Spark---转换算子、行动算子、持久化算子
一、转换算子和行动算子
1、Transformations转换算子
1)、概念
Transformations类算子是一类算子(函数)叫做转换算子,如map、flatMap、reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。
2)、Transformation类算子
filter :过滤符合条件的记录数,true保留,false过滤掉
map:将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。特点:输入一条,输出一条数据。
flatMap:先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
sample:随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。
reduceByKey:将相同的Key根据相应的逻辑进行处理。
sortByKey/sortBy:作用在K,V格式的RDD上,对Key进行升序或者降序排序。
2、Action行动算子
1)、概念:
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
2)、Action类算子
count:返回数据集中的元素数。会在结果计算完成后回收到Driver端。
take(n):返回一个包含数据集前n个元素的集合。
first:first=take(1),返回数据集中的第一个元素。
foreach:循环遍历数据集中的每个元素,运行相应的逻辑。
collect:将计算结果回收到Driver端。
3)、demo:动态统计出现次数最多的单词个数,过滤掉。
- 一千万条数据量的文件,过滤掉出现次数多的记录,并且其余记录按照出现次数降序排序。
假设有一个records.txt文件
hello Spark
hello HDFS
hello hadoop
hello linux
hello Spark
hello Spark
hello Spark1
hello Spark
hello Spark
hello Spark2
hello Spark
hello Spark
hello Spark
hello Spark3
hello Spark
hello HDFS
hello hadoop
hello linux
hello Spark
hello Spark
hello Spark4
hello Spark
hello Spark
hello Spark5
hello Spark
hello Spark代码处理:
package com.bjsxt.demo;import java.util.Arrays;
import java.util.List;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;import scala.Tuple2;
/*** 动态统计出现次数最多的单词个数,过滤掉。* @author root**/
public class Demo1 {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local").setAppName("demo1");JavaSparkContext jsc = new JavaSparkContext(conf);JavaRDD<String> lines = jsc.textFile("./records.txt");JavaRDD<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Iterable<String> call(String t) throws Exception {return Arrays.asList(t.split(" "));}});JavaPairRDD<String, Integer> mapToPair = flatMap.mapToPair(new PairFunction<String,String, Integer>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Tuple2<String, Integer> call(String t) throws Exception {return new Tuple2<String, Integer>(t, 1);}});JavaPairRDD<String, Integer> sample = mapToPair.sample(true, 0.5);final List<Tuple2<String, Integer>> take = sample.reduceByKey(new Function2<Integer,Integer,Integer>(){/*** */private static final long serialVersionUID = 1L;@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1+v2;}}).mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Tuple2<Integer, String> call(Tuple2<String, Integer> t)throws Exception {return new Tuple2<Integer, String>(t._2, t._1);}}).sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer,String>, String, Integer>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Tuple2<String, Integer> call(Tuple2<Integer, String> t)throws Exception {return new Tuple2<String, Integer>(t._2, t._1);}}).take(1);System.out.println("take--------"+take);JavaPairRDD<String, Integer> result = mapToPair.filter(new Function<Tuple2<String,Integer>, Boolean>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Boolean call(Tuple2<String, Integer> v1) throws Exception {return !v1._1.equals(take.get(0)._1);}}).reduceByKey(new Function2<Integer,Integer,Integer>(){/*** */private static final long serialVersionUID = 1L;@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1+v2;}}).mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Tuple2<Integer, String> call(Tuple2<String, Integer> t)throws Exception {return new Tuple2<Integer, String>(t._2, t._1);}}).sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer,String>, String, Integer>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Tuple2<String, Integer> call(Tuple2<Integer, String> t)throws Exception {return new Tuple2<String, Integer>(t._2, t._1);}});result.foreach(new VoidFunction<Tuple2<String,Integer>>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic void call(Tuple2<String, Integer> t) throws Exception {System.out.println(t);}});jsc.stop();}
}
3、Spark代码流程
1)、创建SparkConf对象
可以设置Application name。
可以设置运行模式。
可以设置Spark application的资源需求。
2)、创建SparkContext对象
3)、基于Spark的上下文创建一个RDD,对RDD进行处理。
4)、应用程序中要有Action类算子来触发Transformation类算子执行。
5)、关闭Spark上下文对象SparkContext。
二、Spark持久化算子
1、控制算子
1)、概念
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
2)、cache
默认将RDD的数据持久化到内存中。cache是懒执行。
注意:chche()=persist()=persist(StorageLevel.Memory_Only)
测试cache文件:
测试代码:
1.SparkConf conf = new SparkConf();
2.conf.setMaster("local").setAppName("CacheTest");
3.JavaSparkContext jsc = new JavaSparkContext(conf);
4.JavaRDD<String> lines = jsc.textFile("persistData.txt");
5.
6.lines = lines.cache();
7.long startTime = System.currentTimeMillis();
8.long count = lines.count();
9.long endTime = System.currentTimeMillis();
10.System.out.println("共"+count+ "条数据,"+"初始化时间+cache时间+计算时间="+
11.(endTime-startTime));
12.
13.long countStartTime = System.currentTimeMillis();
14.long countrResult = lines.count();
15.long countEndTime = System.currentTimeMillis();
16.System.out.println("共"+countrResult+ "条数据,"+"计算时间="+ (countEndTime-
17.countStartTime));
18.
19.jsc.stop();persist:
可以指定持久化的级别。最常用的是MEMORY_ONLY和MEMORY_AND_DISK。”_2“表示有副本数。
持久化级别如下:

