【深度学习】卷积神经网络结构组成与解释
1. 卷积层
常见的卷积操作如下:
| 卷积操作 | 解释 | 图解 |
| 标准卷积 | 一般采用3x3、5x5、7x7的卷积核进行卷积操作。 | 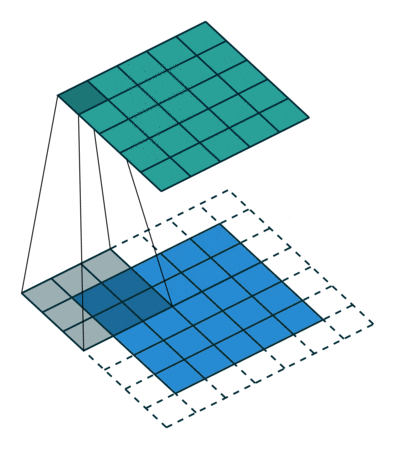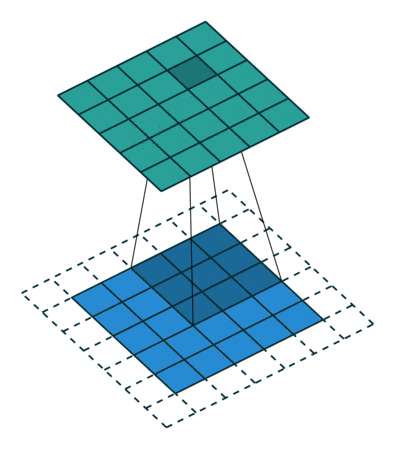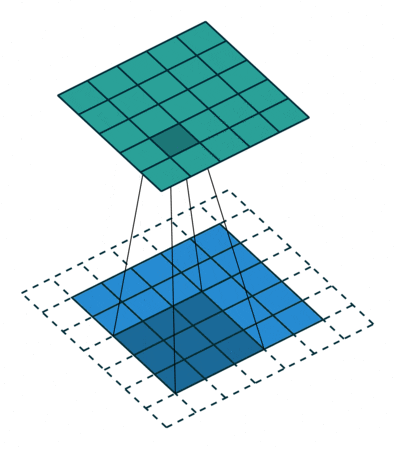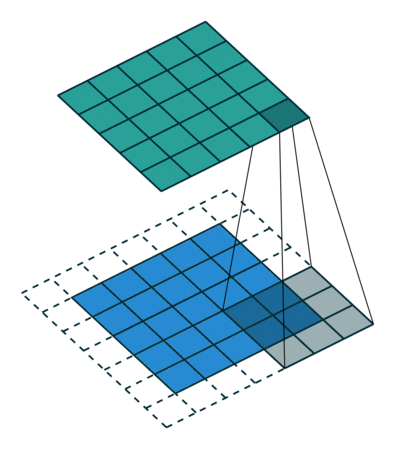 |
| 分组卷积 | 将输入特征图按通道均分为 x 组,然后对每一组进行常规卷积,最后再进行合并。 | 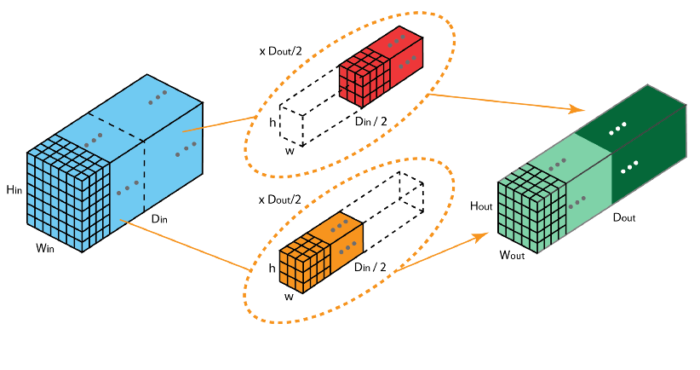 |
| 空洞卷积 | 为扩大感受野,在卷积核里面的元素之间插入空格来“膨胀”内核,形成“空洞卷积”(或称膨胀卷积),并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,则内核元素之间没有插入空格,变为标准卷积。 | 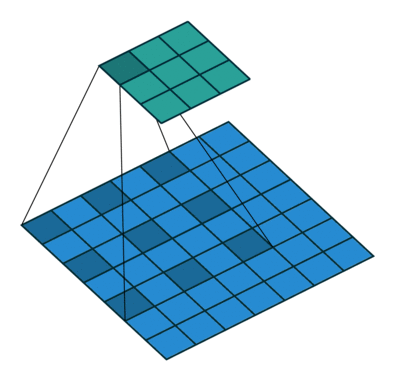 |
| 深度可分离卷积 | 深度可分离卷积包括为逐通道卷积和逐点卷积两个过程。 | 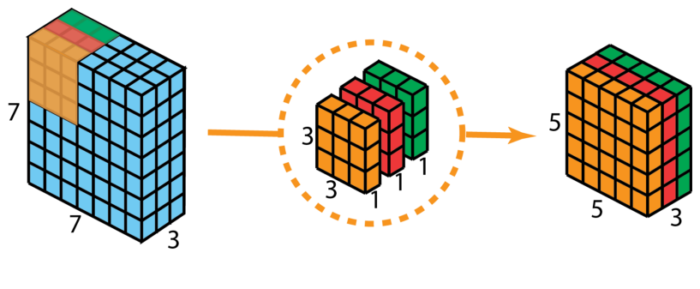 (通道卷积,2D标准卷积)
(逐点卷积,1x1卷积) |
| 反卷积 | 属于上采样过程,“反卷积”是将卷积核转换为稀疏矩阵后进行转置计算。 | 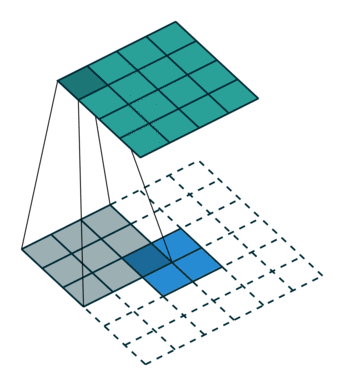 |
| 可变形卷积 | 指标准卷积操作中采样位置增加了一个偏移量offset,如此卷积核在训练过程中能扩展到很大的范围。 | 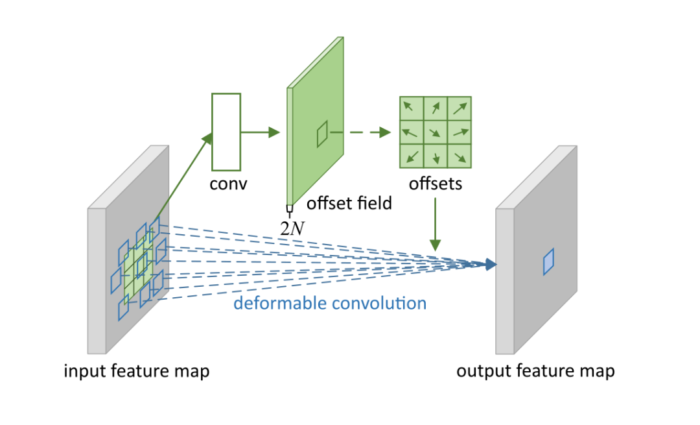 |
补充:
1 x 1卷积即用1 x 1的卷积核进行卷积操作,其作用在于升维与降维。升维操作常用于chennel为1(即是通道数为1)的情况下,降维操作常用于chennel为n(即是通道数为n)的情况下。
降维:通道数不变,数值改变。

