kafka,RabbitMQ,RocketMQ,他们之间的区别,架构,如何保证消息的不丢失,保证不重复消费,保证消息的有序性
文章目录
- Kafka、RabbitMQ、RocketMQ 之间的区别是什么?
- 性能
- 数据可靠性
- 服务可用性
- 功能
- RabbitMQ如何保证消息不丢失?
- Kafka 的架构说一下?
- Kafka 怎么保证消息是有序的?
- Kafka 怎么解决重复消费?
- Kafka 怎么保证消息不丢失?
- RocketMQ 如何监听消息的?
- RocketMQ 常见的面试题
- 哪个环节会有消息丢失的可能?
- RocketMQ消息零丢失方案
- 1、生产者使用事务消息机制保证消息零丢失
- 2、**RocketMQ**配置同步刷盘+**Dledger**主从架构保证**MQ**自身不会丢消息
- 3、消费者端不要使用异步消费机制
- 4、RocketMQ特有的问题,NameServer挂了如何保证消息不丢失?
- 使用RocketMQ如何快速处理积压消息?
- 1、如何确定RocketMQ有大量的消息积压?
- 2、如何处理大量积压的消息?
- RocketMQ的消息轨迹
- RocketMQ 如何处理流量削峰
- 使用RocketMQ如何保证消息顺序
Kafka、RabbitMQ、RocketMQ 之间的区别是什么?
性能
消息中间件的性能主要衡量吞吐量,Kafka的吞吐量比RabbitMQ要高出1~2个数量级,RabbitMQ的单机QPS在万级别,Kafka的单机QPS能够达到百万级别。RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节,Kafka如果开启幂等、事务等功能,性能也会有所降低。
数据可靠性
Kafka与RabbitMQ 都具备多副本机制,数据可靠性较高。RocketMQ支持异步实时刷盘,同步刷盘,同步Replication(拷贝),异步Replication,数据可靠性高。
服务可用性
Kafka采用集群部署,分区与多副本的设计,使得单节点宕机对服务无影响,并且支持消息容量的线性提升。RabbitMQ支持集群部署,集群节点数量有多种规格。RocketMQ是分布式架构,可用性高。
功能
Kafka与RabbitMQ都是比较主流的两款消息中间件,具备消息传递的基本功能,但在一些特殊的功能方面存在差异,RocketMQ在阿里集团内部有大量的应用在使用。
RabbitMQ如何保证消息不丢失?

Kafka 的架构说一下?
整个架构中包括三个角色:
⚫ 生产者(Producer):消息和数据生产者。
⚫ 代理(Broker):缓存代理,Kafka的核心功能。
⚫ 消费者(Consumer):消息和数据消费者。
Kafka给Producer和Consumer提供注册的接口,数据从Producer发送到Broker,Broker承担一个中间缓存和分发的作用,负责分发注册到系统中的Consumer。
Kafka 怎么保证消息是有序的?
消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。Kafka 通过偏移量(offset)来保证消息在分区内的有序性。发送消息的时候指定key/Partition。
Kafka 怎么解决重复消费?
⚫ 生产者发送每条数据的时候,里面加一个全局唯一的id,消费到了之后,先根据这个id去比对Redis里查一下,之前是否消费过,如果没有消费过,就处理,然后把这个id写入到Redis中。如果消费过就别处理了。
⚫ 基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。
Kafka 怎么保证消息不丢失?
生产者丢失消息的情况
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。 为了确定消息是发送成功,我们要判断消息发送的结果,Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果,但是这样也让它变为了同步操作,可以采用为其添加回调函数的形式,示例代码如下:
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
future.addCallback(result -> logger.info(“生产者成功发送消息到topic:{} partition:{}的消息”, result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
ex -> logger.error(“生产者发送消失败,原因:{}”, ex.getMessage())); Producer 的retries(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你3次一下子就重试完了
消费者丢失消息的情况
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
Kafka 弄丢了消息
试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。
当我们配置了 unclean.leader.election.enable = false 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
RocketMQ 如何监听消息的?
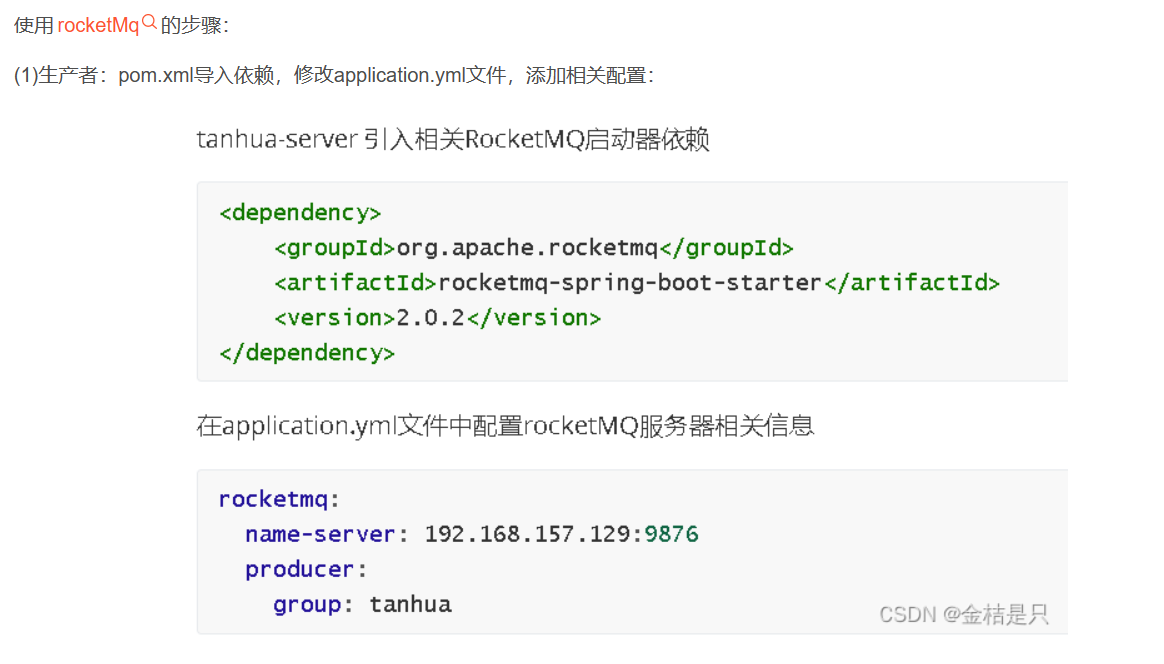

