清华提出 SoRA,参数量只有 LoRA 的 70%,表现更好!
现在有很多关于大型语言模型(LLM)的研究,都围绕着如何高效微调展开。微调是利用模型在大规模通用数据上学到的知识,通过有针对性的小规模下游任务数据,使模型更好地适应具体任务的训练方法。
在先前的工作中,全量微调的训练代价昂贵、Adapter Tuning 的训练和推理存在延迟,Prefix Tuning 会减少原始训练数据中的有效文字长度,因此有人提出使用低秩微调 LoRA,在原始预训练矩阵的旁路上,用低秩矩阵 A 和 B 来近似替代增量更新。
近期,又有了新方法助力大型语言模型更高效地适应任务!来自清华的研究团队在 LoRA 的基础上,提出了一项名为 Sparse Low-Rank Adaptation(SoRA)的创新微调方法,通过动态调整内在秩,实现了对预训练模型的高效微调。SoRA 不仅在多项任务上取得了令人瞩目的性能,而且通过稀疏方式显著减少了参数数量,加速了训练过程。
论文题目:
Sparse Low-rank Adaptation of Pre-trained Language Models
论文链接:
https://arxiv.org/abs/2311.11696
GitHub 地址:
https://github.com/TsinghuaC3I/SoRA
微调策略
全量微调
全量微调(full-parameter fine-tuning)是指在微调预训练模型时,对整个模型的所有参数进行调整。
-
在预训练阶段,模型使用大规模数据集进行训练,学习了通用的语言表示。
-
在微调阶段,模型根据特定任务或领域的小规模数据集进行进一步训练,以适应特定任务的要求。
全量微调的过程包括调整模型的所有权重和参数,使其更好地适应微调阶段的任务。
-
优点:模型可以充分利用预训练阶段学到的通用知识。
-
缺点:需要较大的计算资源和时间,并且在一些小规模任务上容易过拟合。
参数效率微调
参数效率微调是一类微调预训练模型的策略,旨在通过调整模型的部分参数而不是整个参数集,以降低计算成本、提高微调效率,并在小规模任务上取得良好性能。这些方法的核心思想是在保留模型在大规模预训练任务中学到的通用知识的同时,通过有选择地微调模型的部分参数,减少计算开销和提高微调效率,并使其更适应特定任务。这些方法特别是在资源受限或数据有限的情况下很有效。
-
适配器(Adapter): 这是一种轻量级的模型扩展方法,通过在预训练模型的层之间插入额外的小型神经网络(适配器)来微调模型。这些适配器仅包含相对较少的参数,因此微调的计算成本相对较低。
-
低秩自适应(Low-Rank Adaptation,LoRA): 使用低秩矩阵来近似权重的变化,从而减少需要微调的参数数量。通过冻结大多数预训练权重,只微调低秩矩阵的参数,可以在保留性能的同时显著减少计算开销。
什么是近端正则化?
近端梯度方法是一类优化算法,通常用于处理带有正则化项的优化问题。这类方法结合了梯度下降和近端操作,以有效地在考虑正则化惩罚的同时更新模型参数。
在机器学习中,正则化用于控制模型的复杂性,以防止过度拟合训练数据。近端梯度方法通过在每次迭代中对梯度下降的步骤应用“近端操作”来实现正则化,这通常是指应用软阈值或硬阈值等函数,将每个参数调整到一个接近零的值,以促使模型参数更稀疏或具有低秩性。
近端梯度方法的目标是在梯度下降的基础上最小化损失函数,并通过近端操作来确保参数满足正则化的要求。在处理稀疏性和低秩性等正则化问题时非常有用,因为它们能够有效地在梯度下降和正则化之间取得平衡。
