【UCAS自然语言处理作业二】训练FFN, RNN, Attention机制的语言模型,并计算测试集上的PPL
文章目录
- 前言
- 前馈神经网络
- 数据组织
- Dataset
- 网络结构
- 训练
- 超参设置
- RNN
- 数据组织&Dataset
- 网络结构
- 训练
- 超参设置
- 注意力网络
- 数据组织&Dataset
- 网络结构
- Attention部分
- 完整模型
- 训练部分
- 超参设置
- 结果与分析
- 训练集Loss
- 测试集PPL
前言
本次实验主要针对前馈神经网络,RNN,以及基于注意力机制的网络学习语言建模任务,并在测试集上计算不同语言模型的PPL
- PPL计算:我们采用
teacher forcing的方式,给定ground truth context,让其预测next token,并将这些token的log probability进行平均,作为文本的PPL。 CrossEntropyLoss:可以等价于PPL的计算,因此,我们将交叉熵损失作为ppl,具体原理可参考本人博客:如何计算文本的困惑度perplexity(ppl)_ppl计算_长命百岁️的博客-CSDN博客- 我们将数据分为训练集和测试集(后1000条)
- 分词采用
bart-base-chinese使用的tokenizer,词表大小为21128。当然,也可以利用其他分词工具构建词表 - 本文仅对重要的实验代码进行说明
前馈神经网络
数据组织
我们利用前馈神经网络,训练一个2-gram语言模型,即每次利用两个token来预测下一个token
def get_n_gram_data(self, data, n):res_data = []res_label = []if len(data) < n:raise VallueError("too short")start_idx = 0while start_idx + n <= len(data):res_data.append(data[start_idx: start_idx + n - 1])res_label.append(data[start_idx + n - 1])start_idx += 1return res_data, res_label
- 该函数的输入是一个分词后的
token_ids列表,输出是将这个ids分成不同的data, label对
def get_data(path, n):res_data = []res_label = []tokenizer = BertTokenizer.from_pretrained('/users/nishiyu/ict/Models/bart-base-chinese')with open(path) as file:data = file.readlines()for sample in data:sample_data, sample_label = get_n_gram_data(tokenizer(sample, return_tensors='pt')['input_ids'][0], n)for idx in range(len(sample_data)):res_data.append(sample_data[idx])res_label.append(sample_label[idx])return res_data, res_label
- 该函数对数据集中的每条数据进行分词,并得到对应的
data, label对 - 值得注意的是,这样所有的输入/输出都是等长的,因此可以直接组装成batch
Dataset
class NGramDataset(Dataset):def __init__(self, data_path, window_size=3):self.data, self.label = get_data(data_path, window_size)def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i], self.label[i]
- 通过
window_size来指定n-gram - 每次访问返回
data,label
网络结构
class FeedForwardNNLM(nn.Module):def __init__(self, vocab_size, embedding_dim, window_size, hidden_dim):super(FeedForwardNNLM, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim)self.e2h = nn.Linear((window_size - 1) * embedding_dim, hidden_dim)self.h2o = nn.Linear(hidden_dim, vocab_size)self.activate = F.reludef forward(self, inputs):embeds = self.embeddings(inputs).reshape([inputs.shape[0], -1])hidden = self.activate(self.e2h(embeds))output = self.h2o(hidden)return output
- 网络流程:
embedding层->全连接层->激活函数->线性层词表映射
训练
class Trainer():def __init__(self, args, embedding_dim, hidden_dim):self.args = argsself.model = FeedForwardNNLM(self.args.vocab_size, embedding_dim, args.window_size, hidden_dim)self.train_dataset = NGramDataset(self.args.train_data, self.args.window_size)self.train_dataloader = DataLoader(self.train_dataset, batch_size=args.batch_size, shuffle=True)self.test_dataset = NGramDataset(self.args.test_data, self.args.window_size)self.test_dataloader = DataLoader(self.test_dataset, batch_size=args.batch_size, shuffle=False)def train(self):self.model.train()device = torch.device('cuda')self.model.to(device)criterion = nn.CrossEntropyLoss()optimizer = Adam(self.model.parameters(), lr=5e-5)for epoch in range(args.epoch):total_loss = 0.0for step, batch in enumerate(self.train_dataloader):input_ids = batch[0].to(device)label_ids = batch[1].to(device)logits = self.model(input_ids)loss = criterion(logits, label_ids)loss.backward()optimizer.step()self.model.zero_grad()total_loss += lossprint(f'epoch: {epoch}, train loss: {total_loss / len(self.train_dataloader)}')self.evaluation()
