跟着chatgpt学习|1.spark入门
首先先让chatgpt帮我规划学习路径,使用Markdown格式返回,并转成思维导图的形式
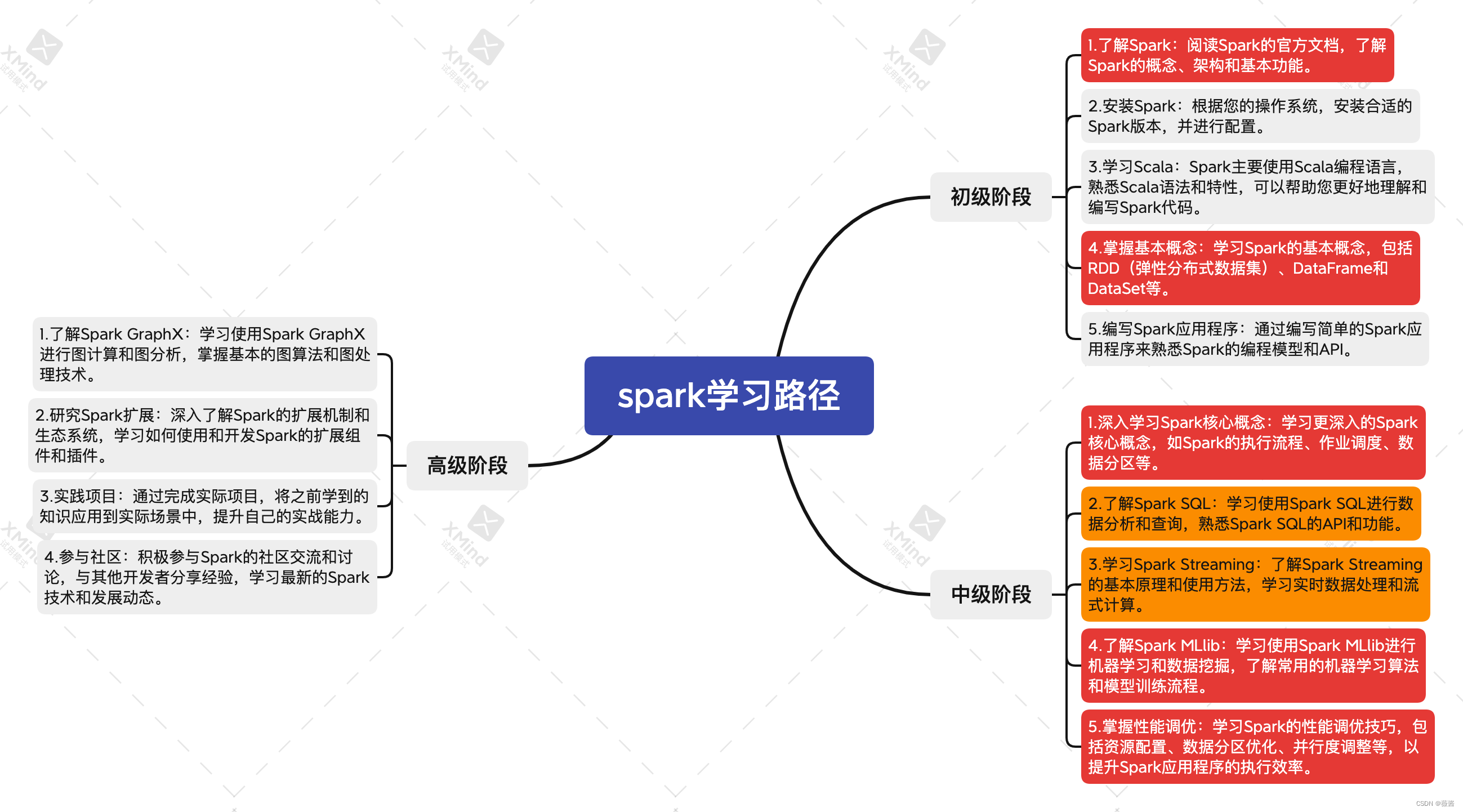
目录
目录
1. 了解spark
1.1 Spark的概念
1.2 Spark的架构
1.3 Spark的基本功能
2.spark中的数据抽象和操作方式
2.1.RDD(弹性分布式数据集)
2.2 DataFrame
2.3 DataSet
1. 了解spark
1.1 Spark的概念
-
弹性分布式数据集(RDD)
是Spark的核心抽象,代表分布式内存中的不可变的对象集合。RDD可以跨多个节点并行操作,是Spark实现高性能的基础。 -
DataFrame和DataSet
Spark提供了结构化数据处理的API,可以使用DataFrame和DataSet进行高效的数据操作和分析。 -
Spark SQL
用于处理结构化数据的模块,提供了SQL查询和数据集操作的API。 -
Spark Streaming
用于实时数据处理和流式计算的模块,能够对数据流进行实时处理和分析。 - Spark MLlib
是Spark提供的机器学习库,包含了常见的机器学习算法和工具,用于数据挖掘和模型训练。
-
Spark GraphX
用于图计算和图分析的模块,提供了图处理和图算法的API。
1.2 Spark的架构
-
Cluster Manager(集群管理器)
集群管理器负责在集群中启动和管理Spark应用程序的执行。常见的集群管理器包括Hadoop YARN、Apache Mesos和Kubernetes。为Spark应用程序分配Executor的资源,并监控各个Executor的状态 -
Driver(驱动器)
驱动器是Spark应用程序的主要控制节点,运行用户编写的Spark应用程序的main函数。驱动器负责解析用户程序,将任务分配给各个Executor,并协调各个组件之间的交互。驱动器负责创建和维护SparkContext对象,SparkContext是与Spark集群进行交互的主要入口点 -
Executor(执行器)
执行器是运行在集群节点上的工作进程,负责执行具体的任务。每个应用程序都有自己的一组执行器,它们在启动时由集群管理器分配。执行器负责执行驱动器分配给它们的任务,并将计算结果返回给驱动器。执行器还负责将数据存储在内存中,并提供对数据的读写能力。在执行器中,每个任务都会被分配到一个线程上执行,可以并行执行多个任务。