回顾 LoRA
LoRA(Low-Rank Adaptation)是用于参数有效微调预训练语言模型的方法。具体来说,如图 1 所示,预训练的权重被冻结,而可训练的 LoRA 模块使用低秩矩阵来近似每个权重矩阵的变化。这个变化矩阵可以分解为两个低秩矩阵的乘积:其中一个用于下投影(down projection),另一个用于上投影(up projection)。通过这种方式,LoRA 可以在微调的过程中调整模型的参数,而不改变主模型的结构。
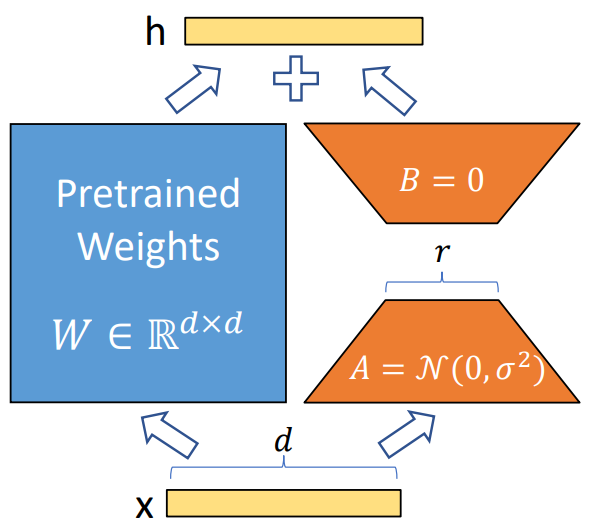
▲图1 LoRA 的结构
核心思想是使用低秩矩阵来表示权重矩阵的变化,从而在微调中保持模型的参数效率。通过这种方式,LoRA 能够在适应特定任务时保留预训练模型的知识,并且相对于直接对整个模型进行微调,它的参数量更小,计算效率更高。
SoRA 方法
SoRA(Sparse Low-Rank Adaptation)基于 LoRA 进行改进,旨在解决 LoRA 在选择最佳秩时的不灵活性。在 LoRA 中,秩是一个离散的值,其选择会直接改变模型的结构,而 SoRA 的目标是通过引入一种自适应秩选择机制,更灵活地调整模型的秩。
核心思想是自适应秩选择机制,如图 2 所示,SoRA 引入了一个可优化的门控单元(gate),通过使用近端梯度方法(proximal gradient method)来调整这个门控单元,从而实现对模型秩的动态调整。这使得在训练过程中可以自适应地选择最佳的秩,而不再受到离散秩选择的限制。SoRA 的方法相对于 LoRA 更为灵活,能够更好地适应不同的骨干模型和下游任务。
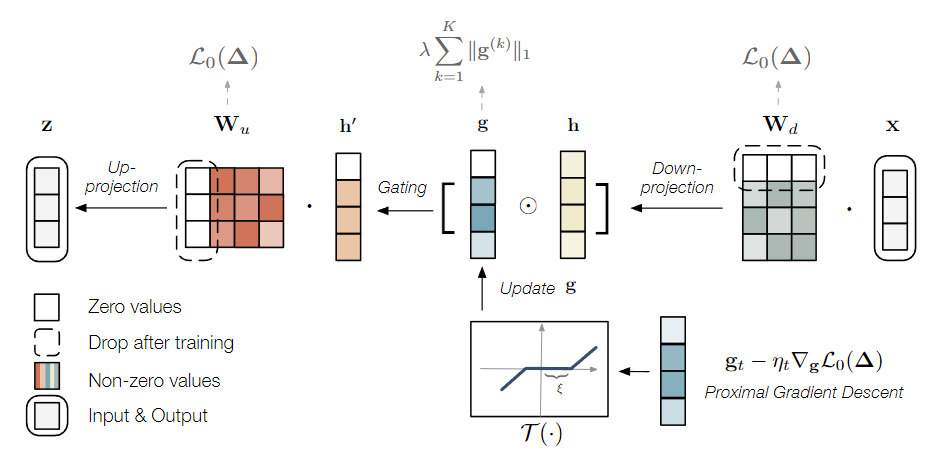
▲图2 稀疏低秩自适应(SoRA)的示意图
构建模块
首先确定一个最大的可接受秩 ,每个 SoRA 模块继承自 LoRA,包括下投影矩阵和上投影矩阵。如何以一种稀疏的方式有效地控制最大秩 呢?受到奇异值分解(SVD)启发,在投影矩阵之间引入一个门控单元 ,SoRA 模块的前向传播表示如下:
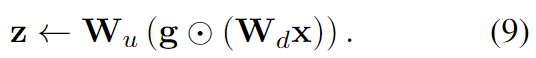
优化
使用随机梯度方法,类似于 LoRA 中对下投影和上投影矩阵的优化。每个门控单元 以不同的方式提高稀疏性,并通过以下公式进行更新:
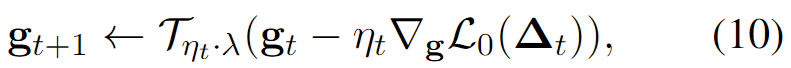
其中, 表示语言模型的原始损失函数, 表示完整的可调参数(包括门), 表示第 次迭代的步长,λ 作为促使稀疏性的正则化强度超参数。此外, 表示下述软阈值(soft-thresholding operation)函数的逐元素广播:
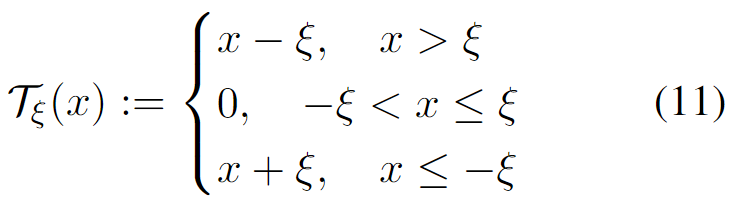
其中 是阈值。
进一步修剪
为减少计算负担,当训练完成后,通过进一步修剪 SoRA 权重来去除被零化的秩,并将模块还原为 LoRA 形式。
调度 以探索记忆和泛化
作者将用于调整模型稀疏性的阈值参数表示为 。在适应过程中,通过动态更改 ,SoRA 可以作为一个有效的工具,用于评估模型 M 和数据 D 下的记忆和泛化方面的行为。
如算法 1 所示,在适应过程中逐步增加 的值,以提升模型的稀疏性。该过程允许评估模型在给定模型 M 和数据集 D 下,达到特定性能水平额外所需的参数量。