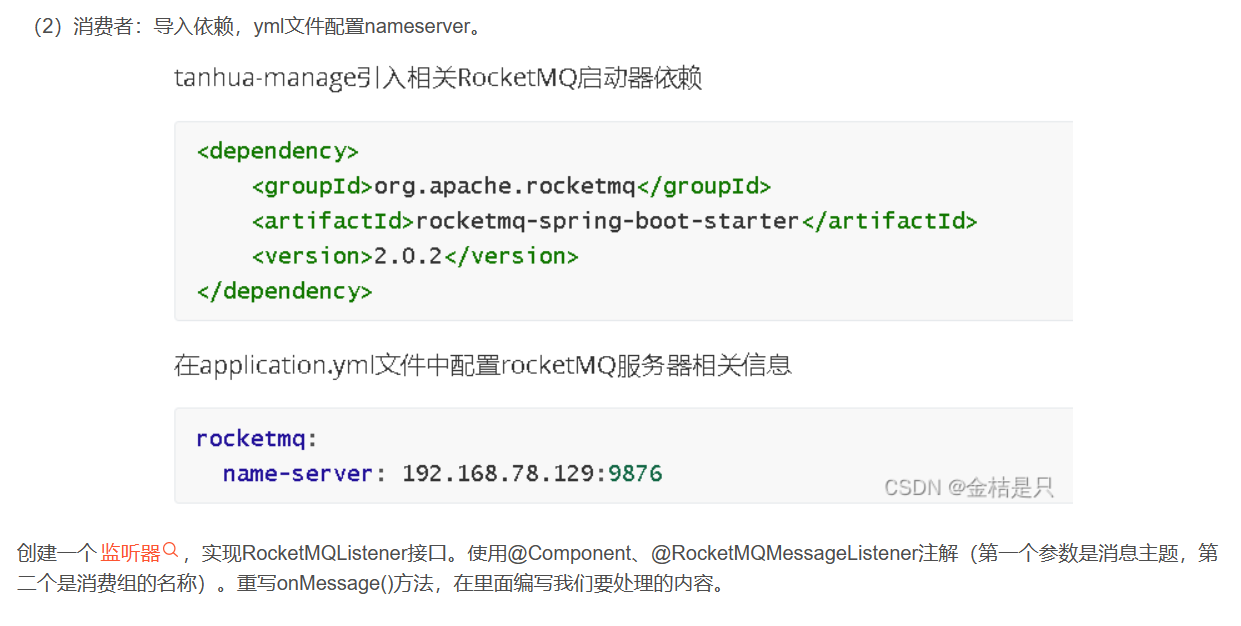

RocketMQ 常见的面试题
链接1: (20条消息) RocketMQ 常见面试问题_rocketmq面试题_柚子茶1990的博客-CSDN博客 主要是保证消息的不丢失。
哪个环节会有消息丢失的可能?
我们考虑一个通用的MQ场景:
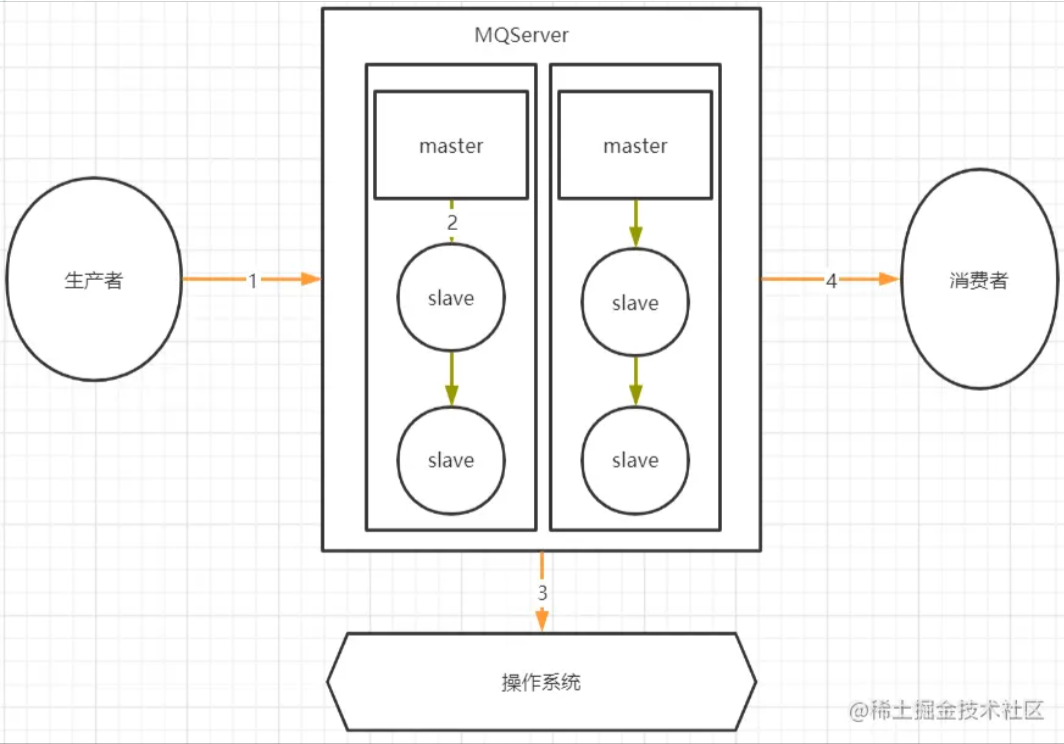
其中,1,2,4三个场景都是跨网络的,而跨网络就肯定会有丢消息的可能。 然后关于3这个环节,通常MQ存盘时都会先写入操作系统的缓存page cache中,然后再由操作系统异步的将消息写入硬盘。这个中间有个时间差,就可能会造成消息丢失。如果服务挂了,缓存中还没有来得及写入硬盘的消息就会丢失。 这个是MQ场景都会面对的通用的丢消息问题。那我们看看用Rocket时要如何解决这个问题
RocketMQ消息零丢失方案
1、生产者使用事务消息机制保证消息零丢失
这个结论比较容易理解,因为RocketMQ的事务消息机制就是为了保证零丢失来设计的,并且经过阿里的验证,肯定是非常靠谱的。 但是如果深入一点的话,我们还是要理解下这个事务消息到底是不是靠谱。我们以最常见的电商订单场景为例,来简单分析下事务消息机制如何保证消息不丢失。我们看下下面这个流程图:
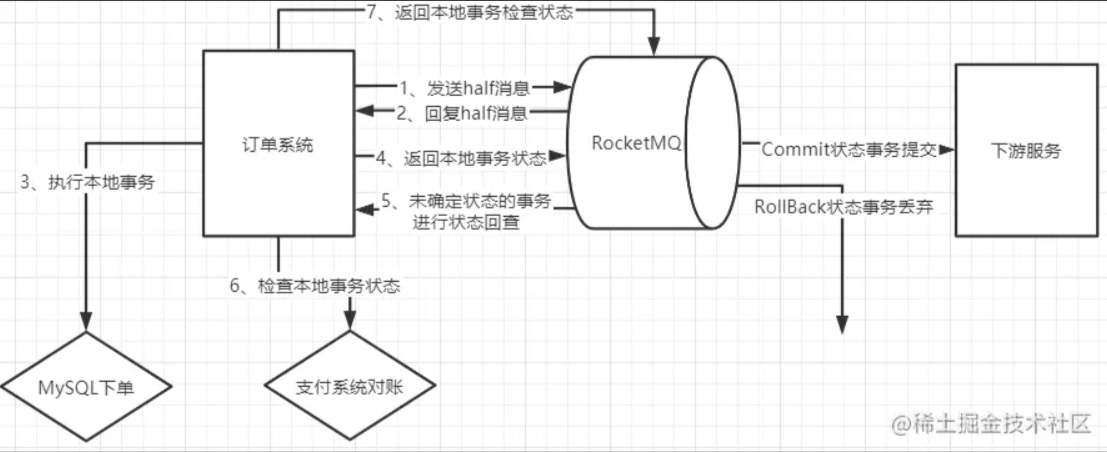
(1)、为什么要发送个half消息?有什么用?
这个half消息是在订单系统进行下单操作前发送,并且对下游服务的消费者是不可见的。那这个消息的作用更多的体现在确认RocketMQ的服务是否正常。相当于嗅探下RocketMQ服务是否正常,并且通知RocketMQ,我马上就要发一个很重要的消息了,你做好准备。
(2).half消息如果写入失败了怎么办?
如果没有half消息这个流程,那我们通常是会在订单系统中先完成下单,再发送消息给MQ。这时候写入消息到MQ如果失败就会非常尴尬了。而half消息如果写入失败,我们就可以认为MQ的服务是有问题的,这时,就不能通知下游服务了。我们可以在下单时给订单一个状态标记,然后等待MQ服务正常后再进行补偿操作,等MQ服务正常后重新下单通知下游服务。
(3).订单系统写数据库失败了怎么办? 这个问题我们同样比较下没有使用事务消息机制时会怎么办?如果没有使用事务消息,我们只能判断下单失败,抛出了异常,那就不往MQ发消息了,这样至少保证不会对下游服务进行错误的通知。但是这样的话,如果过一段时间数据库恢复过来了,这个消息就无法再次发送了。当然,也可以设计另外的补偿机制,例如将订单数据缓存起来,再启动一个线程定时尝试往数据库写。而如果使用事务消息机制,就可以有一种更优雅的方案。 如果下单时,写数据库失败(可能是数据库崩了,需要等一段时间才能恢复)。那我们可以另外找个地方把订单消息先缓存起来(Redis、文本或者其他方式),然后给RocketMQ返回一个UNKNOWN状态。这样RocketMQ就会过一段时间来回查事务状态。我们就可以在回查事务状态时再尝试把订单数据写入数据库,如果数据库这时候已经恢复了,那就能完整正常的下单,再继续后面的业务。这样这个订单的消息就不会因为数据库临时崩了而丢失。
(4).half消息写入成功后RocketMQ挂了怎么办?
我们需要注意下,在事务消息的处理机制中,未知状态的事务状态回查是由RocketMQ的Broker主动发起的。也就是说如果出现了这种情况,那RocketMQ就不会回调到事务消息中回查事务状态的服务。这时,我们就可以将订单一直标记为"新下单"的状态。而等RocketMQ恢复后,只要存储的消息没有丢失,RocketMQ就会再次继续状态回查的流程。
(5).下单成功后如何优雅的等待支付成功?
