mysql 性能参数调优详解
1 优化连接池
连接池运行机制
MySQL连接器中的连接池,用以提高数据库密集型应用程序的性能和可扩展性,默认启用。MySQL连接器负责管理连接池中的多个连接,自动创建、打开、关闭和破坏连接,多个连接的创建,可满足多客户端的频繁连接,连接的重复使用获得最佳性能。
MySQL连接器
每三分钟运行一次后台作业,并从池中删除闲置(未使用)超过三分钟的连接。池清理释放客户端和服务器端的资源。这是因为在客户端每个连接都使用一个Socket,而在服务器端每个连接都使用一个Socket和一个线程。
max_connections,MySQL最大并发连接数,默认值是151,最大连接数上限是16384;
经验:实际连接数是最大连接数的 85% 较为合适。 设置 max_used_connections 方法
- 查询数据库目前设置的最大并发连接数是多少
SHOW VARIABLES LIKE ‘max_connections’;
-
查询数据库目前实际连接的并发数是多少
SHOW STATUS LIKE ‘max_used_connections’; -
在MySQL配置文件 /etc/my.cnf 中设置 max_connections=3000,表示修改最大连接数为3000。
注意:需要重启 MySQL 才能生效。 – MySQL为每个连接创建缓冲区,所以不应该盲目上调最大连接数。
如果最大连接数达到了上面设置的 3000,会消耗大约 800M 内存。
其他连接池设置:
开启连接池: Pooling=true,默认开启
复用时重置连接状态: ConnectionReset=True
保持连接设置: CacheServerProperties=True
连接超时回收(秒): ConnectionLifeTime=300
支持的最大连接数量: Max Pool Size=100
保持最小的连接数量: Min Pool Size=10
2. 优化请求堆栈
back_log,存放执行请求的堆栈大小,默认值是50。
- 该值设置为最大并发连接数的 20%~30% 较为合适。
设置 back_log 方法: - 在MySQL配置文件 /etc/my.cnf 中,设置 back_log=600
- 修改后需要重启 MySQL 才能生效。
back_log 在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。
也就是说,如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
将会报:unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL |
login | NULL 的待连接进程时. back_log值不能超过TCP/IP连接的侦听队列的大小。
若超过则无效,查看当前系统的TCP/IP连接的侦听队列的大小命令:cat
/proc/sys/net/ipv4/tcp_max_syn_backlog,目前系统为1024。
对于Linux系统推荐设置为大于512的整数。 修改系统内核参数,可以编辑/etc/sysctl.conf去调整它。
如:net.ipv4.tcp_max_syn_backlog = 2048,改完后执行sysctl -p 让修改立即生效。 查看mysql
当前系统默认back_log值,命令:
show variables like ‘back_log’;
3. 修改连接超时时间
wait-timeout,超时时间,单位是秒,连接默认超时为8小时,连接长期不用不销毁,比较浪费资源。
查看
SHOW VARIABLES LIKE 'wait_timeout%';
经验:设置超时时间为 10 分钟 wait-timeout=600
4. 优化内存缓冲池
缓冲池运行机制
- 在MySQL5.5之前,广泛使用的和默认的存储引擎是MyISAM。MyISAM使用操作系统缓存来缓存数据。InnoDB需要innodb buffer pool中处理缓存,所以非常需要有足够的InnoDB buffer pool空间。
- 缓冲区分为 热数据区 / 冷数据区,两者空间占比约为 7/3,每区中的数据集依使用频率按顺序依次排列。当一个新的查询结果出现后,首先考虑存放到冷数据区,当冷数据区的结果集使用达到一定频率,会被改存到热数据区,使用频率最好的数据集会被存放到热区的首位,当然也有热区转到冷区的状况。
InnoDB 缓冲池不仅仅是一个缓存,MySQL InnoDB buffer pool 包含四部分:
1. 数据缓存,InnoDB 数据页面;
2. 索引缓存,索引数据;
3. 缓冲数据,脏页(在内存中修改尚未写入到磁盘的数据);
4. 内部结构,如自适应哈希索引,行锁等。
innodb_buffer_pool_instances 内存缓冲池。
-
buffer_pool 把需要缓冲的数据 hash 到不同的缓冲池中,这样可以并行的内存读写。通过减少争用不同线程对缓存页面进行读写的争用,将缓冲池划分为多个单独的实例可以提高并发性。
-
MySQL 5.7、MySQL 8.0 下 innodb_buffer_pool_instances 默认为 1,若 MySQL 存在高并发和高负载访问,设置为 1 则会造成大量线程对 buffer_pool 的单实例互斥锁竞争,这样会消耗一定量的性能的。
-
innodb_buffer_pool_instances 建议设置为 cpu核心数。