▲算法1
SoRA 和 AdaLoRA 的比较
SoRA 和 AdaLoRA(2023 年提出的新方法)都受到了奇异值分解(SVD)的启发,但它们在实现上存在区别:
-
正交正则化的应用: SoRA 不使用 AdaLoRA 中采用的正交正则化技术。相反,SoRA 通过使用稀疏化门 来进行秩选择,避免了正交正则化的应用。这样的设计选择是为了减少计算开销,因为坚持 SVD 的原始要求可能导致额外的计算负担。
-
移动平均的重要性分数与秩选择的关系: AdaLoRA 中使用移动平均的重要性分数作为启发式参数“敏感性”的度量,用于近似损失变化。然而,SoRA 采用了一种基于软阈值操作(公式 10)的明确秩选择方法。相比之下,SoRA 的秩选择方法更为清晰,而且其合理性得到了通过近端梯度迭代的理论证明。
总体而言,SoRA 的更新规则是通过权衡插值复杂性和最小化正则化损失目标来制定的,这使得其在应对参数敏感性、计算效率等方面具有一定优势。
实验
如下表所示,不论是 AdaLoRA 还是 SoRA,都始终优于初始 baseline —— LoRA,这表明了自适应秩是增强模型适应性的有效解决方案。不过尽管使用更少的参数,SoRA 的表现都比 AdaLoRA 更为出色,这证明了近端梯度方法可能是实现自适应秩更有效和重要的途径。并且,SoRA只需要0.91M的参数,是LoRA的70%,就能够达到89.36%的平均表现,明显优于LoRA的88.38%。展现了SoRA强大的自适应稀疏化能力。
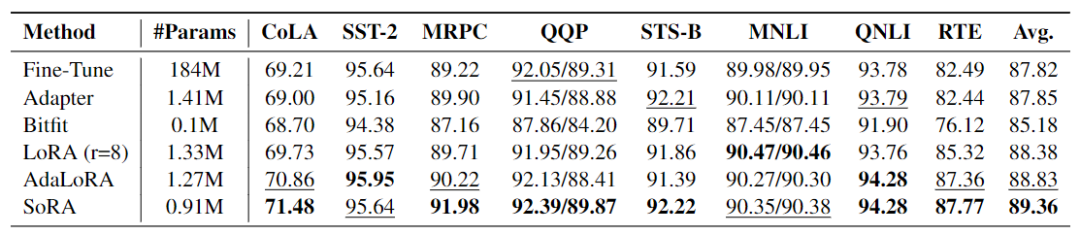
▲表1 SoRA 在 GLUE 基准上的测试结果
为了深入了解自适应秩的有效性,下表的实验结果证实,SoRA 在不同参数预算下都具有优越性。
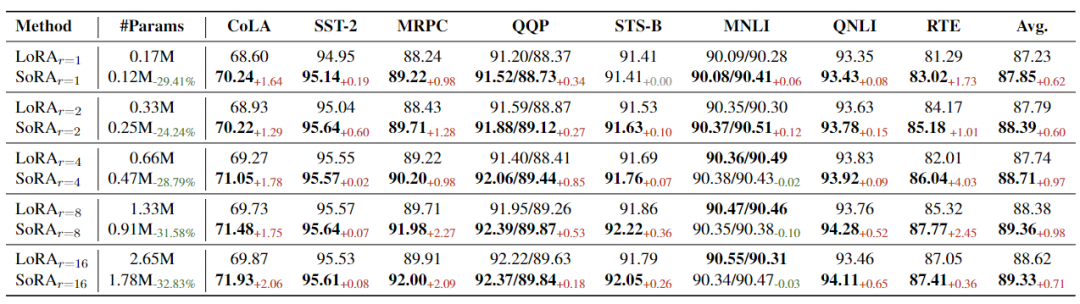
▲表2 在 GLUE 基准上使用不同 初始化的 SoRA 与具有相同秩的 LoRA 进行的比较测试,涉及性能表现和参数量
稀疏调度器
作者通过逐步增加 SoRA 中的稀疏指示器 来在适应过程中动态微调。图 3 展示了在 MRPC、RTE、STS-B、CoLA、QNLI 和 SST-2 数据集上的 RoBERTa-large 的记忆和泛化曲线。其中记忆通过在训练集上的性能衡量,而泛化是通过在验证集上的性能来衡量的。
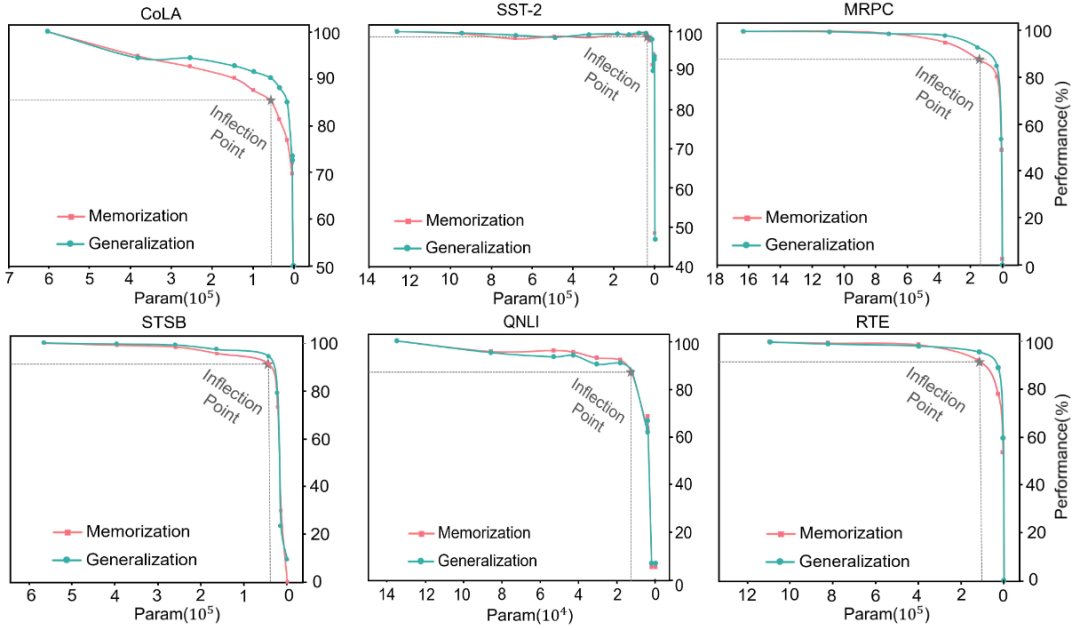
▲图3 在不同数据集上的记忆和泛化曲线
-
