带着GPT-4V(ision)上路,自动驾驶新探索
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving

GitHub | https://github.com/PJLab-ADG/GPT4V-AD-Exploration
arXiv | https://arxiv.org/abs/2311.05332
自动驾驶技术的追求取决于对感知、决策和控制系统的复杂集成。传统方法,无论是数据驱动还是基于规则的方法,都因其无法把握复杂驾驶环境和其他道路使用者意图的能力而受到阻碍
这一点尤其是在发展常识推理和对安全可靠的自动驾驶所必需的微妙场景理解方面,一直是一个重要的瓶颈。视觉语言模型(VLM)的出现代表着实现完全自主驾驶汽车的一个新领域。本报告对最新的 VLM 技术进行了详尽的评估,并探讨了其在自动驾驶场景中的应用
作者团队研究了该模型理解和推理驾驶场景、做出决策,并最终充当驾驶员角色的能力。涵盖从基本场景识别到复杂因果推理和在不同条件下实时决策的全面测试。研究结果显示,与现有的自动驾驶系统相比,视觉语言模型在场景理解和因果推理方面表现出色
文章展示了处理分布之外场景、识别意图并在实际驾驶环境中做出明智决策的潜力。然而,仍然存在一些挑战,特别是在方向判断、交通灯识别、视觉引导和空间推理任务方面。这些局限性强调了进一步的研究和开发的必要性
NExT-Chat: An LMM for Chat, Detection and Segmentation

arXiv | https://arxiv.org/abs/2311.04498
大型语言模型(LLMs)的发展极大地推动了多模态理解领域的进步,使得大型多模态模型(LMMs)不断涌现。为了提高对视觉的理解水平,近期的研究将通过将物体边界框坐标表示为一系列文本序列(pixel2seq)使得LMMs配备了区域级别的理解能力
在本文中,引入了一种称为 pixel2emb 方法的物体定位建模新范例,其中要求 LMM 输出位置embedding,然后通过不同的解码器对其进行解码。允许在多模态对话中使用不同的位置格式(如bounding boxes和mask)
此外,这种embedding-based的位置建模可以结合检测和分割等定位任务。在资源有限的场景中, pixel2emb 在位置输入和输出任务中表现出比SOTA方法更优越的性能。通过利用所提出的 pixel2emb 方法,还训练了一个名为 NExT-Chat 的 LMM,并展示了它处理多任务(如视觉引导、场景描述和基础推理)的能力
Video Instance Matting

arXiv | https://arxiv.org/abs/2311.04212
传统的视频抠图为视频帧中出现的所有实例输出一个 alpha 遮罩。虽然视频实例分割提供了时间一致的实例掩模,但由于应用了二值化,其结果对于抠像应用来说并不理想
为了解决这个问题,本文提出了视频实例抠图(VIM),即在视频序列的每一帧中估计每个实例的 alpha 抠图。具体的,提出 MSG-VIM,即 Mask Sequence Guided Video Instance Matting 神经网络,作为 VIM 的新基线模型
MSG-VIM 利用混合的掩模增强来使预测对不准确和不一致的掩模引导更具有鲁棒性。它结合了时间掩模和时间特征引导,以提高 alpha 抠图预测的时间一致性。此外,建立了一个新的 VIM 基准,称为 VIM50,其中包括 50 个视频剪辑,具有多个人类实例作为前景对象
为了评估在 VIM 任务上的性能,引入了一个度量标准,称为 Video Instance-aware Matting Quality(VIMQ)。所提 MSG-VIM 在 VIM50 上构建了一个强有力的baseline,并在很大程度上优于现有方法。该项目开源在
https://github.com/SHI-Labs/VIM
EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision

arXiv | https://arxiv.org/abs/2311.02077
本文提出 EmerNeRF,这是一种简单而强大的方法,用于学习动态驾驶场景的时空表示。基于神经场,EmerNeRF 通过自助引导同时捕捉场景几何、外观、运动和语义
EmerNeRF 依赖于两个核心组件:
- 首先,将场景分为静态场和动态场。这种分解是通过自我监督产生的,使模型能够从一般的野外数据源中学习
- 其次,
EmerNeRF从动态场中参数化一个引导流场,并使用该流场进一步聚合多帧特征,提高动态对象的渲染精度
将这三个场(静态、动态和流)耦合在一起使 EmerNeRF 能够自给自足地表示高度动态的场景,无需依赖地面真值对象注释或预训练的动态对象分割或光流估计模型。本文方法在传感器模拟中实现了最先进的性能,在重建静态(+2.93 PSNR)和动态(+3.70 PSNR)场景时显著优于先前的方法
此外,为了增强 EmerNeRF 的语义泛化,将 2D 视觉基础模型特征提升到 4D 时空,并解决现代 Transformers 中的一般位置偏差,显著提高了 3D 感知性能(例如,在occupancy预测准确度上相对提高了 37.50%)。最后,构建了一个多样且具有挑战性的120-sequence数据集,以在极端和高度动态的环境中对神经场进行基准测试
Holistic Evaluation of Text-To-Image Models

项目地址 | https://crfm.stanford.edu/heim/v1.1.0
GitHub | https://github.com/stanford-crfm/helm
arXiv | https://arxiv.org/abs/2311.04287
最近的文本到图像模型令人惊叹的质量改进引起了广泛的关注。然而,他们缺乏对其能力和风险的全面定量了解。为了填补这一空白,本文引入了一个新的基准:文本到图像模型的整体评估(HEIM)
虽然之前的评估主要关注文本图像对齐和图像质量,但作者确定了 12 个方面,包括文本与图像的对齐、图像质量、美感、独创性、推理能力、知识水平、偏见、有害信息、公平性、稳健性、多语言支持和效率
他们策划了62个涵盖这些方面的场景,并在这一基准测试中评估了26个最先进的文本到图像模型。结果显示,没有单一模型在所有方面都表现出色,不同模型展现出不同的优势
以上就是本期全部内容,我是啥都生,下次再见
相关文章:
带着GPT-4V(ision)上路,自动驾驶新探索
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving GitHub | https://github.com/PJLab-ADG/GPT4V-AD-Exploration arXiv | https://arxiv.org/abs/2311.05332 自动驾驶技术的追求取决于对感知、决策和控制系统的复杂集成。…...

19. Python 数据处理之 Pandas
目录 1. 认识 Pandas2. 安装和导入 Pandas3. Pandas 数据结构4. Pandas 基本功能5. Pandas 数据分析 1. 认识 Pandas Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。 Pandas 的出…...