升维:通道数改变为kernel的数量(即为filters),运算本质可以看为全连接。

卷积计算在深度神经网络中的量是极大的,压缩卷积计算量的主要方法如下:
| 序号 | 方法 |
| 1 | 采用多个3x3卷积核代替大卷积核(如用两个3 x 3的卷积核代替5 x 5的卷积核) |
| 2 | 采用深度可分离卷积(分组卷积) |
| 3 | 通道Shuffle |
| 4 | Pooling层 |
| 5 | Stride = 2 |
| 6 | 等等 |
2. 激活层
介绍:为了提升网络的非线性能力,以提高网络的表达能力。每个卷积层后都会跟一个激活层。激活函数主要分为饱和激活函数(sigmoid、tanh)与非饱和激活函数(ReLU、Leakly ReLU、ELU、PReLU、RReLU)。非饱和激活函数能够解决梯度消失的问题,能够加快收敛速度。
常用函数:ReLU函数、Leakly ReLU函数、ELU函数等
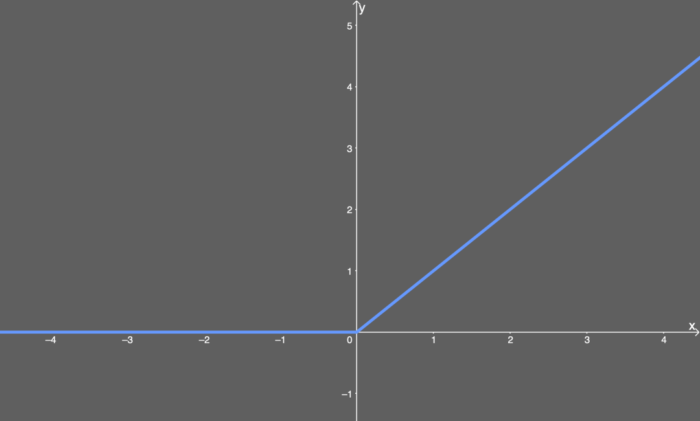
ReLU函数
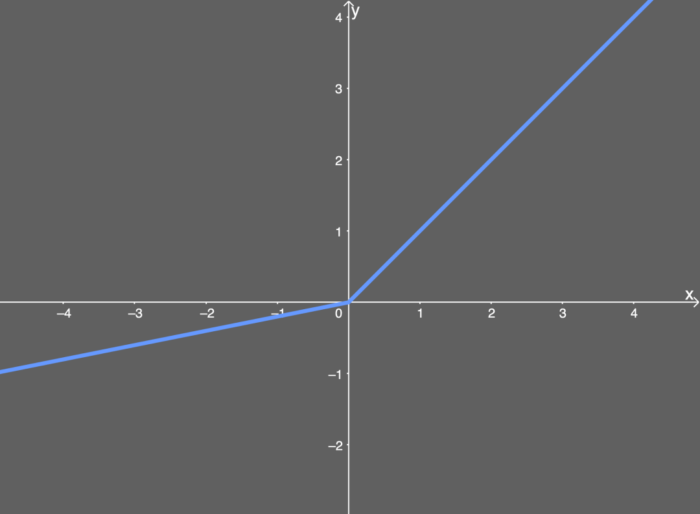
Leakly ReLU函数
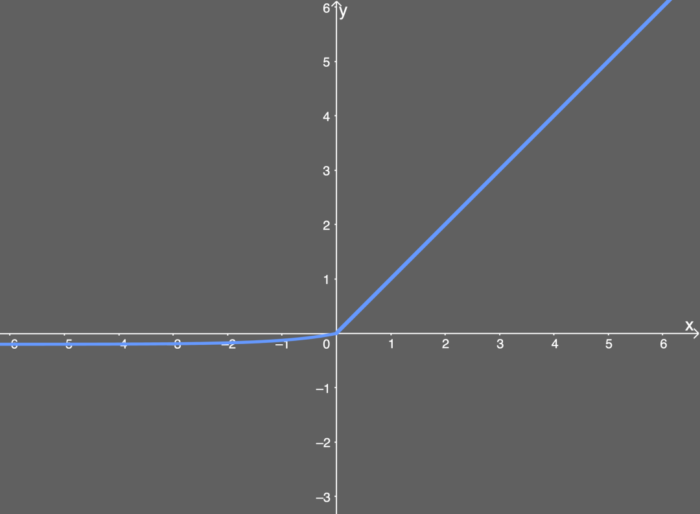
ELU函数
3. BN层(BatchNorm)
介绍:通过一定的规范化手段,把每层神经网络任意神经元的输入值的分布强行拉回到均值为0,方差为1的标准正态分布。BatchNorm是归一化的一种手段,会减小图像之间的绝对差异,突出相对差异,加快训练速度。但不适用于image-to-image以及对噪声明感的任务中。
常用函数:BatchNorm2d
pytorch用法:nn.BatchNorm2d(num_features, eps, momentum, affine)
num_features:一般输入参数为batch_sizenum_featuresheight*width,即为其中特征的数量。
eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5。momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数)。
affine:当设为true时,会给定可以学习的系数矩阵gamma和beta。
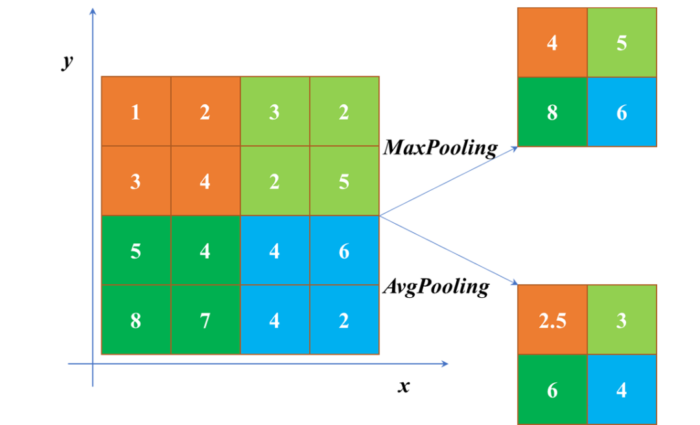
4. 池化层(pooling)
介绍:pooling一方面使特征图变小,简化网络计算复杂度。一方面通过多次池化压缩特征,提取主要特征。属于下采样过程。
常用函数:Max Pooling(最大池化)、Average Pooling(平均池化)等。
MaxPooling 与 AvgPooling用法:1. 当需综合特征图上的所有信息做相应决策时,通常使用AvgPooling,例如在图像分割领域中用Global AvgPooling来获取全局上下文信息;在图像分类中在最后几层中会使用AvgPooling。2. 在图像分割/目标检测/图像分类前面几层,由于图像包含较多的噪声和目标处理无关的信息,因此在前几层会使用MaxPooling去除无效信息。
补充:上采样层重置图像大小为上采样过程,如Resize,双线性插值直接缩放,类似于图像缩放,概念可见最邻近插值算法和双线性插值算法。实现函数有nn.functional.interpolate(input, size = None, scale_factor = None, mode = ‘nearest’, align_corners = None)和nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, output_padding = 0, bias = True)