几乎在所有数据集上都存在强大的“压缩性能”。在 SST-2 上,即使限制了 4 万多个非零参数,模型仍能保持超过 99% 的性能。
-
存在一些关键参数支撑着性能。随着稀疏化过程的进行,模型在不同的数据上遇到了不同的“拐点”,而后性能显著下降。
-
模型在不同数据集上的适应难度存在不同程度的差异。某些数据集会更早更显著地导致性能下降。
-
在稀疏化过程中的记忆和泛化趋势是一致的。
-
中间和深层参数保持其密集的趋势,而浅层参数显示出更高的稀疏性倾向。
秩分析
当单一模型适应不同的下游数据集时,会面临不同程度的挑战。同时,并非模型中的所有参数都具有相等的重要性,有些参数对性能的贡献更为关键。
通过图 4 的可视化反映了存在不同程度的挑战。此外,确定模型性能和参数的最佳平衡时,需要具体考虑特定的情境和问题,不能一成不变。
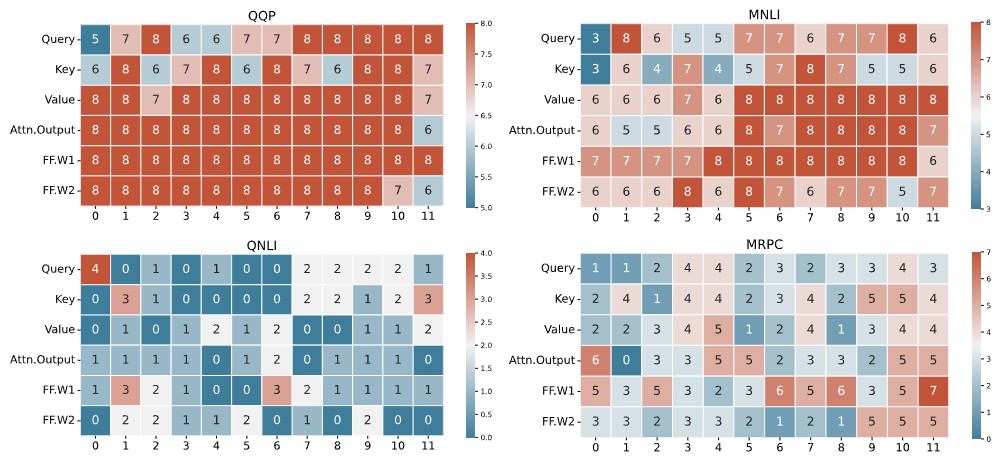
▲图4 在四个数据集(即QQP、MNLI、QNLI 和 MRPC)上使用 SoRA 进行训练后的最终秩
效率分析
如表 4 所示,**SoRA 相对于 AdaLoRA 的训练时间减少约 30%**,在训练效率上有明显的优势。相反,尽管在其他数据集上 SoRA 一直领先于 AdaLoRA,但优势并不那么显著。这种差异可能是由于AdaLoRA和SoRA在不同任务下具有不同的秩分布所致。这种分布对于AdaLoRA中正则化计算的影响可能导致了这种效果上的变化。
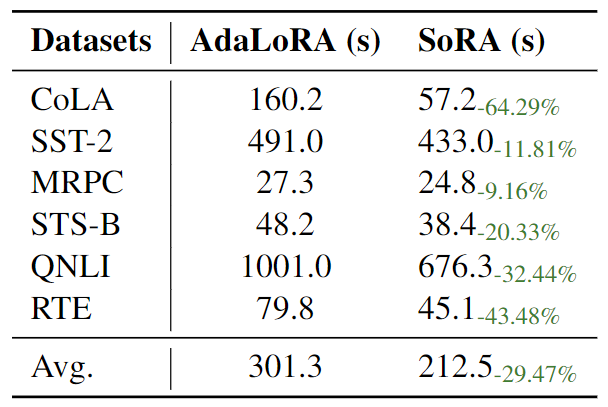
▲表4 相同 batch size 下,每个 epoch 的平均训练时间
总结
在本文中,作者深入研究了稀疏低秩适应(SoRA)方法,为大型预训练语言模型提供了高效的参数微调策略。通过充分利用内在稀疏性假设,引入可优化的门控单元,并采用近端梯度方法微调稀疏性,SoRA展现了出色的性能,为模型提供了一种灵活的替代秩,从而扩展了优化空间并提升了参数效率。
然而,还要认识到研究中存在一些限制:
-
实验主要聚焦在传统自然语言处理任务上,对于其他领域的适应性仍需进一步研究。例如,参数高效的方法可能在跨模态或指导微调的场景中具有广泛应用。
-
虽然稀疏调度器提供了关于语言模型适应过程的思路,但深入解释该过程及更有效地评估适应难度仍然是一个具有挑战性事情。
最后,我们期待未来能有更多研究可以持续推动人工智能领域的发展。通过合理利用计算资源,借助更小规模的参数微调,为大模型“减负”,我们能不断提升模型的性能,拓展模型适应性的边界,更好地应对多样化的任务和数据场景。

