第二十一章 解读XML与JSON文件格式(工具)
XML
XML tree and elements
将XML文档解析为树(tree)
我们先从基础讲起。XML是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树。ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着树上的单个节点。对整个XML文档的交互(读取,写入,查找需要的元素),一般是在ElementTree层面进行的。对单个XML元素及其子元素,则是在Element层面进行的。
XML是一种固有的分层数据格式,最自然的表示方法是使用树ET。ET有两个类:
- ElementTree:表示整个XML文档为树,元素表示此树中的单个节点。与整个文档的交互(读取和写入文件)通常是在ElementTree级别上完成的。
- Element:与单个XML元素及其子元素的交互是在Element元素级别上完成的。
tree和root分别是ElementTree中两个很重要的类的对象:ElementTree和Element。
下面对XML文件的格式做一些说明:
- Tag: 使用
<>包围的部分,如:<表示:start-tag,>表示:end-tags; - Element:被Tag包围的部分,如:
<rank>68</rank>中的68,可以认为是一个节点,它可以有子节点; - Attribute:在Tag中可能存在的name/value对,如
<country name="Liechtenstein">中的name=”Liechtenstein”,一般表示属性。
在Python中处理XML格式文件需要导入的第三方库:
# 导入第三方库
import xml.etree.ElementTree as ET
详细参考:xml.etree.ElementTree的官方文档
XML文件的常见操作
1. 读入xml格式的文件,并显示全部行数据
读入xml格式的文件,并显示全部行数据:
假设有.xml格式文件file_xml,现需要使用Python读入.xml格式文件,并显示全部行数据,执行代码如下:
open_file = open(file_xml) # file_xml为.xml格式文件
read_file = open_file.readlines() # 读入所有行数据
典型范例:
from xml.etree import ElementTree as ETfile_xml = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/anno.xml'open_file = open(file_xml)
read_file = open_file.readlines() # 读入所有行数据
print(read_file)
>>>
['<annotation>\n','\t<folder>id12_玻璃膜疣</folder>\n','\t<filename>014f80f346d72001267240b1a62f1b72.jpg</filename>\n','\t<path>/Users/edz/Documents/yandi_data/taishi_loading/load_image/原始TXT表/第一批七种病灶/id12_玻璃膜疣/014f80f346d72001267240b1a62f1b72.jpg</path>\n','\t<source>\n','\t\t<database>Unknown</database>\n','\t</source>\n','\t<size>\n','\t\t<width>1924</width>\n','\t\t<height>1556</height>\n','\t\t<depth>3</depth>\n','\t</size>\n','\t<segmented>0</segmented>\n','\t<object>\n','\t\t<name>id12</name>\n','\t\t<pose>Unspecified</pose>\n','\t\t<truncated>0</truncated>\n','\t\t<difficult>0</difficult>\n','\t\t<bndbox>\n','\t\t\t<xmin>1378</xmin>\n','\t\t\t<ymin>742</ymin>\n','\t\t\t<xmax>1700</xmax>\n','\t\t\t<ymax>1319</ymax>\n','\t\t</bndbox>\n','\t</object>\n','\t<object>\n','</annotation>\n']
2. 解析xml格式的文件
解析xml格式的文件:
欲解析xml格式的文件,需要先以另外一种方式读入一个XML模板文件(如:file_xml),方便后续以它为基础模板,进行增、删、改等操作,得到自定义的目标XML文件。
备注: 个人理解解析xml格式的文件与上边提到的读入xml文件的区别在于:
读入xml文件进行的是只读操作,无法对其进行后续的增、删、改等操作;而解析xml文件则是先读入一个模板xml文件,后续可以对其进行增、删、改等一系列神操作。
在解析xml格式的文件之前,读入模板XML文件(如:file_xml),有两种途径,从文件读入和从字符串读入。
1. 从文件读入: 通过tree = ET.parse(file_xml)和root = tree.getroot()两行代码实现,具体示例如下:
import xml.etree.ElementTree as ETfile_xml = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/anno.xml'
tree = ET.parse(file_xml) # 类ElementTree
root = tree.getroot() # 类Element
print(root) # 这时得到的root是一个指向Element的对象
>>> <Element 'annotation' at 0x135444590>
2. 从字符串读入: 通过root = ET.fromstring(sample_as_string)实现,不太推荐!!!
root = ET.fromstring(sample_as_string) # 没有尝试过
获取XML中的元素
查看一个Element的Tag和Attribute的方法
tree和root分别是ElementTree中两个很重要的类的对象:ElementTree和Element。
以解析XML文件的方式读入一个xlm文件后,得到的 root是一个指向Element的对象 ,我们可以通过root.tag和root.attrib来分别查看root的tag和attrib,从而验证这一点,示例如下:
# - 查看root下的`Tag`和`Attribute`
root.tag
>>> 'data'
root.attrib
>>>{} # 字典为空,表示无属性
上面的代码说明了查看一个Element的Tag和Attribute的方法,Tag是一个字符串,而Attribute得到的是一个字典。
另外,还可以使用Element.get(AttributeName)来代替Element.attrib[AttributeName]来访问(此处的Element即:root)。
获取XML中的元素:
Element有一些有用的方法,可以帮助递归地遍历它下面的所有子树(它的子树,它们的子树,等等)比如:Element.iter():
for neighbor in root.iter('neighbor'):print(neighbor.attrib)
>>>
{'name': 'Austria', 'direction': 'E'}
{'name': 'Switzerland', 'direction': 'W'}
{'name': 'Malaysia', 'direction': 'N'}
{'name': 'Costa Rica', 'direction': 'W'}
{'name': 'Colombia', 'direction': 'E'}
1.Element.findall(): 只找到带有标签的元素,该标签是当前元素的直接子元素。
2.Element.find() :找到第一个带有特定标签的子元素,例如:root.find('folder').text可以查看指向Element的对象root的"folder"项标签对应的内容,即:”玻璃膜疣“。
3.Element.text: 查看Element的值(或访问标签的内容), 使用root.find('filename').text查看标签内容时,可以根据缩进层次不同,依次添加多个find(‘xxx’)级层,得到对应层级下的Element的值。
4.Element.get():访问标签的属性值
典型范例:
.xml格式的模板文件template_file的内容如下:
<annotation><folder>玻璃膜疣</folder><filename>0002.jpg</filename><path>/Users/edz/Documents/yandi_data/taishi_loading/load_image/原始TXT表/第一批七种病灶/id12_玻璃膜疣/002.jpg</path><source><database>Unknown</database></source><size><width>1924</width><height>1556</height><depth>3</depth></size><segmented>0</segmented><object><name>id12</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>1378</xmin><ymin>742</ymin><xmax>1700</xmax><ymax>1319</ymax></bndbox></object>
</annotation>
使用root.find('filename').text查看标签内容,并根据缩进层次不同添加多个find(‘xxx’)级层,详细代码如下:
from lxml.etree import Element, SubElement, tostring, ElementTree
from xml.dom import minidom # 修改自己的路径
template_file = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/anno.xml'
# 通过读取模板xlm文件来导入这些数据:
tree.parse(template_file) # 调用parse()方法,返回解析树
root = tree.getroot() # 获取根节点# 查看Element的值——我们可以直接用`Element.text`来得到这个Element的值。
# 使用root.find().text查看
root.find('filename').text # 第一层下每一项内容
>>>
0002.jpgroot.find('size').find('height').text # 查看第二层下每一项内容
>>>
1556root.find('object').find('bndbox').find('xmin').text # 查看第三层下每一项内容
>>>
1378# 使用root.findall('size')[i].findall('width')[i].text查看
print([root.findall('size')[i].findall('width')[i].text for i in range(len(root.findall('size')[i].findall('width')))]) # 列表生成式输出# 使用root.iter('filename')循环查看:
for neighbor in root.iter('filename'):print(neighbor.text)
修改XML文件——修改一个Element
前面已经介绍了如何获取一个Element的对象,以及查看它的Tag、Attribute、值和它的孩子。下面介绍如何修改一个Element并对XML文件进行保存。
修改Element:
- 修改Element可以直接访问
Element.text。 - 修改Element的
Attribute,也可以用来新增Attribute,语法格式为:Element.set('AttributeName','AttributeValue'),示例如下:
##Element.set('AttributeName','AttributeValue') # 通过修改Element的`Attribute`,实现新增`Attribute`
root[0].set('name','9999')
新增孩子节点:
Element.append(childElement)
删除孩子节点:
Element.remove(childElement)
保存XML文件
保存XML文件:
我们从文件解析的时候,我们用了一个ElementTree的对象tree,在完成修改之后,还用tree来保存最终的XML文件,语法格式为:tree=ET.ElementTree(root)和tree.write(file_path)两行代码实现。
tree=ET.ElementTree(root) # root为修改后的root
tree.write("/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/99.xml")
构建XML文件
