全网最全卡方检验汇总
一文整理了卡方检验全部内容,包括卡方检验的定义(基本思想、卡方值计算、适用条件分析)、卡方检验分类(2*2四格表卡方、R*C表格卡方、配对卡方、卡方拟合优度检验、分层卡方)、卡方检验如何分析(数据格式、软件操作、结果解读、卡方多重比较)、卡方检验在其他方面的应用(多选题分析、logistic回归分析筛选变量、定类数据关系的可视化分析、趋势卡方判断是否有线性趋势)、对比分析(参数检验与非参数检验、差异性分析的其他方法等)5大部分内容。

- 卡方检验定义
- 基本思想
卡方检验又称独立性检验,是由数学家卡尔·皮尔逊发明的用于检验两变量是否相关的假设检验方法。其基本思想是统计样本的实际频数与理论频数的吻合程度,主要应用于定类数据和定类数据之间的关系分析,即我们常说的定类数据与定类数据之间的差异性研究。比如研究男生女生是否吸烟的差异。
卡方检验的基本思想也可以通过卡方值的基本公式来理解。 - 卡方值计算
(1)卡方值计算公式
卡方值基本公式——Pearson

(\chi^2=\sum\frac{(O-E)^2}E(\chi^2\geq0))
式中O为实际频数,E为理论频数,卡方值表示实际频数与理论频数之间的偏离程度。卡方值越大,则实际频数与理论频数的偏离程度越大。
同时,卡方值大小还受自由度的影响,自由度v越大,卡方值也会越大,所以只有考虑了自由度v的影响,卡方值才能正确反映实际频数与理论频数的偏离程度。
(2)卡方检验自由度
卡方检验的自由度与样本量n无关,取决于列联表中可以自由取值的格子个数,自由度计算公式v=(行数-1)*(列数-1)。比如四格表中有两行两列数据,自由度=(2-1)*(2-1)=1。
(3)理论频数计算
卡方值计算公式中涉及到理论频数的计算,卡方检验理论频数的计算是根据假设检验H0成立的前提下,计算所得的理论频数。
具体计算方法为:对于每个单元格,其理论频数E=(行合计×列合计)/总样本数n。也就是第R行第C列单元格的理论频数E= (第R行合计×第C列合计)/总样本量n。
- 适用条件判断
一般情况下,我们所说的卡方检验均为Pearson卡方,卡方值基本公式也为Pearson卡方值计算公式。除此之外,还有两种卡方值——yates连续性校正卡方和Fisher卡方值。
三种卡方值的选择,需要结合变量个数、样本量n、理论频数E分布情况等,选择最终应该使用的卡方值。具体选择标准如下:
- 针对2*2四格表(R=2,C=2)n>=40,且 E全部>=5则使用Pearson卡方;n>=40但其中有1个格子出现1<=E<5则使用yates连续性校正卡方;任何一格子出现E <1或n<40则使用Fisher卡方(仅2*2表格使用)。
- 针对R*C表格(R,C中任意一个大于2;且R>=2,且C>=2)E全部>1 且 1<=E<5格子的比例小于20% 则使用Pearson卡方,否则使用yates连续性校正卡方。
Yates连续性校正卡方公式:

- 卡方检验分类
卡方检验从使用频率角度分类来分的话可分为以下5类:独立样本2*2表格卡方检验(四格表卡方)、多独立样本R*C表格卡方检验、卡方拟合优度检验、配对设计资料卡方检验、分层卡方检验。接下来将分别进行说明。
- 独立样本2*2表格卡方检验
四格表卡方检验在日常研究是最常用的一种,用于比较两样本构成比是否有差异。四格表是一种常用的数据表格形式,表格由四个单元格组成,每个单元格代表一个分类变量的不同组合。四格表示例如下,表中的其余数据都可以用abcd这四个数据计算得到,所以也称为四格表资料。

四格表卡方检验除上面提到的基本公式外,还有一个四格表的特有公式:

(\chi^2=\frac{(ad-bc)^2n}{(a+b)(c+d)(a+c)(b+d)})
注意:
n>=40,且 E全部>=5则使用Pearson卡方;n>=40但其中有1个格子出现1<=E<5则使用yates连续性校正卡方;任何一格子出现E <1或n<40则使用Fisher卡方(仅2*2表格使用)。
- 多独立样本R*C表格卡方检验
R行,C列(R,C中任意一个大于2)表格资料卡方检验,用于分析两定类数据之间的差异性,与四格表卡方检验类似,但无法确定具体哪两组数据之间存在差异,需要进行多重比较,常采用Bonferroni法进行两两组别之间的多重比较。SPSSAU卡方检验会自动输出多重比较分析结果。
资料示例:下图展示了3*2表格卡方检验结果:

利用卡方检验研究不同疗法的治疗效果的差异性,从上表可以看出:卡方值为21.038,p值小于0.05,说明不同疗法的治疗效果呈现出显著差异性。具体两两组别的差异性可查看下方多重比较结果。

分析上表可知,外用膏药组、物理疗法组、药物治疗组,两两组别之间进行多重比较,治疗效果均呈现出显著差异性。
3、卡方拟合优度
卡方拟合优度用于分析数据的实际比例与预期比例是否一致,它只针对于类别数据,比如性别、职业、学历等。比如预期收集的样本男女比例为6:4,那么预期比例与实际收集的样本男女比例是否一致?就可以使用卡方拟合优度检验分析。
同时,卡方拟合优度检验常用于问卷多选题分析,用于分析多选题选项被选择比例是否有差异。后面在卡方检验应用部分也会进行详细说明。
资料示例:下图展示了卡方拟合优度检验结果:

针对体型进行卡方拟合优度检验,研究样本数据分布是否与期望分布保持一致,从上表可以看出:体型全部均没有呈现显著性(卡方值为7.018,p>0.05),说明样本体型分布与预期比例一致。
4、配对设计资料卡方检验
配对卡方检验用于分析两配对定类数据的差异,比如使用两种方法对同一批患者进行诊断(诊断结果为阳性&阴性),判断两种方法的诊断结果是否有差异,可以使用配对卡方检验进行分析。
资料示例:下图展示了配对卡方检验结果:

分析上表可知,使用配对卡方检验分析甲法、乙法诊断结果的差异性,从配对卡方分析结果可以看出,p=0.022<0.05,说明甲、乙两种方法的检测结果有显著差异。
5、分层卡方检验
分层卡方是在卡方检验基础上进一步考虑分层项的干扰(混杂因素)。比如想要调查某一地区接种疫苗(X)对感染病毒 (Y)的影响,由此来判断疫苗的有效性;但考虑到男性、女性体质的不同,疫苗可能会造成不一样的抵抗病毒能力,因此将性别 (Z)作为分层项来进行分析。就可以使用分层卡方检验进行分析。
针对分层卡方,涉及到的理论知识比较多,如下表格说明:

通常情况下,首先查看‘比值比齐性检验’,如果其呈现出显著性(p 值小于0.05),则说明具有混杂因素,即需要考虑分层项,即分别查看不同分层项下的数据结果。反之如果没有通过‘比值比齐性检验’,即说明没有混杂因素不需要考虑分层项,报告整体的结果即可(包括卡方检验,以及OR值)。
对于分层卡方检验的更多内容,建议参考SPSSAU帮助手册说明,内容较多,不在这里进行说明。https://spssau.com/helps/medicalmethod/layerchi.html
- 卡方检验分析
上面介绍了5类卡方检验及其简单的分析过程,接下来通过一个具体的卡方检验的示例,详细介绍一下卡方检验的分析过程。包括卡方检验需要的数据格式、软件的操作、分析结果的详细解读、具体差异的对比、效应量的分析、多重比较如何分析等。
- 数据格式
使用软件进行卡方检验分析时,需要注意卡方检验的数据格式。一般来讲可分为3种,分别是常规格式、加权格式、列联表格式。
- 常规格式
一行代表一个样本,一列代表一个属性,将全部的原始数据信息列出即可,使用数字代表定类数据的类别,如下图所示:

- 加权格式
在实际研究中,很多时候没有原始数据,此时就应该使用汇总数据,即带加权项的数据。比如下图中X分为2类,Y分为3类,一种有2*3=6种组合,数据信息只有6种组别的汇总项(即加权项),分别是40,10,20,30,20,50;相当于总共有170个样本,如果是使用常规格式(即非加权格式),此时应该有170行;但加权格式则只需要6行即可表示,如下图所示:

- 列联表格式
以上两种数据格式是非常常用的,除此之外,在使用SPSSAU的Fisher卡方进行分析时,还会涉及到列联表格式数据。其本质也是加权数据的一种类型,只是以列联表的形式直接输入到软件中进行分析。在编辑数据时需要注意,A1单元格一定要空着,并且放入的数据不包括合计数据。如下图所示:

- 软件操作
(1)SPSSAU位置
SPSSAU在以下6个部分提供卡方检验的不同方法,如下图:

①SPSSAU【通用方法】->【交叉(卡方)】,此处分析最为简单,仅提供卡方检验结果,以及相应的可视化图形,不会输出额外的指标及计算过程等。
②SPSSAU【实验/医院研究】模块,提供【卡方检验】【配对卡方】【卡方拟合优度】【分层卡方】【Fisher卡方】5类卡方检验。
(2)SPSSAU操作
以R*C表格卡方检验为例,使用SPSSAU【实验/医学研究】模块【卡方检验】进行分析。
案例背景:某年级想要研究重点班与普通班学习成绩(优秀、及格、不及格)之间是否有差异,以及具体的差异在哪部分,收集的数据如下:

分析:很显然,这是一个2*3表格资料卡方检验,从已知数据可知,数据格式为加权格式,故将数据整理成如下格式:

上传数据至SPSSAU系统,在【实验/医学研究】模块,选择【卡方检验】,拖拽变量至右侧相应分析框,操作如下图:

【提示】:从实际意义上来讲,卡方检验是会区分X与Y的,但是在算法角度是不区分X与Y的。放置位置不同只会影响表格的输出格式,不会影响卡方检验分析结果。分析时可选择“百分比(按列)”或者“百分比(按行)”,二者的差别在于表格内数据按行加和为100%还是按列加和为100%,试个人分析角度决定,无固定标准,并不会影响卡方检验的分析结果。
3、结果解读
本案例数据卡方检验分析结果如下:

(1)先看p值
首先看p值是否呈现出显著性(p值小于0.05或小于0.01),若呈现出显著性则说明应该拒绝原假设(卡方检验原假设为两定类数据之间无差异)。若p值大于0.05,则无差异,分析停止。本案例卡方值为32.752,对应p值小于0.01,说明差异具有显著性,即普通班与重点班的成绩具有显著差异。
(2)具体差异对比
- 括号内百分比对比
分析具有显著差异时,具体可对比卡方检验结果中括号内百分比描述具体差异。本案例数据按列加和为100%,具体分析可知:普通班中,成绩及格人数占比最高为50%,优秀人数占比最少为23.684%。重点班中,成绩优秀的人数占比最高为64.516%,不及格人数占比最少为16.129%。同时也可以结合SPSSAU可视化图案进行直观对比,如下图:

如果想要横向对比,也可以在分析时选择“百分比(按行)”,在这里不再过多阐述。除使用括号内百分比具体对比差异,还可使用效应量指标描述差异幅度。
- 效应量指标
卡方检验的效应量指标主要用于分析两个或多个分类变量之间的差异幅度,它的取值范围在0到1之间,效应量值越大说明差异幅度越大,通常情况下效应量小、中、大的区分临界点分别是: 0.20、0.50和0.80。
SPSSAU卡方检验默认会提供5类效应量指标,本文对各指标具体原理和计算公式不做深入探讨,SPSSAU输出效应量指标结果如下:

效应量指标的选择需要结合交叉表格类型以及数据类型进行选择,选择标准如下:

本案例为2*3表格,应该使用Cramer V指标。Cramer V值为0.405,表示重点班和普通班的成绩存在中等程度的差异。
(3)多重比较
卡方检验的结果只能知道整体是否存在差异,无法对比两两组合之间的差异情况,如果需要具体对比两两组合之间的差异,需要使用多重比较进行分析。多重比较的次数=C(X类别个数)*C(Y类别个数),比如X类别为3,Y类别个数为5,则为C(3,2)*C(5,2)=30次。
在多重比较时,通常使用Pearson卡方检验。然而,随着多重比较次数的增加,一类错误的概率也会增加。因此,建议在显著性水平为0.05的情况下,使用校正显著性水平(Bonferroni校正)来进行分析。例如,如果两两比较次数为3次,那么Bonferroni校正显著性水平为0.05/3次=0.0167,即p值需要与0.0167进行对比,而不是0.05。
比如本案例中,要分析具体差异在于优秀与及格之间,还是优秀与不及格之间,或者及格与不及格之间,查看多重比较结果如下:

从上表可以看出,普通班与重点班成绩不及格与优秀之间、优秀与及格之间的差异均呈现出显著性(p值小于Bonferroni校正显著性水平为0.0167)。而成绩不及格与及格之间差异并未呈现出显著性,那么可以认为,普通班与重点班的成绩差异主要在于优秀成绩的人数上。
(4)卡方检验统计量过程值
在前面讲卡方检验适用条件时有提到3类卡方统计量的选择问题(非专业选手可忽略),SPSSAU【实验/医学研究】模块的【卡方检验】结果会自动输出卡方检验统计量过程值,用于判断卡方统计量,如下图:

分析上表可知,本案例数据为2*3表格,理论频数E≥5格子占比为100%,因此使用Pearson卡方,即本案例输出的卡方结果为Pearson卡方。
四、卡方检验应用
卡方检验不仅可用于差异性分析,在其他方面均有不同的应用。比如用于问卷多选题分析、logistic回归分析前筛选变量、可视化分析、判断是否存在线性趋势等,接下来将分为进行介绍。
1、多选题分析
多选题分析:首先在单独对多选题进行分析时,使用的是卡方拟合优度检验,分析多选题的各选项被选择比例是否一致,如下图,为SPSSAU多选题分析结果:

从卡方拟合优度检验结果可以看出,各选项被选择比例有显著差异,百分比选择分布不均匀(卡方值为225.749,p=<0.05)。
单选-多选分析:在进行单选题与多选题的交叉分析时,也会涉及到卡方检验(具体为Pearson卡方),如下图,为SPSSAU单选-多选分析结果:

从卡方检验结果可以看出,对于共6项表示的多选题,性别并未表现出显著的差异性,即男性和女性选择课程的原因并不存在差异性。
同理,多选-多选交叉分析中,也涉及卡方检验,在此不再进行赘述。
2、logistic回归分析
当因变量Y为定类数据时,研究X对Y的影响关系应该使用logistic回归分析。当自变量非常多时,首先应该进行自变量的筛选,筛选出对Y有影响的X放入回归模型中。当自变量为定量数据时,使用方差分析或t检验进行变量的筛选;当X为定类数据时,应该使用卡方检验进行变量的筛选。在进行筛选时,如果害怕遗漏重要变量,那么可以适当将p值放大,如以0.1或0.15为标准,将p值大于0.15的变量排除在外。
举例:对二元logistic回归分析的因变量Y与定类变量X1-X4进行卡方检验,结果如下:

从上表可知,除X4外,X1、X2、X3与Y之间的差异均为呈现出显著性,那么在进行logistic回归分析前,就需要考虑是否有必要将X1、X2、X3放入模型中。
3、可视化分析
(1)交叉汇总图
卡方检验的选择百分比差异性可通过图形进行直观的展示,SPSSAU进行卡方检验时也会自动输出对应的交叉图,比较基础的如柱形图、条形图、堆积柱形图、堆积条形图等。
SPSSAU输出交叉图如下,可通过右上角按钮切换图形展示方式。