2、cache和persist的注意事项
1)、cache和persist都是懒执行,必须有一个action类算子触发执行。
2)、cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
3)、cache和persist算子后不能立即紧跟action算子。
4)、cache和persist算子持久化的数据当applilcation执行完成之后会被清除。
错误:rdd.cache().count() 返回的不是持久化的RDD,而是一个数值了。
3、checkpoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。checkpoint目录数据当application执行完之后不会被清除。
- persist(StorageLevel.DISK_ONLY)与Checkpoint的区别?
1)、checkpoint需要指定额外的目录存储数据,checkpoint数据是由外部的存储系统管理,不是Spark框架管理,当application完成之后,不会被清空。
2)、cache() 和persist() 持久化的数据是由Spark框架管理,当application完成之后,会被清空。
3)、checkpoint多用于保存状态。
- checkpoint 的执行原理:
1)、当RDD的job执行完毕后,会从finalRDD从后往前回溯。
2)、当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
3)、Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
- 优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。
- 使用:
1.SparkConf conf = new SparkConf();
2.conf.setMaster("local").setAppName("checkpoint");
3.JavaSparkContext sc = new JavaSparkContext(conf);
4.sc.setCheckpointDir("./checkpoint");
5.JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3));
6.parallelize.checkpoint();
7.parallelize.count();
8.sc.stop();相关文章:
Spark---转换算子、行动算子、持久化算子
一、转换算子和行动算子 1、Transformations转换算子 1)、概念 Transformations类算子是一类算子(函数)叫做转换算子,如map、flatMap、reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。 2)、Transf…...