利用ET,很容易就可以完成XML文档构建,并写入保存为文件。ElementTree对象的write方法就可以实现这个需求。
一般来说,有两种主要使用场景:
- 一是你先读取一个XML文档,进行修改,然后再将修改写入文档;
- 二是从头创建一个新XML文档。
构建XML文件:
ElementTree提供了两个静态函数(直接用类名访问,这里我们用的是ET)可以很方便的构建一个XML,语法格式为:root = ET.Element('data')和b = ET.SubElement(root, 'b'):用于创建新的子元素b。示例如下:
import xml.etree.ElementTree as ET
root = ET.Element('data')
country = ET.SubElement(root,'country', {'name':'Liechtenstein'})
rank = ET.SubElement(country,'rank')
rank.text = '1'
year = ET.SubElement(country,'year')
year.text = '2008'
tree=ET.ElementTree(root)
tree.write("99.xml")
创建的xml文件内容如下:
<data><country name="Liechtenstein"><rank>1</rank><year>2008</year></country></data>
完整练手实例
实例001:
Target: 本实例旨在帮助大家学习、了解XML文件的解析、元素查询等操作的使用:
准备工作: 下面这段XML文件,我们将它保存为文件sample.xml,并将其作为.xml格式的模板文件,用以完成后续所有操作。
<?xml version="1.0"?>
<data><country name="Liechtenstein"><rank>1</rank><year>2008</year><gdppc>141100</gdppc><neighbor name="Austria" direction="E"/><neighbor name="Switzerland" direction="W"/></country><country name="Singapore"><rank>4</rank><year>2011</year><gdppc>59900</gdppc><neighbor name="Malaysia" direction="N"/></country><country name="Panama"><rank>68</rank><year>2011</year><gdppc>13600</gdppc><neighbor name="Costa Rica" direction="W"/><neighbor name="Colombia" direction="E"/></country>
</data>
功能实现:
(1)解析xml格式的文件:
import xml.etree.ElementTree as ET
#首先从文件读入:
file_xml = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/anno.xml'
tree = ET.parse(file_xml) # 类ElementTree
root = tree.getroot() # 类Element
print(root) # 这时得到的root是一个指向Element的对象
>>> <Element 'annotation' at 0x135444590>
(2)查看一个Element的Tag和Attribute的方法:
# 读入xlm文件后得到的root是一个指向Element的对象,我们可以通过查看root的tag和attrib来验证这一点:
root.tag #`Tag`是一个字符串,
>>> 'data'
root.attrib # `Attribute`得到的是一个字典。
>>>{}
###另外,还可以使用`Element.get(AttributeName)`来代替`Element.attrib[AttributeName]`来访问。
(3)获取XML中的元素:
for neighbor in root.iter('neighbor'):print(neighbor.attrib)
>>>
{'name': 'Austria', 'direction': 'E'}
{'name': 'Switzerland', 'direction': 'W'}
{'name': 'Malaysia', 'direction': 'N'}
{'name': 'Costa Rica', 'direction': 'W'}
{'name': 'Colombia', 'direction': 'E'}
#1.`Element.findall():` 只找到带有标签的元素,该标签是当前元素的直接子元素。
#2.`Element.find()` :找到第一个带有特定标签的子元素。
#3.`Element.text`:访问标签的内容
#4.`Element.get()`:访问标签的属性值
(4)获取XML中的元素:
#修改Element可以直接访问Element.text。
#修改Element的Attribute,也可以用来新增Attribute,语法如下:Element.set('AttributeName','AttributeValue')
root[0].set('name','9999')
# 新增孩子节点:
Element.append(childElement)
# 删除孩子节点:
Element.remove(childElement)
实例002:
Target: 先打开一个定义好的.xlm格式的模板文件,之后将TXT文件中的标注框信息逐行读入,用于修改xlm文件模板对应的指标数据,最后将修改后的新xlm文件写出保存。
"""核心思想:先打开一个定义好的xlm文件模板,之后将TXT文件中的标注框信息逐行读入,用于修改xlm文件模板对应的指标数据,最后将修改后的新xlm文件写出保存。"""
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import cv2# 模板xlm文件的存储路径
template_file = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/anno.xml'
path = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/' # TXT文件数据的原始格式
train_files = '014f80f346d72001267240b1a62f1b72.jpg id12 1.3418148e+03, 6.2916492e+02, 1.4483580e+03, 9.2253162e+02, 6.3271374e-01'