相关文章:
清华提出 SoRA,参数量只有 LoRA 的 70%,表现更好!
现在有很多关于大型语言模型(LLM)的研究,都围绕着如何高效微调展开。微调是利用模型在大规模通用数据上学到的知识,通过有针对性的小规模下游任务数据,使模型更好地适应具体任务的训练方法。 在先前的工作中ÿ…...

FO-like Transformation
参考文献: [RS91] Rackoff C, Simon D R. Non-interactive zero-knowledge proof of knowledge and chosen ciphertext attack[C]//Annual international cryptology conference. Berlin, Heidelberg: Springer Berlin Heidelberg, 1991: 433-444.[BR93] Bellare M…...
通过ros系统中websocket中发送sensor_msgs::Image数据给web端显示(三)
通过ros系统中websocket中发送sensor_msgs::Image数据给web端显示(三) 不使用base64编码方式传递 #include <ros/ros.h> #include <signal.h> #include <sensor_msgs/Image.h> #include <message_filters/subscriber.h> #include <message_filter…...
Navicat 技术指引 | 适用于 GaussDB 的模型功能
Navicat Premium(16.2.8 Windows版或以上) 已支持对 GaussDB 主备版的管理和开发功能。它不仅具备轻松、便捷的可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构同步、协同合作、数据迁移等),这…...
Ubuntu18.4中安装wkhtmltopdf + Odoo16配置【二】
deepin Linux 安装wkhtmltopdf 1、先从官网的链接里下载linux对应的包 wkhtmltopdf/wkhtmltopdf 下载需要的版本,推荐版本,新测有效: wkhtmltox-0.12.4_linux-generic-amd64.tar.xz 2、解压下载的文件 解压后会有一个wkhtmltox文件夹 3…...

