Elasticsearch基础优化
分片策略
分片和副本得设计为ES提供支付分布式和故障转移得特性,但不意味着分片和副本是可以无限分配,
而且索引得分片完成分配后由于索引得路由机制,不能重新修改分片数(副本数可以动态修改)
- 一个分片得底层为一个lucene索引,会消耗一定文件句柄、内存以及CPU运转,当分片数越多资源消耗就会更多
- 每个搜索请求都需要命中索引中得每个分片,如果分片处于不同节点还好,但如果处于相同节点上竞争使用相同资源就导致性能降低
- 控制每个分片占用磁盘容量不超过ES得最大JVM堆空间设置(一般不超过32G),因此如果索引得总容量在500G左右,那么分片大小在16个左右即可
- 考虑node数量,一般一个节点有时就是一台物理机,如果分片数量过多,大大超过节点数,可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持1个以上得副本,同样有可能会导致数据丢失,一般设置分片数不超过节点数得3倍
- 主分片,副本和节点最大数之间数量 节点数<=主分片数*(副本数+1)
推迟分片分配
对于节点瞬时中断得问题,默认情况,集群会等待一分钟来查看节点是否重新加入,如果节点再次期间重新加入,重新加入得节点会保持其现有分片得数据,不会触发新的分片分配,这样就可以减少ES在自动在平衡可用分片所带来的极大开销
通过修改参数delayed_timeout,延长在均衡时间,可全局设置也可以在索引级别修改
PUT /_all/_settings
{"settings" : {"index.unassigned.node_left.delayed_timeout" : "5m"}
}
路由选择
当我们查询文档时,ES是如何知道一个文档应该存放在那个分片中,路由计算
#shard=hash(routing) % number_of_primary_shards
routing默认值是文档 id,也可以采用自定义值,比如用户id
- 不带routing查询
请求到达协调节点上,协调节点查询分发到所有分片上,协调节点搜集每个分片得查询结果,再将查询结果排序聚合,返回结果 - 带routing查询
查询可直接根据routing信息定位到某个分片查询,不需要查询所有分片,经过协调节点排序,比如自定义用户查询,如果routing设置为userid,就可以直接查询出数据,效率提升
写入速度
ES默认配置,综合数据可靠性、写入速度、搜索实时等因素,实际使用我们需要根据项目要求,进行偏向性优化。
针对搜索性能不高,但是写入有要求场景,需要尽可能得选择恰当写优化策略
- 加大Translog Flush,降低磁盘 Iops、Writeblock
- 增加Index Refresh 刷新间隔,减少Segment Merge次数(间隔短意味频繁将内存数据放入文件系统缓存中,文件系统缓存相应写入磁盘中,当磁盘文件数据多就会合并随之影响性能)
- 调整Bulk线程池和队列(批量处理)
- 优化节点间得任务分布
- 优化Lucene层索引建立,降低CPU和IO
优化存储
ES是一种密集使用磁盘得应用,在段合并时候会频繁操作磁盘,所以对磁盘要求较高,当磁盘速度提升,集群整体性能大幅提高(固态硬盘)
减少Refresh次数
#Lucene是一个开源的全文索引与信息检索(IR)库,采用Java实现
Lucene在新增数据时,采用延迟写入策略,默认情况下索引得refresh_interval为1秒
Lucene将代写入得数据先写到内存中,超过默认1秒会触发一次refresh,然后refresh会把内存得数据刷新到操作系统得文件缓存系统中。
- 如果对搜索得实效性不高,可以将refresh周期延长调整30秒等
- 有效减少刷次次数,意味着需要消耗更多得Heap内存
加大Flush设置
#Translog是Elasticsearch的事务日志文件,它记录了所有对索引分片的事务操作(add/update/delete),每个分片对应一个Translog文件。
#Translog是用来恢复数据的。在Elasticsearch中,写入的索引并没有实时落盘到索引文件,而是先双写到内存和Translog文件。如果掉电,Elasticsearch重启后还可以把数据从日志文件中读回来。在flush的时候,Translog文件会被清空
Flush主要目的是把文件缓存系统中得段持久化到磁盘,当Translog得数据量达到512MB或者30分钟,会触发一次Flush
减少副本数量
ES为了保证集群得可用性,提供了Replicas支持,然后每个副本也会执行分析,索引及可能合并得过程,所以Replicas得数量严重影响写索引得效率。
当写索引时,需要把写入数据都同步到副本节点,副本节点越多,写索引得效率就越慢,如果有大批量进行写入操作,可以先禁止Replca副本复制,设置index.number_of_replicas:0关闭副本,再写入完成后,Replca修改回正常状态,提升效率
内存设置
ES在默认安装后设置得内存是1GB,对于任何一个业务来说,这个设置都太小了。config目录文件包含一个jvm.option文件,添加如下命令设置ES堆大小,Xms表示堆初始大小,Xmx表示可分配得最大内存。
一般来说这两数值配置保持相同,目的为了能够在java垃圾回收机制清理完堆分区后不需要重新分割计算堆区得大小而浪费资源,可以减轻伸缩堆大小带来得压力。
- 不要超过物理内存得50%,Lucene设计目的是把底层得OS里得数据缓存到内存中。
Lucene得段分别储存到单个文件中的,这些文件都是不会变化得,所以很利于缓存,同时操作系统也会吧这些文件缓存起来,以便更快得访问
如果我们设置堆内存过大,Lucene可用得内存将减少,会影响降低Lucene得全文本查询性能 - 堆内存大小最好不超过32GB,在java中,所有的对象都分配在堆上,然后有一个Klass pointer指针向它得类元数据
假设有个机器有128GB内存,你可以创建2个节点,每节点内存分配不超过32GB,也就是不超过64GB内存给ES堆内存,剩下超过64GB得内存给Lucene
重要配置
| 参数 | 参数值 | 说明 |
|---|---|---|
| cluster.name | ES | 配置ES集群名称,默认值是ES,ES会自动发现在同一网段下集群名称相同得节点 |
| node.name | node1 | 集群中节点名,在同一集群中不能重复,节点名称一单设置不能在改变 |
| node.master | true | 指定该节点是否有资格被选举为Master节点,默认为True,具体能否成为Master节点,需要通过选举产生 |
| node.data | true | 执行该节点是否存储索引数据,默认为True,数据的增、删、改、查都是在Data节点完成 |
| index.number_of_shards | 1 | 设置索引分片个数,默认是1。可以在创建索引时设置该值,具体设置多少根据数据量大小来定,如果数据量不大,保持默认1时效率最高 |
| index.number_of_replicas | 1 | 设置默认索引副本个数,默认为1,副本越多,集群可用性越好,但是写索引时需要同步得数据随之越多 |
| transport.tcp.compress | false | 设置在节点间传输时是否压缩,默认为False,不压缩 |
| discovery.zen.minimum_master_nodes | 1 | 设置在选举Master节点时需要参与最少候选主节点数,默认1,如果使用默认值,则当网络不稳定时有可能出现脑裂。合理数值为(master_eligible_nodes/2)+1,其中master_eligible_nodes表示集群中候选主节点数 |
| descovery.zen.ping.timeout | 3s | 设置在集群中自动发现其他节点时ping连接超时时间,默认为3秒,在较差得网络环境需要设置大一点,防止因误判该节点存活状态而导致分片转移 |
相关文章:

Elasticsearch基础优化
分片策略 分片和副本得设计为ES提供支付分布式和故障转移得特性,但不意味着分片和副本是可以无限分配, 而且索引得分片完成分配后由于索引得路由机制,不能重新修改分片数(副本数可以动态修改) 一个分片得底层为一个l…...
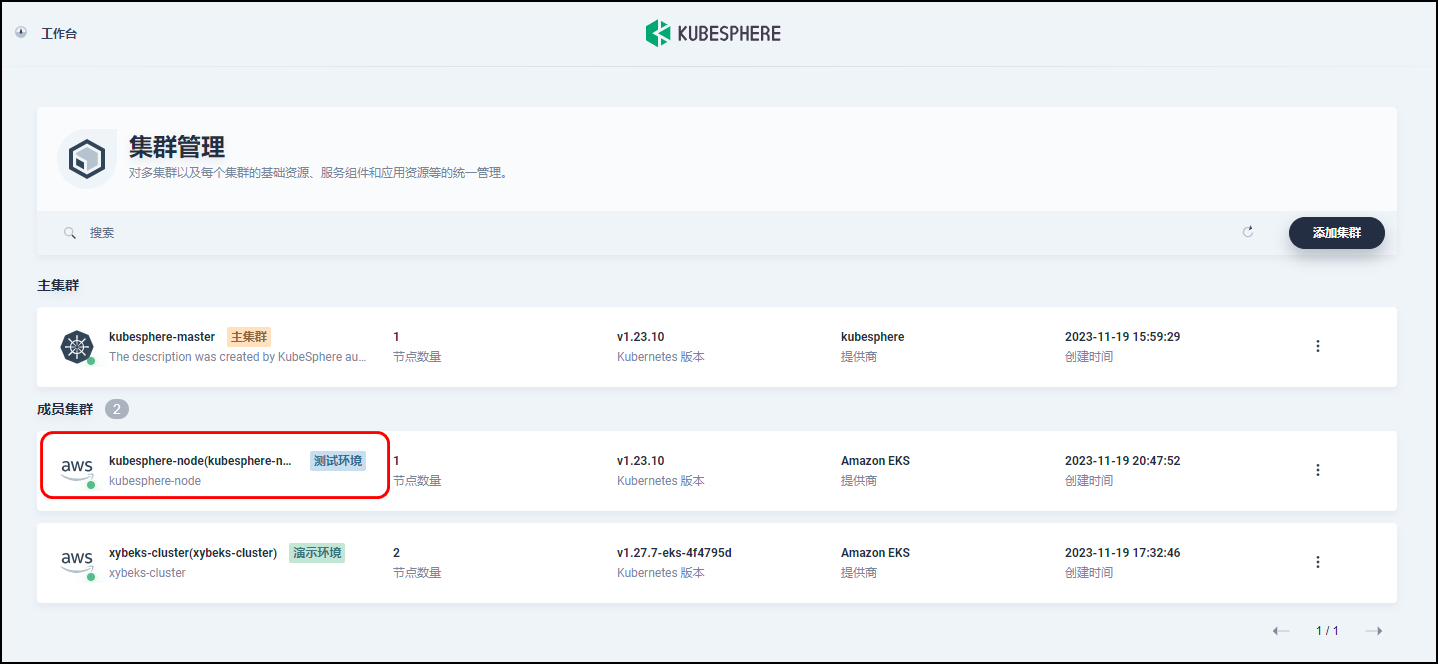
【Amazon】通过直接连接的方式导入 KubeSphere集群至KubeSphere主容器平台
文章目录 一、设置主集群方式一:使用 Web 控制台方式二:使用 Kubectl命令 二、在主集群中设置代理服务地址方式一:使用 Web 控制台方式二:使用 Kubectl命令 三、登录控制台验证四、准备成员集群方式一:使用 Web 控制台…...
三数之和问题
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1&…...