在订单场景下,通常会要求下单完成后,客户在一定时间内,例如10分钟,内完成订单支付,支付完成后才会通知下游服务进行进一步的营销补偿。 如果不用事务消息,那通常会怎么办? 最简单的方式是启动一个定时任务,每隔一段时间扫描订单表,比对未支付的订单的下单时间,将超过时间的订单回收。这种方式显然是有很大问题的,需要定时扫描很庞大的一个订单信息,这对系统是个不小的压力。 那更进一步的方案是什么呢?是不是就可以使用RocketMQ提供的延迟消息机制。往MQ发一个延迟1分钟的消息,消费到这个消息后去检查订单的支付状态,如果订单已经支付,就往下游发送下单的通知。而如果没有支付,就再发一个延迟1分钟的消息。最终在第十个消息时把订单回收。这个方案就不用对全部的订单表进行扫描,而只需要每次处理一个单独的订单消息。 那如果使用上了事务消息呢?我们就可以用事务消息的状态回查机制来替代定时的任务。在下单时,给Broker返回一个UNKNOWN的未知状态。而在状态回查的方法中去查询订单的支付状态。这样整个业务逻辑就会简单很多。我们只需要配置RocketMQ中的事务消息回查次数(默认15次)和事务回查间隔时间(messageDelayLevel),就可以更优雅的完成这个支付状态检查的需求。
(6)、事务消息机制的作用
整体来说,在订单这个场景下,消息不丢失的问题实际上就还是转化成了下单这个业务与下游服务的业务的分布式事务一致性问题。而事务一致性问题一直以来都是一个非常复杂的问题。而RocketMQ的事务消息机制,实际上只保证了整个事务消息的一半,他保证的是订单系统下单和发消息这两个事件的事务一致性,而对下游服务的事务并没有保证。但是即便如此,也是分布式事务的一个很好的降级方案。目前来看,也是业内最好的降级方案。
2、RocketMQ配置同步刷盘+Dledger主从架构保证MQ自身不会丢消息
(1)、同步刷盘 这个从我们之前的分析,就很好理解了。我们可以简单的把RocketMQ的刷盘方式 flushDiskType配置成同步刷盘就可以保证消息在刷盘过程中不会丢失了。
(2)、Dledger的文件同步
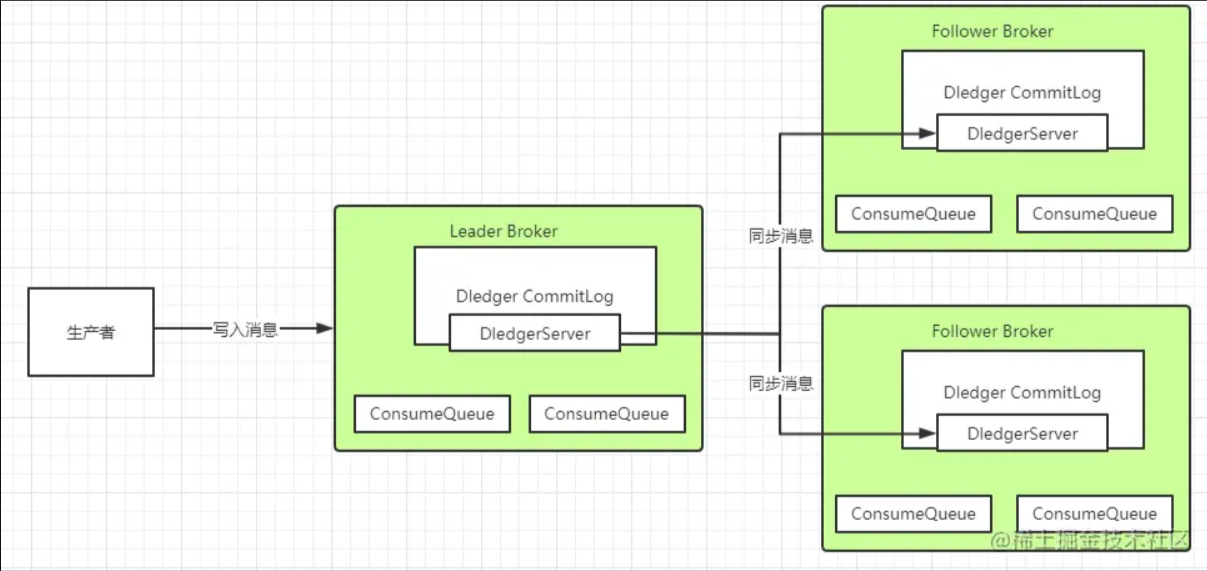
在使用Dledger技术搭建的RocketMQ集群中,Dledger会通过两阶段提交的方式保证文件在主从之间成功同步。 简单来说,数据同步会通过两个阶段,一个是uncommitted阶段,一个是commited阶段。 Leader Broker上的Dledger收到一条数据后,会标记为uncommitted状态,然后他通过自己的DledgerServer组件把这个uncommitted数据发给Follower Broker的DledgerServer组件。 接着Follower Broker的DledgerServer收到uncommitted消息之后,必须返回一个ack给Leader Broker的Dledger。然后如果Leader Broker收到超过半数的Follower Broker返回的ack之后,就会把消息标记为committed状态。 再接下来, Leader Broker上的DledgerServer就会发送committed消息给Follower Broker上的DledgerServer,让他们把消息也标记为committed状态。这样,就基于Raft协议完成了两阶段的数据同步。
3、消费者端不要使用异步消费机制
正常情况下,消费者端都是需要先处理本地事务,然后再给MQ一个ACK响应,这时MQ就会修改Offset,将消息标记为已消费,从而不再往其他消费者推送消息。所以在Broker的这种重新推送机制下,消息是不会在传输过程中丢失的。但是也会有下面这种情况会造成服务端消息丢失:
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");
consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {new Thread(){public void run(){//处理业务逻辑System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);}};return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}
