如何利用Python进行数据归一化?
1. 知识简介
数据归一化是数据预处理的一项重要步骤,它对于提高模型性能、加速模型训练、避免数值计算问题以及提高模型的泛化能力都具有重要作用。进行数据归一化可以起到以下作用:消除量纲影响,加速模型收敛,提高模型性能,防止数值计算问题,提高模型泛化能,更好地处理异常值。
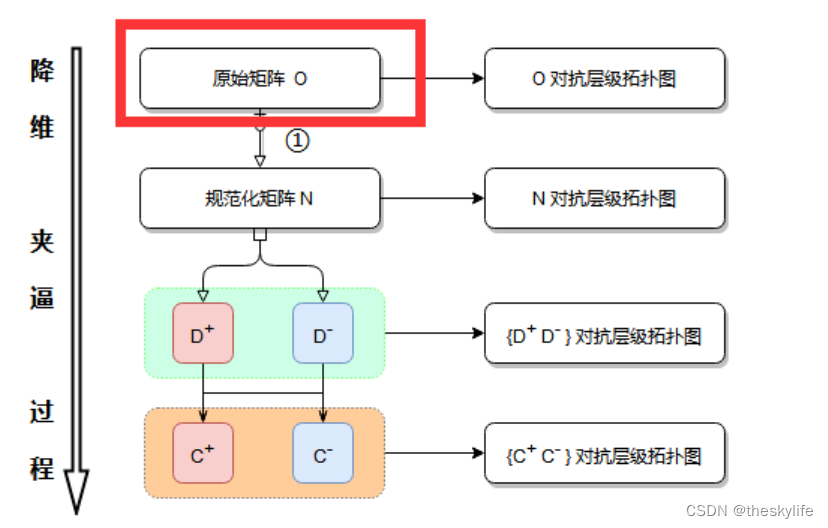
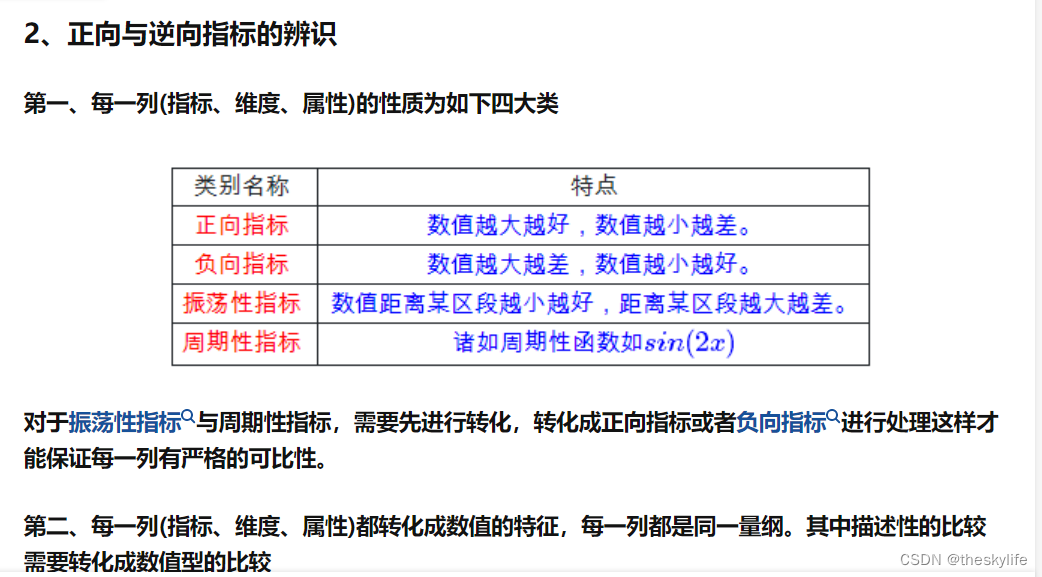

