数据挖掘 朴素贝叶斯
直入正题,直接看代码:
这是一段判断是不是藏话的代码
import numpy as np# 数据采集(定义函数加载数据集)
def load_dataset():sent_list = [['my', 'name', 'is', 'Devin'],['you', 'are', 'stupid'],['my', 'boyfriend', 'is', 'SB'],['you', 'looks', 'very', 'smart', 'I', 'like', 'you', 'very', 'much']]class_vec = [-1, 1, 1, -1] # -1代表不粗鲁,1代表粗鲁return sent_list, class_vec# 数据预处理(创建一个包含数据集中所有单词的词汇表,词汇表中包含所有唯一的单词)
def create_vocab_list(dataset):vocab_set = set([])for doc in dataset:vocab_set = vocab_set | set(doc)return list(vocab_set)# 将每一段文字进行离散化,即进行空间向量化
def set_of_words2vec(vocab_list, input_set):return_vec = [0] * len(vocab_list)for word in input_set:if word in vocab_list:return_vec[vocab_list.index(word)] = 1 # 如果该单词在词汇表中出现,则将 return_vec 中对应位置的值设为 1。return return_vec# 建模与分析
def trainNB(train_matrix, train_catagory):num_train_docs = len(train_matrix)num_words = len(train_matrix[0])pos_num = 0for i in train_catagory:if i == 1:pos_num += 1pAbusive = pos_num / float(num_train_docs)p0_num = np.ones(num_words) # 使用 NumPy 库创建了一个长度为 num_words 的一维数组 p0_num,并将数组中的所有元素初始化为 1。p1_num = np.ones(num_words)p0_demon = 2.0 # 当某个特征在某个类别下从未出现时,使用 Laplace 平滑会将该特征的出现次数初始化为一个小的正数(通常是 1),并将分母加上特征总数乘以一个小的正数(通常是特征的种类数),从而使得概率值不会变成零。p1_demon = 2.0for i in range(num_train_docs):if train_catagory[i] == 1:p1_num += train_matrix[i] # p1_num=[1,0,1,0,1,1,1,1,1,0,0]p1_demon += sum(train_matrix[i]) # 样本中在类标签为1的单词出现的总次数p1_demon=7else:p0_num += train_matrix[i] # p0_num=[1,0,1,0,1,1,1,1,1,0,0]p0_demon += sum(train_matrix[i]) # 样本中在类标签为0的单词出现总次数p0_demon=4p1_vect = np.log(p1_num / p1_demon) # 举证p1_num和p0_num分别除以p1_demon和p0_demon即可以得到各自的条件概率p0_vect = np.log(p0_num / p0_demon) # 使用了 NumPy 的 np.log() 函数来计算条件概率,避免数值溢出return p0_vect, p1_vect, pAbusive # p1_vect表示正样本条件下的各单词的出现的概率,即条件概率 p(xi|y=yes)# 同理,p0_vect表示负样本条件下的各单词的出现的概率,即条件概率 p(xi|y=no)# 计算概率比较大小
# vec2classify: 待分类的特征向量 p0_vec: 类别 0 下各个特征的条件概率向量 p1_vec: 类别 1 下各个特征的条件概率向量 pClass1: 类别 1 的先验概率
def classifyNB(vec2classify, p0_vec, p1_vec, pClass1):p1 = sum(vec2classify * p1_vec) + np.log(pClass1) # 在类别 1 下的概率p0 = sum(vec2classify * p0_vec) + np.log(1.0 - pClass1) # 在类别 0 下的概率if p1 > p0:return 1elif p0 > p1:return -1else:return 0# 加载数据集
list_sents, list_classes = load_dataset()
# 创建词汇表
my_vocab_list = create_vocab_list(list_sents)
# 将每一段文字进行离散化,即进行空间向量化
train_mat = []
for sent_in_doc in list_sents:train_mat.append(set_of_words2vec(my_vocab_list, sent_in_doc))# 训练朴素贝叶斯
p0V, p1V, pAb = trainNB(train_mat, list_classes)
# 测试语句
test_entry = ['I', 'like', 'you']
print("利用朴素贝叶斯测试语句“I like you”是粗鲁还是不粗鲁:")
print("1代表粗鲁,-1代表不粗鲁")
print("结果为:")
print(classifyNB(np.array(set_of_words2vec(my_vocab_list, test_entry)), p0V, p1V,pAb)) # 使用 numpy 数组可以高效地进行元素级别的操作,例如计算两个向量的点积、元素相乘等。
代码来源
相关文章:

数据挖掘 朴素贝叶斯
直入正题,直接看代码: 这是一段判断是不是藏话的代码 import numpy as np# 数据采集(定义函数加载数据集) def load_dataset():sent_list [[my, name, is, Devin],[you, are, stupid],[my, boyfriend, is, SB],[you, looks, ver…...

