哈希和unordered系列封装(C++)
哈希和unordered系列封装
- 一、哈希
- 1. 概念
- 2. 哈希函数,哈希碰撞
- 哈希函数(常用的两个)
- 哈希冲突(碰撞)
- 小结
- 3. 解决哈希碰撞
- 闭散列
- 线性探测
- 二次探测
- 代码实现
- 载荷因子(扩容)
- 开散列
- 哈希桶
- 代码实现
- 扩容
- 二、unordered系列封装
- hash_table
- 迭代器实现原理(单项迭代器)
- hash_table实现代码
- unordered_set封装
- unordered_map封装
- 三、总结
一、哈希
1. 概念
通过某种函数使用元素的存储位置与其关键码之间建立映射关系。
- 插入元素时,通过该函数求得的值,就是该元素的存储位置。
- 搜索元素时,通过该函数求得的值进行比对,如果关键码相等则搜索成功。
该方法称为哈希(散列)方法, 而其中的某中函数被称为哈希(散列)函数,构造出来的结构成为哈希表(散列表)。
2. 哈希函数,哈希碰撞
哈希函数(常用的两个)
直接定址法
- 函数
取关键字的某个线性函数得出散列地址:Hash(Key) = A * Key + B- 优缺
优点:简单均匀
缺点:关键码的分布范围需要集中- 场景
统计字符串中字符出现的个数,其中字符是集中的。
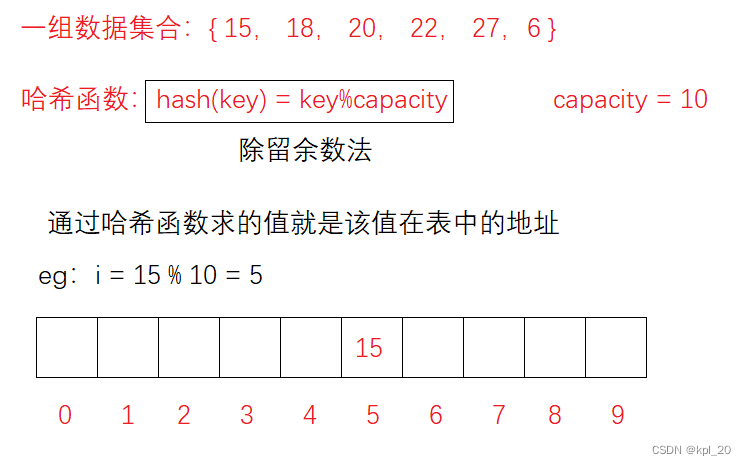
除留余数法
- 函数
Hash(Key) = Key % m(m是小于等于表中可取地址数即可(建议:质数))- 场景
适用于值的方位分散
eg:
注意:
- 使用除留余数法,所以就要求被%的key必须是整型。如果key为字符串如何转成整型呢?
答:字符串哈希函数。评价hash函数性能的一个重要指标就是冲突,在相关资源允许的条件下冲突越少hash函数的性能越好。
常见的字符串哈希算法BKDRHash,APHash,DJBHash…
eg:
// BKDR Hash Function
unsigned int BKDRHash(char *str)
{unsigned int seed = 131; // 31 131 1313 13131 131313 etc..unsigned int hash = 0;while (*str){hash = hash * seed + (*str++);}return (hash & 0x7FFFFFFF);
}
- 使用除留余数法,最好模一个素数,如何快速模一个类似两倍关系的素数?
答:使用了一个默认的素数集合,这个集合中包含了一系列素数。在不同的STL实现中,这个素数集合可能会有所不同。一般来说,这个集合中的素数经过仔细选择,以确保哈希表的负载因子(即平均哈希桶中元素的数量)保持在一个较小的范围内,从而提供更好的性能。
//素数集合
size_t GetNextPrime(size_t prime)
{const int PRIMECOUNT = 28;static const size_t primeList[PRIMECOUNT] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul, 786433ul,1572869ul, 3145739ul, 6291469ul, 12582917ul,25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul,805306457ul,1610612741ul, 3221225473ul, 4294967291ul};size_t i = 0;for (; i < PRIMECOUNT; ++i){if (primeList[i] > prime)return primeList[i];}return primeList[i];
}
哈希冲突(碰撞)
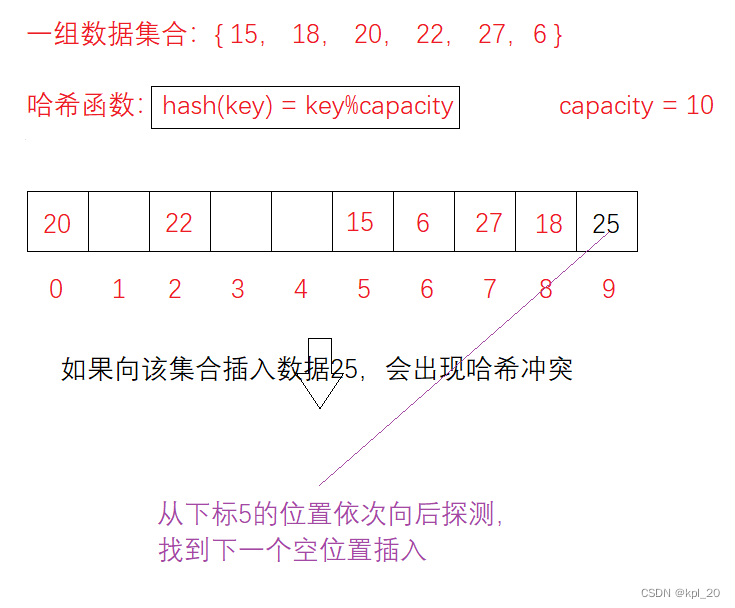
根据上面的例子,如果在数据集合中添加一个数据25,那么会发现通过哈希函数求的地址已经被别的关键码占据。
概念: 不同关键码通过相同的哈希函数计算出相同的哈希地址,被称为哈希冲突(碰撞)。
小结
哈希函数的设计跟哈希冲突有着必要的联系。
哈希函数的设计:
- 哈希函数的定义域,需要包含存储的全部关键码。值域,0到哈希表允许地址数最大值-1
- 哈希函数计算的地址,均匀分布在哈希表中
- 设计简单
3. 解决哈希碰撞
解决哈希碰撞的两种方法:闭散列和开散列
闭散列
闭散列:也叫开放地址法,当发生哈希冲突时,如果哈希表未被填满,说明哈希表还有空位置,那么就可以从冲突位置为起始找下一个空位置。
线性探测
概念:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
优缺点
- 优点:实现简单
- 缺点:一旦发生冲突连在一起,容易产生数据“堆积”。搜索效率下降
插入
- 通过哈希函数获取待插入元素在哈希表的目标位置
- 如果该位置没有元素直接插入,如果有元素则发生冲突,使用线性探测找到下一个空位置,然后插入。
eg:
删除
- 因为哈希冲突的原因,不能随便删除,会影响后面元素的搜索。例如:删除上个例子哈希表的6,那么我们查找25会被影响。
- 所以采用伪删除,给哈希表每个空间设置一个状态
`状态: EMPTY此位置为空,EXIST此位置有元素,DELETE此位置元素被删除。
enum STATE
{EXIST, EMPTY,DELETE
};`
二次探测
不同于线性探测是依次寻找空位置,二次探测是通过公式跳跃式的寻找空位置。
Hash(i) = (Hash(x) + i^2) % m;
Hash(X):通过哈希函数计算key值得到的位置,但是已经存在元素
Hash(i):将要存放位置
m:哈希表的大小
i = 1,2,3,4…
注意: 除了线性探测,二次探测,还有双重哈希…
代码实现
//开放地址法
namespace open_address