【计网 可靠数据传输RDT】 中科大笔记 (十 一)
目录 0 引言1 RDT的原理RDT的原理: 2 RDT的机制与作用2.1 重要协议停等协议(Stop-and-Wait):连续ARQ协议: 2.2 机制与作用实现机制:RDT的作用: 🙋♂️ 作者:海码007📜 专栏&#x…...
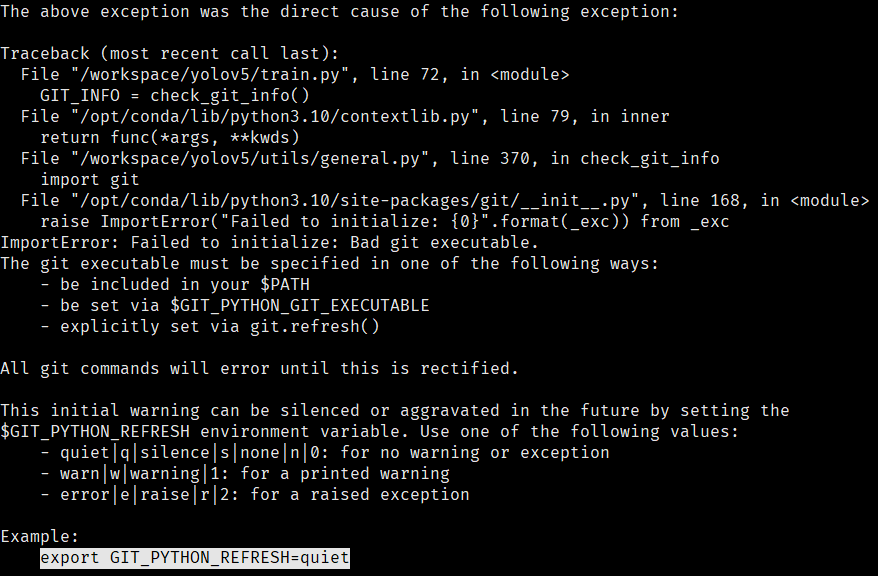
ubuntu下训练自己的yolov5数据集
参考文档 yolov5-github yolov5-github-训练文档 csdn训练博客 一、配置环境 1.1 安装依赖包 前往清华源官方地址 选择适合自己的版本替换自己的源 # 备份源文件 sudo cp /etc/apt/sources.list /etc/apt/sources.list_bak # 修改源文件 # 更新 sudo apt update &&a…...
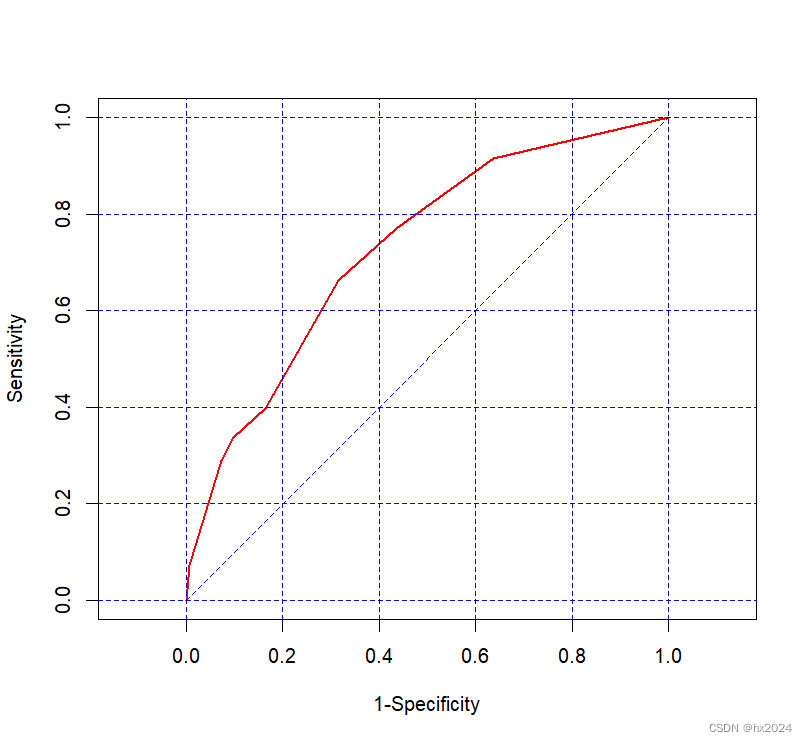
ROC及曲线面积汇总学习
目录 ROC基础 生成模拟数据 率的计算 R语言计算测试 ROCR: pROC ROC绘制 单个ROC 两个ROC Logistic回归的ROC曲线 timeROC ROC基础 ROC曲线的横坐标是假阳性率,纵坐标是真阳性率,需要的结果是这个率表示疾病阳性的率(…...

LeetCode Hot100 35.搜索插入位置
题目: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 方法:灵神 二分查找 闭区间写法 c…...

Android frameworks 开发总结之八
Quick Settings增加一項 XXX device要求在quick settings中增加一項touch panel. 在/frameworks/base/packages/SystemUI/res/values/config.xml文件中的quick_settings_tiles_default string 中增加touch panel。並在String resource文件中增加顯示的title <!-- The def…...
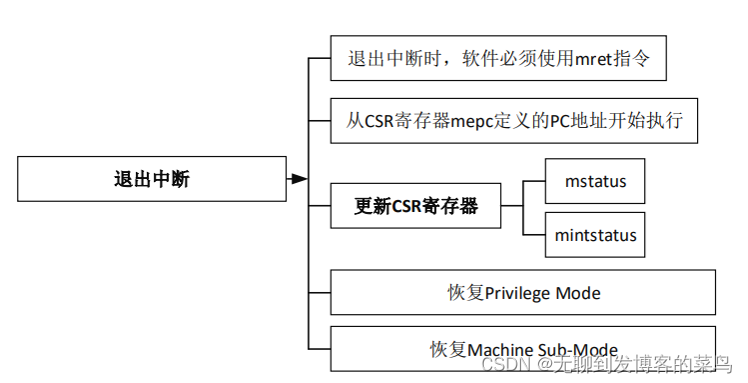
Cortex-M与RISC-V区别
环境 Cortex-M以STM32H750为代表,RISC-V以芯来为代表 RTOS版本为RT-Thread 4.1.1 寄存器 RISC-V 常用汇编 RISC-V 关于STORE x4, 4(sp)这种寄存器前面带数字的写法,其意思为将x4的值存入sp4这个地址,即前面的数字表示偏移的意思 反之LOA…...