- 首先调用
dataset和dataloader对数据进行组织 - 然后利用
CrossEntropyLoss,Adam优化器(lr=5e-5)进行训练 - 评估测试集效果
超参设置
def get_args():parser = argparse.ArgumentParser()# 添加命令行参数parser.add_argument('--vocab_size', type=int, default=21128)parser.add_argument('--train_data', type=str)parser.add_argument('--test_data', type=str)parser.add_argument('--window_size', type=int)parser.add_argument('--epoch', type=int, default=50)parser.add_argument('--batch_size', type=int, default=4096)args = parser.parse_args()return args
embedding_dim=128hidden_dim=256epoch= 150
RNN
数据组织&Dataset
RNN的数据组织比较简单,就是每一行作为一个输入就可以,不详细展开
网络结构
class RNNLanguageModel(nn.Module):def __init__(self, args, embedding_dim, hidden_dim):super(RNNLanguageModel, self).__init__()self.args = argsself.embeddings = nn.Embedding(self.args.vocab_size, embedding_dim)self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)self.linear = nn.Linear(hidden_dim, self.args.vocab_size)def forward(self, inputs):embeds = self.embeddings(inputs)output, hidden = self.rnn(embeds)output = self.linear(output)return output
- 网络流程:
embedding->rnn网络->线性层词表映射 - 这里
RNN模型直接调用API
训练
自回归模型的训练是值得注意的
class Trainer():def __init__(self, args, embed_dim, head_dim):self.args = argsself.tokenizer = BertTokenizer.from_pretrained('/users/nishiyu/ict/Models/bart-base-chinese')self.model = RNNLanguageModel(args, embed_dim, head_dim)self.train_dataset = AttenDataset(self.args.train_data)self.train_dataloader = DataLoader(self.train_dataset, batch_size=args.batch_size, shuffle=True)self.test_dataset = AttenDataset(self.args.test_data)self.test_dataloader = DataLoader(self.test_dataset, batch_size=args.batch_size, shuffle=False)def train(self):self.model.to(self.args.device)criterion = nn.CrossEntropyLoss()optimizer = Adam(self.model.parameters(), lr=5e-5)for epoch in range(args.epoch):self.model.train()total_loss = 0.0for step, batch in enumerate(self.train_dataloader):tokens = self.tokenizer(batch, truncation=True, padding=True, max_length=self.args.max_len, return_tensors='pt').to(self.args.device)input_ids = tokens['input_ids'][:, :-1]label_ids = tokens['input_ids'][:, 1:].clone()pad_token_id = self.tokenizer.pad_token_idlabel_ids[label_ids == pad_token_id] = -100 logits = self.model(input_ids)loss = criterion(logits.view(-1, self.args.vocab_size), label_ids.view(-1))loss.backward()optimizer.step()self.model.zero_grad()total_loss += lossprint(f'epoch: {epoch}, train loss: {total_loss / len(self.train_dataloader)}')self.evaluation()
-
与FFN不同的是,我们在需要数据的时候才进行分词
-
注意到,数据集中不同数据的长度是不同的,我们想要将这些数据组织成batch,进行并行化训练,需要加padding。在训练过程中我们选择右padding
input_ids = tokens['input_ids'][:, :-1] label_ids = tokens['input_ids'][:, 1:].clone() pad_token_id = self.tokenizer.pad_token_id label_ids[label_ids == pad_token_id] = -100- 这四句是训练的核心代码,决定是否正确,从上往下分别是:
- 组织输入:因为我们要预测下一个token,因此,输入最多就进行到倒数第二个token,所以不要最后一个
- 组织label:因为我们要预测下一个token,因此作为label来说,不需要第一个token
- 组织loss:对于padding部分的token,是不需要计算loss的,因此我们将padding部分对应的label_ids设置为-100,这是因为,损失函数默认id为-100的token为pad部分,不进行loss计算
- 这四句是训练的核心代码,决定是否正确,从上往下分别是:
超参设置
embedding_dim=512hidden_dim=128epoch=30batch_size=12
注意力网络
数据组织&Dataset