什么是关系型数据库?
什么是关系型数据库? 关系型数据库(RDBMS)是建立在关系模型基础上的数据库系统。关系模型是一种数据模型,它表示数据之间的联系,包括一对一、一对多和多对多的关系。在关系型数据库中,数据以表格的形式存储…...
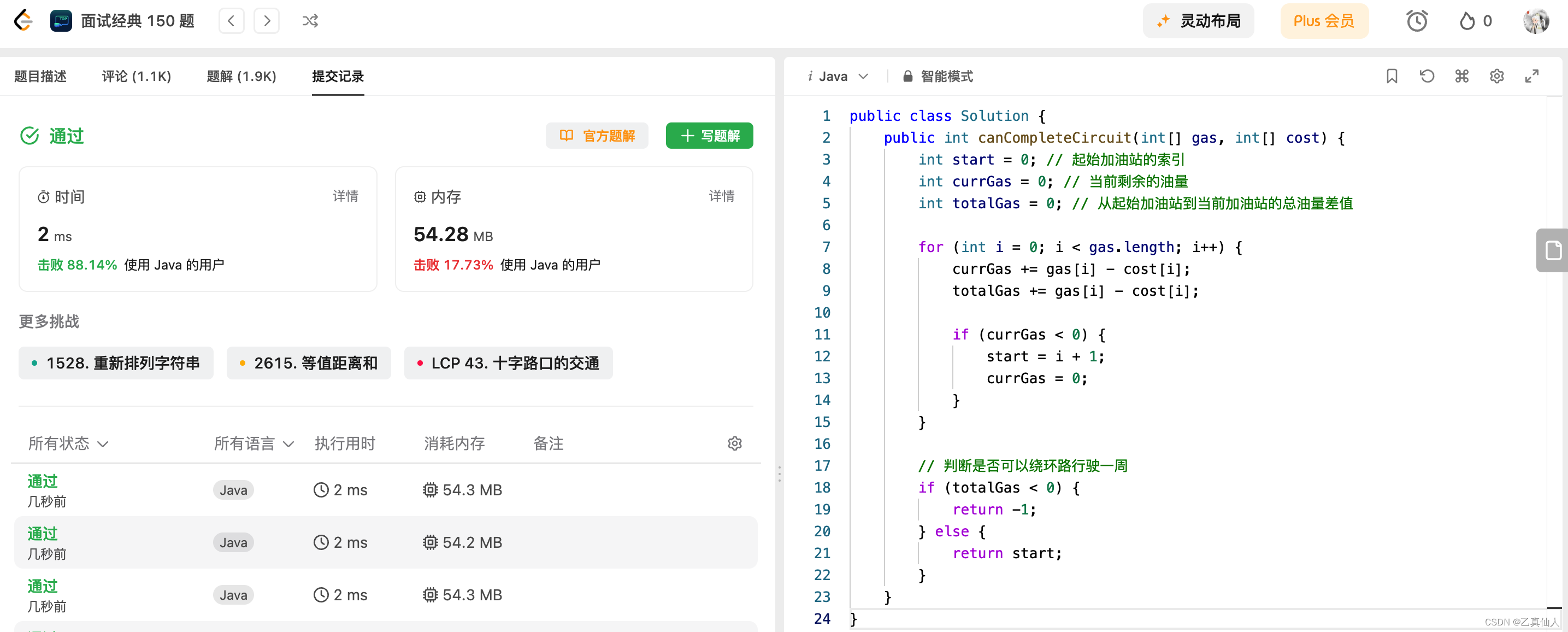
【LeetCode】挑战100天 Day12(热题+面试经典150题)
【LeetCode】挑战100天 Day12(热题面试经典150题) 一、LeetCode介绍二、LeetCode 热题 HOT 100-142.1 题目2.2 题解 三、面试经典 150 题-143.1 题目3.2 题解 一、LeetCode介绍 LeetCode是一个在线编程网站,提供各种算法和数据结构的题目&…...
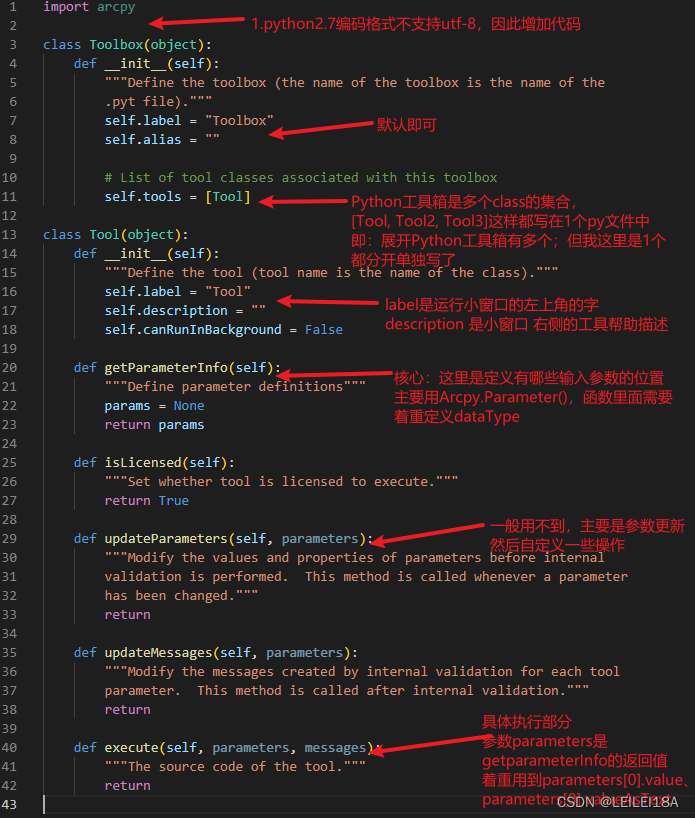