innodb_buffer_pool_chunk_size,缓冲池每块大小,默认128M。 -
pool_chunk_size 一般不做改动,使用默认值就可以。
innodb_buffer_pool_size,缓冲池的承载总量。 -
innodb_buffer_pool_size 可以缓存索引和行数据,值越大、IO读写就越少;
设置规则:innodb_buffer_pool_size = (innodb_buffer_pool_chunk_size * {N}块 )*innodb_buffer_pool_instances
如果单纯的做数据库服务,该参数可以设置到电脑物理内存的80%;
为了更好的配合 pool_instance,pool_size 需要设置为 pool_instance 和 pool_chunk_size 的整数倍,这样可以被 pool_instance 整除,为每个 buffer pool 实例平均分配内存。如果设置的值不是倍数,MySQL会自动将 pool_size 调整为 pool_chunk_size 的倍数。
5. 优化并发线程数
innodb_thread_concurrency,代表并发线程数。
默认是0,表示没有设置线程数量的上限。不是分配给 MySQL 的线程越多越好,线程多反而会损耗cpu性能,导致速度变慢。
经验:并发线程数应该设置为 cpu 核心数的两倍。
注意:这个变量特定于Solaris 8和更早的系统,MySQL 5.7.2中删除了这个变量。
设置 innodb_thread_concurrency 方法:
在MySQL配置文件 /etc/my.cnf 中,设置 innodb_thread_concurrency=8。
– 查看cpu型号
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
– 查看cpu核心数
cat /proc/cpuinfo | grep “cores”|uniq
6. 优化线程池
客户端发起连接到 MySQL Server 后,MySQL Server监听进程监听到新的请求,然后 Sever 会为其分配一个新的 thread去处理此请求。
从建立连接之开始,CPU要给它划分一定的 thread stack,然后进行用户身份认证,建立上下文信息,最后请求完成,关闭连接,同时释放资源。
在高并发的情况下,这个过程将给系统带来巨大的压力,不能保证性能。MySQL服务器的线程数需要在一个合理的范围之内,这样才能保证MySQL服务器健康平稳地运行。
6.1 查看线程池的状态:
mysql> show variables like ‘thread%’;
±-------------------±--------------------------+
| Variable_name | Value |
±-------------------±--------------------------+
| thread_cache_size | 64 |
| thread_concurrency | 10 |
| thread_handling | one-thread-per-connection |
| thread_stack | 262144 |
±-------------------±--------------------------+thread_cache_size
thread_cache_size,Threads_cached 中存放的最大连接线程数。
- 在短连接的应用中,Threads_cached 的功效非常明显,因为在应用中数据库的连接和创建是非常频繁的。如果不使用 Threads_cached,那么消耗的资源是非常频繁的。
- 在长连接中虽然带来的改善没有短连接的那么明显,但是好处是显而易见的。但并不是越大越好,大了反而浪费资源,这个的确定一般认为和物理内存有一定关系。
- Mysql默认值为9。
设置 thread_cache_size 方法: - 参考下面额对照表,根据物理内存设置对应的 thread_cache_size 数值:
1G —> 8
2G —> 16
3G —> 32
3G —> 64
6.2 在 mysql 命令行中设置:
mysql> set global thread_cache_size=64;
thread_concurrency
- thread_concurrency 应设为 CPU核数的2倍。
比如有一个双核的CPU,那么thread_concurrency的应该为4。这个变量是针对Solaris系统的,如果设置这个变量的话,mysqld就会调用thr_setconcurrency()。这个函数使应用程序给同一时间运行的线程系统提供期望的线程数目。但是在5.7以后就已经抛弃了。
设置 thread_concurrency 方法:
– 在 mysql 命令行中设置:
mysql> set global thread_concurrency=4;
thread_handling
运用 Thread_Cache 处理连接的方式,从 5.1.19 添加的新特性,有两个值可选 no-threads、one-thread-per-connection。
- no-threads :服务器使用一个线程
- one-thread-per-connection :服务器为每个客户端请求使用一个线程
thread_stack
每个连接被创建的时候,mysql分配给它的内存。这个值一般认为默认就可以应用于大部分场景了,除非必要非则不要动它。上面表示是256kb。
