软著项目推荐 深度学习中文汉字识别
文章目录
- 0 前言
- 1 数据集合
- 2 网络构建
- 3 模型训练
- 4 模型性能评估
- 5 文字预测
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习中文汉字识别
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 数据集合
学长手有3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建。
用深度学习做文字识别,用的网络当然是CNN,那具体使用哪个经典网络?VGG?RESNET?还是其他?我想了下,越深的网络训练得到的模型应该会更好,但是想到训练的难度以及以后线上部署时预测的速度,我觉得首先建立一个比较浅的网络(基于LeNet的改进)做基本的文字识别,然后再根据项目需求,再尝试其他的网络结构。这次任务所使用的深度学习框架是强大的Tensorflow。
2 网络构建
第一步当然是搭建网络和计算图
其实文字识别就是一个多分类任务,比如这个3755文字识别就是3755个类别的分类任务。我们定义的网络非常简单,基本就是LeNet的改进版,值得注意的是我们加入了batch
normalization。另外我们的损失函数选择sparse_softmax_cross_entropy_with_logits,优化器选择了Adam,学习率设为0.1
#network: conv2d->max_pool2d->conv2d->max_pool2d->conv2d->max_pool2d->conv2d->conv2d->max_pool2d->fully_connected->fully_connecteddef build_graph(top_k):keep_prob = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob')images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1], name='image_batch')labels = tf.placeholder(dtype=tf.int64, shape=[None], name='label_batch')is_training = tf.placeholder(dtype=tf.bool, shape=[], name='train_flag')with tf.device('/gpu:5'):#给slim.conv2d和slim.fully_connected准备了默认参数:batch_normwith slim.arg_scope([slim.conv2d, slim.fully_connected],normalizer_fn=slim.batch_norm,normalizer_params={'is_training': is_training}):conv3_1 = slim.conv2d(images, 64, [3, 3], 1, padding='SAME', scope='conv3_1')max_pool_1 = slim.max_pool2d(conv3_1, [2, 2], [2, 2], padding='SAME', scope='pool1')conv3_2 = slim.conv2d(max_pool_1, 128, [3, 3], padding='SAME', scope='conv3_2')max_pool_2 = slim.max_pool2d(conv3_2, [2, 2], [2, 2], padding='SAME', scope='pool2')conv3_3 = slim.conv2d(max_pool_2, 256, [3, 3], padding='SAME', scope='conv3_3')max_pool_3 = slim.max_pool2d(conv3_3, [2, 2], [2, 2], padding='SAME', scope='pool3')conv3_4 = slim.conv2d(max_pool_3, 512, [3, 3], padding='SAME', scope='conv3_4')conv3_5 = slim.conv2d(conv3_4, 512, [3, 3], padding='SAME', scope='conv3_5')max_pool_4 = slim.max_pool2d(conv3_5, [2, 2], [2, 2], padding='SAME', scope='pool4')flatten = slim.flatten(max_pool_4)fc1 = slim.fully_connected(slim.dropout(flatten, keep_prob), 1024,activation_fn=tf.nn.relu, scope='fc1')logits = slim.fully_connected(slim.dropout(fc1, keep_prob), FLAGS.charset_size, activation_fn=None,scope='fc2')# 因为我们没有做热编码,所以使用sparse_softmax_cross_entropy_with_logitsloss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels))accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), labels), tf.float32))update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)if update_ops:updates = tf.group(*update_ops)loss = control_flow_ops.with_dependencies([updates], loss)global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)optimizer = tf.train.AdamOptimizer(learning_rate=0.1)train_op = slim.learning.create_train_op(loss, optimizer, global_step=global_step)probabilities = tf.nn.softmax(logits)# 绘制loss accuracy曲线tf.summary.scalar('loss', loss)tf.summary.scalar('accuracy', accuracy)merged_summary_op = tf.summary.merge_all()# 返回top k 个预测结果及其概率;返回top K accuracypredicted_val_top_k, predicted_index_top_k = tf.nn.top_k(probabilities, k=top_k)accuracy_in_top_k = tf.reduce_mean(tf.cast(tf.nn.in_top_k(probabilities, labels, top_k), tf.float32))return {'images': images,'labels': labels,'keep_prob': keep_prob,'top_k': top_k,'global_step': global_step,'train_op': train_op,'loss': loss,'is_training': is_training,'accuracy': accuracy,'accuracy_top_k': accuracy_in_top_k,'merged_summary_op': merged_summary_op,'predicted_distribution': probabilities,'predicted_index_top_k': predicted_index_top_k,'predicted_val_top_k': predicted_val_top_k}3 模型训练
训练之前我们应设计好数据怎么样才能高效地喂给网络训练。
首先,我们先创建数据流图,这个数据流图由一些流水线的阶段组成,阶段间用队列连接在一起。第一阶段将生成文件名,我们读取这些文件名并且把他们排到文件名队列中。第二阶段从文件中读取数据(使用Reader),产生样本,而且把样本放在一个样本队列中。根据你的设置,实际上也可以拷贝第二阶段的样本,使得他们相互独立,这样就可以从多个文件中并行读取。在第二阶段的最后是一个排队操作,就是入队到队列中去,在下一阶段出队。因为我们是要开始运行这些入队操作的线程,所以我们的训练循环会使得样本队列中的样本不断地出队。
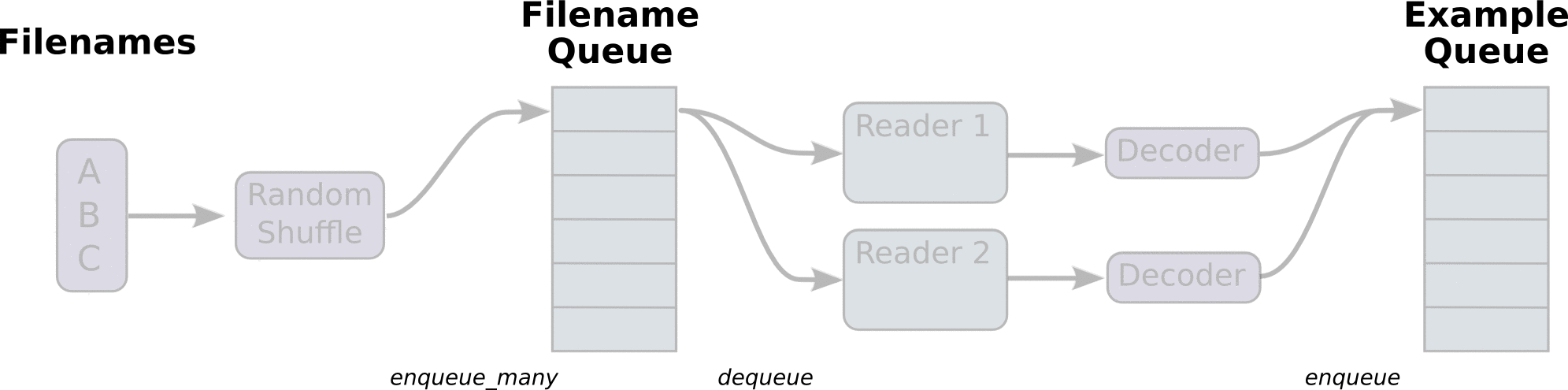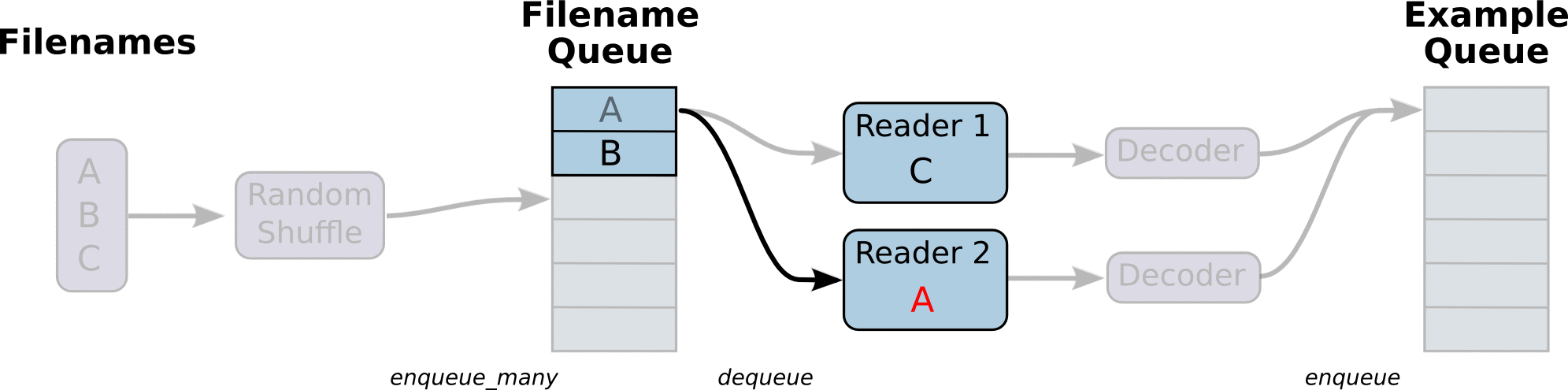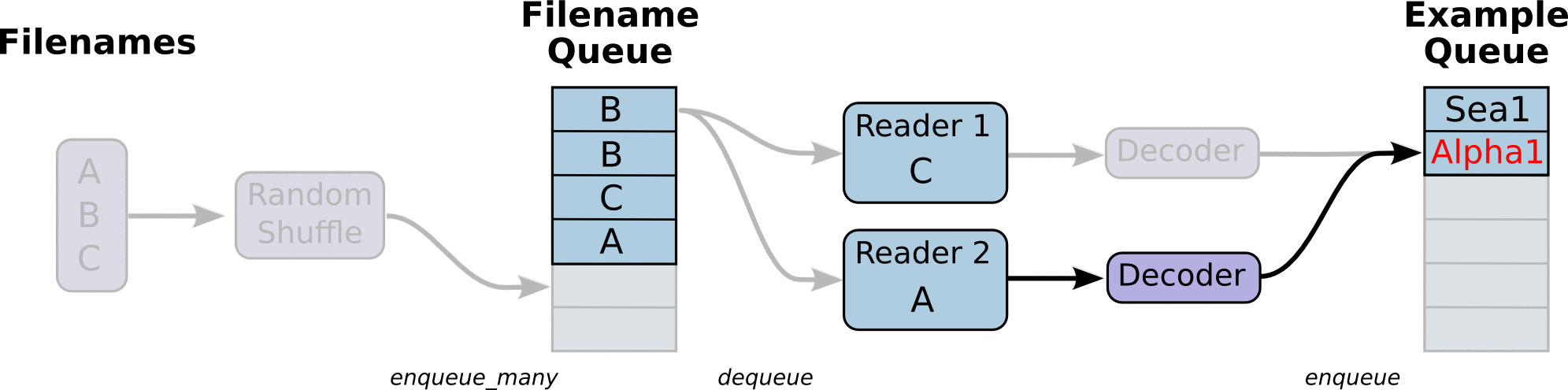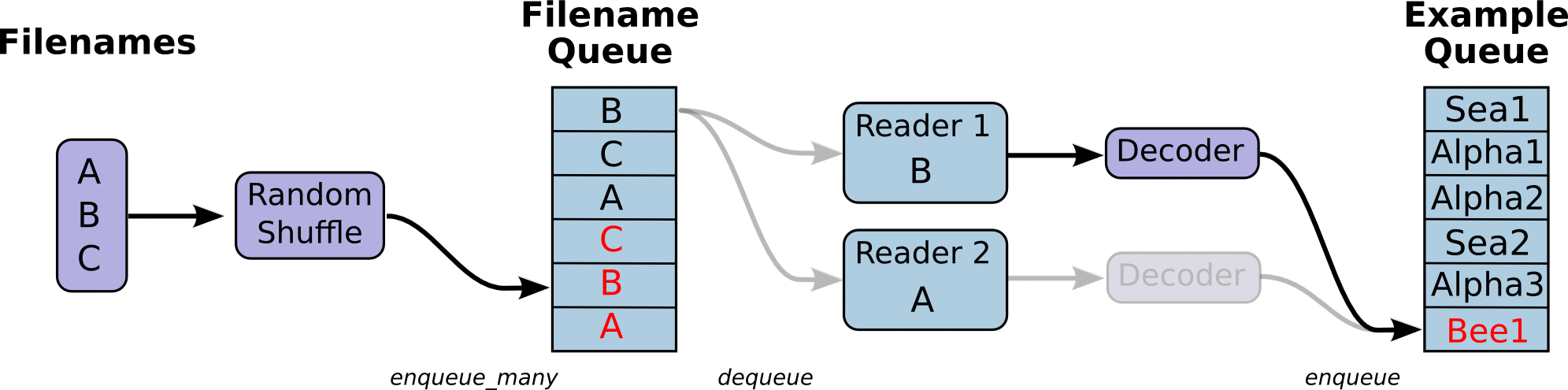
入队操作都在主线程中进行,Session中可以多个线程一起运行。 在数据输入的应用场景中,入队操作是从硬盘中读取输入,放到内存当中,速度较慢。
使用QueueRunner可以创建一系列新的线程进行入队操作,让主线程继续使用数据。如果在训练神经网络的场景中,就是训练网络和读取数据是异步的,主线程在训练网络,另一个线程在将数据从硬盘读入内存。
# batch的生成
def input_pipeline(self, batch_size, num_epochs=None, aug=False):# numpy array 转 tensorimages_tensor = tf.convert_to_tensor(self.image_names, dtype=tf.string)labels_tensor = tf.convert_to_tensor(self.labels, dtype=tf.int64)# 将image_list ,label_list做一个slice处理input_queue = tf.train.slice_input_producer([images_tensor, labels_tensor], num_epochs=num_epochs)labels = input_queue[1]images_content = tf.read_file(input_queue[0])images = tf.image.convert_image_dtype(tf.image.decode_png(images_content, channels=1), tf.float32)if aug:images = self.data_augmentation(images)new_size = tf.constant([FLAGS.image_size, FLAGS.image_size], dtype=tf.int32)images = tf.image.resize_images(images, new_size)image_batch, label_batch = tf.train.shuffle_batch([images, labels], batch_size=batch_size, capacity=50000,min_after_dequeue=10000)# print 'image_batch', image_batch.get_shape()return image_batch, label_batch
训练时数据读取的模式如上面所述,那训练代码则根据该架构设计如下:
def train():print('Begin training')# 填好数据读取的路径train_feeder = DataIterator(data_dir='./dataset/train/')test_feeder = DataIterator(data_dir='./dataset/test/')model_name = 'chinese-rec-model'with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, allow_soft_placement=True)) as sess:# batch data 获取train_images, train_labels = train_feeder.input_pipeline(batch_size=FLAGS.batch_size, aug=True)test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size)graph = build_graph(top_k=1) # 训练时top k = 1saver = tf.train.Saver()sess.run(tf.global_variables_initializer())# 设置多线程协调器coord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph)test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/val')start_step = 0# 可以从某个step下的模型继续训练if FLAGS.restore:ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt:saver.restore(sess, ckpt)print("restore from the checkpoint {0}".format(ckpt))start_step += int(ckpt.split('-')[-1])logger.info(':::Training Start:::')try:i = 0while not coord.should_stop():i += 1start_time = time.time()train_images_batch, train_labels_batch = sess.run([train_images, train_labels])feed_dict = {graph['images']: train_images_batch,graph['labels']: train_labels_batch,graph['keep_prob']: 0.8,graph['is_training']: True}_, loss_val, train_summary, step = sess.run([graph['train_op'], graph['loss'], graph['merged_summary_op'], graph['global_step']],feed_dict=feed_dict)train_writer.add_summary(train_summary, step)end_time = time.time()logger.info("the step {0} takes {1} loss {2}".format(step, end_time - start_time, loss_val))if step > FLAGS.max_steps:breakif step % FLAGS.eval_steps == 1:test_images_batch, test_labels_batch = sess.run([test_images, test_labels])feed_dict = {graph['images']: test_images_batch,graph['labels']: test_labels_batch,graph['keep_prob']: 1.0,graph['is_training']: False}accuracy_test, test_summary = sess.run([graph['accuracy'], graph['merged_summary_op']],feed_dict=feed_dict)if step > 300:test_writer.add_summary(test_summary, step)logger.info('===============Eval a batch=======================')logger.info('the step {0} test accuracy: {1}'.format(step, accuracy_test))logger.info('===============Eval a batch=======================')if step % FLAGS.save_steps == 1:logger.info('Save the ckpt of {0}'.format(step))saver.save(sess, os.path.join(FLAGS.checkpoint_dir, model_name),global_step=graph['global_step'])except tf.errors.OutOfRangeError:logger.info('==================Train Finished================')saver.save(sess, os.path.join(FLAGS.checkpoint_dir, model_name), global_step=graph['global_step'])finally:# 达到最大训练迭代数的时候清理关闭线程coord.request_stop()coord.join(threads)
执行以下指令进行模型训练。因为我使用的是TITAN
X,所以感觉训练时间不长,大概1个小时可以训练完毕。训练过程的loss和accuracy变换曲线如下图所示
然后执行指令,设置最大迭代步数为16002,每100步进行一次验证,每500步存储一次模型。
python Chinese_OCR.py --mode=train --max_steps=16002 --eval_steps=100 --save_steps=500