});这种异步消费的方式,就有可能造成消息状态返回后消费者本地业务逻辑处理失败造成消息丢失的可能。
4、RocketMQ特有的问题,NameServer挂了如何保证消息不丢失?
NameServer在RocketMQ中,是扮演的一个路由中心的角色,提供到Broker的路由功能。但是其实路由中心这样的功能,在所有的MQ中都是需要的。kafka是用zookeeper和一个作为Controller的Broker一起来提供路由服务,整个功能是相当复杂纠结的。而RabbitMQ是由每一个Broker来提供路由服务。而只有RocketMQ把这个路由中心单独抽取了出来,并独立部署。 这个NameServer之前都了解过,集群中任意多的节点挂掉,都不会影响他提供的路由功能。那如果集群中所有的NameServer节点都挂了呢? 有很多人就会认为在生产者和消费者中都会有全部路由信息的缓存副本,那整个服务可以正常工作一段时间。其实这个问题大家可以做一下实验,当NameServer全部挂了后,生产者和消费者是立即就无法工作了的。至于为什么,可以回顾一下我们之前的源码课程去源码中找找答案。 那再回到我们的消息不丢失的问题,在这种情况下,RocketMQ相当于整个服务都不可用了,那他本身肯定无法给我们保证消息不丢失了。我们只能自己设计一个降级方案来处理这个问题了。例如在订单系统中,如果多次尝试发送RocketMQ不成功,那就只能另外找给地方(Redis、文件或者内存等)把订单消息缓存下来,然后起一个线程定时的扫描这些失败的订单消息,尝试往RocketMQ发送。这样等RocketMQ的服务恢复过来后,就能第一时间把这些消息重新发送出去。整个这套降级的机制,在大型互联网项目中,都是必须要有的。
完整分析过后,整个RocketMQ消息零丢失的方案其实挺简单
- 生产者使用事务消息机制。
- Broker配置同步刷盘+Dledger主从架构
- 消费者不要使用异步消费。
- 整个MQ挂了之后准备降级方案
使用RocketMQ如何快速处理积压消息?
1、如何确定RocketMQ有大量的消息积压?
在正常情况下,使用MQ都会要尽量保证他的消息生产速度和消费速度整体上是平衡的,但是如果部分消费者系统出现故障,就会造成大量的消息积累。这类问题通常在实际工作中会出现得比较隐蔽。例如某一天一个数据库突然挂了,大家大概率就会集中处理数据库的问题。等好不容易把数据库恢复过来了,这时基于这个数据库服务的消费者程序就会积累大量的消息。或者网络波动等情况,也会导致消息大量的积累。这在一些大型的互联网项目中,消息积压的速度是相当恐怖的。所以消息积压是个需要时时关注的问题。 对于消息积压,如果是RocketMQ或者kafka还好,他们的消息积压不会对性能造成很大的影响。而如果是RabbitMQ的话,那就惨了,大量的消息积压可以瞬间造成性能直线下滑。 对于RocketMQ来说,有个最简单的方式来确定消息是否有积压。那就是使用web控制台,就能直接看到消息的积压情况。 在Web控制台的主题页面,可以通过 Consumer管理 按钮实时看到消息的积压情况。
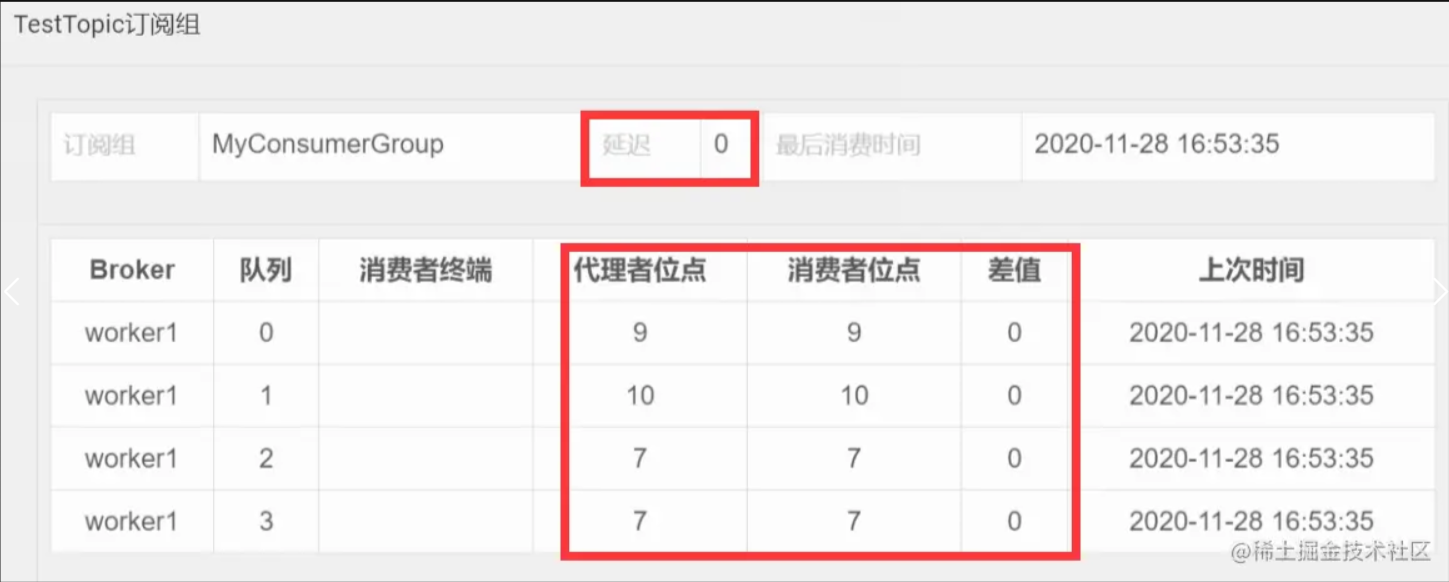
另外,也可以通过mqadmin指令在后台检查各个Topic的消息延迟情况。 还有RocketMQ也会在他的 ${storePathRootDir}/config 目录下落地一系列的json文件,也可以用来跟踪消息积压情况。
2、如何处理大量积压的消息?