6.2 查看线程使用情况:
mysql> show global status like ‘Thread%’;
±------------------±------+
| Variable_name | Value |
±------------------±------+
| Threads_cached | 41 |
| Threads_connected | 53 |
| Threads_created | 541 |
| Threads_running | 4 |
±------------------±------+
Threads_cached
MySQL里面为了提高客户端请求创建连接过程的性能,提供了一个连接池也就是 Thread_cache 池(大小是thread_cache_size),将空闲的连接线程放在连接池中,而不是立即销毁。
这样的好处就是,当又有一个新的请求的时候,mysql不会立即去创建连接 线程,而是先去 Thread_Cache 中去查找空闲的连接线程,如果存在则直接使用,不存在才创建新的连接线程。Thread_cache 值表示已经被线程缓存池缓存的线程个数。
Threads_connected
当前处于连接状态的线程个数,等于 show processlist。
Threads_created
Threads_created 表示创建过的线程数,如果发现 Threads_created 值过大的话,表明MySQL服务器一直在创建线程,这也是比较耗资源,可以适当增加配置文件中 thread_cache_size 值。
Threads_running
处于激活状态的线程的个数,这个一般都是远小于Threads_connected的。
7.优化日志
日志运行机制
MySQL在运行时,会有各种不同日志的记录,大量的各种类型的日志产生,会对资源的开销产生严重的影响,必要的时候我们选择性的开启。
但在生产环境时,有些日志并不是必须,以下列出MySQL各种日志信息:
- 错误日志:启动、关闭、运行时 产生的异常记录,建议开启,设置 log_error
查询日志:客户端连接和执行的脚本,建议关闭,设置 general_log - 慢查询日志:记录超时的查询,记录不适用索引的查询等,建议关闭,设置 slow_query_log
- 二进制日志:用于数据同步复制,需发送的数据日志,多用于集群,如需开启,设置 log_bin
- 中继日志:用于数据同步复制时,接收到的数据日志,多用于集群,如需开启,设置 relay_log
8. 锁优化
8.1. innodb 锁优化
Innodb 存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面所带来的性能损耗可能比表级锁定会要更高一些,但是在整体并发处理能力方面要远远优于MyISAM 的表级锁定的。
尽可能让所有的数据检索都通过索引来完成,从而避免Innodb 因为无法通过索引键加锁而升级为表级锁定;
合理设计索引,让Innodb 在索引键上面加锁的时候尽可能准确,尽可能的缩小锁定范围,避免造成不必要的锁定而影响其他Query 的执行;
尽可能减少基于范围的数据检索过滤条件,避免因为间隙锁带来的负面影响而锁定了不该锁定的记录;
尽量控制事务的大小,减少锁定的资源量和锁定时间长度;
在业务环境允许的情况下,尽量使用较低级别的事务隔离,以减少MySQL 因为实现事务隔离级别所带来的附加成本;
减少 innodb 死锁产生概率的建议:
类似业务模块中,尽可能按照相同的访问顺序来访问,防止产生死锁;
在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
9.2. MyISAM 锁优化
在MyISAM里读写操作是串行的,但当对同一个表进行查询和插入操作时,为了降低锁竞争的频率,根据concurrent_insert的设置,MyISAM是可以并行处理查询和插入的
缩短锁定时间
-
尽两减少大的复杂Query,将复杂Query 分拆成几个小的Query 分布进行;
-
尽可能的建立足够高效的索引,让数据检索更迅速;
-
尽量让MyISAM 存储引擎的表只存放必要的信息,控制字段类型;
-
利用合适的机会优化MyISAM 表数据文件;
-
max_write_lock_count:
缺省情况下,写操作的优先级要高于读操作的优先级,即便是先发送的读请求,后发送的写请求,此时也会优先处理写请求,然后再处理读请求。这就造成一 个问题:一旦我发出若干个写请求,就会堵塞所有的读请求,直到写请求全都处理完,才有机会处理读请求。此时可以考虑使用 max_write_lock_count:
max_write_lock_count=1
有了这样的设置,当系统处理一个写操作后,就会暂停写操作,给读操作执行的机会。
low-priority-updates:
我们还可以更干脆点,直接降低写操作的优先级,给读操作更高的优先级。
low-priority-updates=1
综合来看,concurrent_insert=2是绝对推荐的,至于max_write_lock_count=1和low-priority- updates=1,则视情况而定,如果可以降低写操作的优先级,则使用low-priority-updates=1,否则使用 max_write_lock_count=1。
set-variable = max_allowed_packet=1M
set-variable = net_buffer_length=2K
相关文章:

mysql 性能参数调优详解
1 优化连接池 连接池运行机制 MySQL连接器中的连接池,用以提高数据库密集型应用程序的性能和可扩展性,默认启用。MySQL连接器负责管理连接池中的多个连接,自动创建、打开、关闭和破坏连接,多个连接的创建,可满足多客户…...
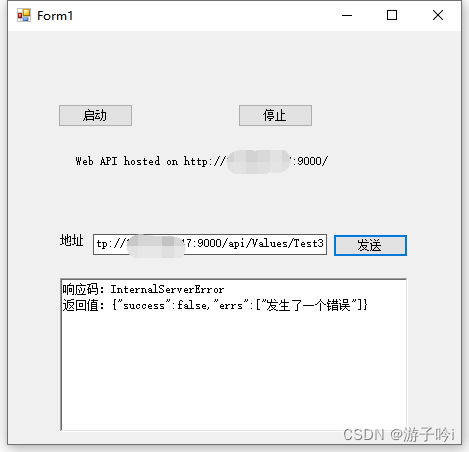
基于.net framework4.0框架下winform项目实现寄宿式web api
首先Nuget中下载包:Microsoft.AspNet.WebApi.SelfHost,如下: 注意版本哦,最高版本只能4.0.30506能用。 1.配置路由 public static class WebApiConfig{public static void Register(this HttpSelfHostConfiguration config){// …...
)
Vue中项目进行文件压缩与解压缩 (接口返回文件的url压缩包前端解析并展示出来,保存的时候在压缩后放到接口入参进行保存)
安装 npm install pako在Vue组件中引入pako: import pako from pako;接口返回的url是这个字段 tableSsjsonUrl 其实打开就是压缩包const source await tableFileUrl ({ id: this.$route.query.id}); if(source.code 0) {this.titleName source.data.tableNam…...
Linux shell编程学习笔记31:alias 和 unalias 操作 命令别名
目录 0 前言1 定义别名2 查看别名 2.1 查看所有别名2.2 查看某个别名 2.2.1 alias 别名2.2.2 alias | grep 别名字符串2.2.3 使用 CtrlAltE 组合键3 unalias:删除别名4 如何执行命令本身而非别名 4.1 方法1:使用 CtrlAltE 组合键 && unalias4…...
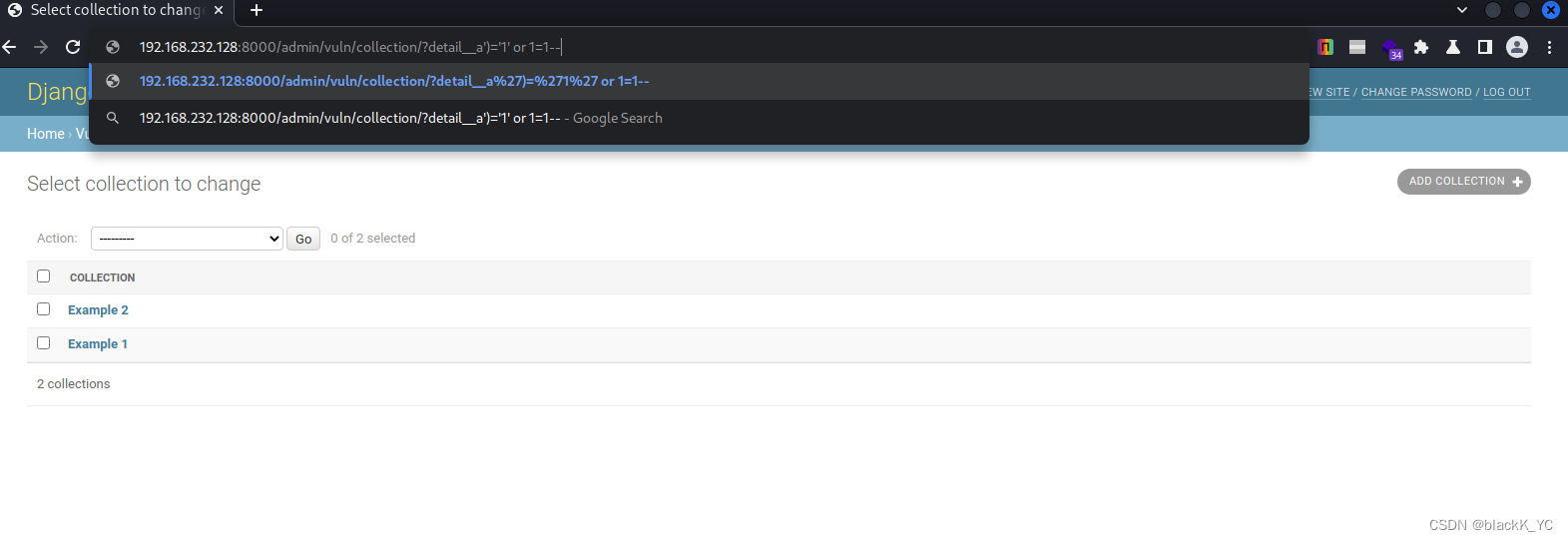
Django JSONField/HStoreField SQL注入漏洞(CVE-2019-14234)
漏洞描述 Django 于2019年8月1日 日发布了安全更新,修复了 JSONField 和 HStoreField 两个模型字段的 SQL 注入漏洞。 参考链接: Django security releases issued: 2.2.4, 2.1.11 and 1.11.23 | Weblog | DjangoDjango JSONField SQL注入漏洞&#x…...