与RNN完全相同,不进行介绍
网络结构
因为此网络比较重要,我之前也BART, GPT-2等模型的源码,因此我们选择自己写一个一层的decoder-only模型
- 我们主要实现了自注意力机制
- 对
dropout,layerNorm,残差链接等操作并没有关注
Attention部分
class SelfAttention(nn.Module):def __init__(self,args,embed_dim: int,num_heads: int,bias = True):super(SelfAttention, self).__init__()self.args = argsself.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsself.scaling = self.head_dim**-0.5self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()def forward(self, hidden_states: torch.Tensor):"""Input shape: Batch x seq_len x dim"""bsz, tgt_len, _ = hidden_states.size()# get query projquery_states = self.q_proj(hidden_states) * self.scaling# self_attentionkey_states = self._shape(self.k_proj(hidden_states), -1, bsz) # bsz, heads, seq_len, dimvalue_states = self._shape(self.v_proj(hidden_states), -1, bsz)proj_shape = (bsz * self.num_heads, -1, self.head_dim)query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape) # bsz_heads, seq_len, dimkey_states = key_states.reshape(*proj_shape)value_states = value_states.reshape(*proj_shape)attn_weights = torch.bmm(query_states, key_states.transpose(1, 2)) # bsz*head_num, tgt_len, src_lensrc_len = key_states.size(1)# causal_maskmask_value = torch.finfo(attn_weights.dtype).minmatrix = torch.ones(bsz * self.num_heads, src_len, tgt_len).to(self.args.device)causal_mask = torch.triu(matrix, diagonal=1)causal_weights = torch.where(causal_mask.byte(), mask_value, causal_mask.double())attn_weights += causal_weights# do not need attn_maskattn_probs = nn.functional.softmax(attn_weights, dim=-1)# get outputattn_output = torch.bmm(attn_probs, value_states)attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)attn_output = attn_output.transpose(1, 2)attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)attn_output = self.out_proj(attn_output)return attn_output
- 首先我们定义了
embed_dim, 多少个头,以及K,Q,V的映射矩阵 - forward函数的输入是一个batch的embedding,流程如下
- 将输入分别映射为
K, Q, V, 并将尺寸转换为多头的形式,shape(bsz*num_heads, seq_len, dim) - 进行
casual mask- 首先定义一个当前数据个数下的最小值,当一个数加上这个值再进行softmax,概率基本为0
- 根据
K, Q, V,得到一个分数矩阵attn_weights - 然后定义一个大小为
bsz * self.num_heads, src_len, tgt_len的全1矩阵 - 将该矩阵变成一个上三角矩阵,其中为1的地方,代表着当前位置需要进行mask,其他位置都是0
- 对于矩阵中为1的地方,我们用定义的最小值来替换、
- 将分数矩阵与mask矩阵相加,就实现了一个causal 分数矩阵
- 然后进行
softmax,通过V得到目标向量
- 为什么没有对padding进行mask?
- 因为不需要,我们进行的是右padding,所以causal mask已经对后面的padding进行了mask
- 另外,当真正的输入输出算完后,对于后面padding位置对应的输出,是不统计loss的,因此padding没有影响
- 将输入分别映射为
完整模型
class AttentionModel(nn.Module):def __init__(self, args, embed_dim, head_num):super(AttentionModel, self).__init__()self.args = argsself.embeddings = nn.Embedding(self.args.vocab_size, embed_dim)self.p_embeddings = nn.Embedding(self.args.max_len, embed_dim)self.attention = SelfAttention(self.args, embed_dim, head_num)self.output = nn.Linear(embed_dim, self.args.vocab_size)def forward(self, input_ids, attn_mask):embeddings = self.embeddings(input_ids)position_embeddings = self.p_embeddings(torch.arange(0, input_ids.shape[1], device=self.args.device))embeddings = embeddings + position_embeddingsoutput = self.attention(embeddings, attn_mask)logits = self.output(output)return logits
- 我们不仅做了embedding,还实现了position embedding
训练部分
训练阶段与RNN一直,也是组织输入,输出,以及loss
超参设置
embed_dim=512num_head=8epoch=30batch_size=12
结果与分析
训练集Loss
-
FFN loss(最小值4.332110404968262)