UI自动化测试工具有哪些优势?
UI自动化测试工具通过提高测试效率、覆盖率,减少测试时间和成本,以及支持持续集成等方式,为软件开发团队提供了一系列重要的优势,有助于提升软件质量和开发效率。 自动化执行:UI自动化测试工具可以模拟用户与应用程序的…...

【论文阅读笔记】InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
【论文阅读笔记】StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation 论文阅读笔记论文信息引言动机挑战 方法结果 关键发现相关工作1. 视觉语言基础模型2. 视觉通用模型 方法/模型视觉任务的统一说明训练数据构建网络结构 实验设…...

笔记62:注意力汇聚 --- Nadaraya_Watson 核回归
本地笔记地址:D:\work_file\(4)DeepLearning_Learning\03_个人笔记\3.循环神经网络\第10章:动手学深度学习~注意力机制 a a a a a a a a a a a a a a a a...

给定一个n×n的方阵,本题要求计算该矩阵除副对角线、最后一列和最后一行以外的所有元素之和。
7-5 矩阵运算 分数 20 全屏浏览题目 切换布局 作者 C课程组 单位 浙江大学 给定一个nn的方阵,本题要求计算该矩阵除副对角线、最后一列和最后一行以外的所有元素之和。副对角线为从矩阵的右上角至左下角的连线。 输入格式: 输入第一行给出正整数n(…...

Go语言的学习笔记3——Go语言项目布局
Go 1.11 版本开始引入 go.mod 和 go.sum 以支持Go Module构建机制,而这种机制成为官方的依赖包管理方式。 现在Go可执行程序项目的典型布局如下所示: exe-layout ├── cmd/ │ ├── app1/ │ │ └── main.go │ └── app2/ │ └…...

70-76-堆、贪心算法
LeetCode 热题 100 文章目录 LeetCode 热题 100堆70. 中等-数组中的第K个最大元素71. 中等-前K个高频元素72. 困难-数据流中的中位数 贪心算法73. 简单-买卖股票的最佳时机74. 中等-跳跃游戏75. 中等-跳跃游戏II76. 中等-划分字母区间 本文存储我刷题的笔记。 堆 70. 中等-数组…...

Qt Network
Qt Network Qt Network为使用TCP/IP的应用程序编程提供了一组API。各种C++类处理诸如请求、cookies和通过HTTP发送数据之类的操作。 标题使用模块 使用Qt模块需要直接或通过其他依赖项链接到模块库。一些构建工具对此有专门的支持,包括CMake和qmake. 标题使用CMake构建 使…...
Win10电脑用U盘重装系统的步骤
在Win10电脑中,用户遇到了无法解决的系统问题,用户这时候就可以考虑重装Win10系统,这样即可轻松解决问题,从而满足自己的操作需求。接下来小编给大家详细介绍关于Win10电脑中用U盘重装系统的教程步骤。 准备工作 1. 一台正常联网可…...

