ClickHouse入门手册1.0
1、数据类型
1.1 整数类型:
ClickHouse中整型数据均为固定长度(可以设置长度参数,但是会被忽略),整型包括有符号整型和无符号整型。
有符号整型:Int8,Int16,Int32,Int64,Int128,Int256
无符号整型:UInt8,UInt16,UInt32,UInt64,UInt128,UInt256
1.2 字符串类型:
String
1.3 固定字符串:
FixedString(N)
固定字符串需要指定长度!
当数据长度刚好是N时,FixedString类型比较高效,其他情况下效率会降低。
注意:插入数据时,如果字符串长度小于N,则会对字符串尾部用空子节填充;如果长度大于N,会抛出Too large value for FixedString(N)异常。
1.4 标识符类型:
UUID
通用唯一标识符是一个16字节的数字,用于标志记录。
1.5 日期/时间类型:
Date32
DateTime64
1.6 ip4/6地址
IPv4
IPv6
tips:IPv4是与UInt32类型保持兼容的类型,用于保存IPv4地址的值;而IPv6是与FixedString(16)兼容的类型,用于保存IPv6地址的值。
1.7 浮点数
Float32
Float64
1.8 定点数:
Decimal(P,S)
有符号定点数,在运算过程中保持精度。其中参数P表示精度,有效范围[1~38],决定有多少个十进制数字;参数S表示规模,有小范围[0~P],决定小数位的位数。
部分资料中定点数有Decimal32,Decimal64,Decimal128类型,其实是不同P参数的表示:
P取值[1~9],对应Decimal32(S);
P取值[10~18],对应Decimal64(S);
P取值[19~38],对应Decimal128(S);
1.9 枚举类型:
Enum8
Enum16
ClickHouse中Enum类型用来保存String=Integer的映射关系,其中Enum8是String=Int8的描述,Enum16是String=Int16的描述。
1.10 数组类型:
Array(T)
由T类型组成的数组,T可以是任意类型,包含数组类型(但是不推荐,ClickHouse对多维数组的支持有限)。
1.11 键值对:
Map(key,value)
用来保存k-v键值对类型的数据。其中参数key类型支持String/FixedString/Integer,参数value支持String/FixedString/Array/Integer。
1.12 空类型:
Nullable
空类型,ClickHouse允许用NULL表示缺省值,如Nullable(Int8)可以保存Int8类型的值,没有值的行会存储为NULL。
注意:使用Nullable对数据库几乎总是负面影响!!!
建表语句示例:
CREATE TABLE ALL_COLUMN_TYPE_Table
(col1_Int8 Int8 COMMENT '字段Int8',col2_Int16 Int16 COMMENT '字段Int16',col3_Int32 Int32 COMMENT '字段Int32',col4_Int64 Int64 COMMENT '字段Int128',col5_Int128 Int128 COMMENT '字段UInt8',col6_UInt8 UInt8 COMMENT '字段UInt8',col7_UInt16 UInt16 COMMENT '字段UInt16',col8_UInt32 UInt32 COMMENT '字段UInt32',col9_UInt64 UInt64 COMMENT '字段UInt64',col10_UInt128 UInt128 COMMENT '字段UInt128',col11_UUID UUID COMMENT '字段UUID',col12_Date32 Date32 COMMENT '字段Date32',col13_DateTime64 DateTime64 COMMENT '字段DateTime64',col14_Float32 Float32 COMMENT '字段Float32',col15_Float64 Float64 COMMENT '字段Float64',col16_String String COMMENT '字段String',col17_Enum8 Enum8('a'=2,'b'=3) COMMENT '字段Enum8',col18_Enum16 Enum16('男'=1,'女'=2) COMMENT '字段Enum16',col19_FixedString FixedString(12) COMMENT '字段FixedString',col20_Decimal Decimal(16,12) COMMENT '字段Int8',col21_IPv4 IPv4 COMMENT '字段IPv4',col22_IPv6 IPv6 COMMENT '字段IPv6',col23_Map Map(String, Int8) COMMENT '字段Map',col24_Array Array(IPv4) COMMENT '字段数组'
)
ENGINE = MergeTree
ORDER BY col1_Int8
PARTITION BY col24_ArrayTips:
(1)字段大小写敏感,`UP`和`up`会认为是两个字段。
(2)ClickHouse关键字部分大小写敏感,建议sql全部用大写,避免迷の错误。
(3)Array(T),T支持所有类型。
(4)不同引擎支持的建表参数有区别,如Log家族不支持索引和分区,具体参见4.2引擎说明。
(5)如果CREATE TABLE没有指定Schema,那么会建在default数据库中(If you do not specify the database name, the table will be in the default database.)。
(6)ClickHouse主键和排序键。官网对主键的说明如下:
primary keys in ClickHouse are not unique for each row in a table
The primary key of a ClickHouse table determines how the data is sortedwhen written to disk. Every 8,192 rows or 10MB of data (referred to
as the index granularity) creates an entry in the primary key index file.