其实我们回顾下RocketMQ的负载均衡的内容就不难想到解决方案。 如果Topic下的MessageQueue配置得是足够多的,那每个Consumer实际上会分配多个MessageQueue来进行消费。这个时候,就可以简单的通过增加Consumer的服务节点数量来加快消息的消费,等积压消息消费完了,再恢复成正常情况。最极限的情况是把Consumer的节点个数设置成跟MessageQueue的个数相同。但是如果此时再继续增加Consumer的服务节点就没有用了。 而如果Topic下的MessageQueue配置得不够多的话,那就不能用上面这种增加Consumer节点个数的方法了。这时怎么办呢? 这时如果要快速处理积压的消息,可以创建一个新的Topic,配置足够多的MessageQueue。然后把所有消费者节点的目标Topic转向新的Topic,并紧急上线一组新的消费者,只负责消费旧Topic中的消息,并转储到新的Topic中,这个速度是可以很快的。然后在新的Topic上,就可以通过增加消费者个数来提高消费速度了。之后再根据情况恢复成正常情况。 在官网中,还分析了一个特殊的情况。就是如果RocketMQ原本是采用的普通方式搭建主从架构,而现在想要中途改为使用Dledger高可用集群,这时候如果不想历史消息丢失,就需要先将消息进行对齐,也就是要消费者把所有的消息都消费完,再来切换主从架构。因为Dledger集群会接管RocketMQ原有的CommitLog日志,所以切换主从架构时,如果有消息没有消费完,这些消息是存在旧的CommitLog中的,就无法再进行消费了。这个场景下也是需要尽快的处理掉积压的消息。
RocketMQ的消息轨迹
RocketMQ默认提供了消息轨迹的功能:
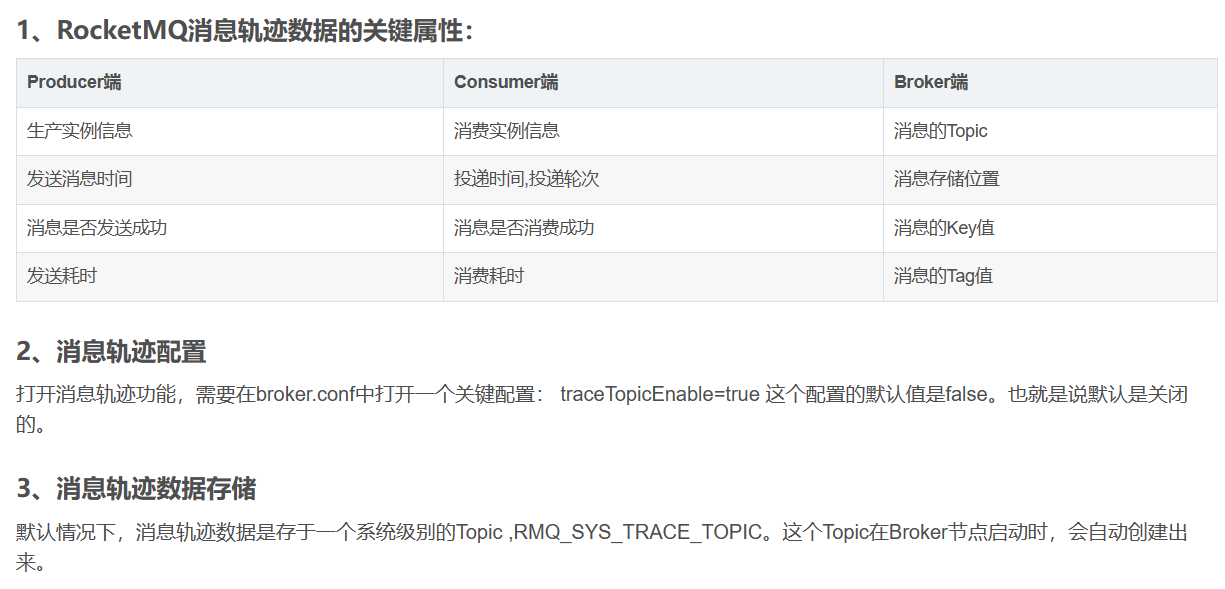
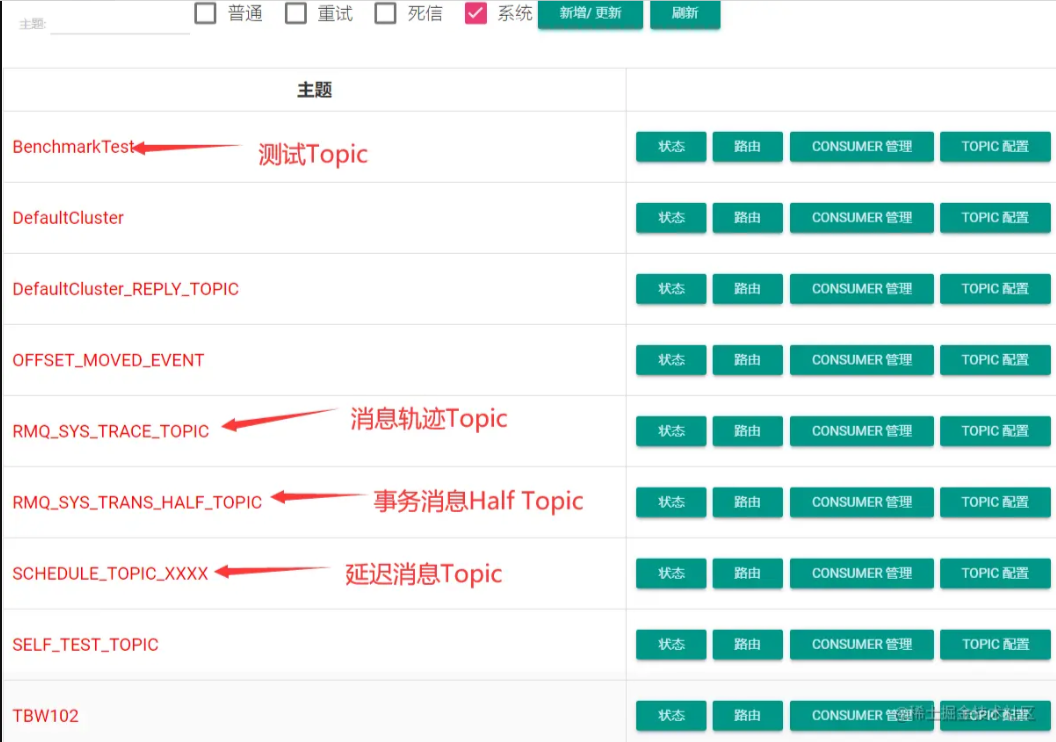
另外,也支持客户端自定义轨迹数据存储的Topic。 在客户端的两个核心对象 DefaultMQProducer和DefaultMQPushConsumer,他们的构造函数中,都有两个可选的参数来打开消息轨迹存储
-
enableMsgTrace:是否打开消息轨迹。默认是false。
-
customizedTraceTopic:配置将消息轨迹数据存储到用户指定的Topic 。
RocketMQ 如何处理流量削峰
连接地址: [(23条消息) RocketMQ实现流量削峰_mq削峰_ClareTung的博客-CSDN博客](https://blog.csdn.net/qq_36135928/article/details/121146631?ops_request_misc=&request_id=&biz_id=102&utm_term=RocketMQ 如何处理流量肖峰&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-121146631.142v80insert_down1,201v4add_ask,239v2insert_chatgpt&spm=1018.2226.3001.4187)
实现的思路:
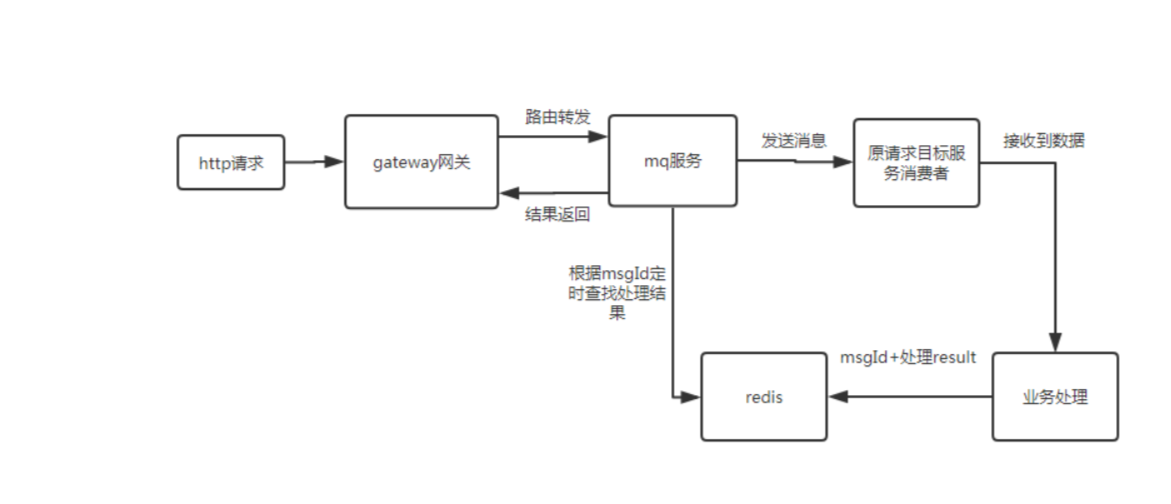
总体思路
- http请求到gateway网关
- gateway通过RouteLocator配置路由信息转发到mq服务
- mq服务接收到数据后,将数据发送到对应的topic
- mq消费者监听消息,拉取消息,进行业务处理,处理完后将msgId作为key,结果作为value存入redis 中
- mq服务发送消息的线程发送完消息后挂起,每隔一秒根据msgId去redis查询消费结果
使用RocketMQ如何保证消息顺序
为什么要保证消息的有序:例如如果我们有个大数据系统,需要对业务系统的日志进行收集分析,这时候为了减少对业务系统的影响,通常都会通过MQ来做消息中转。而这时候,对消息的顺序就有一定的要求了。
MQ的顺序问题分为全局有序和局部有序:
全局有序:整个MQ系统的所有消息严格按照队列先入先出顺序进行消费。
局部有序:只保证一部分关键消息的消费顺序。
相关文章:
kafka,RabbitMQ,RocketMQ,他们之间的区别,架构,如何保证消息的不丢失,保证不重复消费,保证消息的有序性
文章目录 Kafka、RabbitMQ、RocketMQ 之间的区别是什么?性能数据可靠性服务可用性功能 RabbitMQ如何保证消息不丢失?Kafka 的架构说一下?Kafka 怎么保证消息是有序的?Kafka 怎么解决重复消费?Kafka 怎么保证消息不丢失…...