安防视频监控/磁盘阵列/集中云存储平台EasyCVR设备录像保活不生效原因是什么?该如何解决?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
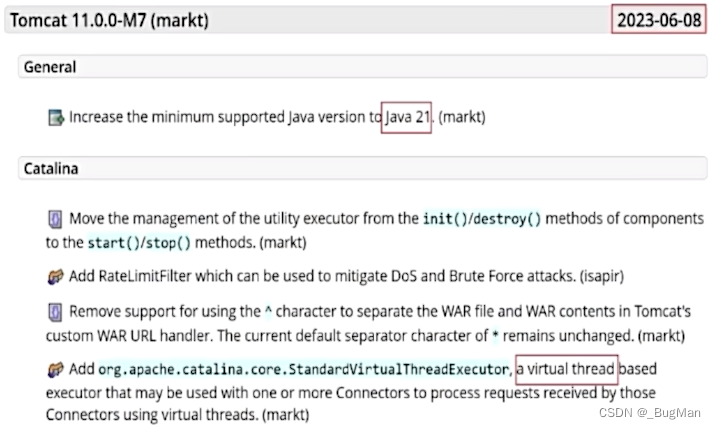
【JDK21】详解虚拟线程
目录 1.概述 2.虚拟线程是为了解决哪些问题 2.1.线程切换的巨大代价 2.2.哪些情况会造成线程的切换 2.3.线程资源是有限的 3.虚拟线程 4.适用场景 1.概述 你发任你发,我用JAVA8?JDK21可能要对这句话say no了。 现在Oracle JDK是每4个版本&#x…...
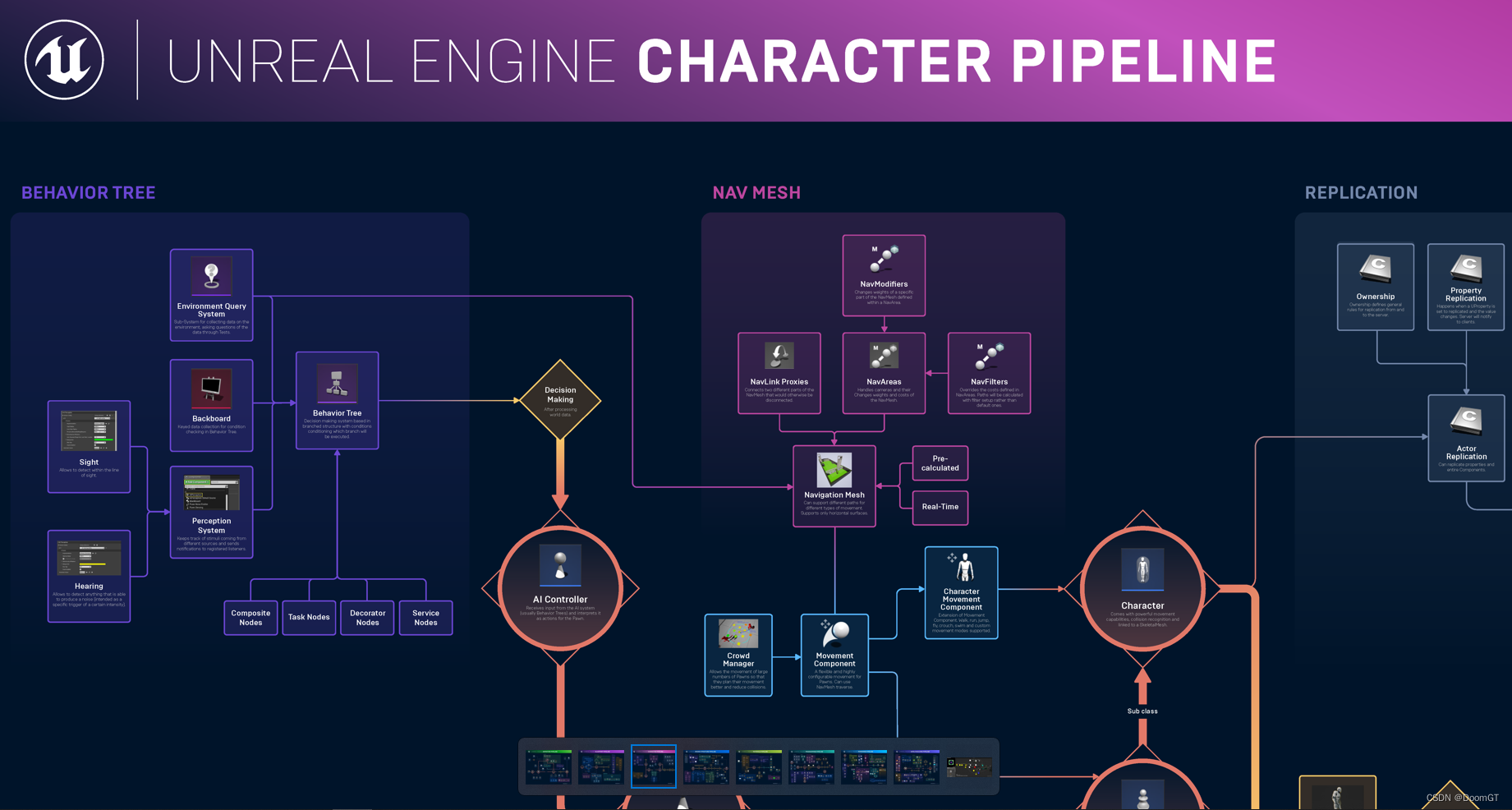
UE5 - 虚幻引擎各模块流程图
来自虚幻官方的一些资料,分享一下; 一些模块的流程图,比如动画模块: 或角色相关流程: 由于图片比较大,上传到了网络,可自取: 链接:https://pan.baidu.com/s/1BQ2KiuP08c…...
vue3实现element table缓存滚动条
背景 对于后台管理系统,数据的展示形式大多都是通过表格,常常会出现的一种场景,从表格跳到二级页面,再返回上一页时,需要缓存当前的页码和滚动条的位置,以为使用keep-alive就能实现这两种诉求,…...
)
flutter布局详解及代码示例(下)
布局 基本布局 GridView(二维滚动列表):比ListView多了一个方向的数据填充。ListBody(滚动列表):相比ListView,没有回收复用,简单易用。Table(表格布局)&am…...