RC-MVSNet:无监督的多视角立体视觉与神经渲染--论文笔记(2022年)
RC-MVSNet:无监督的多视角立体视觉与神经渲染--论文笔记(2022年) 摘要1 引言2 相关工作2.1 基于监督的MVS2.2 无监督和自监督MVS2.3 多视图神经渲染 3 实现方法3.1 无监督的MVS网络 Chang, D. et al. (2022). RC-MVSNet: Unsupervised Multi-…...

gradle构建项目速度优化及排查方式
文章目录 一、前言二、Android项目优化1、相关配置2、构建速度分析 三、Gradle项目通用优化1、分析构建耗时2、使用配置进行优化3、优化依赖解析a. 避免不必要和未使用的依赖项b. 优化存储库顺序 c. 最小化动态和快照版本d. 通过构建扫描查找动态和变化的版本e. 通过构建扫描可…...
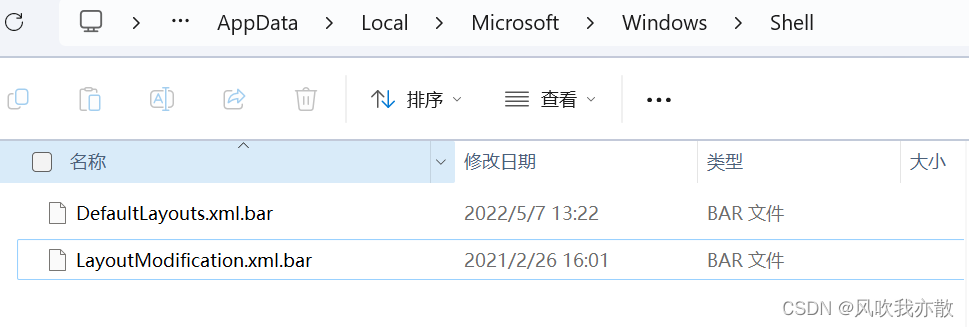
MSI Center,XBox从任务栏取消固定
1,设置查看方式中隐藏项目可见 2,进入文件夹:C:\Users\Default\AppData\Local\Microsoft\Windows\Shell 找到下面这两个文件夹: 3,修改文件名或者删除这两个文件即可...
1、postman的安装及使用
一、安装、登录 1.安装 下载地址 2.注册登录(保存云服务进度) 二、界面介绍 三、执行接口测试页面 请求页签: 1、params:当是get请求时,通过params传参 2、authorization:鉴权 3、headers࿱…...

VUE简易计划清单
目录 效果预览图 完整代码 效果预览图 完整代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>…...

c++日志单例实现
为了使项目的所有日志都打印到同一个日志中,必须使得所有类使用同一个日志,因此将日志类实现为单例。 .h文件 #pragma once#include<fstream>class LogHablee { private:LogHablee(std::string& dbg_dir);LogHablee(const LogHablee&) …...
,返回其最大和 某知名企业笔试题)
C/C++实现:找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和 某知名企业笔试题
目录 题目描述: 示例 1: 示例 2: 示例 3: 提示: 思路:...