{//哈希函数template<class K>struct DefaultHashFunc{size_t operator()(const K& key){return size_t(key); //转成无符号整型}};//模板特化 -- 针对字符串 BKDRHash算法template<>struct DefaultHashFunc<string>{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash *= 131;hash += ch;}return hash;}};//状态enum STATE{EXIST,EMPTY,DELETE};//数据template<class K, class V>struct HashData{pair<K, V> _kv;STATE _state = EMPTY;};template<class K, class V, class HashFunc = DefaultHashFunc<K>>class HashTable{public:HashTable(){_table.resize(10); //给哈希表初始化十个空间}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;//扩容 --> 根据载荷因子//if ((double)_n / (double)_table.size() >= 0.7)if (10 * _n / _table.size() >= 7){size_t newSize = _table.size() * 2;//造新表HashTable<K, V, HashFunc> newHT;newHT._table.resize(newSize);//遍历旧表重新映射到新表for (size_t i = 0; i < _table.size(); i++){if (_table[i]._state == EXIST){newHT.Insert(_table[i]._kv);}}//交换新旧表,原空间出作用域自动销毁_table.swap(newHT._table);}//线性探测HashFunc hf;size_t hashi = hf(kv.first) % _table.size();while (_table[hashi]._state == EXIST){++hashi;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._state = EXIST;_n++;return true;}HashData<const K, V>* Find(const K& key){HashFunc hf;size_t hashi = hf(key) % _table.size();while (_table[hashi]._state != EMPTY){if (_table[hashi]._state == EXIST&& _table[hashi]._kv.first == key){//&_table[hashi]类型是HashData<K, V>*return (HashData<const K, V>*)&_table[hashi]; }++hashi;//如果到_table的最后了,绕到最前面hashi %= _table.size();}return nullptr;}bool Erase(const K& key){HashData<const K, V>* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}return false;}private:vector<HashData<K, V>> _table;size_t _n = 0; //存储有效数据};}
载荷因子(扩容)
载荷因子的就算方法:α = 表中有效的元素个数 / 散列表的长度。
对于开放地址法,载荷因子是特别重要的元素,通过一些科学实验,载荷因子应严格控制在0.7-0.8。∵散列表的长度是一定的,表中有效元素个数和α成正比,∴如果超过载荷因子0.8,产生冲突的可能就越大,查表时CPU缓存命中率低。再进行插入操作的时候要根据载荷因子判断需不需要扩容,用空间换时间
开散列
开散列:也叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同关键码的归于同一子集合,每个自己和称为一个桶,各个桶中的元素通过单链表链起来,各链表的头节点存在哈希表中。
哈希桶
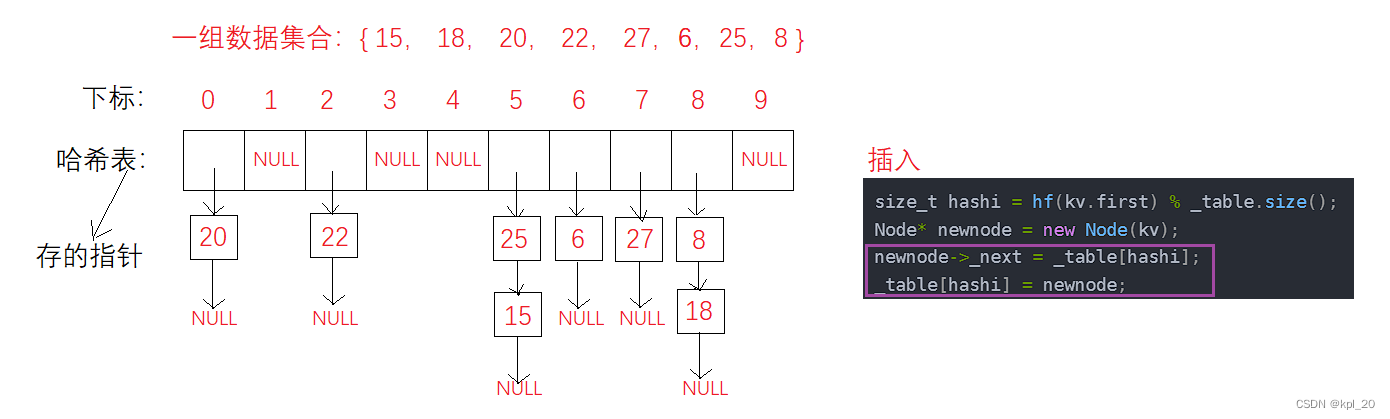
5和8下标都存在哈希冲突
代码实现
namespace hash_bucket
{template<class K>struct DefaultHashFunc{size_t operator()(const K& key){return size_t(key);}};//模板特化 -- 针对字符串template<>struct DefaultHashFunc<string>{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash *= 131;hash += ch;}return hash;}};template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;//初始化HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}};template<class K, class V, class HashFunc = DefaultHashFunc<K>>class HashTable{typedef HashNode<const K, V> Node;public:HashTable(){//开十个空间,初始化为nullptr_table.resize(10, nullptr);}~HashTable(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}bool Insert(const pair<K, V>& kv){if (Find(kv.first)){return false;}HashFunc hf;//负载因子到1扩容if (_n == _table.size()){size_t newSize = _table.size() * 2;vector<Node*> newTable;newTable.resize(newSize, nullptr);//遍历旧表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = hf(cur->_kv.first) % newSize;cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashi = hf(kv.first) % _table.size();Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;}Node* Find(const K& key){HashFunc hf;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){HashFunc hf;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (cur->_kv.first == key){if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}void Print(){for (size_t i = 0; i < _table.size(); i++){printf("[%d]->", i);Node* cur = _table[i];while (cur){cout << cur->_kv.first << ":" << cur->_kv.second << "->";cur = cur->_next;}printf("nullptr\n");}cout << endl;}private:vector<Node*> _table;size_t _n = 0;};