ArcGIS10.x系列 Python工具箱教程
ArcGIS10.x系列 Python工具箱教程 目录 1.前提 2.需要了解的资料 3.Python工具箱制作教程 4. Python工具箱具体样例代码(DEM流域分析-河网等级矢量化) 1.前提 如果你想自己写Python工具箱,那么假定你已经会ArcPy,如果只是自己…...
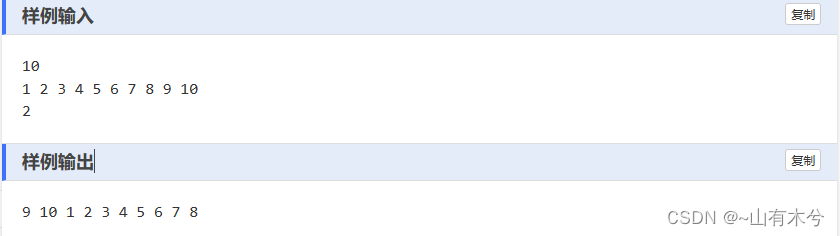
【蓝桥杯】刷题
刷题网站 记录总结刷题过程中遇到的一些问题 1、最大公约数与最小公倍数 a,bmap(int,input().split())sa*bwhile a%b:a,bb,a%bprint(b,s//b)2.迭代法求平方根(题号1021) #include<stdio.h> #include<math.h> int main() {double x11.0,x2;int a;scanf("%d&…...