(2)对应分析
除基础的柱形图外,与卡方检验相关的可视化图形还有对应分析中得到的对应图。如果希望使用图形直观展示关系情况,也或者想研究多个分类数据间的关系,并且使用图形直观展示,而且还需要看出类别间的具体关系情况。此时则可以使用对应分析。
对应分析是一种视觉化的数据分析方法,它能够将几组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来。其基本思想是将一个列联表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
举例说明:研究不同收入水平人群收集品牌偏好的差异,使用SPSSAU【问卷研究】模块的【对应分析】进行分析,得到分析结果包括“对应表”以及“对应图”分别如下:

可以看到,对应表分析结果即为卡方检验的分析结果。

对应图的分析:
①离原点越远,意味着该点对于‘关系幅度’的表达越强,即说明该点越能体现出‘关系’。
②点与点之间挨着越近,意味着它们之间关联关系越强;点与点之间挨着越远,意味着它们之间关联关系越弱。
分析上图可知,低收入群体与手机B、E品牌之间有着较强关系;中等收入群体与手机D品牌之间有着较强关系;高收入群体与A、C、F这3个手机品牌之间有着较强关系。另外,低收入和B、E品牌,它们离原点的距离较远,意味着低收入与B、E品牌之间的关系非常明显。
4、趋势卡方检验线性趋势
卡方检验还可用于分析列联表数据的趋势差异关系,具体方法为Cochran-Armitage 趋势卡方检验。比如你想要分析患肺癌的比例是否会随着年龄的增大而出现增加的趋势(这里年龄为分阶段的定类数据),就可以使用Cochran-Armitage 趋势卡方检验进行分析。
Cochran-Armitage 趋势卡方检验通常用于k*2(或2*k)的列联表结构,k为有序定类数据,2指两个类别。如果p值小于0.05则说明k组间呈现出某种趋势变化;如果p值大于0.05则说明k组间不会呈现出趋势变化。
在SPSSAU【卡方检验】进行分析时,默认会输出Cochran-Armitage 趋势卡方检验结果,如下图:

从上表可知,趋势卡方检验p值大于0.05,说明不同年龄段患肺癌的比例并没有呈现出趋势变化。若呈现出趋势变化,则可对比卡方检验结果中的百分比进行具体描述。
五、参数检验与非参数检验
很多同学不明白为什么卡方检验属于非参数检验,下面简单补充一下参数检验与非参数检验的内容。
1、基本说明
参数检验是假定样本总体为某一已知分布的情况下,对总体参数如均值或者方差进行估计和检验的方法。与参数检验相对的是非参数检验,非参数检验并不对总体的分布形态做假定,此时不能进行参数间的比较,而是做分布间的比较。
2、对比

(1)检验指标对比
参数检验:假设数据服从某种特定的分布,例如正态分布,并且总体参数是已知的。因此,参数检验通常关注的是样本均值与总体均值的差异,以检验样本数据是否符合预期的分布。
非参数检验:不需要数据符合特定的分布,而是基于数据本身的分布来推断总体参数。非参数检验通常关注的是数据的次序而不是具体的值,例如中位数、四分位数等。
(2)优缺点对比
参数检验:优点在于符合条件时,检验效率高。然而,它对数据的要求较为严格,如等级数据、非确定数据不能使用参数检验,而且要求数据的分布型已知和总体方差相等。此外,参数检验不适用于样本量较小且分布未知的情况。当样本量足够大时,参数检验的方法对非正态分布的数据也能够很好地进行处理,因为样本均值的分布根据中心极限定理是近似正态分布。
非参数检验:优点在于不受总体分布的限制,对数据的要求不严格,应用范围广、简便、易掌握。缺点在于若对符合参数检验条件的数据用非参数检验,则检验效率低于参数检验。非参数检验主要使用等级或者符号秩,而不是使用原始数据,会损失部分信息,降低统计检验效率,导致犯第二类错误的概率比参数检验大。此外,当样本量较小且分布未知时,通常会考虑使用非参数检验。
3、常用方法对比
常用方法对比如下:

4、差异性分析的其他方法
卡方检验用于分析定类数据之间的差异性,如果要分析定类与定量数据之间的差异性,应该使用方差分析或者t检验进行分析。对比说明如下:

相关文章:
全网最全卡方检验汇总
一文整理了卡方检验全部内容,包括卡方检验的定义(基本思想、卡方值计算、适用条件分析)、卡方检验分类(2*2四格表卡方、R*C表格卡方、配对卡方、卡方拟合优度检验、分层卡方)、卡方检验如何分析(数据格式、…...
)
Java基础-中级-高级面试题汇(一)
第一部分: Java基础面试题汇总 1.面向对象和面向过程的区别? 面向对象和面向过程是两种不同的编程思想。面向对象是一种以对象为中心的编程思想,将数据和处理数据的方法封装在一起,形成一个类。程序通过创建对象来调用类中的方法…...

数据结构 / day04 作业
1. 单链表任意位置删除, 单链表任意位置修改, 单链表任意位置查找, 单链表任意元素查找, 单链表任意元素修改, 单链表任意元素删除, 单链表逆置 // main.c#include "head.h"int main(int argc, const char *argv[]) {Linklist headNULL; //head 是头指针// printf(&q…...
Java核心知识点整理大全20-笔记
目录 17. 设计模式 17.1.1. 设计原则 17.1.24. 解释器模式 18. 负载均衡 18.1.1.1. 四层负载均衡(目标地址和端口交换) 18.1.1.2. 七层负载均衡(内容交换) 18.1.2. 负载均衡算法/策略 18.1.2.1. 轮循均衡(Roun…...

Spark---转换算子、行动算子、持久化算子
一、转换算子和行动算子 1、Transformations转换算子 1)、概念 Transformations类算子是一类算子(函数)叫做转换算子,如map、flatMap、reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。 2)、Transf…...

什么是关系型数据库?
什么是关系型数据库? 关系型数据库(RDBMS)是建立在关系模型基础上的数据库系统。关系模型是一种数据模型,它表示数据之间的联系,包括一对一、一对多和多对多的关系。在关系型数据库中,数据以表格的形式存储…...
【LeetCode】挑战100天 Day12(热题+面试经典150题)
【LeetCode】挑战100天 Day12(热题面试经典150题) 一、LeetCode介绍二、LeetCode 热题 HOT 100-142.1 题目2.2 题解 三、面试经典 150 题-143.1 题目3.2 题解 一、LeetCode介绍 LeetCode是一个在线编程网站,提供各种算法和数据结构的题目&…...
ArcGIS10.x系列 Python工具箱教程
ArcGIS10.x系列 Python工具箱教程 目录 1.前提 2.需要了解的资料 3.Python工具箱制作教程 4. Python工具箱具体样例代码(DEM流域分析-河网等级矢量化) 1.前提 如果你想自己写Python工具箱,那么假定你已经会ArcPy,如果只是自己…...
【蓝桥杯】刷题
刷题网站 记录总结刷题过程中遇到的一些问题 1、最大公约数与最小公倍数 a,bmap(int,input().split())sa*bwhile a%b:a,bb,a%bprint(b,s//b)2.迭代法求平方根(题号1021) #include<stdio.h> #include<math.h> int main() {double x11.0,x2;int a;scanf("%d&…...

软件产品登记的材料条件
(1)申请双软认证前应该要获得信息产业部授权的软件检测机构出具的检测证明,这份检测证明可以到软件行业协会申请,然后协会会派专家到公司进行“检测”,检测通过后出具证明,这份证明的申请与软件著作权等无关࿰…...

春节后跟进客户开发信模板?外贸邮件模板?
适合新年的客户开发信模板?年后给客户的邮件怎么写? 在春节这一传统的中国节日结束后,跟进客户对于维持和发展业务至关重要。客户开发信模板是一种有效的工具。蜂邮将介绍一些春节后跟进客户开发信模板的关键技巧,以确保您的业务…...