trainFile = train_files.split() # trainFile存放全量的原始数据
print('原始数据集格式:{}'.format(trainFile))
>>>
原始数据集格式:['014f80f346d72001267240b1a62f1b72.jpg', 'id12', '1.3418148e+03,', '6.2916492e+02,', '1.4483580e+03,', '9.2253162e+02,', '6.3271374e-01']
file_name = trainFile[0]
print(file_name)
>>>
014f80f346d72001267240b1a62f1b72.jpg# 定义新的xlm文件的详细指标数据
label = trainFile[1]
xmin = trainFile[2]
ymin = trainFile[3]
xmax = trainFile[4]
ymax = trainFile[5]############# 读取模板xlm文件——用于存放TXT文件内容:
tree.parse(template_file) # 调用parse()方法,返回解析树
root = tree.getroot() # 获取根节点##########修改新的xlm文件的详细指标数据
# folder
root.find('folder').text = 'new_folders'
# 修改魔板xlm文件中的内容为目标结果
root.find('filename').text = file_name # 2.Element.find() :找到第一个带有特定标签的子元素。
# # path
root.find('path').text = path + file_name
# 查看部分修改结果
print(root.find('filename').text) # 第一层下每一项内容
print(root.find('path').text) # 第一层下每一项内容
print(root.find('size').find('height').text) # 查看第二层下每一项内容
print(root.find('object').find('bndbox').find('xmin').text) # 查看第三层下每一项内容
>>>
014f80f346d72001267240b1a62f1b72.jpg
/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/014f80f346d72001267240b1a62f1b72.jpg
1556
1378
# size
sz = root.find('size')
im = cv2.imread(path + file_name) # 读取图片信息sz.find('height').text = str(im.shape[0])
sz.find('width').text = str(im.shape[1])
sz.find('depth').text = str(im.shape[2])print('iamge height:',im.shape[0])
print('iamge width:',im.shape[1])
print('iamge depth:',im.shape[2])
>>>
iamge height: 1556
iamge width: 1924
iamge depth: 3# object
obj = root.find('object')obj.find('name').text = label
bb = obj.find('bndbox')
bb.find('xmin').text = xmin
bb.find('ymin').text = ymin
bb.find('xmax').text = xmax
bb.find('ymax').text = ymax########## 校验修改后的root是否为新数据
root.find('object').find('bndbox').find('ymax').text
>>>
'9.2253162e+02,' # 符合预期
########## 保存新生成的xlm数据文件
tree=ET.ElementTree(root)
tree.write("/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/99.xml")
常用的属性 & 方法
ET 里面的属性 & 方法很多,这里列出常用的几个,供使用中备查。
1.Element 对象
常用的属性如下:
- tag:string,元素数据种类
- text:string,元素的内容
- attrib:dictionary,元素的属性字典
- tail:string,元素的尾形
针对属性的操作如下:
- clear():清空元素的后代,属性,text 和 tail 也设置为 None。
- items():根据属性字典返回一个列表,列表元素为(key,value)。
- keys():返回包含所有元素属性键的列表。
- set(key,value):设置新的属性键和值。
针对后代的操作如下:
- append(subelement):添加直系子元素。
- extend(sunelements):增加一串元素对象作为子元素。
- find(match):寻找第一个匹配子元素,匹配对象可以为 tag 或 path。
- findall(match):寻找所有匹配子元素,匹配对象可以为 tag 或 path。
- insert(index,element):在指定位置插入子元素。
- remove(subelement):删除子元素
2.ElementTree 对象
- find(match)。
- findall(match)。
- getroot():获取根结点。
- parse(source,parser = None):装载 XML 对象,source 可以为文件名或文件类型对象。
具体使用
- 解析XML文件并获取根节点:
import xml.etree.ElementTree as ETtree = ET.parse('example.xml')
root = tree.getroot()
print(root.tag)
- 遍历XML文件的所有节点:
for child in root:print(child.tag, child.attrib)for subchild in child:print(subchild.tag, subchild.text)
- 根据标签名查找子节点:
for child in root.iter('tagName'):print(child.text)