三者的关系如下:
- driver和executor是通过cluster manager进行通信的,cluster manager负责将driver和executor连接起来,并协调它们之间的任务调度和资源分配。
- driver通过SparkContext对象与cluster manager通信,并将任务分发给executor执行。driver还负责监控和处理executor的状态和计算结果。
- executor接收来自driver的任务,并在本地执行。executor将计算结果返回给driver,并及时向driver汇报任务的状态。
总结起来,Cluster Manager负责资源的分配和任务调度,Driver负责解析用户程序并协调任务的执行,而Executor负责实际执行任务并返回计算结果。它们三者一起协作,实现了Spark应用程序的分布式计算。
1.3 Spark的基本功能
-
分布式数据处理
Spark可以处理大规模数据集,并支持在分布式环境中进行并行计算。它通过将数据加载到内存中并在集群中进行分布式计算,提供高性能的数据处理能力。 -
数据抽象和操作
Spark提供了弹性分布式数据集(RDD)的抽象,可以以类似于本地集合的方式对数据进行处理。Spark的API支持各种数据操作,如映射、过滤、聚合和排序等。 -
批处理和交互式查询
Spark提供了Spark SQL模块,支持使用SQL语言进行数据查询和操作。它可以处理结构化数据,并提供了高级API(如DataFrame和DataSet),使得批处理和交互式查询更加方便和高效。 -
流处理和实时分析
Spark Streaming模块使得实时数据处理和流式分析成为可能。它支持将连续数据流以微批处理的方式进行处理,并提供了窗口操作、状态管理和实时计算等功能。 -
机器学习和数据挖掘
Spark提供了Spark MLlib机器学习库,包含了常见的机器学习算法和工具。它支持分类、回归、聚类、推荐等机器学习任务,并提供了特征处理、模型评估和模型调优等功能。 -
图计算和图分析
Spark GraphX模块提供了图处理和图算法的功能。它支持构建和处理大规模图数据,并提供了图遍历、图算法和图分析等功能。 -