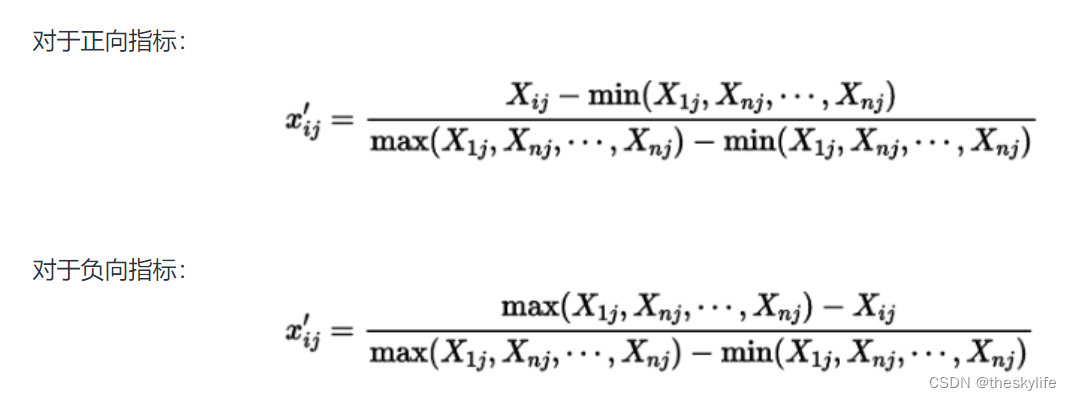
3.python中实现
3.1 正向型指标和负向型指标
正向型指标的取值范围在0到正无穷,数值越大表示绩效越好。在归一化时,通常使用 Min-Max 归一化方法,将指标缩放到0到1之间。
负向型指标的取值范围在负无穷到0之间,数值越接近0表示绩效越好。在归一化时,也使用 Min-Max 归一化方法,将指标缩放到0到1之间,但需要注意取值范围的定义。
import numpy as np
import pandas as pddef min_max_normalize(data, method='positive', feature_range=(0, 1)):"""Min-Max归一化Parameters:- data: 需要进行处理的DataFrame- method: 归一化方向,'positive'为正向,'negative'为逆向- feature_range: 设置归一化后的最小最大值,默认为 (0, 1)Returns:- normalized_data: 归一化后的DataFrame"""y_min, y_max = feature_rangenormalized_data = pd.DataFrame()for col in data.columns:col_max, col_min = data[col].max(), data[col].min()if method == 'negative':normalized_values = (y_max - y_min) * (col_max - data[col]) / (col_max - col_min) + y_minelif method == 'positive':normalized_values = (y_max - y_min) * (data[col] - col_min) / (col_max - col_min) + y_minnormalized_data[col] = normalized_values.valuesreturn normalized_data# 示例用法
# data = pd.DataFrame({'amount': [20, 40, 30, 26], 'cost': [3, 6, 2, 10]})
# normalized_data = min_max_normalize(data[['cost']], method='negative', feature_range=(0, 1))3.2 中心倾向指标
中心倾向指标的取值范围一般视数据情况而定,数值越靠近中间位置表示绩效越好。在归一化时,通常使用 Min-Max 归一化方法,将指标缩放到0到1之间。
一些场景举例,比如财务绩效数据,利润、营业收入等中心倾向稳定的话,现实场景中,代表经营状况越好,比如生产质量控制越靠近设置的目标值越符合要求。
若是基于数据的情况,取中心位置的话,可以用以下方法:
import numpy as np
import pandas as pddef mid_normalize(data, feature_range=(0, 1)):"""中心倾向指标归一化Parameters:- data: 需要进行处理的DataFrame- feature_range: 设置归一化后的最小最大值,默认为 (0, 1)Returns:- normalized_data: 归一化后的DataFrame"""y_min, y_max = feature_rangenormalized_data = pd.DataFrame()for col in data.columns:col_max, col_min = data[col].max(), data[col].min()col_mid = (col_max + col_min) / 2normalized_values = data[col].map(lambda x: 2 * (x - col_min) / (col_max - col_min) if x < col_mid else 2 * (col_max - x) / (col_max - col_min))normalized_values *= (y_max - y_min)normalized_data[col] = normalized_values.valuesreturn normalized_data# 示例用法
#data=pd.DataFrame({'ph':[2,5,7,10,12],
# 'mid':[100,20,50,70,90],
# 'temperature':[-10,10,25,30,40]})
# normalized_data=mid_normalize(data[['ph', 'mid']])若是有给定的中心值,则可以参考一下用法:
import pandas as pddef mid_normalize(data, best_values=None, feature_range=(0, 1)):"""中心倾向指标归一化Parameters:- data: 需要进行处理的DataFrame- best_values: 中心指标值,如果为None,则使用(feature_range[0] + feature_range[1]) / 2- feature_range: 设置归一化后的最小最大值,默认为 (0, 1)Returns:- normalized_data: 归一化后的DataFrame"""y_min, y_max = feature_rangenormalized_data = pd.DataFrame()if data.empty:raise ValueError("Input DataFrame is empty.")for col_index, col in enumerate(data.columns):c_max, c_min = data[col].max(), data[col].min()if best_values is None:c_mid = (y_max + y_min) / 2else:c_mid = best_values[col_index]normalized_values = 1 - abs(data[col] - c_mid) / (c_max - c_min)normalized_values *= (y_max - y_min)normalized_data[col] = normalized_valuesreturn normalized_data# 示例用法
#data=pd.DataFrame({'ph':[2,5,7,10,12],
# 'mid':[100,20,50,70,90],
# 'temperature':[-10,10,25,30,40]})
#normalized_data = mid_normalize(data[['ph', 'mid']], [7, 50])3.3 区间型指标
区间型指标是一种度量指标,其特点是具有明确的数值区间,通常表示一个范围或区间内的值。这种类型的指标提供了更多的信息,而不仅仅是单一的数值。区间型指标在统计学、经济学、工程学、生态学等领域经常被使用。
import numpy as np
import pandas as pddef section_normalize(data, feature_range=(0, 1), target_section=(40, 60)):"""区间型指标归一化Parameters:- data: 需要进行处理的DataFrame- feature_range: 设置归一化后的最小最大值,默认为 (0, 1)- target_section: 目标区间,表示在该区间内的值将被保持不变Returns:- normalized_data: 归一化后的DataFrame"""y_min, y_max = feature_rangenormalized_data = pd.DataFrame()if data.empty:raise ValueError("Input DataFrame is empty.")for col in data.columns:col_max, col_min = data[col].max(), data[col].min()distance_to_min = max((target_section[0] - col_min), 0)distance_to_max = max((col_max - target_section[1]), 0)c = distance_to_min + distance_to_max# 区间映射函数简化normalized_values = 1 - np.abs(data[col] - np.mean(target_section)) / c# 当数值位于目标区间内时,将归一化的值设为1mask = (data[col] >= target_section[0]) & (data[col] <= target_section[1])normalized_values[mask] = 1normalized_values = np.clip(normalized_values, 0, 1)normalized_values *= (y_max - y_min)# 标记后输出normalized_data[col] = normalized_valuesreturn normalized_data# 示例用法
# normalized_data = section_normalize(data[['temperature']], target_section=(20, 30))
4.后记
数据归一化是数据分析和机器学习中必不可少的步骤之一。它可以消除量纲影响,提高模型的性能和稳定性,加快模型的收敛速度,并方便特征选择过程。通过归一化,可以更好地理解和利用数据,提高模型的准确性和可解释性。
在进行数据归一化时,需要注意选择合适的归一化范围和方法,处理异常值,确定归一化顺序,并注意归一化的逆操作。通过合理的数据归一化处理,可以更好地利用数据进行分析和建模。
相关文章:
如何利用Python进行数据归一化?
1. 知识简介 数据归一化是数据预处理的一项重要步骤,它对于提高模型性能、加速模型训练、避免数值计算问题以及提高模型的泛化能力都具有重要作用。进行数据归一化可以起到以下作用:消除量纲影响,加速模型收敛,提高模型性能&…...
Linux 基本语句_13_消息队列
概念: 不同进程能通过消息队列来进行通信,不同进程也能获取或发送特定类型的消息,即选择性的收发消息。 一般一个程序采取子进程发消息,父进程收消息的模式 常用函数功能: fork(); // 创建子进程 struct msgbuf{ …...
Maven——仓库
Maven坐标和依赖是任何一个构件在Maven世界中的逻辑表示方式;而构件的物理表示方式是文件,Maven通过仓库来统一管理这些文件。 1、何为Maven仓库 在Maven世界中,任何一个依赖、插件或者项目构建的输出,都可以称为构件。例如&…...