- 根据属性查找节点:
for child in root.findall('.//tagName[@attrName="value"]'):print(child.text)
- 修改XML文件中的文本内容:
for subchild in root.findall('.//tagName'):subchild.text = 'new text'
tree.write('example.xml')
- 添加新的子节点:
new_child = ET.Element('tagName')
new_child.text = 'new text'
root.append(new_child)
tree.write('example.xml')
- 删除XML文件中的节点:
for child in root.findall('.//tagName'):root.remove(child)
tree.write('example.xml')
- 创建XML文件并保存到磁盘:
root = ET.Element('root')
child = ET.SubElement(root, 'child')
child.text = 'child text'
tree = ET.ElementTree(root)
tree.write('example.xml')
- 解析XML字符串并获取根节点:
xml_string = '<root><child>child text</child></root>'
root = ET.fromstring(xml_string)
print(root.tag)
JSON
就数据传递而言, XML 是一种选择,当然这里还有另一种选择 – 「JSON」。它是一种轻量级的数据交换格式,如果各位想要做 Web 编程的话,则肯定会用到它。下面我们就开始今天的学习。
首先我们参考《维基百科》中的相关内容,来对 JSON 做如下介绍:
JSON ( JavaScript Object Notation )
是一种由道格拉斯构想设计、轻量级的数据交换语言,以文字为基础,且易于让人阅读。尽管 JSON 是 JavaScript 的一个子集,但
JSON 是独立于语言的文本格式,并且采用了类似 C 语言家族的一些习惯。 关于 JSON
更为详细的内容,可以参考其官方网站,在这我截取部分内容,让大家更好的了解一下 JSON 的结构。
JSON 构建于两种结构基础之上:
- “名称/值”对的集合。不同的语言中,它被理解为对象(object),记录(record),结构(struct),字典(dictionary),哈希表(hash table)等。
- 值的有序列表。在某些语言中,它被理解为数组(array),类似于 Python 中的类表。
Python 标准库中有 JSON 模块,主要是执行序列化和反序列化功能。
- 序列化:encoding,把一个 Python 对象编码转化成 JSON 字符串;
- 反序列化:decoding,把 JSON 格式字符串解码转换为 Python 数据对象。
基本操作
JSON 模块相比于 XML 来说真的是简单多了:
>>> import json
>>> json.__all__
['dump', 'dumps', 'load', 'loads', 'JSONDecoder', 'JSONDecodeError', 'JSONEncoder']
1.encoding:dumps()
>>> data = [{'name':'rocky','like':('python','c++'),'age':23}]
>>> data
[{'name': 'rocky', 'like': ('python', 'c++'), 'age': 23}]
>>> data_json = json.dumps(data)
>>> data_json
'[{"name": "rocky", "like": ["python", "c++"], "age": 23}]'
encoding 的操作比较简单,请仔细观察一下上面代码中 data 和 data_json 的不同:like 的值从元组变成了列表,其实还有不同,请看下面:
>>> type(data)
<class 'list'>
>>> type(data_json)
<class 'str'>
2.decoding:loads()
decoding 的过程其实也像上面那么简单:
>>> new_data = json.loads(data_json)
>>> new_data
[{'name': 'rocky', 'like': ['python', 'c++'], 'age': 23}]
上面需要注意的是,解码之后并没有将值中的列表还原为数组。上面的 data 都不是很长,还能凑活着看,如何很长,阅读其实就很有难度了。所以 JSON 的 dumps() 提供了可选的参数,利用它们能在输入上对人更好,当然这个对机器来说都是无所谓的事情。
>>> data1 = json.dumps(data,sort_keys = True,indent = 2)
>>> print(data1)
[{"age": 23,"like": ["python","c++"],"name": "rocky"}
]
sort_keys = True 的意思是按照键的字典顺序排序;indent = 2 则是让每个键值对显示的时候,以缩进两个字符对齐,这样的视觉效果就好多了。
n)
new_data
[{‘name’: ‘rocky’, ‘like’: [‘python’, ‘c++’], ‘age’: 23}]
上面需要注意的是,解码之后并没有将值中的列表还原为数组。上面的 data 都不是很长,还能凑活着看,如何很长,阅读其实就很有难度了。所以 JSON 的 dumps() 提供了可选的参数,利用它们能在输入上对人更好,当然这个对机器来说都是无所谓的事情。```text
>>> data1 = json.dumps(data,sort_keys = True,indent = 2)
>>> print(data1)
[{"age": 23,"like": ["python","c++"],"name": "rocky"}
]
sort_keys = True 的意思是按照键的字典顺序排序;indent = 2 则是让每个键值对显示的时候,以缩进两个字符对齐,这样的视觉效果就好多了。
相关文章:
)
第二十一章 解读XML与JSON文件格式(工具)
XML XML tree and elements 将XML文档解析为树(tree) 我们先从基础讲起。XML是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树。ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着…...