分布式文件系统和数据源支持
Spark支持多种分布式文件系统和数据源,如Hadoop HDFS、Amazon S3、Apache Cassandra等。这使得Spark可以方便地与各种数据存储和数据处理平台集成。
2.spark中的数据抽象和操作方式
2.1.RDD(弹性分布式数据集)
- 分布式内存中不可变对象集合
- 分区的数据集,可以跨节点并行操作
- 特性
- 容错性
- 不可变性
- 对RDD进行转换操作会生成一个新的RDD
- 可分区性
- 根据数据的键或哈希值进行分区,以便在集群中进行并行处理
- 可持久化
- 可以将数据存储在内存中,以便进行高速计算
2.2 DataFrame
- Spark SQL中的数据抽象
- 是具有命名列和逻辑模式的分布式数据集
- 特性
- 结构化数据
- 优化执行
- 使用Spark的优化器,将查询转为更高效的物理执行计划
- 支持SQL查询
2.3 DataSet
- Spark1.6后引入的数据抽象,是DataFrame的扩展
- 提供类型安全的分布式数据集
- 特性
- 类型安全
支持编译时类型检查 - 面向对象
可以使用面向对象的方式进行数据操作,同时也支持SQL查询 - 高性能
可以和DataFrame共享相同的执行计划和优化器,提供高性能的数据处理能力
- 类型安全
相关文章:
跟着chatgpt学习|1.spark入门
首先先让chatgpt帮我规划学习路径,使用Markdown格式返回,并转成思维导图的形式 目录 目录 1. 了解spark 1.1 Spark的概念 1.2 Spark的架构 1.3 Spark的基本功能 2.spark中的数据抽象和操作方式 2.1.RDD(弹性分布式数据集) 2…...
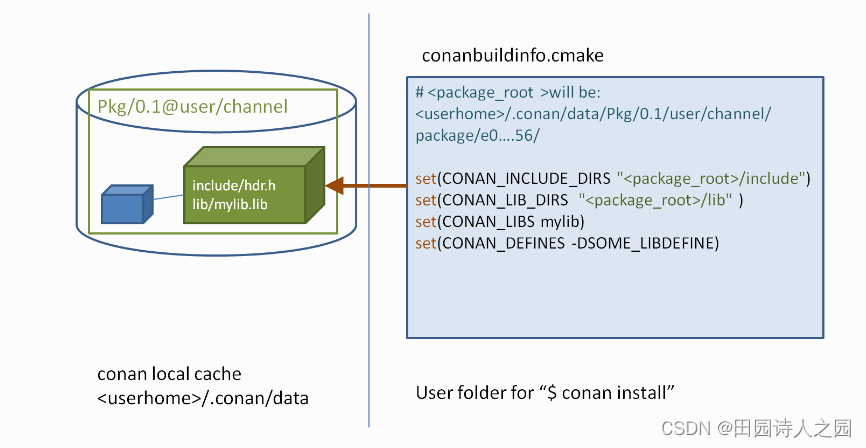
使用conan包 - 安装依赖项
使用conan包 - 安装依赖项 主目录 conan Using packages1 Requires2 Optional user/channel3 Overriding requirements4 Generators5 Options 本文是基于对conan官方文档Installing dependencies的翻译而来, 更详细的信息可以去查阅conan官方文档。 This section s…...