This granularity concept creates a sparse index that can easily fit inmemory, and the granules represent a stripe of the smallest amount of
column data that gets processed during SELECT queries.
The primary key can be defined using the PRIMARY KEY parameter. If you
define a table without a PRIMARY KEY specified, then the key becomes the
tuple specified in the ORDER BY clause. If you specify both a PRIMARY KEY
and an ORDER BY, the primary key must be a subset of the sort order.
The primary key is also the sorting key......主键不唯一;主键用作写入排序;未定义主键会使用排序键排序,如果同时定义了主键和排序键,主键必须是排序键的子集。
2、常用sql语法
这部分资料搬运自官网中文文档,建议直接访问官网:SQL语法 | ClickHouse Docs
2.1 SELECT
数据检索,略。
2.2 ALTER
表修改,ALTER操作只支持MergeTree家族引擎表。语法结构:
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ...2.3 SHOW
SHOW查询,语法结构:
#table
SHOW CREATE [TEMPORARY] [TABLE|DICTIONARY] [db.]table [INTO OUTFILE filename] [FORMAT format]#database
SHOW DATABASES [INTO OUTFILE filename] [FORMAT format]#processlist
SHOW PROCESSLIST [INTO OUTFILE filename] [FORMAT format]2.4 DESCRIBE
DESCRIBE TABLE,语法结构:
DESC|DESCRIBE TABLE [db.]table [INTO OUTFILE filename] [FORMAT format]2.5 DROP
删除操作,语法结构:
#table
DROP DATABASE [IF EXISTS] db [ON CLUSTER cluster]#dictionary
DROP DICTIONARY [IF EXISTS] [db.]name#user
DROP USER [IF EXISTS] name [,...] [ON CLUSTER cluster_name]注意:DROP操作大小写敏感!!!
2.6 CREATE
创建操作,语法结构:
#table
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1] [compression_codec] [TTL expr1] [COMMENT 'comment for column'],name2 [type2] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr2] [compression_codec] [TTL expr2] [COMMENT 'comment for column'],...
) ENGINE = engineCOMMENT 'comment for table'#database
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]#view
CREATE [OR REPLACE] VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster_name] AS SELECT ...2.7 INSERT
插入操作,语法结构:
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...tips:ClickHouse有2类解析器:完整SQL解析器和数据格式解析器,除了INSERT查询,其他情况下使用完整SQL解析器。可以通过设置input_format_values_interpret_expressions参数,当其值为1时,ClickHouse优先使用数据格式解析器(快速流式解析器),如果失败,ClickHouse会在尝试使用完整SQL解析器。
3、建表参数
3.1 分区
通过PARTITION BY关键字定义分区信息。
分区主要目的是降低扫描范围,优化查询速度。
MergeTree家族可以使用分区键。设置分区的表会通过指定的规则划分为逻辑数据库,为减少操作,分区是分开存储的,访问数据时候ClickHouse尽量使用分区的最小子集。
分区支持表达式和元数据,如:
PARTITION BY (toMonday(StartDate), EventType)可通过如下语句查看表分区信息:
SELECTpartition,name,active
FROM system.parts
WHERE table = 'ALL_COLUMN_TYPE_Table'3.2 排序
通过ORDER BY关键字定义排序。
排序键支持多个字段集合,如:
#list,需要括号
ORDER BY (col1_Int8,col4_Int64)
#单个字段
ORDER BY col1_Int8Tips:部分资料中表示排序键是必填字段,这种论述是错误。正确论述应该是——排序键和主键必须指定至少一个!