Web 自动化神器 TestCafe(三)—用例编写篇
一、用例编写基本规范 1、 fixture 测试夹具 使用 TestCafe 编写测试用例,必须要先使用 fixture 声明一个测试夹具,然后在这个测试夹具下编写测试用例,在一个编写测试用例的 js 或 ts 文件中,可以声明多个测试夹具 fixture(测试…...

Redis 基本命令—— 超详细操作演示!!!
内存数据库 Redis7—— Redis 基本命令 三、Redis 基本命令(下)3.8 benchmark 测试工具3.9 简单动态字符串SDS3.10 集合的底层实现原理3.11 BitMap 操作命令3.12 HyperLogLog 操作命令3.13 Geospatial 操作命令3.14 发布/订阅命令3.15 Redis 事务 四、Re…...

Linux:centOS常用命令
CentOS是一种基于Red Hat Enterprise Linux(RHEL)的开源操作系统,因此与其他基于Linux的系统共享很多相似的命令。以下是一些在CentOS上常用的命令 件和目录操作: ls: 列出目录内容。cd: 切换目录。pwd: 显示当前工作目录。mkdir: 创建目录…...
数据结构-二叉树(1)
1.树概念及结构 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。 1.有一个特殊的结点&…...
SpringBoot——国际化
优质博文:IT-BLOG-CN 一、Spring 编写国际化时的步骤 【1】编写国际化配置文件; 【2】使用ResourceBundleMessageSource管理国际化资源文件; 【3】在页面使用ftp:message取出国际化内容; 二、SpringBoot编写国际化步骤 【1】创…...
shell 条件语句 if case
目录 测试 test测试文件的表达式 是否成立 格式 选项 比较整数数值 格式 选项 字符串比较 常用的测试操作符 格式 逻辑测试 格式 且 (全真才为真) 或 (一真即为真) 常见条件 双中括号 [[ expression ]] 用法 &…...
C语言:写一个函数,实现3*3矩阵的转置(指针)
分析: 在主函数 main 中,定义一个 3x3 的整型数组 a,并定义一个指向整型数组的指针 p。然后通过循环结构和 scanf 函数,从标准输入中读取用户输入的 3x3 矩阵的值,并存储到数组 a 中。 接下来,调用 mov…...

