HTTP/1.1" 404 Not Found的红色警告,这场景是不是很熟悉?作为一个长期使用FastAPI的开发者,我完全理解…...

Gemini-CLI 从零到精通的命令行AI开发指南
1. 认识Gemini-CLI:你的命令行AI助手 第一次听说Gemini-CLI时,我也觉得这不过又是一个AI玩具。直到在本地终端里用它5分钟写完一个Python爬虫脚本,才意识到这个命令行工具的强大。简单来说,Gemini-CLI就像把Google最先进的AI模型…...

为什么93%的企业NER项目卡在第2.7阶段?——基于奇点大会27家头部厂商落地数据的断点诊断模型
第一章:为什么93%的企业NER项目卡在第2.7阶段? 2026奇点智能技术大会(https://ml-summit.org) “第2.7阶段”并非官方标准,而是工业界对NER(命名实体识别)落地过程中一个高频失败临界点的戏称——它介于完成模型训练&…...