Unity中Shader的Standard材质解析(一)
文章目录 前言一、在Unity中,按一下步骤准备1、在资源管理面板创建一个 Standard Surface Shader2、因为Standard Surface Shader有很多缺点,所以我们把他转化为顶点片元着色器3、整理只保留主平行光的Shader效果4、精简后的最终代码 前言 在Unity中&am…...
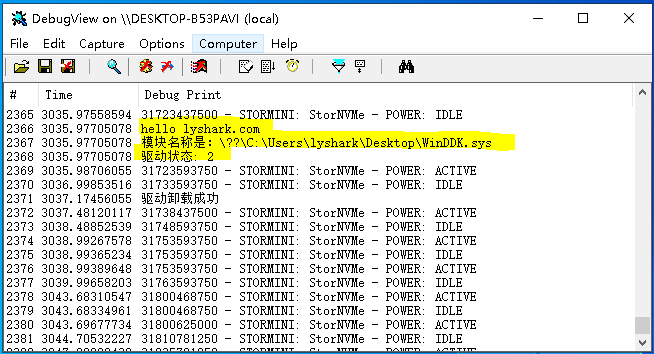
5.1 Windows驱动开发:判断驱动加载状态
在驱动开发中我们有时需要得到驱动自身是否被加载成功的状态,这个功能看似没啥用实际上在某些特殊场景中还是需要的,如下代码实现了判断当前驱动是否加载成功,如果加载成功, 则输出该驱动的详细路径信息。 该功能实现的核心函数是NtQuerySys…...
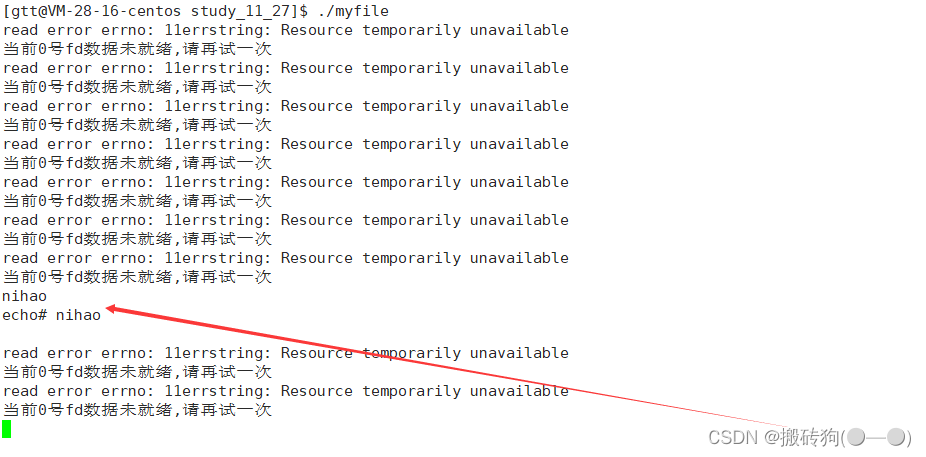
Linux之高级IO
目录 IO基本概念五种IO模型钓鱼人例子五种IO模型高级IO重要概念同步通信 VS 异步通信阻塞 VS 非阻塞其他高级IO阻塞IO非阻塞IO IO基本概念 I/O(input/output)也就是输入和输出,在著名的冯诺依曼体系结构当中,将数据从输入设备拷贝…...
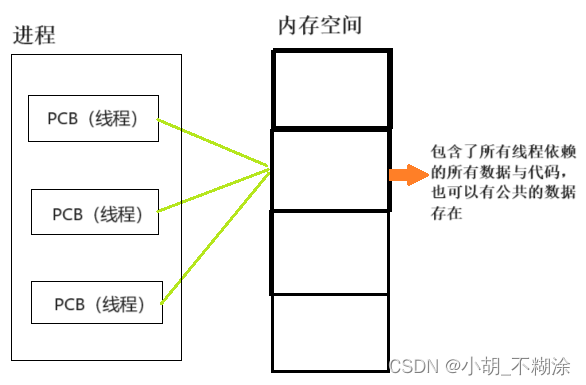
进程和线程的关系
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:JavaEE 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 进程&线程 1. 什么是进程PCB 2. 什么是…...
,公开数据集mAP有效涨点,来打造新颖YOLOv5检测器)
YOLOv5全网独家改进:NanoDet算法动态标签分配策略(附原创改进代码),公开数据集mAP有效涨点,来打造新颖YOLOv5检测器
💡本篇内容:YOLOv5全网独家改进:NanoDet算法动态标签分配策略(附原创改进代码),公开数据集mAP有效涨点,来打造新颖YOLOv5检测器 💡🚀🚀🚀本博客 YOLOv5+ 改进NanoDet模型的动态标签分配策略源代码改进 💡一篇博客集成多种创新点改进:NanoDet 💡:重点:更…...