5. FC层(全连接层)
介绍:连接所有的特征,将输出值送给分类器。主要是对前层的特征进行一个加权和(卷积层是将数据输入映射到隐层特征空间),将特征空间通过线性变换映射到样本标记空间(label)。全连接层可以通过1 x 1卷机 global average pooling代替。可以通过全连接层参数冗余,全连接层参数和尺寸相关。
常用函数:nn.Linear(in_features, out_features, bias)
补充:分类器包括线性分类器与非线性分类器。
| 分类器 | 介绍 | 常见种类 | 优缺点 |
| 线性分类器 | 线性分类器就是用一个“超平面”将正、负样本隔离开 | LR、Softmax、贝叶斯分类、单层感知机、线性回归、SVM(线性核)等 | 线性分类器速度快、编程方便且便于理解,但是拟合能力低 |
| 非线性分类器 | 非线性分类器就是用一个“超曲面”或者多个超平(曲)面的组合将正、负样本隔离开(即,不属于线性的分类器) | 决策树、RF、GBDT、多层感知机、SVM(高斯核)等 | 非线性分类器拟合能力强但是编程实现较复杂,理解难度大 |
6. 损失层
介绍:设置一个损失函数用来比较网络的输出和目标值,通过最小化损失来驱动网络的训练。网络的损失通过前向操作计算,网络参数相对于损失函数的梯度则通过反向操作计算。
常用函数:分类问题损失(离散值:分类问题、分割问题):nn.BCELoss、nn.CrossEntropyLoss等。回归问题损失(连续值:推测问题、回归分类问题):nn.L1Loss、nn.MSELoss、nn.SmoothL1Loss等。
7. Dropout层
介绍:在不同的训练过程中随机扔掉一部分神经元,以防止过拟合,一般用在全连接层。在测试过程中不使用随机失活,所有的神经元都激活。
常用函数:nn.dropout
8. 优化器
介绍:为了更高效的优化网络结构(损失函数最小),即是网络的优化策略,主要方法如下:
| 解释 | 优化器种类 | 特点 |
| 基于梯度下降原则(均使用梯度下降算法对网络权重进行更新,区别在于使用的样本数量不同) | GD(梯度下降); SGD(随机梯度下降,面向一个样本); BGD(批量梯度下降,面向全部样本); MBGD(小批量梯度下降,面向小批量样本) | 引入随机性和噪声 |
| 基于动量原则(根据局部历史梯度对当前梯度进行平滑) | Momentum(动量法); NAG(Nesterov Accelerated Gradient) | 加入动量原则,具有加速梯度下降的作用 |
| 自适应学习率(对于不同参数使用不同的自适应学习率;Adagrad使用梯度平方和、Adadelta和RMSprop使用梯度一阶指数平滑,RMSprop是Adadelta的一种特殊形式、Adam吸收了Momentum和RMSprop的优点改进了梯度计算方式和学习率) | Adagrad; Adadelta; RMSprop; Adam | 自适应学习 |
常用优化器为Adam,用法为:torch.optim.Adam。
补充:卷积神经网络正则化是为减小方差,减轻过拟合的策略,方法有:L1正则(参数绝对值的和); L2正则(参数的平方和,weight_decay:权重衰退)。
