Node.js入门指南(二)
目录
http模块
创建http服务端
浏览器查看 HTTP 报文
获取 HTTP 请求报文
设置响应报文
网页资源的基本加载过程
静态资源服务
hello,大家好!上一篇文章我们对Node.js进行了初步的了解,并介绍了Node.js的Buffer、fs模块以及path模块。这一篇文章主要介绍Node.js的http模块。
http模块
创建http服务端
首先需要导入http模块,接着创建服务对象,调用http中的createsServer方法,该方法会传入两个形参,request以及response。request会接受请求报文的封装对象,能够通过该对象获取到请求头,请求行以及请求体。response会传入对响应报文的封装对象,它能够设置响应头,响应行以及响应体。当我们在浏览器发送http请求时,该回调函数就会执行。
// 导入http模块
const http=require('http');
// 创建服务对象
const server=http.createServer((request,response)=>{//设置响应体response.end('Hello http server');
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})server.listen用于设置监听的端口号,当我们成功运行js文件时,我们就可以通过本地的9000端口访问到我们设置的响应体了。以下有一些注意事项:
1️⃣命令行 ctrl + c 停止服务。
2️⃣当服务启动后,更新代码必须重启服务才能生效。
3️⃣响应内容中文乱码的解决办法 response.setHeader('content-type','text/html;charset=utf-8');
4️⃣当端口号被占用时,可以关闭当前正在运行监听端口的服务,或者修改其他端口号。
5️⃣HTTP 协议默认端口是 80 。HTTPS 协议的默认端口是 443, HTTP 服务开发常用端口有 3000,8080,8090,9000 等。
6️⃣如果端口被其他程序占用,可以使用 资源监视器 找到占用端口的程序,然后使用任务管理器 关闭对应的程序。
浏览器查看 HTTP 报文
学会使用浏览器来查看我们的http报文是非常重要的,对于后续我们的调试会起到很大的作用。当我们向服务端发送get请求时,我们如何查询对应的请求头请求行以及请求体呢?我们还是以上面的代码为例向9000端口发送请求。
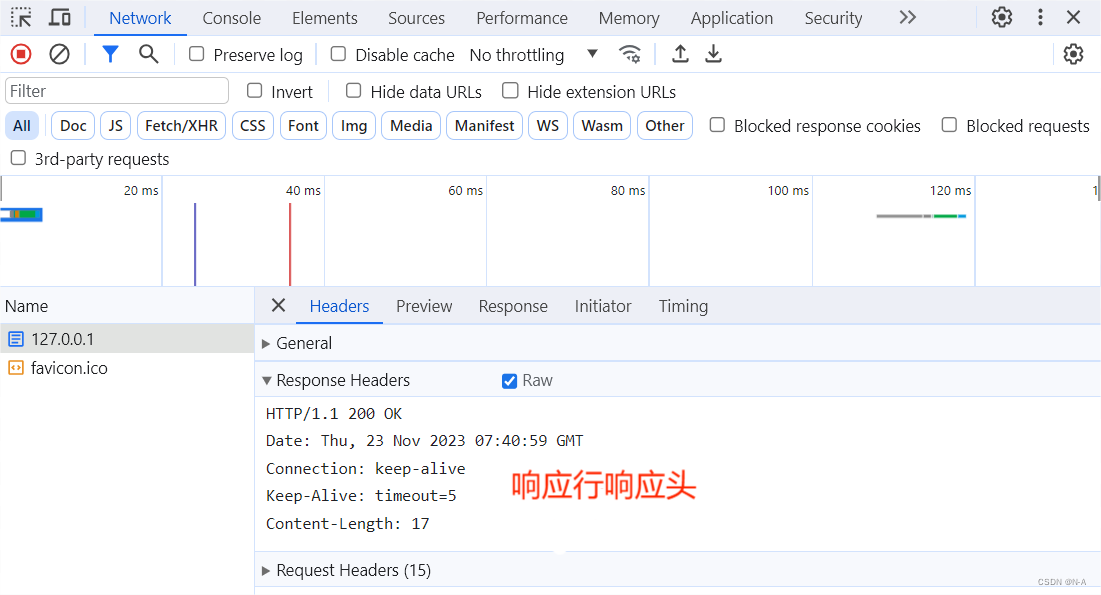
点击Network,然后发送请求之后会有显示,点击127.0.0.1,然后在点击Headers部分,点击Response Heasers,然后再点击Raw就可以清晰地看到相应的响应头和响应行。