【JavaEE】多线程 (2) --线程安全
目录 1. 观察线程不安全 2. 线程安全的概念 3. 线程不安全的原因 4. 解决之前的线程不安全问题 5. synchronized 关键字 - 监视器锁 monitor lock 5.1 synchronized 的特性 5.2 synchronized 使⽤⽰例 1. 观察线程不安全 package thread; public class ThreadDemo19 {p…...

关于点胶机那些事
总结一下点胶机技术要点: 1:不论多复杂的点胶机,简单点,可以简化为:1:运控 2:点胶,3:检测 运控的目的就是负责把针头移到面板对应的胶路上,点胶即就是排胶&…...
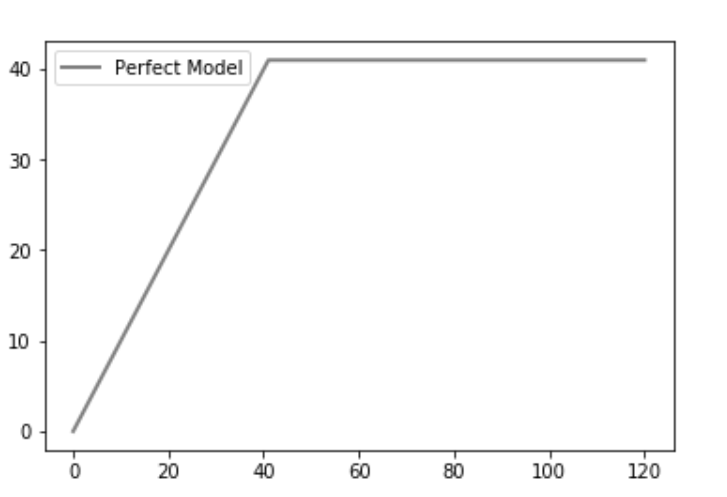
Python | CAP - 累积精度曲线分析案例
CAP通常被称为“累积精度曲线”,用于分类模型的性能评估。它有助于我们理解和总结分类模型的鲁棒性。为了直观地显示这一点,我们在图中绘制了三条不同的曲线: 一个随机的曲线(random)通过使用随机森林分类器获得的曲线…...