STL pair源码分析
STL pair源码分析 pair是STL中提供的一个简单的struct,用来处理类型不同的一对值,是非常常用的数据结构。这一对值是以public的形式暴露出来的,直接通过first和second就能访问。我们以MSVC提供的STL源码为例,分析pair的具体实现。…...

【开源】基于Vue和SpringBoot的农家乐订餐系统
项目编号: S 043 ,文末获取源码。 \color{red}{项目编号:S043,文末获取源码。} 项目编号:S043,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 用户2.2 管理员 三、系统展示四、核…...

MyBatis 操作数据库(入门)
一:MyBatis概念 (1)MyBatis 💗MyBatis是一款优秀的持久层框架,用于简化JDBC的开发 (2)持久层 1.持久层 💜持久层:持久化操作的层,通常指数据访问层(dao),是用来操作数据库的 2.持久层的规范 ①…...

JVM——垃圾回收器(G1,JDK9默认为G1垃圾回收器)
1.G1垃圾回收器 JDK9之后默认的垃圾回收器是G1(Garbage First)垃圾回收器。 Parallel Scavenge关注吞吐量,允许用户设置最大暂停时间 ,但是会减少年轻代可用空间的大小。 CMS关注暂停时间,但是吞吐量方面会下降。 而G1…...

多模态——使用stable-video-diffusion将图片生成视频
多模态——使用stable-video-diffusion将图片生成视频 0. 内容简介1. 运行环境2. 模型下载3. 代码梳理3.1 修改yaml文件中的svd路径3.2 修改DeepFloyDataFiltering的vit路径3.3 修改open_clip的clip路径3.4 代码总体结构 4. 资源消耗5. 效果预览 0. 内容简介 近期,…...
)
springboot(ssm网络相册 在线相册管理系统Java(codeLW)
springboot(ssm网络相册 在线相册管理系统Java(code&LW) 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0)…...

邮箱发送短信的多种方式
第一种:邮箱验证方法: 导入依赖: <!-- mail依赖(发送短信的依赖) --><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-mail</artifactId> &l…...
)
R语言——taxize(第五部分)
taxize(第五部分) 3. taxize 文档中译3.71. nbn_synonyms(从 NBN 返回具有给定 id 的分类群名称的所有同义词)3.72. ncbi_children(在 NCBI 中搜索类群的子类群)3.73. ncbi_downstream(检索 NCB…...

负载均衡lvs
简介 ipvsadm 是 Linux 内核中的 IP 虚拟服务器(IPVS)管理工具。IPVS是 Linux 内核提供的一种负载均衡解决方案,它允许将入站的网络流量分发到多个后端服务器,以实现负载均衡和高可用性。IPVS通过在内核中维护一个虚拟服务器表&a…...

【腾讯云云上实验室】探索向量数据库背后的安全监控机制
当今数字化时代,数据安全成为了企业和个人最为关注的重要议题之一。随着数据规模的不断增长和数据应用的广泛普及,如何保护数据的安全性和隐私性成为了迫切的需求。 今天,我将带领大家一起探索腾讯云云上实验室所推出的向量数据库,…...
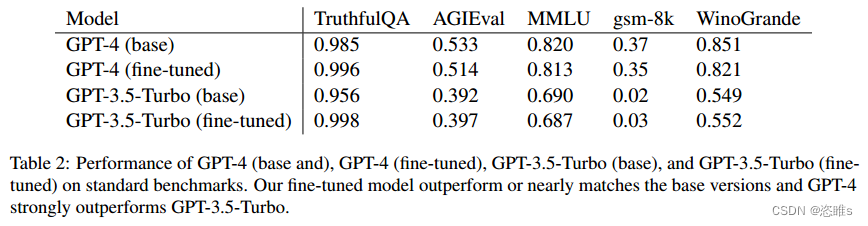
阅读笔记——《Removing RLHF Protections in GPT-4 via Fine-Tuning》
【参考文献】Zhan Q, Fang R, Bindu R, et al. Removing RLHF Protections in GPT-4 via Fine-Tuning[J]. arXiv preprint arXiv:2311.05553, 2023.【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。 目录 摘要 一、介绍 二、背景 三、方法…...