然后点击Response,可以看到相应的响应体信息。
由于我们再向该端口号发送一个post请求,并携带对应的参数,来查看相应的请求头,请求行和请求体。对应大代码如下:
<form action="http://127.0.0.1:9000" method="post"><input type="text" name="username"><input type="text" name="password"><input type="submit" value="提交">
</form>
同样步骤,我们点击Request Headers进行查看请求行和请求头。由于我们携带了相应的数据,因此会多出一个Payload的部分,我们点击它就是我们的请求体。
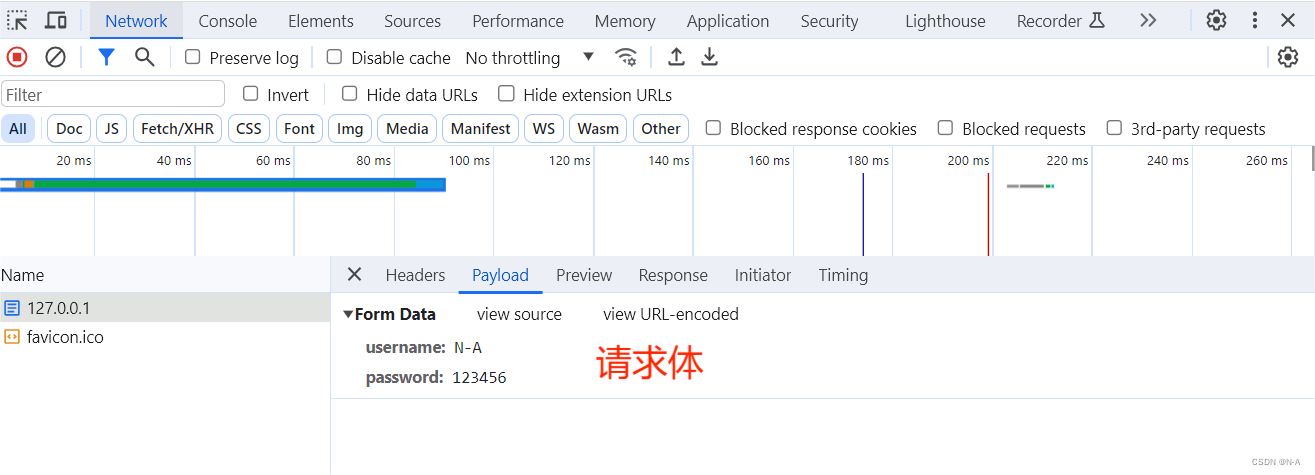
Payload的部分除了可以查看我们请求体的内容,还可以查看我们url中查询字符串的内容,这里就不做演示,感兴趣的小伙伴可以自行实践。
获取 HTTP 请求报文
我们可以通过使用 request 对象来获取请求方法,请求的url,获取协议的版本号以及获取http的请求头等信息。注意:获取请求的url,不会包括协议,域名端口号等信息,只会包含url中的路径以及查询的字符串。
// 导入http模块
const http=require('http');
// 创建服务对象
const server=http.createServer((request,response)=>{//获取请求方法console.log(request.method);//获取请求的url,只会包括url中的路径与查询字符串console.log(request.url);//获取协议的版本号console.log(request.httpVersion);//获取http的请求头console.log(request.headers);//设置响应体response.end('Hello http server');
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})我们还可以获取请求体中的内容,我们通过给request对象绑定data事件以及end事件来实现请求体的获取,当我们发送get请求时,它的请求体会是空的。因此我们使用上面的表单发起post请求,只有我们会在控制台看到输出相应的请求体信息。username=N-A&password=123456。该方式了解即可后续还会提供更加简便的方式。
// 导入http模块
const http=require('http');
// 创建服务对象
const server=http.createServer((request,response)=>{//声明一个变量let body='';//绑定data事件request.on('data',chunk=>{body+=chunk;})//绑定end事件request.on('end',()=>{console.log(body);//username=N-A&password=123456//响应response.end('Hello http server');})});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})对于我们得到的请求路径以及请求的查询字符串是非常重要的,我们可以通过获取相应的请求路径以及查询的字符串向浏览器返回不同的内容。因此我们可以导入url模块来进行获取。这时候可能会有小伙伴有疑问,刚才我们不是可以直接通过request.url来得到请求的路径以及查询的字符串吗?
确实是可以,但是它返回出来的形式并不利于我们更直观更方便地进行获取。因此我们采用导入url模块来获取请求的路径以及查询的参数。
// 导入http模块
const http=require('http');
//导入url模块
const url=require('url');
// 创建服务对象
const server=http.createServer((request,response)=>{//解析request.urllet res=url.parse(request.url);let pathname=res.pathname;//查询路径console.log(pathname);// /serach//设置响应体response.end('Hello http server');
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})当服务启动之后假设我向9000端口发送:http://127.0.0.1:9000/serach?name=N-A的请求,控制台打印出的res为
Url {protocol: null,slashes: null,auth: null,host: null,port: null,hostname: null,hash: null,search: '?name=N-A',query: 'name=N-A',pathname: '/serach',path: '/serach?name=N-A',href: '/serach?name=N-A'