ubuntu22.04安装swagboot遇到的问题
一、基本情况 系统:u 22.04 python: 3.10 二、问题描述 swagboot官方提供的安装路径言简意赅:python3 -m pip install --user snagboot 当然安装python3和pip是基本常识,这里就不再赘述。 可是在安装的时候出现如下提示说 Failed buildin…...

python每日一题——8无重复字符的最长子串
题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示例 2: 输入: s “bbbbb” 输出: 1 解释: 因为无重复字符的最长子串…...
【数据中台】开源项目(2)-Dbus数据总线
1 背景 企业中大量业务数据保存在各个业务系统数据库中,过去通常的同步数据的方法有很多种,比如: 各个数据使用方在业务低峰期各种抽取所需数据(缺点是存在重复抽取而且数据不一致) 由统一的数仓平台通过sqoop到各个…...

职场快速赢得信任
俗话说的好,有人的地方就有江湖。 国内不管是外企、私企、国企,职场环境都是变换莫测。 这里主要分享下怎么在职场中快速赢取信任。 1、找到让自己全面发展的方法 要知道,职场中话题是与他人交流的纽带,为了找到共同的话题&am…...

【SpringBoot3+Vue3】五【完】【实战篇】-前端(配合后端)
目录 一、环境准备 1、创建Vue工程 2、安装依赖 2.1 安装项目所需要的vue依赖 2.2 安装element-plus依赖 2.2.1 安装 2.2.2 项目导入element-plus 2.3 安装axios依赖 2.4 安装sass依赖 3、目录调整 3.1 删除部分默认目录下文件 3.1.1 src/components下自动生成的…...
[LaTex]arXiv投稿攻略——jpg/png转pdf
一、将图片复制进ppt,右键单击图片选择设置图片格式,获取图片高度和宽度 二、选择“设计-幻灯片大小-自定义幻灯片大小” 三、设置幻灯片大小为图片大小 四、 选择“最大化” 五、 检查幻灯片大小是否与图像大小一致 六、导出为PDF...

使用Pytorch从零开始构建GRU
门控循环单元 (GRU) 是 LSTM 的更新版本。让我们揭开这个网络的面纱并探索这两个兄弟姐妹之间的差异。 您听说过 GRU 吗?门控循环单元(GRU)是更流行的长短期记忆(LSTM)网络的弟弟,也是循环神经网络&#x…...

【尚跑】2023宝鸡马拉松安全完赛,顺利PB达成
1、赛事背景 千年宝地,一马当先!10月15日7时30分,吉利银河2023宝鸡马拉松在宝鸡市行政中心广场鸣枪开跑。 不可忽视的是,这次赛事的卓越之处不仅在于规模和参与人数,还在于其精心的策划和细致入微的组织。为了确保每位…...

Mac nginx安装,通过源码安装教程
第一部分 安装参考网址: https://blog.csdn.net/a1004084857/article/details/128512612; 以上步骤执行完,进入找到sbin目录,查看下面是不是有nginx可执行文件,如果有在当前sbin下执行./nginx,就会发现NGINX已启动 第…...

TypeScript中的枚举是什么?
在TypeScript中,枚举(Enum)是一种用于定义一组有命名的常量值的数据类型。它们可以提供更具可读性和可维护性的代码。 枚举的作用是为一组相关的值提供一个易于理解和使用的命名空间。它们可以用于代表一系列可能的选项、状态或标志…...