}
扩容
桶的个数是一定的(桶的个数 == 表的大小)。如果不进行扩容,可能一个桶中有很多元素,会影响哈希表的性能。开散列最完美的情况就是每个哈希桶中刚好挂一个节点,再插入时就会发生哈希冲突,因此判断扩容的条件就可以是: 元素的个数 == 桶的个数。
二、unordered系列封装
unordered系列set、map的容器接口和红黑树实现的set、map相似,使用大差不差,所以在这里就不进行介绍了。
hash_table
迭代器实现原理(单项迭代器)
- 迭代器++
- 当前桶没遍历完,直接通过链表找下一个节点
- 当前桶遍历完
a. 通过哈希函数确定当前存储位置然后+1
b. 循环(加过1的位置小于哈希表的大小)
- - Ⅰ.该位置不为空,则成功找到,直接返回
- - Ⅱ.该位置为空继续向后+1,继续循环判断
c. 循环结束没找到,返回nullptr
Self& operator++()
{if (_node->_next) //当前桶没完{_node = _node->_next;}else //当前桶完了{HashFunc hf;KeyOfT kot;size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();++hashi;while (hashi < _pht->_table.size()){if (_pht->_table[hashi]){_node = _pht->_table[hashi];return *this;}else{hashi++;}}_node = nullptr;}return *this;
}
hash_table实现代码
#include <vector>// 1、哈希表
// 2、封装map和set
// 3、普通迭代器
// 4、const迭代器
// 5、insert返回值 operator[]
// 6、key不能修改的问题namespace hash_bucket
{template<class K>struct DefaultHashFunc{size_t operator()(const K& key){return (size_t)key;}};template<> //特化struct DefaultHashFunc<string>{size_t operator()(const string& str){size_t hash = 0;for (auto ch : str){hash *= 131;hash += ch;}return hash;}};template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};//类前置声明 --> 因为迭代器的实现会调用哈希表指针template<class K, class T, class KeyOfT, class HashFunc>class HashTable;//迭代器template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>struct HTIterator{typedef HashNode<T> Node;typedef HTIterator<K, T, Ptr, Ref, KeyOfT, HashFunc> Self;//普通迭代器typedef HTIterator<K, T, T*, T&, KeyOfT, HashFunc> Iterator;Node* _node;//哈希表指针 注意这里要加上const限制*this,不然哈希表调用时的this是const的会导致权限放大const HashTable<K, T, KeyOfT, HashFunc>* _pht;HTIterator(Node* node, const HashTable<K, T, KeyOfT, HashFunc>* pht):_node(node),_pht(pht){}//普通迭代器时,是拷贝构造//const迭代器时,是构造。普通迭代器构造const迭代器HTIterator(const Iterator& it):_node(it._node), _pht(it._pht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}Self& operator++(){if (_node->_next) //当前桶没完{_node = _node->_next;}else //当前桶完了{HashFunc hf;KeyOfT kot;size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();++hashi;while (hashi < _pht->_table.size()){if (_pht->_table[hashi]){_node = _pht->_table[hashi];return *this;}else{hashi++;}}_node = nullptr;}return *this;}};//set -> hash_bucket::HashTable<K, K> _ht//map -> hash_bucket::HashTable<K, pair<K, V>> _httemplate<class K, class T, class KeyOfT, class HashFunc = DefaultHashFunc<K>>class HashTable{typedef HashNode<T> Node;//友元 迭代器的实现会调用哈希表指针template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>friend struct HTIterator;public:typedef