}此时我们可以直接获取res的hostname属性来得到对应的路径:/search。那如何得到查询的参数呢?我们可以看到我们的参数存在query的属性里面,如果直接获取得出来的结果也不是我们想要的,因此这时候就需要用到parse方法的第二个参数了,将其设置为true,查询字符串将会以对象的形式进行展示如下。第一个数组不需要管。
Url {query: [Object: null prototype] { name: 'N-A' },
}因此我们通过对应以及键名来进行查询。
// 导入http模块
const http=require('http');
//导入url模块
const url=require('url');
// 创建服务对象
const server=http.createServer((request,response)=>{//解析request.urllet res=url.parse(request.url,true);//查询字符串let keyword=res.query.name;console.log(keyword);//N-A//设置响应体response.end('Hello http server');
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})除了上面介绍的那一种方法,我们还可以采用实例化的方式去创建一个对象,再通过对象里面的属性来获取url里面的相关内容了。这种方式较为简便。
// 导入http模块
const http=require('http');
// 创建服务对象
const server=http.createServer((request,response)=>{//实例化URL对象// let url=new URL('/search?name?N-A','http://127.0.0.1:9000');let url=new URL(request.url,'http://127.0.0.1');//输出路径console.log(url.pathname);// /search//查询字符串console.log(url.searchParams.get('name'));//N-A//设置响应体response.end('Hello http server');
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})设置响应报文
我们可以通过相应的方法来设置响应报文的信息,包括:响应状态码(response.statusCode)、响应状态描述(response.statusMessage) 、响应头信息(response.setHeader)以及响应体(response.write以及 response.end)。
设置响应头可以使用数组来实现设置多个同名的响应头。response.write和 response.end都可以用来设置响应体,区别在与前者可以多次设置,而后者只能设置一次。当使用response.write来设置响应体是,一般就不再使用response.end进行设置响应体,直接为空即可。在回调函数中必须要response.end。
// 导入http模块
const http=require('http');
// 创建服务对象
const server=http.createServer((request,response)=>{//设置响应状态码response.statusCode=203;//设置响应状态的描述response.statusMessage='N-A';//设置响应头response.setHeader('content-type','text/html;charset=utf-8');//设置多个同名的响应头response.setHeader('text',['a','b','c']);//设置响应体,write可以重复设置response.write('N-A');response.write('N-A');response.write('N-A');//设置响应体,end只能设置一次response.end();
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})网页资源的基本加载过程
假设我们在浏览器搜索CSDN,然后向会向CSDN的服务端发送请求,但是这时候需要注意的是,浏览器并不是只发送一次请求。网页资源的加载都是循序渐进的,首先获取 HTML 的内容, 然后解析 HTML 在发送其他资源的请求,如 CSS,Javascript,图片等。
静态资源服务
静态资源是指 内容长时间不发生改变的资源 ,例如图片,视频,CSS 文件,JS文件,HTML文件,字体文件等。而动态资源是指 内容经常更新的资源 ,例如百度首页,网易首页,京东搜索列表页面等。现在我们来试着搭建一个静态资源服务,主要实现以下的功能:

可以通过以下的方式来进行实现:
// 导入http模块
const http=require('http');
const fs=require('fs');
// 创建服务对象
const server=http.createServer((request,response)=>{//获取请求url对象let {pathname}=new URL(request.url,'http://127.0.0.1');if(pathname==='/index.html'){//读取文件内容let html=fs.readFileSync(__dirname+'/page/index.html');response.end(html);}else if(pathname==='/css/app.css'){//读取文件内容let css=fs.readFileSync(__dirname+'/page/css/app.css');response.end(css);}else if(pathname==='/images/logo.png'){//读取文件内容let img=fs.readFileSync(__dirname+'/page/images/logo.png');response.end(img);}else{response.statusCode=404;response.end('<h1>404 Not Found</h1>')}
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})当访问相应的文件路径时,我们就可以再浏览器看到对应文件中的内容。但是这种方式并不简便,当有很多的不同的文件时需要编写很长的代码。因此可以提取公共的路径部分进行修改如下:
// 导入http模块
const http=require('http');
const fs=require('fs');
// 创建服务对象
const server=http.createServer((request,response)=>{//获取请求url对象let {pathname}=new URL(request.url,'http://127.0.0.1');//拼接文件路径let filePath=__dirname+'/page'+pathname;//读取文件fs.readFile(filePath,(err,data)=>{if(err){response.statusCode=500;response.end('文件读取失败');return;}//响应内容response.end(data);})
});
// 监听端口
server.listen(9000,()=>{console.log("服务已经启动.....")
})HTTP 服务在哪个文件夹中寻找静态资源,那个文件夹就是静态资源目录 ,也称之为网站根目录。以上面的静态资源服务为例,path就是网站的根目录。它还可以单独地和__firname赋值给一个变量,该变量再去与pathname进行拼接,结果是一样的,只是后续如果想要修改根目录的话更为方便。
//声明一个变量let root=__dirname+'/page'//拼接文件路径let filePath=root+pathname;再补充一些关于网页中URL的内容,网页中的 URL 主要分为两大类:相对路径与绝对路径。绝对路径可靠性强,而且相对容易理解,在项目中运用较多。相对路径在发送请求时,需要与当前页面 URL 路径进行 计算 ,得到完整 URL 后,再发送请求,学习阶段用的较多。
绝对路径的形式:
| 形式 | 特点 |
| http://atguigu.com/w eb | 直接向目标资源发送请求,容易理解。网站的外链会用到此形式 |
| //atguigu.com/web | 与页面 URL 的协议拼接形成完整 URL 再发送请求。大型网站用的比较多 |
| /web | 与页面 URL 的协议、主机名、端口拼接形成完整 URL 再发送请求。中小型网站 |
| 形式 | 最终的 URL |
| ./css/app.css | http://www.atguigu.com/course/css/app.css |
| js/app.js | http://www.atguigu.com/course/js/app.js |
| ../img/logo.png | http://www.atguigu.com/img/logo.png |
| ../../mp4/show.mp4 | http://www.atguigu.com/mp4/show.mp4 |
在前面我们已经有涉及到,设置响应头的信息时,其中有一部分是text/html,表示请求的资源文件为html类型的文件,除了html类型,还有很多的其他类型也有相应的格式。浏览器会帮助我们识别对应的文件类型,但是如果我们设置文件的相应信息会更加地规范。这一个步骤叫做mime 类型的设置。HTTP 服务可以设置响应头 Content-Type 来表明响应体的 MIME 类型,浏览器会根据该类型决定如何处理资源。它常见的类型有:
html: 'text/html',
css: 'text/css',
js: 'text/javascript',
png: 'image/png',
jpg: 'image/jpeg',
gif: 'image/gif',
mp4: 'video/mp4',
mp3: 'audio/mpeg',
json: 'application/json'对上面我们编写的静态资源服务设置mime类型,如下:
// 导入http模块
const http = require('http');
const fs = require('fs');
const path=require('path')
let mimes = {html: 'text/html',css: 'text/css',js: 'text/javascript',png: 'image/png',jpg: 'image/jpeg',gif: 'image/gif',mp4: 'video/mp4',mp3: 'audio/mpeg',json: 'application/json'
}
// 创建服务对象