【数据库设计和SQL基础语法】--数据库设计基础--数据规范化和反规范化
一、 数据规范化 1.1 数据规范化的概念 定义 数据规范化是数据库设计中的一种方法,通过组织表结构,减少数据冗余,提高数据一致性和降低更新异常的过程。这一过程确保数据库中的数据结构遵循一定的标准和规范,使得数据存储更加高…...

复亚智能交通无人机:智慧交通解决方案大公开
城市的现代化发展离不开高效的交通管理规划。传统的交通管理系统庞大繁琐,交警在执行任务时存在安全隐患。在这一背景下,复亚智能交通无人机应运而生,成为智慧交通管理中的重要组成部分。交通无人机凭借其高灵活性、低成本、高安全性等特点&a…...

MYSQL 及 SQL 注入
文章目录 前言什么是sql注入防止SQL注入Like语句中的注入后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:Mysql 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现…...

古埃及金字塔的修建
从理论上说,古埃及人完全有能力设计并建造出充满各种奇妙细节的胡夫金字塔,但后世还是不断涌现出质疑之声,原因倒也简单,那就是胡夫金字塔实在太大了。据推算,整座金字塔使用大约230万块巨石,总质量可达约5…...

Android 13.0 系统settings系统属性控制一级菜单显示隐藏
1.概述 在13.0的系统rom定制化开发中,系统settings的一级菜单有些在客户需求中需要去掉不显示,所以就需要通过系统属性来控制显示隐藏, 从而达到控制一级菜单的显示的目的,而系统settings是通过静态加载的方式负责显示隐藏,接下来就来实现隐藏显示一级菜单的 功能实现 2.…...
STM32 寄存器配置笔记——USART配置中断接收乒乓缓存处理
一、概述 本文主要介绍如何配置USART接收中断,使用乒乓缓存的设计接收数据并将其回显在PC 串口工具上。以stm32f10为例,配置USART1 9600波特率。具体配置参考上一章节STM32 寄存器配置笔记——USART配置 打印。 乒乓缓存的设计应用场景:当后面…...
)
第二十一章 解读XML与JSON文件格式(工具)
XML XML tree and elements 将XML文档解析为树(tree) 我们先从基础讲起。XML是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树。ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着…...

Web 自动化神器 TestCafe(三)—用例编写篇
一、用例编写基本规范 1、 fixture 测试夹具 使用 TestCafe 编写测试用例,必须要先使用 fixture 声明一个测试夹具,然后在这个测试夹具下编写测试用例,在一个编写测试用例的 js 或 ts 文件中,可以声明多个测试夹具 fixture(测试…...

Redis 基本命令—— 超详细操作演示!!!
内存数据库 Redis7—— Redis 基本命令 三、Redis 基本命令(下)3.8 benchmark 测试工具3.9 简单动态字符串SDS3.10 集合的底层实现原理3.11 BitMap 操作命令3.12 HyperLogLog 操作命令3.13 Geospatial 操作命令3.14 发布/订阅命令3.15 Redis 事务 四、Re…...

Linux:centOS常用命令
CentOS是一种基于Red Hat Enterprise Linux(RHEL)的开源操作系统,因此与其他基于Linux的系统共享很多相似的命令。以下是一些在CentOS上常用的命令 件和目录操作: ls: 列出目录内容。cd: 切换目录。pwd: 显示当前工作目录。mkdir: 创建目录…...
数据结构-二叉树(1)
1.树概念及结构 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。 1.有一个特殊的结点&…...
SpringBoot——国际化
优质博文:IT-BLOG-CN 一、Spring 编写国际化时的步骤 【1】编写国际化配置文件; 【2】使用ResourceBundleMessageSource管理国际化资源文件; 【3】在页面使用ftp:message取出国际化内容; 二、SpringBoot编写国际化步骤 【1】创…...
shell 条件语句 if case
目录 测试 test测试文件的表达式 是否成立 格式 选项 比较整数数值 格式 选项 字符串比较 常用的测试操作符 格式 逻辑测试 格式 且 (全真才为真) 或 (一真即为真) 常见条件 双中括号 [[ expression ]] 用法 &…...
C语言:写一个函数,实现3*3矩阵的转置(指针)
分析: 在主函数 main 中,定义一个 3x3 的整型数组 a,并定义一个指向整型数组的指针 p。然后通过循环结构和 scanf 函数,从标准输入中读取用户输入的 3x3 矩阵的值,并存储到数组 a 中。 接下来,调用 mov…...

STL pair源码分析
STL pair源码分析 pair是STL中提供的一个简单的struct,用来处理类型不同的一对值,是非常常用的数据结构。这一对值是以public的形式暴露出来的,直接通过first和second就能访问。我们以MSVC提供的STL源码为例,分析pair的具体实现。…...

【开源】基于Vue和SpringBoot的农家乐订餐系统
项目编号: S 043 ,文末获取源码。 \color{red}{项目编号:S043,文末获取源码。} 项目编号:S043,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 用户2.2 管理员 三、系统展示四、核…...