9. 学习率
介绍:学习率作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及合适收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
常用函数:torch.optim.lr_scheduler; ExponentialLR; ReduceLROnplateau; CyclicLR等。
卷积神经网络的常见结构
常见结构有:跳连结构(ResNet)、并行结构(Inception V1-V4即GoogLeNet)、轻量型结构(MobileNetV1)、多分支结构(SiameseNet; TripletNet; QuadrupletNet; 多任务网络等)、Attention结构(ResNet Attention)
| 结构 | 介绍与特点 | 图示 |
| 跳连结构(代表:ResNet) | 2015年何恺明团队提出。引入跳连的结构来防止梯度消失问题,今儿可以进一步加大网络深度。扩展结构有:ResNeXt、DenseNet、WideResNet、ResNet In ResNet、Inception-ResNet等 | 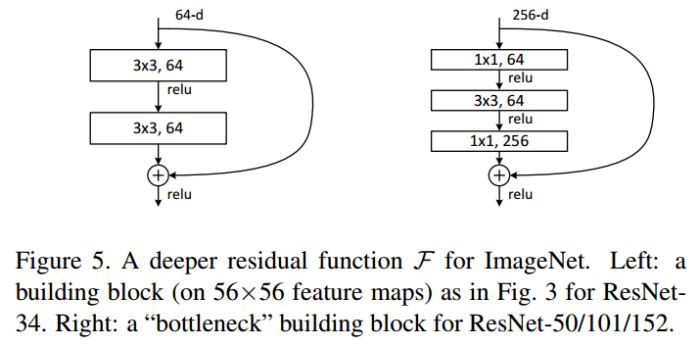 |
| 并行结构(代表:Inception V1-V4) | 2014年Google团队提出。不仅强调网络的深度,还考虑网络的宽度。其使用1×1的卷积来进行升降维,在多个尺寸上同时进行卷积再聚合。其次利用稀疏矩阵分解成密集矩阵计算的原理加快收敛速度。 | 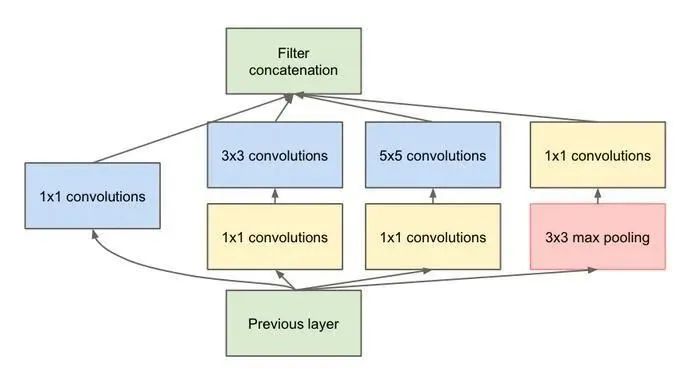 |
| 轻量型结构(代表:MobileNetV1) | 2017年Google团队提出。为了设计能够用于移动端的网络结构,使用Depth-wise Separable Convolution的卷积方式代替传统卷积方式,以达到减少网络权值参数的目的。扩展结构有:MobileNetV2、MobileNetV3、SqueezeNet、ShuffleNet V1、ShuffleNet V2等 | 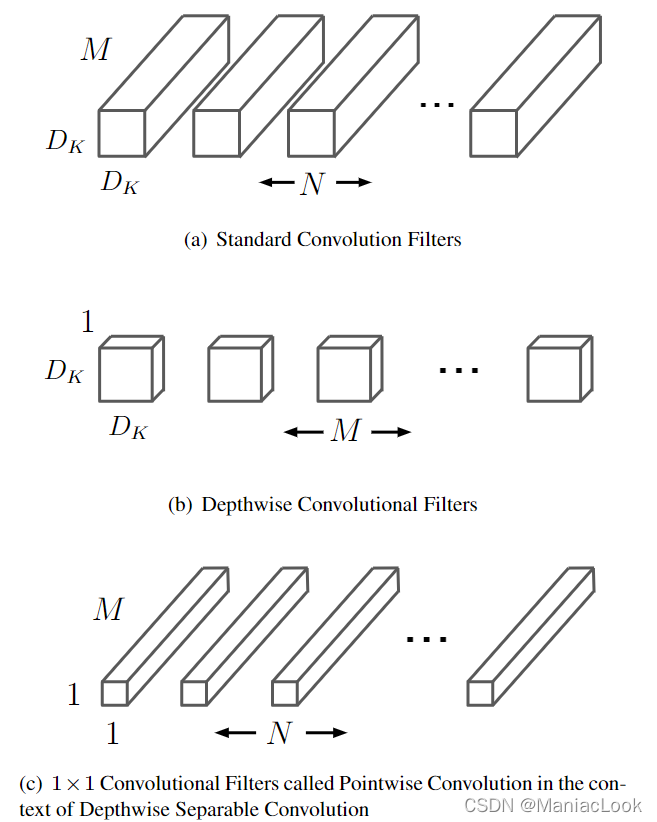 |
| 多分支结构(代表:TripletNet) | 基于多个特征提取方法提出,通过比较距离来学习有用的变量。该网络由3个具有相同前馈网络(共享参数)组成的,需要输入是3个样本,一个正样本和两个负样本,或者一个负样本和两个正样本。训练的目标是让相同类别之间的距离竟可能的小,让不同的类别之间距离竟可能的大。常用于人脸识别。 |  |
| Attention结构(代表:ResNet Attention) | 对于全局信息,注意力机制会重点关注一些特殊的目标区域,也就是注意力焦点,进而利用有限的注意力资源对信息进行筛选,提高信息处理的准确性和效率。注意力机制有Soft-Attention和Hard-Attention区分,可以作用在特征图上、尺度空间上、channel尺度上和不同时刻历史特征上等。 | 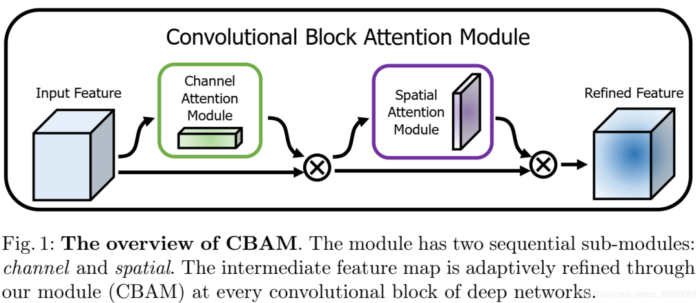 |
参考资料链接:
相关文章:
【深度学习】卷积神经网络结构组成与解释
卷积神经网络是以卷积层为主的深度网路结构,网络结构包括有卷积层、激活层、BN层、池化层、FC层、损失层等。卷积操作是对图像和滤波矩阵做内积(元素相乘再求和)的操作。 1. 卷积层 常见的卷积操作如下: 卷积操作解释图解标准卷…...