HTIterator<K, T, T*, T&, KeyOfT, HashFunc> iterator;typedef HTIterator<K, T, const T*, const T&, KeyOfT, HashFunc> const_iterator;iterator begin(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];if (cur){return iterator(cur, this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}const_iterator begin() const{for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];if (cur){return const_iterator(cur, this);}}return const_iterator(nullptr, this);}const_iterator end() const{return const_iterator(nullptr, this);}HashTable(){_table.resize(10, nullptr);}~HashTable(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}pair<iterator, bool> Insert(const T& data){HashFunc hf;KeyOfT kot;iterator it = Find(kot(data));if (it != end()){return make_pair(it, false);}// 负载因子到1--扩容if (_n == _table.size()){size_t newSize = _table.size() * 2;vector<Node*> newTable;newTable.resize(newSize, nullptr);// 遍历旧表,把节点牵下来挂到新表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = hf(kot(data)) % newSize;cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashi = hf(kot(data)) % _table.size();// 头插Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);}iterator Find(const K& key){HashFunc hf;KeyOfT kot;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return iterator(nullptr, this);}bool Erase(const K& key){HashFunc hf;KeyOfT kot;size_t hashi = hf(key) % _table.size();Node* prev = nullptr;Node* cur = _table[hashi];while (cur){if (kot(cur->_data) == key){if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}--_n;return false;}private:vector<Node*> _table; // 指针数组size_t _n = 0; // 存储有效数据个数};
}
unordered_set封装
namespace kpl
{template<class K>class unordered_set{//该仿函数只是跟map跑struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator iterator;typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator const_iterator;const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}pair<iterator, bool> insert(const K& key){//这里返回值的first的迭代器是普通迭代器,用普通迭代器接收pair<typename hash_bucket::HashTable<K, K, SetKeyOfT>::iterator, bool> ret = _ht.Insert(key);//使用普通迭代器构造一个const的迭代器,这里就体现出迭代器实现中的那个拷贝构造return pair<iterator, bool>(ret.first, ret.second);}private:hash_bucket::HashTable<K, K, SetKeyOfT> _ht;};
}
unordered_map封装
namespace kpl
{template<class K, class V>class unordered_map{//仿函数的主要作用在这里,set的封装只是跟跑,为了就是去键值对的keystruct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}//返回值是与key对应的value的值。V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}private:hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT> _ht;};}
三、总结
闭散列的缺陷:空间利用率低,用空间换时间,这也是哈希缺陷
开散列和闭散列的区别:
链地址法比开地址法更加的节省存储空间。原因:虽然链地址法增加了连接指针,但是开地址法为了保证搜索效率,必须保持大量的空闲空间。
unordered_set和unordered_map
- 前向迭代器
- 遍历出来不是有序
- 通过key访问当个元素的效率比set和map快,遍历元素子集的范围迭代方面效率较低
其余的特征和set,map大差不差,可以参考我的上一篇博客
相关文章:
哈希和unordered系列封装(C++)
哈希和unordered系列封装 一、哈希1. 概念2. 哈希函数,哈希碰撞哈希函数(常用的两个)哈希冲突(碰撞)小结 3. 解决哈希碰撞闭散列线性探测二次探测代码实现载荷因子(扩容) 开散列哈希桶代码实现扩…...