4 模型性能评估
我们的需要对模模型进行评估,我们需要计算模型的top 1 和top 5的准确率。
执行指令
python Chinese_OCR.py --mode=validation

def validation():print('Begin validation')test_feeder = DataIterator(data_dir='./dataset/test/')final_predict_val = []final_predict_index = []groundtruth = []with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,allow_soft_placement=True)) as sess:test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size, num_epochs=1)graph = build_graph(top_k=5)saver = tf.train.Saver()sess.run(tf.global_variables_initializer())sess.run(tf.local_variables_initializer()) # initialize test_feeder's inside statecoord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt:saver.restore(sess, ckpt)print("restore from the checkpoint {0}".format(ckpt))logger.info(':::Start validation:::')try:i = 0acc_top_1, acc_top_k = 0.0, 0.0while not coord.should_stop():i += 1start_time = time.time()test_images_batch, test_labels_batch = sess.run([test_images, test_labels])feed_dict = {graph['images']: test_images_batch,graph['labels']: test_labels_batch,graph['keep_prob']: 1.0,graph['is_training']: False}batch_labels, probs, indices, acc_1, acc_k = sess.run([graph['labels'],graph['predicted_val_top_k'],graph['predicted_index_top_k'],graph['accuracy'],graph['accuracy_top_k']], feed_dict=feed_dict)final_predict_val += probs.tolist()final_predict_index += indices.tolist()groundtruth += batch_labels.tolist()acc_top_1 += acc_1acc_top_k += acc_kend_time = time.time()logger.info("the batch {0} takes {1} seconds, accuracy = {2}(top_1) {3}(top_k)".format(i, end_time - start_time, acc_1, acc_k))except tf.errors.OutOfRangeError:logger.info('==================Validation Finished================')acc_top_1 = acc_top_1 * FLAGS.batch_size / test_feeder.sizeacc_top_k = acc_top_k * FLAGS.batch_size / test_feeder.sizelogger.info('top 1 accuracy {0} top k accuracy {1}'.format(acc_top_1, acc_top_k))finally:coord.request_stop()coord.join(threads)return {'prob': final_predict_val, 'indices': final_predict_index, 'groundtruth': groundtruth}
5 文字预测
刚刚做的那一步只是使用了我们生成的数据集作为测试集来检验模型性能,这种检验是不大准确的,因为我们日常需要识别的文字样本不会像是自己合成的文字那样的稳定和规则。那我们尝试使用该模型对一些实际场景的文字进行识别,真正考察模型的泛化能力。
首先先编写好预测的代码
def inference(name_list):print('inference')image_set=[]# 对每张图进行尺寸标准化和归一化for image in name_list:temp_image = Image.open(image).convert('L')temp_image = temp_image.resize((FLAGS.image_size, FLAGS.image_size), Image.ANTIALIAS)temp_image = np.asarray(temp_image) / 255.0temp_image = temp_image.reshape([-1, 64, 64, 1])image_set.append(temp_image)# allow_soft_placement 如果你指定的设备不存在,允许TF自动分配设备with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,allow_soft_placement=True)) as sess:logger.info('========start inference============')# images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1])# Pass a shadow label 0. This label will not affect the computation graph.graph = build_graph(top_k=3)saver = tf.train.Saver()# 自动获取最后一次保存的模型ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt: saver.restore(sess, ckpt)val_list=[]idx_list=[]# 预测每一张图for item in image_set:temp_image = itempredict_val, predict_index = sess.run([graph['predicted_val_top_k'], graph['predicted_index_top_k']],feed_dict={graph['images']: temp_image,graph['keep_prob']: 1.0,graph['is_training']: False})val_list.append(predict_val)idx_list.append(predict_index)#return predict_val, predict_indexreturn val_list,idx_list
这里需要说明一下,我会把我要识别的文字图像存入一个叫做tmp的文件夹内,里面的图像按照顺序依次编号,我们识别时就从该目录下读取所有图片仅内存进行逐一识别。
# 获待预测图像文件夹内的图像名字
def get_file_list(path):list_name=[]files = os.listdir(path)files.sort()for file in files:file_path = os.path.join(path, file)list_name.append(file_path)return list_name
那我们使用训练好的模型进行汉字预测,观察效果。首先我从一篇论文pdf上用截图工具截取了一段文字,然后使用文字切割算法把文字段落切割为单字,如下图,因为有少量文字切割失败,所以丢弃了一些单字。
从一篇文章中用截图工具截取文字段落。