You must provide an ORDER BY or PRIMARY KEY expression in the table definition.如下建表语句是正确可执行的:
CREATE TABLE ALL_COLUMN_TYPE_Table9
(col1_Int8 Int8 COMMENT '字段Int8',col2_Int16 Int16 COMMENT '字段Int16',col3_Int32 Int32 COMMENT '字段Int32',col4_Int64 Int64 COMMENT '字段Int128',col5_Int128 Int128 COMMENT '字段UInt8',col6_UInt8 UInt8 COMMENT '字段UInt8',col7_UInt16 UInt16 COMMENT '字段UInt16',col8_UInt32 UInt32 COMMENT '字段UInt32',col9_UInt64 UInt64 COMMENT '字段UInt64',col10_UInt128 UInt128 COMMENT '字段UInt128',col11_UUID UUID COMMENT '字段UUID',col12_Date32 Date32 COMMENT '字段Date32',col13_DateTime64 DateTime64 COMMENT '字段DateTime64',col14_Float32 Float32 COMMENT '字段Float32',col15_Float64 Float64 COMMENT '字段Float64',col16_String String COMMENT '字段String',col17_Enum8 Enum8('a'=2,'b'=3) COMMENT '字段Enum8',col18_Enum16 Enum16('男'=1,'女'=2) COMMENT '字段Enum16',col19_FixedString FixedString(12) COMMENT '字段FixedString',col20_Decimal Decimal(16,12) COMMENT '字段Int8',col21_IPv4 IPv4 COMMENT '字段IPv4',col22_IPv6 IPv6 COMMENT '字段IPv6',col23_Map Map(String, Int8) COMMENT '字段Map',col24_Array Array(IPv4) COMMENT '字段数组'
)
ENGINE = MergeTree
PRIMARY KEY col3_Int323.3 主键
通过PRIMARY KEY语法指定。
主键支持字段集合,如下:
#list
PRIMARY KEY (col1_Int8,col3_Int32,col5_Int128)#单个字段
PRIMARY KEY col1_Int84、引擎