PHP基础与安全
基础 1. 简介概述 ●PHP是脚本语言-是一门弱类型语言,不需要事先编译 ●PHP 脚本在服务器上执行,然后向浏览器发送回纯文本的 HTML 结果 ●超文本预处理器,服务器端脚本语 2.创建(声明)PHP变量 ● 变量以 $ 符号开…...

【面试HOT200】滑动窗口篇
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于【CodeTopHot200】进行的,每个知识点的修正和深入主要参…...
)
cocos2dx Animate3D(三)
一些总结 动作(Actions) move移动:moveto/moveby 从一个位置移动到另外一个位置 从一个位置移动多少数量级rotate旋转:rotateto/rotateby 从一个角度旋转到另外一个角度 旋转多少个数量级scale缩放:scaleto/scaleby …...
单文件组件MVVM
单文件组件&MVVM 所谓组件化开发,就是创建一个个组件。 Vue是一个大类,渲染一切从new Vue开始。 指定视图:el template render:jsx语法 $mount[数学公式] 编译App.vue,作为视图入口 单个组件:结构 样式 data compu…...
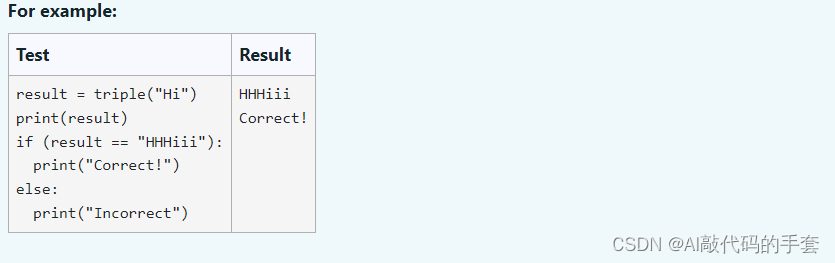
python基础练习题库实验6
文章目录 题目1代码实验结果题目2代码实验结果题目3代码实验结果题目4代码实验结果题目总结题目1 根据以下规范编写一个函数: 函数名称:triple输入参数:1个输入参数数据类型字符串返回值:函数返回1个字符串值。该字符串由每个字符重复3次的句子构成。例如,如果句子是Uni,…...
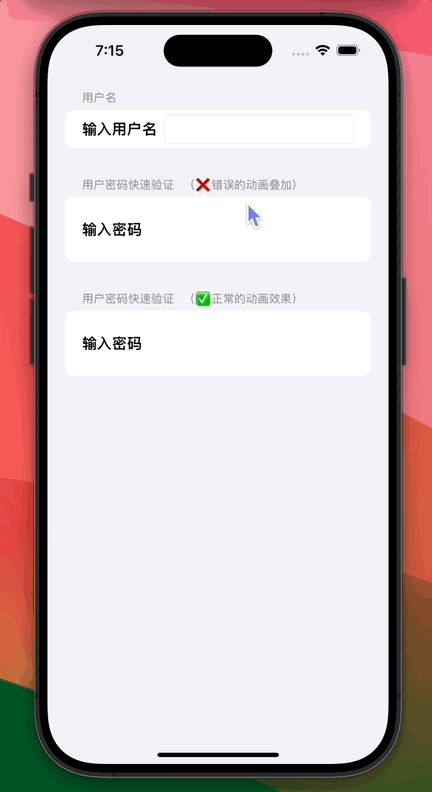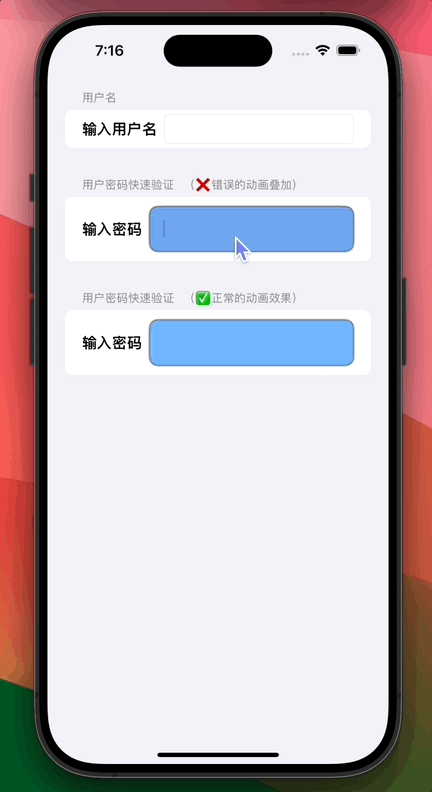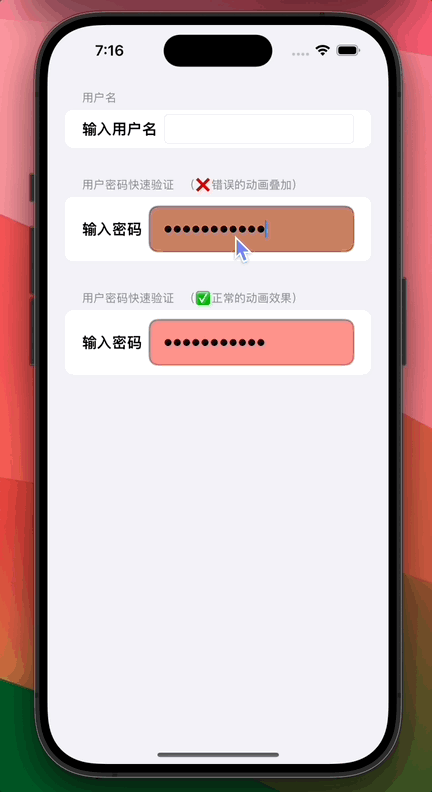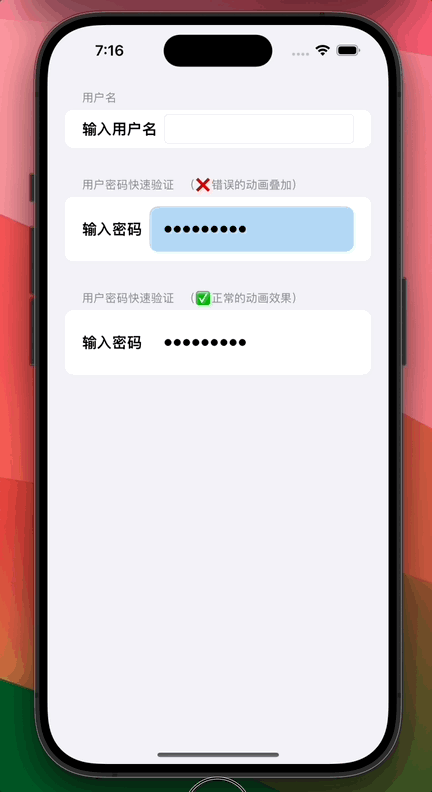
SwiftUI 如何动态开始和停止播放永久重复(repeatForever)动画
0. 功能需求 在 SwiftUI 丰富多彩的动画世界中,我们有时希望可以随意开始和停止永久循环(repeatForever)的动画,不过这时往往会产生错误的动画“叠加”效果。 从上图可以看到:虽然我们希望密码输入框背景只在用户输入密码时才发生闪烁,但顶部的密码输入框随着不断输入其…...