Pandas:一个实用高效的Python数据处理库
个人网站 文章首发公众号:小肖学数据分析 导语: Pandas是一个强大且易于使用的Python数据处理库,广泛应用于数据分析和数据科学领域。本文将介绍Pandas库的基本概念、功能和使用方法,并提供详细的示例,帮助小白快速…...
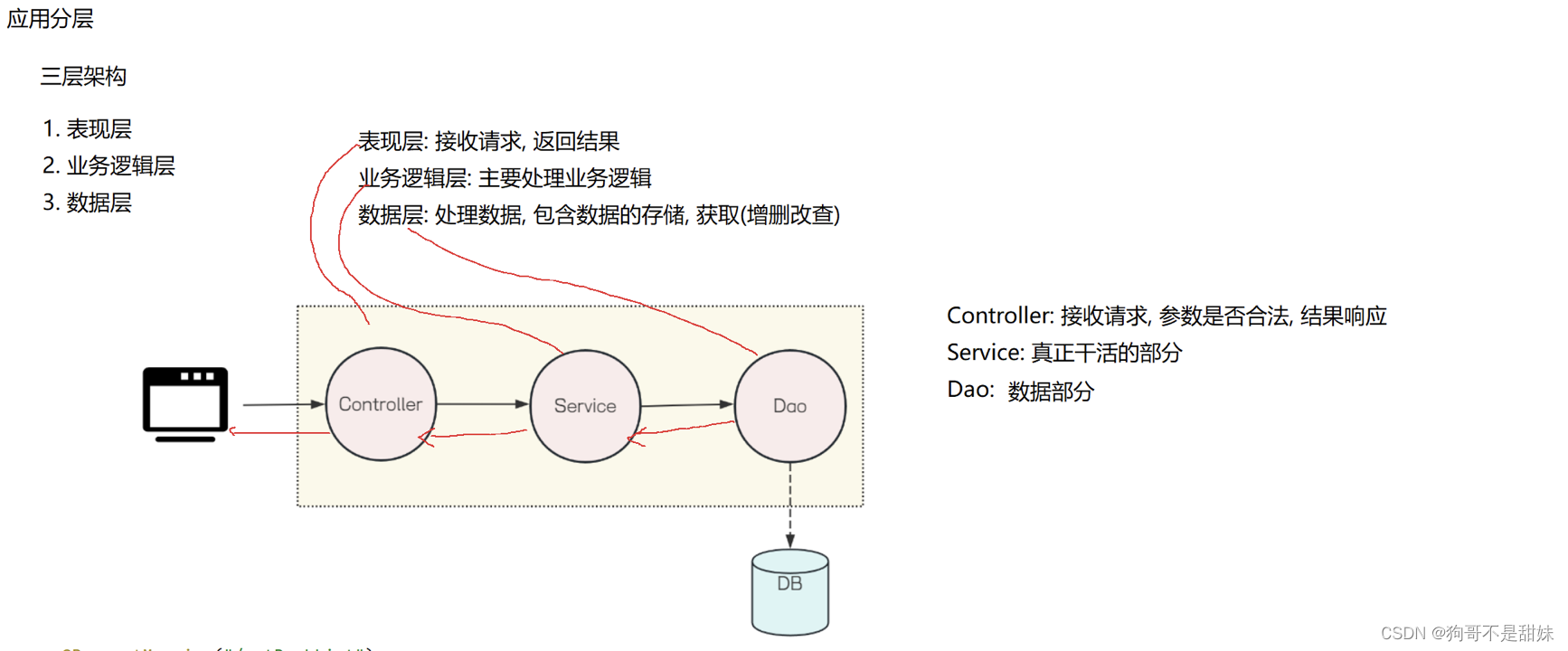
Spring第三课,Lombok工具包下载,对应图书管理系统列表和登录界面的后端代码,分层思想
目录 一、Lombok工具包下载 二、前后端互联的图书管理系统 规范 三、分层思想 三层架构: 1.表现层 2.业务逻辑层 3.数据层 一、Lombok工具包下载 这个工具包是为了做什么呢? 他是为了不去反复的设置setting and getting 而去产生的工具包 ⚠️工具…...