ClickHouse引擎可以分为两类:数据库引擎和表引擎。
4.1 数据库引擎:
创建数据库语法结构:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MaterializeMySQL('host:port', ['database' | database], 'user', 'password') [SETTINGS ...]| 引擎 | 说明 |
| MaterializedMySQL | 实验性,生产中禁止使用。 |
| MySQL | 用于将远程MySQL服务器中的表映射到ClickHouse中,允许对表进行SELECT和INSERT查询。 |
| Lazy | 为存储较小的*Log表优化的,访问之间会存在很长的时间间隔。 |
| Atomic | 数据库Atomic中所有的表都会有唯一UUID,默认情况下使用Atomic数据引擎。 |
| SQLite | 允许连接到SQLite数据库,并支持ClickHouse和SQLite交换数据。 |
| PostgreSQL | 允许连接到远程PostgreSQL服务,支持读写操作。 |
4.2 表引擎:
主要有两类,一类是MergeTree家族,一类是Log家族。
| 引擎家族 | 引擎 | 说明 |
| MergeTree | VersionedCollapsingMergeTree | 允许快速写入不断变化的对象;删除后台中的旧对象状态。 |
| GraphiteMergeTree | 用来对Graphite数据进行瘦身(使用CK保存Graphite数据比较合适) | |
| AggregatingMergeTree | 适合用来做增量数据的聚合统计,包括物化视图等。 | |
| CollapsingMergeTree | 可以异步删除折叠行,可以有效降低存储量并提高SELECT效率。 | |
| MergeTree | 用来保存极大量数据到一张表中,数据片段可以按照一定规则合并。 | |
| ReplacingMergeTree | 和MergeTree相比,该引擎会删除排序键值相同的重复项。 | |
| SharedMergeTree | 插入吞吐量、后台合并吞吐量、扩缩容更快。 | |
| SummingMergeTree | 相同主键会合并为一行,可以有效减少存储空间和提高查询效率。 | |
| Log | Log | 适合临时数据,测试、演示、write-once表等 |
| SpripeLog | 写入数据量较小(小于百万)的场景下,该引擎比较适合。 | |
| TinyLog | 最简单的表引擎,数据保存在磁盘上,数据包都单独压缩在文件中。 |
Tips:Log家族引擎不支持索引,建表不支持ORDER BY/PRIMAEY/PARTITION BY