批量采集淘宝商品数据,有哪些方式可以实现?
引言 在当今的数字化时代,数据已经成为企业竞争的核心资源。对于电商行业来说,对商品数据的采集和分析更是关键。淘宝作为中国最大的电商平台之一,其丰富的商品数据和用户行为数据具有极高的价值。那么,如何批量采集淘宝商品数据…...
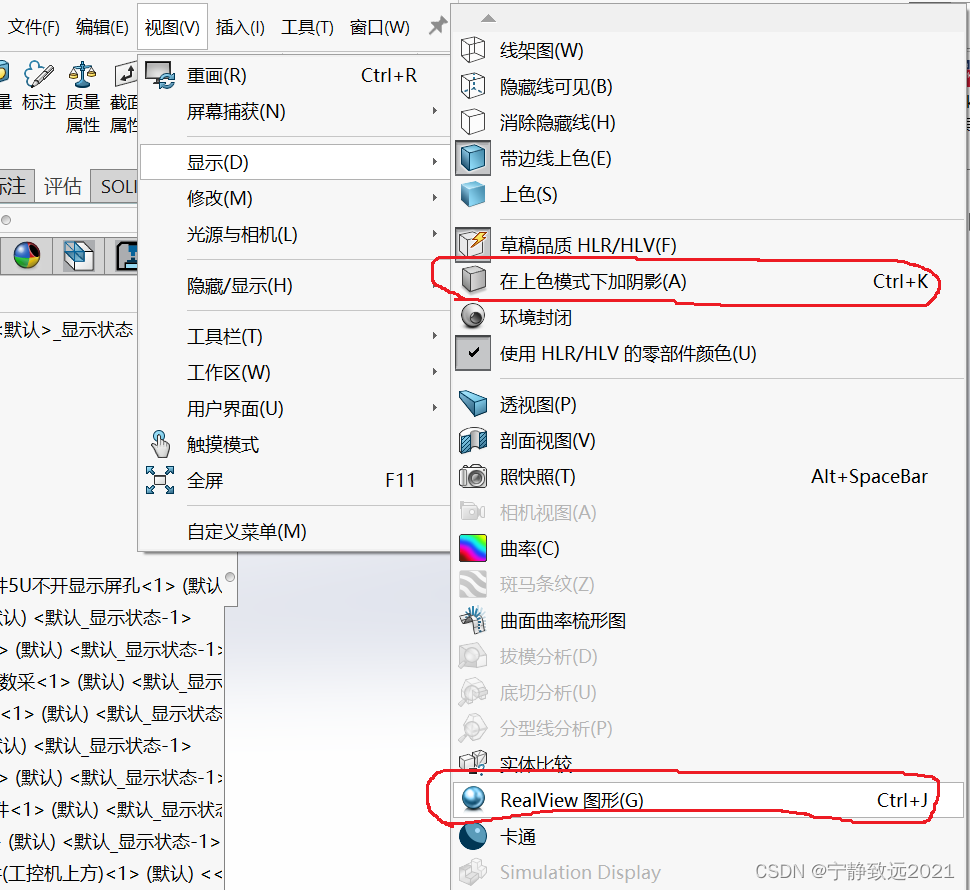
Solidworks模型上色技巧以及增加快捷键快速打开和关闭“阴影效果和楼板反射”
Solidworks模型上色技巧 Chapter1 给Solidworks模型上色技巧设置外观的方法具体操作删除颜色的技巧这样操作: Chapter2 SOLIDWORKS小技巧 | SolidWorks装配体零件快速上色自动设置Chapter3 solidworks装配图如何去掉阴影?Solidworks2022中的阴影效果怎么…...
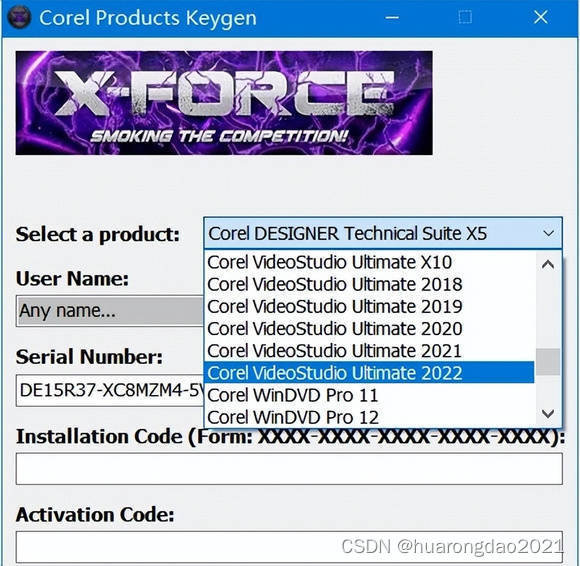
Corel产品注册机Corel Products KeyGen 2023 – XFORCE解决会声会影2023试用30天
CorelDRAW注册机2023支持全系列产品_Corel Products KeyGen 2023 X-FORCE v8 CorelDRAW注册机2023支持全系列产品_Corel Products KeyGen 2023 X-FORCE v8,Corel产品注册机(Corel Products KeyGen 2023 – XFORCE),支持Corel旗下所…...