个人财务管理软件CheckBook Pro mac中文版特点介绍
CheckBook Pro mac是一款Mac平台的个人财务管理软件,主要用于跟踪个人收入、支出和账户余额等信息。 CheckBook Pro mac 软件特点 简单易用:该软件的用户界面非常简洁明了,即使您是初学者也可以轻松上手。 多账户管理:该软件支持…...

rfc4301- IP 安全架构
1. 引言 1.1. 文档内容摘要 本文档规定了符合IPsec标准的系统的基本架构。它描述了如何为IP层的流量提供一组安全服务,同时适用于IPv4 [Pos81a] 和 IPv6 [DH98] 环境。本文档描述了实现IPsec的系统的要求,这些系统的基本元素以及如何将这些元素结合起来…...
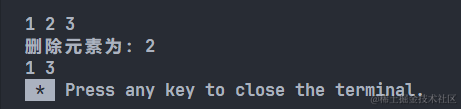
【数据结构/C++】线性表_双链表基本操作
#include <iostream> using namespace std; typedef int ElemType; // 3. 双链表 typedef struct DNode {ElemType data;struct DNode *prior, *next; } DNode, *DLinkList; // 初始化带头结点 bool InitDNodeList(DLinkList &L) {L (DNode *)malloc(sizeof(DNode))…...
前端已死?看看我的秋招上岸历程
背景 求职方向:web前端 技术栈:vue2、springboot(学校开过课,简单的学习过) 实习经历:两段,但都是实训类的,说白了就是类似培训,每次面试官问起时我也会坦诚交代&…...
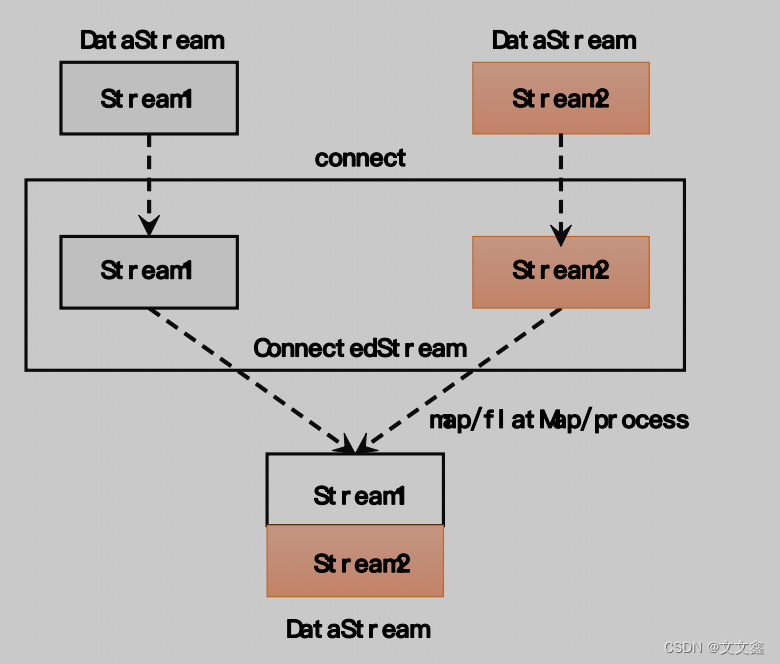
Flink Flink中的合流
一、Flink中的基本合流操作 在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以 Flink 中合流的操作会更加普遍,对应的 API 也更加丰富。 二、联合(Union) 最简单的合流操作…...

工业园区重金属废水深度处理工程项目,稳定出水0.1mg/l
随着环保要求不断提高,工业废水处理已成为众多企业的必修课。然而在工业生产中,如何有效处理含有重金属的废水成为了一个关键的挑战。 重金属废水是指含有汞、铅、铜、镉、锌、镍等有毒有害物质的废水,来源于矿山开采、金属冶炼、电镀、印刷线…...

element table滚动条失效
问题描述:给el-table限制高度之后滚动条没了 给看看咋设置的: <el-table:data"tableData"style"width: 100%;"ref"table"max-height"400"sort-change"changeSort">对比了老半天找不出问题,最后…...