Engine Log doesn't supportPARTITION_BY, PRIMARY_KEY, ORDER_BY or SAMPLE_BY clauses. 相关文章:

ClickHouse入门手册1.0
1、数据类型 1.1 整数类型: ClickHouse中整型数据均为固定长度(可以设置长度参数,但是会被忽略),整型包括有符号整型和无符号整型。 有符号整型:Int8,Int16,Int32,Int64,Int128,Int256 无符号整型:UInt8,UInt16,UI…...
10个火爆的设计素材网站推荐
所谓聪明的女人没有米饭很难做饭,设计师也是如此。如何找到优秀的设计材料是每个设计师的痛点,国内材料网站收费,但也限制使用范围和期限,大多数外国设计网站不能打开或需要特殊互联网使用,有一定的安全风险。 作为一…...
SQL注入 - CTF常见题型
文章目录 题型一 ( 字符型注入 )题型二 ( 整数型注入 )题型三 ( 信息收集SQL注入)题型四 ( 万能密码登录 )题型五 ( 搜索型注入文件读写 )题型六 (…...
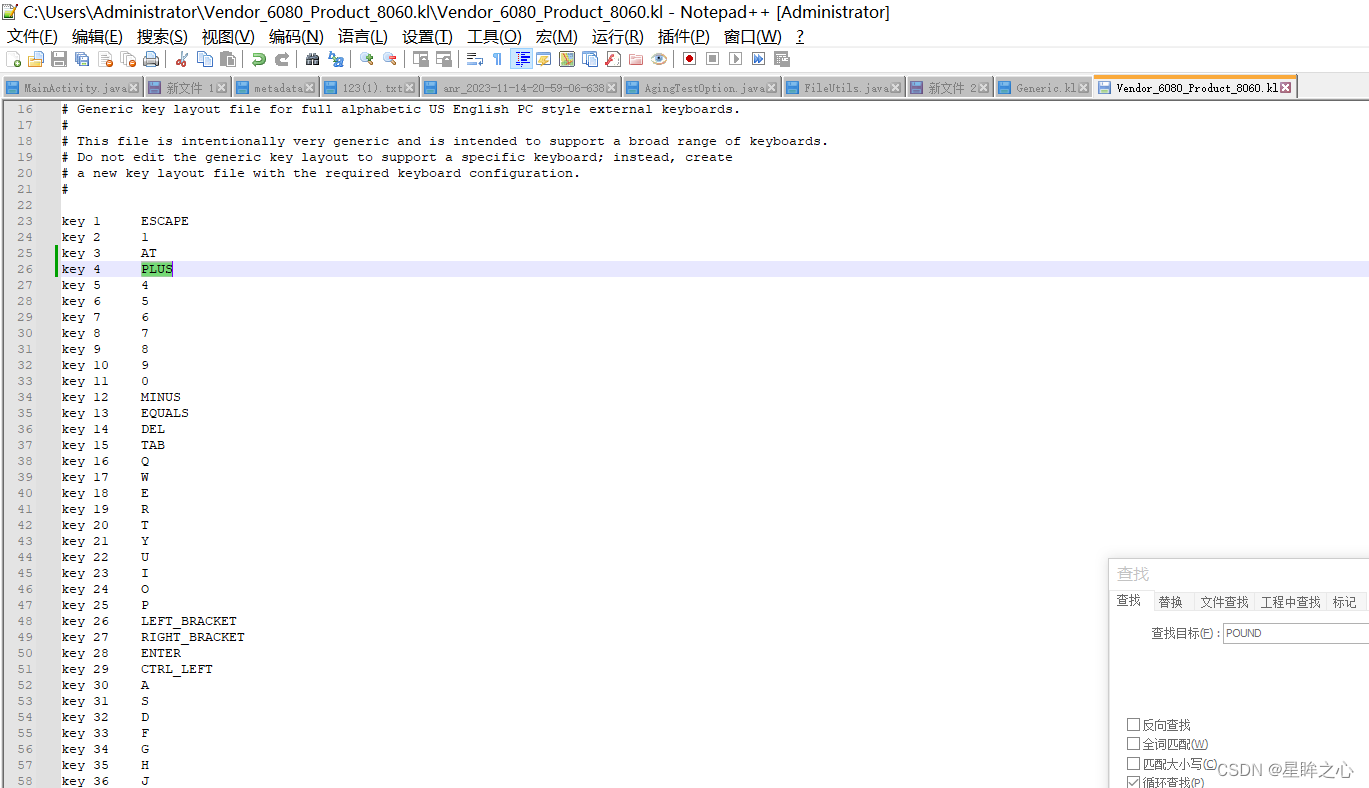
android keylayout键值适配
1、通过getevent打印查看当前keyevent数字对应事件和物理码 2、dumpsys input 查看输入事件对应的 KeyLayoutFile: /system/usr/keylayout/Vendor_6080_Product_8060.kl 3、通过物理码修改键值映射,修改/system/usr/keylayout/目录下的文件...

python读取excel自动化生成sql建表语句和java实体类字段
1、首先准备一个excel文件: idtypenameidint学号namestring姓名ageint年龄sexstring性别weightdecimal(20,4)体重scoredecimal(20,4)分数 2、直接生成java字段和注释: import pandas as pddf pd.read_excel(test.xlsx, sheet_nameSheet1)for i in ran…...
Unity求向量A在平面L上的投影向量
如题:求向量A在平面L上的投影向量(图左) 即求 其实等价于求向量,那在中,,所以只需要求即可 而就是在平面L的法向量的投影坐标,所以代码就是 /// <summary>/// 求向量A在平面B上的投影向量/// </summary>/// <para…...

人机交互2——任务型多轮对话的控制和生成
1.自然语言理解模块 2.对话管理模块 3.自然语言生成模块...

【数据结构】八大排序 (三)
目录 前言: 快速排序 快速排序非递归实现 快速排序特性总结 归并排序 归并排序的代码实现 归并排序的特性总结 计数排序 计数排序的代码实现 计数排序的特性总结 前言: 前文快速排序采用了递归实现,而递归会开辟函数栈帧࿰…...