18、Android 组件化
Android 组件化架构设计从原理到实战-CSDN博客 Android组件化架构解析总结_android 组件化架构_PalmerYang的博客-CSDN博客 Android组件化开发,从未如此简单 - 知乎...

智慧城市交通大屏|助力解决城市交通问题
2017年起,数字孪生连续三年被Gartner列入“未来科技十大趋势”,由此可见数字孪生技术正屹立在数字化发展的风口之中。 数字孪生作为物理世界的数字映射,将流程、物体的信息利用数字技术实时映射到系统中,可以对某个设备、某个企业…...

kafka2.x常用命令:创建topic,查看topic列表、分区、副本详情,删除topic,测试topic发送与消费
原创/朱季谦 接触kafka开发已经两年多,也看过关于kafka的一些书,但一直没有怎么对它做总结,借着最近正好在看《Apache Kafka实战》一书,同时自己又搭建了三台kafka服务器,正好可以做一些总结记录。 本文主要是记录如…...
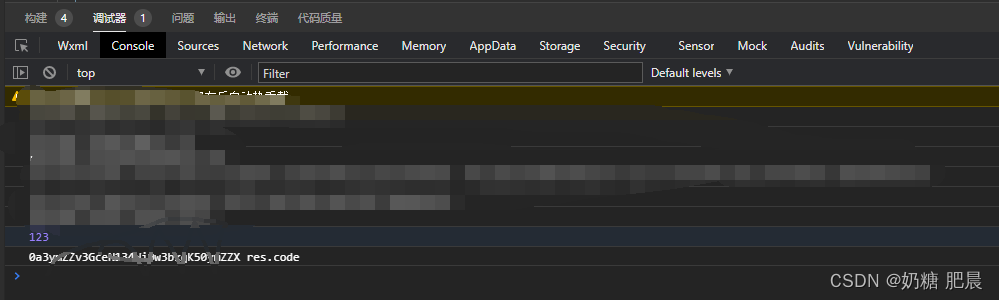
小程序静默授权获取unionid
文章目录 导文文章重点 导文 小程序静默授权获取unionid 文章重点 用wx.login(Object object)放到app.js里面 wx.login({success (res) {console.log(123);if (res.code) {//发起网络请求// wx.request({// url: https://example.com/onLogin,// data: {// code: res.…...
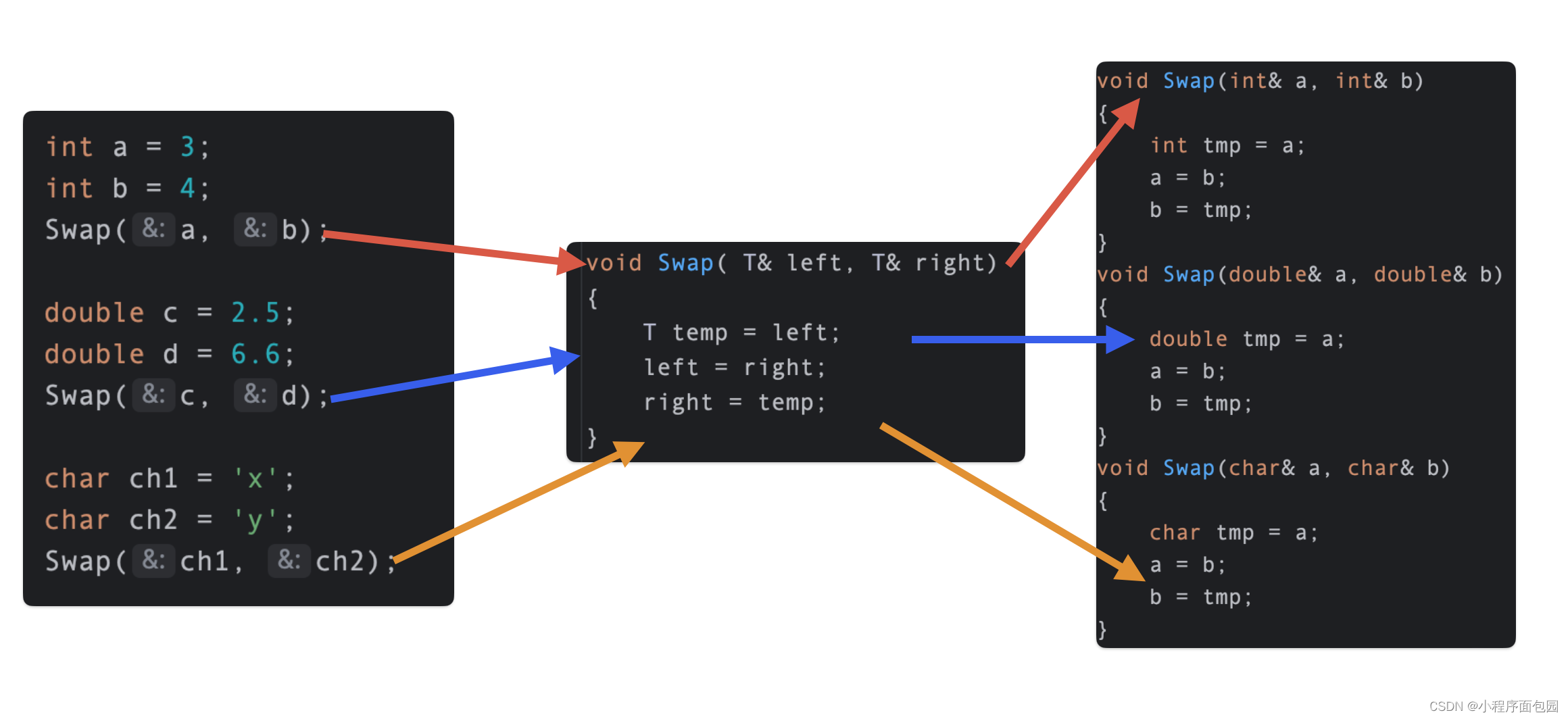
C++之模版初阶(简单使用模版)
前言 在学习C的模版之前,咱们先来说一说模版的概念,模版在我们的日常生活中非常常见,比如我们要做一个ppt,我们会去在WPS找个ppt的模版,我们只需要写入内容即可;比如我们的数学公式,给公式套值&…...
如何提高工作效率和决策能力?试试宽屏尺寸的可视化大屏
[作者整理了17份宽屏尺寸的可视化大屏源文件,开箱即用,支持二次开发!有需要可私我发你提取码哈~!] 随着科技的不断发展,宽屏尺寸的可视化大屏已经成为了商务、政府和企业等领域中不可或缺的一部分。这种大屏幕具有高清…...