YashanDB入选2023年世界互联网大会领先科技奖成果集《科技之魅》
近日,由深圳计算科学研究院自主研发的“崖山数据库系统YashanDB”入编2023年世界互联网大会领先科技奖成果集《科技之魅》。此次入选,充分彰显了YashanDB在数据库技术领域的突破性创新成果。 《科技之魅》是世界互联网大会领先科技奖的重要成果ÿ…...
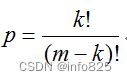
C语言基础程序设计题
1.个人所得税计算 应纳税款的计算公式如下:收入<=1000元部分税率为0%,2000元>=收入>1000元的部分税率为5%,3000元>=收入>2000元的部分税率为10%…...
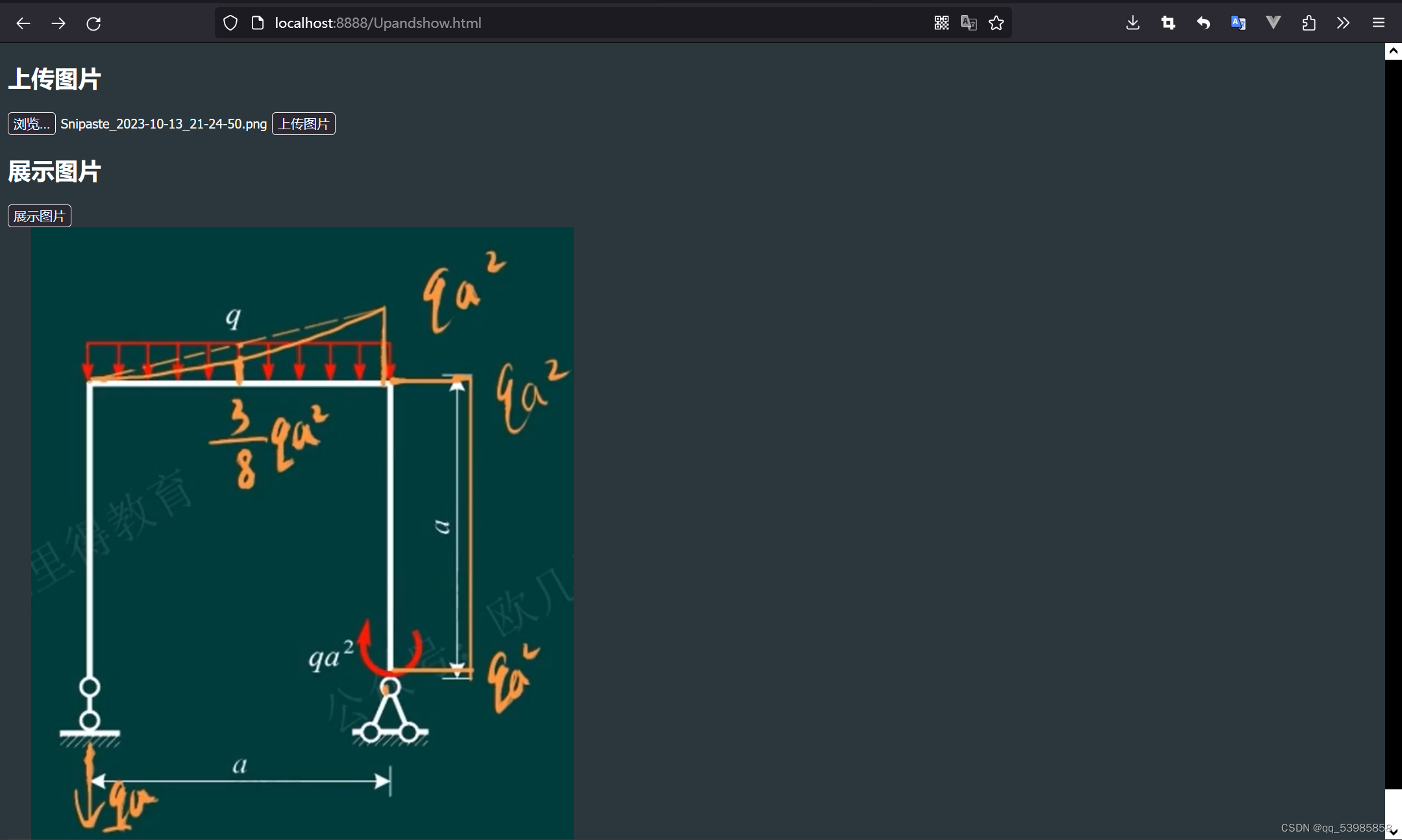
Spring Boot实现图片上传和展示
Spring Boot实现图片上传和展示 本文将介绍如何使用Spring Boot框架搭建后端服务,实现接收前端上传的图片并保存到resources/images目录下。同时,我们还将展示如何在前端编写一个HTML页面,实现上传图片和从resources/images目录下获取图片并…...
)
大数据-之LibrA数据库系统告警处理(ALM-37015 Gaussdb进程可用文件句柄资源不足)
告警解释 操作系统环境文件句柄不足时,产生该告警。 告警属性 告警ID 告警级别 可自动清除 37015 严重 是 告警参数 参数名称 参数含义 ServiceName 产生告警的服务名称 RoleName 产生告警的角色名称 HostName 产生告警的主机名 Instance 产生告警…...