切割出来的单字,黑底白字。

最后将所有的识别文字按顺序组合成段落,可以看出,汉字识别完全正确,说明我们的基于深度学习的OCR系统还是相当给力!

至此,支持3755个汉字识别的OCR系统已经搭建完毕,经过测试,效果还是很不错。这是一个没有经过太多优化的模型,在模型评估上top
1的正确率达到了99.9%,这是一个相当优秀的效果了,所以说在一些比较理想的环境下的文字识别的效果还是比较给力,但是对于复杂场景的或是一些干扰比较大的文字图像,识别起来的效果可能不会太理想,这就需要针对特定场景做进一步优化。
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
软著项目推荐 深度学习中文汉字识别
文章目录 0 前言1 数据集合2 网络构建3 模型训练4 模型性能评估5 文字预测6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习中文汉字识别 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐…...
)
WEB渗透—反序列化(七)
Web渗透—反序列化 课程学习分享(课程非本人制作,仅提供学习分享) 靶场下载地址:GitHub - mcc0624/php_ser_Class: php反序列化靶场课程,基于课程制作的靶场 课程地址:PHP反序列化漏洞学习_哔哩哔_…...

牛客网刷题笔记四 链表节点k个一组翻转
NC50 链表中的节点每k个一组翻转 题目: 思路: 这种题目比较习惯现在草稿本涂涂画画链表处理过程。整体思路是赋值新的链表,用游离指针遍历原始链表进行翻转操作,当游离个数等于k时,就将翻转后的链表接到新的链表后&am…...
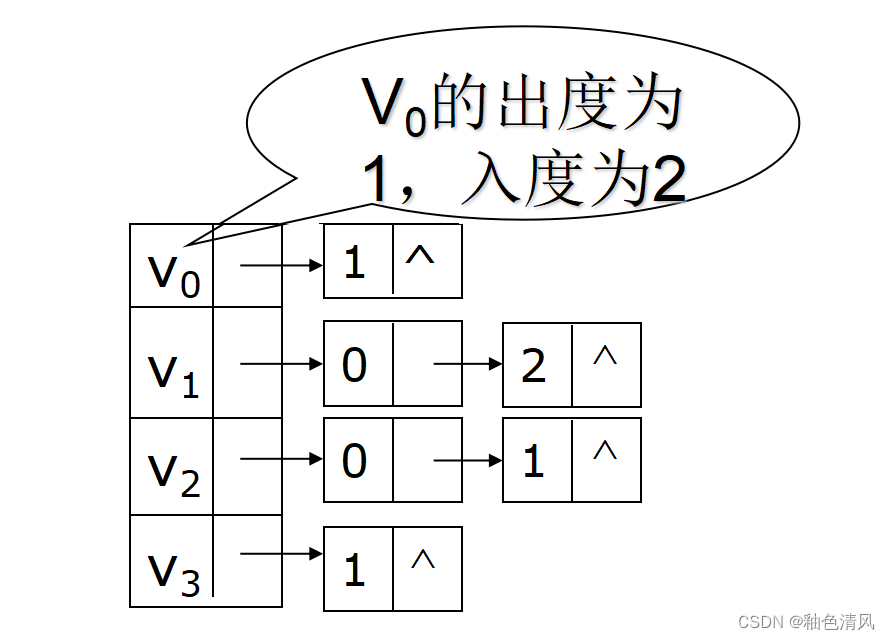
【数据结构】图<简单认识图>
对于下面的内容,大家着重观察和理解图即可,可以直接绕过一些文字性的概念,对图有一个大概的认识。 图 简单认识图图的定义有向图和无向图完全图无向完全图有向完全图 图的基本存储结构邻接矩阵存储邻接矩阵的优点 网络的邻接矩阵邻接表无向图…...