从源码解析Containerd容器启动流程
从源码解析Containerd容器启动流程 本文从源码的角度分析containerd容器启动流程以及相关功能的实现。 本篇containerd版本为v1.7.9。 更多文章访问 https://www.cyisme.top 本文从ctr run命令出发,分析containerd的容器启动流程。 ctr命令 查看文件cmd/ctr/comman…...
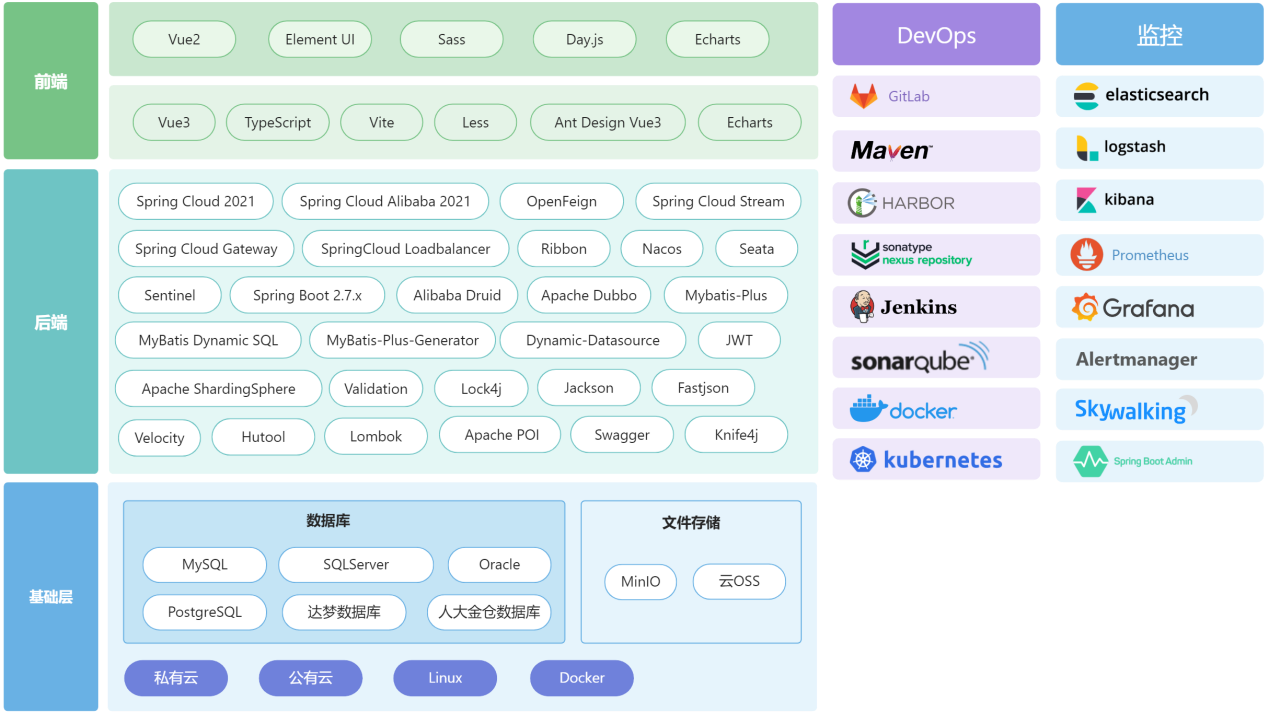
引迈-JNPF低代码项目技术栈介绍
从 2014 开始研发低代码前端渲染,到 2018 年开始研发后端低代码数据模型,发布了JNPF开发平台。 谨以此文针对 JNPF-JAVA-Cloud微服务 进行相关技术栈展示: 1. 项目前后端分离 前端采用Vue.js,这是一种流行的前端JavaScript框架&a…...