大一学编程怎么学?刚接触编程怎么学习,有没有中文编程开发语言工具?
大一学编程怎么学?刚接触编程怎么学习,有没有中文编程开发语言工具? 1、大一刚开始学编程,面对复杂的代码学习非常吃力,很难入门。建议刚接触编程可以先学习中文编程,了解其中的编程逻辑,学编程…...

GoWeb学习-第二天
文章目录 从零开始学Go web——第二天一、安装Go语言二、建立web目录2.1 创建GO语言包目录2.2 创建Go web文件 三、编译并运行Go web应用3.1 编译并运行3.2 查看结果 从零开始学Go web——第二天 第一天我们了解了与web息息相关的HTTP协议,聊了聊Go与web的关系等…...

04-鸿蒙4.0学习之样式装饰器相关
04-鸿蒙4.0学习之样式装饰器 styles装饰器:定义组件重用样式 /*** styles装饰器:定义组件重用样式*/ Entry Component struct StyleUI {State message: string stylesStyles commonStyle(){.width(200).height(100).backgroundColor(Color.Gray).marg…...
)
C# 线程(1)
目录 1 线程与进程2 创建线程3 线程等待4 线程优先级5 前台线程与后台线程6 Lock与线程安全7 Monitor8 死锁9 线程中异常处理 1 线程与进程 进程是计算机概念,一个程序运用时占用的的所有计算机资源(CPU、内存、硬盘、网络)统称为进程。 线程…...
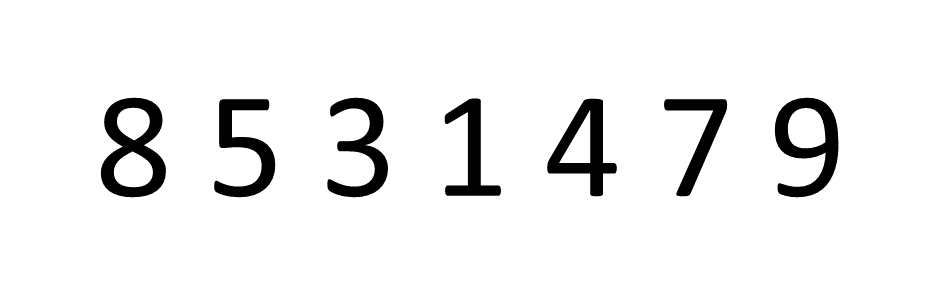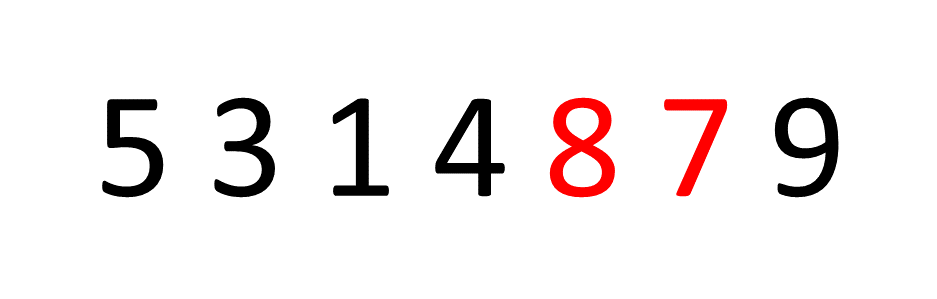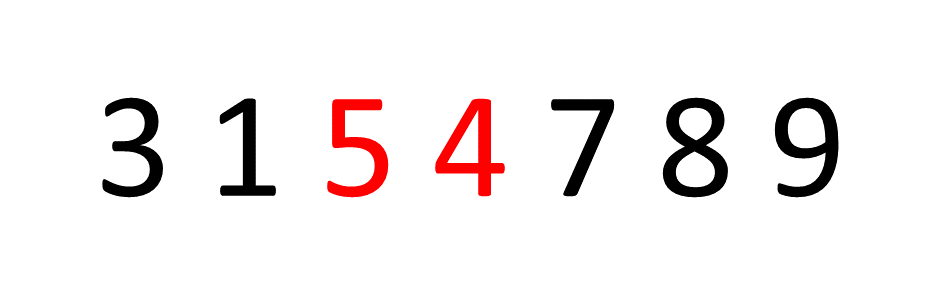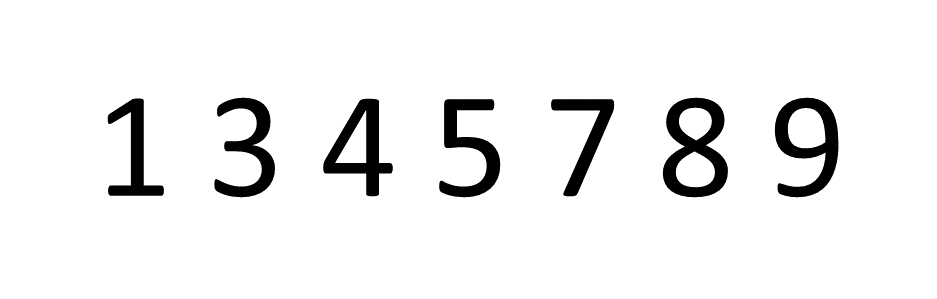