const server = http.createServer((request, response) => {//获取请求url对象let { pathname } = new URL(request.url, 'http://127.0.0.1');//声明一个变量let root = __dirname + '/page'//拼接文件路径let filePath = root + pathname;//读取文件fs.readFile(filePath, (err, data) => {if (err) {response.statusCode = 500;response.end('文件读取失败');return;}//获取文件后缀名let ext = path.extname(filePath).slice(1);//获取对应的类型let type = mimes[ext];if (type) {response.setHeader('content-type', type);} else {response.setHeader('content-type', 'application/octet-stream')}//响应内容response.end(data);})
});
// 监听端口
server.listen(9000, () => {console.log("服务已经启动.....")
})css文件以及js中的文件若存在中文,使用浏览器打开会出现乱码的情况,因此可以设charset=utf-8。修改如下:
if (type) {response.setHeader('content-type', type+';chaeset=utf-8');} else {response.setHeader('content-type', 'application/octet-stream')}对于未知的资源类型,可以选择 application/octet-stream 类型,浏览器在遇到该类型的响应时,会对响应体内容进行独立存储,也就是我们常见的下载效果。
我们还需要对响应错误进行一定的处理,我们前面都只是给你指定为500的错误,我们可以根据不同的状态err.code来设置相应的错误编码以及错误信息,详细完整的错误可看官网。我们对以上的代码进行修改:
// 导入http模块
const http = require('http');
const fs = require('fs');
const path=require('path')
let mimes = {html: 'text/html',css: 'text/css',js: 'text/javascript',png: 'image/png',jpg: 'image/jpeg',gif: 'image/gif',mp4: 'video/mp4',mp3: 'audio/mpeg',json: 'application/json'
}
// 创建服务对象
const server = http.createServer((request, response) => {if(request.method !=='GET'){response.statusCode=405;response.end('<h1>405 Method Not Allowed</h1>');}//获取请求url对象let { pathname } = new URL(request.url, 'http://127.0.0.1');//声明一个变量let root = __dirname + '/page'//拼接文件路径let filePath = root + pathname;//读取文件fs.readFile(filePath, (err, data) => {if (err) {switch(err.code){case 'ENOENT':response.statusCode=404;response.end('<h1>404 Not Found</h1>');case 'EPERM':response.statusCode=403;response.end('<h1>403 Forbidden</h1>');default:response.statusCode=500;response.end('<h1>Internal Server Error</h1>');}return;}//获取文件后缀名let ext = path.extname(filePath).slice(1);//获取对应的类型let type = mimes[ext];if (type) {response.setHeader('content-type', type+';chaeset=utf-8');} else {response.setHeader('content-type', 'application/octet-stream')}//响应内容response.end(data);})
});
// 监听端口
server.listen(9000, () => {console.log("服务已经启动.....")
})最后我们来介绍一下get请求以及post请求的应用场景以及区别:
| GET 请求的情况 | POST 请求的情况: |
| 在地址栏直接输入 url 访问 | form 标签中的 method 为 post (不区分大小写) |
| 点击 a 链接 | AJAX 的 post 请求 |
| link 标签引入 css | |
| script 标签引入 js | |
| img 标签引入图片 | |
| form 标签中的 method 为 get (不区分大小写) | |
| ajax 中的 get 请求 |
1️⃣GET 主要用来获取数据,POST 主要用来提交数据。但是也可以反过来,这并不是绝对的。
2️⃣GET 带参数请求是将参数缀到 URL 之后,在地址栏中输入 url 访问网站就是 GET 请求,POST 带参数请求是将参数放到请求体中。
3️⃣POST 请求相对 GET 安全一些,因为在浏览器中参数会暴露在地址栏。
4️⃣GET 请求大小有限制,一般为 2K,而 POST 请求则没有大小限制。
好啦!本文就先到这里了!感谢阅读。后续持续更新,拜拜!!
相关文章:
Node.js入门指南(二)
目录 http模块 创建http服务端 浏览器查看 HTTP 报文 获取 HTTP 请求报文 设置响应报文 网页资源的基本加载过程 静态资源服务 hello,大家好!上一篇文章我们对Node.js进行了初步的了解,并介绍了Node.js的Buffer、fs模块以及path模块。这一篇文章主…...
解锁Jira本地部署的数据中心版高级功能,打造高效、智能、精细化的项目管理
近日,在龙智携手Atlassian与JFrog共同举办的“大规模开发创新:如何提升企业级开发效率与质量”的线下研讨会中,龙智高级咨询顾问、Atlassian认证专家叶燕秀为大家带来了精彩演讲,解锁Jira Data Center版的诸多高级功能,…...