SQL Server:流程控制语言详解
文章目录 一、批处理、脚本和变量局部变量和全局变量1、局部变量2、全局变量 二、顺序、分支和循环结构语句1、程序注释语句2、BEGIN┅END语句块3、IF┅ELSE语句4、CASE语句5、WHILE语句6、BREAK和CONTINUE语句BREAK语句CONTINUE语句 三、程序返回、屏幕显示等语句1、RETURN语句…...
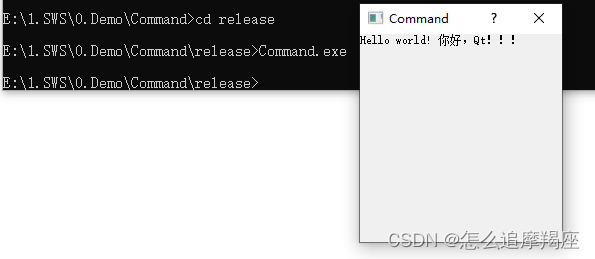
2、用命令行编译Qt程序生成可执行文件exe
一、创建源文件 1、新建一个文件夹,并创建一个txt文件 2、重命名为main.cpp 3、在main.cpp中添加如下代码 #include <QApplication> #include <QDialog> #include <QLabel> int main(int argc, char *argv[]) { QApplication a(argc, argv); QDi…...

【追求卓越08】算法--排序算法
引导 今天开始介绍我们在工作中经常遇到的算法--排序。排序算法有很多,我们主要介绍以下几种: 冒泡排序 插入排序 选择排序 归并排序 快速排序 计数排序 基数排序 桶排序 我们需要了解每一种算法的定义以及实现方式,并且掌握如何评…...
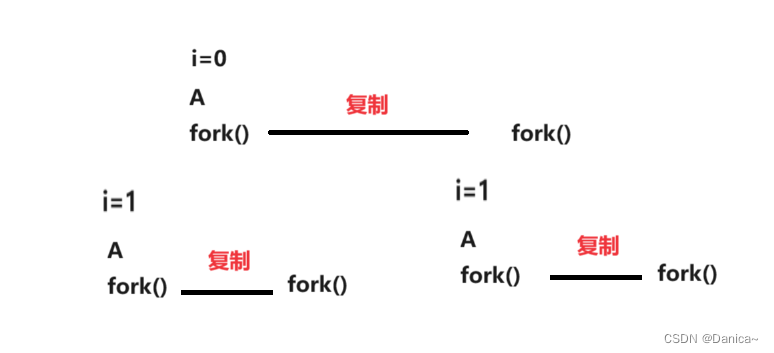
Linux fork笔试练习题
1.打印结果? #include <stdio.h> #include <unistd.h> #include <stdlib.h>int main() {int i0;for(;i<2;i){fork();printf("A\n");}exit(0); } 结果打印 A A A A A A 2.将上面的打印的\n去掉,结果如何? printf("…...