如何处理枚举类型(下)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 上一篇我们通过编写MyB…...
wsj0数据集原始文件.wv1.wv2转换成wav文件
文章目录 准备一、获取WSJO数据集二、安装sph2pipe三、转换代码四、结果展示 最近做语音分离实验需要用到wsj0-2mix数据集,但是从李宏毅语音分离教程里面获取的wsj0-2mix只有一部分。从网上获取到了完整的WSJO数据集后,由于原始的语音文件后缀是wv1或…...
Flask Session 登录认证模块
Flask 框架提供了强大的 Session 模块组件,为 Web 应用实现用户注册与登录系统提供了方便的机制。结合 Flask-WTF 表单组件,我们能够轻松地设计出用户友好且具备美观界面的注册和登录页面,使这一功能能够直接应用到我们的项目中。本文将深入探…...
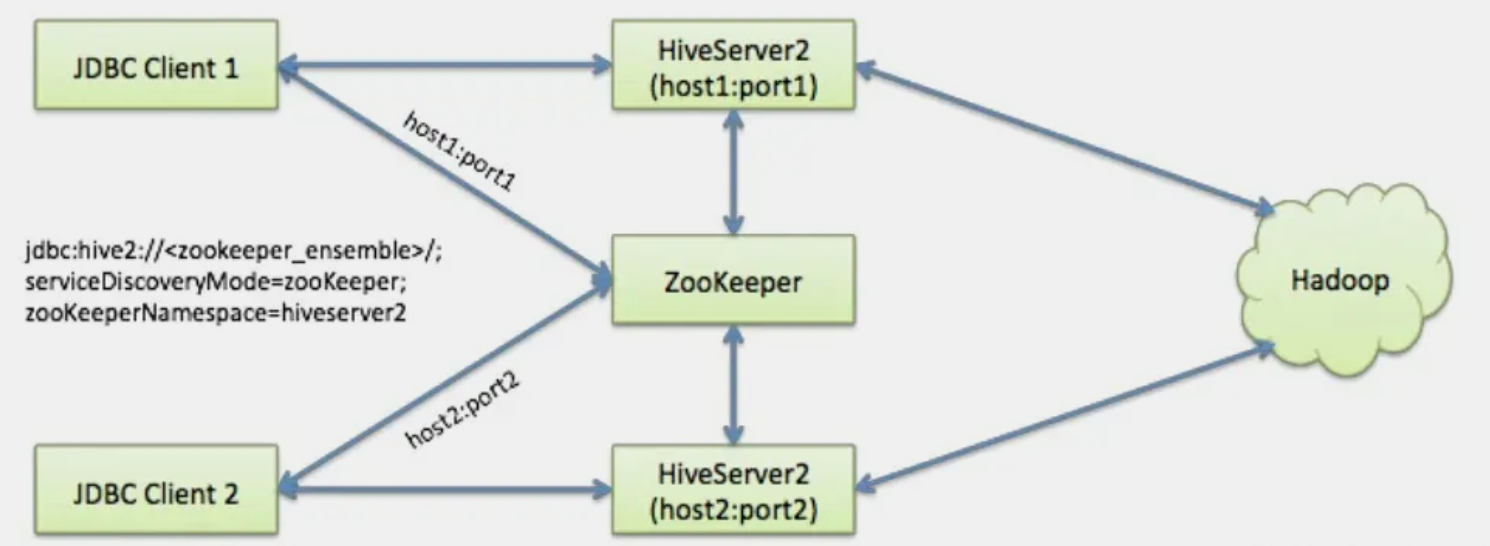
【运维】hive 高可用详解: Hive MetaStore HA、hive server HA原理详解;hive高可用实现
文章目录 一. hive高可用原理说明1. Hive MetaStore HA2. hive server HA 二. hive高可用实现1. 配置2. beeline链接测试3. zookeeper相关操作 一. hive高可用原理说明 1. Hive MetaStore HA Hive元数据存储在MetaStore中,包括表的定义、分区、表的属性等信息。 hi…...