软件产品登记的材料条件
(1)申请双软认证前应该要获得信息产业部授权的软件检测机构出具的检测证明,这份检测证明可以到软件行业协会申请,然后协会会派专家到公司进行“检测”,检测通过后出具证明,这份证明的申请与软件著作权等无关࿰…...

春节后跟进客户开发信模板?外贸邮件模板?
适合新年的客户开发信模板?年后给客户的邮件怎么写? 在春节这一传统的中国节日结束后,跟进客户对于维持和发展业务至关重要。客户开发信模板是一种有效的工具。蜂邮将介绍一些春节后跟进客户开发信模板的关键技巧,以确保您的业务…...

个人财务管理软件CheckBook Pro mac中文版特点介绍
CheckBook Pro mac是一款Mac平台的个人财务管理软件,主要用于跟踪个人收入、支出和账户余额等信息。 CheckBook Pro mac 软件特点 简单易用:该软件的用户界面非常简洁明了,即使您是初学者也可以轻松上手。 多账户管理:该软件支持…...

rfc4301- IP 安全架构
1. 引言 1.1. 文档内容摘要 本文档规定了符合IPsec标准的系统的基本架构。它描述了如何为IP层的流量提供一组安全服务,同时适用于IPv4 [Pos81a] 和 IPv6 [DH98] 环境。本文档描述了实现IPsec的系统的要求,这些系统的基本元素以及如何将这些元素结合起来…...
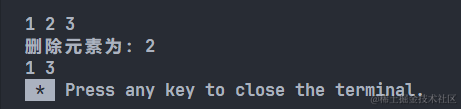
【数据结构/C++】线性表_双链表基本操作
#include <iostream> using namespace std; typedef int ElemType; // 3. 双链表 typedef struct DNode {ElemType data;struct DNode *prior, *next; } DNode, *DLinkList; // 初始化带头结点 bool InitDNodeList(DLinkList &L) {L (DNode *)malloc(sizeof(DNode))…...
前端已死?看看我的秋招上岸历程
背景 求职方向:web前端 技术栈:vue2、springboot(学校开过课,简单的学习过) 实习经历:两段,但都是实训类的,说白了就是类似培训,每次面试官问起时我也会坦诚交代&…...
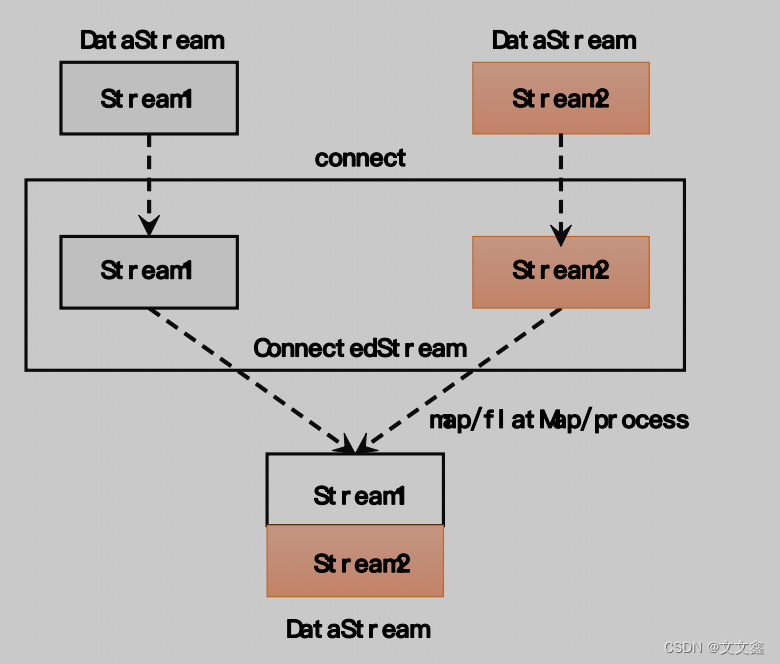
Flink Flink中的合流
一、Flink中的基本合流操作 在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以 Flink 中合流的操作会更加普遍,对应的 API 也更加丰富。 二、联合(Union) 最简单的合流操作…...

工业园区重金属废水深度处理工程项目,稳定出水0.1mg/l
随着环保要求不断提高,工业废水处理已成为众多企业的必修课。然而在工业生产中,如何有效处理含有重金属的废水成为了一个关键的挑战。 重金属废水是指含有汞、铅、铜、镉、锌、镍等有毒有害物质的废水,来源于矿山开采、金属冶炼、电镀、印刷线…...

element table滚动条失效
问题描述:给el-table限制高度之后滚动条没了 给看看咋设置的: <el-table:data"tableData"style"width: 100%;"ref"table"max-height"400"sort-change"changeSort">对比了老半天找不出问题,最后…...