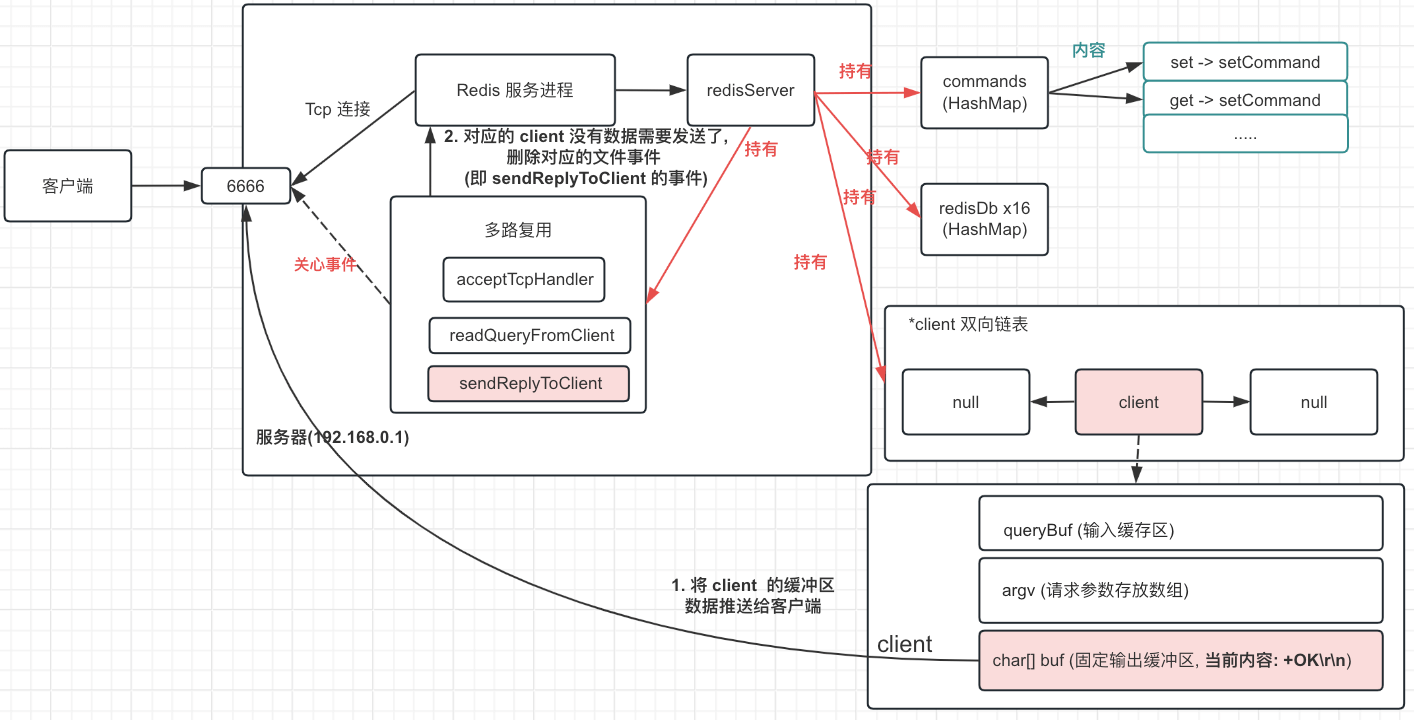
Redis 命令处理过程
我们知道 Redis 是一个基于内存的高性能键值数据库, 它支持多种数据结构, 提供了丰富的命令, 可以用来实现缓存、消息队列、分布式锁等功能。 而在享受 Redis 带来的种种好处时, 是否曾好奇过 Redis 是如何处理我们发往它的命令的呢? 本文将以伪代码的形式简单分析…...

python爬虫进阶教程之如何正确的使用cookie
文章目录 前言一、获取cookie二、程序实现三、动态获取cookie四、其他关于Python爬虫技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项目源码合集①Python工具包②Python实战案例③Python小游戏源码五、面试资料六、Pytho…...

【hacker送书第4期】推荐4本Java必读书籍(各送一本)
第4期图书推荐 Java从入门到精通(第7版)内容简介参与方式 项目驱动零基础学Java内容简介参与方式 深入理解Java高并发编程内容简介参与方式 Java编程讲义内容简介参与方式 Java从入门到精通(第7版) 内容简介 《Java从入门到精通&…...

[密码学]DES
先声明两个基本概念 代换(substitution),用别的元素代替当前元素。des的s-box遵循这一设计。 abc-->def 置换(permutation),只改变元素的排列顺序。des的p-box遵循这一设计。 abc-->bac DES最核心的算法就是…...

15个超级实用的Python操作,肯定有你意想不到的!