C#开发的OpenRA游戏之属性SelectionDecorations(13)
C#开发的OpenRA游戏之属性SelectionDecorations(13) 在前面分析SelectionDecorations属性类时,会发现它有下面这个属性: public class SelectionDecorations : SelectionDecorationsBase, IRender { readonly Interactable interactable; 它是定义了一个Interactabl…...
接手了一个外包开发的项目,我感觉我的头快要裂开了~
嗨,大家好,我是飘渺。 最近,我和小伙伴一起接手了一个由外包团队开发的微服务项目,这个项目采用了当前流行的Spring Cloud Alibaba微服务架构,并且是基于一个“大名鼎鼎”的微服务开源脚手架(附带着模块代…...

git常规使用方法,常规命令
Git是一种分布式版本控制系统,它可以记录软件的历史版本,并提供了多人协作开发、版本回退等功能。以下是Git的基本使用方法: 安装Git:下载安装包并进行安装,安装完成后在命令行中输入 git --version 进行验证。 初始化…...

【JavaScript】3.3 JavaScript工具和库
文章目录 1. 包管理器2. 构建工具3. 测试框架4. JavaScript 库总结 在你的 JavaScript 开发之旅中,会遇到许多工具和库。这些工具和库可以帮助你更有效地编写和管理代码,提高工作效率。在本章节中,我们将探讨一些常见的 JavaScript 工具和库&…...