代码随想录算法训练营 ---第四十六天
第一题: 简介: 本题的重点在于确定背包容量和物品数量 确定dp数组以及下标的含义 dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。 2.确定递推公式 如果确定dp[j] 是true,且…...
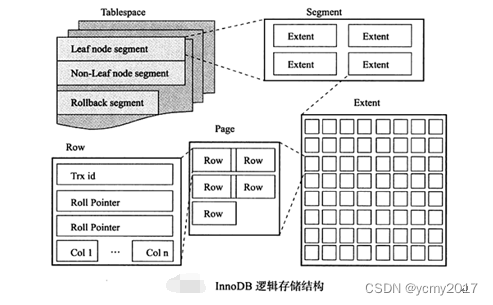
MySQL-02-InnoDB存储引擎
实际的业务系统开发中,使用MySQL数据库,我们使用最多的当然是支持事务并发的InnoDB存储引擎的这种表结构,下面我们介绍下InnoDB存储引擎相关的知识点。 1-Innodb体系架构 InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一…...
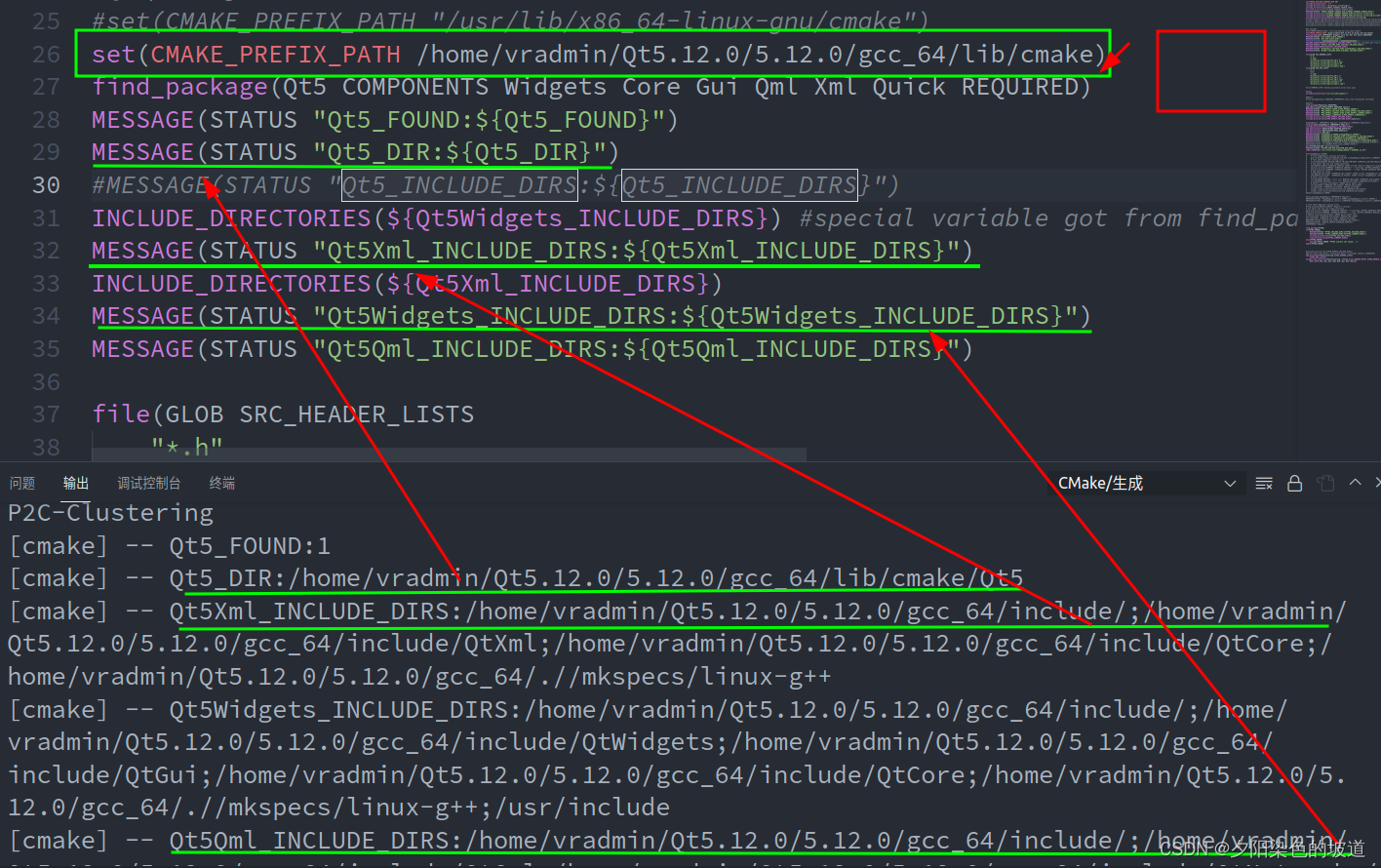
Qt路径和Anaconda中QT路径冲突(ubuntu系统)
最近做一个项目需要配置QT库,本项目配置环境如下: Qt version 5 Operating system, version and so on ubuntu 20.04 Description 之前使用过anaconda环境安装过QT5,所以在项目中CMakeLists文件中使用find_package时候,默认使用An…...