uni-app中vue3+setup实现下拉刷新、上拉加载更多效果
在小程序或各类app中,下拉刷新和上拉加载更多是极为常见和使用非常频繁的两个功能,通过对这两个功能的合理使用可以极大的方便用户进行操作。 合理的设计逻辑才能更容易挽留住用户,因为这些细节性的小功能点就变得极为重要起来。 那么在uni…...

微服务实战系列之Nginx(技巧篇)
前言 今天北京早晨竟然飘了一些“雪花”,定睛一看,似雪非雪,像泡沫球一样,原来那叫“霰”。 自然中,雨雪霜露雾,因为出场太频繁,认识门槛较低,自然不费吹灰之力,即可享受…...

好工具|datamap,一个好用的地图可视化Excel插件,在Excel中实现地理编码、拾取坐标
在做VRP相关研究的时候,需要对地图数据做很多处理,比如地理编码,根据“重庆市沙坪坝区沙正街174号”这样的一个文本地址知道他的经纬度;再比如绘制一些散点图,根据某个位置的经纬度在地图上把它标注出来。还有有的时候…...

Java——继承
继承是面向对象编程的三大特征之一,它让我们更加容易实现对已有类的扩展、更加容易实现对现实世界的建模。 继承有两个主要作用: 代码复用,更加容易实现类的扩展方便建模 继承的实现 继承让我们更加容易实现对类的扩展。比如我们定义了人…...

十、sdl显示yuv图片
前言 SDL中内置加载BMP的API,使用起来会更加简单,便于初学者学习使用SDL 如果需要加载JPG、PNG等其他格式的图片,可以使用第三方库:SDL_image 测试环境: ffmpeg的4.3.2自行编译版本windows环境qt5.12sdl2.0.22&…...

Docker Nginx容器部署vue项目
Docker Nginx容器部署vue项目 文章目录 Docker Nginx容器部署vue项目1. 前提2. 下载nginx镜像3. 编写nginx.conf配置文件4. 编写构建命令5. vue项目上传 1. 前提 Docker服务已部署 2. 下载nginx镜像 首先查看有没有nginx镜像 docker images没有的情况下再进行下载 docker …...
【深度学习】如何找到最优学习率
经过了大量炼丹的同学都知道,超参数是一个非常玄乎的东西,比如batch size,学习率等,这些东西的设定并没有什么规律和原因,论文中设定的超参数一般都是靠经验决定的。但是超参数往往又特别重要,比如学习率&a…...
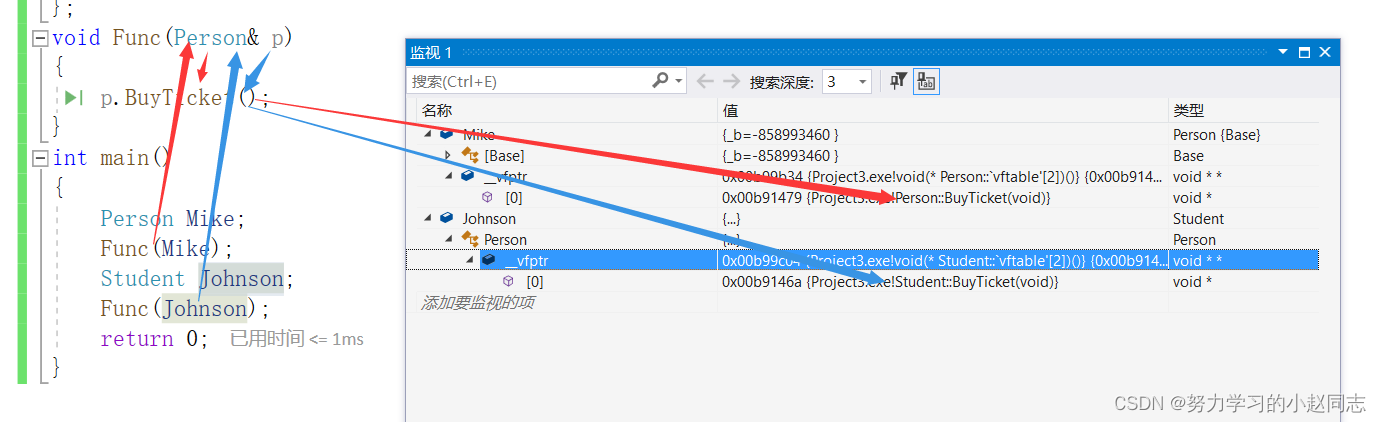
详解—C++三大特性——多态
目录 一. 多态的概念 1.1 概念 二. 多态的定义及实现 2.1多态的构成条件 2.2 虚函数 2.3虚函数的重写 2.3.1虚函数重写的两个例外: 1. 协变(基类与派生类虚函数返回值类型不同) 2. 析构函数的重写(基类与派生类析构函数的名字不同) 2.4 C11 override 和 f…...