Git介绍和基础命令解析
Git基本操作指令 工作区和暂存区 Git管理的文件分为:工作区(本地的文件夹),版本库(.git文件夹),版本库又分为暂存区stage和暂存区分支master(仓库) 工作区>>>>暂存区>>>>仓库 git add把文件从工作区>>>…...
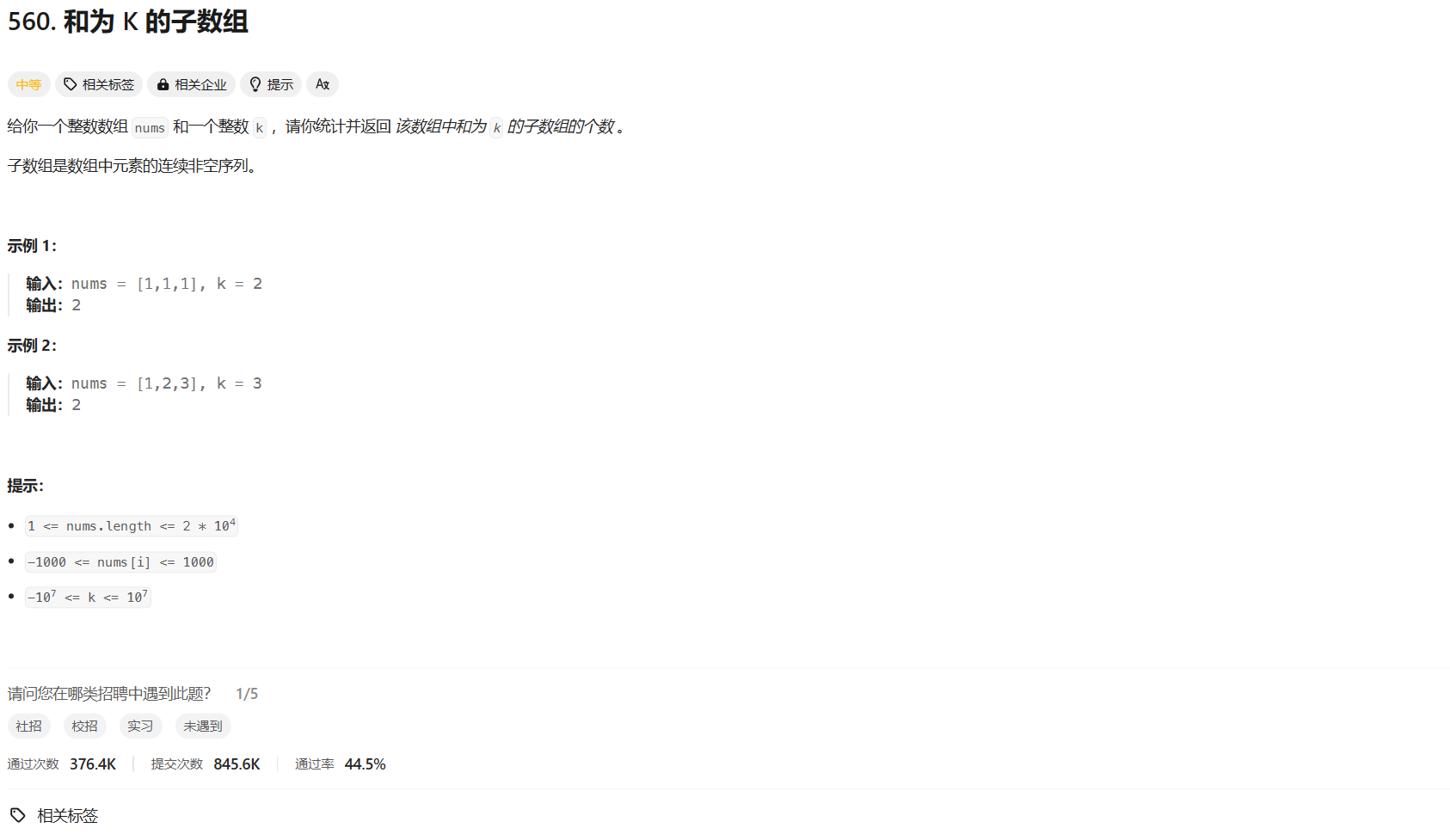
力扣hot100 和为 K 的子数组 前缀和
👨🏫 题目地址 🍻 AC code class Solution {public int subarraySum(int[] nums, int k){int ans 0;int n nums.length;int[] s new int[n 1];// 前缀和s[0] 0;s[1] nums[0];for (int i 2; i < n; i)s[i] s[i - 1] nums[i - 1…...
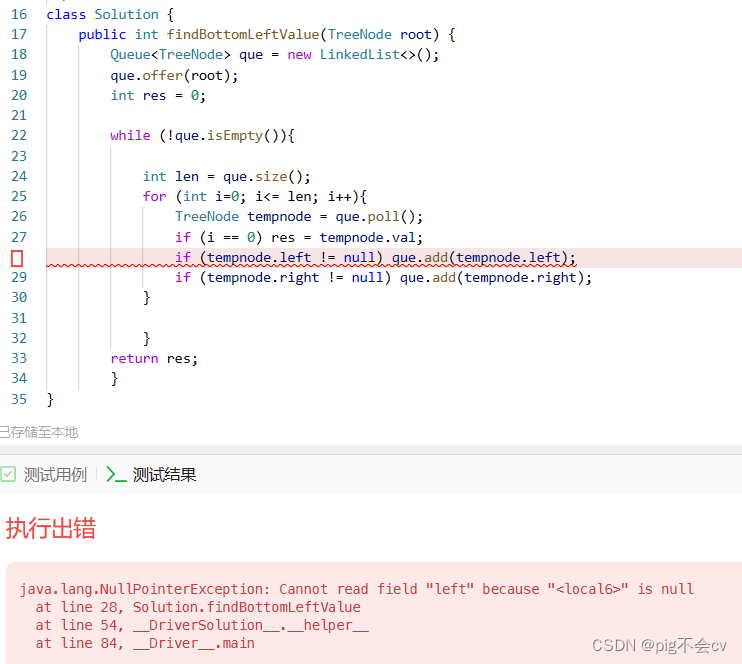
6.12找树左下角的值(LC513-M)
算法: 这道题适合用迭代法,层序遍历:按层遍历,每次把每层最左边的值保存、更新到result里面。 看看Java怎么实现层序遍历的(用队列): /*** Definition for a binary tree node.* public clas…...
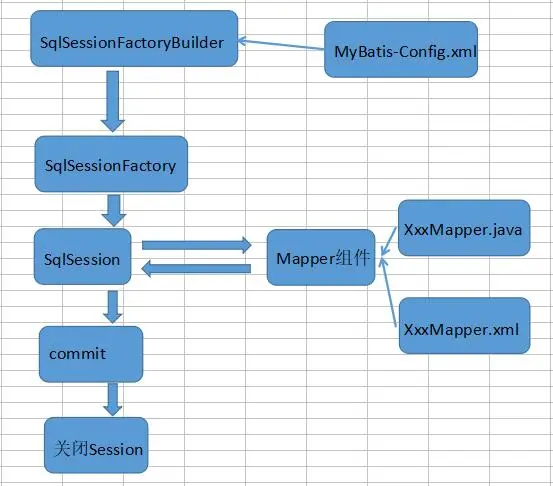
【精选】框架初探篇之——MyBatis的CRUD及配置文件
MyBatis增删改查 MyBatis新增 新增用户 持久层接口添加方法 void add(User user);映射文件添加标签 <insert id"add" parameterType"com.mybatis.pojo.User">insert into user(username,sex,address) values(# {username},# {sex},# {address}) <…...