原生DOM事件、react16、17和Vue合成事件
目录 原生DOM事件 注册/绑定事件 DOM事件级别 DOM0:onclick传统注册: 唯一(同元素的(不)同事件会覆盖) 没有捕获和冒泡的,只有简单的事件绑定 DOM2:addEventListener监听注册:可添加多个…...
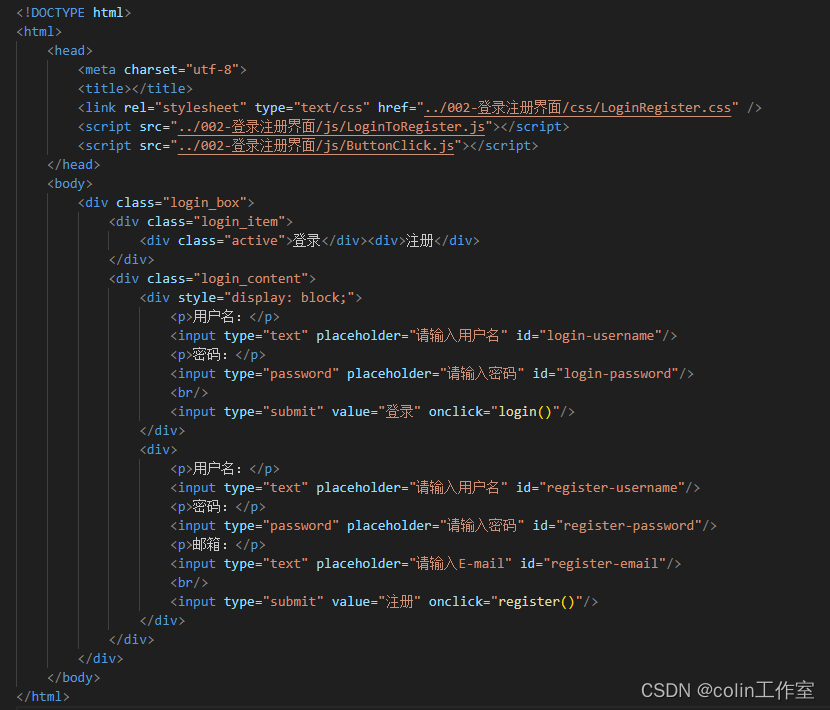
基于HTML+CSS+JavaScript的登录注册界面设计
一、界面效果: 二、HTML代码: 登录注册html: 登录成功html: <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title></title> </head> <body> <h1>登录成功!</h1> </body> <…...
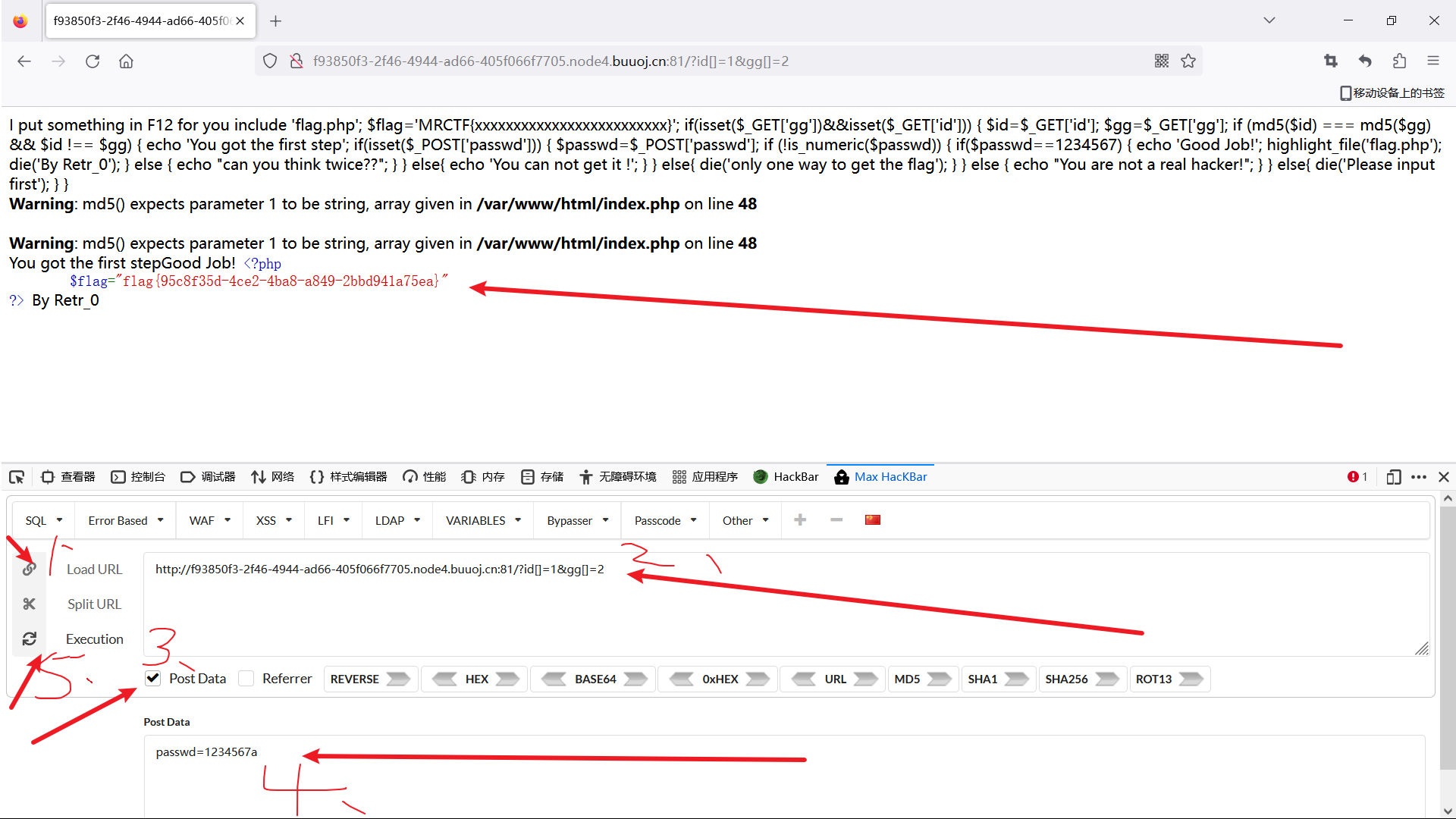
BUUCTF [MRCTF2020]Ez_bypass 1
题目环境:F12查看源代码 I put something in F12 for you include flag.php; $flagMRCTF{xxxxxxxxxxxxxxxxxxxxxxxxx}; if(isset($_GET[gg])&&isset($_GET[id])) { $id$_GET[id]; $gg$_GET[gg]; if (md5($id) md5($gg) && $id ! $gg) { …...
基于Apache部署虚拟主机网站
文章目录 Apache释义Apache配置关闭防火墙和selinux 更改默认页内容更改默认页存放位置个人用户主页功能基于口令登录网站虚拟主机功能基于ip地址相同ip不同域名相同ip不同端口 学习本章完成目标 1.httpd服务程序的基本部署。 2.个人用户主页功能和口令加密认证方式的实现。 3.…...
大数据平台/大数据技术与原理-实验报告--部署全分布模式HBase集群和实战HBase
实验名称 部署全分布模式HBase集群和实战HBase 实验性质 (必修、选修) 必修 实验类型(验证、设计、创新、综合) 综合 实验课时 2 实验日期 2023.11.07-2023.11.10 实验仪器设备以及实验软硬件要求 专业实验室ÿ…...