-
RNN loss(最小值4.00740385055542)

-
Attention loss(最小值3.7037367820739746)

测试集PPL
-
FFN(最小值4.401318073272705)

-
RNN(最小值4.0991902351379395)

-
Attention(最小值3.9784348011016846)

从结果来看,无论是train loss, 还是test ppl,均有FFN>RNN>Attention的关系,且我们看到后两个模型还未完全收敛,性能仍有上升空间。
- 尽管FFN的任务更简单,其性能仍最差,这是因为其模型结构过于简单
- RNN与Attention任务一致,但性能更差
- Attention性能最好,这些观察均符合基本认识
代码可见:ShiyuNee/Train-A-Language-Model-based-on-FFN-RNN-Attention (github.com)
相关文章:
【UCAS自然语言处理作业二】训练FFN, RNN, Attention机制的语言模型,并计算测试集上的PPL
文章目录 前言前馈神经网络数据组织Dataset网络结构训练超参设置 RNN数据组织&Dataset网络结构训练超参设置 注意力网络数据组织&Dataset网络结构Attention部分完整模型 训练部分超参设置 结果与分析训练集Loss测试集PPL 前言 本次实验主要针对前馈神经网络࿰…...
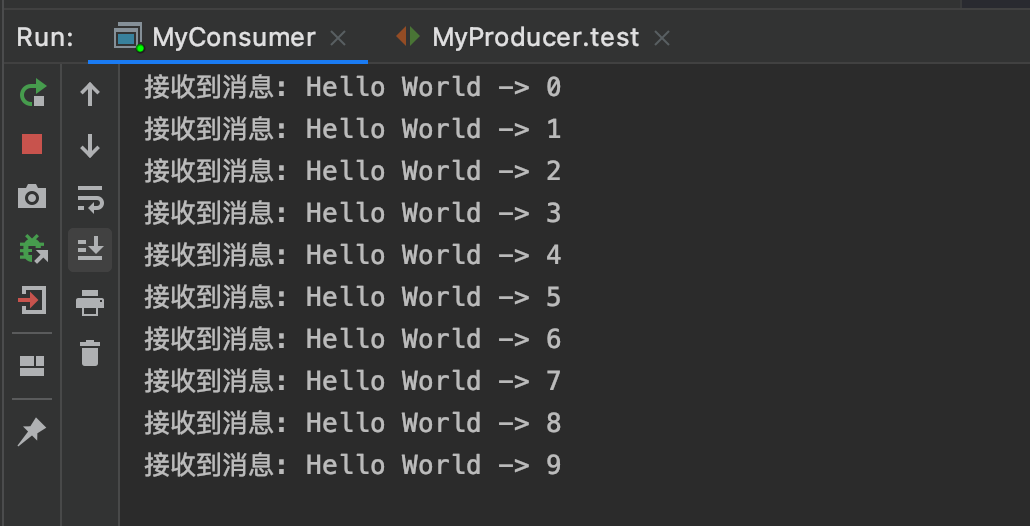
RabbitMQ消息模型之Sample
Hello World Hello World是官网给出的第一个模型,使用的交换机类型是直连direct,也是默认的交换机类型。 在上图的模型中,有以下概念: P:生产者,也就是要发送消息的程序C:消费者:消…...