用idea搭建一个spring cloud微服务项目
以下是使用 IntelliJ IDEA 搭建 Spring Cloud 微服务项目的步骤: 创建一个新的 Maven 项目。 在 pom.xml 文件中添加以下依赖: <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-…...
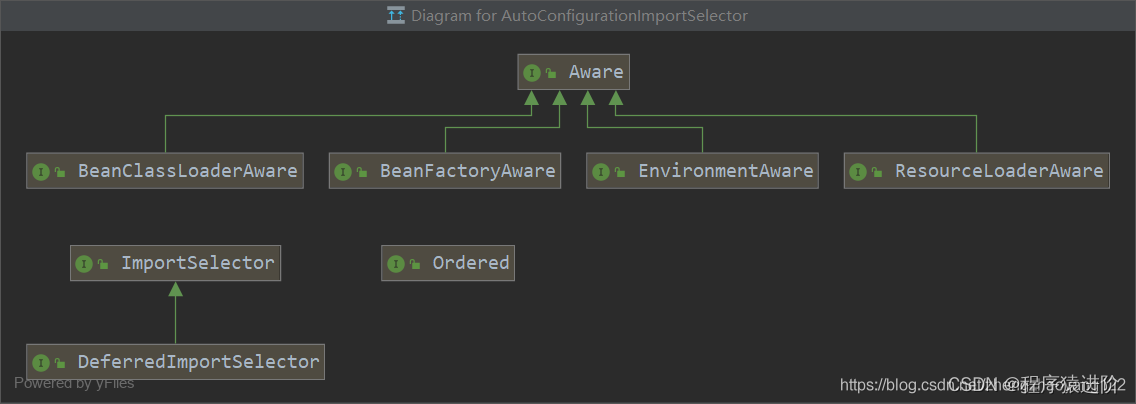
SpringBoot——启动类的原理
优质博文:IT-BLOG-CN SpringBoot启动类上使用SpringBootApplication注解,该注解是一个组合注解,包含多个其它注解。和类定义SpringApplication.run要揭开SpringBoot的神秘面纱,我们要从这两位开始就可以了。 SpringBootApplicati…...
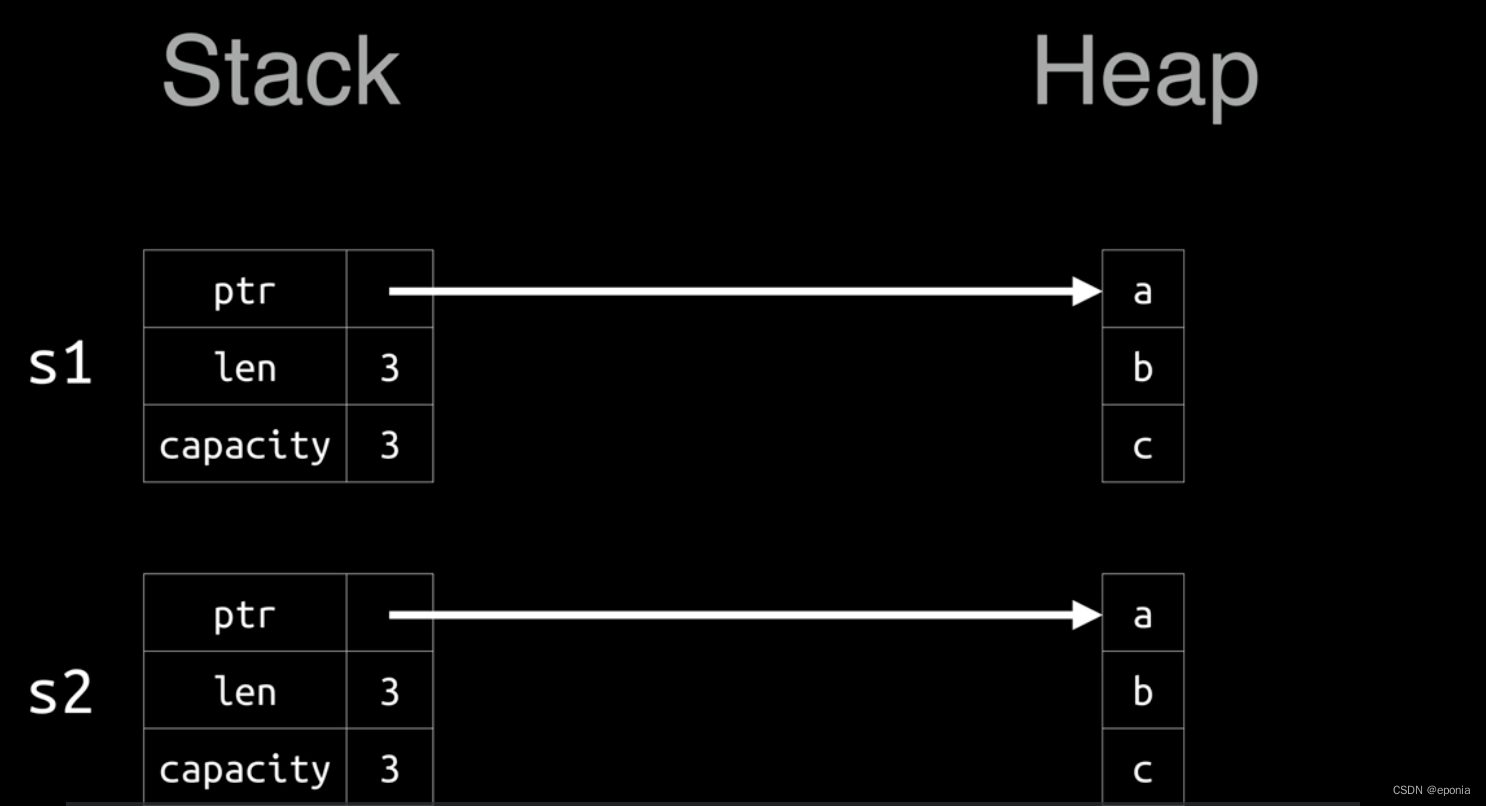
Rust语言入门教程(七) - 所有权系统
所有权系统是Rust敢于声称自己为一门内存安全语言的底气来源,也是让Rust成为一门与众不同的语言的所在之处。也正是因为这个特别的所有权系统,才使得编译器能够提前暴露代码中的错误,并给出我们必要且精准的错误提示。 所有权系统的三个规则…...
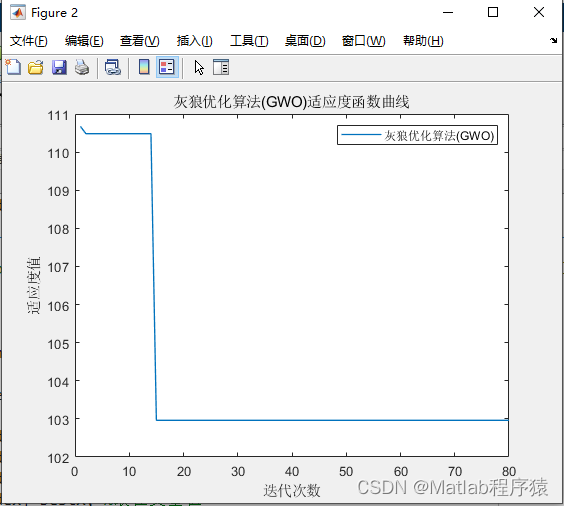
【MATLAB源码-第89期】基于matlab的灰狼优化算法(GWO)无人机三维路径规划,输出做短路径图和适应度曲线
操作环境: MATLAB 2022a 1、算法描述 灰狼优化算法(Grey Wolf Optimizer, GWO)是一种模仿灰狼捕食行为的优化算法。灰狼是群居动物,有着严格的社会等级结构。在灰狼群体中,通常有三个等级:首领ÿ…...