DDoS高防IP到底是什么?
DDoS高防IP是提供一个带防御的IP,主要是针对网络中的DDoS攻击进行保护,是针对互联网服务器遭受大流量的DDoS攻击后,导致服务不可用的情况下,用户可以通过配置高防IP,将攻击流量引流到高防IP上,从而确保源站…...
el-row错位问题解决
<el-row type"flex" style"flex-wrap:wrap">...

torch indices x[indices] 内存不足崩溃,python进程锁报错。
报错 Process Process-167: Traceback (most recent call last):File "/usr/lib/python3.10/multiprocessing/process.py", line 317, in _bootstraputil._exit_function()File "/usr/lib/python3.10/multiprocessing/util.py", line 360, in _exit_funct…...
第二证券:机构争分夺秒抢滩 金融大模型落地为时尚早
本年以来,大模型席卷金融业,一夜之间,简直悉数金融场景都在探索适配大模型接口。但是,志向丰满,实践骨感。有大型金融组织IT部分人士比方,金融大模型从战略规划到安顿落地,有着从“卖家秀”走到…...

C#WPF使用MaterialDesign 显示带遮罩的对话框
第一步定义对话框 <UserControlx:Class="TemplateDemo.Views.Edit.UCEditUser"xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d="http://schemas.m…...

Nuxt.js:下一代Web开发框架的革命性力量
文章目录 一、Nuxt.js简介二、Nuxt.js的特点1. 集成Vue.js和Node.js2. 自动代码分割和优化3. 服务端渲染(SSR)4. 强大的路由管理5. 丰富的插件系统 三、Nuxt.js的优势1. 提高开发效率2. 降低维护成本3. 提高用户体验 四、Nuxt.js在实际应用中的案例1. 电…...