文章目录 1)映射代理(不可变字典)2)dict 对于类和对象是不同的3) any() 和 all()4) divmod()5) 使用格式化字符串轻松检查变量6) 我们可以将浮点数转换为比率7) 用globals()和locals()显示现有的全局/本地变量8) import() 函数9) …...

GitHub上8个强烈推荐的 Python 项目
文章目录 前言1. Manim2. DeepFaceLab3. Airflow4. GPT-25. XSStrike6. 谷歌图片下载7. Gensim8. SocialMapper总结关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项目源码合集①Python工具包②Python实战案例③…...

什么是依赖倒置原则
1、什么是依赖倒置原则 依赖倒置原则(Dependency Inversion Principle,DIP)是指高层模块不应该依赖于低层模块,它们都应该依赖于抽象。换句话说,具体类之间的依赖关系应该尽可能减少,而抽象类或接口之间的…...
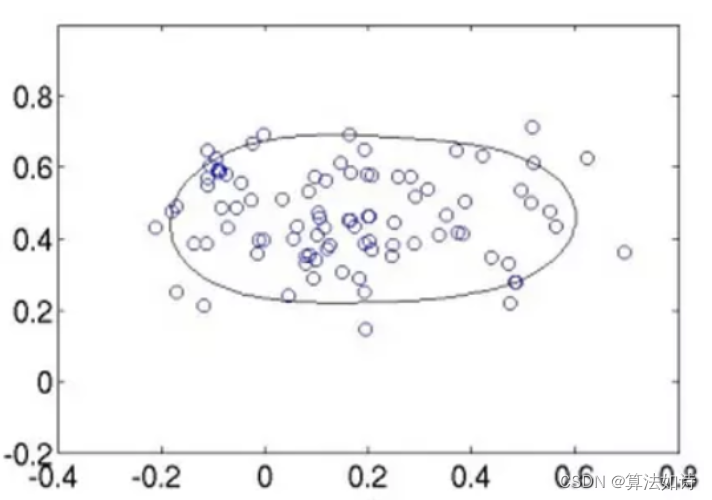
异常数据检测 | Python实现oneclassSVM模型异常数据检测
支持向量机(SVM)的异常检测 SVM通常应用于监督式学习,但OneClassSVM[8]算法可用于将异常检测这样的无监督式学习,它学习一个用于异常检测的决策函数其主要功能将新数据分类为与训练集相似的正常值或不相似的异常值。 OneClassSVM OneClassSVM的思想来源于这篇论文[9],SVM使用…...
)
using meta-SQL 使用元SQL (3)
%FirstRows Syntax %FirstRows(n) Description The %FirstRows meta-SQL variable is replaced by database-specific SQL syntax to optimize retrieval of n rows. Depending on the database, this variable optimizes: FirstRows meta-SQL变量被特定于数据库的SQL语法…...