线程池的饱和策略有哪些?
线程池的饱和策略是指当线程池中的任务队列已满时,线程池如何处理新提交的任务。常见的饱和策略有以下几种: 阻塞策略 阻塞策略是指当线程池中的任务队列已满时,新提交的任务会等待队列中有空闲位置后再执行。这种策略可以避免过多的任务被…...

Git设置多个仓库同时推送
Git设置多个仓库同时推送 添加 在Git中,有时我们需要将同一份代码推送到不同的远程仓库,只是URL地址不同。 下面是一种优化的方法来设置多个仓库同时推送: # 添加一个新的远程仓库 git remote set-url --add origin2 新的仓库地址这样&am…...

前端入职环境安装
前端入职 后环境安装 ,内函 nodenvmgit微信开发者工具vscode 的安装包 一.node安装-js运行环境 1.node下载,下载地址Node.js 2.配置淘宝镜像 npm config set registry https://registry.npmmirror.com/ 3.查看配置 npm config list 二.nvm安装-切…...
《金融科技行业2023年专利分析白皮书》发布——科技变革金融,专利助力行业发展
金融是国民经济的血脉,是国家核心竞争力的重要组成部分,金融高质量发展成为2023年中央金融工作的重要议题。《中国金融科技调查报告》中指出,我国金融服务业在科技的助力下,从1.0时代的“信息科技金融”、2.0时代的“互联网金融”…...

Introducing the Arm architecture
快速链接: . 👉👉👉 个人博客笔记导读目录(全部) 👈👈👈 付费专栏-付费课程 【购买须知】:【精选】ARMv8/ARMv9架构入门到精通-[目录] 👈👈👈 — 适合小白入门【目录】ARMv8/ARMv9架构高级进阶-[目录]👈👈👈 — 高级进阶、小白勿买【加群】ARM/TEE…...

Python 使用SQLAlchemy数据库模块
SQLAlchemy 是用Python编程语言开发的一个开源项目,它提供了SQL工具包和ORM对象关系映射工具,使用MIT许可证发行,SQLAlchemy 提供高效和高性能的数据库访问,实现了完整的企业级持久模型。 ORM(对象关系映射࿰…...
)
【nlp】4.3 nlp中常用的预训练模型(BERT及其变体)
nlp中常用的预训练模型 1 当下NLP中流行的预训练模型1.1 BERT及其变体1.2 GPT1.3 GPT-2及其变体1.4 Transformer-XL1.5 XLNet及其变体1.6 XLM1.7 RoBERTa及其变体1.8 DistilBERT及其变体1.9 ALBERT1.10 T5及其变体1.11 XLM-RoBERTa及其变体2 预训练模型说明3 预训练模型的分类1…...

硬件发烧友玩法:多GPU分配OpenClaw调用Qwen3-32B
硬件发烧友玩法:多GPU分配OpenClaw调用Qwen3-32B 1. 为什么需要多GPU分配 作为一个长期折腾AI本地部署的硬件爱好者,我最近在尝试用OpenClaw对接Qwen3-32B模型时遇到了显存瓶颈。单卡RTX4090D的24GB显存在处理复杂任务时经常捉襟见肘,特别是…...

如何计算SEO页面优化的费用_SEO页面优化费用如何收取
如何计算SEO页面优化的费用_SEO页面优化费用如何收取 在当今数字化时代,网站的SEO优化成为了提升网站流量和品牌知名度的关键因素。SEO页面优化的费用如何计算和收取,这个问题困扰着许多初学者和企业主。本文将详细解析如何计算SEO页面优化的费用&#…...

智能开门柜自动售货机哪里生产
当你考虑引入一台智能开门柜自动售货机时,脑海中浮现的第一个问题往往是:“这东西,哪里生产的靠谱?”这背后,是对设备质量、技术稳定性和长期服务的深度关切。今天,我们就来深入剖析智能开门柜的生产格局&a…...
)
避坑指南:在Ubuntu 22.04上为Autoware配置Docker与NVIDIA GPU支持(含代理与镜像源配置)
深度避坑:Ubuntu 22.04下Autoware与Docker的GPU实战配置全解 当你在深夜的终端前反复输入docker run --gpus all却只收获冰冷的错误提示时,这种挫败感我深有体会。本文不是又一份标准安装教程,而是从17次失败尝试中提炼出的生存手册ÿ…...

[具身智能-235]:OpenCV - 图像是RGB三通道,Mask是单通道
在 OpenCV 和计算机视觉中,图像(Image)通常是三维的(高 H 宽 W 通道 C,例如 RGB 三通道),而 掩膜(Mask)通常是二维的(高 H 宽 W,单通道黑白&am…...

终极指南:如何使用snabbt.js创建惊艳的Web动画效果
终极指南:如何使用snabbt.js创建惊艳的Web动画效果 【免费下载链接】snabbt.js Fast animations with javascript and CSS transforms 项目地址: https://gitcode.com/gh_mirrors/sn/snabbt.js 在当今的Web开发领域,snabbt.js作为一款极简主义的J…...

BigDL-2.x与Spark MLlib集成:传统机器学习与深度学习的完美融合
BigDL-2.x与Spark MLlib集成:传统机器学习与深度学习的完美融合 【免费下载链接】BigDL-2.x BigDL: Distributed TensorFlow, Keras and PyTorch on Apache Spark/Flink & Ray 项目地址: https://gitcode.com/gh_mirrors/bi/BigDL-2.x BigDL-2.x是一个强…...

容器编排:Docker Compose与Kubernetes的适用场景
容器编排:Docker Compose与Kubernetes的适用场景 在容器化技术蓬勃发展的今天,容器编排工具的选择直接影响着应用的部署效率、运维复杂度和系统稳定性。Docker Compose与Kubernetes作为两大主流工具,分别在单机环境与分布式集群领域展现出独特优势。本文将结合真实项目经验…...

Boost电路与SMC滑模控制策略:文章复现及性能优化探讨
boost电路,smc滑模控制,文章复现Boost电路在电力电子里算是老熟人了,但真要玩转它的闭环控制可不容易。最近在复现一篇用滑模控制(SMC)搞Boost电路的论文,实测发现这货对付负载突变确实有两把刷子。今天咱们…...

运算放大器基础:从符号到负反馈的实战解析
1. 运算放大器基础认知 第一次接触运算放大器时,我盯着电路板上那个小小的三角形符号发愣——这玩意儿凭什么能同时处理比较和放大两种任务?后来才发现,它的强大之处恰恰藏在最简单的符号里。运放的符号主体是个三角形,五个关键引…...