electron实现截图的功能
Electron是一种跨平台的桌面应用程序开发框架,可以使用HTML、CSS和JavaScript等Web技术构建桌面应用程序。下面是一种使用Electron实现截图的简单方法: 安装Electron和截图库 首先,需要安装Electron和一个截图库,例如electron-sc…...
)
人工智能如何悄然重塑我们的日常生活(从身边小事谈起)
1. 早晨被AI温柔唤醒的每一天 清晨6:30,我的卧室窗帘自动缓缓拉开到45度角,这个精确的角度是AI根据季节和天气预报计算出的最佳采光位置。床头的小爱同学用比上周低沉3%的嗓音说:"今天空气质量优,建议步行上班。"这个细…...

音频频谱分析师的成长之路:Spek实战秘籍深度解锁
音频频谱分析师的成长之路:Spek实战秘籍深度解锁 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 你是否曾好奇专业音频工程师如何"看见"声音?当音乐制作人谈论"频率冲突&qu…...

我是木质拼装玩具的源头工厂,今天揭秘为什么大牌卖那么贵
大家好,我是达克熊玩具的负责人,也是安徽六安鑫龙木业的老板。做胶合板这一行,十几年了。这十几年里,我给无数品牌供过板材,看着一块块木板变成精美的拼装玩具,贴上大牌logo,价格翻几倍。今天不…...

Ostrakon-VL-8B完整指南:支持中文/英文双语输入的零售多模态问答实践
Ostrakon-VL-8B完整指南:支持中文/英文双语输入的零售多模态问答实践 1. 引言:当AI走进零售店,它能看懂什么? 想象一下,你是一家连锁超市的运营经理。每天,你需要检查数百张货架照片,看看商品…...

从‘听不清’到‘听得准’:深入FunASR的VAD模型,教你调参优化语音识别在嘈杂环境下的表现
从‘听不清’到‘听得准’:深入FunASR的VAD模型,教你调参优化语音识别在嘈杂环境下的表现 在工业巡检的轰鸣声中,工程师的语音指令频繁被机器噪音淹没;车载语音助手总在高速风噪下错误触发;户外采访录音里的对话被风声…...

个人开发者如何用隧道代理实现“代理自由”?
那个被反爬逼疯的周末去年有个周末,我窝在家里写一个比价脚本。想爬几个主流电商平台的价格数据,做个小工具自己用。代码写得挺顺,Requests库套上代理,循环跑起来。前50次请求一切正常,第51次——啪,403。换…...

MKVToolNix Batch Tool:高效处理视频字幕的批量解决方案
MKVToolNix Batch Tool:高效处理视频字幕的批量解决方案 【免费下载链接】mkvtoolnix-batch-tool Batch video and subtitle processing program with the ability to add, remove, or extract subtitles from all video files in a directory and its sub-director…...

ai辅助环境配置:让快马平台的kimi帮你智能编写jdk17安装脚本与验证程序
今天在配置JDK17开发环境时,发现手动设置环境变量和验证流程有点繁琐,于是尝试用InsCode(快马)平台的AI辅助功能来简化整个过程。这里记录下具体操作和心得,分享给同样需要配置Java环境的小伙伴们。 环境变量冲突检测 首先让AI帮我分析现有…...

3个简单步骤:让Windows 11完美运行经典老游戏的终极DDrawCompat方案
3个简单步骤:让Windows 11完美运行经典老游戏的终极DDrawCompat方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirr…...

实战指南:基于快马平台生成trea国际版本地化价格展示组件代码
最近在开发一个国际电商项目时,遇到了一个很实际的需求:需要根据不同地区用户展示本地化格式的商品价格。这个看似简单的功能,其实涉及到货币转换、数字格式化、符号位置等多个细节。经过一番摸索,我总结出了一套比较完整的实现方…...