多模态——使用stable-video-diffusion将图片生成视频
多模态——使用stable-video-diffusion将图片生成视频
- 0. 内容简介
- 1. 运行环境
- 2. 模型下载
- 3. 代码梳理
- 3.1 修改yaml文件中的svd路径
- 3.2 修改DeepFloyDataFiltering的vit路径
- 3.3 修改open_clip的clip路径
- 3.4 代码总体结构
- 4. 资源消耗
- 5. 效果预览
0. 内容简介
近期,stabilityAI发布了一个新的项目,是将图片作为基础,生成一个相关的小视频,其实也算是其之前研究内容的扩展。早在stable-diffusion的模型开源出来的时候,除了由prompt生成图片之外,也可以生成连续帧的短视频。
本文主要是体验一下stable-video-diffusion的使用,以及对其使用方法进行简单的介绍。具体原理相关内容并不是我的主要研究方法,也就不在此展开介绍了。
下面的这个小火箭就是项目的示例图片,生成视频之后,小火箭可以发射升空。

项目地址:
HF:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
git:https://github.com/Stability-AI/generative-models
论文地址:
https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
观前提醒:此项目消耗显存较多,最好是48G以上,请根据实际情况判断是否继续尝试。
1. 运行环境
这里提供一下我的运行环境以供大家参考。
系统:CentOS 7
Python:3.10
驱动:470.63.01
CUDA:11.4
cudnn:8.5.0
torch:2.0.1+cu117
torchvision:0.15.2+cu117
其他模块参考https://github.com/Stability-AI/generative-models/blob/main/requirements/pt2.txt.
2. 模型下载
由于国内目前不能正常访问HF了,所以代码的一键运行可能会遇到网络连接的问题,于是可以考虑将模型先下载到本地,然后直接从本地读取模型。需要下载的模型包括:
- laion/CLIP-ViT-H-14-laion2B-s32B-b79K
- ViT-L/14
- stable-video-diffusion-img2vid-xt
3. 代码梳理
代码主要参考官方git上的样例脚本:https://github.com/Stability-AI/generative-models/blob/main/scripts/sampling/simple_video_sample.py
3.1 修改yaml文件中的svd路径
模型的创建用到了yaml配置文件,所以需要把git中的svd_xt.yaml等yaml文件下载下来,并且将其中的模型地址ckpt_path,修改为第2部分中,从HF下载的stable-video-diffusion-img2vid-xt/svd_xt.safetensors的地址。
svd_xt_image_decoder.yaml同理。
3.2 修改DeepFloyDataFiltering的vit路径
注意运行脚本的import部分:
import math
import os
from glob import glob
from pathlib import Path
from typing import Optionalimport cv2
import numpy as np
import torch
from einops import rearrange, repeat
from fire import Fire
from omegaconf import OmegaConf
from PIL import Image
from torchvision.transforms import ToTensor# from scripts.util.detection.nsfw_and_watermark_dectection import \
# DeepFloydDataFiltering
# from sgm.inference.helpers import embed_watermark
# from sgm.util import default, instantiate_from_config
找到其中的DeepFloyDataFiltering,将其中的路径修改为2中下载的ViT-L-14.pt的路径。
3.3 修改open_clip的clip路径
在python环境中,找到…lib/python3.10/site-packages/open_clip/factory.py,大约在210行的if model_cfg is None之后,添加:
if model_cfg is None:with open('.../CLIP-ViT-H-14-laion2B-s32B-b79K/open_clip_config.json', 'r') as f:model_cfg = json.load(f)['model_cfg']
其中的路径是2中下载的clip的路径。
3.4 代码总体结构
代码的运行就是参考https://github.com/Stability-AI/generative-models/blob/main/scripts/sampling/simple_video_sample.py的结构,我是在jupyter中执行的,下面给出我的代码的结构以供参考,所包含的函数和类只给出了名称,其具体内容均可在原项目的git中找到。
import math
import os
from glob import glob
from pathlib import Path
from typing import Optionalimport cv2
import numpy as np
import torch
from einops import rearrange, repeat
from fire import Fire
from omegaconf import OmegaConf
from PIL import Image
from torchvision.transforms import ToTensor# from scripts.util.detection.nsfw_and_watermark_dectection import \
# DeepFloydDataFiltering
from sgm.inference.helpers import embed_watermark
from sgm.util import default, instantiate_from_configimport clip
import torchvision.transforms as Tos.environ['CUDA_VISIBLE_DEVICES'] = '0'# 注意这里的路径,是配置文件yaml所在的目录,我直接把yaml放在同级目录了
RESOURCES_ROOT = './'def load_model_weights(path: str):def load_img(path: str) -> torch.Tensor:# 注意将self.clip_model, _ = clip.load中的路径修改为下载的ViT-L-14.pt路径
class DeepFloydDataFiltering(object):def predict_proba(X, weights, biases):def get_unique_embedder_keys_from_conditioner(conditioner):def clip_process_images(images: torch.Tensor) -> torch.Tensor:def get_batch(keys, value_dict, N, T, device):def load_model(...# 在这个方法里修改输入图像的路径
def sample(...# 执行:可以不用Fire,直接调用即可
sample()
所有的方法均可在项目的git中找到,找不到的话可以直接在git搜索对应的函数名。
4. 资源消耗
官方提供的样例图片,尺寸为(1024, 576),在所有参数均选择默认的情况下,占用显存约为60G。
当我使用的图片为手机原图时,程序很容易就OOM了,所以对于一般手机的相片,可以将尺寸压缩到(960, 720),显存消耗就大概维持在60G。
图片的裁剪主要用到PIL模块,非常方便:
(1) 加载图片:
from PIL import Image
img = Image.open("image.png")
(2) 裁剪图片:
img = img.crop((left, top, right, bot))
(3) 缩放图片:
img = img.resize((960, 720))
需要注意的是,此项目似乎并不能使用cpu进行计算,也不能将device设置成’cuda:0’的方法来指定显卡,但是可以利用os.environ[‘CUDA_VISIBLE_DEVICES’] = '0’的方法来指定显卡。
关于图片的帧数,目前还没有进一步实验,猜测应该是代码中的num_frames参数来控制。
5. 效果预览
下面展示一下我用自己拍的照片的生成效果:

381b3b2a5906da699b1271fc6695f89f

c06e3a2fa85fb925e6a23fe9064cacc6

6a5943a31f38a8b87e54b0394ddf2d16
从效果来看,在前几帧的生成效果通常比较好,随着帧数的推移,视频的部分内容可能会发生形变。尤其是在图三中,随着西郊线小火车由远及近,模型“脑补”出的列车部分开始变得不够真实。
经过我的一些测试,如果输入的图片是街道,以及行人车辆的话,镜头会顺着街道移动,行人和车辆也会移动;如果输入图片是动物,则需要动物主体的分辨率需要高,否则动物主体可能形变失真,如果是人像或静物,则镜头一般只是左右晃动。
总的来说,模型的效果是让人惊喜,但可以预见的。尽管模型在生成所需step上与之前的工作相比,有了很大的改善,但整个生成过程仍然需要较大的显存消耗。
与此同时,图像生成类任务应该是有可以输入prompt的地方以指导生成,但是在该项目中,暂时还没找到文本编码器。希望随着技术的发展,通过文本来指导图片生成视频的,或利用部分关键帧来生成连续视频的技术,可以早日成熟并普及。在今后的学习中,看到有趣的开源项目,我也会试着体验并与大家分享。
相关文章:
多模态——使用stable-video-diffusion将图片生成视频
多模态——使用stable-video-diffusion将图片生成视频 0. 内容简介1. 运行环境2. 模型下载3. 代码梳理3.1 修改yaml文件中的svd路径3.2 修改DeepFloyDataFiltering的vit路径3.3 修改open_clip的clip路径3.4 代码总体结构 4. 资源消耗5. 效果预览 0. 内容简介 近期,…...
)
springboot(ssm网络相册 在线相册管理系统Java(codeLW)
springboot(ssm网络相册 在线相册管理系统Java(code&LW) 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0)…...

邮箱发送短信的多种方式
第一种:邮箱验证方法: 导入依赖: <!-- mail依赖(发送短信的依赖) --><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-mail</artifactId> &l…...
)
R语言——taxize(第五部分)
taxize(第五部分) 3. taxize 文档中译3.71. nbn_synonyms(从 NBN 返回具有给定 id 的分类群名称的所有同义词)3.72. ncbi_children(在 NCBI 中搜索类群的子类群)3.73. ncbi_downstream(检索 NCB…...

负载均衡lvs
简介 ipvsadm 是 Linux 内核中的 IP 虚拟服务器(IPVS)管理工具。IPVS是 Linux 内核提供的一种负载均衡解决方案,它允许将入站的网络流量分发到多个后端服务器,以实现负载均衡和高可用性。IPVS通过在内核中维护一个虚拟服务器表&a…...