ES8语法async与await
async和await两种语法结合可以让异步代码像同步代码一样。 一、async函数 async函数的返回值为Promise对象promise对象的结果由async函数执行的返回值决定 async function fn() {// 返回一个字符串return 字符串;// 返回的结果不是一个Promise类型的对象…...

c#处理SQLSERVER 中image数量类型为空
项目场景: DataRow dataRow dataTable.Rows[i]; var pxpicture dataRow ["pxImage"];if (pxpicture!null){byte[] pic (byte[])pxpicture;acs.Add("pxpicture", Convert.ToBase64String(pic));}问题描述 代码执行出现错误: 无…...

五子棋游戏
import pygame #导入pygame模块 pygame.init()#初始化 screen pygame.display.set_mode((750,750))#设置游戏屏幕大小 running True#建立一个事件 while running:#事件运行for event in pygame.event.get():if event.type pygame.QUIT:#当点击事件后退出running False #事…...
vue+SpringBoot的图片上传
前端VUE的代码实现 直接粘贴过来element-UI的组件实现 <el-uploadclass"avatar-uploader"action"/uploadAvatar" //这个action的值是服务端的路径,其他不用改:show-file-list"false":on-success"handleAvatarSuccess"…...
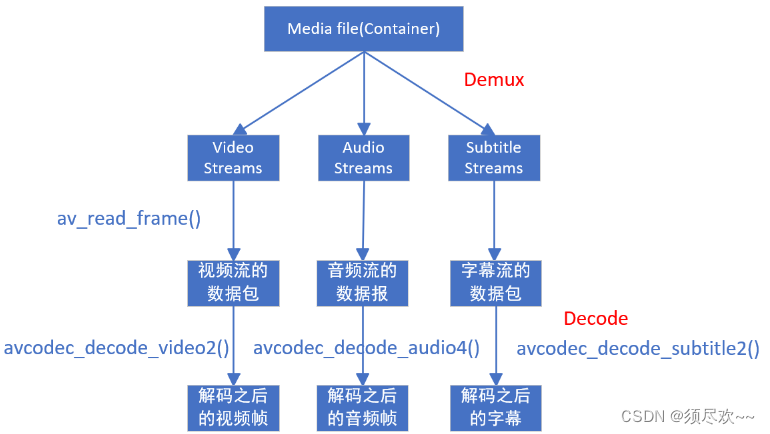
FFmepg 核心开发库及重要数据结构与API
文章目录 前言一、FFmpeg 核心开发库二、FFmpeg 重要数据结构与 API1、简介2、FFmpeg 解码流程①、FFmpeg2.x 解码流程②、FFmpeg4.x 解码流程 3、FFMpeg 中比较重要的函数以及数据结构①、数据结构②、初始化函数③、音视频解码函数④、文件操作⑤、其他函数 三、FFmpeg 流程1…...

训练 CNN 对 CIFAR-10 数据中的图像进行分类
1. 加载 CIFAR-10 数据库 import keras from keras.datasets import cifar10# 加载预先处理的训练数据和测试数据 (x_train, y_train), (x_test, y_test) cifar10.load_data() 2. 可视化前 24 个训练图像 import numpy as np import matplotlib.pyplot as plt %matplotlib …...

香港科技大学广州|智能制造学域博士招生宣讲会—天津大学专场
时间:2023年12月07日(星期四)15:30 地点:天津大学卫津路校区26楼B112 报名链接:https://www.wjx.top/vm/mmukLPC.aspx# 宣讲嘉宾: 汤凯教授 学域主任 https://facultyprofiles.hkust-gz.edu.cn/faculty-p…...
— 子数组中满足max -min <= sum的个数)
滑动窗口练习(二)— 子数组中满足max -min <= sum的个数
题目 给定一个整型数组arr,和一个整数num 某个arr中的子数组sub,如果想达标,必须满足: sub中最大值 – sub中最小值 < num, 返回arr中达标子数组的数量 暴力对数器 暴力对数器方法主要是用来和另一个方法互相校验正…...

用xlwings新建一个excel并同时生成多个sheet
新建一个excel并同时生成多个sheet,要实现如下效果: 一般要使用数据透视表来快速实现。 今天记录用xlwings新建一个excel并同时生成多个sheet。 import xlwings as xw # 打开excel,参数visible表示处理过程是否可视,add_book表示是否打开新的Excel程序…...

诺威信,浪潮云,微众区块链
目录 诺威信B隐私计算平台 浪潮云=星火连-澳优码 HyperChain 产品介绍 CA认证即电子认证服务...