MyBatis 操作数据库(入门)
一:MyBatis概念 (1)MyBatis 💗MyBatis是一款优秀的持久层框架,用于简化JDBC的开发 (2)持久层 1.持久层 💜持久层:持久化操作的层,通常指数据访问层(dao),是用来操作数据库的 2.持久层的规范 ①…...

JVM——垃圾回收器(G1,JDK9默认为G1垃圾回收器)
1.G1垃圾回收器 JDK9之后默认的垃圾回收器是G1(Garbage First)垃圾回收器。 Parallel Scavenge关注吞吐量,允许用户设置最大暂停时间 ,但是会减少年轻代可用空间的大小。 CMS关注暂停时间,但是吞吐量方面会下降。 而G1…...

别再删容器重装了!Docker运行n8n工作流的正确姿势:从环境变量到数据持久化
Docker部署n8n工作流:从环境变量配置到持久化存储的完整实践指南 遇到n8n的Secure Cookie警告就删容器重装?这种简单粗暴的操作不仅低效,还可能丢失关键数据。本文将带你深入理解Docker部署n8n的正确方法论,从环境变量配置到数据…...

别再用鼠标拖滚动条了!GoLand 2022.2.3 这几个插件让你的代码阅读效率翻倍
GoLand 2022.2.3 插件组合:打造专业开发者的代码阅读工作流 作为一名长期与Go代码打交道的开发者,你是否经历过这样的场景:接手一个数万行代码的项目时,面对密密麻麻的函数和结构体,像在迷宫中寻找出口;或是…...

G-Helper华硕优化工具:5分钟解锁300%性能提升的轻量级解决方案
G-Helper华硕优化工具:5分钟解锁300%性能提升的轻量级解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, S…...

STM32主控的三相逆变器及单相/三相逆变程序实现
三相逆变 单相/三相逆变器 SPWM ---stm32主控(输入、输出具体可根据需要设定),本逆变器可以二次开发。 本内容只包括 逆变程序,实现变频(0~100Hz)、变压调节,均有外接按键控制(使用C…...

工厂升级不换设备?揭秘全志T113-i边缘网关的“万能翻译”魔法
在当今智能制造和工业物联网的浪潮下,工厂车间正经历着一场深刻的“神经”系统升级。以PROFINET、EtherNet/IP、Modbus TCP为代表的工业以太网协议,凭借其高速、实时、开放的特性,已成为现代自动化系统的“中枢神经”。然而,走进许…...

新手避坑指南:用Matlab给六轴机器人做路径规划,选笛卡尔空间还是关节空间?
六轴机器人路径规划实战:从零开始掌握笛卡尔与关节空间选择策略 1. 初识机器人路径规划的核心挑战 第一次接触六轴机器人路径规划时,我被各种专业术语和数学公式淹没。直到亲手在Matlab中实现第一个机械臂运动程序,才真正理解路径规划的本质—…...

the-glorious-dotfiles 核心功能解析:从通知中心到屏幕录制
the-glorious-dotfiles 核心功能解析:从通知中心到屏幕录制 【免费下载链接】the-glorious-dotfiles A glorified personal dot files 项目地址: https://gitcode.com/gh_mirrors/th/the-glorious-dotfiles the-glorious-dotfiles 是一套功能丰富的个人配置文…...

如何通过WeChatMsg实现微信聊天记录的永久保存与智能分析?
如何通过WeChatMsg实现微信聊天记录的永久保存与智能分析? 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

OpenClaw开源贡献:为gemma-3-12b-it开发并共享自定义技能
OpenClaw开源贡献:为gemma-3-12b-it开发并共享自定义技能 1. 为什么选择为gemma-3-12b-it开发技能 去年冬天第一次接触OpenClaw时,我就被它的设计理念吸引了——一个真正能在本地运行的AI智能体框架。当时我正为重复性的数据清洗工作头疼,而…...

ESP32轻量级GraphQL客户端库设计与嵌入式实践
1. 项目概述esp32-graphql-client是一款专为 ESP32 平台设计的轻量级、高可靠性 GraphQL 客户端库,其设计哲学直接受益于 Apollo Client 的简洁性与表达力。该库并非简单封装 HTTP 请求,而是构建了一套面向嵌入式场景的完整数据交互抽象层:它…...