【腾讯云云上实验室】探索向量数据库背后的安全监控机制
当今数字化时代,数据安全成为了企业和个人最为关注的重要议题之一。随着数据规模的不断增长和数据应用的广泛普及,如何保护数据的安全性和隐私性成为了迫切的需求。 今天,我将带领大家一起探索腾讯云云上实验室所推出的向量数据库,…...
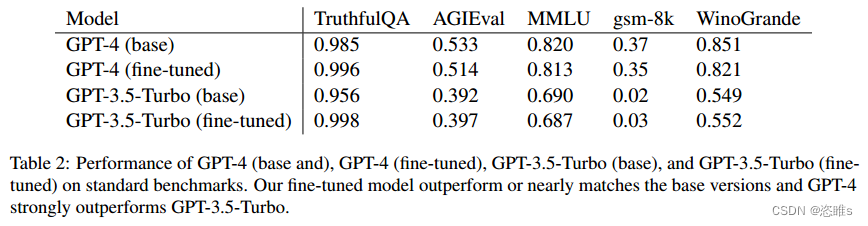
阅读笔记——《Removing RLHF Protections in GPT-4 via Fine-Tuning》
【参考文献】Zhan Q, Fang R, Bindu R, et al. Removing RLHF Protections in GPT-4 via Fine-Tuning[J]. arXiv preprint arXiv:2311.05553, 2023.【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。 目录 摘要 一、介绍 二、背景 三、方法…...

electron实现截图的功能
Electron是一种跨平台的桌面应用程序开发框架,可以使用HTML、CSS和JavaScript等Web技术构建桌面应用程序。下面是一种使用Electron实现截图的简单方法: 安装Electron和截图库 首先,需要安装Electron和一个截图库,例如electron-sc…...

11、动态数码管显示
数码管驱动方式 1、单片机直接扫描:硬件设备简单,但会消耗大量的单片机CPU时间 2、专用驱动芯片:内部自带显存、扫描电路,单片机只需告诉他显示什么即可 #include <REGX52.H> //数组代表显示亮灯的内容0、1、2、3、4、5、…...

Linux的基本指令(三)
目录 前言 echo指令(简述) Linux的设计理念 输出重定向操作符 > 追加输出重定向操作符 >> 输入重定向操作符 < 补充知识 学前补充 more指令 less指令 head指令 tail指令 查看文件中间的内容 利用输出重定向实现 利用管道“ |…...

使用python 实现华为设备的SFTP文件传输
实验目的: 公司有一台CE12800的设备,管理地址位172.16.1.2,现在需要编写自动化脚本,通过SFTP实现简单的上传下载操作。 实验拓扑: 实验步骤: 步骤1:将本地电脑和ensp的设备进行桥接ÿ…...

高防cdn防护原理是什么,是否可以防护服务器吗
随着互联网业务的迅速发展,网络安全问题日益凸显。在这样的背景下,高防CDN作为一种有效的网络安全解决方案,受到了越来越多的关注。那么高防CDN的防护原理是什么呢?接下来就跟小德一起深入了解下吧! 1. 高防CDN的基本概念 我们要明确什么是…...
)
SELinux零知识学习三十五、SELinux策略语言之角色和用户(6)
接前一篇文章:SELinux零知识学习三十四、SELinux策略语言之角色和用户(5) 三、SELinux策略语言之角色和用户 SELinux提供了一种依赖于类型强制(类型增强,TE)的基于角色的访问控制(Role-Based Access Control),角色用于组域类型和限制域类型与用户之间的关系,SELinux…...

初学Flink 学后总结
最近开始学习Flink,一边学习一边记录,以下是基于【尚硅谷】Flink1.13实战教程总结的笔记,方便后面温习 目录 初始 Flink 一:基础概念 1.Flink是什么 2.Flink主要应用场景...

CSS新手入门笔记整理:CSS基本介绍
CSS,指的是“Cascading Style Sheet(层叠样式表)”,用于控制网页外观。 CSS引入方式 外部样式表 独立建立一个.CSS文件,在HTML中使用 link标签 来引用CSS文件。link标签放置在head标签内部。 语法 <link rel&qu…...

【华为OD】B\C卷真题 100%通过:需要打开多少监控器 C/C++实现
【华为OD】B\C卷真题 100%通过:需要打开多少监控器 C/C实现 目录 题目描述: 示例1 代码实现: 题目描述: 某长方形停车场,每个车位上方都有对应监控器,当且仅当在当前车位或者前后左右四个方向任意一个…...

HarmonyOS开发(七):构建丰富页面
1、组件状态管理 1.1、概述 在应用中,界面一般都是动态的。界面会根据不同状态展示不一样的效果。 ArkUI作为一种声明式UI,具有状态驱动UI更新的特点,当用户进行界面交互或有外部事件引起状态改变时,状态的变会会触发组件的自动…...
--rsa - RSA加密解密)
LuatOS-SOC接口文档(air780E)--rsa - RSA加密解密
示例 -- 请在电脑上生成私钥和公钥, 当前最高支持4096bit, 一般来说2048bit就够用了 -- openssl genrsa -out privkey.pem 2048 -- openssl rsa -in privkey.pem -pubout -out public.pem -- privkey.pem 是私钥, public.pem 是公钥 -- 私钥用于 加密 和 签名, 通常保密, 放在…...
简易版王者荣耀
所有包和类 GameFrame类 package newKingOfHonor;import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.event.KeyAdapter; import java.awt.event.KeyEvent; import java.io.File; import java.util.ArrayList;im…...