Redux在React中的使用
Redux在React中的使用 1.构建方式 采用reduxjs/toolkitreact-redux的方式 安装方式 npm install reduxjs/toolkit react-redux2.使用 ①创建目录 创建store文件夹,然后创建index和对应的模块,如上图所示 ②编写counterStore.js 文章以counterStore…...
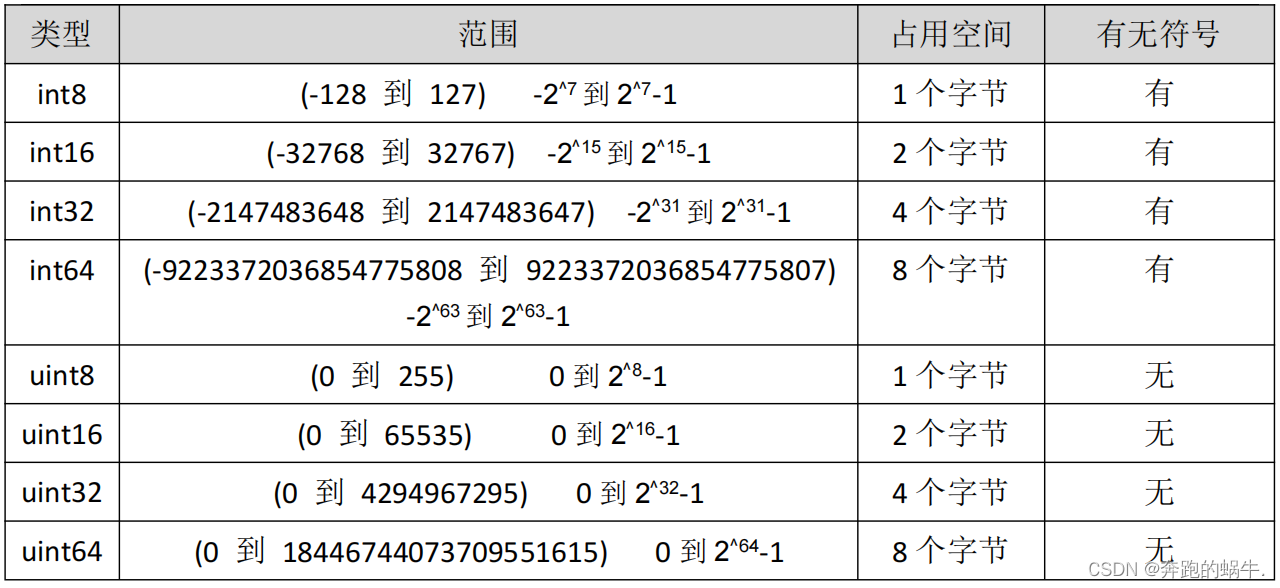
Go 数字类型
一、数字类型 1、Golang 数据类型介绍 Go 语言中数据类型分为:基本数据类型和复合数据类型基本数据类型有: 整型、浮点型、布尔型、字符串复合数据类型有: 数组、切片、结构体、函数、map、通道(channel)、接口 2、…...

OpenClaw语音转写方案:千问3.5-9B处理会议录音与摘要
OpenClaw语音转写方案:千问3.5-9B处理会议录音与摘要 1. 为什么需要本地化的语音处理方案 上个月我连续参加了三场跨时区技术会议,每次会后都要花两小时整理录音和纪要。尝试过主流语音转写工具后,发现两个痛点:一是敏感技术术语…...

如何提高网站在百度搜索引擎的排名_国内 SEO 优化需要注意哪些技巧
如何提高网站在百度搜索引擎的排名_国内 SEO 优化需要注意哪些技巧 在当今信息化时代,网站的流量直接关系到一个企业的品牌知名度和市场竞争力。对于许多企业来说,百度作为中国最主要的搜索引擎,其在用户搜索中的占比极高。因此,…...

单向链表的创建、插入、删除、遍历
文章目录单向链表:从创建到操作全解析 📝1. 单向链表的基本概念 🧠2. 实现单向链表 🛠️2.1 定义节点类2.2 创建链表3. 插入操作 ➕3.1 在头部插入3.2 在尾部插入3.3 在特定位置插入4. 删除操作 ❌4.1 删除头部节点4.2 删除特定值…...

008.S3C2440中断分析|千篇笔记实现嵌入式全栈/裸机篇
1. 流程 S3C2440中断流程如下, 发生中断时,[SUB]SRCPND源挂起寄存器对应的bit位会置位, 然后[SUB]MASK屏蔽寄存器对应的bit位会卡一下,决定中断流要不要继续, 也就是说不管中断有没有被屏蔽,源挂起寄存…...

FireRedASR-AED-L效果实测:微信语音转文字→长语音断句与上下文连贯性
FireRedASR-AED-L效果实测:微信语音转文字→长语音断句与上下文连贯性 你是不是也遇到过这种情况?微信里收到一段长达5分钟的语音消息,点开听吧,太费时间;不听吧,又怕错过重要信息。更让人头疼的是&#x…...

如何检查网页标题是否符合 SEO 要求
如何检查网页标题是否符合 SEO 要求 在当今互联网时代,搜索引擎优化(SEO)已经成为每一个网站成功的关键要素之一。其中,网页标题的优化尤为重要。一个好的网页标题不仅能吸引用户点击,还能提高搜索引擎的排名。如何检…...

测试、项目管理、软件度量和质量
欢迎来到我的软考中级——软件设计师备考合集。这里不只是一份简单的知识点堆砌,而是我在备考征途中,对庞杂知识体系进行深度梳理与内化的结晶。 面对浩瀚的考纲,从计算机组成原理的底层逻辑,到操作系统的进程调度;从数…...

《jEasyUI 格式化列》
《jEasyUI 格式化列》 引言 jEasyUI 是一款流行的开源jQuery UI库,旨在简化Web用户界面(UI)的开发。在jEasyUI中,格式化列是一种常见且强大的功能,它允许开发者根据需要自定义表格列的显示格式。本文将详细介绍jEasyUI…...

从 99.8% 到 14.9%!Paperxie 降 AIGC:本科生论文通关的「隐形 buff」
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AIPPThttps://www.paperxie.cn/weight?type1https://www.paperxie.cn/weight?type1 一、写在前面:被 AIGC 检测卡脖子的毕业季,你不是一个人在战斗 当毕业论文从「查重焦虑」升级…...
)
Verilog实战:手把手教你实现8B/10B编码与解码(附完整代码)
Verilog实战:从零构建8B/10B编解码器的工程化实现 在高速串行通信领域,数据完整性如同精密钟表的齿轮咬合——任何微小的时序偏差都可能导致整个系统崩溃。8B/10B编码技术正是解决这一痛点的关键钥匙,它通过精心设计的编码规则,确…...