手写字符识别神经网络项目总结
1.数据集 手写字符数据集 DIGITS,该数据集的全称为 Pen-Based Recognition of Handwritten Digits Data Set,来源于 UCI 开放数据集网站。 2.加载数据集 import numpy as np from sklearn import datasets digits datasets.load_digits() 3.分割数…...
八、Lua数组和迭代器
一、Lua数组 数组,就是相同数据类型的元素按一定顺序排列的集合,可以是一维数组和多维数组。 在 Lua 中,数组不是一种特定的数据类型,而是一种用来存储一组值的数据结构。 实际上,Lua 中并没有专门的数组类型…...
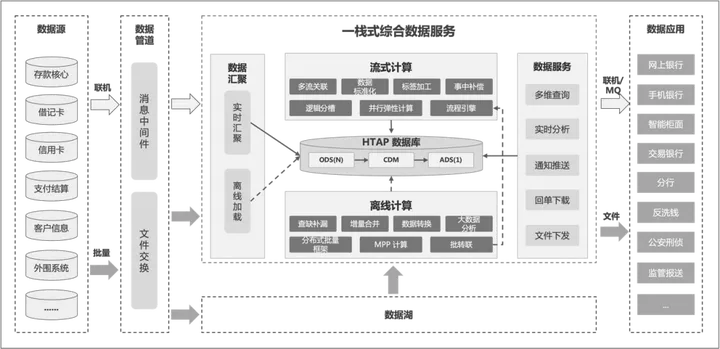
平凯星辰 TiDB 获评 “2023 中国金融科技守正创新扬帆计划” 十佳优秀实践奖
11 月 10 日,2023 金融街论坛年会同期举办了“第五届成方金融科技论坛——金融科技守正创新论坛”,北京金融产业联盟发布了“扬帆计划——分布式数据库金融应用研究与实践优秀成果”, 平凯星辰提报的实践报告——“国产 HTAP 数据库在金融规模…...