安全技术与防火墙
目录 安全技术 防火墙 按保护范围划分: 按实现方式划分: 按网络协议划分. 数据包 四表五链 规则链 默认包括5种规则链 规则表 默认包括4个规则表 四表 查询 格式: 规则 面试题 NFS常见故障解决方法 安全技术 入侵检测系统 (Intrusion Detection Sy…...
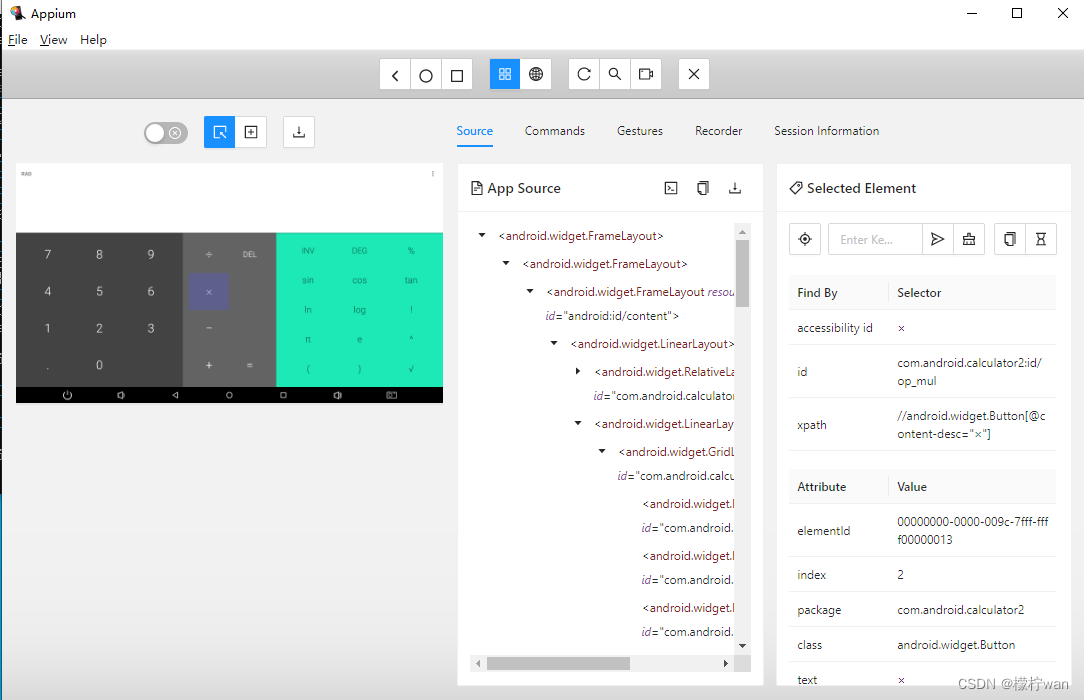
Windows系统搭建Appium 2 和 Appium Inspector 环境
前言 自 2022 年 1 月 1 日起,Appium 核心团队不再维护 Appium 1.x。官方支持的平台驱动程序的所有最新版本均不兼容 Appium 1.x,需要 Appium 2 才能运行。 Appium 2是一个自动化移动应用程序的开源工具,它带来了以下重要改进: …...

计算机应用基础_错题集_OutLook操作题_操作系统应用题_电子表格---网络教育统考工作笔记005
6、(说明:考生单击窗口下方的“打开[Outlook]应用程序”启动Outlook) 按以下要求保存草稿。 收件人:test_xiao_ming@163.com...

2023-11-26 LeetCode每日一题(统计子串中的唯一字符)
2023-11-26每日一题 一、题目编号 828. 统计子串中的唯一字符二、题目链接 点击跳转到题目位置 三、题目描述 我们定义了一个函数 countUniqueChars(s) 来统计字符串 s 中的唯一字符,并返回唯一字符的个数。 例如:s “LEETCODE” ,则其…...

HTML新手入门笔记整理:特殊符号
音标符 音标符 字符 Construct 输出结果 ̀、 a a à ́′ a a án ˆ a a â ̃~ a a ã ̀̀、 O O Ò ́́′ O O Ó ˆ O O Ô ̃~ O O Õ 字符 显示结果 描述 实体名称 实体编号 空格 <…...
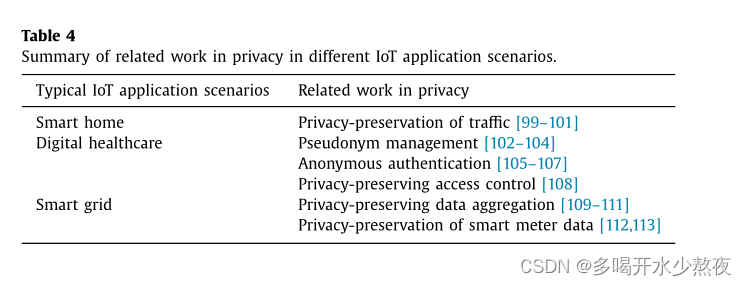
物联网中基于信任的安全性调查研究:挑战与问题
A survey study on trust-based security in Internet of Things: Challenges and issues 文章目录 a b s t r a c t1. Introduction2. Related work3. IoT security from the one-stop dimension3.1. Output data related security3.1.1. Confidentiality3.1.2. Authenticity …...