Qt实现绘制自定义形状
先创建一个继承自QWidget的控件: class MyPainterWidget:public QWidget 重写各种鼠标方法: protected:void paintEvent(QPaintEvent *) override;void mousePressEvent(QMouseEvent *e) override; //按下void mouseMoveEvent(QMouseEvent *e) …...
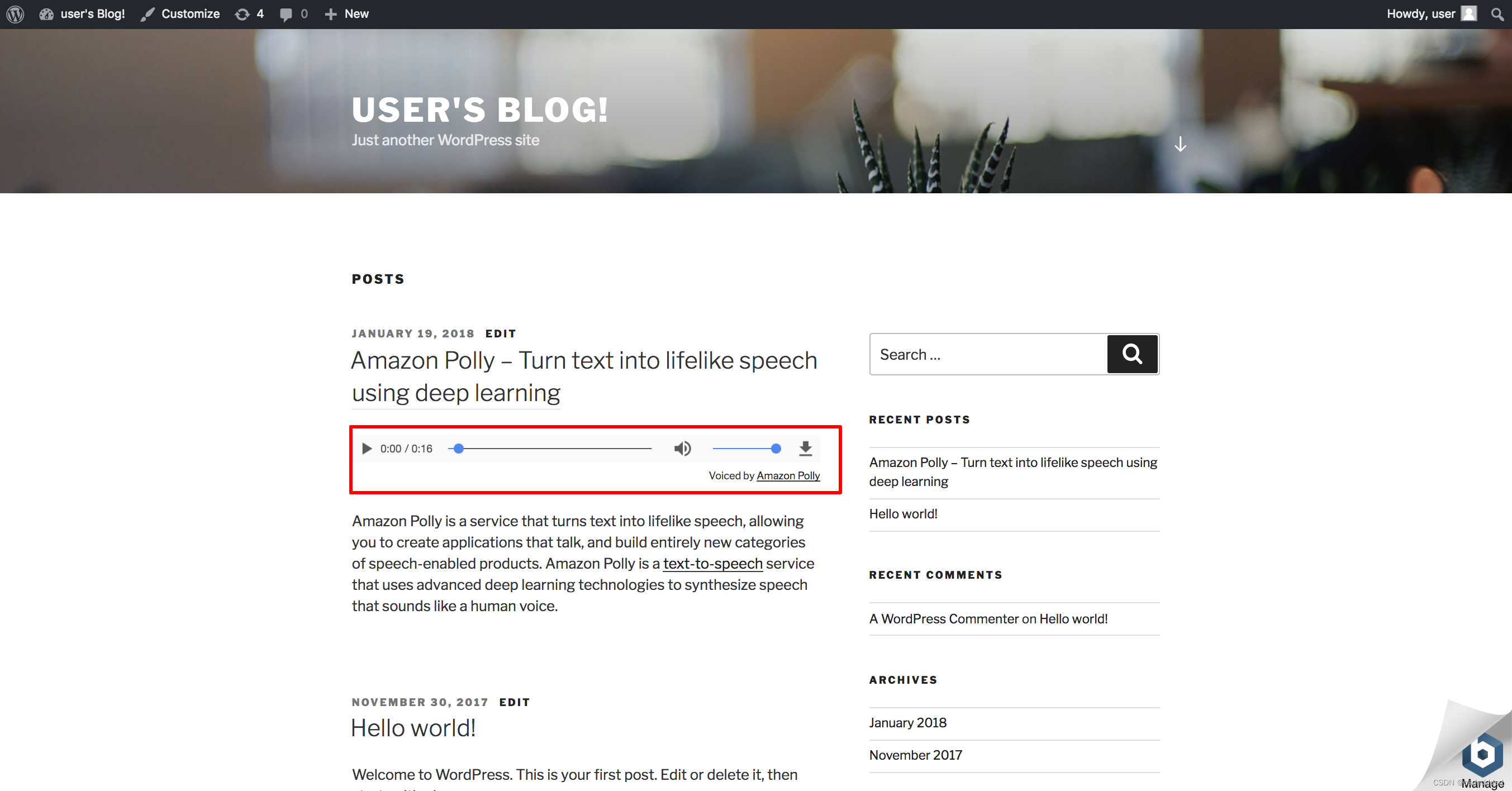
WordPress安装AWS插件实现文本转语音功能
适用于 WordPress 的 AWS 插件示例演示了内容创建者如何轻松地为所有书面内容添加文本转语音功能。随着语音搜索的不断增加,以音频格式提供更多网站内容变得至关重要。通过添加语音功能,网站访客可以通过在线音频播放器和播客应用程序等新渠道使用您的内…...

87-96-多维动态规划、技巧
LeetCode 热题 100 文章目录 LeetCode 热题 100多维动态规划87. 中等-不同路径88. 中等-最小路径和89. 中等-最长回文子串90. 中等-最长公共子序列91. 困难-编辑距离 技巧92. 简单-只出现一次的数字93. 简单-多数元素94. 中等-颜色分类95. 中等-下一个排列96. 中等-寻找重复数 …...

NX二次开发UF_CURVE_ask_wrap_curve_parents 函数介绍
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan UF_CURVE_ask_wrap_curve_parents Defined in: uf_curve.h int UF_CURVE_ask_wrap_curve_parents(tag_t curve_tag, tag_t * defining_face, tag_t * defining_plane, tag_t * defin…...