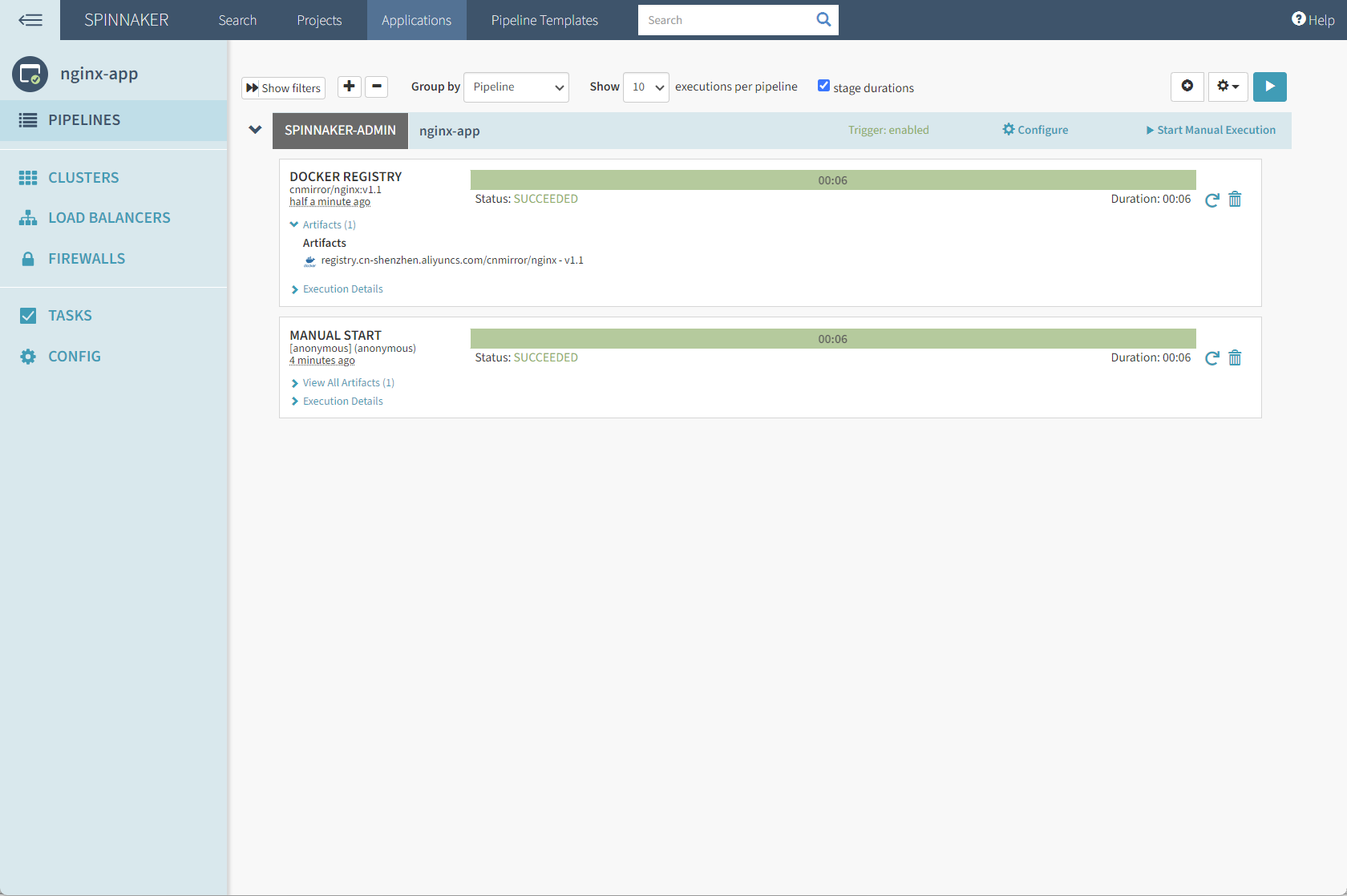
Spinnaker 基于 docker registry 触发部署
docker registry 触发部署 Spinnaker可以通过Docker镜像的变化来触发部署,这种方法允许你在Docker镜像发生变化时自动启动新的部署流程。 示例原理如下图所示: 以下是如何在Spinnaker中实现基于Docker Registry触发部署的配置流程。最终实现的效果如下…...

2023亚马逊云科技re:Invent,在开发者板块探究如何利用技术重塑业务
美国当地时间11月27日,一年一度的亚马逊云科技re:Invent大会在美国拉斯维加斯盛大开幕。这场全球云计算领域的前沿盛会,已连续12年成为引领行业的风向标。那么本次2023亚马逊云科技re:Invent大会又有哪些可玩、可看的新项目,下面就一起来瞧一…...

JAVA 使用stream流将List中的对象某一属性创建新的List
JAVA 使用stream流将List中的对象某一属性创建新的List 1.stream流介绍 Java Stream是Java 8引入的一种新机制,它可以让我们以声明式方式操作集合数据,提供了更加简洁、优雅的集合处理方式。Stream是一个来自数据源的元素队列,并支持聚合操…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...