开发基于 ChatGPT 分析热点事件并生成文章的网站应用【热点问天】把百度等热点用chatGPT来对热点事件分析海量发文章 开发步骤 多种方式获取利润
这样做的优点: 1.不用每个人都问chatGPT同样的问题。 2.已经生成的,反应快速。 3.内容分析的客观,真实,基于数据,无法造假。 4.无其它目的这种基于 ChatGPT 分析热点事件并生成文章的网站,可以通过多种方式…...
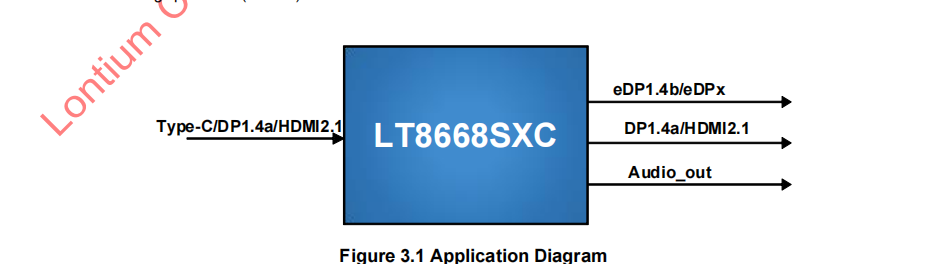
龙迅LT8668SXC适用于TPYE-C/DP/HDMI转EDP/VBO同时环出一路HDMI/DP,支持分辨率缩放功能。
1.描述 应用功能:LT8668SXC适用于TYPE-C/DP1.4/HDMI2.1转EDP/VBO同时环出一路HDMI/DP应用方案 分辨率:高达8K30HZ, 工作温度范围:−40C to 85C 产品封装:QFN88 (10*10)最小包装数:1680pcs 2.产品应用 •视频…...

跳板机原理
跳板机原理 跳板机(Jump Server)是一种网络安全设备或计算机,用于管理和保护内部网络中的其他计算机或系统。跳板机通常位于内部网络和外部网络之间,充当连接这两个网络的中间节点或跳板。以下是跳板机的主要功能和用途࿱…...
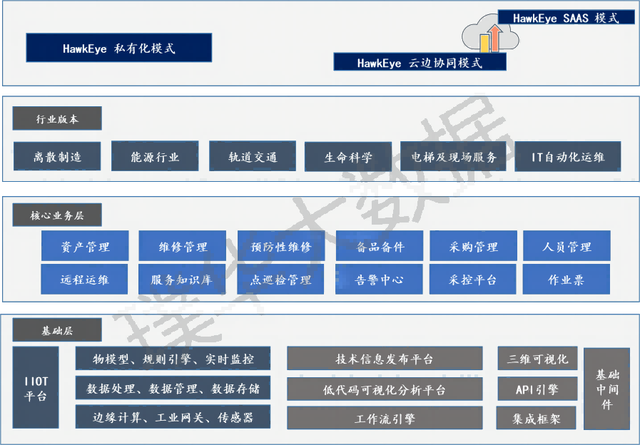
璞华大数据产品入选中国信通院“铸基计划”
武汉璞华大数据技术有限公司HawkEye设备数字化管理平台产品,凭借优秀的产品技术能力,通过评估后,入选中国信通院“铸基计划”《高质量数字化转型产品及服务全景图(2023)》的工业数字化领域。 “铸基计划”是中国信通院…...

1146. 新的开始,prim算法,超级原点
发展采矿业当然首先得有矿井,小 FF 花了上次探险获得的千分之一的财富请人在岛上挖了 n 口矿井,但他似乎忘记了考虑矿井供电问题。 为了保证电力的供应,小 FF 想到了两种办法: 在矿井 i 上建立一个发电站,费用为 vi&…...

HTTP常见响应码
HTTP(Hypertext Transfer Protocol)是用于在客户端和服务器之间传输资源的协议。HTTP响应码(HTTP status code)用来表示服务器对请求的处理结果。以下是常见的HTTP响应码及其概要: 1. 响应码大类: 主要分…...

物联网边缘计算是什么?如何实现物联网边缘计算?
物联网边缘计算是一种在物联网设备和网络中实施计算和数据处理的技术。它允许在物联网设备或网络边缘进行数据分析和处理,而不需要将所有数据传输到远程数据中心或云端进行处理。物联网边缘计算将计算和数据处理的能力迁移到物联网设备的边缘,使得设备能…...

带着GPT-4V(ision)上路,自动驾驶新探索
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving GitHub | https://github.com/PJLab-ADG/GPT4V-AD-Exploration arXiv | https://arxiv.org/abs/2311.05332 自动驾驶技术的追求取决于对感知、决策和控制系统的复杂集成。…...

19. Python 数据处理之 Pandas
目录 1. 认识 Pandas2. 安装和导入 Pandas3. Pandas 数据结构4. Pandas 基本功能5. Pandas 数据分析 1. 认识 Pandas Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。 Pandas 的出…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

实战解锁:在Blender中掌握专业级MMD动画制作全流程
实战解锁:在Blender中掌握专业级MMD动画制作全流程 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools MMD …...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...