使用 HTML、CSS 和 JavaScript 创建图像滑块
使用 HTML、CSS 和 JavaScript 创建轮播图 在本文中,我们将讨论如何使用 HTML、CSS 和 JavaScript 构建轮播图。我们将演示两种不同的创建滑块的方法,一种是基于opacity的滑块,另一种是基于transform的。 创建 HTML 我们首先从 HTML 代码开…...
ubuntu环境删除qtcreator方法
文章目录 方法1方法2方法3参考不同的安装方法,对应不同的删除方法 方法1 apt-get或者dpkg 方法2 QtCreatorUninstaller 方法3 MaintenanceTool...

软件测试基础知识
软件测试基本概念 1、软件程序文档,软件测试程序测试文档测试。 “程序”是指能够实现某种功能的指令的集合,“文档”是指软件在开发、使用和维护过程中产生的图文集合。; 2、软件的分类 按功能分:系统软件、应用软件 按技术架构分…...
 方法生成当前时间的ISO格式字符串,解决UTC时区差问题)
使用 .toISOString() 方法生成当前时间的ISO格式字符串,解决UTC时区差问题
方法分析: 日常开发中,有时我们需要向后端传递的时间值可能并非一个时间对象,而是字符串格式。 例 1:[2023-08-16T08:07:25.577Z] 但是我们通过 new Date() 之后直接使用 .toString() 方法得到的却并非这种格式。 例 2࿱…...

Win11 + WSL2 + VS Code:打造高效跨平台开发环境全攻略
1. 为什么选择Win11 WSL2 VS Code组合? 如果你是一名开发者,同时需要在Windows和Linux环境下工作,那么Win11 WSL2 VS Code的组合绝对是你的最佳选择。这个组合不仅能让你在Windows系统下享受到Linux的开发环境,还能通过VS Cod…...

雅特力AT32 I2C实战:从零构建EEPROM存储系统
1. 硬件连接与基础配置 第一次玩AT32的I2C外设时,我对着开发板上的SCL和SDA引脚发呆了半天。后来发现,硬件连接其实就三个要点:上拉电阻、开漏输出、引脚复用。以AT32F403A开发板为例,I2C1的SCL(PB6)和SDA(PB7)需要配置为复用开漏…...

CLAP Zero-Shot Audio Classification Dashboard部署教程:Kubernetes集群中水平扩缩容配置要点
CLAP Zero-Shot Audio Classification Dashboard部署教程:Kubernetes集群中水平扩缩容配置要点 1. 项目概述与核心价值 CLAP Zero-Shot Audio Classification Dashboard是一个基于LAION CLAP模型的交互式音频分类应用。这个工具让用户能够上传任意音频文件&#x…...

暗黑3技能自动化:从手动挣扎到智能操控的技术跃迁
暗黑3技能自动化:从手动挣扎到智能操控的技术跃迁 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 在暗黑破坏神3的高层秘境中,…...

LiuJuan20260223Zimage与MySQL数据库交互:安装配置与数据管理
LiuJuan20260223Zimage与MySQL数据库交互:安装配置与数据管理 为AI模型数据提供稳定可靠的数据存储方案 1. 前言:为什么需要数据库支持 在实际的AI应用开发中,我们经常遇到一个痛点:模型生成的数据如何持久化保存?比如…...

granite-4.0-h-350m实战教程:Ollama本地大模型部署+韩语技术文档理解+代码补全
granite-4.0-h-350m实战教程:Ollama本地大模型部署韩语技术文档理解代码补全 想在自己电脑上跑一个能看懂韩语技术文档、还能帮你写代码的AI助手吗?今天我们就来聊聊怎么用Ollama部署一个轻量但功能强大的模型——granite-4.0-h-350m。 这个模型只有3.5亿…...

QMCDecode全解析:3步解锁QQ音乐加密音频的终极方案
QMCDecode全解析:3步解锁QQ音乐加密音频的终极方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换…...

造相Z-Image小白友好教程:无需代码基础,网页界面直接操作生成
造相Z-Image小白友好教程:无需代码基础,网页界面直接操作生成 1. 快速了解造相Z-Image 造相Z-Image是阿里通义万相团队开源的一款强大的文生图扩散模型,拥有20亿级参数规模。这个模型最大的特点就是能够生成768768及以上分辨率的高清图像&a…...

MAA明日方舟助手:3个步骤告别重复性游戏操作,实现全自动智能管理
MAA明日方舟助手:3个步骤告别重复性游戏操作,实现全自动智能管理 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. …...

cv_unet_image-colorization色彩心理学应用:不同历史时期配色风格AI学习案例
cv_unet_image-colorization色彩心理学应用:不同历史时期配色风格AI学习案例 1. 项目概述 今天要介绍的是一个特别有意思的工具——基于AI的黑白照片上色神器。这个工具能让那些尘封已久的老照片重新焕发光彩,就像给黑白电影加上颜色一样神奇。 这个工…...