tex2D使用学习
1. 背景: 项目中使用到了纹理进行插值的加速,因此记录一些自己在学习tex2D的一些过程 2. 代码: #include "cuda_runtime.h" #include "device_launch_parameters.h" #include <assert.h> #include <stdio.h>…...

[iOS开发]UITableView的性能优化
一些基础的优化 (一)CPU 1. 用轻量级对象 比如用不到事件处理的地方,可以考虑使用 CALayer 取代 UIView CALayer * imageLayer [CALayer layer]; imageLayer.bounds CGRectMake(0,0,200,100); imageLayer.position CGPointMake(200,200…...

使用opencv实现图像滤波
1 图像滤波介绍 滤波是信号和图像处理中的基本任务之一,其旨在有选择地提取图像的某些特征,可以用于在给定应用程序的上下文中传达重要信息,例如,去除图像中的噪声、提取所需的视觉特征、图像重采样等。 1.1 图像滤波理论 图像…...
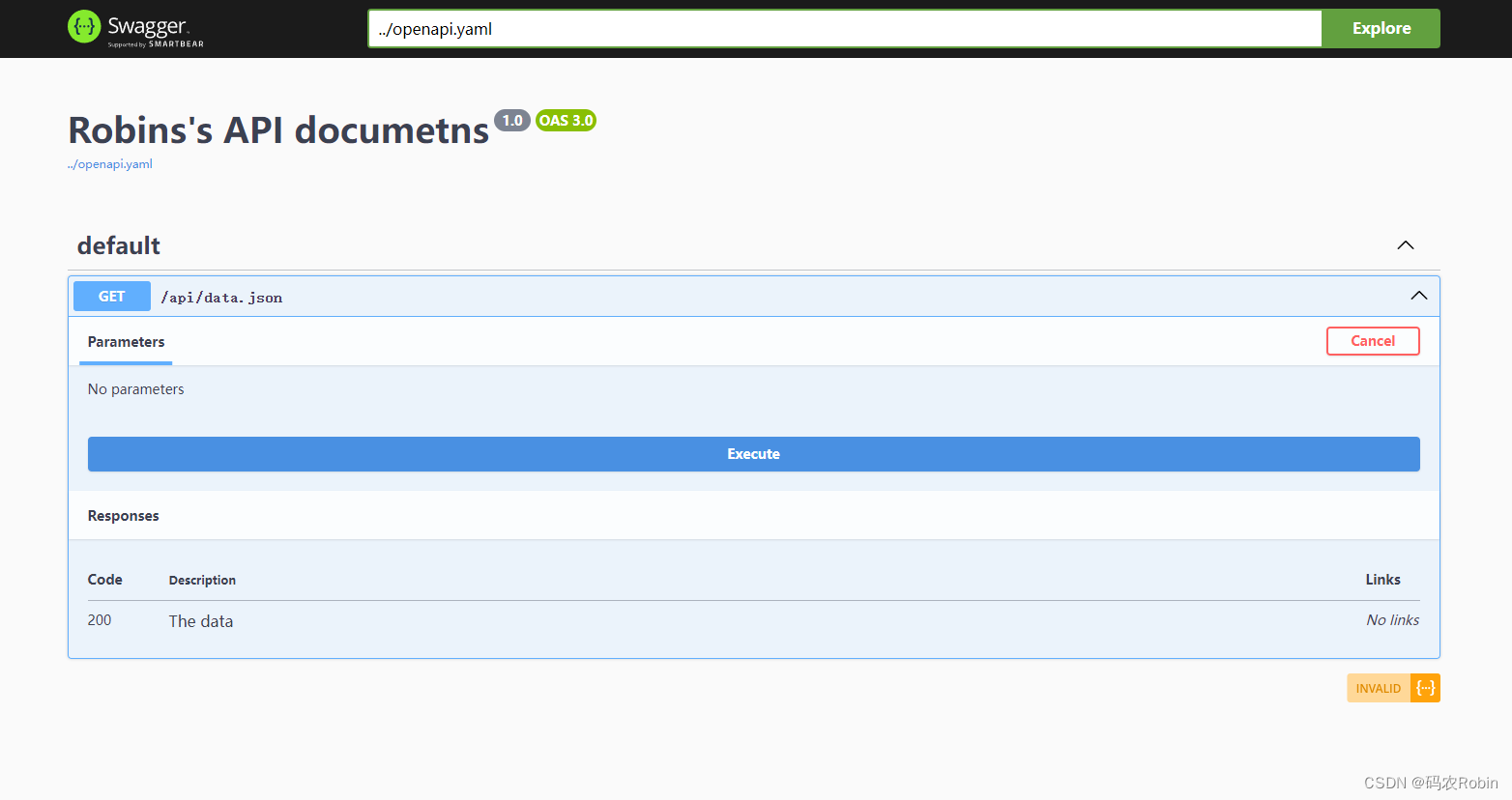
Swagger在php和java项目中的应用
Swagger在php和java项目中的应用 Swagger简介Swagger在java项目中的应用步骤常用注解 Swagger在php项目中的应用 Swagger简介 Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。 总体目标是使客户端和文件系统作为服务器以…...
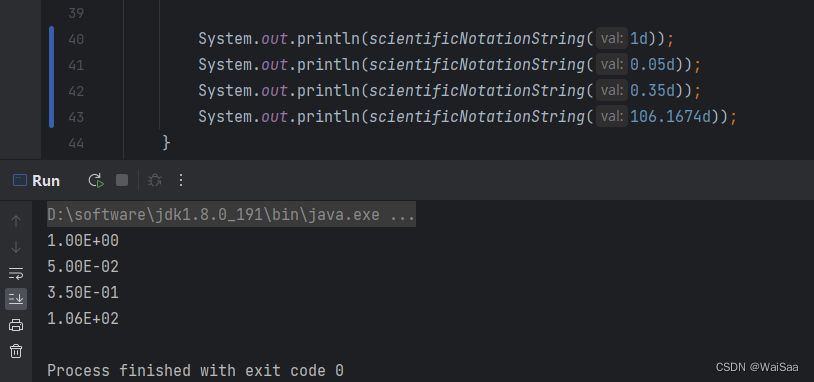