代码随想录算法训练营 ---第四十六天
第一题: 简介: 本题的重点在于确定背包容量和物品数量 确定dp数组以及下标的含义 dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。 2.确定递推公式 如果确定dp[j] 是true,且…...
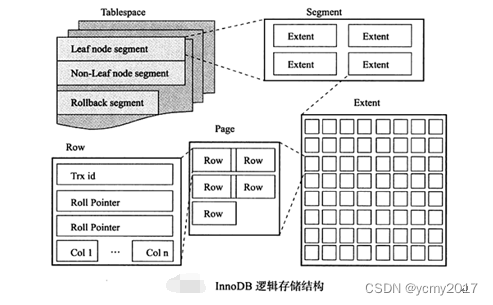
MySQL-02-InnoDB存储引擎
实际的业务系统开发中,使用MySQL数据库,我们使用最多的当然是支持事务并发的InnoDB存储引擎的这种表结构,下面我们介绍下InnoDB存储引擎相关的知识点。 1-Innodb体系架构 InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一…...

OpenMetrics安全指南:保护你的监控数据免受威胁
OpenMetrics安全指南:保护你的监控数据免受威胁 【免费下载链接】OpenMetrics Evolving the Prometheus exposition format into a standard. 项目地址: https://gitcode.com/gh_mirrors/op/OpenMetrics OpenMetrics作为Prometheus exposition format的标准化…...

RDM接收端避坑指南:从哑音状态处理到UID校验,我的调试血泪史
RDM接收端避坑指南:从哑音状态处理到UID校验,我的调试血泪史 灯光控制系统的开发者们,如果你正在为RDM协议接收端的稳定性头疼不已,这篇文章或许能帮你省下几周的通宵调试时间。在实际工程中,协议文档的"理想情况…...

OpCore-Simplify黑苹果配置革命:从复杂到简单的10分钟解决方案
OpCore-Simplify黑苹果配置革命:从复杂到简单的10分钟解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为繁琐的OpenCore配置而…...

uniapp中SQLite表缺失问题的排查与解决——以“no such table”错误为例
1. 初识"no such table"错误:从报错信息说起 第一次在uniapp开发中遇到SQLite的"no such table"错误时,我盯着控制台输出的-1404错误代码足足愣了三分钟。控制台清晰地显示着: { "code": -1404, "message…...

Uplift模型评估避坑指南:为什么你的AUUC指标总是不准?
Uplift模型评估避坑指南:为什么你的AUUC指标总是不准? 在营销优化和个性化干预场景中,Uplift模型的价值已得到广泛认可。但当我们满怀期待地将模型投入实际应用时,常常发现AUUC指标的评估结果与业务效果存在明显偏差——这就像精心…...

对前端总体结构的认识
前端:qian/ — Vue 3 SPA 前端是一个轻量级的单页应用,使用带有 <script setup> 语法的 Vue 3 组合式 API。它作为面向用户的界面,提供认证、题目浏览和代码提交功能。 文件结构 qian/ ├── index.html ← …...

桌面端 Claw 个人微信接入指南焕
1.概述在人工智能快速发展的今天,AI不再仅仅是回答问题的聊天机器人,而是正在演变为能够主动完成复杂任务的智能代理。OpenAI的Codex CLI就是这一趋势的典型代表——一个跨平台的本地软件代理,能够在用户的机器上安全高效地生成高质量的软件变…...

ExBody2: Generalist-Specialist Architecture for Expressive Humanoid Control
目录 Part I: Theoretical Foundations and Methodology 第一部分:理论基础与方法论 1.1 Architectural Overview of the Generalist-Specialist Framework 1.1.1 Paradigm Motivation and Design Philosophy 1.1.2 Two-Stage Training Paradigm 1.2 Generalist Phase: L…...

2026届毕业生推荐的十大降重复率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 能有效把文本被认作是AIGC也就是人工智能生成内容的概率给降下来的做法,是要从语…...

赛博朋克2077存档编辑器完全指南:掌握夜之城的数据控制权
赛博朋克2077存档编辑器完全指南:掌握夜之城的数据控制权 【免费下载链接】CyberpunkSaveEditor A tool to edit Cyberpunk 2077 sav.dat files 项目地址: https://gitcode.com/gh_mirrors/cy/CyberpunkSaveEditor 你是否曾想在《赛博朋克2077》中拥有上帝般…...