java线程三种方式
1.继承Thread类 线程1.2交替执行 public class MyThread extends Thread {Overridepublic void run() {for (int i 0; i < 100; i) {System.out.println(getName()"------""HelloWorld");}} } /*** desc 继承Thread类,线程1 2 交替执行* …...

关于mysql的lower_case_table_names引发的思考
lower_case_table_names设置大小写敏感的三个值0、1、2的区别? lower_case_table_names参数详解 1.参数说明: lower_case_table_names 0 表名 存储为给定的大小和比较是区分大小写的lower_case_table_names 1 表名 存储在磁盘是小写的 ,但…...
springboot+vue实现websocket通信实例,进入页面建立连接
springbootvue实现websocket通信实例 进入页面建立连接 前端代码: <template><div class"app-container"><el-form :model"queryParams" ref"queryForm" size"small" :inline"true" v-show&qu…...

【个人记录】同步Linux服务器时间和时区
修改时区 timedatectl set-timezone Asia/Shanghai时间同步 使用ntp进行同步,时间服务器使用阿里云NTP服务器 安装NTP服务 yum install -y ntp写入NTP配置文件 cat > /etc/ntp.conf <<EOF driftfile /var/lib/ntp/drift restrict default nomodify no…...

面试常问-如何判断链表有环、?
如何判断链表有环 题目:解决方案一:解决方案二:解决方案三: 题目: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,…...

基于springboot实现农机电招平台系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现农机电招平台系统演示 摘要 随着农机电招行业的不断发展,农机电招在现实生活中的使用和普及,农机电招行业成为近年内出现的一个新行业,并且能够成为大群众广为认可和接受的行为和选择。设计农机电招平台的目的就是借助计算…...