java科学计数法表示数值
Background 大多数计算器及计算机程序用科学记数法显示非常大和非常小的结果;但很多时候,我们需要做一个统一,要么全部以科学计数法输出,要么就全部显示为普通计数。注意:这里对大于等于1的数据做了特殊处理࿰…...
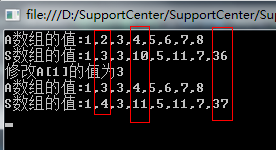
基于C#实现树状数组
有一种数据结构是神奇的,神秘的,它展现了位运算与数组结合的神奇魅力,太牛逼的,它就是树状数组,这种数据结构不是神人是发现不了的。 一、概序 假如我现在有个需求,就是要频繁的求数组的前 n 项和&#x…...

Ubuntu Server 20.04.6下Anaconda3安装Pytorch
环境 Ubuntu 20.04.6 LTS Anaconda3-2023.09-0-Linux-x86_64.sh conda 23.7.4 Pytorch 1.11.0 安装 先创建一个工作环境,环境名叫lia: conda create -n lia python3.8环境的使用方法如下: conda activate lia # 激活环境 conda deactiv…...

C#-关于日志的功能扩展
目录 一、日志Sink(接收器) 二、Trace追踪实现日志 三、日志滚动 一、日志Sink(接收器) 安装NuGet包:Serilog Sink有很多种,这里介绍两种: Console接收器(安装Serilog.Sinks.Console); File接收器(安装…...
小程序禁止二次转发分享私密消息动态消息
第一种用法:私密消息 私密消息:运营人员分享小程序到个人或群之后,该消息只能在被分享者或被分享群内打开,不可以二次转发。 用途:主要用于不希望目标客群外的人员看到的分享信息,比如带有较高金额活动的…...