进程并发-信号量经典例题-面包师问题
1 题目描述 面包师有很多面包和蛋糕,由N个销售人员销售。每个顾客进店后先取一个号,并且等着叫号。当一个销售人员空闲下来,就叫下一个号。试用信号量的P、V操作设计该问题的同步算法,给出所用共享变量(如果需要&…...
)
c语言练习12周(11~15)
编写double fun(int a[],int n)函数,计算返回评分数组a中,n个评委打分,去掉一个最高分去掉一个最低分之后的平均分 题干编写double fun(int a[],int n)函数,计算返回评分数组a中,n个评委打分,去掉一…...

Java 实现视频转音频功能
在实际开发中,我们经常需要处理各种多媒体文件。本文将介绍如何使用 Java 语言实现将视频文件转换为音频文件的功能。我们将使用 FFmpeg 工具来进行视频转换操作,并通过 Java 的 ProcessBuilder 实现调用系统命令执行 FFmpeg 的功能。 准备工作 首先,我们需要确保系统中已安…...
可以在Playgrounds或Xcode Command Line Tool开始学习Swift
一、用Playgrounds 1. App Store搜索并安装Swift Playgrounds 2. 打开Playgrounds,点击 文件-新建图书。然后就可以编程了,如下: 二、用Xcode 1. 安装Xcode 2. 打开Xcode,选择Creat New Project 3. 选择macOS 4. 选择Comman…...

Java的java.lang.StackWalker工具处理
Java的StackWalker工具:深入解析堆栈跟踪新方式 在Java开发中,堆栈跟踪是调试和问题排查的核心工具之一。传统的Throwable.getStackTrace()方法虽然简单,但存在性能开销大、灵活性不足的问题。Java 9引入的java.lang.StackWalker工具通过惰性…...

Beyond Compare 5 开源密钥生成工具:从评估模式到专业授权的完整解决方案
Beyond Compare 5 开源密钥生成工具:从评估模式到专业授权的完整解决方案 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当你在使用Beyond Compare 5进行文件对比或同步工作时&…...

银行数据中心基础设施建设与运维管理【1.2】
2. 2 数据中心的容量 如何规划数据中心容量一直是数据中心管理者和从业者的一个重大问题。 当一个数据中心建设意向提出之后, 数据中心的建设容量到底该多大? 到底该按照哪些因素去规划数据中心的容量? 数据中心到底该按照那种方式去建设? 如何使将要建设的数据中心能够面…...

使用 Python 设置 Excel 表格的行高与列宽
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...
Spring事务与事务传播机制教程|从入门到实战,一篇吃透@Transactional
—JavaEE专栏— Spring事务与事务传播机制教程|从入门到实战,一篇吃透Transactional 大家好,我是一名后端开发,今天带来一篇Spring事务传播机制的硬核实战博客,包含原理代码图文面试高频完整实战案例,看完…...

打字不如说话,说话不如截图——AI 代码助手的多模态输入实践捕
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

线上全是9块9,实体店怎么转?
摘要:本文以浙江金华浦江县一家小微服装店的真实经营困境为背景,探讨在电商低价内卷环境下,如何通过技术手段实现线上线下(O2O)业务的深度融合。文章重点分析了统一库存管理、多渠道订单聚合、会员数据打通等核心痛点&…...

Calico IPIP 使用指南妹
本课概览 Microsoft Agent Framework (MAF) 提供了一套强大的 Workflow(工作流) 框架,用于编排和协调多个智能体(Agent)或处理组件的执行流程。 本课将以通俗易懂的方式,帮助你理解 MAF Workflow 的核心概念…...

终极glTF 2.0查看器:用Rust构建的高性能3D模型浏览器
终极glTF 2.0查看器:用Rust构建的高性能3D模型浏览器 【免费下载链接】gltf-viewer glTF 2.0 Viewer written in Rust 项目地址: https://gitcode.com/gh_mirrors/gl/gltf-viewer 想要在本地快速预览和查看glTF 3D模型吗?gltf-viewer正是你需要的…...

Python装饰器高级用法详解
Python装饰器高级用法详解 Python装饰器是函数式编程的精华之一,它能在不修改原函数代码的情况下增强功能。从简单的日志记录到复杂的权限校验,装饰器的应用场景极为广泛。除了基础的函数装饰器,Python还支持更高级的用法,如类装…...