冒泡排序以及改进方案
冒泡排序以及改进方案 介绍: 冒泡排序属于一种典型的交换排序(两两比较)。冒泡排序就像是把一杯子里的气泡一个个往上冒一样。它不断比较相邻的元素,如果顺序不对就像水泡一样交换它们的位置,直到整个序列像水泡一样…...

QTextEdit 是 Qt 框架中的一个类,用于显示和编辑多行文本内容的可编辑部件
QTextEdit 是 Qt 框架中的一个类,用于显示和编辑多行文本内容的可编辑部件。 QTextEdit 提供了一个用于显示和编辑富文本(包括格式化文本、图像和链接等)和纯文本的文本编辑器。它支持基本的文本操作(如复制、粘贴、撤销、重做等…...
vue+jsonp编写可导出html的模版,可通过外部改json动态更新页面内容
效果 导出后文件结果如图所示,点击Index.html即可查看页面,页面所有数据由report.json控制,修改report.json内容即可改变index.html展示内容 具体实现 1. 编写数据存储的json文件 在index.html所在的public页面新建report.json文件ÿ…...

查看各ip下的连接数
netstat -n | awk /^tcp/ {print $5} | awk -F: {print $1} | sort | uniq -c| sort -rn netstat -n:显示所有的网络连接,不包括任何服务名的解释。awk /^tcp/ {print $5}:使用awk命令过滤出tcp协议的连接,并打印出每个连接的第五…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...