普乐蛙绵阳科博会一场VR科普航天科学盛宴科普知识
普乐蛙绵阳科普展:一场科学盛宴,点燃孩子探索欲望的火花! 普乐蛙绵阳科普展正在如火如荼地进行中,吸引了无数孩子和家长的热情参与。这场科普盛宴以独特的内外视角,让人们感受到科学的魅力,激发了孩子们对知识的渴望和…...

FFNPEG编译脚本
下面是一个ffmpeg编译脚本: #!/bin/bash set -eu -o pipefail set eu o pipefailFFMPEG_TAGn4.5-dev build_path$1 git_repo"https://github.com/FFmpeg/FFmpeg.git" cache_tool"" sysroot"" c_compiler"gcc" cxx_compile…...

Python期末复习题库(下)——“Python”
小雅兰期末加油冲冲冲!!! 1. (单选题)下列关于文件打开模式的说法,错误的是( C )。 A. r代表以只读方式打开文件 B. w代表以只写方式打开文件 C. a代表以二进制形式打开文件 D. 模式中使用时,文件可读可写 2. (单选题)下列选项中,以追加…...

python flash加一个字段
USE product_db; ALTER TABLE products ADD COLUMN remark TEXT COMMENT 商品备注信息,支持长文本 AFTER cost_price;2. 修改数据访问层(product_dao.py)需要在以下函数中添加 remark 字段的处理:修改 get_all_products 函数&…...

【Elasticsearch从入门到精通】第15篇:Elasticsearch删除与更新API——精确操作与脚本更新
上一篇【第14篇】Elasticsearch文档检索API——GET、MGet与字段选择 下一篇【第16篇】Elasticsearch批量操作API——Bulk、Reindex与跨集群索引 摘要 数据的删除和更新是Elasticsearch文档操作中不可或缺的环节。本文全面讲解了Elasticsearch删除与更新API的使用方法ÿ…...

Burp Suite渗透测试工作流:从环境搭建到报告生成
1. 这不是“学个工具”,而是一套可复用的渗透工作流很多人点开“Burp Suite 入门”类教程,心里想的是:“装个插件、抓个包、改个参数,不就完事了?”——结果三天后连 repeater 怎么发 POST 请求都得翻笔记。我带过二十…...

【Appium 系列】第20节-测试项目结构设计 — 从脚本到工程
对应代码:配套代码/test/ 完整目录结构说明:本节讲解如何组织一个中大型 Appium 测试项目,从目录结构到文件职责,从脚本到工程的演进。这节讲什么测试项目从小到大会经历三个阶段:阶段 1:脚本阶段test_logi…...

暗黑2存档修改终极指南:5分钟学会免费d2s文件编辑器
暗黑2存档修改终极指南:5分钟学会免费d2s文件编辑器 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 暗黑破坏神2的d2s存档编辑器是一款专为玩家设计的强大工具,让你能够轻松修改角色属性、管理装备和调整…...

开发者在多模型项目中如何利用 Taotoken 进行灵活路由与降级
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在多模型项目中如何利用 Taotoken 进行灵活路由与降级 在构建依赖大模型服务的应用时,服务的连续性与稳定性是开…...

G-Helper终极指南:三步打造高效轻量的华硕笔记本控制中心
G-Helper终极指南:三步打造高效轻量的华硕笔记本控制中心 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

通过Taotoken接入Claude Code解决编程助手Token不足与封号困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken接入Claude Code解决编程助手Token不足与封号困扰 许多开发者将Claude Code作为日常编程的得力助手,用于代…...

12点标定
12点标定九点标定和十二点标定转换本质是两个平面二维空间的转换两个平面的二维空间的转换公式X物理 X图像200 k * 2 k缩放系数 k2/2000.01剪切图像是一个标准的二维平面空间物理世界,某个固定高度的平面物理空间 高度为5的,板子的所在的物理平面空间…...

终极指南:如何使用Play Integrity API检查器确保Android设备安全
终极指南:如何使用Play Integrity API检查器确保Android设备安全 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-app…...