森林无人机高效解决巡查难题,林区防火掀新篇
山东省某市为了强化森林火灾防范,采用了一项新兴手段——复亚智能无人机森林火情监测系统。这套系统在AI飞行大脑的指挥下,让无人机在空中巡逻,实现了无人机森林防火系统的实施落地。 一、AI大脑如何引领森林无人机高空巡逻? 在山…...

python 爬虫之 爬取网站信息并保存到文件
文章目录 前期准备探索该网页的HTML码的特点开始编写代码存入文件总的程序文件存储效果 前期准备 随便找个网站进行爬取,这里我选择的是(一个卖书的网站) https://www.bookschina.com/24hour/62700000/ 我的目的是爬取这个网站的这个页面的书籍的名称以…...

kubelet漏洞CVE-2020-8559复现与分析
首先下载源码 git clone --branch v1.17.1 --single-branch https://github.com/kubernetes/kubernetes.git 参考 移花接木:看CVE-2020-8559如何逆袭获取集群权限-腾讯云开发者社区-腾讯云...

基于C#实现奇偶排序
这篇就从简单一点的一个“奇偶排序”说起吧,不过这个排序还是蛮有意思的,严格来说复杂度是 O(N2),不过在多核的情况下,可以做到 N2 /(m/2)的效率,这里的 m 就是待排序的个数,当 m100,复杂度为 N…...
Kibana部署
服务器 安装软件主机名IP地址系统版本配置KibanaElk10.3.145.14centos7.5.18042核4G软件版本:nginx-1.14.2、kibana-7.13.2-linux-x86_64.tar.gz 1. 安装配置Kibana (1)安装 [rootelk ~]# tar zxf kibana-7.13.2-linux-x86_64.tar.gz -C…...

【Linux】了解进程的基础知识
进程 1. 进程的概念1.1 进程的理解1.2 Linux下的进程1.3 查看进程属性1.4 getpid和getppid 2. 创建进程3. 进程状态4. 进程优先级5. 进程切换6. 环境变量7. 本地变量与内建命令 1. 进程的概念 一个已经加载到内存中的程序,叫做进程(也叫任务)…...

ES6 — ES14 新特性
一、ES6 新特性(2015) 1. let和const 在ES6中,新增了let和const关键字,其中 let 主要用来声明变量,而 const 通常用来声明常量。let、const相对于var关键字有以下特点: 特性varletconst变量提升✔️全局…...
附录12-time.h的常用方法
目录 1 数据类型 1.1 time_t 1.2 tm 1.3 clock_t 2 相关知识 3 获取从1970年1月1日以来的UTC秒数 time() 4 获取本时区时间字符串 ctime() 5 获取GMT时间的tm gmttime() 6 获取本地时间的tm localtime() 7 记录当前毫秒数 clock() 8 将表示本地时间的tm转…...
C语言公交车之谜(ZZULIOJ1232:公交车之谜)
题目描述 听说郑州紫荆山公园有英语口语角,还有很多外国人呢。为了和老外对上几句,这周六早晨birdfly拉上同伴早早的就坐上了72路公交从学校向紫荆山进发。一路上没事干,birdfly开始思考一个问题。 从学校到紫荆山公园共有n(1<n<20)站路…...

Liunx Ubuntu Server 安装配置 Docker
1. 安装Docker 1.1 更新软件包列表 sudo apt update1.2 添加Docker存储库 sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-a…...
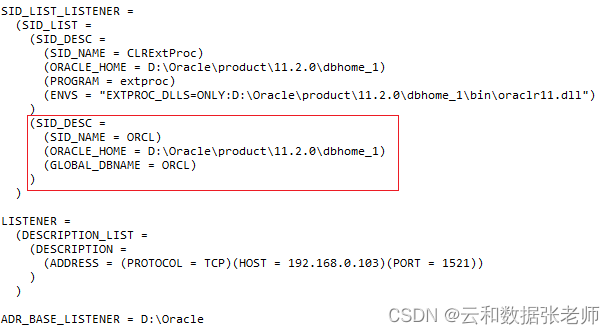
Oracle ORA12514 监听程序当前无法识别连接描述符中请求的服务
最简单的有可能是你的服务还没有开启,需要启动服务!!!! 在连接数据库的时候,有时会遇到一个“ORA12514:监听程序当前无法识别连接描述符中请求的服务”的错误,这个错误其实就是数据…...

druid keepAlive 导致数据库连接数飙升
一.背景 应用在执行完某个复杂业务,主要包含20几个查询SQL的操作后,会导致数据库连接池一直升高 druid版本:1.2.11 druid配置文件: spring.datasource.druid.maxActive100 spring.datasource.druid.initialSize20 spring.datas…...