Jenkins 整合 Docker 自动化部署
Docker 安装 Jenkins 配置自动化部署 1. Docker 安装 Jenkins 1.1 拉取镜像文件 docker pull jenkins/jenkins1.2 创建挂载文件目录 mkdir -p $HOME/jenkins_home1.3 启动容器 docker run -d -p 8080:8080 -v $HOME/jenkins_home:/var/jenkins_home --name jenkins jenkin…...

竞赛选题 题目:基于大数据的用户画像分析系统 数据分析 开题
文章目录 1 前言2 用户画像分析概述2.1 用户画像构建的相关技术2.2 标签体系2.3 标签优先级 3 实站 - 百货商场用户画像描述与价值分析3.1 数据格式3.2 数据预处理3.3 会员年龄构成3.4 订单占比 消费画像3.5 季度偏好画像3.6 会员用户画像与特征3.6.1 构建会员用户业务特征标签…...

突破QQ音乐加密限制:qmcdump全场景解密工具实战指南
突破QQ音乐加密限制:qmcdump全场景解密工具实战指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 副标题&…...

Xbox手柄电量监控:告别游戏中断的终极解决方案
Xbox手柄电量监控:告别游戏中断的终极解决方案 【免费下载链接】XB1ControllerBatteryIndicator A tray application that shows a battery indicator for an Xbox-ish controller and gives a notification when the battery level drops to (almost) empty. 项目…...

Vant Weapp组件库无障碍颜色方案实践指南
Vant Weapp组件库无障碍颜色方案实践指南 【免费下载链接】vant-weapp 轻量、可靠的小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/va/vant-weapp 问题引入:被忽视的视觉障碍用户体验痛点 在小程序开发中,颜色设计往往聚焦于视觉美…...
)
WinCC TIA Portal数据交换实战:用VBS脚本玩转XML导入导出(附避坑指南)
WinCC TIA Portal数据交换实战:用VBS脚本玩转XML导入导出(附避坑指南) 在工业自动化项目中,数据交换是连接控制系统与上层信息系统的关键桥梁。WinCC作为西门子TIA Portal中的重要组件,其数据交互能力直接影响着生产报…...

PyTorch 2.9镜像入门:无需配置,直接开启GPU加速
PyTorch 2.9镜像入门:无需配置,直接开启GPU加速 1. 为什么选择PyTorch 2.9镜像 深度学习开发环境配置一直是让新手头疼的问题,特别是GPU驱动的安装和CUDA环境的配置。PyTorch 2.9镜像解决了这个痛点,它预装了完整的PyTorch 2.9环…...

Z-Image-Turbo广告设计:多语言海报生成系统
Z-Image-Turbo广告设计:多语言海报生成系统 1. 引言 电商商家每天需要制作大量商品海报,人工设计成本高且效率低。传统设计流程需要找设计师、反复沟通修改,一张海报从构思到完成往往需要数小时甚至数天时间。对于需要覆盖多个市场的品牌来…...

LaTeX公式转Word工具:让学术写作告别格式困扰的Chrome扩展
LaTeX公式转Word工具:让学术写作告别格式困扰的Chrome扩展 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 在学术研究和论文撰写过程…...

零基础入门:Qwen3-ASR-1.7B语音识别Docker部署全流程
零基础入门:Qwen3-ASR-1.7B语音识别Docker部署全流程 1. 为什么选择Docker部署语音识别服务 想象一下,你刚学会使用Qwen3-ASR-1.7B这个强大的语音识别模型,在本地电脑上测试效果非常棒。但当你想把它部署到服务器上时,突然发现各…...
Pixel Language Portal惊艳效果展示:全屏沉浸双栏布局下中英对照滚动同步+光标联动演示
Pixel Language Portal惊艳效果展示:全屏沉浸双栏布局下中英对照滚动同步光标联动演示 1. 像素语言传送门概览 **像素语言跨维传送门(Pixel Language Portal)**是一款基于腾讯Hunyuan-MT-7B核心引擎构建的创新翻译工具。与传统翻译软件不同,它将语言转…...

用神经网络、数学、理性思维能实现通用智能吗?
1. 核心结论:仅依靠神经网络、数学建模与纯粹理性思维,无法实现真正的通用人工智能(AGI),三者仅为人类智能的局部子集,而非智能本质。2. 数理逻辑边界:哥德尔不完备定理证明,纯形式化…...