vue2.js添加水印
通过canvas生成水印图片 function addWaterMark(str) {let ctx document.createElement("canvas");ctx.width 900;ctx.height 450;ctx.style.display "none";let cans ctx.getContext("2d");cans.rotate((-20 * Math.PI) / 180);cans.font…...
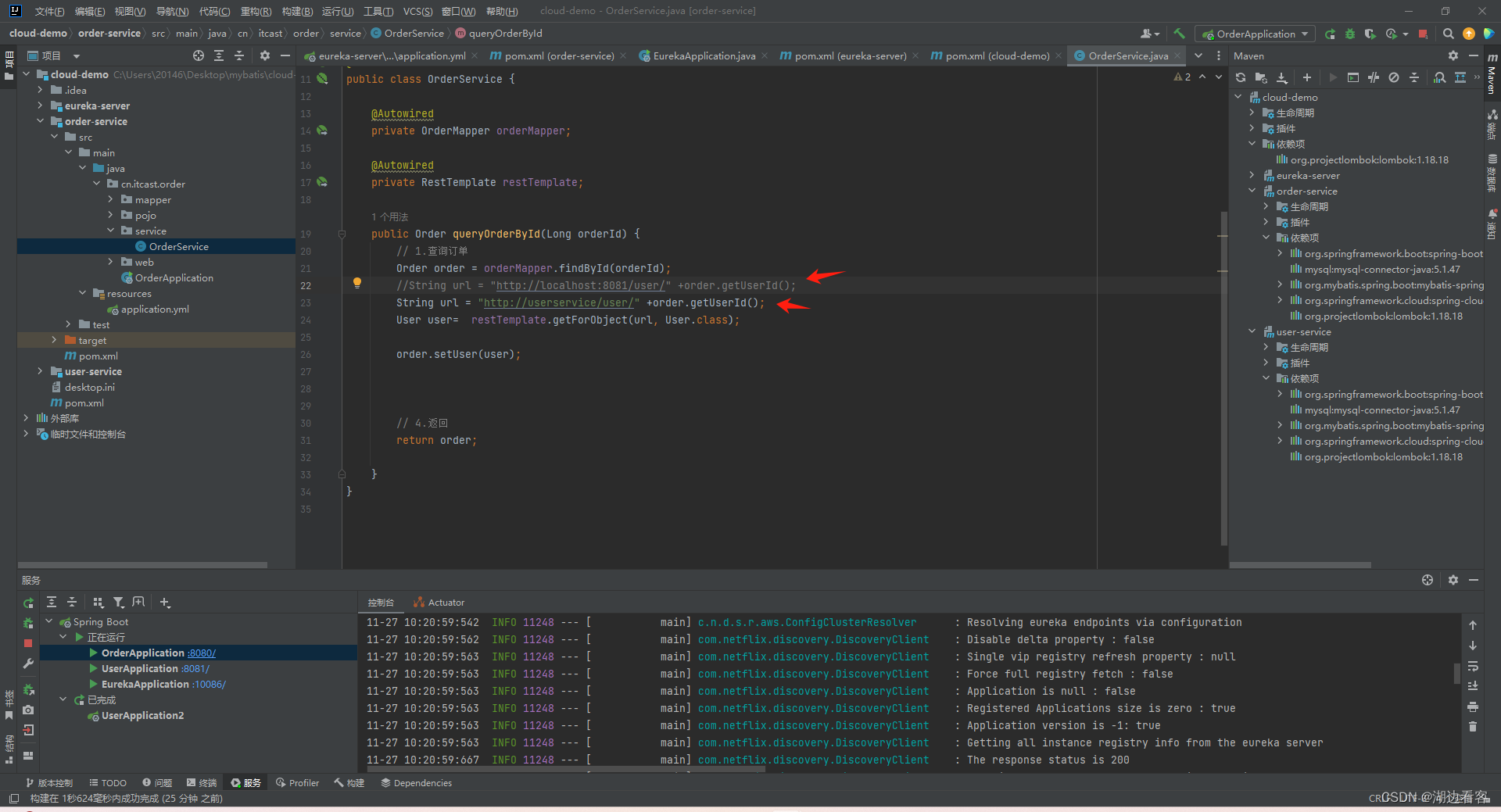
Eureka简单使用做微服务模块之间动态请求
创建一个eureka模块,引入eureka 为启动项加上EnableEurekaServer注解 配置信息 orderService和userService的操作是一样的 这里以orderService为例: 引入eureka客户端 加上 LoadBalanced注解 配置 orderService和userService都配置好了之后 启动 这样我们在http://localhos…...