OSG编程指南<十三>:OSG渲染状态
1、前言 在 OSG 中存在两棵树,即场景树和渲染树。渲染树是一棵以 StateSet 和 RenderLeaf 为节点的树,它可以做到 StateSet 相同的 RenderLeaf 同时渲染而不用切换 OpenGL状态,并且做到尽量少但在多个不同 State 间切换。渲染树在 CullVisito…...
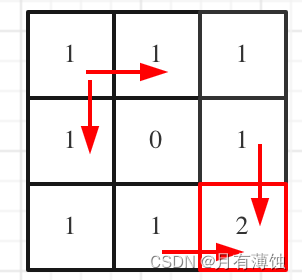
不同路径 II(力扣LeetCode)动态规划
不同路径 II 题目描述 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。 现在考虑网格中有障碍物。…...

探索深度学习:从理论到实践的全面指南
探索深度学习:从理论到实践的全面指南 摘要: 本文旨在提供一个关于深度学习的全面指南,带领读者从理论基础到实践应用全方位了解这一技术。我们将介绍深度学习的历史、基本原理、常用算法和应用场景,并通过Python代码示例和Tens…...
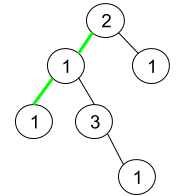
统计二叉树中的伪回文路径 : 用位运用来加速??
题目描述 这是 LeetCode 上的 「1457. 二叉树中的伪回文路径」 ,难度为 「中等」。 Tag : 「DFS」、「位运算」 给你一棵二叉树,每个节点的值为 1 到 9 。 我们称二叉树中的一条路径是 「伪回文」的,当它满足:路径经过的所有节点值…...

YOLO11实例分割教程:快速掌握数据标注、格式转换与模型训练
YOLO11实例分割教程:快速掌握数据标注、格式转换与模型训练 1. 准备工作与环境搭建 1.1 获取YOLO11镜像 YOLO11镜像提供了完整的计算机视觉开发环境,包含预装好的所有依赖项。您可以通过以下两种方式使用: Jupyter Notebook方式࿱…...

逆向思维看保护:我是如何用VMProtect SDK给自己的工具软件“上锁”,并防止被破解的?
逆向思维构建软件护城河:VMProtect SDK实战防御手册 当我在深夜调试自己开发的工具软件时,突然冒出一个念头:如果我是黑客,会如何破解这个软件?这个看似简单的自问,彻底改变了我对软件保护的认知方式。传统…...

HagiCode Soul 平台技术解析:从需求萌发到独立平台的演进之路奶
1 安装与初始化 # 全局安装 OpenSpec npm install -g fission-ai/openspeclatest # 在项目目录下初始化 cd /path/to/your-project openspec init 初始化时,OpenSpec 会提示你选择使用的 AI 工具(Claude Code、Cursor、Trae、Qoder 等)。 3 O…...

我让 Claude 和 Codex 同时审计 个模块,它们只在 个上达成共识砸
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

给硬件工程师讲明白:为什么DDR读写时DQS和DQ要对齐两次?
为什么DDR读写时DQS和DQ要对齐两次?硬件工程师的深度解析 调试DDR接口时序时,很多工程师都会遇到一个令人困惑的现象:读操作要求DQS边沿与DQ边沿对齐,而写操作却要求DQS边沿与DQ中心对齐。这种"双重标准"背后隐藏着怎样…...

如何在 Divi 主题中禁用锚点链接的平滑滚动动画
本文介绍一种无需修改 Divi 核心文件的安全方式,通过重写 et_pb_smooth_scroll 全局函数,将锚点跳转强制设为瞬时定位(0ms 动画),彻底禁用默认的平滑滚动效果。 本文介绍一种无需修改 divi 核心文件的安全方式&am…...

3步解决Mac视频预览难题:QuickLookVideo让你的Finder支持MKV等格式
3步解决Mac视频预览难题:QuickLookVideo让你的Finder支持MKV等格式 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: ht…...

猫抓浏览器扩展终极指南:一站式网页资源嗅探解决方案
猫抓浏览器扩展终极指南:一站式网页资源嗅探解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为无法下载网页视频、音频而烦…...
替代传统统计公平性的工程实践(附FAIR-ML Pipeline v3.1源码))
为什么你的公平性测试总被算法团队驳回?——用因果公平性度量(CFM)替代传统统计公平性的工程实践(附FAIR-ML Pipeline v3.1源码)
第一章:大模型工程化中的模型公平性评估 2026奇点智能技术大会(https://ml-summit.org) 大模型在部署前必须通过系统化的公平性评估,否则可能在招聘筛选、信贷审批、司法辅助等高风险场景中放大社会偏见。公平性不是单一指标,而是涵盖群体公…...

FPGA 实现 YCbCr 到 RGB 色彩空间转换的定点化设计
1. 色彩空间转换的基础原理 第一次接触YCbCr和RGB转换时,我完全被那些小数系数搞晕了。后来才发现,这其实就是把颜色信息用不同方式"打包"的过程。想象你有一套乐高积木,RGB是按红绿蓝三种基础积木的数量来记录,而YCbCr…...