运算符展开、函数,对象,数组,字符串变化 集合
... 展开运算符 用于函数实参或者赋值号右边 console.log(...[1, 2, 3]) // 1,2,3console.log(Math.max(...[1, 2, 3]))//3 console.log(Math.max.apply(null, [1, 2, 3]))//3const o { a: 1, b: 2 }const obj { ...o, c: 3 }console.log(obj)//Object ... 剩余运算符 用于…...

NI自动化测试系统用电必备攻略,电源规划大揭秘
就像使用电脑之前需接通电源一样,自动化测试系统的电源选择也是首当其冲的问题,只不是这个问题更复杂。 比如,应考虑地理位置因素,因为不同国家或地区的公共电网所提供的线路功率有所不同。在电源布局和设备选型方面,有…...

DeepAnalyze在教育领域的个性化学习应用
DeepAnalyze在教育领域的个性化学习应用 1. 当作业不再只是对错判断,而是学习路径的起点 你有没有遇到过这样的情况:学生交上来一份开放性题目答案,内容丰富但思路跳跃,老师批改时反复斟酌——这算对还是不对?该给多…...

Windows系统使用nvm实现多版本切换Node.js详细教程
一、什么是nvm-windows? nvm(Node Version Manager)是一个用于管理多个Node.js版本的工具。在Windows系统中,我们使用的是nvm-windows,它允许你在同一台电脑上安装、切换和管理多个Node.js版本,避免版本冲…...

STM32新手必看:用CH340模块烧录程序的5个常见错误及解决方法
STM32与CH340模块烧录全攻略:从驱动安装到实战避坑指南 第一次接触STM32开发板时,那块蓝色的小板子躺在桌面上,USB线连着电脑却毫无反应——这场景恐怕是许多嵌入式开发者的共同记忆。作为性价比最高的ARM Cortex-M系列微控制器,S…...

喔去,litellm 竟然被投毒了,赶紧检查你的机器中招了没有号
一、什么是setuptools? setuptools 是一个用于创建、分发和安装 Python 包的核心库。 它可以帮助你: 定义 Python 包的元数据(如名称、版本、作者等)。 声明包的依赖项,确保你的包能够正确运行。 构建源代码分发包&…...

分析管理化技术数据挖掘与预测分析
数据驱动决策:管理技术中的挖掘与预测 在数字化时代,企业每天生成海量数据,如何从中提取价值成为关键。分析管理化技术通过数据挖掘与预测分析,帮助组织优化运营、降低成本并提升竞争力。数据挖掘从历史数据中发现模式࿰…...

基于File-Based App开发MVP项目汤
Issue 概述 先来看看提交这个 Issue 的作者是为什么想到这个点子的,以及他初步的核心设计概念。?? 本 PR 实现了 Apache Gravitino 与 SeaTunnel 的集成,将其作为非关系型连接器的外部元数据服务。通过 Gravitino 的 REST API 自动获取表结构和元数据&…...
)
PromptOps新范式:支持语义比对、影响面分析、自动回归测试的提示词版本引擎(附开源POC)
第一章:大模型工程化中的提示词版本管理 2026奇点智能技术大会(https://ml-summit.org) 在大模型落地实践中,提示词(Prompt)已从临时调试脚本演变为关键生产资产——其质量、可复现性与可审计性直接影响推理稳定性、业务指标合规…...

Autosar代码生成避坑指南:Simulink模型到RTE接口的5个关键步骤
Autosar代码生成避坑指南:Simulink模型到RTE接口的5个关键步骤 当Simulink模型需要与Autosar架构对接时,许多开发者会在代码生成阶段遭遇各种"水土不服"。本文将从实际工程问题出发,拆解五个最易出错的环节,并给出可立即…...

Emotional First Aid Dataset:破解AI心理陪伴技术瓶颈的20,000条高质量对话语料库
Emotional First Aid Dataset:破解AI心理陪伴技术瓶颈的20,000条高质量对话语料库 【免费下载链接】efaqa-corpus-zh ❤️Emotional First Aid Dataset, 心理咨询问答、聊天机器人语料库 项目地址: https://gitcode.com/gh_mirrors/ef/efaqa-corpus-zh 在心理…...

3步打造你的云端Windows 12:无需安装,浏览器直接体验
3步打造你的云端Windows 12:无需安装,浏览器直接体验 【免费下载链接】win12 Windows 12 网页版,在线体验 点击下面的链接在线体验 项目地址: https://gitcode.com/gh_mirrors/wi/win12 想要在浏览器中体验最新的Windows系统界面吗&am…...