竞赛选题 题目:基于深度学习卷积神经网络的花卉识别 - 深度学习 机器视觉
文章目录 0 前言1 项目背景2 花卉识别的基本原理3 算法实现3.1 预处理3.2 特征提取和选择3.3 分类器设计和决策3.4 卷积神经网络基本原理 4 算法实现4.1 花卉图像数据4.2 模块组成 5 项目执行结果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基…...

NCM解密终极指南:3步解锁网易云音乐加密音频的完整方案
NCM解密终极指南:3步解锁网易云音乐加密音频的完整方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他播放器播放而烦恼吗?这款高效专业的ncmdump工具让你轻松突…...

awesome-design-systems 中的电子商务设计系统:Shopify Polaris到Magento的案例
awesome-design-systems 中的电子商务设计系统:Shopify Polaris到Magento的案例 【免费下载链接】awesome-design-systems 💅🏻 ⚒ A collection of awesome design systems 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-des…...

FreakStudio俅
环境安装 pip install keystone-engine capstone unicorn 这3个工具用法极其简单,下面通过示例来演示其用法。 Keystone 示例 from keystone import * CODE b"INC ECX; ADD EDX, ECX" try:ks Ks(KS_ARCH_X86, KS_MODE_64)encoding, count ks.asm(CODE)…...

2026亲测:同时降重复率与AI率的实用工具推荐
现在国内高校和期刊普遍实行重复率AIGC率双重检测,单独只降重或者只消AI痕迹的工具已经很难满足需求。我们针对知网、维普、Turnitin等主流平台做了多轮复测,筛选出几款适配不同场景的高效工具,覆盖中英文论文、学生初稿到硕博定稿全需求。 一…...

从实验室到生产线:差动变压器和霍尔传感器在工业自动化中的选型与避坑指南
工业自动化中的位移检测双雄:差动变压器与霍尔传感器的实战选型指南 在机床主轴定位误差超过0.01mm就会导致零件报废的生产线上,在机械臂末端执行器需要实时反馈位置的精密装配场景中,位移传感器的选型直接决定了自动化系统的可靠性与精度。不…...

乙巳马年春联生成终端环境部署:HTTPS证书自动签发与更新
乙巳马年春联生成终端环境部署:HTTPS证书自动签发与更新 1. 项目背景与核心价值 想象一下,你正在筹备一个新年线上活动,需要向用户展示一个充满节日氛围的春联生成应用。这个应用不仅要有惊艳的视觉效果和强大的AI生成能力,更要…...

MetaBCI脑机接口开发终极指南:从零到精通的完整学习路径
MetaBCI脑机接口开发终极指南:从零到精通的完整学习路径 【免费下载链接】MetaBCI MetaBCI: China’s first open-source platform for non-invasive brain computer interface. The project of MetaBCI is led by Prof. Minpeng Xu from Tianjin University, China…...

SUPER COLORIZER与微信小程序结合:打造个人AI画师工具
SUPER COLORIZER与微信小程序结合:打造个人AI画师工具 你有没有想过,把那些老照片、线稿或者黑白涂鸦,变成色彩鲜艳的艺术作品?以前这需要专业的设计师和复杂的软件,但现在,每个人都能成为自己的画师。今天…...
)
新KS型单级单吸离心泵的设计(说明书+CAD图纸+调研报告+任务书+英文翻译)
新KS型单级单吸离心泵作为工业流体输送领域的核心设备,其设计聚焦于提升效率、降低能耗与延长使用寿命三大核心目标。该泵型通过优化叶轮几何结构与流道设计,显著减少流体在泵体内的能量损失,实现高效稳定的流量输出。其单级单吸结构简化了内…...

编程未来发展趋势
编程未来发展趋势:技术变革与无限可能 在数字化浪潮席卷全球的今天,编程作为技术发展的核心驱动力,正以前所未有的速度重塑世界。从人工智能的崛起到量子计算的突破,编程的未来充满无限可能。本文将探讨编程领域的三大发展趋势&a…...