功能测试进阶建议,学习思路讲解
1. 深入了解测试理论: 了解测试的原理、方法和最佳实践,包括黑盒测试、白盒测试、灰盒测试等。可以阅读相关的书籍或参加在线课程。 2. 学习相关测试工具: 掌握常用的测试工具,如缺陷发现工具、性能测试工具、安全测试工具等。可以…...

PythonOcc实战避坑指南:处理复杂STEP装配体时,如何准确识别零件并计算几何属性?
PythonOcc工业级STEP装配体处理实战:从零件识别到爆炸图生成的全流程避坑指南 在工业设计和机械工程领域,处理复杂装配体模型是日常工作中的重要环节。当我们需要对阀门、齿轮箱等工业设备进行数字化分析时,准确识别零件并计算几何属性是后续…...

ICDM 2024论文精读:MetaSTC如何用‘聚类+元学习’四两拨千斤,大幅提升预测效率?
MetaSTC技术解析:如何用聚类与元学习重构时空预测范式 清晨的城市交通如同人体血管,数据在其中奔流不息。预测这些流动的规律,是智能交通系统的核心挑战。传统深度学习模型往往陷入"算力黑洞"——为了1%的精度提升,需要…...

如何快速在浏览器中搭建全功能Office办公环境:SE Office扩展终极指南
如何快速在浏览器中搭建全功能Office办公环境:SE Office扩展终极指南 【免费下载链接】se-office se-office扩展,提供基于开放标准的全功能办公生产力套件,基于浏览器预览和编辑office。 项目地址: https://gitcode.com/gh_mirrors/se/se-o…...

如何通过社交媒体来提升网站的 SEO 表现
如何通过社交媒体来提升网站的 SEO 表现 在当今互联网时代,社交媒体已经成为了人们获取信息、交流互动的重要平台。越来越多的企业和个人发现,社交媒体不仅仅是一个交流工具,它还能为网站带来巨大的 SEO 价值。本文将探讨如何通过社交媒体来…...

BLIP-2:如何通过Q-Former桥接冻结视觉与大语言模型实现高效多模态预训练
1. BLIP-2为什么能成为多模态预训练的里程碑 第一次看到BLIP-2论文时,最让我惊讶的是它用如此"简单"的方式解决了多模态预训练的两个核心痛点。传统方法就像要求一个厨师同时精通中餐和西餐,而BLIP-2的创新在于让中餐主厨和西餐主厨各司其职&a…...

UE5对象池系统深度解析:如何基于Subsystem框架设计可扩展的Gameplay工具
UE5对象池系统深度解析:如何基于Subsystem框架设计可扩展的Gameplay工具 在快节奏的现代游戏开发中,性能优化始终是开发者面临的核心挑战之一。想象一下这样的场景:当玩家在射击游戏中连续发射数百发子弹,或者在开放世界游戏中频繁…...
)
【Netty】【调试工具】----Windows上网络调试助手NetAssist的使用(Java 开发者实用指南)
NetAssist是Windows下轻量免装的TCP/UDP调试工具,对Java开发者核心价值是快速模拟网络对端、裸抓报文、联调硬件/第三方接口,大幅降低网络编程调试成本。一、Java开发者用它的核心用处 网络编程快速验证 不用写完整客户端/服务端,用NetAssist…...

【GESP】C++五级练习题 luogu-P1226 【模板】快速幂
GESP C 五级练习题,考查并应用快速幂知识点。题目难度⭐⭐☆☆☆,洛谷难度等级普及−。 luogu-P1226 【模板】快速幂 题目要求 题目题解详见:https://www.coderli.com/gesp-5-luogu-p1226/ https://www.coderli.com/gesp-5-luogu-p1226/ht…...

猫抓浏览器扩展:终极网页资源嗅探工具使用完整指南
猫抓浏览器扩展:终极网页资源嗅探工具使用完整指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat Catch…...

开源PDF工具clawPDF:高效办公的终极解决方案
开源PDF工具clawPDF:高效办公的终极解决方案 【免费下载链接】clawPDF Open Source Virtual (Network) Printer for Windows that allows you to create PDFs, OCR text, and print images, with advanced features usually available only in enterprise solutions…...