实习08-Mamba 和 SSM
🔹 第一部分:Mamba 基础概念(先补地基) 1.1 什么是 State Space Model (SSM)? [公式] - SSM 思想 SSM 源自控制理论,核心是一个连续时间系统: # 连续形式(控制理论) h(t)…...

显卡要求高吗?实测Asian Beauty Z-Image Turbo在不同配置下的运行表现
显卡要求高吗?实测Asian Beauty Z-Image Turbo在不同配置下的运行表现 如果你对AI图像生成感兴趣,特别是想生成东方风格的人像写真,Asian Beauty Z-Image Turbo绝对值得关注。但很多人在尝试前都会问:这个工具对显卡要求高吗&…...

脑电信号解码终极指南:5个步骤实现运动想象分类
脑电信号解码终极指南:5个步骤实现运动想象分类 【免费下载链接】bcidatasetIV2a This is a repository for BCI Competition 2008 dataset IV 2a fixed and optimized for python and numpy. This dataset is related with motor imagery 项目地址: https://gitc…...

解锁Android的Linux潜能:PRoot如何重塑移动开发边界
解锁Android的Linux潜能:PRoot如何重塑移动开发边界 【免费下载链接】proot An chroot-like implementation using ptrace. 项目地址: https://gitcode.com/gh_mirrors/pro/proot 在移动设备上运行完整的Linux环境曾经是遥不可及的梦想,需要复杂的…...

用刚性小球定义的宇宙图景-超流体宇宙概述
一、 终极定义:相位场 ϕ 的唯一使命在这个超流体宇宙里,唯一真实的物理量是 “位置” 和 “时间”。但因为介质是连续的,我们无法用 “质点” 来描述整个场的演化。所以,为了数学上描述 “连续介质的运动”,我们必须引…...

Stable Yogi Leather-Dress-Collection 模型蒸馏与轻量化部署探索
Stable Yogi Leather-Dress-Collection 模型蒸馏与轻量化部署探索 想不想在手机或者树莓派这样的小设备上,也能跑起来 Stable Yogi 这样的图片生成模型,让它为你设计皮革裙装?这听起来有点天方夜谭,毕竟这类模型动辄几十GB&#…...

提升Docker镜像构建效率的10个秘诀:Docker Buildx和Bake高级构建技巧
提升Docker镜像构建效率的10个秘诀:Docker Buildx和Bake高级构建技巧 【免费下载链接】docs Source repo for Dockers Documentation 项目地址: https://gitcode.com/gh_mirrors/docs3/docs Docker Buildx和Bake是Docker生态系统中强大的高级构建工具&#x…...

自动化测试质量
自动化测试质量:提升软件交付效率的关键 在当今快速迭代的软件开发环境中,自动化测试已成为保障产品质量的重要手段。它不仅能够显著提高测试效率,还能减少人为错误,确保软件在复杂场景下的稳定性。自动化测试的质量直接影响其效…...

3个步骤解锁《艾尔登法环》帧率限制:告别60帧束缚的终极指南
3个步骤解锁《艾尔登法环》帧率限制:告别60帧束缚的终极指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/…...

Step3-VL-10B教育应用:小学数学题图解析+分步解题提示生成
Step3-VL-10B教育应用:小学数学题图解析分步解题提示生成 你是不是也遇到过这样的场景?孩子拿着数学作业本跑过来,指着上面一道带图的题目问:“爸爸/妈妈,这道题怎么做?”你仔细一看,题目里有图…...