【JavaEE初阶】死锁问题
目录 一、死锁的三种典型场景 1、一个线程,一把锁 2、两个线程,两把锁 3、N个线程,M把锁 死锁,是多线程代码中的一类经典问题。我们知道加锁是能解决线程安全问题的,但是如果加锁的方式不当,就可能产生死…...
uniapp 打包的 IOS打开白屏 uniapp打包页面空白
uniapp的路由跟vue一样,有hash模式和history模式, 使用 URL 的 hash 来模拟一个完整的 URL,于是当 URL 改变时,页面不会重新加载。 如果不想要很丑的 hash,我们可以用路由的 history 模式,这种模式充分利用 history.pushState API 来完成 URL 跳转而无须重新加载页面。…...
在 Redis 中使用 JSON 文档:命令行界面(CLI)和 Navicat 集成
Redis,因其极高的性能而闻名,是一款多功能的 NoSQL 数据库,擅长处理键值对。虽然 Redis主要用于处理简单数据结构,但是同样支持更多复杂的数据类型,如列表、集合甚至是 JSON 文件。在本文,我们将深入到 Red…...
Win Server 2019远程桌面服务部署
一、添加远程桌面授权服务 服务器管理 - 添加角色和功能打开“添加角色和功能向导”窗口,选择基于角色或给予功能安装: 打开服务器管理,打开角色和功能,添加远程回话主机和远程桌面授权 image.png 以上配置完成后使用期限为120…...
vue3-在自定义hooks使用useRouter 报错问题
文章目录 前言一、报错分析报错的Vue warn截图:查看文档 二、那么在hook要怎么引入路由呢? 前言 记录在vue3项目中,hook使用useRouter 报错问题 一、报错分析 报错的Vue warn截图: 警告 inject() can only be used inside setup…...
深度学习框架:Pytorch与Keras的区别与使用方法
☁️主页 Nowl 🔥专栏《机器学习实战》 《机器学习》 📑君子坐而论道,少年起而行之 文章目录 Pytorch与Keras介绍 Pytorch 模型定义 模型编译 模型训练 输入格式 完整代码 Keras 模型定义 模型编译 模型训练 输入格式 完整代…...
1145. 北极通讯网络(Kruskal,并查集维护)
北极的某区域共有 n 座村庄,每座村庄的坐标用一对整数 (x,y) 表示。 为了加强联系,决定在村庄之间建立通讯网络,使每两座村庄之间都可以直接或间接通讯。 通讯工具可以是无线电收发机,也可以是卫星设备。 无线电收发机有多种不…...

【23-24 秋学期】NNDL 作业9 RNN - SRN
简单循环网络(Simple Recurrent Network,SRN)只有一个隐藏层的神经网络. 目录 1. 实现SRN (1)使用Numpy (2)在1的基础上,增加激活函数tanh (3࿰…...
Docker + Jenkins + Nginx实现前端自动化部署
目录 前言一、前期准备工作1、示例环境2、安装docker3、安装Docker Compose4、安装Git5、安装Nginx和Jenkinsnginx.confdocker-compose.yml 6、启动环境7、验证Nginx8、验证Jenkins 二、Jenkins 自动化部署配置1、设置中文2、安装Publish Over SSH、NodeJS(1&#x…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

Claude Mythos Preview首月揪万余漏洞、拦截150万美元电诈,网络安全格局将变?
玻璃翼计划首战告捷A厂的玻璃翼计划首战告捷,Mythos 30天内就挖出1万个致命漏洞,甚至拦截了150万美元电诈。面对雪片式的报告,人类程序员崩溃求饶:「求别挖了,根本修不完啊!」就在刚刚,Anthropi…...
)
保姆级教程:在Ubuntu 22.04上搞定水星MW310UH无线网卡驱动(含安全启动关闭指南)
水星MW310UH无线网卡在Ubuntu 22.04的完整驱动指南当你刚拿到水星MW310UH无线网卡,满心欢喜地插入Ubuntu 22.04系统,却发现系统毫无反应时,那种挫败感我深有体会。作为一款性价比极高的USB无线网卡,MW310UH在Windows下即插即用&am…...

BetterJoy终极配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy终极配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

VMnet8 的8到底是什么意思?
它的本质是:8 仅仅是一个 内部标识符 (Internal Identifier) 或 数组索引 (Array Index),用于在 VMware 的虚拟化网络栈中唯一标识 NAT 模式 对应的虚拟交换机实例。它没有任何数学、物理或协议层面的特殊含义(如端口号、版本号或二进制位&am…...

谷歌CEO承认Coding落后了
梦瑶 发自 凹非寺量子位 | 公众号 QbitAI谷歌CEO皮查伊这次真没藏着掖着,直接一个真心话大放送了:在Coding这事儿上,我们家Gemini确实有点了落后哈…..(Gemini:怎么这话还从我自家老板嘴里说出来了呢!&…...